Servlet 3.0异步处理可将服务器吞吐量提高十倍
我们的JCG合作伙伴之一Tomasz Nurkiewicz最近写了一篇非常不错的文章, 介绍如何使用异步处理来提高服务器的吞吐量 。 让我们找出他是如何做到的。
(注意:对原始帖子进行了少量编辑以提高可读性)
Java servlet容器并不特别适合处理大量并发用户,这不是秘密。 通用的每请求线程数模型有效地将并发连接数限制为JVM可以处理的并发运行线程数。 而且,由于每个新线程都会显着增加内存占用量和CPU利用率(上下文切换),因此处理100-200个以上的并发连接在Java中似乎是一个荒谬的想法。 至少在Servlet 3.0之前的时代。
在本文中,我们将编写一个具有速度限制的可伸缩且健壮的文件服务器。 在第二个版本中,利用Servlet 3.0异步处理功能,我们将能够使用更少的线程来处理10倍大的负载。 无需额外的硬件,只需做出一些明智的设计决策即可。
令牌桶算法
建立文件服务器,我们必须自觉地管理我们的资源,尤其是网络带宽。 我们不希望单个客户端消耗全部流量,我们甚至可能希望根据用户,一天中的时间等在运行时动态限制下载限制-当然,所有操作都在高负载下发生。 开发人员喜欢重新发明轮子,但是我们的所有要求已经通过简单的令牌桶算法解决了 。
Wikipedia中的解释非常好,但是由于我们会根据需要对算法进行一些调整,因此这里的描述更加简单。 首先有一个水桶。 在这个桶里有统一的令牌。 每个令牌价值20 kiB(我将使用我们应用程序中的实际值)的原始数据。 客户端每次请求文件时,服务器都会尝试从存储桶中获取一个令牌。 如果成功,他将20 kiB发送给客户端。 重复最后两个句子。 如果服务器由于存储桶已经为空而无法获取令牌,该怎么办? 他在等。
那么代币从哪里来呢? 后台进程不时充满水桶。 现在变得清楚了。 如果此后台进程每100毫秒(每秒10次)添加100个新令牌,每个令牌价值20 kiB,则服务器最多可以发送20 MiB / s(100乘以20 kiB乘以10),在所有客户端之间共享。 当然,如果存储桶已满(1000个令牌),则将忽略新令牌。 这非常好用–如果存储桶为空,则客户正在等待下一个存储桶填充周期; 通过控制存储桶容量,我们可以限制总带宽。
言归正传,我们对令牌桶的简化实现是从一个接口开始的(整个源代码可在GitHub的global-bucket分支中找到):
public interface TokenBucket {int TOKEN_PERMIT_SIZE = 1024 * 20;void takeBlocking() throws InterruptedException;void takeBlocking(int howMany) throws InterruptedException;boolean tryTake();boolean tryTake(int howMany);}takeBlocking()方法同步等待令牌可用,而tryTake()仅在令牌可用时接受令牌,如果采用则立即返回true,否则返回false。 幸运的是,术语存储桶只是一个抽象:因为令牌是无法区分的,我们需要实现的所有操作都是存储桶,它是一个整数计数器。 但是,由于存储桶本质上是多线程的,并且涉及一些等待,因此我们需要更复杂的机制。 信号量似乎几乎是理想的:
@Service
@ManagedResource
public class GlobalTokenBucket extends TokenBucketSupport {private final Semaphore bucketSize = new Semaphore(0, false);private volatile int bucketCapacity = 1000;public static final int BUCKET_FILLS_PER_SECOND = 10;@Overridepublic void takeBlocking(int howMany) throws InterruptedException {bucketSize.acquire(howMany);}@Overridepublic boolean tryTake(int howMany) {return bucketSize.tryAcquire(howMany);}}信号量完全符合我们的要求。 bucketSize表示存储桶中当前的令牌数量。 另一方面,bucketCapacity限制了存储桶的最大大小。 它是易变的,因为可以通过JMX对其进行修改(可见性):
@ManagedAttribute
public int getBucketCapacity() {return bucketCapacity;
}@ManagedAttribute
public void setBucketCapacity(int bucketCapacity) {isTrue(bucketCapacity >= 0);this.bucketCapacity = bucketCapacity;
}如您所见,我正在使用Spring及其对JMX的支持。 Spring框架在此应用程序中不是绝对必要的,但是它带来了一些不错的功能。 例如,实现一个定期填充存储桶的后台进程如下所示:
@Scheduled(fixedRate = 1000 / BUCKET_FILLS_PER_SECOND)
public void fillBucket() {final int releaseCount = min(bucketCapacity / BUCKET_FILLS_PER_SECOND, bucketCapacity - bucketSize.availablePermits());bucketSize.release(releaseCount);
}这段代码包含主要的多线程错误,出于本文的目的,我们可以将其忽略。 假设将水桶装满最大值–它会一直工作吗?
