MySQL性能优化-根据执行计划进行性能优化
2019独角兽企业重金招聘Python工程师标准>>> 
1. 使用执行计划explain命令分析
在要运行的sql前面加上explain就可以得到执行计划如下表:
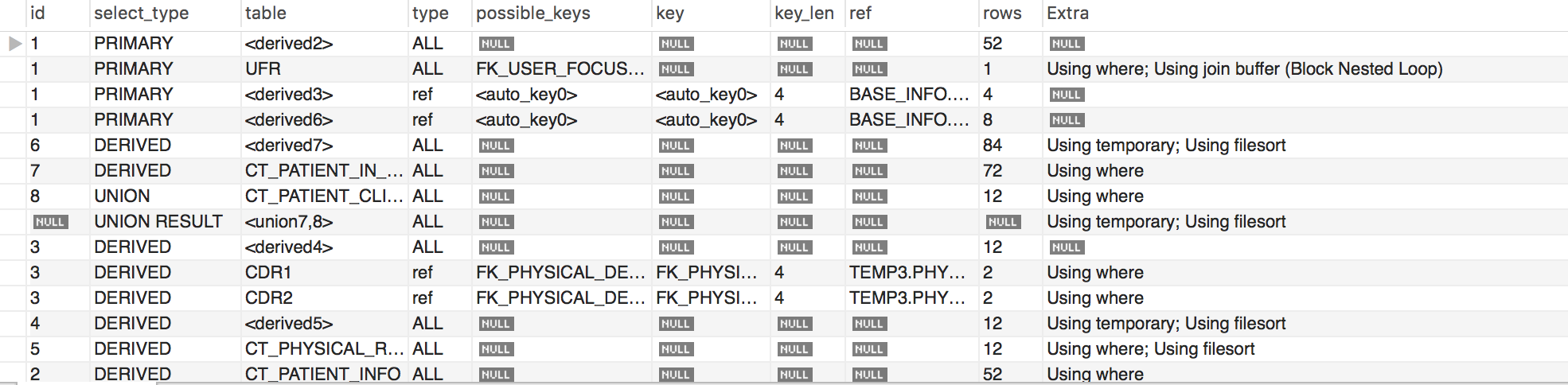
在explain后面增加限制 format = json,可以让返回的数据已json格式返回。
对执行计划得到的各个列的含义:
1)、id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
2)、select_type列常见的有:
A:simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
B:primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个
C:union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
D:dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
E:union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
F:subquery:除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery
G:dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
H:derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
3)、table显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的<derived N>就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与<derived N>类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。
4)、type依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
A:system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
B:const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
C:eq_ref:出现在要连接多个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
D:ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
E:fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
F:ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
G:unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
H:index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
I:range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
J:index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
K:index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
L:all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
5)、possible_keys
查询可能使用到的索引都会在这里列出来
6)、key查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
7)、key_len用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
8)、ref如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
9)、rows 这里是执行计划中估算的扫描行数,不是精确值
10)、extra 这个列可以显示的信息非常多,有几十种,常用的有
A:distinct:在select部分使用了distinc关键字
B:no tables used:不带from子句的查询或者From dual查询
C:使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接。即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
D:using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
E:using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
F:using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询。
G:using sort_union,using_union,using intersect,using sort_intersection:
using intersect:表示使用and连接各个索引的条件时,该信息表示是从处理结果获取交集
using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
H:using temporary:表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
I:using where:表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
J:firstmatch(tb_name):5.6.x开始引入的优化子查询的新特性之一,常见于where子句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
K:loosescan(m..n):5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
除了这些之外,还有很多查询数据字典库,执行计划过程中就发现不可能存在结果的一些提示信息
11)、filtered 使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
2. 使用show profile命令分析
最后,在mysql的每个版本中都会对执行计划进行改进,所以执行计划也不是一成不变的。在具体进行sql优化查询执行计划的时候,还要考虑版本的问题。
参考的文章:
show profile命令分析:http://www.cnblogs.com/SQL888/p/5750123.html
转载于:https://my.oschina.net/ChinaHaoYuFei/blog/850240
MySQL性能优化-根据执行计划进行性能优化相关推荐
- MySQL之索引,执行计划及SQL优化
1.1 索引的分类 从功能逻辑上说,分为普通索引,唯一索引,主键索引,全文索引 从物理实现方式上说,分为聚簇索引,非聚簇索引(2级索引) 从字段个数上来说,分为分为单列索引,联合索引 1.2 适合创建 ...
