HashMap、ConcurrentHashMap源码解读(JDK7/8)
下载地址(已将图片传到云端,md文件方便浏览更改):https://download.csdn.net/download/hancoder/12318377
推荐视频地址:
https://www.bilibili.com/video/BV1FE411t7M7
https://www.bilibili.com/video/BV1Nz4y1d77x
笔记地址:https://blog.csdn.net/hancoder/article/details/107829728
推荐阅读:https://javadoop.com/post/hashmap
一 HashMap(源码级解读)
0 直接说区别
对于hashmap:
- 7中是头插,8中是尾插
- 8中链表会转换成红黑树(超过8个),7一直是链表
- 8中可以是没有对应key时才插入,7中没这个功能
对于ConcurrentHashMap
- 7中采用的是两级hashmap,8中采用的是一级hashmap
- 7中锁会锁第二级hashmap
- 8在升级红黑树的过程中不一定每次扩容都升级,而是还得大于64
HashTable:
- 不允许value==0
线程安全时不能为Null的原因:
假设使用map.get(key1)时返回为null。
会有两种可能:1.key1不存在,所以返回为null;
key对应的值为null
- 对于单线程的HashMap,可以通过contains(key)来检查是哪种情况;
- 多线程场景下:假设concurrentHashMap允许存放值为null的value。有A、B两个线程。
线程A调用concurrentHashMap.get(key1)方法,返回为null我们用containsKey(key1)来验证我们的假设是否成立,我们期望的结果是返回false。
但是在我们调用concurrentHashMap.get(key1)方法之后,containsKey方法之前,有一个线程B执行了concurrentHashMap.put(key1,null)的操作。那么我们调用containsKey方法返回的就是true了。这就与我们的假设的真实情况不符合了。也就是上面说的二义性。
1.HashMap简介
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null,但是key只能有一个为null。此外,HashMap中的映射不是有序的。
- JDK1.8 之前 HashMap 由 数组+链表== 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突**(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)**而存在的(“拉链法”解决冲突)。
- JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8,或者红黑树的边界值)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
- 如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考
treeifyBin方法。 - 这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。具体可以参考
treeifyBin方法。 - 当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于8并且数组长度大于64时,链表转换为红黑树时,效率也变的更高效。
- 如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考
2.HashMap底层的数据结构
2.1数据结构概念
7组成结构
在JDK1.8 之前 HashMap 由 数组+链表 数据结构组成的。

大方向上,HashMap7 里面是一个数组,然后数组中每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
loadFactor:负载因子,默认为 0.75。
threshold:扩容的阈值,等于 capacity * loadFactor
8组成结构
在JDK1.8 之后 HashMap 由 数组+链表 +红黑树数据结构组成的。

8与7的区分:
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
2.2存储数据过程浅析
测试:
public class Demo01 {public static void main(String[] args) {HashMap<String, Integer> map = new HashMap<>();map.put("刘德华", 53);map.put("柳岩", 35);map.put("张学友", 55);map.put("郭富城", 52);map.put("黎明", 51);map.put("林青霞", 55);map.put("刘德华", 50);}
}
存储过程如下所示:
![]()
说明:
1.面试题1:HashMap中hash函数是怎么实现的?还有哪些hash函数的实现方式?
对于key的hashCode做hash操作,无符号右移16位然后做异或运算。
还有伪随机数法和取余数法。这2种效率都比较低。而无符号右移16位和异或运算效率是最高的。至于底层是如何计算的我们下面看源码时给大家讲解。
2.面试题2:当两个对象的hashCode相等时会怎么样?
会产生哈希碰撞,若key值内容相同则替换旧的value.不然连接到链表后面,链表长度超过阈值8并且数组长度大于等于64就转换为红黑树存储。
3.面试题3:何时发生哈希碰撞和什么是哈希碰撞,如何解决哈希碰撞?
只要两个元素的key计算的哈希码值相同就会发生哈希碰撞。jdk8前使用链表解决哈希碰撞。jdk8之后使用链表+红黑树解决哈希碰撞。
4.面试题4:如果两个键的hashcode相同,如何存储键值对?
hashcode相同,通过equals比较内容是否相同。
相同:则新的value覆盖之前的value
不相同:则将新的键值对添加到哈希表中
5.在不断的添加数据的过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
6.通过上述描述,当位于一个链表中的元素较多,即hash值相等但是内容不相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度(阈值)超过 8 时且当前数组的长度 > 64时,将链表转换为红黑树,这样大大减少了查找时间。jdk8在哈希表中引入红黑树的原因只是为了查找效率更高。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。如下图所示。
![]()
但是这样的话问题来了,传统hashMap的缺点,1.8为什么引入红黑树?这样结构的话不是更麻烦了吗,为何阈值大于8换成红黑树?
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。 当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。
jdk8存储过程:
![]()
说明:
1.size表示 HashMap中K-V的实时数量 , 注意这个不等于数组的长度 。
2.threshold( 临界值) =capacity(容量) * loadFactor( 加载因子 )。这个值是当前已占用数组长度的最大值。size超过这个临界值就重新resize(扩容),扩容后的 HashMap 容量是之前容量的两倍 。
3.HashMap继承关系
HashMap继承关系如下图所示:
![]()
说明:
- Cloneable 空接口,表示可以克隆。 创建并返回HashMap对象的一个副本。
- Serializable 序列化接口。属于标记性接口。HashMap对象可以被序列化和反序列化。
- AbstractMap 父类提供了Map实现接口。以最大限度地减少实现此接口所需的工作。
4.HashMap类成员+方法
4.1成员变量
//JDK8
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {// 序列号private static final long serialVersionUID = 362498820763181265L; // 默认的初始容量是16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 最大容量static final int MAXIMUM_CAPACITY = 1 << 30; // 默认的填充因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 当桶(bucket)上的结点数大于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8; // 当桶(bucket)上的结点数小于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;// 桶中结构转化为红黑树对应的table的最小大小static final int MIN_TREEIFY_CAPACITY = 64;// 存储元素的数组,总是2的幂次倍transient Node<k,v>[] table; /*transient修饰符的作用是使该变量在序列化的时候不会被储存。但是hashmap中的变量table是储存了容器中所有的元素,在序列化中不被储存,那么反序列化后hashmap对象中岂不是个空容器?后来通过细想,table里存的只是引用,就算在序列化中储存到硬盘里,反序列化后table变量里的引用已经没有意义了。至于hashmap是如何在序列化中储存元素呢?原来是它通过重写Serializable接口中的writeObject方法和readObject方法实现的。*/// 存放具体元素的集transient Set<map.entry<k,v>> entrySet;// 存放元素的个数,注意这个不等于数组的长度。数组不会放满的transient int size;// 每次扩容和更改map结构的计数器transient int modCount; // 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容int threshold;// 加载因子final float loadFactor;
}
Node内部类
Node节点类源码:
7Entry
//JDK7
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;int hash;Entry(int h,K k,V v,Entry<K,V> n){//n为旧索引上结点value=v;next=n;//由此可见是头插key=k;hash=h;}
}
8Node
// 持有该数组的属性:
// transient Node<K,V>[] table;// JDK8
static class Node<K,V> implements Map.Entry<K,V> {//继承自 Map.Entry<K,V>final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较final K key;//键V value;//值// 指向下一个节点Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }// 重写hashCode()方法,他的hash值是key和value的结合,只要有一个不一样,node的hash就不等(大概率)public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}// 重写 equals() 方法public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}
树节点类源码:
//JDK8
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {//static class Entry<K,V> extends HashMap.Node<K,V> {TreeNode<K,V> parent; // 父TreeNode<K,V> left; // 左TreeNode<K,V> right; // 右TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red; // 判断颜色TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}// 返回根节点final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}}
}
DEFAULT_INITIAL_CAPACITY初始大小
1.集合的初始化容量( 必须是二的n次幂 )
//默认的初始容量是16 -- 1<<4相当于1*2的4次方---1*16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
问题: 为什么必须是2的n次幂?如果输入值不是2的幂比如10会怎么样?
HashMap构造方法还可以指定集合的初始化容量大小:
HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
根据上述讲解我们已经知道,当向HashMap中添加一个元素的时候,需要根据key的hash值,去确定其在数组中的具体位置。 HashMap为了存取高效,要尽量减少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法。
这个算法实际就是取模,hash%length,但是计算机中直接求余效率不如位运算(这点上述已经讲解)。所以源码中做了优化,使用 hash&(length-1),而实际上hash%length等于hash&(length-1)的前提是length是2的n次幂。
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
举例:
说明:按位与运算:相同的二进制数位上,都是1的时候,结果为1,否则为零。
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;
例如长度length为8时候,8是2的3次幂。二进制是:1000
length-1 二进制运算:1000
- 1
---------------------111
如下所示:当hash为3时
hash&(length-1)
3 &(8 - 1)=3 00000011 3 hash
& 00000111 7 length-1
---------------------00000011-----》3 数组下标hash&(length-1) 当hash为2时
2 & (8 - 1) = 2 00000010 2 hash
& 00000111 7 length-1
---------------------00000010-----》2 数组下标
说明:上述计算结果是不同位置上,不碰撞;
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
例如长度length为9时候,9不是2的n次幂。二进制是:00001001
length-1 二进制运算:1001
- 1
---------------------1000
如下所示:
hash&(length-1) 当hash为3时
3 &(9 - 1)=0 00000011 3 hash
& 00001000 8 length-1
---------------------00000000-----》0 数组下标hash&(length-1) 当hash为2时
2 & (9 - 1) = 2 00000010 2 hash
& 00001000 8 length-1
---------------------00000000-----》0 数组下标
说明:上述计算结果都在0上,碰撞了;
注意: 当然如果不考虑效率直接求余即可(就不需要要求长度必须是2的n次方了)
小结:
1.由上面可以看出,当我们根据key的hash确定其在数组的位置时,如果n为2的幂次方,可以保证数据的均匀插入,如果n不是2的幂次方,可能数组的一些位置永远不会插入数据,浪费数组的空间,加大hash冲突。
2.另一方面,一般我们可能会想通过 % 求余来确定位置,这样也可以,只不过性能不如 & 运算。而且当n是2的幂次方时:hash & (length - 1) == hash % length
3.因此,HashMap 容量为2次幂的原因,就是为了数据的的均匀分布,减少hash冲突,毕竟hash冲突越大,代表数组中一个链的长度越大,这样的话会降低hashmap的性能
4.如果创建HashMap对象时,输入的数组长度是10,不是2的幂,HashMap通过一通位移运算和或运算得到的肯定是2的幂次数,并且是大于且离那个数最近的数字。
tableSizeFor()向上取整2次幂
//创建HashMap集合的对象,指定数组长度是10,不是2的幂
HashMap hashMap = new HashMap(10);
public HashMap(int initialCapacity) {//initialCapacity=10this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {//initialCapacity=10if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);
}// JDK7和8的实现方法不一样,下面分开讲解//-----JDK8--------
static final int tableSizeFor(int cap) {//给容量返回一个2的幂大小的数//思路:把最高位1后面的位全变成1,然后+1int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}//-----JDK7--------
private static int roundUpToPowerOf2(int number) {//number >= 0,不能为负数,//(1)number >= 最大容量:就返回最大容量//(2)0 =< number <= 1:返回1//(3)1 < number < 最大容量:return number >= MAXIMUM_CAPACITY? MAXIMUM_CAPACITY: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;//-1
}
//该方法和jdk8中的tabSizeFor实现基本差不多,只不过这里求的是小于该数的最大2次幂
public static int Integer.highestOneBit(int i) {//只保留最大的位,如果后面都是0还好我没就是想要这个值,但后面不全为0我没就想求更大的幂,所以我们代入此方法时先-1//因为传入的i>0,所以i的高位还是0,这样使用>>运算符就相当于>>>了,高位0。//还是举个例子,假设i=5=0101i |= (i >> 1); //(1)i>>1=0010;(2)i= 0101 | 0010 = 0111i |= (i >> 2); //(1)i>>2=0011;(2)i= 0111 | 0011 = 0111i |= (i >> 4); //(1)i>>4=0000;(2)i= 0111 | 0000 = 0111i |= (i >> 8); //(1)i>>8=0000;(2)i= 0111 | 0000 = 0111i |= (i >> 16); //(1)i>>16=0000;(2)i= 0111 | 0000 = 0111return i - (i >>> 1); //(1)0111>>>1=0011(2)0111-0011=0100=4//所以这里返回4。//而在上面的roundUpToPowerOf2方法中,最后会将highestOneBit的返回值进行 << 1 操作,即最后的结果为4<<1=8.就是返回大于number的最小2次幂
}
说明:
由此可以看到,当在实例化HashMap实例时,如果给定了initialCapacity(假设是10),由于HashMap的capacity必须都是2的幂,因此tableSizeFor()这个方法用于找到大于等于initialCapacity(假设是10)的最小的2的幂(initialCapacity如果就是2的幂,则返回的还是这个数)。
下面分析这个算法:
1)、首先,为什么要对cap做减1操作。int n = cap - 1;
这是为了防止,cap已经是2的幂。如果cap已经是2的幂, 又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。如果不懂,要看完后面的几个无符号右移之后再回来看看。
下面看看这几个无符号右移操作:
2)、如果n这时为0了(经过了cap-1之后),则经过后面的几次无符号右移依然是0,最后返回的capacity是 1(最后有个(n < 0) ? 1的操作)。
这里只讨论n不等于0的情况。
3)、注意:|(按位或运算):运算规则:相同的二进制数位上,都是0的时候,结果为0,否则为1。
只要是1就是1
//关于移位的说明:
>> :按二进制形式把所有的数字向右移动对应位数,低位移出(舍弃),高位的空位补符号位,即正数补零,负数补1。符号位不变。
>>>:按二进制形式把所有的数字向右移动对应位数,低位移出(舍弃),高位的空位补零。对于正数来说和带符号右移相同,对于负数来说不同。-1在32位二进制中表示为:
11111111 11111111 11111111 11111111-1>>1:按位右移,符号位不变,仍旧得到
11111111 11111111 11111111 11111111
因此值仍为-1而-1>>>1的结果为 01111111 11111111 11111111 11111111
第一次右移 :
int n = cap - 1;//cap=10 n=9
n |= n >>> 1;00000000 00000000 00000000 00001001 //9
| 00000000 00000000 00000000 00000100 //9右移之后变为4
-------------------------------------------------00000000 00000000 00000000 00001101 //按位异或之后是13
由于n不等于0,则n的二进制表示中总会有一bit为1,这时考虑最高位的1。通过无符号右移1位,则将最高位的1右移了1位,再做或操作,使得n的二进制表示中与最高位的1紧邻的右边一位也为1,如:
00000000 00000000 00000000 00001101
第二次右移 :
n |= n >>> 2;//n通过第一次右移变为了:n=1300000000 00000000 00000000 00001101 // 13
|00000000 00000000 00000000 00000011 //13右移之后变为3
-------------------------------------------------00000000 00000000 00000000 00001111 //按位异或之后是15
注意,这个n已经经过了n |= n >>> 1; 操作。假设此时n为00000000 00000000 00000000 00001101 ,则n无符号右移两位,会将最高位两个连续的1右移两位,然后再与原来的n做或操作,这样n的二进制表示的高位中会有4个连续的1。如:
00000000 00000000 00000000 00001111 //按位异或之后是15
第三次右移 :
n |= n >>> 4;//n通过第一、二次右移变为了:n=1500000000 00000000 00000000 00001111 // 15
|00000000 00000000 00000000 00000000 //15右移之后变为0
-------------------------------------------------00000000 00000000 00000000 00001111 //按位异或之后是15
这次把已经有的高位中的连续的4个1,右移4位,再做或操作,这样n的二进制表示的高位中正常会有8个连续的1。如00001111 1111xxxxxx 。
以此类推
注意,容量最大也就是32bit的正数,因此最后n |= n >>> 16; ,最多也就32个1(但是这已经是负数了。在执行tableSizeFor之前,对initialCapacity做了判断,如果大于MAXIMUM_CAPACITY(2 ^ 30),则取MAXIMUM_CAPACITY。如果等于MAXIMUM_CAPACITY(2 ^ 30),会执行移位操作。所以这里面的移位操作之后,最大30个1,不会大于等于MAXIMUM_CAPACITY。30个1,加1之后得2 ^ 30) 。
请看下面的一个完整例子:
![]()
注意,得到的这个capacity却被赋值给了threshold。
this.threshold = tableSizeFor(initialCapacity);//initialCapacity=10
2.默认的负载因子,默认值是0.75 。达到这个值后就扩容
static final float DEFAULT_LOAD_FACTOR = 0.75f;
3.集合最大容量
//集合最大容量的上限是:2的30次幂
static final int MAXIMUM_CAPACITY = 1 << 30;
4.当链表的值超过8则会转红黑树(1.8新增)
//当桶(bucket)上的结点数大于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8;
// 红黑树是JDK8开始的。要求是桶长度超过8.且数组大小大于64
问题:为什么Map桶中节点个数超过8才转为红黑树?
8这个阈值定义在HashMap中,针对这个成员变量,在源码的注释中只说明了8是bin(bin就是bucket(桶))从链表转成树的阈值,但是并没有说明为什么是8:
在HashMap中有一段注释说明: 我们继续往下看 :
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5)*pow(0.5, k)/factorial(k)).
