面向对象的3个基本对象
谢谢作者
面向对象的三个基本特征(讲解)
面向对象的三个基本特征是:封装、继承、多态。

封装
封装最好理解了。封装是面向对象的特征之一,是对象和类概念的主要特性。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承
面向对象编程 (OOP) 语言的一个主要功能就是 “ 继承 ” 。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。
被继承的类称为 “ 基类 ” 、 “ 父类 ” 或 “ 超类 ” 。
继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过 “ 继承 ” ( Inheritance )和 “ 组合 ” ( Composition )来实现。
在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。
继承概念的实现方式有三类:实现继承、接口继承和可视继承。
Ø 实现继承是指使用基类的属性和方法而无需额外编码的能力;
Ø 接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
Ø 可视继承是指子窗体(类)使用基窗体(类)的外观和实现代码的能力。
在考虑使用继承时,有一点需要注意,那就是两个类之间的关系应该是 “ 属于 ” 关系。例如, Employee 是一个人, Manager 也是一个人,因此这两个类都可以继承 Person类。但是 Leg 类却不能继承 Person 类,因为腿并不是一个人。
抽象类仅定义将由子类创建的一般属性和方法,创建抽象类时,请使用关键字 Interface 而不是 Class 。
OO 开发范式大致为:划分对象 → 抽象类 → 将类组织成为层次化结构 ( 继承和合成 ) → 用类与实例进行设计和实现几个阶段。
多态
多态性( polymorphisn )是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。
实现多态,有二种方式,覆盖,重载。
覆盖,是指子类重新定义父类的虚函数的做法。
重载,是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
其实,重载的概念并不属于 “ 面向对象编程 ” ,重载的实现是:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数(至少对于编译器来说是这样的)。如,有两个同名函数: function func(p:integer):integer; 和 function func(p:string):integer; 。那么编译器做过修饰后的函数名称可能是这样的: int_func 、str_func 。对于这两个函数的调用,在编译器间就已经确定了,是静态的(记住:是静态)。也就是说,它们的地址在编译期就绑定了(早绑定),因此,重载和多态无关!真正和多态相关的是 “ 覆盖 ” 。当子类重新定义了父类的虚函数后,父类指针根据赋给它的不同的子类指针,动态(记住:是动态!)的调用属于子类的该函数,这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址无法给出)。因此,这样的函数地址是在运行期绑定的(晚邦定)。结论就是:重载只是一种语言特性,与多态无关,与面向对象也无关!引用一句 Bruce Eckel 的话: “ 不要犯傻,如果它不是晚邦定,它就不是多态。 ”
那么,多态的作用是什么呢?我们知道,封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了 —— 代码重用。而多态则是为了实现另一个目的 —— 接口重用!多态的作用,就是为了类在继承和派生的时候,保证使用 “ 家谱 ” 中任一类的实例的某一属性时的正确调用。
概念讲解
泛化( Generalization )

图表 1 泛化
在上图中,空心的三角表示继承关系(类继承),在 UML 的术语中,这种关系被称为泛化( Generalization )。 Person( 人 ) 是基类, Teacher( 教师 ) 、Student( 学生 ) 、 Guest( 来宾 ) 是子类。
若在逻辑上 B 是 A 的“一种”,并且 A 的所有功能和属性对 B 而言都有意义,则允许 B 继承 A 的功能和属性。
例如, 教师是人, Teacher 是 Person 的“一种”( a kind of )。 那么类 Teacher 可以从类 Person 派生(继承)。
如果 A 是基类, B 是 A 的派生类,那么 B 将继承 A 的数据和函数。
如果类 A 和类 B 毫不相关,不可以为了使 B 的功能更多些而让 B 继承 A 的功能和属性。
若在逻辑上 B 是 A 的“一种”( a kind of ),则允许 B 继承 A 的功能和属性。
聚合(组合)

图表 2 组合
若在逻辑上 A 是 B 的“一部分”( a part of ),则不允许 B 从 A 派生,而是要用 A 和其它东西组合出 B 。
例如,眼( Eye )、鼻( Nose )、口( Mouth )、耳( Ear )是头( Head )的一部分,所以类 Head 应该由类 Eye 、 Nose 、 Mouth 、 Ear 组合而成,不是派生(继承)而成。
聚合的类型分为无、共享 ( 聚合 ) 、复合 ( 组合 ) 三类。
聚合( aggregation )

图表 3 共享
上面图中,有一个菱形(空心)表示聚合( aggregation )(聚合类型为共享),聚合的意义表示 has-a 关系。聚合是一种相对松散的关系,聚合类 B 不需要对被聚合的类 A 负责。
组合( composition )

图表 4 复合
这幅图与上面的唯一区别是菱形为实心的,它代表了一种更为坚固的关系 —— 组合( composition )(聚合类型为复合)。组合表示的关系也是 has-a ,不过在这里, A 的生命期受 B 控制。即 A 会随着 B 的创建而创建,随 B 的消亡而消亡。
依赖 (Dependency)

图表 5 依赖
这里 B 与 A 的关系只是一种依赖 (Dependency) 关系,这种关系表明,如果类 A 被修改,那么类 B 会受到影响。
==================接口与抽象类有什么区别==================
abstract class和interface是Java语言中对于抽象类定义进行支持的两种机制,正是由于这两种机制的存在,才赋予了Java强大的面向对象能力。abstract class和interface之间在对于抽象类定义的支持方面具有很大的相似性,甚至可以相互替换,因此很多开发者在进行抽象类定义时对于abstract class和interface的选择显得比较随意。其实,两者之间还是有很大的区别的,对于它们的选择甚至反映出对于问题领域本质的理解、对于设计意图的理解是否正确、合理。本文将对它们之间的区别进行一番剖析,试图给开发者提供一个在二者之间进行选择的依据。
理解抽象类
abstract class和interface在Java语言中都是用来进行抽象类(本文中的抽象类并非从abstract class翻译而来,它表示的是一个抽象体,而abstract class为Java语言中用于定义抽象类的一种方法,请读者注意区分)定义的,那么什么是抽象类,使用抽象类能为我们带来什么好处呢?
