Hadoop MapReduce篇
http://blog.chinaunix.net/uid-12014716-id-4306505.html
如果联系到hadoop集群的话,其实到现在才真正的明白这个MR。我的理解偏差了好多,下面大概讲讲(口语,不专业),不对的地方还请指正;
你程序中写的MR函数,运行程序,这里叫做提交作业,Jobtracker接到作业后会分析MR的规则(如果你不特定规则它会按照系统默认的规则),比如需要多少个map,按照什么分map等规划,然后分配具体任务给每个Tasktracker去执行,待每个Tasktracker按照先map后reduce计算完毕后会把reduce结果汇总给Jobtracker,最终Jobtracker把结果返回给客户端;
这个流程你可以这样理解:
MR就是需求----Jobtracker分析此需求并制定计划发送任务给Tasktracker(多个)---Tasktracker就是工人接到任务开始干活并报告结果(map和reduce的函数执行是在这里进行的)---Jobtracker最终汇总所有Tasktracker的报告结果输出;
再拿施工队的例子解释:
MR就是给工头L(Jobtracker)看的图纸,L(Jobtracker)分析图纸后知道如何建造这个房子了,比如先地基,再柱子等等,然后根据实际情况分任务,地基技术比较简单,那就给A(Tasktracker1)这个工人,柱子适合给B(Tasktracker2)这个工人,分配好后,A和B就开始干活了,待AB都干完了,告诉L,我们做完了。OK,任务完成,L说房子可以交工了,任务完成;
下面具体是的map和reduce函数都怎么计算数据的,稍稍专业点:
上一篇也简单提到了Hadoop中的MapReduce(下面都简写为MR)是一种分布式计算模型,起初由Google提出,主要用于搜索领域,解决海量数据的计算问题。MR由两个阶段组成:Map和Reduce,用户只需要实现Map()和Reduce()两个函数,即可实现分布式计算,这两个函数的形参是key、value对,表示函数的输入信息。
1、MR的执行流程
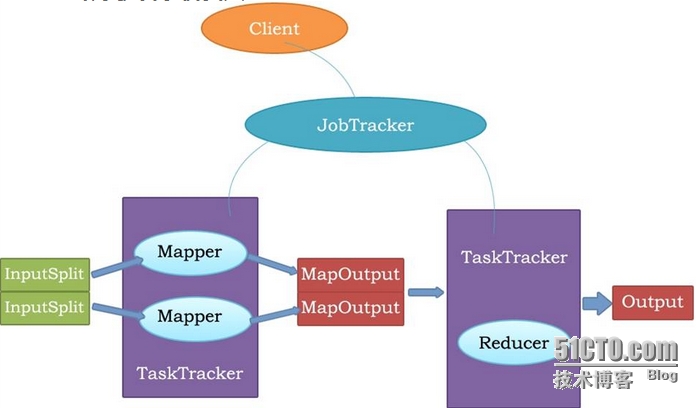
2、MR原理
MR框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上(Hadoop集群采用主从结构模型Master和Slave)的TaskTracker共同组成,这里顺便提下:JobTracker可以运行于集群中的任意一台计算机上,负责分配和监控TaskTracker的执行,TaskTracker负责执行任务,它必须运行在DataNode上。JobTracker将map任务和reduce任务分发给空闲的TaskTracker,这些任务并行运行,并监控运行情况。
1、Map任务处理
读取输入文件内容,对输入文件的每一行,解析成key,value对,按照自己的逻辑,对不同分区的数据,按照Key进行排序、分组,相同key的value放到一个集合中。
在集群中就是每个节点处理自己的key,value值,最后汇总给Reduce函数去处理;
2、Reduce任务处理
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点,合并排序,最后把reduce的输出保存到文件中。
形象化的解释MR就是Linux中经常用的命令: cat xxx.txt |grep "abc" |wc -l 其中grep是Map任务,wc -l是reduce任务;
最后:MR不是Hadoop特有的,只是在集群中操作MR能体现出性能的优势,多点并发执行,最后综合结果;Map不能做reduce的工作,但reduce可以做map的工作;
转载于:https://blog.51cto.com/3855471/1650964
Hadoop MapReduce篇相关推荐
- 又双叒叕来更新啦!Hadoop———MapReduce篇
文章目录 MapReduce(计算) MapReduce概述 MapReduce定义 MapReduce的优缺点 核心思想 MapReduce计算程序运行时的相关进程 官方WordCount源码 Ma ...