The first values are:
因为树节点的大小大约是普通节点的两倍,所以我们只在箱子包含足够的节点时才使用树节点(参见TREEIFY_THRESHOLD)。当它们变得太小(由于删除或调整大小)时,就会被转换回普通的桶。在使用分布良好的用户hashcode时,很少使用树箱。理想情况下,在随机哈希码下,箱子中节点的频率服从泊松分布
(http://en.wikipedia.org/wiki/Poisson_distribution),默认调整阈值为0.75,平均参数约为0.5,尽管由于调整粒度的差异很大。忽略方差,列表大小k的预期出现次数是(exp(-0.5)*pow(0.5, k)/factorial(k))。
第一个值是:0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
TreeNodes占用空间是普通Nodes的两倍,所以只有当bin包含足够多的节点时才会转成TreeNodes,而是否足够多就是由TREEIFY_THRESHOLD的值决定的。当bin中节点数变少时,又会转成普通的bin。并且我们查看源码的时候发现,链表长度达到8就转成红黑树,当长度降到6就转成普通bin。
这样就解释了为什么不是一开始就将其转换为TreeNodes,而是需要一定节点数才转为TreeNodes,说白了就是权衡,空间和时间的权衡。
这段内容还说到:当hashCode离散性很好的时候,树型bin用到的概率非常小,因为数据均匀分布在每个bin中,几乎不会有bin中链表长度会达到阈值。但是在随机hashCode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的hash算法,因此就可能导致不均匀的数据分布。不过理想情况下随机hashCode算法下所有bin中节点的分布频率会遵循泊松分布,我们可以看到,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。所以,之所以选择8,不是随便决定的,而是根据概率统计决定的。由此可见,发展将近30年的java每一项改动和优化都是非常严谨和科学的。
也就是说:选择8因为符合泊松分布,超过8的时候,概率已经非常小了,所以我们选择8这个数字。
补充:
1).
Poisson分布(泊松分布),是一种统计与概率学里常见到的离散[概率分布]。
泊松分布的概率函数为:
![]()
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。
2).以下是我在研究这个问题时,在一些资料上面翻看的解释:供大家参考:
红黑树的平均查找长度是log(n),如果长度为8,平均查找长度为log(8)=3,链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,这才有转换成树的必要;链表长度如果是小于等于6,6/2=3,而log(6)=2.6,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
5.当链表的值小于6则会从红黑树转回链表
//当桶(bucket)上的结点数小于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;
6.当Map里面的数量超过这个值时,表中的桶才能进行树形化 ,否则桶内元素太多时会扩容,而不是树形化。为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD (8)
//桶中结构转化为红黑树对应的数组长度最小的值
static final int MIN_TREEIFY_CAPACITY = 64;
7、table用来初始化(必须是二的n次幂)(重点)
//存储元素的数组
transient Node<K,V>[] table;
table在JDK1.8中我们了解到HashMap是由数组加链表加红黑树来组成的结构其中table就是HashMap中的数组,jdk8之前数组类型是Entry<K,V>类型。从jdk1.8之后是Node<K,V>类型。只是换了个名字,都实现了一样的接口:Map.Entry<K,V>。负责存储键值对数据的。
8、 HashMap中存放元素的个数(重点)
//存放元素的个数,注意这个不等于数组的长度。transient int size;
size为HashMap中K-V的实时数量,不是数组table的长度。
9、 用来记录HashMap的修改次数
// 每次扩容和更改map结构的计数器transient int modCount;
10、 用来调整大小下一个容量的值计算方式为(容量*负载因子)
// 临界值 当实际大小(容量*负载因子)超过临界值时,会进行扩容
int threshold;
loadFactor加载因子
// 加载因子 元素个数/数组长度
final float loadFactor;
说明:
1.loadFactor加载因子,默认0.75,是用来衡量 HashMap 满的程度,表示HashMap的数组存放数据疏密程度,影响hash操作到同一个数组位置的概率,计算HashMap的实时加载因子的方法为:size/capacity,而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是 table 的长度length。
loadFactor太大导致查找元素效率低,而太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
当HashMap里面容纳的元素已经达到HashMap数组长度的75%时,表示HashMap太挤了,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能。,所以开发中尽量减少扩容的次数,可以通过创建HashMap集合对象时指定初始容量来尽量避免。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
如何传入加载因子;构造haspMap时构造传入
构造方法:
HashMap(int initialCapacity, float loadFactor) 构造一个带指定初始容量和加载因子的空 HashMap。
2.为什么加载因子设置为0.75,初始化临界值是12?
loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
如果希望链表尽可能少些。要提前扩容,有的数组空间有可能一直没有存储数据。加载因子尽可能小一些。
举例:
例如:加载因子是0.4。 那么16*0.4--->6 如果数组中满6个空间就扩容会造成数组利用率太低了。加载因子是0.9。 那么16*0.9---->14 那么这样就会导致链表有点多了。导致查找元素效率低。
所以既兼顾数组利用率又考虑链表不要太多,经过大量测试0.75是最佳方案。
- threshold计算公式:capacity(数组长度默认16) * loadFactor(负载因子默认0.75)。这个值是当前已占用数组长度的最大值。当Size>=threshold的时候,那么就要考虑对数组的resize(扩容),也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。 扩容后的 HashMap 容量是之前容量的两倍.
哈希种子:默认为0
final boolean initHashSeedAsNeeded(int capacity) {//通过上面的过程,我们知道了currentAltHashing =falseboolean currentAltHashing = hashSeed != 0;//useAltHashing = false//我们想让useAltHashing为trueboolean useAltHashing = sun.misc.VM.isBooted() &&(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);//容量大于//ALTERNATIVE_HASHING_THRESHOLD是JVM中配置的参数// false ^ false 结果为false,switching为falseboolean switching = currentAltHashing ^ useAltHashing;//两个不相等返回trueif (switching) {//true了后种子才可能不是0hashSeed = useAltHashing//只有在这个地方会改变种子? sun.misc.Hashing.randomHashSeed(this): 0;}//返回falsereturn switching;
}
4.2构造方法
HashMap 中重要的构造方法,它们分别如下:
1、构造一个空的 HashMap ,默认初始容量(16)和默认负载因子(0.75)。
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // 将默认的加载因子0.75赋值给loadFactor// 没有new数组的语句,也就是类似于懒加载的,第一次put时再new
}
2、传入另一个Map
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);//下面会分析到这个方法
}
3、 构造一个具有指定的初始容量和默认负载因子(0.75) HashMap。
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);//重载
}// 指定的初始容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {//初试容量,加载因子//判断初始化容量initialCapacity是否小于0if (initialCapacity < 0)//如果小于0,则抛出非法的参数异常IllegalArgumentExceptionthrow new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);//判断初始化容量initialCapacity是否大于集合的最大容量MAXIMUM_CAPACITY-》2的30次幂if (initialCapacity > MAXIMUM_CAPACITY)//如果超过MAXIMUM_CAPACITY,会将MAXIMUM_CAPACITY赋值给initialCapacityinitialCapacity = MAXIMUM_CAPACITY;//判断负载因子loadFactor是否小于等于0或者是否是一个非数值if (loadFactor <= 0 || Float.isNaN(loadFactor))//如果满足上述其中之一,则抛出非法的参数异常IllegalArgumentExceptionthrow new IllegalArgumentException("Illegal load factor: " +loadFactor);//将指定的加载因子赋值给HashMap成员变量的负载因子loadFactorthis.loadFactor = loadFactor;/*tableSizeFor(initialCapacity) 判断指定的初始化容量是否是2的n次幂,如果不是那么会变为比指定初始化容量大的最小的2的n次幂。这点上述已经讲解过。但是注意,在tableSizeFor方法体内部将计算后的数据返回给调用这里了,并且直接赋值给threshold边界值了。有些人会觉得这里是一个bug,应该这样书写:this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;这样才符合threshold的意思(当HashMap的size到达threshold这个阈值时会扩容)。但是,请注意,在jdk8以后的构造方法中,并没有对table这个成员变量进行初始化,table的初始化被推迟到了put方法中,在put方法中会对threshold重新计算,put方法的具体实现我们下面会进行讲解*/this.threshold = tableSizeFor(initialCapacity);
}
4.3成员方法
计算索引思路:
由key到hashCode:key有个key.hashCode()方法
由hashCode()得到hash:利用hash()函数。JDK7和8主要是hash()不同,但思想都是移位后按位异或。
hash值得到坐标:直接 i = (length - 1) & hash;
hash()
流程:key–>key.hashCode()–>hash=hash(key.hashCode())–>hash移位、求异或–>取余得到坐标i
JDK8的hash():
这个哈希方法首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或得到最后的hash值。计算过程如下所示:
//JDK8
static final int hash(Object key) {int h;/* 1)如果key等于null:null也是有哈希值的,返回的是0.2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h【无符号右移16位】后的二进制进行【按位异或】得到最后的hash值*/return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//>>>无符号右移后按位异或
}
//------------------
//JDK7
static int hash(int h) {//h是k.hashCode();与hash种子的结合,初学认为是k.hashCode();即可h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);
}//性能会稍差一点,因为扰动了4次hashCode
从上面可以得知HashMap是支持Key为空的,而HashTable是直接用Key来获取HashCode所以key为空会抛异常。
{其实上面就已经解释了为什么HashMap的长度为什么要是2的幂因为HashMap 使用的方法很巧妙,它通过 hash & (table.length -1)来得到该对象的保存位,前面说过 HashMap 底层数组的长度总是2的n次方,这是HashMap在速度上的优化,位操作比取模操作速度快。
当 length 总是2的n次方时,hash & (length-1)运算等价于对 length 取模,也就是hash%length,但是&比%具有更高的效率。比如 n % 32 = n & (32 -1)。}
在putVal函数中使用到了上述hash函数计算的哈希值:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {。。。。。。。。。;if ((p = tab[i = (n - 1) & hash]) == null){...;}//这里的n表示数组长度16。。。。。。。。。;
}
hash()的按位处理演示:
- key.hashCode();返回散列值也就是hashcode。假设随便生成的一个值。
- n:数组初始化的长度是16
- &(按位与运算):运算规则:相同的二进制数位上,都是1的时候,结果为1,否则为零。
- ^(按位异或运算):运算规则:相同的二进制数位上,数字相同,结果为0,不同为1。
>>>:按位无符号右移。无符号右移无论正负,左面都填充0;而有符号右移>>是正补0负补1
1)key.hashCode();返回散列值也就是hashcode。假设随便生成的一个值。
![]()
简单来说就是:
高16 bit 不变,低16 bit 和高16 bit 做了一个异或(得到的 hashcode 转化为32位二进制,前16位和后16位低16 bit和高16 bit做了一个异或)
问题:为什么要这样操作呢?
如果当n即数组长度很小,假设是16的话,那么n-1即为 —》1111 ,这样的值和hashCode()直接做按位与操作,实际上只使用了哈希值的后4位。如果当哈希值的高位变化很大,低位变化很小,这样就很容易造成哈希冲突了,所以这里把hashCode的高低位都利用起来,从而解决了这个问题。
例如上述:hashCode()的异或结果为hh: 1111 1111 1111 1111 1111 0000 1110 1010&n-1即16-1--》15: 。。。。。。。。。。。。。。。。。....1111-------------------------------------------------------------------0000 0000 0000 0000 0000 0000 0000 1010 ----》10作为索引其实就是将hashCode值作为数组索引,那么如果下个高位hashCode不一致,低位一致的话,就会造成计算的索引还是10,从而造成了哈希冲突了。降低性能。
(n-1) & hash = -> 得到下标 (n-1) n表示数组长度16,n-1就是15
取余数本质是不断做除法,把剩余的数减去,运算效率要比位运算低。
put()
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);//final V putVal()方法缺省权限修饰符,对外不可见,用户无法调用,只能通过put()
}
putVal()
主要参数:
- hash: key的hash值
- key: 原始Key
- value: 要存放的值
- onlyIfAbsent: true代表只插入新值。如果有旧值,不修改。
- evict: 如果为false表示table为创建状态
putVal()方法流程:
![]()
if坐标为null先resize()然后直接赋值
else原来有值
- if判断第一个key对不对。key同则拿到e结点
- elif判断是不是树,是树就按照树的方法处理
- else往后遍历for
- 到了尾结点,顺便判断超没超8,树化或者直接插入。加入后e还是为null。break
- 没到尾结点判断key是否等,同则拿到e后break for,不同则往后遍历for binCount++
- if(e!=null),e为null代表是新插入的,跳过if;不为null代表是修改,修改并给调用者return旧值;
执行至此代表e是新插入的,++size判断是否需要resize
与JDK1.7区别:JDK1.7采用头插,1.8采用尾插
8 put():尾插
要点:
- 尾插
- 第一次插入才创建数组,第一次添加才创建链表
- 插入删除才
++modCount;,修改该值并不变
//JDK8
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);//第一个false为覆盖旧值
}
//JDK8
final V putVal(int hash, K key,V value, boolean onlyIfAbsent, // 如果是 true,那么只有在不存在该 key 时才会进行 put 操作boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;/*1)transient Node<K,V>[] table; 表示存储Map集合中元素的数组。2)(tab = table) == null 表示将table赋值给tab,然后判断tab是否等于null,空构造函数第一次执行到这肯定是null3)(n = tab.length) == 0 表示将数组的长度赋值给n,然后判断n是否等于0,n等于0由于if判断使用双或,满足一个即可,则执行代码 n = (tab = resize()).length; 进行数组初始化。并将初始化好的数组长度赋值给n.4)执行完n = (tab = resize()).length,数组tab每个空间都是null*/if ((tab = table) == null || (n = tab.length) == 0)//Node数组为空的话就resizen = (tab = resize()).length;/*1)i = (n - 1) & hash 表示计算数组的索引赋值给i,即确定元素存放在哪个桶(数组坐标)中2)p = tab[i = (n - 1) & hash]表示获取计算出的位置的数据赋值给节点p3) (p = tab[i = (n - 1) & hash]) == null 判断节点位置是否等于null,如果为null,则执行代码:tab[i] = newNode(hash, key, value, null);直接根据键值对创建新的节点放入该位置的桶中小结:如果当前桶没有哈希碰撞冲突,则直接把键值对插入空间位置*/ if ((p = tab[i = (n - 1) & hash]) == null)//该索引上没有Node//p为该位置"链表",也是一个Node结点//创建一个新的节点存入到桶中tab[i] = newNode(hash, key, value, null);//还不return,一会做些记录后再returnelse {// tab[i]!=null,表示这个位置已经有值了。下面基本都是在“位置上有值”的基础上进行操作的Node<K,V> e; K k;//【e标识要修改的那个结点】,先查出来那个结点(不存在就创建),最后再改/*比较桶中第一个元素(数组中的结点)的hash值和key是否相等1)p.hash == hash :p.hash表示原来存在数据的hash值,hash表示要添加数据的hash值,比较两个hash值是否相等。不等就直接跳过if2)(k = p.key) == key :p.key获取原来数据的key赋值给k,key表示要添加数据的key,比较两个key的地址值是否相等3)key != null && key.equals(k):能够执行到这里说明两个key的地址值不相等,那么先判断后添加的key是否等于null,如果不等于null再调用equals方法判断两个key的内容是否相等//把首节点与后面的for分离是为了拿到*/if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))){//k为该链表的key e = p;//将旧的元素整体对象赋值给e,用e来记录}else if (p instanceof TreeNode)// key不同;判断p是否为红黑树结点// 放入树中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 不是红黑树,说明是链表节点//不是首结点,往后遍历/*1)如果是链表的话需要遍历到最后节点然后插入2)采用循环遍历的方式,判断链表中是否有重复的key*/for (int binCount = 0; ; ++binCount) {// p是前结点if ((e = p.next) == null) {//说明到达该位置尾Node,没有重复key// 虽然new了,但是e还是指向的空p.next = newNode(hash, key, value, null);//传入Node的4个成员(hash,k,v,next)//这里没连接上p e,但连接上了结点,我们所想要的e就是上面new的if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //binCount为0时,e为第2个结点。所以bin为7时>=8-1,此时e为第9个>8开始变成红黑树。即是存在链表长度为8的链表的//转换为红黑树//传入tab与对应的hash,就可知道位置//treeifyBin()里不一定会把链表转成红黑树。如果长度小于64,会去调用resize。如果长度>=64,则会执行真正的红黑树变形treeifyBin(tab, hash);break;//到达了尾结点,结束for遍历"链表"}//endif key==p.key//下面即!=/*执行到这里说明(e = p.next)!=null,即还有元素可以遍历。继续判断链表中结点的key值与插入的元素的key值是否相等*/if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 有相等的key,跳出循环,但没更改值,一会再更改值/*要添加的元素和链表中的存在的元素的key相等了,则跳出for循环。不用再继续比较了直接执行下面的if语句去替换去 if (e != null) */break;/*说明新添加的元素和当前节点不相等,继续查找下一个节点。用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表*/p = e;//更新p为下一结点,for binCount++}//end for}//endif key等不等// 在这里更改值;而添加值不在这里操作,在后面++modCount// 在上面for里新建结点的时候,e还是为null;而原来有值更改值的时候,e是对应的那个Node。//如果是更改值,返回旧值,如果是添加值,去后面进行++modCountif (e != null) { // 前面说过了,当添加时,虽然已经new了结点,但是e还是为空// 记录e的旧的valueV oldValue = e.value;// onlyIfAbsent为true代表如果有旧值,并不覆盖旧值,直接返回旧值if (!onlyIfAbsent || // 可以覆盖旧值。onlyIfAbsent=false代表不是只有没值的时候才覆盖,换个说法就是可以覆盖oldValue == null)// 不可以覆盖旧值但是旧值为null//用新值替换旧值//e.value 表示旧值 value表示新值 e.value = value;// 访问后回调,空方法,可以自己实现afterNodeAccess(e);// 返回旧值 // 如果是设置了ifAbsent的话,返回旧值但是没有其他操作return oldValue;}}//endif tab[i]!=null// 能运行到这里,表示这次进行的是插入操作,而不是修改// map变更性操作计数器// 比如map结构化的变更 像内容增减或者rehash,这将直接导致外部map的并发迭代引起fail-fast问题,该值就是比较的基础++modCount;//添加记录次数+1//修改不计入数量//结构性修改次数// 判断实际大小是否大于threshold阈值,如果超过则扩容// size即map中包括k-v数量的多少// 当map中的内容大小已经触及到扩容阈值时,则需要扩容了// 注:我曾有很长一段时间以外只有数组原来对应位置元素为空的时候才size++,后来才发现是map中总个数。那不得不思考,为什么不直接用数组存Node呢?我想原因大概是因为碰撞不好处理?但仔细想想,原来hashMap的本意就是这样的,元素个数永远不能多于数组,否则数组存不下,但hash碰撞了不是存到下一个位置,因为下一个位置可能有值,而且查的时候不方便,所以直接用链表解决hash碰撞。if (++size > threshold)//第一次阈值为16,后面resize会操作。resize();//扩容或者//如果多线程的时候 会出现循环链表的情况,造成CPU升高,值错乱// 插入后回调//空函数afterNodeInsertion(evict);return null;