在面向对象的概念中,我们知道所有的对象都是通过类来描绘的,但是反过来却不是这样。并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。抽象类往往用来表征我们在对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。比如:如果我们进行一个图形编辑软件的开发,就会发现问题领域存在着圆、三角形这样一些具体概念,它们是不同的,但是它们又都属于形状这样一个概念,形状这个概念在问题领域是不存在的,它就是一个抽象概念。正是因为抽象的概念在问题领域没有对应的具体概念,所以用以表征抽象概念的抽象类是不能够实例化的。
在面向对象领域,抽象类主要用来进行类型隐藏。我们可以构造出一个固定的一组行为的抽象描述,但是这组行为却能够有任意个可能的具体实现方式。这个抽象描述就是抽象类,而这一组任意个可能的具体实现则表现为所有可能的派生类。模块可以操作一个抽象体。由于模块依赖于一个固定的抽象体,因此它可以是不允许修改的;同时,通过从这个抽象体派生,也可扩展此模块的行为功能。熟悉OCP的读者一定知道,为了能够实现面向对象设计的一个最核心的原则OCP(Open-Closed Principle),抽象类是其中的关键所在。
从语法定义层面看abstract class和interface
在语法层面,Java语言对于abstract class和interface给出了不同的定义方式,下面以定义一个名为Demo的抽象类为例来说明这种不同。
使用abstract class的方式定义Demo抽象类的方式如下:
abstract class Demo {
abstract void method1();
abstract void method2();
…
}
使用interface的方式定义Demo抽象类的方式如下:
interface Demo {
void method1();
void method2();
…
}
在abstract class方式中,Demo可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface方式的实现中,Demo只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在interface中一般不定义数据成员),所有的成员方法都是abstract的。从某种意义上说,interface是一种特殊形式的abstract class。
从编程的角度来看,abstract class和interface都可以用来实现"design by contract"的思想。但是在具体的使用上面还是有一些区别的。
首先,abstract class在Java语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。也许,这是Java语言的设计者在考虑Java对于多重继承的支持方面的一种折中考虑吧。
其次,在abstract class的定义中,我们可以赋予方法的默认行为。但是在interface的定义中,方法却不能拥有默认行为,为了绕过这个限制,必须使用委托,但是这会 增加一些复杂性,有时会造成很大的麻烦。
在抽象类中不能定义默认行为还存在另一个比较严重的问题,那就是可能会造成维护上的麻烦。因为如果后来想修改类的界面(一般通过abstract class或者interface来表示)以适应新的情况(比如,添加新的方法或者给已用的方法中添加新的参数)时,就会非常的麻烦,可能要花费很多的时间(对于派生类很多的情况,尤为如此)。但是如果界面是通过abstract class来实现的,那么可能就只需要修改定义在abstract class中的默认行为就可以了。
同样,如果不能在抽象类中定义默认行为,就会导致同样的方法实现出现在该抽象类的每一个派生类中,违反了"one rule,one place"原则,造成代码重复,同样不利于以后的维护。因此,在abstract class和interface间进行选择时要非常的小心。
从设计理念层面看abstract class和interface
上面主要从语法定义和编程的角度论述了abstract class和interface的区别,这些层面的区别是比较低层次的、非本质的。本小节将从另一个层面:abstract class和interface所反映出的设计理念,来分析一下二者的区别。作者认为,从这个层面进行分析才能理解二者概念的本质所在。
前面已经提到过,abstarct class在Java语言中体现了一种继承关系,要想使得继承关系合理,父类和派生类之间必须存在"is a"关系,即父类和派生类在概念本质上应该是相同的(参考文献〔3〕中有关于"is a"关系的大篇幅深入的论述,有兴趣的读者可以参考)。对于interface 来说则不然,并不要求interface的实现者和interface定义在概念本质上是一致的,仅仅是实现了interface定义的契约而已。为了使论述便于理解,下面将通过一个简单的实例进行说明。
考虑这样一个例子,假设在我们的问题领域中有一个关于Door的抽象概念,该Door具有执行两个动作open和close,此时我们可以通过abstract class或者interface来定义一个表示该抽象概念的类型,定义方式分别如下所示:
使用abstract class方式定义Door:
abstract class Door {
abstract void open();
abstract void close();
}
使用interface方式定义Door:
interface Door {
void open();
void close();
}
其他具体的Door类型可以extends使用abstract class方式定义的Door或者implements使用interface方式定义的Door。看起来好像使用abstract class和interface没有大的区别。
如果现在要求Door还要具有报警的功能。我们该如何设计针对该例子的类结构呢(在本例中,主要是为了展示abstract class和interface反映在设计理念上的区别,其他方面无关的问题都做了简化或者忽略)?下面将罗列出可能的解决方案,并从设计理念层面对这些不同的方案进行分析。
解决方案一:
简单的在Door的定义中增加一个alarm方法,如下:
abstract class Door {
abstract void open();
abstract void close();
abstract void alarm();
}
或者
interface Door {
void open();
void close();
void alarm();
}
那么具有报警功能的AlarmDoor的定义方式如下:
class AlarmDoor extends Door {
void open() { … }
void close() { … }
void alarm() { … }
}
或者
class AlarmDoor implements Door {
void open() { … }
void close() { … }
void alarm() { … }
}
这种方法违反了面向对象设计中的一个核心原则ISP(Interface Segregation Priciple),在Door的定义中把Door概念本身固有的行为方法和另外一个概念"报警器"的行为方法混在了一起。这样引起的一个问题是那些仅仅依赖于Door这个概念的模块会因为"报警器"这个概念的改变(比如:修改alarm方法的参数)而改变,反之依然。
解决方案二:
既然open、close和alarm属于两个不同的概念,根据ISP原则应该把它们分别定义在代表这两个概念的抽象类中。定义方式有:这两个概念都使用abstract class方式定义;两个概念都使用interface方式定义;一个概念使用abstract class方式定义,另一个概念使用interface方式定义。
显然,由于Java语言不支持多重继承,所以两个概念都使用abstract class方式定义是不可行的。后面两种方式都是可行的,但是对于它们的选择却反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理。我们一一来分析、说明。
如果两个概念都使用interface方式来定义,那么就反映出两个问题:1、我们可能没有理解清楚问题领域,AlarmDoor在概念本质上到底是Door还是报警器?2、如果我们对于问题领域的理解没有问题,比如:我们通过对于问题领域的分析发现AlarmDoor在概念本质上和Door是一致的,那么我们在实现时就没有能够正确的揭示我们的设计意图,因为在这两个概念的定义上(均使用interface方式定义)反映不出上述含义。
如果我们对于问题领域的理解是:AlarmDoor在概念本质上是Door,同时它有具有报警的功能。我们该如何来设计、实现来明确的反映出我们的意思呢?前面已经说过,abstract class在Java语言中表示一种继承关系,而继承关系在本质上是"is a"关系。所以对于Door这个概念,我们应该使用abstarct class方式来定义。另外,AlarmDoor又具有报警功能,说明它又能够完成报警概念中定义的行为,所以报警概念可以通过interface方式定义。如下所示:
abstract class Door {
abstract void open();
abstract void close();
}
interface Alarm {
void alarm();
}
class AlarmDoor extends Door implements Alarm {
void open() { … }
void close() { … }
void alarm() { … }
}
这种实现方式基本上能够明确的反映出我们对于问题领域的理解,正确的揭示我们的设计意图。其实abstract class表示的是"is a"关系,interface表示的是"like a"关系,大家在选择时可以作为一个依据,当然这是建立在对问题领域的理解上的,比如:如果我们认为AlarmDoor在概念本质上是报警器,同时又具有Door的功能,那么上述的定义方式就要反过来了。
==================游标,可不可以嵌套,可以用什么办法替换使用游标==================
For standard SQL, it is surely that cursors can be nested, just like LOOPs can be nested.