此外,这是使@Scheduled批注起作用所需的XML代码段(applicationContext.xml):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:task="http://www.springframework.org/schema/task"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsdhttp://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd"><context:component-scan base-package="com.blogspot.nurkiewicz.download" /><context:mbean-export/><task:annotation-driven scheduler="bucketFillWorker"/><task:scheduler id="bucketFillWorker" pool-size="1"/></beans>具有令牌桶抽象和非常基本的实现,我们可以开发实际的servlet返回文件。 我总是返回大小几乎为200 kiB的相同固定文件):
@WebServlet(urlPatterns = "/*", name="downloadServletHandler")
public class DownloadServlet extends HttpRequestHandlerServlet {}@Service
public class DownloadServletHandler implements HttpRequestHandler {private static final Logger log = LoggerFactory.getLogger(DownloadServletHandler.class);@Resourceprivate TokenBucket tokenBucket;@Overridepublic void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar");final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file));try {response.setContentLength((int) file.length());sendFile(request, response, input);} catch (InterruptedException e) {log.error("Download interrupted", e);} finally {input.close();}}private void sendFile(HttpServletRequest request, HttpServletResponse response, BufferedInputStream input) throws IOException, InterruptedException {byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE];final ServletOutputStream outputStream = response.getOutputStream();for (int count = input.read(buffer); count > 0; count = input.read(buffer)) {tokenBucket.takeBlocking();outputStream.write(buffer, 0, count);}}
}这里使用了HttpRequestHandlerServlet 。 尽可能简单:读取20 kiB的文件,从存储桶中获取令牌(如果不可用,则等待),将块发送到客户端,重复直到文件结束。
信不信由你,这实际上有效! 无论有多少个(或几个)客户端同时访问该servlet,总的传出网络带宽都不会超过20 MiB! 该算法有效,希望您对如何使用它有一些基本的了解。 但是,让我们面对现实吧-全局限制太不灵活,有点of脚-单个客户端实际上可以消耗您的整个带宽。
那么,如果我们为每个客户有一个单独的存储桶怎么办? 而不是一个信号量–地图? 每个客户端都有单独的独立带宽限制,因此没有饥饿的风险。 但是还有更多:
一些客户可能有更大的特权,甚至没有更大的限制,甚至根本没有限制,
有些可能被列入黑名单,从而导致连接被拒绝或吞吐量非常低
禁止IP,要求身份验证,Cookie /用户代理验证等。 我们可能会尝试关联来自同一客户端的并发请求,并对所有请求使用相同的存储桶,以免通过打开多个连接而作弊。 我们也可能拒绝后续连接 以及更多…
我们的存储桶接口不断增长,允许实现利用新的可能性(请参阅分支per-request-synch ):
public interface TokenBucket {void takeBlocking(ServletRequest req) throws InterruptedException;void takeBlocking(ServletRequest req, int howMany) throws InterruptedException;boolean tryTake(ServletRequest req);boolean tryTake(ServletRequest req, int howMany);void completed(ServletRequest req);