}
7 put():头插
要点:
- 头插
- 刚开始数组也是空的
- 可以插入key=null
//jdk7
public V put(K key, V value) {// 当插入第一个元素的时候,需要先初始化数组大小if (table == EMPTY_TABLE) {inflateTable(threshold);}// 如果 key 为 null,感兴趣的可以往里看,最终会将这个 entry 放到 table[0] 中if (key == null)return putForNullKey(value);// 1. 求 key 的 hash 值int hash = hash(key);// 2. 找到对应的数组下标int i = indexFor(hash, table.length);// 3. 遍历一下对应下标处的链表,看是否有重复的 key 已经存在,// 如果有,直接覆盖,put 方法返回旧值就结束了for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;// key存在,覆盖旧值if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;return oldValue;//不去修改modCount++;直接返回}}modCount++;//增删rehash时会修改// 4. 不存在重复的 key,将此 entry 添加到链表中addEntry(hash, key, value, i);return null;
}//原来没有这个key,需要添加
void addEntry(int hash, K key, V value, int bucketIndex) {// 如果当前 HashMap 大小(元素的个数)已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容if ((size >= threshold) && (null != table[bucketIndex])) {// 扩容resize(2 * table.length);// 扩容以后,重新计算 hash 值hash = (null != key) ? hash(key) : 0;// 重新计算扩容后的新的下标bucketIndex = indexFor(hash, table.length);}// 往下看createEntry(hash, key, value, bucketIndex);
}//1.7采用头插,对于链表,头插法快
void createEntry(int hash, K key, V value, int bucketIndex){//不管原来的数组对应的下标是否为 null ,都作为 Entry 的 BucketIndex 的 next值Entry<K,V> e = table[bucketIndex];//这个构造函数里有头部连接(头插)的过程table[bucketIndex] = new Entry<K,V>(hash, key, value, e);size++;
}
resize()扩容
扩容原理
1.什么时候才需要扩容
- 当前数组一个元素都没有的时候,初始长度为0,添加第一个元素后要改成16
- 当数组中的元素超过一定比例。当HashMap中的元素个数超过数组大小(数组长度)*loadFactor(负载因子)。loadFactor的默认值(DEFAULT_LOAD_FACTOR)是0.75。那么当HashMap中的元素个数超过16×0.75=12(这个值就是阈值或者边界值threshold值)的时候,就把数组的大小扩展为2×16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预知元素的个数能够有效的提高HashMap的性能。
- 当HashMap中的其中一个链表的对象个数如果达到了8个,此时如果数组长度没有达到64,那么HashMap会先用扩容解决,如果已经达到了64,那么这个链表会变成红黑树,节点类型由Node变成TreeNode类型。当然,如果映射关系被移除后,下次执行resize方法时判断树的节点个数低于6,也会再把树转换为链表。
2.HashMap的扩容是什么
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
HashMap在进行扩容时,使用的rehash方式非常巧妙,因为每次扩容都是翻倍,与原来的数组长度n计算的 (n-1)&hash的结果相比,只是多了一个bit位,所以节点要么就在原来的位置,要么就被分配到"原位置+旧容量"这个位置。那么多的这一位怎么判断是0还是1呢?:e.hash & oldCap原容量,然后判断等不等于0即可。等0即新位是0,不等0即新位是1。
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:
&(按位与运算):运算规则:相同的二进制数位上,都是1的时候,结果为1,否则为零。
![]()
n-1=15:0000 0000 0000 0000 0000 0000 000【0】 1111hash1: 1111 1111 1111 1111 0000 1111 000【0】 0101
hash2: 1111 1111 1111 1111 0000 1111 000【1】 0101(n-1)&hash
5 : 0000 0000 0000 0000 0000 0000 000【0】 0101
16 : 0000 0000 0000 0000 0000 0000 000【1】 0101n=16 : 0000 0000 0000 0000 0000 0000 000【1】 0000n & hash
5 : 0000 0000 0000 0000 0000 0000 000【0】 0000 ==0
16 : 0000 0000 0000 0000 0000 0000 000【1】 0000 !=0
因此元素在重新计算hash之后,因为n变为2倍,那么n-1的标记范围在高位多1bit(红色),因此新的index就会发生这样的变化:
![]()
说明:5是假设计算出来的原来的索引。这样就验证了上述所描述的:扩容之后所以节点要么就在原来的位置,要么就被分配到"原位置+旧容量"这个位置。
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就可以了,是0的话索引没变,是1的话索引变成“原索引+oldCap(原位置+旧容量)”。为1还是为0可以通过这个式子判断:(e.hash & oldCap) == 0,代表为0。可以看看下图为16扩充为32的resize示意图:
![]()
正是因为这样巧妙的rehash方式,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,在resize的过程中保证了rehash之后每个桶上的节点数一定小于等于原来桶上的节点数,保证了rehash之后不会出现更严重的hash冲突,均匀的把之前的冲突的节点分散到新的桶中了。
流程:
调用resize肯定是在求变,容量一定变化
- 拿到Node[] table,计算原来的数组长度oldCap
- if(oldCap>0),把阈值设置为
oldCap<<1 - else(oldCap==0),设置容量为16,设置阈值为12
- if (oldTab != null)
- for(oldCap),循环每个坐标位置
- if ((e = oldTab[j]) != null),先清空原坐标位置的链表,原来链表拿e保存。
- if如果只有一个结点,直接计算该结点新的坐标
- elif如果是树结点,变形
- else如果是链表不只一个结点,构造两个链表,while原来的链表把结点重新定位到两个链表上。最后把两个链表接到坐标上。
- if ((e = oldTab[j]) != null),先清空原坐标位置的链表,原来链表拿e保存。
- for(oldCap),循环每个坐标位置
resize-JDK8
要点:
- resize的时候是尾插的。
- 构造两个链表,一下转移过去(JDK7是挨个元素转移)
//jdk8
final Node<K,V>[] resize() {//得到当前数组Node<K,V>[] oldTab = table;//Node<K,V>[] table//原容量:如果当前数组等于null长度返回0,否则返回当前数组的长度int oldCap = (oldTab == null) ? 0 : oldTab.length;//当前阈值点 默认是12(16*0.75)int oldThr = threshold;//容量为0时,threshold//HashMap构造函数中有这么一句:this.threshold = tableSizeFor(initialCapacity);//即第一次扩容(包括0->16)前阈值==容量int newCap, newThr = 0;//新的容量和阈值//如果老的数组长度大于0,开始计算扩容后的大小if (oldCap > 0) {// 超过最大值就不再扩充了,就只好随你碰撞去吧if (oldCap >= MAXIMUM_CAPACITY) {//2^30//修改阈值为int的最大值threshold = Integer.MAX_VALUE;return oldTab;}/*没超过最大值,就扩充为原来的2倍1)(newCap = oldCap << 1) < MAXIMUM_CAPACITY 扩大到2倍之后容量要小于最大容量2)oldCap >= DEFAULT_INITIAL_CAPACITY 原数组长度大于等于数组初始化长度16*/else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)//阈值扩大一倍newThr = oldThr << 1; // double threshold}//老阈值点大于0 直接赋值else if (oldThr > 0) // oldCap==0,老阈值赋值给新的数组长度newCap = oldThr;else {// oldCap==0 && oldThr==0,直接使用默认值16与0.75newCap = DEFAULT_INITIAL_CAPACITY;//16newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//重新计算阈值16*0.75}// 计算新的resize最大上限if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//新的阈值 默认原来是12 乘以2之后变为24threshold = newThr;//创建新的哈希表@SuppressWarnings({"rawtypes","unchecked"})// newCap是新的数组长度--》32Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//创建空Node数组table = newTab;//判断旧数组是否等于空if (oldTab != null) {//原来有值则复制到新Node数组里// 把每个bucket都移动到新的buckets中//遍历旧的哈希表的每个桶,重新计算桶里元素的新位置for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {//原来的数据赋值为null 便于GC回收,原来的值在e中保存着oldTab[j] = null;// 如果数组当前位置只有一个元素if (e.next == null)//没有下一个引用,说明不是链表,当前桶上只有一个键值对,直接插入newTab[e.hash & (newCap - 1)] = e;//判断是否是红黑树else if (e instanceof TreeNode)//说明是红黑树来处理冲突的,则调用相关方法把树分开 // 利用的是红黑树的双线链表 // 里面可能还会有祛树化的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // 采用链表处理冲突Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;//通过上述讲解的原理来计算节点的新位置do {// 原索引//记录下个结点next = e.next;//这里来判断如果等于true e这个节点在resize之后不需要移动位置if ((e.hash & oldCap) == 0) {// hash最高位为0,放到小的索引位置if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;//更新尾节点} else {//hash最高位为1 // 原索引+oldCapif (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 原索引放到索引为j的bucket里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 原索引+oldCap放到索引为j+oldCap的bucket里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}
resize-JDK7
要点:
- 头插
- 每遍历一个就立刻转移到新数组
//jdk7
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {//扩容前的数组大小如果已经达到最大(2^30)了threshold = Integer.MAX_VALUE;//修改阈值为int的最大值(2^31-1),这样以后就不会扩容了return;}// 新Entry数组Entry[] newTable = new Entry[newCapacity];// 将原来数组中的值迁移到新的更大的数组中transfer(newTable, initHashSeedAsNeeded(newCapacity));table = newTable; //这句要放在transfer之后threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);//修改阈值
}
void transfer(Entry[] newTable, boolean rehash) {//JDK7//新table的容量int newCapacity = newTable.length;//遍历原tablefor (Entry<K,V> e : table) {while(null != e) {//保存下一次循环的 Entry<K,V>Entry<K,V> next = e.next;//分析线程不安全:这个位置线程暂停if (rehash) {//通过e的key值计算e的hash值e.hash = null == e.key ? 0 : hash(e.key);}//得到e在新table中的插入位置int i = indexFor(e.hash, newCapacity);//采用头插法将e插入i位置,最后得到的链表相对于原table正好是头尾相反的e.next = newTable[i];newTable[i] = e;e = next;//更新e}}
}
JDK7是一个一个resize转移过去,JDK8是先组成两个链表再贴上去
resize线程安全问题
为什么线程不安全:
JDK7中,对于一个旧链表
while(null != e) {//保存下一次循环的 Entry<K,V>Entry<K,V> next = e.next;//分析线程不安全:这个位置线程暂停if (rehash) {//通过e的key值计算e的hash值e.hash = null == e.key ? 0 : hash(e.key);}//得到e在新table中的插入位置int i = indexFor(e.hash, newCapacity);//采用头插法将e插入i位置,最后得到的链表相对于原table正好是头尾相反的e.next = newTable[i];newTable[i] = e;e = next;//更新e
}
流程:先把当前结点e的下一个结点保存起来,然后把当前结点保存到新索引处,然后更新下一结点为当前结点。
首先两个线程都有new,可能会生成2个数组。在这期间可能会丢元素。另外jdk7中这个过程多个线程操作会形成死循环。
刚开始:
线程1中的e指向key(0),next指向key(4),此时线程1挂起。(next是局部变量,每个线程都有自己的next和e。但那些key锁对象的结点是不变的,只有那些,因为他们在堆中,存的是地址引用)
while(null != e) {Entry<K,V> next = e.next;// 线程1在这里被挂起,线程1指向的e是下图的key0,next是下图的key4if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;
}
![]()
线程2已经执行完了,结果为:
![]()
线程1继续执行,回顾一下他暂停的地方
while(null != e) {Entry<K,V> next = e.next;// 线程1在这里被挂起,线程1指向的e是下图的key0,next是下图的key4if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;
}
因为他还没把key0放到新的位置,所以先放key0到新的table上,此时新table那个地方的第一个元素是key0
线程1然后再更新e为key4,next为key0,如下所示。开始挪动key4(现在key4在线程2的新数组上。但是因为使用的是对象的索引,所以next指向的key是还是唯一的key4。)
![]()
- 保存新的next=e.next。next为key0
- 把e即key4移动到新table上。新的table上第一个元素为key4
- 更新新e为最新一次的next。即e=next,e为key0
马上就要出问题了
- e为key0,
- 保存新的next=e.next=key4
- 把e即key0移动到新table上,此时还要利用头插法,让key0.next指向key4。
- next为key4,造成了死循环
![]()
总结版:HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
get()
8get()
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {// 数组元素相等if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;// 桶中不止一个节点if ((e = first.next) != null) {// 在树中getif (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);// 在链表中遍历getdo {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;//找到} while ((e = e.next) != null);}}return null;
}
7get()
public V get(Object key) {// 之前说过,key 为 null 的话,会被放到 table[0],所以只要遍历下 table[0] 处的链表就可以了if (key == null)return getForNullKey();// Entry<K,V> entry = getEntry(key);return null == entry ? null : entry.getValue();
}final Entry<K,V> getEntry(Object key) {if (size == 0) { return null; }int hash = (key == null) ? 0 : hash(key);// 确定数组下标,然后从头开始遍历链表,直到找到为止for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;
}
遍历map
Set<String> keys = map.keySet();
for (String key : keys) {System.out.print(key+" ");
}Collection<String> values = map.values();
for (String value : values) {System.out.print(value+" ");
}Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();
for (java.util.Map.Entry<String, String> entry : entrys) {System.out.println(entry.getKey() + "--" + entry.getValue());
}
remove
// JDK8
public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;
}final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {Node<K,V> node = null, e; K k; V v;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) //key等node = p;else if ((e = p.next) != null) {if (p instanceof TreeNode)node = ((TreeNode<K,V>)p).getTreeNode(hash, key);else {do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) { // 再次判断key等node = e;// 要删除的结点nodebreak;}p = e;// p为要删除结点前一个结点} while ((e = e.next) != null);}}// node为要删除的结点,p为要删除的前一个结点if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount;--size;afterNodeRemoval(node);return node;}}return null;
}
// 内部类HashIterator的remove
public final void remove() {Node<K,V> p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount;
}
红黑树
红黑树的知识阅读:https://blog.csdn.net/hancoder/article/details/107805459
树结点:TreeNode
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {//JDK8//static class Entry<K,V> extends HashMap.Node<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletion //双向链表// 后指针在Node<K,V>类中:Node<K,V> next;boolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}...();//其他方法
}
// 因为继承了LinkedHashMap.Entry<K,V> ,所以有next指针
treeifyBin()单向链表转双向链表
功能:将链表转换为红黑树
