azure第一个月_MLOps:两个Azure管道的故事
azure第一个月
Luuk van der Velden and Rik Jongerius
卢克·范德·费尔登(Luuk van der Velden)和里克 ·琼格里乌斯( Rik Jongerius)
目标 (Goal)
MLOps seeks to deliver fresh and reliable AI products through continuous integration, continuous training and continuous delivery of machine learning systems. When new data becomes available, we update the AI model and deploy it (if improved) with DevOps practices. Azure DevOps pipelines support such practices and is our platform of choice. AI or Machine Learning is however focused around AzureML, which has its own pipeline and artifact system. Our goal is to combine DevOps with AzureML pipelines in an end-to-end solution. We want to continuously train models and conditionally deploy them on our infrastructure and applications. More specifically, our goal is to continuously update a PyTorch model running within an Azure function.
MLOps寻求通过持续集成,持续培训和持续交付机器学习系统来交付新鲜且可靠的AI产品。 当有新数据可用时,我们将更新AI模型,并通过DevOps实践进行部署(如果有改进)。 Azure DevOps管道支持此类做法,并且是我们的首选平台。 但是,AI或机器学习的重点是AzureML ,它具有自己的管道和工件系统。 我们的目标是在端到端解决方案中将DevOps与AzureML管道结合起来。 我们希望不断训练模型并将其有条件地部署到我们的基础架构和应用程序中。 更具体地说,我们的目标是不断更新在Azure函数中运行的PyTorch模型。
解决方案概述 (Solution overview)
The following diagram shows our target solution. Three triggers are shown at the top. Changes to the infrastructure-as-code triggers the Terraform infrastructure pipeline. Changes to the Python code of the function triggers the Azure function deploy pipeline. Finally, new data on a schedule triggers the model training pipeline, which does a conditional deploy of the function with the new model if it performs better.
下图显示了我们的目标解决方案。 顶部显示三个触发器。 对基础架构即代码的更改触发了Terraform基础架构管道。 对函数的Python代码的更改将触发Azure函数部署管道。 最后,时间表上的新数据会触发模型训练管道,如果新模型性能更好,则有条件地使用新模型进行功能部署。

1个DevOps基础架构管道 (1 DevOps infrastructure pipeline)
Within a DevOps pipeline we can organize almost any aspect of the Azure cloud. They allow repeatable and reproducible infrastructure and application deployment. Some of the key features are:
在DevOps管道中,我们几乎可以组织Azure云的任何方面。 它们允许可重复和可复制的基础架构和应用程序部署。 一些关键功能包括:
- Support to automate almost all Azure Services支持自动化几乎所有Azure服务
- Excellent secret management出色的秘密管理
- Integration with Azure DevOps for team collaboration and planning与Azure DevOps集成以进行团队协作和规划
1.1管道作业,步骤和任务 (1.1 Pipeline jobs, steps and tasks)
DevOps pipelines are written in YAML and have several possible levels of organization: stages, jobs, steps. Stages consist of multiple jobs and jobs consist of multiple steps. Here we focus on jobs and steps. Each job can include a condition for execution and each of its steps contains a task specific to a certain framework or service. For instance, a Terraform task to deploy infrastructure or an Azure KeyVault task to manage secrets. Most tasks need a service connection linked to our Azure subscription to be allowed to access and alter our resources. In our case, we appropriate the authentication done by the Azure CLI task to run Python scripts with the right credentials to interact with our AzureML workspace.
DevOps管道使用YAML编写,具有几种可能的组织级别:阶段,作业,步骤。 阶段包含多个作业,而作业包含多个步骤。 在这里,我们专注于工作和步骤。 每个作业都可以包含执行条件,并且每个步骤都包含特定于某个框架或服务的任务。 例如,用于部署基础结构的Terraform任务或用于管理机密的Azure KeyVault任务 。 大多数任务需要链接到我们的Azure订阅的服务连接,才能访问和更改我们的资源。 在我们的案例中,我们使用由Azure CLI任务完成的身份验证来运行具有正确凭据的Python脚本,以与我们的AzureML工作区进行交互。
1.2基础架构即代码 (1.2 Infrastructure as code)
There are good arguments to use tools such as Terraform and Azure Resource Manager to manage our infrastructure, which we will try not to repeat here. Important for us, these tools can be launched repeatedly from our DevOps pipeline and always lead to the same resulting infrastructure (idempotence). So, we can launch the infrastructure pipeline often not only when there are changes to the infrastructure-as-code. We use Terraform to manage our infrastructure, which requires the appropriate service connection.