Below is an example written in PL/SQL:
Declare
Cursor_H IS CURSOR AS SELECT * FROM customer_header;
Cursor_L (p_cust_id) IS CURSOR AS SELECT * FROM customer_detail WHERE customer_id = p_cust_id;
Begin
For H in Cursor_H
Loop
Print customer_header;
For L in Cursor_L (H.customer_id)
Loop
Print_customer_detail;
End loop;
End loop;
End;
In PL/SQL, you can use Direct-Loop instead of cursor;
For example:
Begin
For H in (SELECT * FROM customer_header) -- instead of Cursor_H
Loop
Print customer_header;
For L in (SELECT * FROM customer_detail WHERE customer_id = H.customer_id) -- instead of Cursor_L
Loop
Print_customer_detail;
End loop;
End loop;
End;
=======================
MVC是一种目前广泛流行的软件设计模式,早在70年代,IBM就推出了Sanfronscisico项目计划,其实就是MVC设计模式的研究。近来,随着J2EE的成熟,它正在成为在J2EE平台上推荐的一种设计模型,也是广大Java开发者非常感兴趣的设计模型。MVC模式也逐渐在PHP和ColdFusion开发者中运用,并有增长趋势。随着网络应用的快速增加,MVC模式对于Web应用的开发无疑是一种非常先进的设计思想,无论你选择哪种语言,无论应用多复杂,它都能为你理解分析应用模型时提供最基本的分析方法,为你构造产品提供清晰的设计框架,为你的软件工程提供规范的依据。
MVC设计思想
MVC英文即Model-View-Controller,即把一个应用的输入、处理、输出流程按照Model、View、Controller的方式进行分离,这样一个应用被分成三个层——模型层、视图层、控制层。
视图(View)代表用户交互界面,对于Web应用来说,可以概括为HTML界面,但有可能为XHTML、XML和Applet。随着应用的复杂性和规模性,界面的处理也变得具有挑战性。一个应用可能有很多不同的视图,MVC设计模式对于视图的处理仅限于视图上数据的采集和处理,以及用户的请求,而不包括在视图上的业务流程的处理。业务流程的处理交予模型(Model)处理。比如一个订单的视图只接受来自模型的数据并显示给用户,以及将用户界面的输入数据和请求传递给控制和模型。
模型(Model):就是业务流程/状态的处理以及业务规则的制定。业务流程的处理过程对其它层来说是黑箱操作,模型接受视图请求的数据,并返回最终的处理结果。业务模型的设计可以说是MVC最主要的核心。目前流行的EJB模型就是一个典型的应用例子,它从应用技术实现的角度对模型做了进一步的划分,以便充分利用现有的组件,但它不能作为应用设计模型的框架。它仅仅告诉你按这种模型设计就可以利用某些技术组件,从而减少了技术上的困难。对一个开发者来说,就可以专注于业务模型的设计。MVC设计模式告诉我们,把应用的模型按一定的规则抽取出来,抽取的层次很重要,这也是判断开发人员是否优秀的设计依据。抽象与具体不能隔得太远,也不能太近。MVC并没有提供模型的设计方法,而只告诉你应该组织管理这些模型,以便于模型的重构和提高重用性。我们可以用对象编程来做比喻,MVC定义了一个顶级类,告诉它的子类你只能做这些,但没法限制你能做这些。这点对编程的开发人员非常重要。
业务模型还有一个很重要的模型那就是数据模型。数据模型主要指实体对象的数据保存(持续化)。比如将一张订单保存到数据库,从数据库获取订单。我们可以将这个模型单独列出,所有有关数据库的操作只限制在该模型中。
控制(Controller)可以理解为从用户接收请求, 将模型与视图匹配在一起,共同完成用户的请求。划分控制层的作用也很明显,它清楚地告诉你,它就是一个分发器,选择什么样的模型,选择什么样的视图,可以完成什么样的用户请求。控制层并不做任何的数据处理。例如,用户点击一个连接,控制层接受请求后, 并不处理业务信息,它只把用户的信息传递给模型,告诉模型做什么,选择符合要求的视图返回给用户。因此,一个模型可能对应多个视图,一个视图可能对应多个模型。
MVC的优点
大部分用过程语言比如ASP、PHP开发出来的Web应用,初始的开发模板就是混合层的数据编程。例如,直接向数据库发送请求并用HTML显示,开发速度往往比较快,但由于数据页面的分离不是很直接,因而很难体现出业务模型的样子或者模型的重用性。产品设计弹性力度很小,很难满足用户的变化性需求。MVC要求对应用分层,虽然要花费额外的工作,但产品的结构清晰,产品的应用通过模型可以得到更好地体现。
首先,最重要的是应该有多个视图对应一个模型的能力。在目前用户需求的快速变化下,可能有多种方式访问应用的要求。例如,订单模型可能有本系统的订单,也有网上订单,或者其他系统的订单,但对于订单的处理都是一样,也就是说订单的处理是一致的。按MVC设计模式,一个订单模型以及多个视图即可解决问题。这样减少了代码的复制,即减少了代码的维护量,一旦模型发生改变,也易于维护。

MVC设计模型
其次,由于模型返回的数据不带任何显示格式,因而这些模型也可直接应用于接口的使用。
再次,由于一个应用被分离为三层,因此有时改变其中的一层就能满足应用的改变。一个应用的业务流程或者业务规则的改变只需改动MVC的模型层。
控制层的概念也很有效,由于它把不同的模型和不同的视图组合在一起完成不同的请求,因此,控制层可以说是包含了用户请求权限的概念。
最后,它还有利于软件工程化管理。由于不同的层各司其职,每一层不同的应用具有某些相同的特征,有利于通过工程化、工具化产生管理程序代码。
MVC的缺点
MVC的设计实现并不十分容易, 理解起来比较容易,但对开发人员的要求比较高。MVC只是一种基本的设计思想,还需要详细的设计规划。
模型和视图的严格分离可能使得调试困难一些,但比较容易发现错误。
经验表明,MVC由于将应用分为三层,意味着代码文件增多,因此,对于文件的管理需要费点心思。
综合上述,MVC是构筑软件非常好的基本模式,至少将业务处理与显示分离,强迫将应用分为模型、视图以及控制层, 使得你会认真考虑应用的额外复杂性,把这些想法融进到架构中,增加了应用的可拓展性。如果能把握到这一点,MVC模式会使得你的应用更加强壮,更加有弹性,更加个性化。
引言: MVC如何工作 MVC是一个设计模式,它强制性的使应用程序的输入、处理和输出分开。
·网络上md5的java实现. »显示摘要« 摘要:无意间发现的.不过章章师兄研究的密码学里md5好象已经用c++实现了.package com.sinosoftgroup.msd.util; /** * * <p>title: </p> * <p>description: </p> * <p>copyright: copyright (c) 2003</p> * <p...... ·jie server开发指南 »显示摘要« 摘要: 一个简单的action,返回hello world package org.jie.demo; import org.jie.server.action.standardaction;import javax.servlet.http.httpservletrequest; class testaction extends standardaction { publi......
MVC设计模式带来更好的软件结构和代码重用
mvc如何工作
mvc是一个设计模式,它强制性的使应用程序的输入.处理与输出分开.使用mvc应用程序被分成三个核心部件:模型.视图.控制器.它们各自处理自己的任务.