}public class PerRequestTokenBucket extends TokenBucketSupport {private final ConcurrentMap<Long, Semaphore> bucketSizeByRequestNo = new ConcurrentHashMap<Long, Semaphore>();@Overridepublic void takeBlocking(ServletRequest req, int howMany) throws InterruptedException {getCount(req).acquire(howMany);}@Overridepublic boolean tryTake(ServletRequest req, int howMany) {return getCount(req).tryAcquire(howMany);}@Overridepublic void completed(ServletRequest req) {bucketSizeByRequestNo.remove(getRequestNo(req));}private Semaphore getCount(ServletRequest req) {final Semaphore semaphore = bucketSizeByRequestNo.get(getRequestNo(req));if (semaphore == null) {final Semaphore newSemaphore = new Semaphore(0, false);bucketSizeByRequestNo.putIfAbsent(getRequestNo(req), newSemaphore);return newSemaphore;} else {return semaphore;}}private Long getRequestNo(ServletRequest req) {final Long reqNo = (Long) req.getAttribute(REQUEST_NO);if (reqNo == null) {throw new IllegalAccessError("Request # not found in: " + req);}return reqNo;}}实现非常相似( 此处为全类),只不过单个信号量已被map取代。 由于各种原因,我没有将请求对象本身用作映射键,而是在接收新连接时手动分配的唯一请求号。 调用completed()非常重要,否则映射将持续增长,从而导致内存泄漏。 总而言之,令牌桶的实现没有太大变化,下载servlet几乎相同(除了将请求传递给令牌桶)。 我们现在准备进行压力测试!
吞吐量测试
为了进行测试,我们将JMeter与这套出色的插件结合使用 。 在20分钟的测试过程中,我们对服务器进行预热,每6秒启动一个新线程(并发连接),以在10分钟后达到100个线程。 在接下来的十分钟内,我们将保持100个并发连接,以查看服务器的工作稳定性。 以下是一段时间内的活动线程:

重要说明 :在Tomcat(已测试7.0.10)中,我人为地将HTTP工作线程的数量减少到10 。 这与实际配置相差甚远,但是我想强调一些与服务器功能相比在高负载下发生的现象。 使用默认池大小,我将需要几台运行分布式JMeter会话的客户端计算机以生成足够的流量。 如果您在云中有一个服务器场或几个服务器(与我3岁的笔记本电脑相对),我将很高兴在更现实的环境中看到结果。
记住Tomcat中有多少个HTTP工作线程可用,随着时间的推移响应时间就远远不能令人满意:
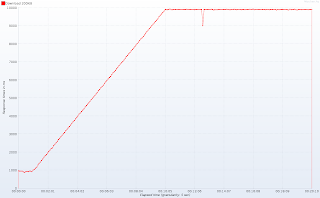
请注意测试开始时的平稳期:大约一分钟后(提示:当并发连接数超过10时),响应时间激增,在10分钟(并发连接数达到100)后稳定在10秒左右。 再次:100个工作线程和1000个并发连接会发生相同的行为–这只是规模问题。 响应延迟图(发送请求和接收响应的第一行之间的时间)消除了任何疑问:

在神奇的10个线程数量以下,我们的应用程序几乎立即响应。 这对于客户端来说确实很重要,因为仅接收标头(尤其是Content-Type和Content-Length)可以使标头更准确地告知用户正在发生的事情。 那么Tomcat等待响应的原因是什么? 真的没有魔术。 我们只有10个线程,每个连接都需要一个线程,因此Tomcat(和其他任何其他Servlet 3.0之前的容器)处理10个客户端,而其余90个正在排队。 当十个幸运者之一完成时,就从队列中获得一个连接。 这解释了平均9秒钟的延迟,而Servlet仅需要1秒钟即可处理请求(200 kiB,限制为20 kiB / s)。 如果您仍然不确定,Tomcat提供了不错的JMX指示器,可显示占用了多少线程以及有多少请求排队:

使用传统的servlet,我们无能为力。 吞吐量太可怕了,但是增加线程总数是不可行的(想想:从100增加到1000)。 但是您实际上并不需要探查器来发现线程并不是这里的真正瓶颈。 仔细查看DownloadServletHandler,您认为大部分时间都花在哪里? 正在读取文件? 将数据发送回客户端? 不,servlet等待……然后等待更多。 非有效地挂在信号量上–幸运的是,CPU并未受到损害,但是如果使用繁忙的等待时间来实现呢? 幸运的是,Tomcat 7终于支持了……
Servlet 3.0异步处理
我们已经接近将服务器容量增加一个数量级,但是需要进行一些不重要的更改(请参阅master分支)。 首先,需要将下载servlet标记为异步(好的,这仍然很简单):