使用Terraform和Azure资源管理器之类的工具来管理我们的基础结构有很多理由,我们将在这里不再赘述。 对我们而言重要的是,这些工具可以从我们的DevOps管道中反复启动,并始终导致相同的基础架构(幂等)。 因此,我们不仅可以在对基础架构代码进行更改的情况下,经常启动基础架构管道。 我们使用Terraform来管理我们的基础架构,这需要适当的服务连接。
The following Terraform definition (Code 1) will create a function app service with its storage account and Standard app service plan. We have included it as the documented Linux example did not work for us. For full serverless benefits we were able to deploy on a consumption plan (elastic), but the azurerm provider for Terraform seems to have an interfering bug that prevented us from including it here. For brevity, we did not include the DevOps pipelines steps for applying Terraform and refer to the relevant documentation.
以下Terraform定义(代码1)将使用其存储帐户和标准应用程序服务计划创建功能应用程序服务。 我们将其包括在内,因为已记录的Linux示例对我们不起作用。 为了获得无服务器的全部收益,我们可以在使用计划(弹性)上进行部署,但是Terraform的azurerm提供程序似乎存在一个干扰性错误,使我们无法在其中包含它。 为简便起见,我们没有包括应用Terraform的DevOps管道步骤,而是参考相关文档 。
# Code 1: terraform function app infrastructureresource "azurerm_storage_account" "torch_sa" { name = "sa-function-app" resource_group_name = data.azurerm_resource_group.rg.name location = data.azurerm_resource_group.rg.location account_tier = "Standard" account_replication_type = "LRS"}resource "azurerm_app_service_plan" "torch_asp" { name = "asp-function-app" location = data.azurerm_resource_group.rg.location resource_group_name = data.azurerm_resource_group.rg.name kind = "Linux" reserved = truesku { tier = "Standard" size = "S1" }}resource "azurerm_function_app" "torch" { name = "function-app" location = data.azurerm_resource_group.rg.location resource_group_name = data.azurerm_resource_group.rg.name storage_account_name = azurerm_storage_account.torch_sa.name storage_account_access_key = azurerm_storage_account.torch_sa.primary_access_key app_service_plan_id = azurerm_app_service_plan.torch_asp.id storage_connection_string = os_type = "linux" version = "~3"
app_settings = { FUNCTIONS_EXTENSION_VERSION = "~3" FUNCTIONS_WORKER_RUNTIME = "python" FUNCTIONS_WORKER_RUNTIME_VERSION = "3.8" APPINSIGHTS_INSTRUMENTATIONKEY = "<app_insight_key>" } site_config { linux_fx_version = "PYTHON|3.8" }}2 AzureML管道 (2 AzureML pipeline)
AzureML is one of the ways to do data science on Azure, besides Databricks and the legacy HDInsight cluster. We use the Python SDK for AzureML to create and run our pipelines. Setting up an AzureML development environment and running of training code on AMLCompute targets I explain here. In part 2 of that blog I describe the AzureML Environment and Estimator, which we use in the following sections. The AzureML pipeline combines preprocessing with estimators and allows data transfer with PipelineData objects.
除Databricks和旧版HDInsight群集外,AzureML是在Azure上进行数据科学的方法之一。 我们使用适用于AzureML的Python SDK创建和运行我们的管道。 设置AzureML开发环境并在AMLCompute目标上运行训练代码,我在这里进行解释。 在该博客的第2部分中,我描述了AzureML环境和估计器,我们将在以下各节中使用它们。 AzureML管道将预处理与估计器结合在一起,并允许通过PipelineData对象进行数据传输。
Some benefits are:
一些好处是:
- Reproducible AI可重现的AI
- Reuse data pre-processing steps重用数据预处理步骤
- Manage data dependencies between steps管理步骤之间的数据依存关系
- Register AI artifacts: model and data versions注册AI工件:模型和数据版本
2.1管道创建和步骤 (2.1 Pipeline creation and steps)
Our Estimator wraps a PyTorch training script and passes command line arguments to it. We add an Estimator to the pipeline by wrapping it with the EstimatorStep class (Code 2).