如何处理应用程序的界面变得越来越有挑战性.mvc一个大的好处是它能为你的应用程序处理很多不同的视图.在视图中其实没有真正的处理发生,不管这些数据是联机存储的还是一个雇员列表,作为视图来讲,它只是作为一种输出数据并允许用户操纵的方式. 【程序编程相关:Hibernate middlegen中】
视图
视图是用户看到并与之交互的界面.对老式的web应用程序来说,视图就是由html元素组成的界面,在新式的web应用程序中,html依旧在视图中扮演着重要的角色,但一些新的技术已层出不穷,它们包括macromedia flash与象xhtml,xml/xsl,wml等一些标识语言与web services. 【推荐阅读:JAVA文件加密器(收藏)】
控制器
控制器接受用户的输入并调用模型与视图去完成用户的需求.所以当单击web页面中的超链接与发送html表单时,控制器本身不输出任何东西与做任何处理.它只是接收请求并决定调用哪个模型构件去处理请求,然后用确定用哪个视图来显示模型处理返回的数据. 【扩展信息:CruiseControl简介】
模型
模型表示企业数据与业务规则.在mvc的三个部件中,模型拥有最多的处理任务.例如它可能用象ejbs与coldfusion components这样的构件对象来处理数据库.被模型返回的数据是中立的,就是说模型与数据格式无关,这样一个模型能为多个视图提供数据.由于应用于模型的代码只需写一次就可以被多个视图重用,所以减少了代码的重复性
-----------------
强命名程序集(Strong Name Assembly)的概念
因为不同的公司可能会开发出有相同名字的程序集来,如果这些程序集都被复制到同一 个相同的目录下,最后一个安装的程序集将会代替前面的程序集。这就是著名的Windows “DLL Hell”出现的原因。
很明显,简单的用文件名来区分程序集是不够的,CLR需要支持某种机制来唯一的标识一个程序集。这就是所谓的强命名程序集。
一个强命名程序集包含四个唯一标志程序集的特性:文件名(没有扩展名),版本号,语言文化信息(如果有的话),公有秘钥。
这些信息存储在程序集的清单(manifest)中。清单包含了程序集的元数据,并嵌入在程序集的某个文件中。
下面的字符串标识了四个不同的程序集文件:
“MyType, Version=1.0.1.0,
Culture=neutral, PublicKeyToken=bf5779af662fc055”
“MyType, Version=1.0.1.0,
Culture=en-us, PublicKeyToken=bf5779af662fc055”
“MyType, Version=1.0.2.0,
Culture=neturl, PublicKeyToken=bf5779af662fc055”
“MyType, Version=1.0.2.0,
Culture=neutral, PublicKeyToken=dbe4120289f9fd8a”
如果一个公司想唯一的标识它的程序集,那么它必须首先获取一个公钥/私钥对,然后将共有秘钥和程序集相关联。不存在两个两个公司有同样的公钥/私钥对的情况,正是这种区分使得我们可以创建有着相同名称,版本和语言文化信息的程序集,而不引起任何冲突。
与强命名程序集对应的就是所谓的弱命名程序集。(其实就是普通的没有被强命名的程序集)。两种程序集在结构上是相同的。都使用相同的PE文件格式,PE表头,CLR表头,元数据,以及清单(manifest)。二者之间真正的区别在于:强命名程序集有一个发布者的公钥/私钥对签名,其中的公钥/私钥对唯一的标识了程序集的发布者。利用公钥/私钥对,我们可以对程序集进行唯一性识别、实施安全策略和版本控制策略,这种唯一标识程序集的能力使得应用程序在试图绑定一个强命名程序集时,CLR能够实施某些“已确知安全”的策略(比如只信任某个公司的程序集)。
请说明在.net中常用的几种页面间传递参数的方法,并说出他们的优缺点。
session(viewstate) 简单,但易丢失
application 全局
cookie 简单,但可能不支持,可能被伪造
input type="hidden" 简单,可能被伪造
url参数 简单,显示于地址栏,长度有限
数据库 稳定,安全,但性能相对弱
===============================asp.net 页面生命周期
错误:
每个页面的生命周期为用户的访问开始到结束,也就是说程序中的全局变量同时生存到用户的访问结束.
正确:
每个页面的生命周期为用户的每一次访问,也就是说每一次客户端与服务器之间的一个往返过程.全局变量的生命周期在此之间.
例:
string gb_string;
void Page_Load()
{
if(!IsPostBack)
{
//第一次被访问的代码
gb_string ="Test!";
}
}
void btnSubmit_Click(Object sender, EventArgs e)
{
//在这里gb_string 为空,是这一次postback新建的字符串
//跟第一次那个被赋值的字符串不是同一对象.
}
ASP.NET 页面生命周期
1. Page_Init();
2. Load ViewState and Postback data;
3. Page_Load();
4. Handle control events;
5. Page_PreRender();
6. Page_Render();
7. Unload event;
8. Dispose method called;
总结:
在Page_Load()中执行的初始化工作
1.一般都是初始化web控件,因为这些控件的状态(值),由系统自动保存(__VIEWSTATE),
下次返回时,自动赋值,这是ASP.NET保存"web控件"状态的特性.
2.但是初始的如果是程序中用到的全局变量,就应该注意他的生命周期的问题.如果函数都在一个生命周期中,全局变量的值当然是一致的.但是如果在"由客户激发"的事件中,这就不同了,每个客户事件的激发,都会导致新的页面生命周期的产生,全局变量的值会丢失,因为它们不在同一页面生命周期(就像上面出现的错误1).
*********************************************************
|
asp.net2.0 页面生命周期方法 |
|
| 方法 | 活动 |
|
Constructor |
Always |
|
Construct |
Always |
|
TestDeviceFilter |
Always |
|
AddParsedSubObject |
Always |
|
DeterminePostBackMode |
Always |
|
OnPreInit |
Always |
|
LoadPersonalizationData |
Always |
|
InitializeThemes |
Always |
|
OnInit |
Always |
|
ApplyControlSkin |
Always |
|
ApplyPersonalization |
Always |
|
OnInitComplete |
Always |
|
LoadPageStateFromPersistenceMedium |
Always |
|
LoadControlState |
Always |
|
LoadViewState |
Always |
|
ProcessPostData1 |
Always |
|
OnPreLoad |
Always |
|
OnLoad |
Always |
|
ProcessPostData2 |
Always |
|
RaiseChangedEvents |
Always |
|
RaisePostBackEvent |
Always |
|
OnLoadComplete |
Always |
|
OnPreRender |
Always |
|
OnPreRenderComplete |
Always |
|
SavePersonalizationData |
Always |
|
SaveControlState |
Always |
|
SaveViewState |
Always |
|
SavePageStateToPersistenceMedium |
Always |
|
Render |
Always |
|
OnUnload |
Always |
查看页面生命周期的底层细节,我们可以看到 ASP.NET 2.0 中提供的许多功能(例如主题和个性化)将在什么地方容易实现。例如,主题在 IntializeThemes事件中处理,而个性化数据将在 LoadPersonalizationData 中加载并稍后用于 ApplyPersonalization 方法。请注意,就哪一个 UI 元素将决定 Web 应用程序的最终外观和感觉而言,方法的顺序非常重要。
在以前写个一篇关于ASP.NET页面生命周期的草稿,最近又看了看ASP.NET,做个补充,看看页面初始过程到底是怎么样的
下面是ASP.NET页面初始的过程:
1. Page_Init();
2. Load ViewState;
3. Load Postback data;
4. Page_Load();
5. Handle control events;
6. Page_PreRender();
7. Page_Render();
8. Unload event;
9. Dispose method called;
下面对其中的一些过程作下描述:
1. Page_Init();
这个过程主要是初始化控件,每次页面载入执行这个初始过程,包括第一次和以后的Postback(这里说下Postback,其实就可以简单理解成用户点 击SUBMIT按钮之类的,把表单<Form>提交给服务器,这就是一次postback),在这里面可以访问控件,但是这里面的控件值不是我们期待的控件里面 的值,他只是一个控件的初始值(默认值),举例: 比如一个TextBox1,我们填入了"哈哈",在点击SUBMIT提交了页面后,在Page_Init()里面,我们访 问到的TextBox1.Text不是我们的"哈哈",而是开始的""空字符串,如果TextBox1在我们设计的时候提供了默认值,这里访问到的也就是提供的默 认值,为什么呢,这就要看下一个过程了.