@WebServlet(urlPatterns = "/*", name="downloadServletHandler", asyncSupported = true)
public class DownloadServlet extends HttpRequestHandlerServlet {}主要变化发生在下载处理程序中。 我们不是将整个文件发送到涉及大量等待(takeBlocking())的循环中,而是将循环分为多个单独的迭代,每个迭代都包装在Callable中。 现在,我们将利用一个小的线程池,该线程池将由所有等待的连接共享。 池中的每个任务非常简单:它不等待令牌,而是以非阻塞方式(tryTake())进行请求。 如果令牌可用,则将文件的一部分发送给客户端(sendChunkWorthOneToken())。 如果令牌不可用(存储桶为空),则不会发生任何事情。 无论令牌是否可用,任务都会将自己重新提交到队列中以进行进一步处理(这本质上是非常花哨的多线程循环)。 因为只有一个池,所以该任务降落在队列的末尾,允许服务其他连接。
@Service
public class DownloadServletHandler implements HttpRequestHandler {@Resourceprivate TokenBucket tokenBucket;@Resourceprivate ThreadPoolTaskExecutor downloadWorkersPool;@Overridepublic void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar");response.setContentLength((int) file.length());final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file));final AsyncContext asyncContext = request.startAsync(request, response);downloadWorkersPool.submit(new DownloadChunkTask(asyncContext, input));}private class DownloadChunkTask implements Callable<Void> {private final BufferedInputStream fileInputStream;private final byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE];private final AsyncContext ctx;public DownloadChunkTask(AsyncContext ctx, BufferedInputStream fileInputStream) throws IOException {this.ctx = ctx;this.fileInputStream = fileInputStream;}@Overridepublic Void call() throws Exception {try {if (tokenBucket.tryTake(ctx.getRequest())) {sendChunkWorthOneToken();} elsedownloadWorkersPool.submit(this);} catch (Exception e) {log.error("", e);done();}return null;}private void sendChunkWorthOneToken() throws IOException {final int bytesCount = fileInputStream.read(buffer);ctx.getResponse().getOutputStream().write(buffer, 0, bytesCount);if (bytesCount < buffer.length)done();elsedownloadWorkersPool.submit(this);}private void done() throws IOException {fileInputStream.close();tokenBucket.completed(ctx.getRequest());ctx.complete();}}}我将保留Servlet 3.0 API的详细信息,整个Internet上有许多不太复杂的示例。 只需记住调用startAsync()并使用返回的AsyncContext而不是简单的请求和响应即可。
BTW使用Spring创建线程池非常简单(与Executors和ExecutorService相比,我们得到了不错的线程名称):
没错,一个线程足以服务一百个并发客户端。 自己看看(HTTP工作线程的数量仍然是10,是的,规模以毫秒为单位)。
随着时间的响应时间

随着时间的响应延迟
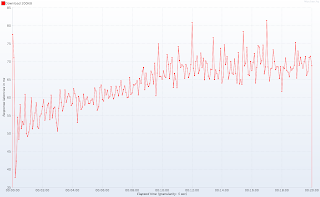
如您所见,与几乎没有负载的系统相比,一百个客户端同时下载文件时的响应时间仅高5%。 同样,响应延迟不会因增加负载而特别受到损害。 由于硬件资源有限,我无法进一步推动服务器运行,但是我有理由相信这个简单的应用程序可以处理甚至两倍以上的连接:整个测试过程中,HTTP线程和下载工作线程均未得到充分利用。 这也意味着我们甚至不使用所有线程就将服务器容量增加了10倍!
