node.js爬虫爬取电影天堂,实现电视剧批量下载。
2019独角兽企业重金招聘Python工程师标准>>> 
###一、项目描述
引言:在电影天堂下电视剧的下伙伴有木有发现,它没有提供批量下载功能,美剧英剧还好,10集左右,我就多点几下吧,可是我们国产局呢,少则三十集,多则四五十级。下载那叫一个痛苦,一个个点(应该有其他什么妙招,但是我们发现,知道的话告诉我一下呗).....不过,想想迅雷不是提供批量下载吗?经过分析,发现迅雷批量下载只需将下载链接分行录入到下载框即可实现批量下载。
**功能:**在网页中录入想看电视剧链接,在该页分行打印出下载链接地址,拷贝链接,迅雷粘贴下载.....
###二、项目截图 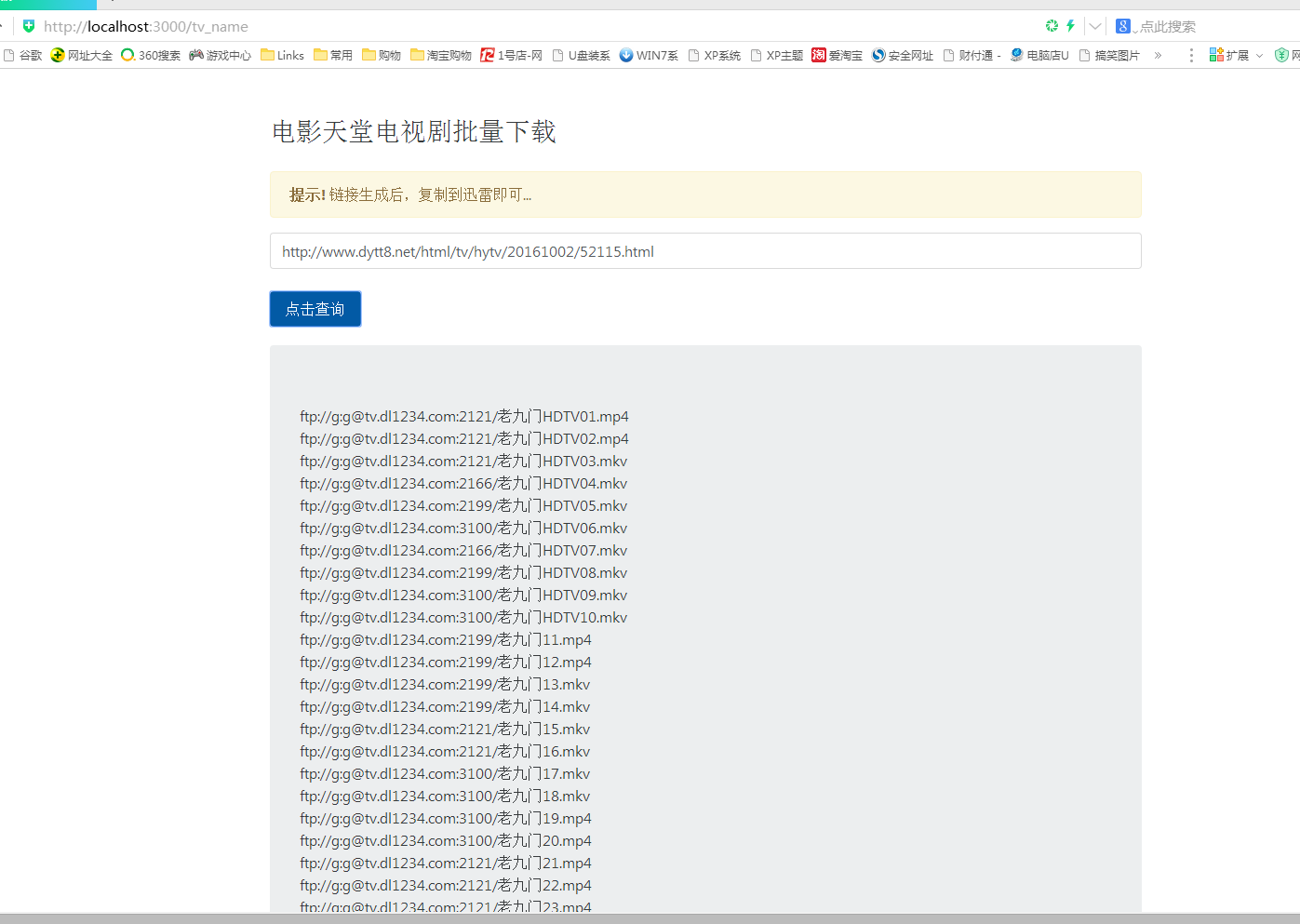
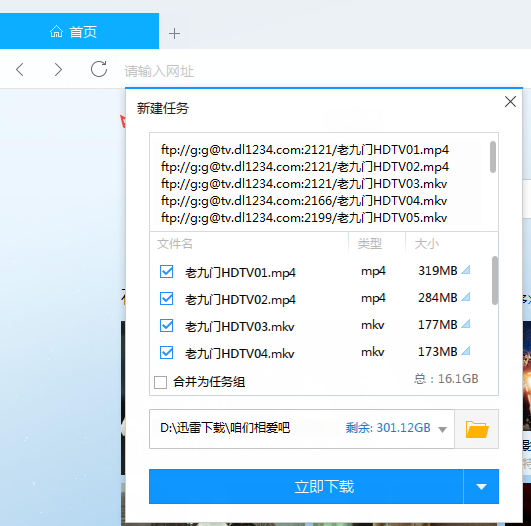
###三、相关github开源工具 感谢开源:
字符编码转换: https://github.com/magicdawn/superagent-charset
类似于jquery操作dom元素工具: https://github.com/cheeriojs/cheerio
配合node.js http请求:https://github.com/visionmedia/superagent
前台:bootstrap+jquery
###四、关键代码 5.1、分行抓取每集下载链接: 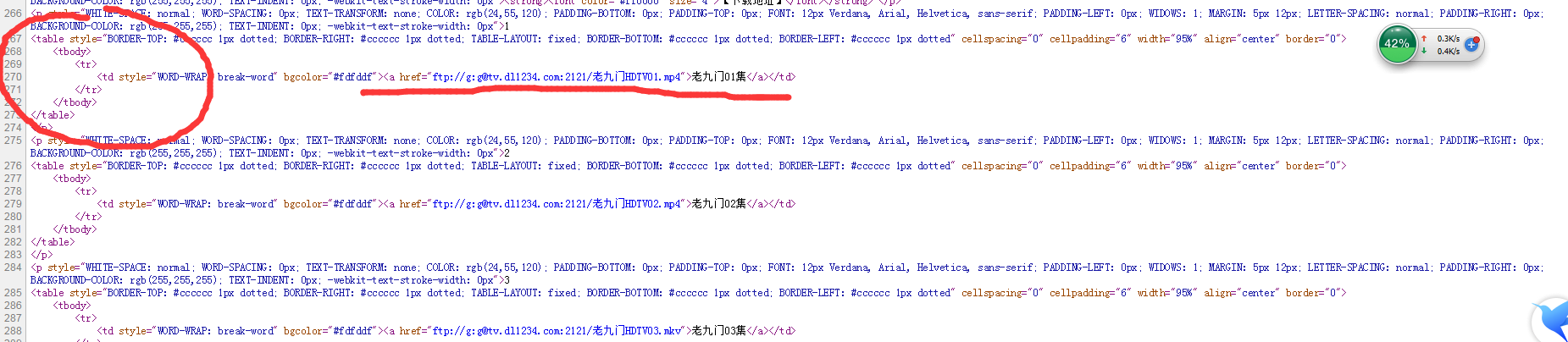
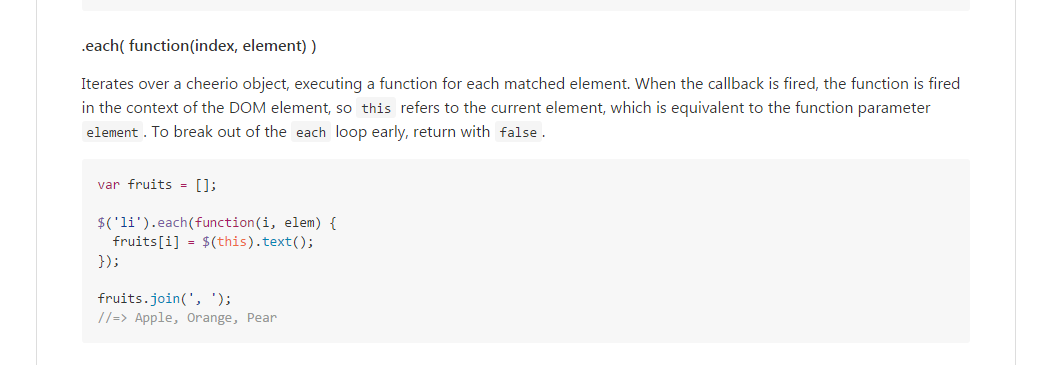
根据github上 cheerio API 文档。通过.each我们可以定位到我们想要的信息。这里我们可以看到每集下载链接就在** tbody >td> a**标签的href中,我们必须确保该链接下的href都是视频链接(第一次想直接通过td> a定位,但是抓取了无关的html链接。)
/*express后台上代码*/
//爬电视剧前台页面
app.get('/tv_name',function (req, res, next) {res.render("index",{title:"express"});
});
//处理请求
app.post('/getTvs',function (req, res, next) {var url=req.body.url;superagent.get(url).charset('gb2312') //这里设置编码.end(function (err, sres) {if (err) {return next(err);}var $ = cheerio.load(sres.text);var items = "";$('tbody td a').each(function (index, element) {var $element = $(element);items=items+$element.attr('href')+"<br/>"});res.send(items);});
});
//这里我想用html页面,压根就不想用ejs或者jade模板引擎。所以需要在app.js中修改模板引擎配置。
app.set('views', path.join(__dirname, 'views'));
app.engine('.html', require('ejs').__express);
app.set('view engine', 'html');
