celebs名人写真图片数据采集,先下载100个G再说
大家好,我是辣条。
今天给大家带来一个宝藏网站,国外名人明星的写真图片网站,冒着进小黑屋的风险出爬虫实战,仅供学习交流!侵删!希望大家给个三连支持。
![]()
采集目标
数据来源: celebs-place
![]()
工具准备
开发环境:win10、python3.7
开发工具:pycharm、Chrome
使用工具包:requests,lxml, os
项目思路
网页图片数据量过大,以单独的一项展示学习 选取单独的A分类
![]()
requests发送网络请求
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
url = 'https://celebs-place.com/photos/people-A.html'
response = requests.get(url, headers=headers)xpath提取对应明星a标签的href属性和明星名字
![]()
html_data = etree.HTML(response.text)
celebs_url_list = html_data.xpath('//div[@class="model_card"]/a/@href')
name_list = html_data.xpath('//div[@class="model_card"]/a/div/span/text()')拼接详情页面url地址, 判断是否能获取数据 提取详情页面所以的url地址 (“你问为啥不获取具体的页数,因为懒!!!!”)
![]()
for page in range(1, 50):url_detail = 'https://celebs-place.com' + celebs_url + 'page{}/'
res = requests.get(url_detail.format(page), headers=headers).text# print(res)data = etree.HTML(res)img_url_list = data.xpath("//div[@class='gallery-p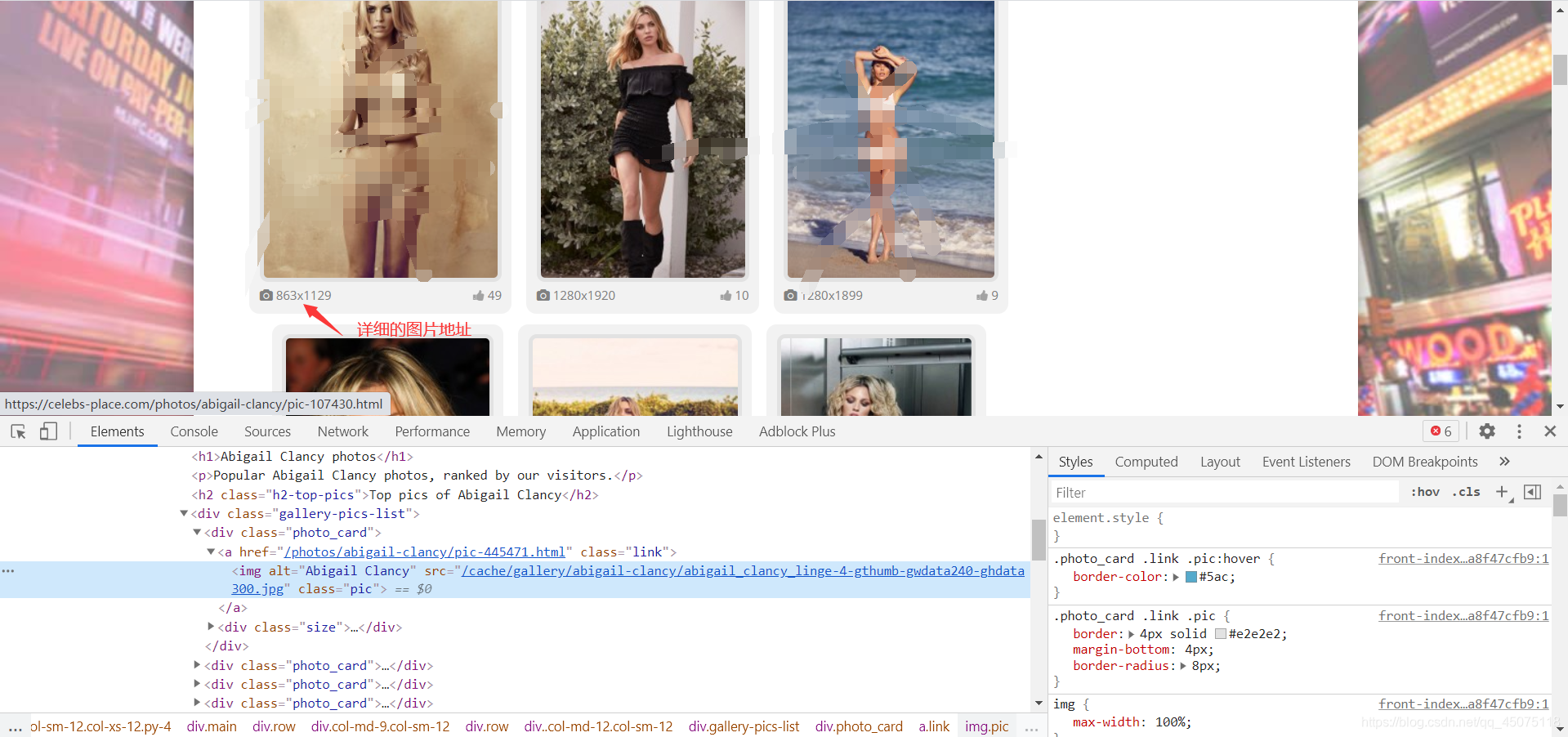
ics-list'][1]/div/a/img/@src")if not img_url_list:break保存的文件夹可以手动创建(最好是代码创建,避免各位大佬在使用代码时有不必要的纠纷 狗头保命)
path = "你的文件路径"if not os.path.exists(path):os.mkdir(path)获取的图片url是小图标的 详细的图片是大图 去除图片url的/cache和后半部分就是大图url(‘-gthumb-gwdata240-ghdata300.jpg’) 提取到准确的图片url地址 请求图片数据,保存对应图片到文件夹
![]()
for img_url in img_url_list:img = "https://celebs-place.com/" + img_url.split('-g')[0].split('/cache/')[1] + '.jpg'result = requests.get(img, headers=headers).content当前网页图片的数据量比较大,有几百G,没有特别需要图片数据的可以和辣条一样做一个文明的爬虫君。
项目思路总结
获取到对明星的分类
requests发送网络请求
xpath提取数据
保存数据到文件
简易源码分享
from lxml import etree
import requests
import os
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
url = 'https://celebs-place.com/photos/people-A.html'
response = requests.get(url, headers=headers)
# print(response.text)
html_data = etree.HTML(response.text)
celebs_url_list = html_data.xpath('//div[@class="model_card"]/a/@href')
name_list = html_data.xpath('//div[@class="model_card"]/a/div/span/text()')
for celebs_url, celebs_name in zip(celebs_url_list, name_list):path = r'E:\python_project\vip_course\celebs_place\img' + "\\" + celebs_nameif not os.path.exists(path):os.mkdir(path)num = 0for page in range(1, 20):url_detail = 'https://celebs-place.com' + celebs_url + 'page{}/'