我们的估算器包装了一个PyTorch训练脚本,并将命令行参数传递给它。 通过将EstimatorStep类(代码2)包装起来,可以将Estimator添加到管道中。
# Code 2: wrap estimator in pipeline stepfrom azureml.core import Workspacefrom azureml.pipeline.steps import EstimatorStepfrom tools import get_computefrom model import train_estimatorworkspace = Workspace.from_config()model_train_step = EstimatorStep( name="train model", estimator=train_estimator, estimator_entry_script_arguments=[], compute_target=get_compute(workspace, CLUSTER_NAME),)To create an AzureML pipeline we need to pass in the Experiment context and a list of steps to run in sequence (Code 3). The goal of our current Estimator is to register an updated model with the AzureML workspace.
若要创建AzureML管道,我们需要传递“实验”上下文和按顺序运行的步骤列表(代码3)。 当前的Estimator的目标是向AzureML工作区注册更新的模型。
# Code 3: create and run azureml pipelinefrom azureml.core import Experiment, Workspacefrom azureml.pipeline.core import Pipelinedef run_pipeline(): workspace = Workspace.from_config() pipeline = Pipeline( workspace=workspace, steps=[model_train_step, model_evaluation_step] ) pipeline_run = Experiment( workspace, EXPERIMENT_NAME).submit(pipeline) pipeline_run.wait_for_completion()2.2模型工件 (2.2 Model artifacts)
PyTorch (and other) models can be serialized and registered with the AzureML workspace with the Model class. Registering a model uploads it to centralized blob storage and allows it to be published wrapped in a Docker container to Azure Docker instances and Azure Kubernetes Service. We wanted to keep it simple and treat the AzureML model registration as an artifact storage. Our estimator step loads an existing PyTorch model and trains it on the newly available data. This updated model is registered under the same name every time the pipeline runs (code 4). The model version is auto incremented. When we retrieve our model without specifying a version it will grab the latest version. With each model iteration we decide whether we want to deploy the latest version.
可以使用Model类将PyTorch(及其他)模型序列化并注册到AzureML工作区中。 注册模型会将其上传到集中式Blob存储,并允许将其包装在Docker容器中发布到Azure Docker实例和Azure Kubernetes服务。 我们希望保持简单,将AzureML模型注册视为工件存储。 我们的估算器步骤会加载现有的PyTorch模型,并在新的可用数据上对其进行训练。 每次管道运行时,此更新的模型都以相同的名称注册(代码4)。 型号版本自动增加。 当我们检索模型而未指定版本时,它将获取最新版本。 每次模型迭代时,我们都会决定是否要部署最新版本。
# Code 4: inside an azureml pipeline stepimport torchfrom azureml.core import RunMODEL_PATH = "./outputs/model.p"updated_model = train_model(model, data)torch.save(updated_model, MODEL_PATH)run_context = Run.get_context()run_context.upload_file(model_path, model_path)run_context.register_model( model_name="pytorch_model", model_path=model_path, description=f"updated model: {run_context.run_id}",)3结合AzureML和DevOps管道 (3 Combining AzureML and DevOps pipelines)
3.1以DevOps管道为中心的架构 (3.1 DevOps pipeline centric architecture)
In our approach to MLOps / Continuous AI the DevOps pipeline is leading. It has better secrets management and broader capabilities than the AzureML pipeline. When new data is available the DevOps pipeline starts the AzureML pipeline and waits for it to finish with a conditional decision whether to deploy the model. This decision is based on the performance of the model compared to the previous best model. We schedule the model DevOps pipeline at regular intervals when new data is expected using the cron trigger.