从哪里调用的这个函数:putVal()里判断添加节点后链表节点个数是否大于TREEIFY_THRESHOLD临界值8,如果大于则将链表转换为红黑树,调用 treeifyBin()。但是在它里面也不一定执行红黑树化,如果数组长度小于64,是进行resize的,而不是红黑树化。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//转换为红黑树 tab表示数组名 hash表示哈希值treeifyBin(tab, hash);
treeifyBin方法如下所示:
首先根据原来Node结点的顺序转成一个双向链表,即增加一个pre指针,然后再根据这个双向链表从上到下依次插入到一颗红黑树中,转成一棵树
/*** Replaces all linked nodes in bin at index for given hash unless* table is too small, in which case resizes instead.替换指定哈希表的索引处桶中的所有链接节点,除非表太小,否则将修改大小。Node<K,V>[] tab = tab 数组名int hash = hash表示哈希值*/
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 如果小于 64只会进行扩容;长度大于64才会树化if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();//只是扩容tab[]else if ((e = tab[index = (n - 1) & hash]) != null) {/*1)执行到这里说明哈希表中的数组长度大于阈值64,开始进行树形化2)e = tab[index = (n - 1) & hash]表示将数组中的元素取出赋值给e*/// 先把原来的单向链表转成双向链表,但值得注意的是,这个双向链表的每个结点也是树节点,因为TreeNode有4个属性parent、left、right、prev另外有一个next属性在他的父类Entry的父类Node中// hd:红黑树的头结点head tl :红黑树的尾结点tailTreeNode<K,V> hd = null, tl = null;do {//把链表的当前结点转成一个树结点。//TreeNode<K,V> p = replacementTreeNode(e, null);//如何转成红黑树:首先根据原来Node结点的顺序转成一个双向链表,即增加一个pre指针,然后再根据这个双向链表从上到下依次插入到一颗红黑树中,转成一棵树// return new TreeNode<>(p.hash, p.key, p.value, next);if (tl == null)//将新创键的p节点赋值给红黑树链表的头结点 //注意这里只是链表,一会我们再根据链表树化,但这里的链表的结点已经变成树结点了hd = p;else {//不为头结点,先尾插法连接成链表,一会再树化 //链表的顺序没有变,原来在前面的还在前面p.prev = tl;tl.next = p;}tl = p;//更新tail} while ((e = e.next) != null);//更新结点 且 判断是否继续查找/*让桶中的第一个元素即数组中的元素指向新建的红黑树的节点,以后这个桶里的元素就是红黑树而不是链表数据结构了*/if ((tab[index] = hd) != null)hd.treeify(tab); //在这里把双线链表转成红黑树}
}
treeify()双向链表转成红黑树
final void treeify(Node<K,V>[] tab) {//head调用的//但没有传入什么,我们已经把head放到对应位置了,TreeNode<K,V> root = null;for (TreeNode<K,V> x = this, next; x != null; x = next) { // 把x设置为当前要插入的结点next = (TreeNode<K,V>)x.next; // 保存原顺序链表的下一节点x.left = x.right = null;if (root == null) {//第一个结点直接作为红黑树根节点x.parent = null;x.red = false;root = x;}else { // 不是根节点K k = x.key;int h = x.hash;Class<?> kc = null;//key的class类型for (TreeNode<K,V> p = root;;) {// 遍历现有红黑树,二分法查找该插入的位置int dir, ph;K pk = p.key;//p是红黑树里的当前结点,x是我们要插入的结点//要插入得先比较,但先比较的是哈希值,if ((ph = p.hash) > h)//如果红黑树里当前结点p的哈希值大于要插入的结点x哈希值dir = -1;//往左子树查 directionelse if (ph < h)//p的哈希值小于x的哈希值dir = 1;//往右子树查//等于else if ((kc == null && (kc = comparableClassFor(k)) == null) || //如果kc为空就先赋值kc//如果该key实现了Comparable<C>可进行比较,就返回Class对象。没实现就返回null //这里应该这是插入根节点的时候或的前半部分才为true,从第二个开始或语句的前半句就不满足了,直接执行或的后半句(dir = compareComparables(kc, k, pk)) == 0)//前面只是比较哈希值,哈希值相对未必就key相等,所以进一步比较p的key和x的key,并且把结果给dir//如果上面的dir==0满足,就进行插入,否则继续进行再查找dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;//待插入节点的父节点// 根据左右值连接if ((p = (dir <= 0) ? p.left : p.right) == null) {//看向左还是向右查找,更新红黑树的当前结点 //如果进入if,代表没有x对应的这个key值,要进行插入了x.parent = xp;// 设置父节点if (dir <= 0)xp.left = x;elsexp.right = x;//先连接上,再调整//当前结点插入到红黑树中root = balanceInsertion(root, x); // 把root节点更新,然后让root节点作为新节点去插入到上层!!!break;// 跳出for}}}}moveRootToFront(tab, root);//把根节点赋值给HashMap的table[i]//树结点同时也是以链表形式存在的//红黑树生成的过程中只是改变了left和right,而原来的next和prev还在,所以还是可以拿双线链表查出来原来后红黑树前的顺序的。我们的结点同时是链表里的一个结点,同时也是红黑树里的一个节点。//但这里还是做了一些变化的,他让红黑树里根节点那个结点移动到了双向链表的头部,即单独单出来放到头部,其他结点再双向链表中的相对顺序不变,包括因拿出来根节点断掉的那个地方,也自动粘合拼接了。
}
balanceInsertion()红黑树插入代码
下面的局面要结合红黑树里的5个局面
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {x.red = true;//插入的结点直接给红色for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {//为什么要for:因为调整完子树后可能导致上面的红黑树失衡,需要向上调整// 变量解释:p:parent// xp:父节点// xpp:祖父// xppl:左面的叔结点(指的是xpp的left左结点,而不是xpp左面的兄弟结点)// xppr:右面的叔结点if ((xp = x.parent) == null) {//局面1:作为根节点x.red = false;//根节点为黑色return x;}else if (!xp.red || (xpp = xp.parent) == null)//局面2:父是黑//或指的是原来只有一个黑结点,没有第2个结点了return root;// 走到这里代表父节点是红色的if (xp == (xppl = xpp.left)) { //父节点是祖父结点的左结点if ((xppr = xpp.right) != null && xppr.red) {//局面3:3红xppr.red = false;//叔变黑xp.red = false; // 父变黑xpp.red = true; // 祖父变红x = xpp;// 更新x为祖父节点}else {//叔结点为空和叔结点为黑都会走到这里if (x == xp.right) {//2红右左//局面4root = rotateLeft(root, x = xp);//先左旋 // 更新x为父节点 // 输入是父节点,但我们可以看认为是插入节点为轴xpp = (xp = x.parent) == null ? null : xp.parent; }//局面4还没处理完,转成局面5了,扔给局面5处理if (xp != null) {//2红左左//局面5xp.red = false;if (xpp != null) {xpp.red = true;root = rotateRight(root, xpp);//右旋 // 输入祖父节点,但我们可以认为是父节点为轴}}}}else { //父节点是祖父结点的右结点if (xppl != null && xppl.red) { //局面3:3红xppl.red = false;xp.red = false;xpp.red = true;x = xpp;}else {//叔结点为空和叔结点为黑都会走到这里if (x == xp.left) { //2红左右 //局面4的镜像root = rotateRight(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}//局面4(的镜像)还没处理完,转成局面5(的镜像)了,扔给局面5(的镜像)处理if (xp != null) {//2红右右//局面5的镜像xp.red = false;if (xpp != null) {xpp.red = true;root = rotateLeft(root, xpp);}}}}// 继续去向上调整}
}
生成红黑树后,原来的双向链表并没有变,我们还是可以用双向链表查到原来的顺序。
红黑树删除代码
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,TreeNode<K,V> x) {for (TreeNode<K,V> xp, xpl, xpr;;) {if (x == null || x == root)return root;else if ((xp = x.parent) == null) {x.red = false;return x;}else if (x.red) {x.red = false;return root;}else if ((xpl = xp.left) == x) {if ((xpr = xp.right) != null && xpr.red) {xpr.red = false;xp.red = true;root = rotateLeft(root, xp);xpr = (xp = x.parent) == null ? null : xp.right;}if (xpr == null)x = xp;else {TreeNode<K,V> sl = xpr.left, sr = xpr.right;if ((sr == null || !sr.red) &&(sl == null || !sl.red)) {xpr.red = true;x = xp;}else {if (sr == null || !sr.red) {if (sl != null)sl.red = false;xpr.red = true;root = rotateRight(root, xpr);xpr = (xp = x.parent) == null ?null : xp.right;}if (xpr != null) {xpr.red = (xp == null) ? false : xp.red;if ((sr = xpr.right) != null)sr.red = false;}if (xp != null) {xp.red = false;root = rotateLeft(root, xp);}x = root;}}}else { // symmetricif (xpl != null && xpl.red) {xpl.red = false;xp.red = true;root = rotateRight(root, xp);xpl = (xp = x.parent) == null ? null : xp.left;}if (xpl == null)x = xp;else {TreeNode<K,V> sl = xpl.left, sr = xpl.right;if ((sl == null || !sl.red) &&(sr == null || !sr.red)) {xpl.red = true;x = xp;}else {if (sl == null || !sl.red) {if (sr != null)sr.red = false;xpl.red = true;root = rotateLeft(root, xpl);xpl = (xp = x.parent) == null ?null : xp.left;}if (xpl != null) {xpl.red = (xp == null) ? false : xp.red;if ((sl = xpl.left) != null)sl.red = false;}if (xp != null) {xp.red = false;root = rotateRight(root, xp);}x = root;}}}}
}
红黑树扩容
扩容时,红黑树调用了split
else if (e instanceof TreeNode)//说明是红黑树来处理冲突的,则调用相关方法把树分开 // 利用的是红黑树的双线链表 // 里面可能还会有祛树化的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
1.5 其他开发问题
容量问题
建议:如果我们确切的知道我们有多少键值对需要存储,那么我们在初始化HashMap的时候就应该指定它的容量,以防止HashMap自动扩容,影响使用效率。
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(3->4、7->8、9->16) .这点我们在上述已经进行过讲解。
《阿里巴巴java开发手册》中建议我们设置HashMap的初始化容量。
10.【推荐】 集合初始化时,指定集合初始值大小。说明:HashMap使用HashMap(int initialCapacacity)初始化
那么,为什么要这么建议?你有想过没有。
当然,以上建议也是有理论支撑的。我们上面介绍过,HashMap的扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。在HashMap中,threshold = loadFactor * capacity。
所以,如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会有可能发生多次扩容,而HashMap中的扩容机制决定了每次扩容都需要重建hash表,是非常影响性能的。
容量多少合适?
在《阿里巴巴java开发手册》有以下建议:
正例:initialCapacity=(需要存储的元素个数/负载因子)+1。注意负载因子(即loader factor)默认为0.75
也就是说,如果我们设置的默认值是7,经过Jdk处理之后,会被设置成8,但是,这个HashMap在元素个数达到 8*0.75 = 6的时候就会进行一次扩容,这明显是我们不希望见到的。我们应该尽量减少扩容。原因也已经分析过。
如果我们通过initialCapacity/ 0.75F + 1.0F计算,7/0.75 + 1 = 10 ,10经过Jdk处理之后,会被设置成16,这就大大的减少了扩容的几率。
当HashMap内部维护的哈希表的容量达到75%时(默认情况下),会触发rehash,而rehash的过程是比较耗费时间的。所以初始化容量要设置成initialCapacity/0.75 + 1的话,可以有效的减少冲突也可以减小误差。
所以,我可以认为,当我们明确知道HashMap中元素的个数的时候,把默认容量设置成initialCapacity/ 0.75F + 1.0F是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
我们想要在代码中创建一个HashMap的时候,如果我们已知这个Map中即将存放的元素个数,给HashMap设置初始容量可以在一定程度上提升效率。
但是,JDK并不会直接拿用户传进来的数字当做默认容量,而是会进行一番运算,最终得到一个2的幂。原因也已经分析过。
但是,为了最大程度的避免扩容带来的性能消耗,我们建议可以把默认容量的数字设置成initialCapacity/ 0.75F + 1.0F。
二 HashMap补充知识点
2.1 快速失败fail-fast
https://blog.csdn.net/zymx14/article/details/78394464
简介:fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。例如:当某一个线程A通过 iterator 去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛 ConcurrentModificationException 异常,产生 fail-fast 事件
当然,不仅是多个线程,单个线程也会出现 fail-fast 机制,包括 ArrayList、HashMap 无论在单线程和多线程状态下,都会出现 fail-fast 机制,即上面提到的异常
先记住一句话:
刚开始得到迭代器时候会同步一下modCount 和expectedModCount ,每当next会先校验modCount 和expectedModCount 是否相等,而list.remove会修改modCount
①单线程fail-fast
1.1ArrayList发生fail-fast例子
public class ArrayListTest {public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(11);Iterator<Integer> iterator = arrayList.iterator();while (iterator.hasNext()) {Integer next = iterator.next();if (next == 11) {arrayList.remove(next);// list的remove方法,不是iterator的remove方法,不能这么用}}}
}
/*
10
11
Exception in thread "main" java.util.ConcurrentModificationExceptionat java.util.ArrayList$Itr.checkForComodification(ArrayList.java:859)at java.util.ArrayList$Itr.next(ArrayList.java:831)at edu.just.failfast.ArrayListTest.main(ArrayListTest.java:15)
*/
从结果看出,在单线程下,在使用迭代器进行遍历的情况下,如果调用 ArrayList 的 remove 方法,此时会报 ConcurrentModificationException 的错误,从而产生 fail-fast 机制
错误信息告诉我们,发生在 iterator.next() 这一行,继续点进去,定位到 checkForComodification() 这一行
public E next() {//iterator.next() checkForComodification();//这里会校验,报错在这int i = cursor;if (i >= size)throw new NoSuchElementException();Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length)throw new ConcurrentModificationException();cursor = i + 1;return (E) elementData[lastRet = i];
}
继续点进去,可以在 ArrayList 的 Itr 这个内部类中找到该方法的详细定义,这里涉及到两个变量,modCount 和 expectedModCount,
- modCount 是在 ArrayList 的父类 AbstractList 中进行定义的,初始值为 0,
- expectedModCount 则是在 ArrayList 的 内部类中进行定义的,
在执行 arrayList.iterator() 的时候,首先会实例化 Itr 这个内部类,在实例化的同时也会对 expectedModCount 进行初始化,将 modCount 的值赋给 expectedModCount
AbstractList源码
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {// modCount 初始值为 0//抽象类的成员变量protected transient int modCount = 0;
}//ArrayList+Iterator源码
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable{public Iterator<E> iterator() {//迭代器// 实例化内部类 Itrreturn new Itr();}/* An optimized version of AbstractList.Itr */private class Itr implements Iterator<E> {//即将遍历的元素的索引int cursor; // index of next element to return//刚刚遍历过的元素的索引。lastRet=cursor-1,默认为1,即不存在上一个时,为-1.int lastRet = -1; // index of last element returned; -1 if no such////迭代器记录的修改次数,一般线程不共享int expectedModCount = modCount;//初始赋值public boolean hasNext() {return cursor != size;}@SuppressWarnings("unchecked")public E next() {checkForComodification();//校验//即如果从得到iter到遍历完iter过程中如果list里的元素改变了就可能会报错(通过iter更改的不报错)int i = cursor;//当前要遍历的if (i >= size)throw new NoSuchElementException();Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length)throw new ConcurrentModificationException();cursor = i + 1;//下个要遍历的return (E) elementData[lastRet = i];//上个遍历的}public void remove() {if (lastRet < 0)//没有遍历过throw new IllegalStateException();checkForComodification();try {ArrayList.this.remove(lastRet);// 调用类的remove方法,里面有modCount++cursor = lastRet;lastRet = -1;expectedModCount = modCount;//这个是关键,只有iter的remove会更新两值} catch (IndexOutOfBoundsException ex) {throw new ConcurrentModificationException();}/*可以看到,该remove方法并不会修改modCount的值,并且不会对后面的遍历造成影响,**因为该方法remove不能指定元素,只能remove当前遍历过的那个元素**,所以调用该方法并不会发生fail-fast现象。该方法有局限性。*/}final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}}}
知道了这两个变量是从何而来之后,我们来看 checkForComodification() 这个方法,如果 modCount 和 expectedModCount 不等,就会抛出 ConcurrentModificationException 这个异常,换句话说,一般情况下,这两个变量是相等的,那么啥时候这两个变量会不等呢?