希望您喜欢这篇文章。 当然,并不是每个用例都可以如此轻松地扩展,但是下次您会注意到Servlet主要在等待–不要浪费HTTP线程,而应考虑Servlet 3.0异步处理。 并测试,测量和比较! 完整的应用程序源代码可用(请查看不同的分支),包括JMeter测试计划。
改进领域
还有几个地方需要关注和改进。 如果愿意,请毫不犹豫地进行分叉,修改和测试:
- 在进行概要分析时,我发现在80%以上的执行中,DownloadChunkTask不会获取令牌,而只会重新计划自身。 这非常浪费CPU时间,可以很轻松地解决(如何?)
- 考虑在工作线程而不是HTTP线程中打开文件并发送内容长度(在启动异步上下文之前)
- 如何在每个请求的带宽限制之上实现全局限制? 您至少有两个选择:限制下载工作程序池队列的大小并拒绝执行,或者用重新实现的GlobalTokenBucket(装饰器模式)包装PerRequestTokenBucket
- TokenBucket.tryTake()方法确实违反了命令查询分离原则。 您能否建议遵循它的外观? 为什么这么难?
- 我知道我的测试会不断读取相同的小文件,因此对I / O性能的影响很小。 但是在现实生活中,某些缓存层肯定会应用于磁盘存储之上。 因此区别并不大(现在应用程序使用的内存量非常小,很多地方用于缓存)。
得到教训
- 回送接口并非无限快。 实际上,在我的计算机上,本地主机无法处理80 MiB / s以上的速度。
- 我不使用普通请求对象作为bucketSizeByRequestNo中的键。 首先,对此接口的equals()和hashCode()没有保证。 更重要的是–阅读下一点...
- 使用Servlet 3.0处理请求时,必须显式调用completed()刷新和关闭连接。 显然,在调用此方法之后,请求和响应对象是无用的。 Tomcat(在请求对象(池)和其中一些内容用于后续连接)中重用了(这并不明显(我知道为什么很难))。 这意味着以下代码不正确且危险,可能导致访问/破坏其他请求的属性,甚至会话(?!?)
ctx.complete();
ctx.getRequest().getAttribute("SOME_KEY");而已。 我们的JCG合作伙伴之一Tomasz Nurkiewicz 使用Servlet 3.0异步处理提高服务器吞吐量的非常不错的教程。 别忘了分享!
相关文章:
- 带有Spring和Maven教程的JAX–WS
- GWT EJB3 Maven JBoss 5.1集成教程
- Tomcat 7上具有RESTeasy JAX-RS的RESTful Web服务-Eclipse和Maven项目
- 正确记录应用程序的10个技巧
- 每个程序员都应该知道的事情
翻译自: https://www.javacodegeeks.com/2011/03/servlet-30-async-processing-for-tenfold.html
Servlet 3.0异步处理可将服务器吞吐量提高十倍相关推荐
- servlet 3.0异步_Servlet 3.0异步处理可将服务器吞吐量提高十倍
servlet 3.0异步 Servlet是Java中处理服务器端逻辑的主要组件,新的3.0规范引入了一些非常有趣的功能,其中异步处理是最重要的功能之一. 可以利用异步处理来开发高度可伸缩的Web应用 ...