res = requests.get(url_detail.format(page), headers=headers).text# print(res)data = etree.HTML(res)img_url_list = data.xpath("//div[@class='gallery-pics-list'][1]/div/a/img/@src")if not img_url_list:break# print(img_url)for img_url in img_url_list:img = "https://celebs-place.com/" + img_urlresult = requests.get(img, headers=headers).contentf = open(path + "\\" + str(num) + ".jpg", "wb")f.write(result)num += 1print("正在下载{}第{}页第{}张".format(celebs_name, page, num))
celebs名人写真图片数据采集,先下载100个G再说相关推荐
- 图片的批量下载 和 爬虫爬取图片数据集
图片的批量下载 和 爬虫爬取图片数据集 1.图片的批量下载 1.图片的批量下载 数据集是深度学习的一切,没有数据集它什么也不是,现在你知道数据集很重要了吧 代码: ''' 项目名称:爬取公章数据 创建 ...
- KRSReader酷狗音乐歌词写真图片提取工具(提取KRS文件中的图片)
最近发现酷狗音乐中的歌词写真图片还是比较给力的,很多友友表示喜欢,但是苦于不懂得如何提取,小菜利用周末闲暇时间写了一个小工具,专门用来提取酷狗音乐歌词写真图片. 废话不多说,软件界面如下: 使用说明: ...
- img绝对路径图片显示_使用python爬虫去风景图片网站批量下载图片
使用python爬虫(requests,BeautifulSoup)去风景图片网站批量下载图片 1.写代码背景: 今天闲来无事,想弄点图片放到电脑,方便以后使用,故去百度查找一些风景图片网站,发现图片 ...
- python爬虫一:必应图片(从网页源代码中找出图片链接然后下载)
这里讲解最简单的爬虫:从网页源代码中找出图片链接然后下载 代码: #coding=utf-8 #必应图片爬虫 import re import os import urllib.request url ...
- [day4]python网络爬虫实战:爬取美女写真图片(Scrapy版)
l> 我的新书<Android App开发入门与实战>已于2020年8月由人民邮电出版社出版,欢迎购买.点击进入详情 文章目录 1.开发环境 2.第三方库 3.Scrapy简介 4. ...
- [day1]python网络爬虫实战:爬取美女写真图片
l> 我的新书<Android App开发入门与实战>已于2020年8月由人民邮电出版社出版,欢迎购买.点击进入详情 文章目录 1.开发环境 2.第三方库 3.实现 1.分析url格 ...
- [day2]python网络爬虫实战:爬取美女写真图片(增强版)
l> 我的新书<Android App开发入门与实战>已于2020年8月由人民邮电出版社出版,欢迎购买.点击进入详情 文章目录 1.开发环境 2.第三方库 3.实现 1.分析url格 ...
- python 爬取菜鸟教程python100题,百度贴吧图片反爬虫下载,批量下载
每天一点点,记录学习 python 爬取菜鸟教程python100题 近期爬虫项目,看完请点赞哦: 1:python 爬取菜鸟教程python100题,百度贴吧图片反爬虫下载,批量下载 2:pytho ...
- Python实现下载图片并显示下载进度
from urllib.request import urlretrieve#这是在百度图片里找到一张图片的地址 url='https://timgsa.baidu.com/timg?image&am ...
最新文章
- pytorch cross_entropy
- 生成Excle模板,SXSSFWorkbook-2007之后版本不上传服务器
- weblogic部署ssh2应用出现异常
- 在Xcode8中 如何添加.pch文件
- PHP将多个文件中的内容合并为新的文件
- Kubernetes 入门(1)基本概念
- 刀片服务器改台式电脑_服务器到底是个什么东东?跟电脑有啥区别?电脑知识学习!...
- 5寸屏,智能之外也可以当数码相框
- 重磅更新!YoloV4最新论文!解读yolov4框架
- 剑指offer第七天
- 经过了多种方法的尝试,终于找到Quartus破解成功但是没有办法编译的解决方法
- 基本知识 100024
- Telink/BDT使用说明
- 易到用车网:没有一辆车的租车公司
- CKFinder baseDir 和 baseURL参数解释
- ImageNet一作、李飞飞高徒邓嘉获最佳论文奖,ECCV 2020奖项全公布
- 三天搞定射频识别技术(二)2.3寻卡防冲突选卡
- 数据库-SQL-相关使用
- 如何使用外部控件来管理Web报表属性
- ccf z字形 java,Java具有简单、 __________ 、稳定、与平台无关、解释型、多线程、动态等特点。...