- HADOOP |MapReduce篇 (08) MapReduce特性
1- 计数器 计数器是收集作业统计信息的有效手段, 用于质量控制或应用级统计. 内置计数器 任务计数器 任务计数器由其关联任务维护, 并定期发送给 tasktracker , 再由 tasktrack ...
- hadoop调用python算法_使用Python实现Hadoop MapReduce程序
根据上面两篇文章,下面是我在自己的ubuntu上的运行过程.文字基本采用博文使用Python实现Hadoop MapReduce程序, 打字很浪费时间滴. 在这个实例中,我将会向大家介绍如何使用Py ...
- 使用Python实现Hadoop MapReduce程序
根据上面两篇文章,下面是我在自己的ubuntu上的运行过程.文字基本采用博文使用Python实现Hadoop MapReduce程序, 打字很浪费时间滴. 在这个实例中,我将会向大家介绍如何使用Py ...
- Hadoop MapReduce编程 API入门系列之wordcount版本2(六)
这篇博客,给大家,体会不一样的版本编程. 代码 1 package zhouls.bigdata.myMapReduce.wordcount4; 2 3 import java.io.IOExcept ...
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- 用Java编写Hadoop MapReduce任务
尽管Hadoop框架本身是使用Java创建的,但MapReduce作业可以用许多不同的语言编写. 在本文中,我将展示如何像其他Java项目一样,基于Maven项目在Java中创建MapReduce作业 ...
- MapReduce 示例:减少 Hadoop MapReduce 中的侧连接
摘要:在排序和reducer 阶段,reduce 侧连接过程会产生巨大的网络I/O 流量,在这个阶段,相同键的值被聚集在一起. 本文分享自华为云社区<MapReduce 示例:减少 Hadoop ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- Hadoop——MapReduce相关eclipse配置及Api调用(图文超详细版)(内含遇到错误的解决方法)
一.前情提要 前面两篇文章我们已经成功搭建了Hadoop以及安装了Hive,Sqoop和Mysql数据库,现在我们就来利用Hadoop尝试做一个小实战,实现单词统计! 还没有搭建Hadoop成功的同学 ...
最新文章
- 深度学习目标检测法进化史,看这一篇就够了
- 测试几款大型LED的反向电流大小
- STM32的GPIO为输出模式时获取其输出状态
- getlab如何编辑提交时显示的用户名_GitHub 如何让你的提交显示被校验
- 收集的一些jQuery (我平常用的少的,但确实挺有效果的)
- log4j slf4j实现_slf4j 与log4j logback的区别以及使用场景
- 云平台需要开发的底层功能
- linux 家目录没有了,linux刀片服务器断电重启以后home目录下的用户文件夹丢失了...
- android volley 请求参数,android – Volley – 如何发送DELETE请求参数?
- 实战项目 仿写小米商城 网页框架
- java万年历 for_java万年历
- 墓碑上的字符C语言,墓碑上常见的“故显考、故显妣、先考、先妣”,分别是什么意思?...
- 除了用jenkins,还有什么方法可实现持续集成?
- 基于ubuntu系统的HEVC视频编码与解码
- Theano安装教程
- 国内小程序生态服务平台即速应用完成5000万元A+轮融资...
- ssh远程连接服务器
- curl采集 根据关键词 获取雅虎竞价排名
- 定义自定义字体需要css的什么规则,css3自定义字体需要什么规则 css3基本选择器...
- 读《聪明的投资者》有感