- 在Grails 2.0中使用Servlet 3.0异步功能
上周,我与某人谈论了Grails 2中对Servlet 3.0异步功能的新支持,并意识到我对可用功能并不了解. 所以我想我会尝试一下并分享一些例子. 该文档对这个主题有些了解,因此首先介绍一些背景信息 ...
- JAVA Web Servlet中的异步处理 (1) -- Servlet3.0中的Async支持
JAVA Web Servlet中的异步处理 (1) – Servlet3.0中的Async支持 每个请求来到Web容器,Web容器会为其分配一个线程来专门负责该请求,直到完成处理前,该执行线程都不会 ...
- Servlet 3.0 新特性概述
Servlet 3.0 新特性概述 Servlet 3.0 作为 Java EE 6 规范体系中一员,随着 Java EE 6 规范一起发布.该版本在前一版本(Servlet 2.5)的基础上提供了若 ...
- Servlet 3.0 新特性详解
https://www.ibm.com/developerworks/cn/java/j-lo-servlet30/ Servlet 3.0 新特性概述 Servlet 3.0 作为 Java EE ...
- 使用Servlet 3.0,Redis / Jedis和CDI的简单CRUD –第2部分
在本文中,我们将重点介绍CDI和Servlet 3.0. 您可以在此处看到第1部分. 让我们从CDI开始. 当我开始撰写源自该系列的文章时,我并没有考虑撰写CDI. 真诚地说,我以前从未使用过. 这篇 ...
- Servlet 3的异步Servlet功能
在深入了解什么是异步Servlet之前,让我们尝试了解为什么需要它. 假设我们有一个Servlet,处理时间很长,如下所示. LongRunningServlet.java package com.j ...
- Servlet 2.0 Servlet 3.0 新特性
概念:透传. Callback 在异步线程中是如何使用的.?? Servlet 2.0 && Servlet 3.0 新特性 Servlet 2.0 && Servle ...
- python processpoolexector 释放内存_一起看看python 中日志异步发送到远程服务器
在python中使用日志最常用的方式就是在控制台和文件中输出日志了,logging模块也很好的提供的相应的类,使用起来也非常方便,但是有时我们可能会有一些需求,如还需要将日志发送到远端,或者直接写入数 ...
最新文章
- 【Spring注解系列03】@Scope与@Lazy
- SparkStreaming
- Silverlight 异步单元测试
- 一个Demo学会用Android兼容包新控件
- [Linux] ubuntu server sudo出现sudo:must be setuid root 完美解决办法
- ADS EM MODEL 问题
- 风力发电仿真系列-基于Simulink搭建的变速恒频双馈风力发电模型
- 物联网知识1---RFID
- 加密html文件如何转换为pdf,PPT转成PDF后如何加密?其实真的很简单!
- java出现次数最多的数_java如何找出一个int数组中出现次数最多
- Solution to no ADO.NET in VS2019 VS里没有ADO的解决办法
- win10关闭任务栏窗口预览
- hmmer 使用(转载)
- IPv6闲谈-一起玩玩IPv6自动配置
- mysql数据库怎么导出导入表
- 采购项目管理:定义和流程
- 《国民经济行业分类》(《国民经济行业分类》)
- Kiel 中Code RO-data RW-data ZI Data是什么意思
- 分享给大家一些UG模具设计常识,值得收藏
- 心的躁动不安 是我对世界的一无所知
热门文章
- Spring boot(八):RabbitMQ详解
- java获取ram_Java:ChronicleMap第2部分,超级RAM映射
- java jinq_将JINQ与JPA和H2一起使用
- web ua检测_UA Web挑战会议:针对初创公司的SpringIO
- javaee编程题_在JavaEE中使用CDI的简单面向方面的编程(AOP)
- java 8流自定义收集器_Java 8编写自定义收集器简介
- Spring @RequestParam批注
- unwind neo4j_Neo4j 2.1:传递节点ID与UNWIND
- java8 javafx_Java8中的外观(JavaFX8)
- scala和java像不像_关于Java和Scala同步的五件事你不知道