对应的事件Page.Init
2. Load ViewState
这个过程是载入VIEWSTATE和Postback数据,比如我们上面的TextBox1,这时就赋了"哈哈",所以,在Post_Init()对控件赋值是无意义的,它都会 在这个过程里被改写,当然第一次页面载入例外,因为没有VIEWSTATE数据。
没有对应的事件
3.Load Postback data;
上面说了,Postback可以理解成用户提交表单数据,所以这里就是处理表单数据,当然这里要设计到控件的设计,一般情况不会要我们自己处理这 个过程,我们暂且略过. (在以前那篇关于ASP.NET页面生命周期的简单描述中,把这个过程和Load ViewState放在了一起,其实那是微软提供的生命周期过程,这里单独提出来是为了让大家明白这是一个单独的过程)
没有对应的事件
4. Page_Load();
这个过程也是每次页面载入时一定会执行的,但是注意和Page_Init的区别,上面已经涉及了,这里注意的是一般都会用到Page.IsPostBack,该 值指示该页是否正为响应客户端回发而加载,或者它是否正被首次加载和访问。
private void Page_Load(object sender, System.EventArgs e)
{
if(!Page.IsPostBack)
{
//第一次执行的CODE HERE
}
else
{
//用户提交FORM(即Postback)CODE HERE
}
//每次这里的都回执行CODE HERE
}
对应的事件Page.Load
5. Handle control events;
这个过程里,相应具体的控件事件,比如private void ListBox1_SelectedIndexChanged(object sender, System.EventArgs e)事件等等
没有对应的事件(我们自己的事件函数都包括在这个过程里比如上面的ListBox1_SelectedIndexChanged)
6. Page_
预先呈递对象,这里是在向用户程序呈现数据的倒数第二步,我估计提供这个过程的意义,也就是在这里能对控件属性等等要呈现给用户的数据进 行修改,这也是最后的修改,以前的修改(比如在Page_Init里面)都可能被覆盖.做完这了还会进行一个操作就是保存状态,即SaveViewState.
对应的事件时Page.PreRender
7. Page_Render();
大家可以在浏缆器里View->Source查看到,每个页面都有一个隐藏的<input>,这里面的"__VIEWSTATE"就是我们服务器写回来的页面状态信息, 在这个之前,服务器要呈现页面(也就是构造HTML格式的文件),就是从这个"__VIEWSTATE"里面获取的数据,当然大家也注意到了,这里有个Page.Render事件,我们可以添加自己的处理代码,也就是说我们又可以更改数据,不过这里推荐不要在这里修改,既然提供了PreRender,就应该在里面做最后的修改,当然这不是必须的,只是推荐!
对应的事件Page.Render
8. Unload event;
大家应该明白,当想服务器请求一个对象的时候,就会在内存里生成一个继承页面对象,也就是页面的类,它继承自System.Web.UI.Page.
当页面对象从内存中卸载时发生,将触发该事件.
对应的事件Page.Unload
9. Dispose method called;
销毁所有的对象.当从内存释放Page时发生,这是生存期的最后阶段。可能第8和9似乎有些模糊,不过我也没怎么搞清楚,待研究!
对应的事件Dispose
以上就是ASP.NET页面周期的描述。
注意上面灰色背景的文字,如果一个过程中有对应的事件,我们可以自己定义一个函数(当然先在MSDN中找到函数原型),然后在
InitializeComponent中向事件的链表上添加上去,像下面:
private void InitializeComponent()
{
this.Unload += new System.EventHandler(this.MainWebForm_Unload);
this.Load += new System.EventHandler(this.Page_Load);
this.Init += new System.EventHandler(this.Page_Init);
this.PreRender += new System.EventHandler(this.My_PreRender);
}
对于几个没有对应事件的过程,比如2.Load ViewState,我们可以重载Page的虚函数protected override void LoadViewState(objectsavedState);来添加自己的控制代码,不过切忌掉用基类的对应方法,比如:
protected override void LoadViewState(object savedState)
{
//自己处理VIEWSTATE
base.LoadViewState (savedState);
}
初学ASP.NET,请各位不吝赐教!
====================\
Asp.net2.0页面的生命周期
表格 1. ASP.NET 页面生存周期中的关键事件
|
阶段 |
页面事件 |
可重写方法 |
|---|---|---|
|
页面初始化 |
Init |
|
|
加载视图状态 |
LoadViewState |
|
|
处理回发数据 |
实现 IPostBackDataHandler 接口的任何控件中的 LoadPostData 方法 |
|
|
加载页面 |
Load |
|
|
回发更改通知 |
实现 IPostBackDataHandler 接口的任何控件中的RaisePostDataChangedEvent 方法 |
|
|
处理回发事件 |
控件所定义的任何回发事件 |
实现了 IPostBackEventHandler 接口的任何控件的 RaisePostBackEvent 方法 |
|
页面呈现前阶段 |
PreRender |
|
|
保存视图状态 |
SaveViewState |
|
|
呈现页面 |
Render |
|
|
卸载页面 |
Unload |
当一个获取网页的请求(可能是通过用户提交完成的,也可能是通过超链接完成的)被发送到Web服务器后,这个页面就会接着运行从创建到处理完成的一系列事件。在我们试图建立Asp.net页面的时候,这个执行周期是不必去考虑的,那样只会自讨苦吃。然而,如果被正确的操纵,一个页面的执行周期将是一道有效而且功能强大的工具。许多开发者在编写 Asp.net的页面以及用户控件的时候发现,如果知道整个过程中发生了什么以及在什么时候发生将对完成整个任务起到很重要的帮助作用。下面我就向大家介绍一下一个Asp.net页面从创建到处理完成过程中的十个事件。同时,也向大家展示如何在这些事件中添加自己的代码以达到预定的效果。
注意,我们只能在PreInit()事件中动态的设置themes 使用母版页时的特例 所以如果一个页有其相关联的母版页的话,那么在PreInit()事件里页中的所有控件都不会被初始化。而只有在Init()事件开始之后,你才能直接访问这些控件。为什么? 这 个原因就是内容页中的所有控件都包含在“ContentPlaceholder”里,而“ContentPlaceholder”其实就是母版页的一个子 控件。现在母版页被处理的过程就相当于内容页中的一个控件,我们早先提到过,除了Init()和Unload()之外的所有事件都是从最外面到最里面被激 发的。虽然页的PreInit()是第一个被触发的事件,但是用户控件和母版页是没有这个事件的,所以在页的Page_PreInit()方法中,母版页 和用户控件都不会被初始化,而是在Init()事件之后 接下来让我们来看一下Page_Init()事件之后控件的层次结构 在这个页面级的事件中,所有在设计时创建的控件都将被用默认值做初始化。例如,如果你有一个Text属性值为“Hello”的TextBox控件,则此时这个属性被设置。我们也可以在这里动态的创建控件。 这个事件仅仅发生在页级别的类中,用户控件和母版页没有这个事件 下面的代码示例了如何重写这个方法以增加你的自定义代码 |