- MySQL性能分析工具的使用:慢查询日志、EXPLAN的使用、分析优化器执行计划:trace、MySQL监控分析视图-sys schema
文章目录 1.数据库服务器的优化步骤 2.查看系统性能参数 2.1 语法 2.2 常用参数 3.统计SQL的查询成本:last_query_cost 4.定位执行慢的SQL:慢查询日志 4.1 慢查询 ...
- 简单介绍oracle执行计划,Oracle性能优化之oracle中常见的执行计划及其简单解释
一.访问表执行计划 1.table access full:全表扫描.它会访问表中的每一条记录(读取高水位线以内的每一个数据块). 2.table access by user rowid:输入源ro ...
- MySQL 的索引、执行计划、优化器算法
SQL处理流程 INDEX 索引 索引介绍 索引:是排序的快速查找的特殊数据结构,定义作为查找条件的字段上,又称为键key,索引通过存储引擎实现: 索引相当于一本书的目录,可以优化查询. 优点: 索引 ...
- SQL点滴27—性能分析之执行计划
一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<Inside Microsoft SQL S ...
- mysql 数据库优化之执行计划(explain)简析
数据库优化是一个比较宽泛的概念,涵盖范围较广.大的层面涉及分布式主从.分库.分表等:小的层面包括连接池使用.复杂查询与简单查询的选择及是否在应用中做数据整合等:具体到sql语句执行效率则需调整相应查询 ...
- MySQL索引管理及执行计划
MySQL索引管理及执行计划 第1章 索引介绍: 索引是对数据库表中一列或者多列 的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息,如果想按特定职员的姓名来查找,则与他在表中搜索所有的 ...
- Mysql 慢查询 Sql执行计划 SQL每阶段的耗时
文章目录 前言 一.慢查询的相关参数 slow_query_log 是否开启了慢查询 开启慢查询 slow_query_log_file 指定慢查询日志的存储路径及文件 long_query_time ...
- 【云和恩墨大讲堂】从执行计划洞察ORACLE优化器的“小聪明”
作者简介 黄浩 惠普 十年一剑,十年磨砺.3年通信行业,写就近3万条SQL:5年制造行业,遨游在ETL的浪潮:2年性能优化,厚积薄发自成一家 主题介绍: Oracle执行计划的另类解读:调皮的执行计 ...
最新文章
- 1.8M超轻量目标检测模型NanoDet,比YOLO跑得快
- Windows 2003 服务器播放FLV的问题解决
- 计算机学校都有哪些怎么联系方式,计算机应用专业学校联系方式推荐
- java通过ldap添加用户后_ldap连接不上改用户_JAVA通过LDAP做用户登录认证,怎么做业务的异常处理?...
- Linux 进程 | 进程间的通信方式
- 图论算法(三)--最短路径 的Bellman-Flod [ 带负权值图 ] 的解法(JAVA )
- C/C++——C风格的字符串的指针指向的内存位置问题(易错)
- 使用Java实现面向对象编程(1)
- ubuntu 安装chrome浏览器
- jenkins安装部署全过程
- POJ 2723 2-SAT
- php inqude函数,Python匿名函数(lambda函数)
- 阻抗匹配(一):信号发生器
- 2016-03-03 道 法 儒
- 计算与推断思维 十六、比较两个样本
- 锐捷商通v6数据库服务器位置,热烈庆祝我校开通IPv6资源
- 虽然没有见过凌晨四点的洛杉矶,但是我们见证了了凌晨灯火通明科技园:程序员的痛谁懂
- 2020年阴历二月二十九 投资理财之一入雪球就被坑
- mysql采集方式_数据采集的几种方法
- JDK、JRE、JVM分别是什么及它们之间的有什么关联