在我们的MLOps /连续AI方法中,DevOps管道处于领先地位。 与AzureML管道相比,它具有更好的秘密管理和更广泛的功能。 当有新数据可用时,DevOps管道将启动AzureML管道并等待其完成,并附有条件决定是否部署模型。 该决策基于与之前最佳模型相比模型的性能。 当使用cron触发器期望新数据时,我们会定期调度模型DevOps管道。
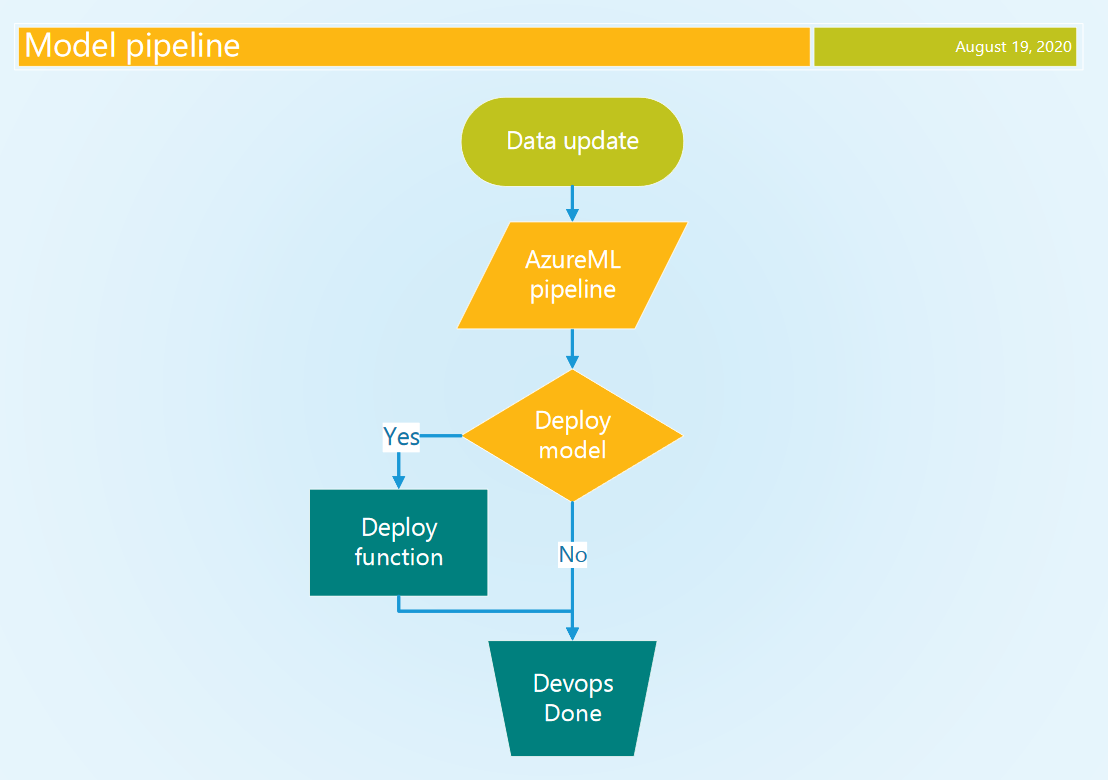
3.2从DevOps启动AzureML (3.2 Launching AzureML from DevOps)
An Azure CLI task authenticates the task with our service connection, which has access to our AzureML Workspace. This access is used by the Python script to create the Workspace and Experiment context to allow us to run the Pipeline using the AzureML SDK. We wait for the AzureML pipeline to complete, with a configurable timeout. The overall DevOps timeout is 2 hours. The implications of this are discussed at the end of the blog. A basic Python script is shown (Code 5) that starts the AzureML pipeline from Code 3.
Azure CLI任务通过我们的服务连接对任务进行身份验证,该服务连接可以访问我们的AzureML工作区。 Python脚本使用此访问权限来创建工作区和实验上下文,以允许我们使用AzureML SDK运行管道。 我们等待AzureML管道完成,并且具有可配置的超时。 DevOps的总体超时为2小时。 博客末尾讨论了其含义。 显示了一个基本的Python脚本(代码5),该脚本从代码3启动AzureML管道。
# Code 5: calling our run function form Code 3from aml_pipeline.pipeline import run_pipelinerun_pipeline()This script is launched from an AzureCLI task (Code 6) for the required authentication. Note: It is not ideal that we need an account with rights on the Azure subscription level to interact with AzureML even for the most basic operations, such as downloading a model.