在这个事件里,我们能读出控件的属性(在设计模式中设置的)。但是我们不能读出用户设置的值,因为得到用户设置的值是在LoadPostData()事件被激发之后。不过在这个事件中我们可以得到POST数据,如下
完成初始化页面OnInit事件后触发。 |
| 四.导入Viewstate数据(LoadViewState) |
| 在初始化事件后,所有控件只可以通过它们的ID被引用访问(因为还没有相应的DOM可使用)。在 LoadViewState这个事件中,所有的控件将获得它们的第一个属性:Viewstate属性。这个属性最终将被返回给服务器以判断这个页面是已经 被用户访问完毕还是仍然在被用户所访问。Viewstate属性以“名称/值”对的字符串方式被保存,它包含了控件的文本以及值等信息。该属性被存储在一 个隐藏的<input>控件的值属性里,在请求页面时被传递。这种方式比起Asp3.0的维持、判断页面状态的方式有了很大的进步啊。还有, 你可以重载LoadViewState事件函数来对相应的控件进行值设定。下图是一个例子: |
|
|

| 五.用LoadPostData处理Postback数据(LoadPostData) |
|
在页面创建的这个阶段,服务器对页面上的控件提交的表单数据(在Asp.net中称postback数据)进行处理。当一个页面提交一个表单时,框 架就在每个提交了数据的控件上执行一个IPostBackDataHandler接口操作。然后页面执行LoadPostData事件,解析页面,找到每 个执行了IpostBackDataHandler接口操作的控件,并用恰当的postback数据更新这些控件状态。Asp.net是通过用 NameValue集中的“名称/值”对和每个控件的唯一的ID匹配来实现这一操作的。所以,在Asp.net的页面上每个控件必须有一个唯一的ID,不 可以出现几个控件共有ID的情况。即使是用户自定义的一些控件,框架也会赋予它们各自唯一的ID的。在LoadPostData事件后,就要执行下面的 RaisePostDataChanged事件了。
在加载页面OnLoad事件前触发。可以在页面里面通过Page_OnPreLoad事件绑定 |
|
七.导入对象(OnLoad) Page_Load是事件绑定得方法 |
| 在Load事件中,对象都实例化了。所有的对象第一次被布置在DOM页面(在Asp.net中称控件树)里了并且可以通 过代码或是相关的位置被引用。这样,对象就可以很容易的从客户端获得诸如宽度、高度、值、可见性等在Html中的属性值。在Load事件中,当然还有像设 置控件属性等操作的发生。这个过程是整个生命周期中最重要、最主要的,你可以通过调用OnLoad来重载Load事件,图示如下: |
|
|

| 八.RaisePostBackChanged事件(RaisePostDataChangedEvent) |
| 就像在上面提到的那样,这个事件是发生在所有的控件执行了IPostBackDataHandler接口操作并被正确的 postback数据更新后的。在这个过程中,每个控件都被赋予一个布尔值来标志该控件有没有被更新。然后,Asp.net就在整个页面上寻找任何已被更 新过的控件并执行RaisePostDataChanged事件操作。不过,这个事件是要在所有的控件都被更新了以及Load事件完成后才进行的。这样就 保证了一个控件在被postback数据更新前,别的控件在RaisePostDataChanged事件中是不会被手动改变的。 |
| 九.处理客户端PostBack事件(RaisePostBackEvent) |
| 当由postback数据在服务器端引起的事件都完成后,产生postback数据的对象就执行 RaisePostBackEvent事件操作。可是会有这种情况,由于一个控件状态的改变使得它将表单返回给服务器或是用户点击了提交按钮使得表单返回 给服务器。在这种情况下应该有相应的处理代码来体现事件驱动这一面向对象(OOP)编程原则。由于要满足呈现给浏览器的数据的精确性要求,在一系列 postback事件中RaisePostBackEvent事件是最后发生的。 |
| 在postback过程中改变的控件不应在执行功能函数被调用后更新。也就是说,任何由于一个预期的事件而改变的数据应该在最终的页面上被反映出来。你可以通过修改RaisePostBackEvent函数来满足你的要求,图示如下: |
|
|

|
十.Page_OnLoadComplete 完成页面加载OnLoad事件后触发。 十一.预先呈递对象 |
|
可以改变对象并将改变保存的最后时刻就是这一步――预先呈递对象。这样,你可以在这一步对控件的属性、控件树结构等作出最后的修改。同时还不用考虑 Asp.net对其作出任何改变,因为此时已经脱离了数据库调用以及viewstate更新了。在这一步之后,对对象的所有修改将最终被确定,不能被保存 到页面的viewstate中了。你可以通过OnPreRender来重载这一步。 十二.完成预呈现(OnPreRenderComplete) 在完成预呈现OnPreRender事件后触发。这是完成页面呈现的最后一道关卡,在此之后,页面将无法再进行任何呈现上的改动。 十三.保存ControlState(SaveControlState) |
| 八.保存ViewState(SaveViewState) |
| 所有对页面控件的修改完成后viewstate就被保存了。对像的状态数据还是保留在隐藏的<input> 控件里面,呈现给Html的对象状态数据也是从这里取得的。在SaveViewState事件中,其值能被保存到viewstate对象,然而这时在页面 上控件的修改却不能了。你可以用SaveViewState来重载这一步,图示如下: |
|
|

| 九.呈递给Html(Render) |
| 运用Html创建给浏览器输出的页面的时候Render事件就发生了。在Render事件过程中,页面调用其中的对象将 它们呈递给Html。然后,页面就可以以Html的形式被用户的浏览器访问了。当Render事件被重载时,开发者可以编写自定义的Html代码使得原先 生成的Html都无效而按照新的Html来组织页面。Render方法将一个HtmlTextWriter对象作为参数并用它将Html在浏览器上以网页 的形式显示。这时仍然可以做一些修改动作,不过它们只是客户端的一些变化而已了。你可以重载Render事件,图示如下: |
|
|

| 十.销毁对象(Page_UnLoad) |
| 在呈递给Html完成后,所有的对象都应被销毁。在Dispose事件中,你应该销毁所有在建立这个页面时创建的对象。这时,所有的处理已经完毕,所以销毁任何剩下的对象都是不会产生错误的,包括页面对象。你可以重载Dispose事件。 |
| 全文总结 |
|
以上就是Asp.net页面生命周期中的几个主要事件。每次我们请求一个Asp.net页面时,我们都经历着同样的过程:从初始化对象到销毁对象。 通过了解Asp.net页面的内部运行机制,我相信大家在编写、调试代码的时候会更加游刃有余的。不过整个页面的生命周期的方法如下:
查看页面生命周期的底层细节,我们可以看到 ASP.NET 2.0 中提供的许多功能(例如主题和个性化)将在什么地方容易实现。例如,主题在 IntializeThemes 事件中处理,而个性化数据将在 LoadPersonalizationData 中加载并稍后用于 ApplyPersonalization 方法。请注意,就哪一个 UI 元素将决定 Web 应用程序的最终外观和感觉而言,方法的顺序非常重要。 AspNet2.0页面生命周期 |
页面框架通过如下过程处理aspx文件请求:
1:解析aspx文件,并创建一个控件树;