/*HTML前台*/
//网页,boottrap直接用cdn加速,无需下载文件、
<head><meta charset="UTF-8"><title>电影天堂电视剧下载</title><script src="//cdn.bootcss.com/jquery/3.1.1/jquery.min.js"></script><link href="//cdn.bootcss.com/bootstrap/4.0.0-alpha.5/css/bootstrap.min.css" rel="stylesheet">
</head>
<body><div class="row" style="margin-top: 50px"><div class="col-md-3"></div><div class="col-md-6"><h3 style="margin-bottom: 30px">电影天堂电视剧批量下载</h3><div class="alert alert-warning" role="alert"><strong>提示!</strong> 链接生成后,复制到迅雷即可...</div><input type="text" class="form-control" id="tv_link" placeholder="请输入电视剧网页链接"></br><button type="button" class="btn btn-primary" onclick="getData()">点击查询</button><!-- 为 地址列表 准备一个具备大小(宽高)的 DOM --><div class="jumbotron" id="main" style="margin-top: 20px"></div></div><div class="col-md-3"></div>
</div>
</div>
<script>function getData(){var url = $("#tv_link").val(); //获取 $.post("/getTvs",{url:url},function(result){$("#main").html(result);});}
</script>
</body>
</html>
前端录入点数据链接,发送post请求,后端解析请求爬取所需数据发送前台,前台通过拼接html将其展示出来。
###六、遇到的问题: 1、cheerio 注意数据解析定位问题。
2、superagent-charset 电影天堂网页编码是gb2312,如果设置编码会出现乱码。(这里刚好看到就前一两天的博客,里面有关于乱码的介绍:http://www.jb51.net/article/97738.htm)
###六、最后相关网址分享: 直接导入到webstrom运行。访问http://localhost:3000/tv_name 即可;
项目源码: https://github.com/dpc761218914/reptileTVs
转载于:https://my.oschina.net/u/2480757/blog/791979
node.js爬虫爬取电影天堂,实现电视剧批量下载。相关推荐
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 本文地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影网的信息 ...