此脚本从AzureCLI任务(代码6)启动,用于所需的身份验证。 注意:甚至对于最基本的操作(例如下载模型),我们都需要一个具有Azure订阅级别权限的帐户来与AzureML交互是不理想的。
# Code 6: launch the azureml pipeline with a devops task- task: AzureCLI@2 name: 'amlTrain' displayName: 'Run AzureML pipeline' inputs: azureSubscription: $(serviceConnection) scriptType: bash scriptLocation: inlineScript inlineScript: 'python run_azure_pipeline.py' workingDirectory: '$(System.DefaultWorkingDirectory)/aml_pipeline'3.3在DevOps中进行条件模型部署 (3.3 Conditional model deployment in DevOps)
An updated model trained with the latest data will not perform better by definition. We want to decide whether to deploy the latest model based on its performance. Thus, we want to communicate our intent to deploy the model from AzureML to the DevOps pipeline. To output a variable to the DevOps context we need to write a specific string to the stdout of our Python script.
从定义上讲,使用最新数据训练的更新模型不会表现更好。 我们要根据性能来决定是否部署最新模型。 因此,我们希望传达将模型从AzureML部署到DevOps管道的意图。 要将变量输出到DevOps上下文,我们需要在Python脚本的stdout中写入特定的字符串。
In our implementation each step in the AzureML pipeline can trigger a deployment by creating the following local empty file “outputs/trigger”. The “outputs” directory is special and Azure uploads its content automatically to the central blob storage accessible through the PipelineRun object and ML studio. After the AzureML pipeline is completed we inspect the steps in the PipelineRun for the existence of the trigger file (Code 7). Based on this an output variable is written to the DevOps context as a Task output variable (Code 7).
在我们的实现中,AzureML管道中的每个步骤都可以通过创建以下本地空文件“输出/触发器”来触发部署。 “输出”目录很特殊,Azure将其内容自动上传到可通过PipelineRun对象和ML Studio访问的中央Blob存储。 在AzureML管道完成之后,我们检查PipelineRun中的步骤是否存在触发文件(代码7)。 基于此,将输出变量作为Task输出变量(代码7)写入DevOps上下文。
# Code 7: expanded run function with devops output variabledef run_pipeline(): workspace = Workspace.from_config() pipeline = Pipeline( workspace=workspace, steps=[model_train_step, model_evaluation_step] ) pipeline_run = Experiment( workspace, EXPERIMENT).submit(pipeline) pipeline_run.wait_for_completion()
deploy_model = False steps = pipeline_run.get_steps() for step in steps: if "outputs/trigger" in step.get_file_names(): deploy_model = True if deploy_model: print("Trigger model deployment.") print("##vso[task.setvariable variable=deployModel;isOutput=true]yes") else: print("Do not trigger model deployment.") print("##vso[task.setvariable variable=deployModel;isOutput=true]no")4将模型和代码部署到Azure功能 (4 Deploy model and code to an Azure function)
4.1条件DevOps部署作业 (4.1 Conditional DevOps deploy job)
We have trained a new model and want to deploy it. We need a DevOps job to take care of the deployment, which runs conditionally on the output of our AzureML training pipeline. We can access the output variable described above and perform an equality check within the jobs’ condition clause. Code 8 below shows how we access the task output variable from the previous train job in the condition of the deploy job.
我们已经训练了一个新模型,并希望部署它。 我们需要一个DevOps作业来处理部署,该部署有条件地在AzureML培训管道的输出上运行。 我们可以访问上述输出变量,并在作业的condition子句中执行相等性检查。 下面的代码8显示了在部署作业的情况下,我们如何访问上一个训练作业的任务输出变量。
# Code 8: Conditional deploy job based on train job output- job: deploy_function dependsOn: train condition: eq(dependencies.train.outputs['amlTrain.deployModel'], 'yes')...4.2检索最新型号 (4.2 Retrieve the latest model version)
To retrieve the latest model from the AzureML Workspace we use an Azure CLI task to handle the required authentication. Within it we run a Python script, which attaches to our AzureML workspace and downloads the latest model within the directory that holds our function (Code 9). When we deploy our function this script is called to package our model with our Python code and requirements (Code 10, task 3). Each model release thus implies a function deploy.