2:使用控件树动态实现一个继承自Page类的类或者控件 ;
3:动态编译类;
4:缓存编译类,以备后用;
5:动态创建一个编译类的实例。页面开始启动生命期,在这个过程中,页面将通过生命周期的不同阶段;=========================================================
页面经历了如下阶段【其中一些阶段标记为仅仅回传,是说只有在被回传到服务器时,页面才经历这些阶段】:
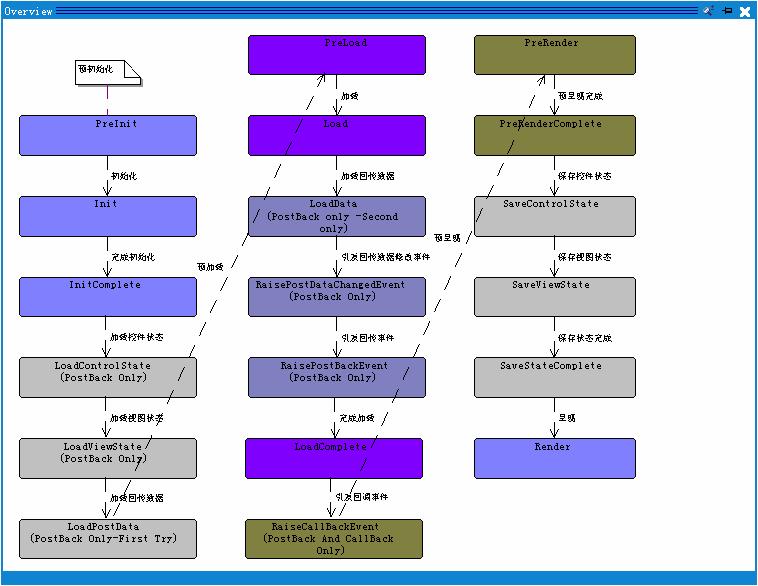
01:页面首先从QueryString或者Request对象的Form集合中获得回传数据。
02:页面检测回传数据集合(NameValueCollection,Form或者QueryString)是否包含一个键为_CallBackId的项。如 果存在,那么设置其Boolean属性IsCallBack为True,以便通过AspNet客户端回调机制,标明页面已经回传到服务器。
03:预初始化(PreInit):
在页面生命周期的预初始化阶段执行如下操作:
a:调用OnPreInit方法引发PreInit事件。
b:利用App_Themes目录中的内容初始化主题,以动态实现一个PageTheme类型的类,
编译该类,并创建一个编译类的实例,接着将实例赋值给它的PageTheme属性值
c:应用母版页
04:初始化(Init):
在页面生命周期的初始化阶段执行以下操作
a:递归初始化Controls集合中的控件。初始化包括设置这些控件的属性,
例如:Page,Id和NameContainer等
b:递归应用控件皮肤
c:调用OnInit方法以引发自身的Init事件,接着递归调用子控件的OnInit方法来引发它们的Init事件
d:调用自身的TrackViewState方法来启动自身的视图状态跟踪,接着递归调用子控件
的TrackViewState方法来启动它们的视图状态跟踪。
05:完成初始化(InitComplete):
页面调用OnInitComplete方法来引发InitComplete事件。该事件标明了初始化阶段的结束。
此时,页面Controls集合的所有控件都被初始化了。
06:加载控件状态(Load Control State)[PostBack Only]:
页面递归调用Control集合中控件的LoadControlState方法,这些控件已经调用了Page类
的RegisterRequiresControlState方法,以使用它们的控件状态。
07:加载视图状态(Load View State)[PostBack Only]:
页面首先调用自身的LoadViewState方法,接着递归调用Controls集合控件的LoadViewState方法,以允许它们加载它们的已经保存的视图状态。
08:加载回传数据(Load Post Data)[PostBack Only]:
页面调用实现IPostBackDataHandler接口的控件的LoadPostData方法,并将回传数据传递给该方法。每个控件的LoadPostDate方法都必须访问回传数据,并据此更新相应的控件属性。
例如:TextBox控件的LoadPostData方法将文本框的新值设置为TextBox控件的Text属性值。
09:预加载(PreLoad):
页面调用OnPreLoad方法以引发PreLoad事件。该事件表示页面生命周期将进入加载阶段。
10:加载(Load):
页面首先调用自身的OnLoad方法以引发自身的Load事件,接着递归调用Controls集合中控件的OnLoad方法以引发它们的Load事件。页面开发人员可以为Load事件注册回调,那么就可以通过编程将子控件添加到页面的Controls集合中。
11:加载回传数据(Load Post Data)[PostBack Only Second Try]:
页面调用控件的LoadPostBack方法。这些控件如果实现了IPostBackDataHandler接口,那么在加载阶段,它们已通过编程添加到Controls集合中。
12:引发回传数据修改事件(Raise Post Data Changed Event)[PostBack Only]:
页面调用控件的RaisePostDataChangeEvent方法,这些控件的LoadPostData方法返回true。
RaisePostDataChangeEvent方法引发了回传数据修改事件。例如:当文本框的新值与旧值
不同时,那么TextBox控件将引发该事件。
13:引发回传事件(Raise PostBack Event)[PostBack Only]:
页面调用控件的RaisePostEvent方法,这些控件相关的Html元素用于提交表单。例如,Button控件的相关Html元素将页面回传到服务器。控件的RaisePostBackEvent方法必须将回传事件映射到一个或多个服务器事件。例如,Button控件的 RaisePostBackEvent方法将事件映射到了服务器端事件Command和Click上。
14:完成加载(Load Complete):
页面调用OnLoadComplete方法来引发LoadComplete事件,这表示所有加载活动,包括加载回传数据,以及引发回传数据修改事件,并以更新控件自身的活动都完成了。
15:引发回调事件(Raise CallBack Event)(PostBack And CallBack Only):
页面调用控件的RaiseCallBackEvent方法。该控件可使用AspNet客户端回调机制来允许客户端方法(例如JavaScript函数)调用服务器端方法,而无需将整个页面回传给服务器。
RaiseCallBackEvent方法必须调用服务器端方法。如果页面的回传使用了客户端回调机制,那么页面将不会执行剩余的页面生命周期阶段。
16:预呈现(PreRender):
在页面生命周期这个阶段执行一下操作。
a:调用EnsureChildControls方法来确保在页面进入呈现阶段之前,创建其子控件。
b:调用自身的OnPreRender方法来引发PreRender事件。
c:递归调用Controls集合中控件的OnPreRender方法,以引发它们的PreRender事件。
17:预呈现完成(PreRender Complete):
页面调用OnPrerenderComplete方法来引发PreRenderComplete事件,这表示所有预呈现活动完成了。
18:保存控件状态(Save Control State):
页面递归调用Controls集合中控件的SaveControlState方法。这些控件已经调用了Page类的RegisterRequiresControlState方法来保存它们的控件状态。
19:保存视图状态(Save View State):
页面首先调用自身的SaveViewState方法,然后调用Controls集合中的SaveViewState方法,以允许它们来保存其视图状态。
20:保存状态完成(Save View Complete):
页面调用OnSaveStateComplete方法以引发SaveStateComplete事件,这表示所有状态保存活动都完成了。
21:呈现:
在页面生命周期的这个阶段执行一下操作。
a:创建一个HtmlTextWriter类实例,该实例封装了输出响应流
b:调用RenderCOntrol方法,并将HtmlTextWriter实例传递给该方法。
RenderControl方法递归调用子控件的RenderControl方法,以便允许每个控件能够呈现其
Html标记文本。子控件的Html标记文本组成了最终发送给客户端浏览器的Html标记文本。
新一篇: 单点登录在ASP.NET上的简单实现
在ASP.NET中,有很多种保存信息的对象.例如:APPlication,Session,Cookie,ViewState和Cache等,那么它们有什么区别呢?每一种对象应用的环境是什么?