- python爬电影_使用Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- java爬虫拉勾网_[Java教程]node.js爬虫爬取拉勾网职位信息
[Java教程]node.js爬虫爬取拉勾网职位信息 0 2017-03-14 00:00:21 简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳 ...
- python爬电影天堂_python爬虫爬取电影天堂电影
python爬虫爬取电影天堂电影?本项目实现一个简单的爬虫,通过requests和BeautifulSoup爬取电影天堂电影信息,包括片名.年代.产地.类别.语言.海报链接和视频链接等内容.pytho ...
- scrapy初步-简单静态爬虫(爬取电影天堂所有电影)
之前用java写过一个简单的爬取电影天堂信息的爬虫,后来发现用python写这种简单的爬虫程序更简单,异步网络框架在不使用多线程和多进程的情况下也能增加爬取的速度,目前刚开始学scrapy,用这个写了 ...
- python软件安装链接电视_Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求 一位高人曾经说过,想爬取数据,要先分析网站 今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了. 这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽 ...
- 多线程爬虫爬取电影天堂资源
先来简单介绍一下,网络爬虫的基本实现原理吧.一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新 ...
- Scrapy爬虫爬取电影天堂
Scrapy CrawlSpider爬取 目标网址:http://www.dytt8.net 创建项目:scrapy startproject <爬虫项目文件的名字> 生成 CrawlSp ...
- 爬虫学习(一)---爬取电影天堂下载链接
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 主要利用了python3.5 requests,Bea ...
最新文章
- find函数注意事项
- [Machine Learning] 梯度下降法的三种形式BGD、SGD以及MBGD
- 改善C#程序的建议10:用Parallel简化Task
- Little Sub and Traveling
- ITK:Levenberg-Marquardt优化
- 机房系统(七)——【报表】
- AJPFX讲解Java 性能优化[4]:关于 finalize 函数
- Linux运维系统工程师系列---13
- rank,dense_rank,row_number使用和区别
- webpack打包缓存_webpack独立打包与缓存处理
- 计算机信息管理的检索步骤,信息检索策略与步骤
- MYS-6ULX资料汇总
- dom4j解析xml格式字符串获取标签属性和内容
- AutoCAD 快捷键
- 3. lambda 方法引用
- 数据分析师前景如何,需要学习什么技能?
- linux保存为jpg格式的文件,Linux 系统转换 CR2 格式原生照片为 JPEG 格式
- LeetCode:401(Python)—— 二进制手表(简单)
- 最近很多笔试的基础题,小汇总下
- Arduino(2560)控制两个步进电机通过控制器