为了从AzureML工作区检索最新模型,我们使用Azure CLI任务来处理所需的身份验证。 在其中,我们运行一个Python脚本,该脚本附加到我们的AzureML工作区,并在保存函数的目录(代码9)中下载最新模型。 部署函数时,将调用此脚本以将模型与Python代码和要求打包在一起(代码10,任务3)。 因此,每个模型版本都意味着功能部署。
# Code 9: retrieve latest model for devops deployment of functionimport osimport shutilfrom azureml.core import Model, WorkspaceMODEL_NAME = "pytorch_model"workspace = Workspace.from_config()model_path = Model.get_model_path(MODEL_NAME, _workspace=workspace)os.makedirs("./model", exist_ok=True)shutil.copyfile(model_path, "./model/model.p")4.3将模型和代码部署到我们的功能应用程序 (4.3 Deploy model and code to our function app)
The azure-functions-core-tools support local development and deployment to a Function App. For our deployment, the function build agent is used to install Python requirements and copy the package to the function App. There is a dedicated DevOps task for function deployments, which you can explore. For the moment we had a better experience installing the azure-functions-core-tools on the DevOps build agent (Ubuntu) and publishing our function with it (Code 10, step 5).
azure-functions-core-tools支持本地开发和部署到Function App。 对于我们的部署,功能构建代理用于安装Python要求并将程序包复制到功能App。 您可以探索用于功能部署的专用DevOps 任务 。 目前,我们有更好的体验在DevOps构建代理(Ubuntu)上安装azure-functions-core-tools并与之一起发布我们的功能(代码10,第5步)。
# Code 10: devops pipeline template for function deploymentparameters: - name: serviceConnection type: string - name: workingDirectory type: string - name: funcAppName type: stringsteps: - task: UsePythonVersion@0 inputs: versionSpec: '3.8' - task: Bash@3 displayName: 'Install AzureML dependencies' inputs: targetType: inline script: pip install azureml-sdk - task: AzureCLI@2 displayName: 'package model with function' inputs: azureSubscription: ${{ parameters.serviceConnection }} scriptType: bash scriptLocation: inlineScript inlineScript: 'python ../scripts/package_model.py' workingDirectory: '${{ parameters.workingDirectory }}/torch_function' - task: Bash@3 displayName: 'Install azure functions tools' inputs: targetType: inline script: sudo apt-get update && sudo apt-get install azure-functions-core-tools-3 - task: AzureCLI@2 displayName: 'publish and build the function' inputs: azureSubscription: ${{ parameters.serviceConnection }} scriptType: bash scriptLocation: inlineScript workingDirectory: '${{ parameters.workingDirectory }}/torch_function' inlineScript: func azure functionapp publish ${{ parameters.funcAppName }} --python讨论区 (Discussion)
In this blog we present a pipeline architecture that supports Continuous AI on Azure with a minimal amount of moving parts. Other solutions we encountered add Kubernetes or Docker Instances for publishing the AzureML models for consumption by frontend facing functions. This is an option, but it might increase the engineering load on your team. We do think that adding Databricks could enrich our workflow with collaborative notebooks and more interactive model training, especially in the exploration phase of the project. The AzureML-MLFlow API allows you to register model from Databricks notebooks and hook into our workflow at that point.