经过观察,发现 ArrayList 在增加、删除(根据对象删除集合元素)、清除等操作中,都有 modCount++ 这一步骤,即代表着,每次执行完相应的方法,modCount 这一变量就会加 1
public boolean add(E e) {//ArrayListensureCapacityInternal(size + 1); // 里面有modCount++elementData[size++] = e;return true;
}// 根据传入的对象来删除,而不是根据位置
public boolean remove(Object o) {//ArrayList if (o == null) {for (int index = 0; index < size; index++)if (elementData[index] == null) {fastRemove(index);return true;}} else {for (int index = 0; index < size; index++)if (o.equals(elementData[index])) {fastRemove(index); // 里面有modCount++return true;}}return false;
}private void fastRemove(int index) {modCount++;int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; // clear to let GC do its work
}public void clear() {//ArrayList modCount++;//++// clear to let GC do its workfor (int i = 0; i < size; i++)elementData[i] = null;size = 0;
}// 而set方法里没有modCount++;
public E set(int index, E element) {rangeCheck(index);E oldValue = elementData(index);elementData[index] = element;return oldValue;
}
分析到这儿,似乎有些明白了,我们来完整的分析一下整个过程,在没有执行删除操作之前,ArrayList 中的 modCount 变量和迭代器中的 expectedModCount 的值一直都是相同的。在迭代的过程中,调用了 ArrayList 的 remove(Object o) 方法,使得 ArrayList 的 modCount 这个变量发生变化(删除成功一次加1),一开始和 modCount 相等的 expectedModCount 是属于内部类的,它直到迭代结束都没能发生变化。在迭代器执行下一次迭代的时候,因为这两个变量不等,所以便会抛出 ConcurrentModificationException 异常,即产生了 fail-fast 异常。
要点:modCount 共享,expectedModCount 不共享
1.2HashMap发生fail-fast:
public class HashMapTest {public static void main(String[] args) {HashMap<Integer, String> hashMap = new HashMap<>();hashMap.put(1, "QQQ");hashMap.put(2, "JJJ");hashMap.put(3, "EEE");Set<Map.Entry<Integer, String>> entries = hashMap.entrySet();Iterator<Map.Entry<Integer, String>> iterator = entries.iterator();while (iterator.hasNext()) {Map.Entry<Integer, String> next = iterator.next();if (next.getKey() == 2) {hashMap.remove(next.getKey()); // 不能这么用}}System.out.println(hashMap);}
}
/*
Exception in thread "main" java.util.ConcurrentModificationExceptionat java.util.HashMap$HashIterator.nextEntry(HashMap.java:922)at java.util.HashMap$EntryIterator.next(HashMap.java:962)at java.util.HashMap$EntryIterator.next(HashMap.java:960)at edu.just.failfast.HashMapTest.main(HashMapTest.java:20)
*/
根据错误的提示,找到出错的位置,也是在 Map.Entry next = iterator.next() 这一行,继续寻找源头,定位到了 HashMap 中的内部类 EntryIterator 下的 next() 方法
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {public Map.Entry<K,V> next() {return nextEntry();}
}
继续往下找,来到了 HashMap 下的另一个私有内部类 HashIterator,该内部类也有 expectedModCount,modCount 是直接定义在 HashMap 中的,初始值为 0,expectedModCount 直接定义在 HashMap 的内部类中,当执行 arrayList.iterator() 这段代码的时候,便会初始化 HashIterator 这个内部类,同时调用构造函数 HashIterator(),将 modCount 的值赋给 expectedModCount
public class HashMap<K,V>extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable{// 初始值为 0transient int modCount;// HashMap 的内部类 HashIteratorprivate abstract class HashIterator<E> implements Iterator<E> {Entry<K,V> next; // next entry to return// 期待改变的值,初始值为 0int expectedModCount; // For fast-failint index; // current slotEntry<K,V> current; // current entryHashIterator() {// expectedModCount 和 modCount 一样,初始值为 0expectedModCount = modCount;if (size > 0) { // advance to first entryEntry[] t = table;while (index < t.length && (next = t[index++]) == null);}}public final boolean hasNext() {return next != null;}final Entry<K,V> nextEntry() {if (modCount != expectedModCount)throw new ConcurrentModificationException();Entry<K,V> e = next;if (e == null)throw new NoSuchElementException();if ((next = e.next) == null) {Entry[] t = table;while (index < t.length && (next = t[index++]) == null);}current = e;return e;}...}
}
来看抛出异常的 nextEntry() 这个方法,只要 modCount 和 expectedModCount 不等,便会抛出 ConcurrentModificationException 这个异常,即产生 fast-fail 错误
同样,我们看一下 modCount 这个变量在 HashMap 的哪些方法中使用到了,和 ArrayList 类似,也是在添加、删除和清空等方法中,对 modCount 这个变量进行了加 1 操作
// 成员方法
public V put(K key, V value) {if (table == EMPTY_TABLE) {inflateTable(threshold);}if (key == null)return putForNullKey(value);int hash = hash(key);int i = indexFor(hash, table.length);for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}// 将 modCount 加 1modCount++;addEntry(hash, key, value, i);return null;
}public V remove(Object key) {Entry<K,V> e = removeEntryForKey(key);//该方法里面,如果删除成功,则将 modCount++return (e == null ? null : e.value);
}public void clear() {// 将 modCount 加 1modCount++;Arrays.fill(table, null);size = 0;
}
我们来捋一下整个过程,在对 HashMap 和 Iterator 进行初始化之后,没有执行 remove 方法之前,HashMap 中的 modCount 和内部类 HashIterator 中的 expectedModCount 一直是相同的。在 HashMap 调用 remove(Object key) 方法时,如果删除成功,则会将 modCount 这个变量加 1,而 expectedModCount 是在内部类中的,一直没有发生变化,当进行到下一次迭代的时候(执行 next 方法),因为 modCount 和 expectedModCount 不同,所以抛出 ConcurrentModificationException 这个异常
在 HashMap 添加了三个键不同的元素,且 Iterator 完成初始化之后,modCount 和 expectedModCount 的值都为 3,直到 HashMap 执行 remove(Object key) 方法,modCount 加 1 变成 4,而 expectedModCount 依然为 3,在下一次循环执行 next() 方法的时候,会检查这两个值,如果不同,则会抛出 ConcurrentModificationException 异常,即产生 fail-fast 机制
②多线程failt-fast
2.1ArrayList
public class ArrayListThreadTest {public static void main(String[] args) throws InterruptedException {final ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.add(5);Thread thread = new Thread("线程1") {@Overridepublic void run() {Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {Integer next = iterator.next();try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程1: " + next);}}};Thread thread1 = new Thread("线程2") {@Overridepublic void run() {Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {Integer next = iterator.next();if (next == 2) {iterator.remove();}System.out.println("线程2: " + next);}}};thread.start();thread1.start();}
}
/*
线程2: 1
线程2: 2
线程2: 3
线程2: 4
线程2: 5
线程1: 1
Exception in thread "线程1" java.util.ConcurrentModificationExceptionat java.util.ArrayList$Itr.checkForComodification(ArrayList.java:859)at java.util.ArrayList$Itr.next(ArrayList.java:831)at edu.just.failfast.ArrayListThreadTest$1.run(ArrayListThreadTest.java:21)*/
同样,在 next 处,抛出了 ConcurrentModificationException 这个异常。
这里和单线程中不同的是,在删除的时候,调用的是 Iterator 对象的 remove() 方法,这是个内部类 Itr 中的方法。该内部类下的 remove 方法,其实还是调用 ArrayList 下的 remove(int index) 方法,但是,删除完之后,会将修改后的 modCount 赋值给 expectedModCount,相当于将这两个变量进行同步了
// ArrayList 中的内部类 Itr
private class Itr implements Iterator<E> {int cursor; // index of next element to returnint lastRet = -1; // index of last element returned; -1 if no suchint expectedModCount = modCount;public boolean hasNext() {return cursor != size;}public void remove() {if (lastRet < 0)throw new IllegalStateException();checkForComodification();try {ArrayList.this.remove(lastRet);cursor = lastRet;lastRet = -1;// 将 modCount 赋给 expectedModCountexpectedModCount = modCount;} catch (IndexOutOfBoundsException ex) {throw new ConcurrentModificationException();}}final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}
}
那么既然已经同步了,为什么还是会抛出这样的异常呢?通过输出的结果,大概可以分析出两个线程执行的流程
线程1先获得处理器的资源,进入运行状态,即执行 run() 方法里的代码,执行完 Iterator iterator = list.iterator() 这段代码之后,线程1因为执行了 sleep 方法,线程1进入阻塞状态
线程2获取处理器的资源,开始执行 run() 方法里面的代码,当迭代到 key 等于 2 的时候,执行 iterator.remove(),同时,ArrayList 下的 modCount 加 1,同时线程2迭代器下的 expectedModCount 的值和 modCount 一样,需要注意的是,modCount 是个共享的变量,即两个线程都可以同时对其进行操作,而 expectedModCount 则是各个线程各自拥有的,这一点很重要。最终,线程1下的 modCount 和 expectedModCount 都变成了 6
当线程2执行完毕,线程1重新获得处理器资源,开始执行,第一次循环没问题,第二次循环时,当执行到 Integer next = iterator.next() 的时候,因为共享变量 modCount 已经变成了 6,而线程 1 的 expectedModCount 依然是 5,两个变量不等,此时抛出 ConcurrentModificationException 异常,即产生 fail-fast 机制
简单的说,因为 modCount 是共享变量,expectedModCount 则是各自独有的变量,这就导致了,一个线程更新了 modCount,同时更新了自己拥有的 expectedModCount,当另一个线程执行的时候,发现 modCount 更新了,但是自己的 expectedModCount 并没有更新,便会产生这样的错误
2.2HashMap
public class HashMapThreadTest {public static void main(String[] args) {final HashMap<Integer, String> hashMap = new HashMap<>();hashMap.put(1, "AAA");hashMap.put(2, "BBB");Thread thread = new Thread("线程1") {@Overridepublic void run() {Iterator<Map.Entry<Integer, String>> iterator = hashMap.entrySet().iterator();while (iterator.hasNext()) {Map.Entry<Integer, String> next = iterator.next();try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程1: " + next);}}};Thread thread1 = new Thread() {@Overridepublic void run() {Iterator<Map.Entry<Integer, String>> iterator = hashMap.entrySet().iterator();while (iterator.hasNext()) {Map.Entry<Integer, String> next = iterator.next();if (next.getKey() == 2) {hashMap.remove(next.getKey());}System.out.println("线程2: " + next);}}};thread.start();thread1.start();}}
/*
线程2: 1=AAA
线程2: 2=BBB
线程1: 1=AAA
Exception in thread "Thread-0" java.util.ConcurrentModificationExceptionat java.util.HashMap$HashIterator.nextEntry(HashMap.java:922)at java.util.HashMap$EntryIterator.next(HashMap.java:962)at java.util.HashMap$EntryIterator.next(HashMap.java:960)at edu.just.failfast.HashMapThreadTest$1.run(HashMapThreadTest.java:19)*/
HashMap 的过程和上面的 ArrayList 类似,因为 modCount 是共享变量,expectedModCount 是每个线程独有的变量,线程2的 HashMap 执行了 remove(),导致 modCount 和expectedModCount 同时加 1,而线程1的 expectedModCount 变量的值并没有修改,导致了 modCount 和 expectedModCount 这两个变量的值不同,因此抛出异常
③避免fail-fast
3.1对于单线程
对应单线程来说,我们执行删除操作的时候,不要使用集合自身的删除方法,而使用集合中迭代器的删除方法
因为无论是 ArrayList 还是 HashMap,他们对应的迭代器中的 remove 方法中,都有这么一句代码,expectedModCount = modCount,这就意味着,即使删除了,这两个变量也是一直同步的,不会发生 modCount 加 1,而 expectedModCount 不变的情况
3.2对于多线程
使用java并发包JUC(java.util.concurrent)中的类来代替ArrayList 和hashMap。
如使用 CopyOnWriterArrayList代替ArrayList,CopyOnWriterArrayList在是使用上跟ArrayList几乎一样,CopyOnWriter是写时复制的容器(COW),在读写时是线程安全的。该容器在对add和remove等操作时,并不是在原数组上进行修改,而是将原数组拷贝一份,在新数组上进行修改,待完成后,才将指向旧数组的引用指向新数组,所以对于CopyOnWriterArrayList在迭代过程并不会发生fail-fast现象。但 CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
对于HashMap,可以使用ConcurrentHashMap,ConcurrentHashMap采用了锁机制,是线程安全的。在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据 ,iterator完成后再将头指针替换为新的数据 ,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。即迭代不会发生fail-fast,但不保证获取的是最新的数据。
参考链接:
http://www.jb51.net/article/84468.htm
http://www.cnblogs.com/ccgjava/p/6347425.html
https://blog.csdn.net/babycan5/article/details/89004482
我们可以发现在put方法中modCount的增加有一个前提,就是只有在key不存在的情况下才会进行自增操作,在进行覆盖时并不会出现自增。也就是说,如果是覆盖HashMap中原有的key的话并不会触发ConcurrentModificationException。例如下面所示代码,在遍历中对Map进行了修改 但是并无异常抛出。
仔细分析不难发现唯一的区别在于key的覆盖并没有更改Map的结构。无论此key的存储方式是链表还是树,key的覆盖都只是简单的替换。遍历下去都可以正常的获取到所有值。但是涉及到Map结构修改的操作都有可能导致遍历无法遍历到所有值,因此才会触发ConcurrentModificationException。
线程不安全问题
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在 JDK1.7 的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配 16 个 Segment,比 Hashtable 效率提高 16 倍。) 到了 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁):使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
两者的对比图:
图片来源:http://www.cnblogs.com/chengxiao/p/6842045.html
Hashtable:
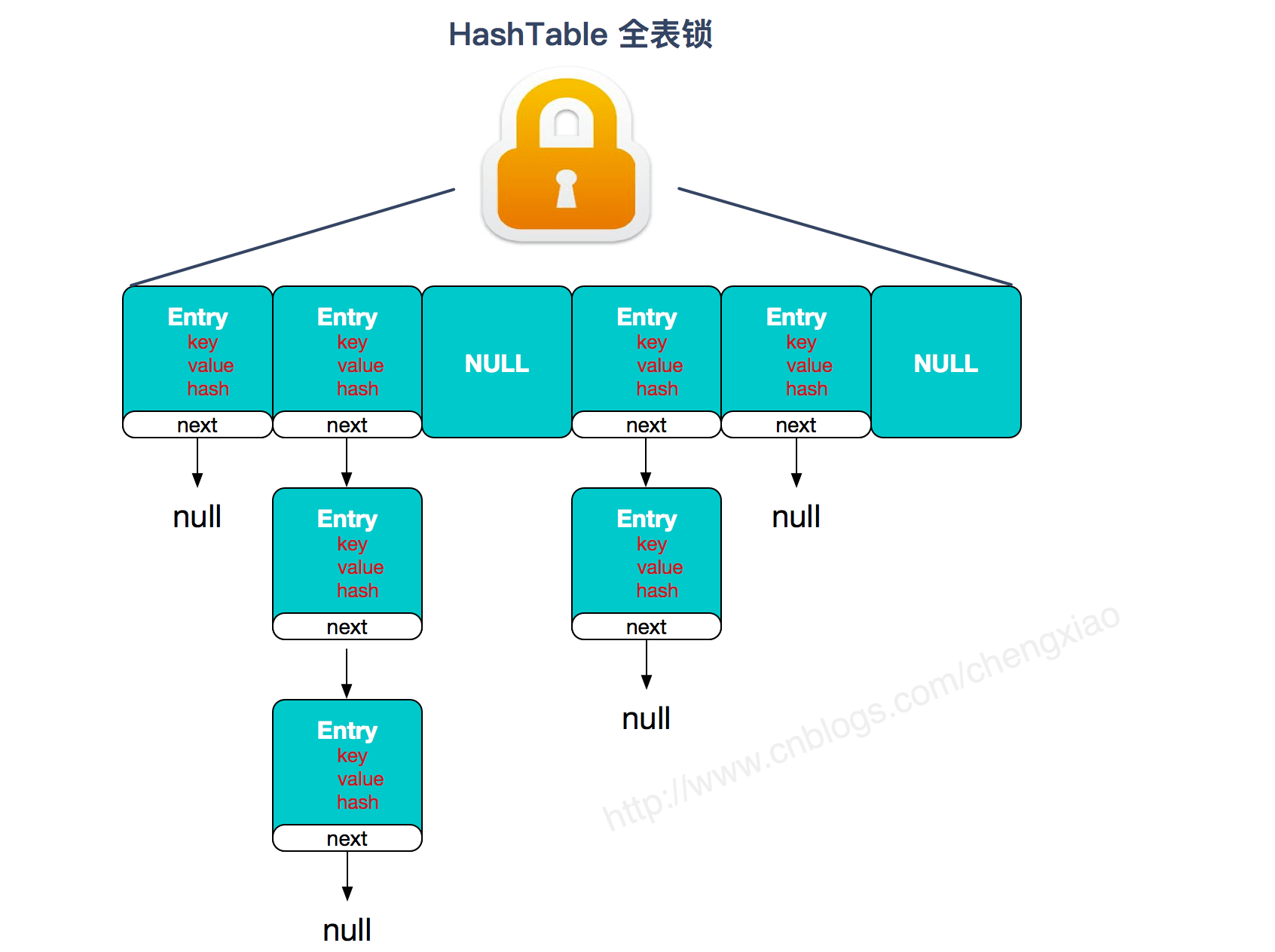
JDK1.7 的 ConcurrentHashMap:
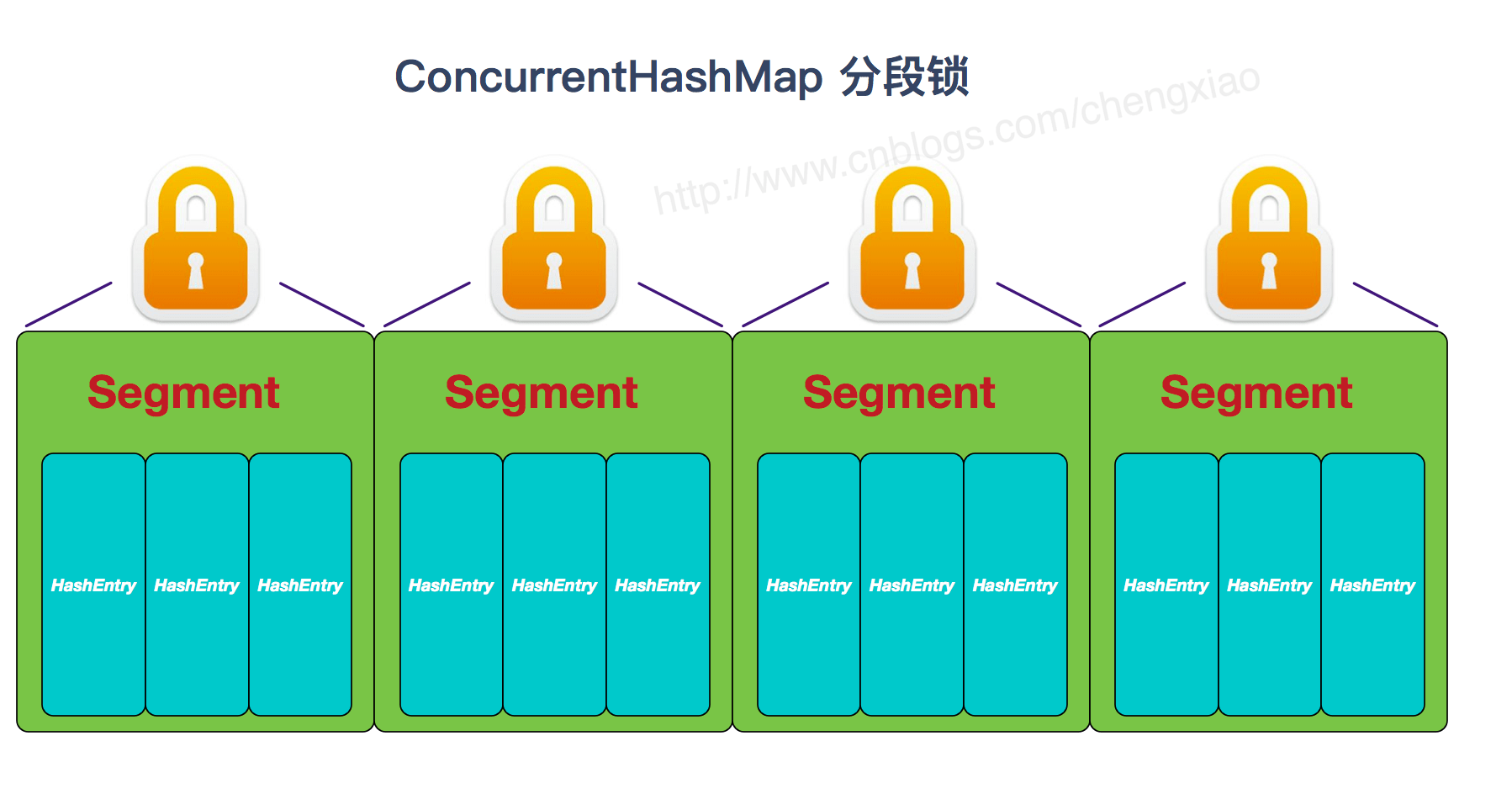
JDK1.8 的 ConcurrentHashMap(TreeBin: 红黑二叉树节点、Node: 链表节点):
![]()
Unsafe
阅读:https://blog.csdn.net/hancoder/article/details/107805260
红黑树
阅读:https://blog.csdn.net/hancoder/article/details/107805459
transient
看HashMap源码的时候,看到如下定义
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
transient关键字的作用:被transient修饰的属性,在序列化时,将不会被序列化。
为什么HashMap中要用transient修饰呢?
1、因为 HashMap 中的存储数据的数组数据成员中,数组还有很多的空间没有被使用,没有被使用到的空间被序列化没有意义。所以需要手动使用 writeObject() 方法,只序列化实际存储元素的数组。
2、在Effective Java 3nd, Item87中有提到
hashmap的底层是散列表,key的索引需要通过hashCode()方法计算,但是不同的JVM中可能会有不同的hashCode()实现,所以持久化或者网络传输了也不一定能继续使用(hashcode都乱了,索引也就乱了)
这对我们有什么借鉴意义?
在我练习的项目中,远程调用(网络传输)中需要定义一个公共类进行接收各个类型的数据。此时我们有可能要传递多种类型,显然不能只使用一个类型来回转换,因为传输的是字节码你根本感受不到传来的类型(除非是有消息头)
HashMap实际上还是可以持久化的:
虽然他的table[]是transient的,但是HashMap实现了Cloneable接口,这代表它自己有把对象转成字节码的能力。
再看clone()方法之前,我们先说一句其实HashMap中还有一个属性
transient Set<Map.Entry<K,V>> entrySet;,虽然它也是transient 的,但是clone中如果把他进行序列化的其实跟transient 是无关的。但是我看了下put等方法,根本就没人管entrySet的值,只有clone的时候才涉及到了entrySet属性,那就是说,clone的时候要自己刷新entrySet,把table中的值放到entrySet中。
但我又看了半天,根本没有更新的操作啊,难道是在父类中有别的方法?又想了一下,不可能啊,父类的方法操作的还是父类的属性,不能操作子类的属性
@Override // HashMap的方法 public Object clone() {HashMap<K,V> result;try {// 调用了父类的克隆方法 // 我们打开它发现相当于只是调用了Object.clone()// 可以强转,父类转子类(为什么可以强转,我印象是因为JVM加载类的时候会先加载父类的方法,所以才能按索引取到方法,我猜属性也差不多,不具体研究了)result = (HashMap<K,V>)super.clone();} catch (CloneNotSupportedException e) {// 不可能发生的异常throw new InternalError(e);}result.reinitialize();// 关键步骤在这里面,是克隆了entrySetresult.putMapEntries(this, false);return result; }// AbstractMap protected Object clone() throws CloneNotSupportedException {// 又调用了Object.clone()是native的 // Object.clone()就是克隆了非transient 属性等信息而已AbstractMap<?,?> result = (AbstractMap<?,?>)super.clone();result.keySet = null;result.values = null;return result; }// HashMap final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();if (s > 0) {if (table == null) { // pre-sizefloat ft = ((float)s / loadFactor) + 1.0F;int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY);if (t > threshold)threshold = tableSizeFor(t);}else if (s > threshold)resize();for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value, false, // 有key的话不用更新,防止线程冲突有错乱的问题evict);// 没有结点时为false。插入一个结点后为true}} }public Set<Map.Entry<K,V>> entrySet() {Set<Map.Entry<K,V>> es;// 下面这句话意思是entrySet为null的话,new EntrySet(),否则把entrySet属性直接赋值esreturn (es = entrySet) == null ? (entrySet = new EntrySet()) : es; }
java中有一个类是TypeReference,它可以结合json工具包把json转成指定的类型,这样我们只需传递json即可
jsonObject.getObject(list,new)
public class R extends HashMap<String, Object> {private static final long serialVersionUID = 1L;/*** @param key 获取指定key的名字*/public <T> T getData(String key, TypeReference<T> typeReference){// get("data") 默认是map类型 所以再由map转成string再转jsonObject data = get(key);return JSON.parseObject(JSON.toJSONString(data), typeReference);}/*** 复杂类型转换 TypeReference*/public <T> T getData(TypeReference<T> typeReference){// get("data") 默认是map类型 所以再由map转成string再转jsonObject data = get("data");String s = JSON.toJSONString(data);return JSON.parseObject(s, typeReference);}public R setData(Object data){// 放入Objectput("data", data);return this;}public R() {put("code", 0);put("msg", "success");}public static R error() {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系FIRENAY");}public static R error(String msg) {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg);}public static R error(int code, String msg) {R r = new R();r.put("code", code);r.put("msg", msg);return r;}public static R ok(String msg) {R r = new R();r.put("msg", msg);return r;}public static R ok(Map<String, Object> map) {R r = new R();r.putAll(map);return r;}public static R ok() {return new R();}public R put(String key, Object value) {super.put(key, value);return this;}public Integer getCode() {return (Integer) this.get("code");}
}Map的深复制
此外我们再考虑一个map的拷贝问题
- = 肯定是不能用的
- putAll()方法,深拷贝
- clone,浅拷贝
- 用entrySet遍历,深拷贝
- 自定义clone深拷贝
三 ConcurrentHashMap
预习只是:HashTable线程安全的做法:
//直接在方法上加synchronized锁住this,这样效率很低
public synchronized V put(k key,V value){}//效率低//put不同索引的时候是没有线程安全的,但也是得等待
3.1 JDK1.7

首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment[] 数组结构和 HashEntry 数组结构组成。
Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {}
一个 ConcurrentHashMap 里包含一个 Segment[] 数组。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
3.1.1 属性:
Segments[] segments
- ConcurrentHashMap有个
Segment<K,V>[] segments;- 默认16 个 Segments,所以理论上,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。
- 这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。它也叫并发度
- 每个segment[i]维护一个
HashEntry<K,V>[] table
HashEntry[] table
每个ConcurrentHashMap下有一个Segments[]数组,数组的每一个元素Segments[i]下面有一个table[]数组,每个元素table[i]下有一个链表。因为java中只要一个对象有next指针,那么这个对象代码的也是一个链表。所以table[i]对应的是一个HashEntry元素,同时也是一个链表
3.1.2 构造
ConcurrentHashMap(无参)
public ConcurrentHashMap(){return this(//整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。 // DEFAULT_INITIAL_CAPACITY,// segment[].length×table[].length,每个table大小为segment[i]=DEFAULT_INITIAL_CAPACITY/DEFAULT_CONCURRENCY_LEVELDEFAULT_LOAD_FACTOR,// 负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。DEFAULT_CONCURRENCY_LEVEL)//16 //并发级别,segment[]数组长度//segments也是2的幂//
}
简单说下有几个参数:初始容量、加载因子、并发级别。初始容量是segment个数×每个segment的初始容量
ConcurrentHashMap(有参)
- 初始化了s[0],其他地方没有初始化
//JDK7
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)//1^16concurrencyLevel = MAX_SEGMENTS;//最大并发级别// Find power-of-two sizes best matching argumentsint sshift = 0;int ssize = 1;//sigments[] Size// 计算并行级别 ssize,因为要保持并行级别是 2 的 n 次方while (ssize < concurrencyLevel) {//如果并发级别输入的是15,那么我们就可以通过while转成16++sshift;//移位次数ssize <<= 1;}//用ssize表示并发级别,肯定为2的幂// 我们这里先不要那么烧脑,用默认值,concurrencyLevel 为 16,sshift 为 4// 那么计算出 segmentShift 为 28,segmentMask 为 15,后面会用到这两个值this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;//并发级别-1,掩码,即1111..用作位运算if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;//总共节点数//1^30// initialCapacity 是设置整个 map 初始的大小,// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小// 如 initialCapacity 为 64,那么每个 Segment 或称之为"槽"可以分到 64/16=4 个int c = initialCapacity / ssize;//c=segment[i]下链表长度if (c * ssize < initialCapacity)//上面有余数造成的++c;// 默认 MIN_SEGMENT_TABLE_CAPACITY 是 2,这个值也是有讲究的,因为这样的话,对于具体的槽上,// 插入一个元素不至于扩容,插入第二个的时候才会扩容// cap也是2的幂int cap = MIN_SEGMENT_TABLE_CAPACITY;//2链表长度至少2while (cap < c)cap <<= 1;//我们后面用的是cap,而不是c。即链表长度最少为2// 先创建segments[]数组和segments[0]Segment<K,V> s0 =new Segment<K,V>(loadFactor,(int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);//cap先只用于s0 //segment[0]Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];//创建Segments[]// 往数组写入 segment[0],后面就可以根据segment[0]的属性算一些值了,这样比较方便UNSAFE.putOrderedObject(ss, SBASE, s0); // 用unsafe类的cas操作:segments[0]=s0this.segments = ss;
}
扩容是扩segment[i],即tab[],不是扩segment[]。
除了segment[0],别的地方刚开始都是空的(懒加载)。要放的时候先new ,如果没有s0,那么每个地方都需要除一下,很麻烦,根据s0 就可以快速算出来。原型。
不够了rehash
//内部类
static final class Segment<K,V>extends ReentrantLock implements Serializable {- concurrrentLevel/segment size一定为2的幂
- cap/c至少为2,initialCapacity / ssize向上取整、再向上取幂。扩容扩的是这个,而不是扩容segment
- capacity:这个等式是不成立的capacity=cap×concurrrentLevel,因为他刚开始只创建ss[0]的table[],别的索引位置还是为null,而是扩容的时候只是扩容对应的table[],即各个table[]的不一样大小的。
7put
7Concurrent.put()
首先了解ConcurrentHashMap类中有如下的关于unsafe的逻辑,对Unsafe类一点不了解的同学去后面先了解下Unsafe:https://blog.csdn.net/hancoder/article/details/107805260
然后应该回顾下有参构造器里的几个参数
++sshift;//移位次数 // 和size是对应的,比如说并发度是16的话sshift是4,ssize是16
ssize <<= 1;this.segmentShift = 32 - sshift;//int32位,也就是size的1(包括)前面有多少位
this.segmentMask = ssize - 1;//并发级别-1,掩码,即00..1111..用作位运算
// Unsafe类相关知识点UNSAFE = sun.misc.Unsafe.getUnsafe();
Class tc = HashEntry[].class;//segment[i]
Class sc = Segment[].class;//concurrentHashMap.segments[]并发数组// base
TBASE = UNSAFE.arrayBaseOffset(tc);
SBASE = UNSAFE.arrayBaseOffset(sc);// 数组每个元素的偏移
ts = UNSAFE.arrayIndexScale(tc);
ss = UNSAFE.arrayIndexScale(sc);SSHIFT = 31 - Integer.numberOfLeadingZeros(ss);
TSHIFT = 31 - Integer.numberOfLeadingZeros(ts);
public V put(K key, V value) {Segment<K,V> s;// JDK7的CHashMap不支持null值if (value == null)throw new NullPointerException();int hash = hash(key);//获取key的hash值// j为segments[j]// 求完key的hash值后以前我们是用类似于取余的操作求得索引位置// 但是在chashmap中取余之前还有个移位的操作hash >>> segmentShift,即无符号右移20多位,得到前几位,位数与和原来hashmap取余位数一样,保留原来hash值的高位int j = (hash >>> segmentShift) & segmentMask;//先取前面的位,然后掩码前面的位。效果为取高位的掩码//segmentMask就是我们的segment.length-1// 刚刚说了,初始化的时候初始化了 segment[0],但是其他位置还是 null,// ensureSegment(j) 对 segment[j] 进行初始化//通过unsafe的getObject方法获取数组segment[]中某个位置的元素// 其实下面就是确保求得segments[j],各个参数去前面的unsafe博客中学习// 求得的segments[j]赋值给sif ((s = (Segment<K,V>)UNSAFE.getObject (segments, (j << SSHIFT) + SBASE)) == null) //如果当前索引位置为null,则创建一个segment对象 // nonvolatile; recheck// 创建数组放到segments[j]这个位置上s = ensureSegment(j);// segments[j].put()return s.put(key, hash, value, false);//调用segment的put方法
}//下面介绍一下为什么j << SSHIFT就是我们想要的 ss 乘 索引,==//而 SSHIFT=31-Integer.numberOfLeadingZeros(ss);//numberOfLeadingZeros二进制时ss前面有多少个0,SSHIFT表示ss表示的二进制的1后面有多少个0//我们不妨再转换回来,用i表示1后面有多少个
//验证:j<<31-Integer.numberOfLeadingZeros(ss) == ss×j
//ss为2的次幂,假设为2的i次幂,那么==左式就为j<<i,而==右式为2^i ×j,结合计算机组成原理知识,显然相等// 这个索引位置为null,这个函数用cas确保多个线程都使用的一个数组
private Segment<K,V> ensureSegment(int k) {//参数为segments[j]final Segment<K,V>[] ss = this.segments;long u = (k << SSHIFT) + SBASE; // u为数组的偏移量Segment<K,V> seg;// 如果执行完前面的代码还是为空的话,使用cas去new数组放到segments[j] // 可以懒汉模式if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {Segment<K,V> proto = ss[0]; // 使用segment[0]作为原型int cap = proto.table.length;//查看ss[0]所对应数组的长度float lf = proto.loadFactor;int threshold = (int)(cap * lf);// 创建和ss[0]所对应数组的长度相同的大小HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheckSegment<K,V> s = new Segment<K,V>(lf, threshold, tab);while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {// 用cas去设置数组if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))break;}}}return seg;
}
segment[]是我们的并发数组,HashEntry[] tablle是每个segment[i]下的数组
7Segment.put()
- Segment[]
- HashEntry[] = Segment[i]
- node=HashEntry[i],同时因为是链表的关系,头元素同时也可以代表一个链表
- put加锁,头插。scanAndLockForPut()尝试获取锁,没有马上获取到就遍历结点
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);最终都会获取到锁。在这个过程中可能会创建结点。
- 什么时候开始计数:只有找到或创建了结点后才计数(遍历到尾null时new Node但还没拼接,找到结点后面没什么用,新建结点才有用)
偶数次计数时看下头结点变没变,变了的话重新找到结点后计数
大于64次直接阻塞
在遍历期间别人可能删除、更改、添加节点,没关系,自己拿到锁后从头遍历一般,能遍历到就是修改操作而非新增操作了
// 内部类Segment //JDK7
static final class Segment<K,V> extends ReentrantLock implements Serializable {final V put(K key, int hash, V value, boolean onlyIfAbsent) {// 在往该 segment 写入前,需要先获取该 segment 的独占锁//tryLock()尝试加锁//与lock()的区别在于:tryLock()不阻塞,如果能获取到锁就取得锁返回true,如果获取不到就返回false// 尝试能否一下就获取到lock锁,拿不到锁就先做点别的事。// 但是最终这里都拿到了锁HashEntry<K,V> node = tryLock() ? null ://如果获取到锁就返回null给node,一会再创建结点scanAndLockForPut(key, hash, value);//没有获取到锁就调用scanAndLockForPut()方法 //while (!tryLock()) { 获取不到锁的时候就去做点别的事情,可能在等待的过程中创建了结点// ----下面的逻辑都是有锁的逻辑,但是未必获得了要创建的结点node------//执行到这里的时候,已经拿到锁了。scanAndLockForPut里也会最终拿到锁//如果是通过scanAndLockForPut得到的node,我们此时还顺便拿到了头结点V oldValue;//如果是修改,则返回旧值try {// 这个是 segment 内部的数组HashEntry<K,V>[] tab = table;// 再利用 hash 值,求应该放置的数组下标int index = (tab.length - 1) & hash;//和原来方法一样,取低位// first 是数组该位置处的链表的表头HashEntry<K,V> first = entryAt(tab, index);//用UNSAFE.getObjectVolatile方法获取tab[index]for (HashEntry<K,V> e = first;;) {if (e != null) {//如果tab[i]下有链表K k;if ((k = e.key) == key || //如果两个new String那么此时不是同一个引用地址(e.hash == hash && key.equals(k))) {//equals能判断key值的内置是否相等,而不是比较引用地址oldValue = e.value;//保存旧值if (!onlyIfAbsent) {//如果onlyIfAbsent==true,就代表map只能添加删除,不能修改e.value = value;++modCount;}break;}//更新e为table中的下一个e = e.next;}else {//当前tab[i]下没有链表。或者说遍历到链表了最后了还是没找到key对应的值,那么就new Node// 如果node!=null,代表第一时间没有获取到锁,在等锁的过程中做了点别的事情,想去利用时间如果遍历到末尾都没有对应的key,就new个结点。但是也可能虽然没有对应的key,但是其他拿到锁了,就先不创建结点先处理正经事了 // 即如果等锁过程中没创建node,那么node还是==nullif (node != null) // 在等锁的过程中已经创建了个node结点了node.setNext(first);//调用unsafe赋值给first // 头插法else // 还没创建node结点,先创建一个node,头插法连接原来的链表node = new HashEntry<K,V>(hash, key, value, first);//在这里同时赋值给firstint c = count + 1;//tab[]里元素到达阈值,扩容table[]if (c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);elsesetEntryAt(tab, index, node);//没有超过阈值直接赋值给tab[index]=node // 这个node是新头结点++modCount;count = c;oldValue = null;break;}}} finally {unlock();//解锁}return oldValue;}
7等锁中Segment.scanAndLockForPut()
先解读下tryLock再解读scanAndLockForPut。scanAndLockForPut是想在等锁的过程中先去做点别的事情,做一会就再试着拿锁,拿到了就出去,不管做没做完。
- 做事过程中一会问一下获取到锁没有,获取不到就继续干活,直到多次询问得到锁
- 干活的过程中,挨个看list的key是否相等
- 如果碰到相等的了retries = 0;
- 如果到最后都没有相等的,node = new HashEntry,然后retries = 0;
- 发现retries 为0之后就tryLock一次就++一次
- 偶数次tryLock的时候看一下头结点被其他线程改变没有,改变了就retries = -1,更新头结点重新遍历list
- 如果tryLock次数过多,直接阻塞等锁
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {HashEntry<K,V> first = entryForHash(this, hash);//取得table[i]对应的链表(头结点)HashEntry<K,V> e = first;//当前结点HashEntry<K,V> node = null;int retries = -1; // 初始值为负。negative while locating node // 值为0时代表new出来新节点或者找到该修改的结点了//如果获取不到锁就先去做点别的事情while (!tryLock()) {HashEntry<K,V> f; // to recheck first belowif (retries < 0) {//进入的几个条件://1 第一次时候进入//2 key不等时也进入//退出if条件://1 直到找到最后一个节点还没找打key,所以new了个新node//2 找到对应的key了if (e == null) {//table[i]上没有链表,或者该链表遍历到最后一个节点了还没有对应的key,就新建if (node == null) //new一个node// 进到这里说明数组该位置的链表是空的,没有任何元素// 当然,进到这里的另一个原因是 tryLock() 失败,所以该槽存在并发,不一定是该位置node = new HashEntry<K,V>(hash, key, value, null);// 这个地方没有拼接retries = 0;//改为0 // 改为0代表new出来新节点或者找到该修改的结点了 // 有新结点了,开始计数}else if (key.equals(e.key))//是否为当前节点retries = 0;//改为0 // 没有把当前结点e给node // 找到结点了,开始计数elsee = e.next;//更新为下一节点}//后面的操作的代码的前提:已经找到key对应的node了//重试次数大于64了,直接阻塞等锁吧else if (++retries > MAX_SCAN_RETRIES) {//++retries//细节:找到key对应的node时才开始累加lock();//阻塞获取锁//如果只有一个CPU的话最大值仅为1break;}// 找到结点或者创建else if ((retries & 1) == 0 && //偶数次 //拿到key对应的node之后的,偶数次重试时,判断table[i]对应的first有没有被其他线程改变 // 没被改变的话继续下一次让++retries,直到拿到锁或者让出cpu// 这个else if的思想是拿到/创建了对应key的结点后,下一次获取锁之前(f = entryForHash(this, hash)) != first) {//在while (!tryLock())的过程中,很可能其他进程已经改了该数组。//JDK7头插法新增//头结点发生了变化e = first = f; // re-traverse if entry changed//被其他线程改变了,重新给当前线程赋值其他线程改了的firstretries = -1;//如果头结点发生了变化,重新设置为-1//重新去获取node,万一node被别的线程删除了呢?//所以其实源码这里有点错误,应该把node再重置为null,否则还是会返回删除的结点}}//可能我们在等待锁的过程中已经找到key对应的node了。也可能还没找到对应的nodereturn node;
}//segment[s]下的取tab[i]
static final <K,V> HashEntry<K,V> entryForHash(Segment<K,V> seg, int h) {//h:hashHashEntry<K,V>[] tab;//先判断seg == null,否则seg未必有table属性return (seg == null || (tab = seg.table) == null) ? null :(HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);//如果seg不为空,就返回tab[i]
}
7扩容Segment.rehash()
解释:即resize(),只不过是resize的HashEntry[] table。在jdk7里没有resize这个函数
关键点:一次挪1-X个
- 重复一下,segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容,扩容后,容量为原来的 2 倍。
- 该方法不需要考虑并发,因为到这里的时候,是持有该 segment 的独占锁的。
- 转移的时候
- 首先一次转移多个【将来同索引的、连续的、链表倒数的】结点,所以顺序并非只是倒序了(比较奇怪)
private void rehash(HashEntry<K,V> node) {//resize table[]//即rehash是相当于我们HahsMap里的resize() //问题:如何保证resize时没有线程安全:resize操作是在put函数内的,而put获取了锁才调用resizeHashEntry<K,V>[] oldTable = table;int oldCapacity = oldTable.length;int newCapacity = oldCapacity << 1;//原长度×2threshold = (int)(newCapacity * loadFactor);//新建新的table[]HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];int sizeMask = newCapacity - 1;// 新容量的maskfor (int i = 0; i < oldCapacity ; i++) {//挨个索引位置进行元素转移HashEntry<K,V> e = oldTable[i];if (e != null) {HashEntry<K,V> next = e.next;// 记录链表上第二个entry// 链表上头结点的新索引int idx = e.hash & sizeMask;if (next == null) // 只有一个结点 Single node on listnewTable[idx] = e;else { // Reuse consecutive sequence at same slot// 记录相对首结点HashEntry<K,V> lastRun = e;//记录最后连续的元素的相对头结点// 记录最后连续元素相对首结点的索引 int lastIdx = idx;// 往下遍历 // 这个for里不改变结构,只是找到原链表中最后属于高索引位的最后的连续的HashEntryfor (HashEntry<K,V> last = next;last != null;last = last.next) {//一次转移多个【将来同索引的、连续的、链表倒数的】结点,所以顺序并非只是倒序了// 当前结点的新索引位置int k = last.hash & sizeMask;//计算是高索引还是低索引// 如果当前结点的新索引位置和上个结点不一样,if (k != lastIdx) {// 原来以为的链表最后几个相对首结点失效// 接下来更新最后元素的相对首结点信息lastIdx = k; // 更新为当前结点的另外一个索引位置lastRun = last;// 更新为当前结点}}/* 执行完for到这的时候,肯定是遍历完了这个链表,但是并没有改变链表的结构,只是拿到了链表最后的一些元素,这些元素将来新索引相同,即这些元素有可能只是一个,有可能多个*/// 先把链表最后的元素挪到新的位置newTable[lastIdx] = lastRun;// 把链表前面的元素移动到新的索引位置 for (HashEntry<K,V> p = e; // e还是头结点,还是从头结点开始遍历p != lastRun; // 排除刚才挪完的一个或一串元素p = p.next) {// 还是采用头插法V v = p.value;int h = p.hash;//当前结点的hashint k = h & sizeMask; //计算高索引位HashEntry<K,V> n = newTable[k];//新的地方的头结点newTable[k] = new HashEntry<K,V>(h, p.key, v, n);//hash,key,value,头结点}}}}// 既然要rehash,所以此时肯定要添加结点,所以此处处理新增加的结点int nodeIndex = node.hash & sizeMask; // add the new nodenode.setNext(newTable[nodeIndex]);//让node连接上原来的链表newTable[nodeIndex] = node;//放在头结点table = newTable;
}
这里的扩容比之前的 HashMap 要复杂一些,代码难懂一点。上面有两个挨着的 for 循环,第一个 for 有什么用呢?