在此博客中,我们介绍了一种管道架构,该架构支持Azure上的Continuous AI,并具有最少的活动部件。 我们遇到的其他解决方案添加了Kubernetes或Docker实例,用于发布AzureML模型以供面向前端的功能使用。 这是一个选项,但可能会增加团队的工程负担。 我们确实认为,添加Databricks可以通过协作笔记本和更多交互式模型培训来丰富我们的工作流程,尤其是在项目的探索阶段。 AzureML-MLFlow API允许您从Databricks笔记本中注册模型,并在那时加入我们的工作流程。
完整的模型训练 (Full model training)
Our focus is on model training for incremental updates with training times measured in hours or less. When we consider full model training measured in days, the pipeline architecture can be expanded to support non-blocking processing. Databricks could be a platform full model training on GPUs as described above. Another option is to run the AzureML pipeline withAzure Datafactory, which is suitable for long running orchestration of data intensive jobs. If the trained model is deemed viable a follow-up DevOps pipeline can be triggered to deploy it. A low-tech trigger option (with limited authentication options) is the http endpoint associated with each DevOps pipeline.
我们的重点是模型培训,以进行增量更新,培训时间以小时或更少为单位。 当我们考虑以天为单位衡量的完整模型训练时,可以扩展管道体系结构以支持非阻塞处理。 如上所述,Databrick可以是在GPU上进行平台全模型训练的平台。 另一个选择是使用Azure Datafactory运行AzureML管道,这适用于长期运行的数据密集型业务编排。 如果认为经过训练的模型可行,则可以触发后续的DevOps管道进行部署。 技术含量低的触发选项(具有有限的身份验证选项)是与每个DevOps管道关联的http端点 。
用例 (Use cases)
AI is not the only use case for our approach, but it is a significant one. Related use cases are interactive reporting applications running on streamlit, which can contain representations of knowledge that have to be updated. Machine Learning models, interactive reports and facts from the datalake work in tandem to inform management or customer and lead to action. Thank you for reading.
人工智能不是我们方法的唯一用例,但它是一个重要的案例。 相关用例是在streamlit上运行的交互式报告应用程序,其中可以包含必须更新的知识表示。 机器学习模型,交互式报告和来自Datalake的事实协同工作,以通知管理层或客户并采取行动。 感谢您的阅读。
Originally published at https://codebeez.nl.
最初发布在 https://codebeez.nl 。
翻译自: https://towardsdatascience.com/mlops-a-tale-of-two-azure-pipelines-4135b954997
azure第一个月
http://www.taodudu.cc/news/show-997532.html
相关文章:
- 编译原理 数据流方程_数据科学中最可悲的方程式
- 解决朋友圈压缩_朋友中最有趣的朋友[已解决]
- pymc3 贝叶斯线性回归_使用PyMC3进行贝叶斯媒体混合建模,带来乐趣和收益
- ols线性回归_普通最小二乘[OLS]方法使用于机器学习的简单线性回归变得容易
- Amazon Personalize:帮助释放精益数字业务的高级推荐解决方案的功能
- 西雅图治安_数据科学家对西雅图住宿业务的分析
- 创意产品 分析_使用联合分析来发展创意
- 多层感知机 深度神经网络_使用深度神经网络和合同感知损失的能源产量预测...
- 使用Matplotlib Numpy Pandas构想泰坦尼克号高潮
- pca数学推导_PCA背后的统计和数学概念
- 鼠标移动到ul图片会摆动_我们可以从摆动时序分析中学到的三件事
- 神经网络 卷积神经网络_如何愚弄神经网络?
- 如何在Pandas中使用Excel文件
- tableau使用_使用Tableau升级Kaplan-Meier曲线
- numpy 线性代数_数据科学家的线性代数—用NumPy解释
- 数据eda_银行数据EDA:逐步
- Bigmart数据集销售预测
- dt决策树_决策树:构建DT的分步方法
- 已知两点坐标拾取怎么操作_已知的操作员学习-第3部分
- 特征工程之特征选择_特征工程与特征选择
- 熊猫tv新功能介绍_熊猫简单介绍
- matlab界area_Matlab的数据科学界
- hdf5文件和csv的区别_使用HDF5文件并创建CSV文件
- 机器学习常用模型:决策树_fairmodels:让我们与有偏见的机器学习模型作斗争
- 100米队伍,从队伍后到前_我们的队伍
- mongodb数据可视化_使用MongoDB实时可视化开放数据
- Python:在Pandas数据框中查找缺失值
- Tableau Desktop认证:为什么要关心以及如何通过
- js值的拷贝和值的引用_到达P值的底部:直观的解释
- struts实现分页_在TensorFlow中实现点Struts
azure第一个月_MLOps:两个Azure管道的故事相关推荐
- (译)Windows Azure的7月更新:SQL数据库,流量管理,自动缩放,虚拟机
Windows Azure的7月更新:SQL数据库,流量管理,自动缩放,虚拟机 今早我们释出一些很棒的Windows Azure更新.这些新的提升包括: SQL数据库:支持SQL自动导出和一个新的高级 ...
- 【2021年1月新书推荐】Azure Arc-Enabled Data Services Revealed
各位好,此账号的目的在于为各位想努力提升自己的程序员分享一些全球最新的技术类图书信息,今天带来的是2021年1月由Apress出版社最新出版的一本关于云计算和数据库的书,涉及的平台为Azure. Az ...
- azure 使用_如何使用JavaScript在Azure上开始使用SignalR
azure 使用 The other day, some fine developers at my company were getting ready to roll out a status u ...
- Azure Administrator Associate(AZ-103/AZ-104)或其他Azure认证备考指南
经过一个多月的复习准备,笔者在几天前顺利通过了AZ-103的Exam,从而解锁了人生的第一个专业技能证书. 话不多说,先上个图 在备考过程中遇到了很多坑,也有一些小插曲,非常感谢CSDN上一些有经验的 ...
- 「Azure」数据分析师有理由爱Azure之二-立即申请帐号开始学习之旅
目前关于Azure的学习资料不多,除了官方的文档和Microsoft Learn频道外,几乎没有什么中文性资料可学习,就算有,也是以IT的思维方式来展开介绍,对没有IT背景的数据分析师来说,非常难于适 ...
- Azure手把手系列 4:深入了解Azure 一块钱当三块用
通过前面的文章,相信大家对Azure有了一个基础的认识,接下来,我们再来看下作为企业,选择公有云服务最重要的因素之一 价格.我们都知道所谓公有云,就是要让IT资源变成我们生活中类似于水电气的资源,按 ...
- azure blob_如何使用Power BI从Azure Blob存储访问数据
azure blob In this article, I am going to explain how we can access the data from the Azure Blob Sto ...
- Azure Stack技术深入浅出系列6:Azure Stack一体机探究 — 揭开黑盒子的神秘面纱
Azure Stack是微软公有云平台的延伸,为客户环境里提供接口和相关的功能.微软的Azure Stack安装在指定的合作伙伴的一体机中,并以一体机的形式部署到客户的混合云应用环境里的.2017年7 ...
- 吴忠军 - 如何理解马云所说的月入两三万,三四万的人最幸福?
这句话源于一段两分钟的视频,马云的一次阿里内部会议演讲. 马云坦承,自己从第一天起就没想过当首富,还为此稀释公司持股,"没想到把自己的股份降到8%,还是有那么多,这是我没有想到的." ...
最新文章
- [POJ] 3687 Labeling Balls(拓扑排序)
- E431 笔记本电池问题 0190 Critical low-battery error 解决办法
- centos配置occi环境变量_拓展学习-golang的下载、安装和环境配置教程
- [Python人工智能] 七.加速神经网络、激励函数和过拟合
- 关于APK文件反编译方法(图文详解)
- 我也说说刘谦在2010年春晚上的魔术作假
- Python快速构建神经网络
- [转载] python中字典中追加_python 中字典中的删除,pop 方法与 popitem 方法
- mysql排序区分大小写吗_MySQL的order by时区分大小写
- 翻译:YOLOv5 新版本——改进与评估
- 利用官方git svn插件迁移svn仓库
- ie11 java提示升级,解决IE11安装升级失败和在安装前需要更新的问题
- 用C#分析华表插件表格数据
- 医院计算机管理办法试行,医院信息工作制度七、计算机中心机房管理制度
- 用g++编译cpp文件
- linux 备份 网络配置,如何备份已经配置好的虚拟机linux系统的网络..._网络编辑_帮考网...
- 电脑隐藏文件夹如何把它显示出来
- 各种三角函数的导数(正六边形记忆法)
- zencart模板修改 (详细)
- 团队任务3每日立会(2018-10-26)