仔细一看发现,如果没有第一个 for 循环,也是可以工作的,但是,这个 for 循环下来,如果 lastRun 的后面还有比较多的节点,那么这次就是值得的。因为我们只需要克隆 lastRun 前面的节点,后面的一串节点跟着 lastRun 走就是了,不需要做任何操作。
我觉得 Doug Lea 的这个想法也是挺有意思的,不过比较坏的情况就是每次 lastRun 都是链表的最后一个元素或者很靠后的元素,那么这次遍历就有点浪费了。不过 Doug Lea 也说了,根据统计,如果使用默认的阈值,大约只有 1/6 的节点需要克隆。
7 get()
相对于 put 来说,get 真的不要太简单。
- 计算 hash 值,找到 segment 数组中的具体位置,或我们前面用的“槽”
- 槽中也是一个数组,根据 hash 找到数组中具体的位置
- 到这里是链表了,顺着链表进行查找即可
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;// 1. hash 值int h = hash(key);long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;// 该hash值对应的索引对应的偏移// 2. 根据 hash 找到对应的 segmentif ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && // 有对应的segment,cas(tab = s.table) != null) { // segment里有table// 3. 找到segment 内部数组相应位置的链表,遍历for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); // table对应的索引e != null; e = e.next) {K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}// 返回空值是本来就没有key还是有key但是value为null呢?有歧义,所以不能有空值return null;
}
7 remove()
final V remove(Object key, int hash, Object value) {if (!tryLock())//也添加了锁scanAndLock(key, hash); // V oldValue = null;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;HashEntry<K,V> e = entryAt(tab, index);HashEntry<K,V> pred = null;while (e != null) {K k;HashEntry<K,V> next = e.next;if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {V v = e.value;if (value == null || value == v || value.equals(v)) {if (pred == null)setEntryAt(tab, index, next);elsepred.setNext(next);++modCount;--count;oldValue = v;}break;}pred = e;e = next;}} finally {unlock();}return oldValue;
}
总结JDK7的concurrentHashMap:
- 大多采用头插法
- rehash的时候先转移链表尾部一些结点
- 每个链表都有一个锁ReentrantLock
- 没获取到锁的时候可能会先创建头结点
7并发问题分析
现在我们已经说完了 put 过程和 get 过程,我们可以看到 get 过程中是没有加锁的,那自然我们就需要去考虑并发问题。
添加节点的操作 put 和删除节点的操作 remove 都是要加 segment 上的独占锁的,所以它们之间自然不会有问题,我们需要考虑的问题就是 get 的时候在同一个 segment 中发生了 put 或 remove 操作。
put 操作的线程安全性。
- 初始化槽,这个我们之前就说过了,使用了 CAS 来初始化 Segment 中的数组。
- 添加节点到链表的操作是插入到表头的,所以,如果这个时候 get 操作在链表遍历的过程已经到了中间,是不会影响的。当然,另一个并发问题就是 get 操作在 put 之后,需要保证刚刚插入表头的节点被读取,这个依赖于 setEntryAt 方法中使用的 UNSAFE.putOrderedObject。
- 扩容。扩容是新创建了数组,然后进行迁移数据,最后面将 newTable 设置给属性 table。所以,如果 get 操作此时也在进行,那么也没关系,如果 get 先行,那么就是在旧的 table 上做查询操作;而 put 先行,那么 put 操作的可见性保证就是 table 使用了 volatile 关键字。
remove 操作的线程安全性。
get 操作需要遍历链表,但是 remove 操作会"破坏"链表。
如果 remove 破坏的节点 get 操作已经过去了,那么这里不存在任何问题。
如果 remove 先破坏了一个节点,分两种情况考虑。
1、如果此节点是头结点,那么需要将头结点的 next 设置为数组该位置的元素,table 虽然使用了 volatile 修饰,但是 volatile 并不能提供数组内部操作的可见性保证,所以源码中使用了 UNSAFE 来操作数组,请看方法 setEntryAt。
2、如果要删除的节点不是头结点,它会将要删除节点的后继节点接到前驱节点中,这里的并发保证就是 next 属性是 volatile 的。
3.2 JDK8
JDK8里面没有了Segment[],那拿什么实现的呢?
ConcurrentHashMap1.8 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似:Node数组+链表/红黑二叉树。整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本
JDK8只有一个数组,每个数组位置包含一个链表(一个node结点)
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 所在的格子不冲突,就不会产生并发。
![]()
![]()
8构造
public ConcurrentHashMap() {}public ConcurrentHashMap(Map<? extends K, ? extends V> m) {this.sizeCtl = DEFAULT_CAPACITY;putAll(m);
}public ConcurrentHashMap(int initialCapacity, float loadFactor) {this(initialCapacity, loadFactor, 1);
}public ConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel) {if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (initialCapacity < concurrencyLevel) // Use at least as many binsinitialCapacity = concurrencyLevel; // as estimated threadslong size = (long)(1.0 + (long)initialCapacity / loadFactor);int cap = (size >= (long)MAXIMUM_CAPACITY) ?MAXIMUM_CAPACITY : tableSizeFor((int)size);this.sizeCtl = cap;// 指定了初始容量的map的sizeCtl为初始容量大小 // 如 initialCapacity 为 10,那么得到 sizeCtl 为 16,如果 initialCapacity 为 11,得到 sizeCtl 为 32。
}
8sizeCtl
以上这些构造方法方法中,都涉及到一个变量sizeCtl,它的值不同,对应的含义也不一样。
- sizeCtl==0,代表数组未初始化,且数组的初始容量为16
- sizeCtl>0,
- 如果数组未初始化,那么其记录的是数组的初始容量,
- 如果数组已经初始化,那么其记录的是数组的扩容阈值(数组的0.75)
- sizeCtl==-1,表示数组正在初始化
- sizeCtl<0 且不等于-1,表示数组正在扩容,-(1+n),表示此时有n个线程正在共同完成数组的扩容操作
- sizeCtl==N。N是int类型,分为两部分,高15位是指定容量标识,低16位表示并行扩容线程数+1,具体在resizeStamp函数介绍。
很多线程如果都对size进行+1的话,线程阻塞没有必要,baseCount+1,如果有个线程cas没有成功,这些线程会生成一个随机数,也是利用一个&length-1,相当于一个取余操作,取余的结果是CounterCell[]里的某个元素。最后算size的时候另外把CounterCell各个位置上的值加上就行。即baseCount+CounterCell[0~length-1]
通过上面的阅读发现我们的扩容是cas方式进行的,那么既然有cas,那它多半有volatile控制,实际上也是的
private transient volatile int sizeCtl;
我们在构造函数里有提过,sizeCtrl的初始值为给定容量大小或默认容量大小。
- 如果是无参构造,那么sizeCtrl
8Node
Node是ConcurrentHashMap存储结构的基本单元,继承于HashMap中的Entry,用于存储数据,源代码如下
//JDK8 ConcurrentHashMap内部类
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;...;
}//TreeNode继承与Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,他就是通过TreeNode作为存储结构代替Node来转换成黑红树源代码如下
static final class TreeNode<K,V> extends Node<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;...;
}//TreeBin从字面含义中可以理解为存储树形结构的容器,而树形结构就是指TreeNode,所以TreeBin就是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制
static final class TreeBin<K,V> extends Node<K,V> {TreeNode<K,V> root;volatile TreeNode<K,V> first;volatile Thread waiter;volatile int lockState;// values for lockStatestatic final int WRITER = 1; // set while holding write lockstatic final int WAITER = 2; // set when waiting for write lockstatic final int READER = 4; // increment value for setting read lock...;
}
8put()
- 不让放key==null,因为 无法分辨是key没找到的null还是有key值为null,这在多线程里面是模糊不清的,所以压根就不让put null。
- HashMap 支持key==null
- 初始化
- 持有锁的是头结点
public V put(K key, V value) {return putVal(key, value, false);
}final V putVal(K key, V value, boolean onlyIfAbsent) {// chashMap不允许空值空键 // 因为没有找到对应的key而为空,而用于单线程状态的hashmap却可以用containKey(key) 去判断到底是否包含了这个null。if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());// 根据key得到hash值 // 这个值在这里一定是个正数 // 后面会改,然后可以根据hash值判断结点是树的节点还是链表的结点// 记录某个桶上元素的个数,如果超过8个,会转成红黑树int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh; //f是first// 如果数组还未初始化,先对数组进行初始化if (tab == null || (n = tab.length) == 0)//如果整个table[]为空tab = initTable();// 初始化容量为16 // 初始化完后进入下一次while就不进入这里了// 如果hash计算得到的桶位置没有元素,利用cas将元素添加else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //f为tab[i]对应的node // 如果为空就直接创建node放到这个位置// cas自旋(和外侧的for构成自旋循环),保证元素添加安全if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null))) //如果tab[i]为空,就通过CAS创建node//如果CAS失败就进行下一次循环,失败的原因可能是其他线程已经new了,所以下一次循环可能不进入这个else if了break; // no lock when adding to empty bin}// 执行到这说明当前索引位置不为空// 如果hash计算得到的桶位置元素的hash值为MOVED,表明正在扩容,那么当前线程协助扩容else if ((fh = f.hash) == MOVED)//把tab[i]头结点的hash赋值给fh,看这个node值的hash值是否为-1,代表有其他线程在对整个tab[]进行初始化 //MOVED==-1tab = helpTransfer(tab, f);//帮助进行扩容else {// hash计算得到的桶位置元素不为空,且目前没有处于扩容操作,进行元素添加V oldVal = null;// 对当前桶(头结点)进行加锁,保证线程安全,执行元素添加操作synchronized (f) { //同步//拿到当前tab[i]的头结点node 同步锁//我们这里只是拿了根节点的同步锁,万一经过旋转后根节点变化了呢?那其他线程岂不是有自己的根节点锁从而也能执行?所以有下一句的判断 // double checkif (tabAt(tab, i) == f) {//重新拿一下头结点,防止这个头结点被其他线程删除了// 普通链表结点if (fh >= 0) {//头结点hash值不为负,代表不是树结点binCount = 1;//记录链表上有多少个元素for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) { //当前结点是红黑树Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}//End Of if (fh >= 0) {}//end of if (tabAt(tab, i) == f)}//synchronized同步结束if (binCount != 0) {//这里没锁,所以在里面得加锁 //==0代表put没生效,if (binCount >= TREEIFY_THRESHOLD)// 默认8// 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换,// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树treeifyBin(tab, i);if (oldVal != null)//修改后返回旧值return oldVal;break;//没有转为红黑树,同时也是新建结点插入,而不是修改}}}//end foraddCount(1L, binCount);return null;
}
![]()
8initTable
再贴一下sizeCtl
- sizeCtl==0,代表数组未初始化,且数组的初始容量为16
- sizeCtl>0,
- 如果数组未初始化,那么其记录的是数组的初始容量,
- 如果数组已经初始化,那么其记录的是数组的扩容阈值(数组的0.75)
- sizeCtl==-1,表示数组正在初始化
- sizeCtl<0 且不等于-1,表示数组正在扩容,-(1+n),表示此时有n个线程正在共同完成数组的扩容操作
- sizeCtl==N。N是int类型,分为两部分,高15位是指定容量标识,低16位表示并行扩容线程数+1,具体在resizeStamp函数介绍。
很多线程如果都对size进行+1的话,线程阻塞没有必要,baseCount+1,如果有个线程cas没有成功,这些线程会生成一个随机数,也是利用一个&length-1,相当于一个取余操作,取余的结果是CounterCell[]里的某个元素。最后算size的时候另外把CounterCell各个位置上的值加上就行。即
baseCount+CounterCell[0~length-1]
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;//sizeCtrlwhile ((tab = table) == null || tab.length == 0) {// 如果其他线程正在初始化,就让出当前线程if ((sc = sizeCtl) < 0)Thread.yield(); //yield代表放弃cpu拥有权,重新去排队,而重新配对再进入的时候别的线程已经初始化好了// 可能多个线程同时想要进行初始化。用cas只有一个线程能把sc从0改为-1,-1代表正在初始化 // 如果是无参构造SIZECTL和sc都没被赋值过,因为是成员变量,所以都是0 // 如果是有参构造,sizeCtrl是给定的数组容量else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {//当前线程把它变成-1,别的线程就感应到了 //(对象,偏移,旧值,新值) try {// double check双重验证if ((tab = table) == null || tab.length == 0) {// 看是否被指定了初始容量int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//16@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// transient volatile Node<K,V>[] table;table = tab = nt;sc = n - (n >>> 2);// 0.75阈值 }} finally {// 初始化完成后,sizeCtl成员变量变为阈值(或者恢复原值)sizeCtl = sc;}// 总结:初始化过程中sizeCtl先变为-1,初始化结束前,变为阈值break;// 初始化完break}}return tab;
}
addCount
如果每个线程都对baseCount进行++操作,那么会有竞争。如果竞争baseCount成功了,那么就在baseCount上++,竞争失败的线程如下操作:
解决方法是另定义一个数组CounterCell[],然后每个线程随机产生一个随机数取余后定位到CounterCell[i],在这个位置上进行++操作。
最后baseCount加上每个CounterCell[i]
private final void addCount(long x, int check) {CounterCell[] as; long b, s;if ((as = counterCells) != null || //counterCells[]是成员变量,第一次时为null!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { // 第一个线程不进入if,去加baseCount// 操作baseCount失败的线程进入这里 // counterCells不为空的也会进入这里CounterCell a; long v; int m;boolean uncontended = true;// if (as == null || (m = as.length - 1) < 0 ||(a = as[ThreadLocalRandom.getProbe() & m]) == null || // 每个线程生成一个随机数!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { // 用cas对CounterCell[i]+1 // 执行成功就不进入if了fullAddCount(x, uncontended);return;}if (check <= 1)return;s = sumCount();}if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {int rs = resizeStamp(n);if (sc < 0) {if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))transfer(tab, null);s = sumCount();}}
}
private final void fullAddCount(long x, boolean wasUncontended) { //falseint h;if ((h = ThreadLocalRandom.getProbe()) == 0) { // 生成线程的随机值,每个线程是固定的ThreadLocalRandom.localInit(); // force initializationh = ThreadLocalRandom.getProbe();wasUncontended = true;}boolean collide = false; // True if last slot nonemptyfor (;;) {CounterCell[] as; CounterCell a; int n; long v;if ((as = counterCells) != null && (n = as.length) > 0) { // 数组不为空时if ((a = as[(n - 1) & h]) == null) {if (cellsBusy == 0) { // Try to attach new CellCounterCell r = new CounterCell(x); // Optimistic createif (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean created = false;try { // Recheck under lockCounterCell[] rs; int m, j;if ((rs = counterCells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;}if (created)break;continue; // Slot is now non-empty}}collide = false;}else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehashelse if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))break;else if (counterCells != as || n >= NCPU)collide = false; // At max size or staleelse if (!collide)collide = true;else if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {try {if (counterCells == as) {// Expand table unless staleCounterCell[] rs = new CounterCell[n << 1]; // 1变成2for (int i = 0; i < n; ++i)rs[i] = as[i];counterCells = rs;}} finally {cellsBusy = 0;}collide = false;continue; // Retry with expanded table}h = ThreadLocalRandom.advanceProbe(h);}else if (cellsBusy == 0 && counterCells == as &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean init = false;try { // Initialize tableif (counterCells == as) {CounterCell[] rs = new CounterCell[2];rs[h & 1] = new CounterCell(x);counterCells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))break; // Fall back on using base}
}
treeifyBin
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;if (tab != null) {if ((n = tab.length) < MIN_TREEIFY_CAPACITY)tryPresize(n << 1);else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {synchronized (b) {if (tabAt(tab, index) == b) {TreeNode<K,V> hd = null, tl = null;for (Node<K,V> e = b; e != null; e = e.next) {TreeNode<K,V> p =new TreeNode<K,V>(e.hash, e.key, e.val,null, null);if ((p.prev = tl) == null)hd = p;elsetl.next = p;tl = p;}setTabAt(tab, index, new TreeBin<K,V>(hd));}}}}
}
transfer
虽然我们之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range// 如果 nextTab 为 null,先进行一次初始化// 前面我们说了,外围会保证第一个发起迁移的线程调用此方法时,参数 nextTab 为 null// 之后参与迁移的线程调用此方法时,nextTab 不会为 nullif (nextTab == null) {try {// 容量翻倍Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}// nextTable 是 ConcurrentHashMap 中的属性nextTable = nextTab;// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置transferIndex = n;}int nextn = nextTab.length;// ForwardingNode 翻译过来就是正在被迁移的 Node// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了// 所以它其实相当于是一个标志。ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了boolean advance = true;boolean finishing = false; // to ensure sweep before committing nextTab/** 下面这个 for 循环,最难理解的在前面,而要看懂它们,应该先看懂后面的,然后再倒回来看* */// i 是位置索引,bound 是边界,注意是从后往前for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// 下面这个 while 真的是不好理解// advance 为 true 表示可以进行下一个位置的迁移了// 简单理解结局:i 指向了 transferIndex,bound 指向了 transferIndex-stridewhile (advance) {int nextIndex, nextBound;if (--i >= bound || finishing)advance = false;// 将 transferIndex 值赋给 nextIndex// 这里 transferIndex 一旦小于等于 0,说明原数组的所有位置都有相应的线程去处理了else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {// 看括号中的代码,nextBound 是这次迁移任务的边界,注意,是从后往前bound = nextBound;i = nextIndex - 1;advance = false;}}if (i < 0 || i >= n || i + n >= nextn) {int sc;if (finishing) {// 所有的迁移操作已经完成nextTable = null;// 将新的 nextTab 赋值给 table 属性,完成迁移table = nextTab;// 重新计算 sizeCtl:n 是原数组长度,所以 sizeCtl 得出的值将是新数组长度的 0.75 倍sizeCtl = (n << 1) - (n >>> 1);return;}// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 任务结束,方法退出if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了finishing = advance = true;i = n; // recheck before commit}}// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);// 该位置处是一个 ForwardingNode,代表该位置已经迁移过了else if ((fh = f.hash) == MOVED)advance = true; // already processedelse {// 对数组该位置处的结点加锁,开始处理数组该位置处的迁移工作synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> ln, hn;// 头结点的 hash 大于 0,说明是链表的 Node 节点if (fh >= 0) {// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,// 需要将链表一分为二,// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的// lastRun 之前的节点需要进行克隆,然后分到两个链表中int runBit = fh & n;Node<K,V> lastRun = f;for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}// 其中的一个链表放在新数组的位置 isetTabAt(nextTab, i, ln);// 另一个链表放在新数组的位置 i+nsetTabAt(nextTab, i + n, hn);// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了setTabAt(tab, i, fwd);// advance 设置为 true,代表该位置已经迁移完毕advance = true;}else if (f instanceof TreeBin) {// 红黑树的迁移TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}// 如果一分为二后,节点数少于 8,那么将红黑树转换回链表ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;// 将 ln 放置在新数组的位置 isetTabAt(nextTab, i, ln);// 将 hn 放置在新数组的位置 i+nsetTabAt(nextTab, i + n, hn);// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了setTabAt(tab, i, fwd);// advance 设置为 true,代表该位置已经迁移完毕advance = true;}}}}}
}
说到底,transfer 这个方法并没有实现所有的迁移任务,每次调用这个方法只实现了 transferIndex 往前 stride 个位置的迁移工作,其他的需要由外围来控制。
这个时候,再回去仔细看 tryPresize 方法可能就会更加清晰一些了。
8get
get 方法从来都是最简单的,这里也不例外:
- 计算 hash 值
- 根据 hash 值找到数组对应位置: (n - 1) & h
- 根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null 就可以了
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
- 如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
- 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 判断头结点是否就是我们需要的节点if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// 如果头结点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树else if (eh < 0)// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)return (p = e.find(h, key)) != null ? p.val : null;// 遍历链表while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}
简单说一句,此方法的大部分内容都很简单,只有正好碰到扩容的情况,ForwardingNode.find(int h, Object k) 稍微复杂一些,不过在了解了数据迁移的过程后,这个也就不难了,所以限于篇幅这里也不展开说了。
size
由上面分析可知,ConcurrentHashMap 更适合作为线程安全的 Map。在实际的项目过程中,我们通常需要获取集合类的长度, 那么计算 ConcurrentHashMap 的元素大小就是一个有趣的问题,因为他是并发操作的,就是在你计算 size 的时候,它还在并发的插入数据,可能会导致你计算出来的 size 和你实际的 size 有差距。本文主要分析下 JDK1.8 的实现。 关于 JDK1.7 简单提一下。
在 JDK1.7 中,第一种方案他会使用不加锁的模式去尝试多次计算 ConcurrentHashMap 的 size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的。 第二种方案是如果第一种方案不符合,他就会给每个 Segment 加上锁,然后计算 ConcurrentHashMap 的 size 返回。其源码实现:
public int size() {final Segment<K,V>[] segments = this.segments;int size;boolean overflow; // true if size overflows 32 bitslong sum; // sum of modCountslong last = 0L; // previous sumint retries = -1; // first iteration isn't retrytry {for (;;) {if (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)ensureSegment(j).lock(); // force creation}sum = 0L;size = 0;overflow = false;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {sum += seg.modCount;int c = seg.count;if (c < 0 || (size += c) < 0)overflow = true;}}if (sum == last)break;last = sum;}} finally {if (retries > RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}}return overflow ? Integer.MAX_VALUE : size;
}8size
JDK1.8 实现相比 JDK 1.7 简单很多,只有一种方案,我们直接看 size() 代码:
public int size() {long n = sumCount();//关键return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n);
}最大值是 Integer 类型的最大值,但是 Map 的 size 可能超过 MAX_VALUE, 所以还有一个方法 mappingCount(),JDK 的建议使用 mappingCount() 而不是 size()。mappingCount() 的代码如下:
public long mappingCount() {long n = sumCount();return (n < 0L) ? 0L : n; // ignore transient negative values
}
以上可以看出,无论是 size() 还是 mappingCount(), 计算大小的核心方法都是 sumCount()。sumCount() 的代码如下:
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}分析一下 sumCount() 代码。ConcurrentHashMap 提供了 baseCount、counterCells 两个辅助变量和一个 CounterCell 辅助内部类。sumCount() 就是迭代 counterCells 来统计 sum 的过程。 put 操作时,肯定会影响 size(),在 put() 方法最后会调用 addCount() 方法。
addCount() 代码如下:
如果 counterCells == null, 则对 baseCount 做 CAS 自增操作。
![]()
如果并发导致 baseCount CAS 失败了使用 counterCells。
![]()
如果counterCells CAS 失败了,在 fullAddCount 方法中,会继续死循环操作,直到成功。
![]()
然后,CounterCell 这个类到底是什么?我们会发现它使用了 @sun.misc.Contended 标记的类,内部包含一个 volatile 变量。@sun.misc.Contended 这个注解标识着这个类防止需要防止 “伪共享”。那么,什么又是伪共享呢?
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
CounterCell 代码如下:
@sun.misc.Contended static final class CounterCell {volatile long value;CounterCell(long x) { value = x; }
}
总结
JDK1.7 和 JDK1.8 对 size 的计算是不一样的。 1.7 中是先不加锁计算三次,如果三次结果不一样在加锁。
JDK1.8 size 是通过对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和 遍历 CounterCell 数组得出 size。
JDK 8 推荐使用mappingCount 方法,因为这个方法的返回值是 long 类型,不会因为 size 方法是 int 类型限制最大值。
线程不安全问题
代码如图所示,大家都应该知道HashMap不是线程安全的。那么 HashMap在并发场景下可能存在哪些问题?
- 数据丢失
- 数据重复
- 死循环
关于死循环的问题,在Java8中个人认为是不存在了,在Java8之前的版本中之所以出现死循环是因为在resize的过程中对链表进行了倒序处理;在Java8中不再倒序处理,自然也不会出现死循环。
对这个问题Doug Lea 是这样说的:
Doug Lea writes: 通过上面Java7中的源码分析一下为什么会出现数据丢失,如果有两条线程同时执行到这条语句 table[i]=null,时两个线程都会区创建Entry,这样存入会出现数据丢失。 如果有两个线程同时发现自己都key不存在,而这两个线程的key实际是相同的,在向链表中写入的时候第一线程将e设置为了自己的Entry,而第二个线程执行到了e.next,此时拿到的是最后一个节点,依然会将自己持有是数据插入到链表中,这样就出现了数据 重复。
通过商品put源码可以发现,是先将数据写入到map中,再根据元素到个数再决定是否做resize.在resize过程中还会出现一个更为诡异都问题死循环。
这个原因主要是因为hashMap在resize过程中对链表进行了一次倒序处理。假设两个线程同时进行resize,
A->B 第一线程在处理过程中比较慢,第二个线程已经完成了倒序编程了B-A 那么就出现了循环,B->A->B.这样就出现了就会出现CPU使用率飙升。
在下午突然收到其中一台机器CPU利用率不足告警,将jstack内容分析发现,可能出现了死循环和数据丢失情况,当然对于链表的操作同样存在问题。
PS:在这个过程中可以发现,之所以出现死循环,主要还是在于对于链表对倒序处理,在Java 8中,已经不在使用倒序列表,死循环问题得到了极大改善。
首先看一下put源码
通过上面Java7中的源码分析一下为什么会出现数据丢失,如果有两条线程同时执行到这条语句 table[i]=null,时两个线程都会去创建Entry,这样存入会出现数据丢失。
如果有两个线程同时发现自己都key不存在,而这两个线程的key实际是相同的,在向链表中写入的时候第一线程将e设置为了自己的Entry,而第二个线程执行到了e.next,此时拿到的是最后一个节点,依然会将自己持有是数据插入到链表中,这样就出现了数据 重复。通过商品put源码可以发现,是先将数据写入到map中,再根据元素到个数再决定是否做resize.在resize过程中还会出现一个更为诡异的问题死循环。这个原因主要是因为hashMap在resize过程中对链表进行了一次倒序处理。假设两个线程同时进行resize,
A->B 第一线程在处理过程中比较慢,第二个线程已经完成了倒序编程了B-A 那么就出现了循环,B->A->B.这样就出现了就会出现CPU使用率飙升。
在下午突然收到其中一台机器CPU利用率不足告警,将jstack内容分析发现,可能出现了死循环和数据丢失情况,当然对于链表的操作同样存在问题。
PS:在这个过程中可以发现,之所以出现死循环,主要还是在于对于链表对倒序处理,在Java 8中,已经不在使用倒序列表,死循环问题得到了极大改善。
下图是负载和CPU的表现:
![]()
![]()
下面是线程栈的部分日志:
DubboServerHandler-10.172.75.33:20880-thread-139" daemon prio=10 tid=0x0000000004a93000 nid=0x76fe runnable [0x00007f0ddaf2d000]java.lang.Thread.State: RUNNABLEat java.util.HashMap.getEntry(HashMap.java:465)at java.util.HashMap.containsKey(HashMap.java:449)"pool-9-thread-16" prio=10 tid=0x00000000033ef000 nid=0x4897 runnable [0x00007f0dd62cb000]java.lang.Thread.State: RUNNABLEat java.util.HashMap.put(HashMap.java:494)DubboServerHandler-10.172.75.33:20880-thread-189" daemon prio=10 tid=0x00007f0de99df800 nid=0x7722 runnable [0x00007f0dd8b09000]java.lang.Thread.State: RUNNABLEat java.lang.Thread.yield(Native Method)DubboServerHandler-10.172.75.33:20880-thread-157" daemon prio=10 tid=0x00007f0de9a94800 nid=0x7705 runnable [0x00007f0dda826000]java.lang.Thread.State: RUNNABLEat java.lang.Thread.yield(Native Method)
HashMap、ConcurrentHashMap源码解读(JDK7/8)相关推荐
- Java Review - HashMap HashSet 源码解读
文章目录 概述 HashMap结构图 构造函数 重点方法源码解读 (1.7) put() get() remove() 1.8版本 HashMap put resize() 扩容 get HashSe ...
- ConcurrentHashMap源码解读,java大厂面试攻略
当我们享受着jdk带来的便利时同样承受它带来的不幸恶果.通过分析Hashtable就知道, synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,安全的背后是巨大的浪费,慧眼独具 ...
- JDK8之ConcurrentHashMap源码解读
本文默认读者阅读过JDK8的HashMap源码,不再对源码中的红黑树操作进行分析. 本文主要对put().transfer().addCount()进行分析(replaceNode()源码近似于put ...
- ConcurrentHashMap源码解读
曾经研究过jkd1.5新特性,其中ConcurrentHashMap就是其中之一,其特点:效率比Hashtable高,并发性比hashmap好.结合了两者的特点. 集合是编程中最常用的数据结构.而谈到 ...
- Java Review - LinkedHashMap LinkedHashSet 源码解读
文章目录 Pre 概述 数据结构 类继承关系 构造函数 方法 get() put() remove() LinkedHashSet 使用案例 - FIFO策略缓存 Pre Java Review - ...
- ConcurrentHashMap源码跟踪记录
2019独角兽企业重金招聘Python工程师标准>>> concurrentHashMap源码解读 主要理解几个问题1 ConcurrentHashMap如何实现分段锁2 存取数据是 ...
- 【JavaMap接口】HashMap源码解读实例
这里写自定义目录标题 1.HashMap源码 2.HashMap使用 1.HashMap源码 解读HashMap的源码 执行构造器 new HashMap() 初始化加载因子 loadfactor = ...
- HashMap源码解读—Java8版本
[手撕源码系列]HashMap源码解读-Java8版本 一.HashMap简介 1.1 原文 1.2 翻译 1.3 一语中的 1.4 线程安全性 1.5 优劣分析 二.定义 三.数据结构 四.域的解读 ...
- hashmap的特性?HashMap底层源码,数据结构?Hashmap和hashtable ConcurrentHashMap区别?
1.hashmap的特性? 允许空键和空值(但空键只有一个,且放在第一位) 元素是无序的,而且顺序会不定时改变 key 用 Set 存放,所以想做到 key 不允许重复,key 对应的类需要重写 ha ...
最新文章
- bpython ipython_安装ipython后命令找不到ipython bpython -bash: *python: command not found
- java计算正方形_在地图计算圆的外接正方形,并返回左上顶点和右下顶点(java、javascript)...
- linux php7扩展查看,linux安装PHP7以及扩展
- Java 递归解决 quot;仅仅能两数相乘的计算器计算x^yquot; 问题
- Pandas (GeoPandas)笔记:set_index reset_index
- 交通预测论文笔记《Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting》
- 【推荐】揭秘谷歌电影票房预测模型
- python画画需要什么模块_python实战练手项目---使用turtle模块画奥运五环
- Maven学习总结(56)—— Maven、Gradle 、 Ant 哪一个构建工具最适合你?
- 简要描述安装配置apache的一个开源Hadoop集群
- 设计模式----装饰模式(C++实现)
- php读取西门子plc_第三方设备如何读取PLC数据
- 逐一解读Gartner评出的11大信息安全技术
- 代码安全审计工具推荐
- 盘点2016年炙手可热的TV BOX电视盒子
- js常用插件(八)之移动端滑动插件swiper,BScroll
- 面板数据,面板数据的三种基本模型
- 现有的数字版权保护大全
- C# 报表设计器 (winform 设计端)开发与实现生成网页的HTML报表 开放源码及调试
- python正态分布函数_数学之美_正态分布(Python代码)