为了更清楚的了解,我们总结出每一种对象应用的具体环境,如下表所示:
| 方法 | 信息量大小 | 保存时间 | 应用范围 | 保存位置 |
| Application | 任意大小 | 整个应用程序的生命期 | 服务器端 | |
| Session | 小量,简单的数据 |
用户活动时间+一段延迟时间(一般 为20分钟) |
单个用户 | 服务器端 |
| Cookie | 小量,简单的数据 | 可以根据需要设定 | 单个用户 | 客户端 |
| Viewstate | 小量,简单的数据 | 一个Web页面的生命期 | 单个用户 | 客户端 |
| Cache | 任意大小 | 可以根据需要设定 | 所有用户 | 服务器端 |
| 隐藏域 | 小量,简单的数据 | 一个Web页面的生命期 | 单个用户 | 客户端 |
| 查询字符串 | 小量,简单的数据 | 直到下次页面跳转请求 | 单个用户 | 客户端 |
| Web.Config文件 | 不变或极少改变的小量数据 | 直到配置文件被更新 | 单个用户 | 服务器端 |
1.Application对象
Application用于保存所有用户的公共的数据信息,如果使用Application对象,一个需要考虑的问题是任何写操作都要在Application_OnStart事件(global.asax)中完成.尽管使用Application.Lock和Applicaiton.Unlock方法来避免写操作的同步,但是它串行化了对Application对象的请求,当网站访问量大的时候会产生严重的性能瓶颈.因此最好不要用此对象保存大的数据集合. 下面我们做个在线用户统计的例子来说明这个问题:
(以文件的形式存放网站总访问量)
(1)Global.asax类 ![]() using System;
using System;
![]() using System.Collections;
using System.Collections;
![]() using System.ComponentModel;
using System.ComponentModel;
![]() using System.Web;
using System.Web;
![]() using System.Web.SessionState;
using System.Web.SessionState;
![]() using System.IO;
using System.IO;
![]()
![]() namespace WebAppCounter
namespace WebAppCounter
![]()
![]()
![]() {
{
![]()
![]() /**//// <summary>
/**//// <summary>
![]() /// Global 的摘要说明。
/// Global 的摘要说明。
![]() /// </summary>
/// </summary>
![]() public class Global : System.Web.HttpApplication
public class Global : System.Web.HttpApplication
![]()
![]()
![]() {
{
![]()
![]() /**//// <summary>
/**//// <summary>
![]() /// 必需的设计器变量。
/// 必需的设计器变量。
![]() /// </summary>
/// </summary>
![]() private System.ComponentModel.IContainer components = null;
private System.ComponentModel.IContainer components = null;
![]()
![]() private FileStream fileStream;
private FileStream fileStream;
![]() private StreamReader reader;//读字符流
private StreamReader reader;//读字符流
![]() private StreamWriter writer;//写字符流
private StreamWriter writer;//写字符流
![]()
![]() public Global()
public Global()
![]()
![]()
![]() {
{
![]() InitializeComponent();
InitializeComponent();
![]() }
}
![]()
![]() protected void Application_Start(Object sender, EventArgs e)
protected void Application_Start(Object sender, EventArgs e)
![]()
![]()
![]() {
{
![]() Application["CurrentGuests"]=0;//初始花为0;
Application["CurrentGuests"]=0;//初始花为0;
![]() fileStream = File.Open(Server.MapPath("counts.text"),FileMode.OpenOrCreate);//文件不存在,创建文件
fileStream = File.Open(Server.MapPath("counts.text"),FileMode.OpenOrCreate);//文件不存在,创建文件
![]() reader = new StreamReader(fileStream);//要读取的完整路径
reader = new StreamReader(fileStream);//要读取的完整路径
![]() Application["AllGuests"] = Convert.ToInt32(reader.ReadLine()); //从当前流中读取一行字符并将数据作为字符串返回
Application["AllGuests"] = Convert.ToInt32(reader.ReadLine()); //从当前流中读取一行字符并将数据作为字符串返回
![]() reader.Close();//关闭流
reader.Close();//关闭流
![]() }
}
![]()
![]() protected void Session_Start(Object sender, EventArgs e)//当用户访问网站时,在线用户+1,总访问数+1
protected void Session_Start(Object sender, EventArgs e)//当用户访问网站时,在线用户+1,总访问数+1
![]()
![]()
![]() {
{
![]() Application.Lock();//同步,避免同时写入
Application.Lock();//同步,避免同时写入
![]()
![]() Application["CurrentGuests"] =(int)Application["CurrentGuests"]+ 1;//总在线用户数
Application["CurrentGuests"] =(int)Application["CurrentGuests"]+ 1;//总在线用户数
![]() Application["AllGuests"] =(int)Application["AllGuests"]+ 1;//访问网站的总用户数
Application["AllGuests"] =(int)Application["AllGuests"]+ 1;//访问网站的总用户数
![]() fileStream = new FileStream(Server.MapPath("counts.text"),FileMode.OpenOrCreate,FileAccess.ReadWrite);//
fileStream = new FileStream(Server.MapPath("counts.text"),FileMode.OpenOrCreate,FileAccess.ReadWrite);//
![]() writer = new StreamWriter(fileStream);//实现一个写入流,使其以一种特定的编码向流中写入字符
writer = new StreamWriter(fileStream);//实现一个写入流,使其以一种特定的编码向流中写入字符
![]() writer.WriteLine(Application["AllGuests"].ToString());//把访问网站的总用户数再次写入到文件
writer.WriteLine(Application["AllGuests"].ToString());//把访问网站的总用户数再次写入到文件
![]() writer.Close();//关闭写入流
writer.Close();//关闭写入流
![]()
![]() Application.UnLock();//同步结束
Application.UnLock();//同步结束
![]() }
}
![]()
![]() protected void Application_BeginRequest(Object sender, EventArgs e)
protected void Application_BeginRequest(Object sender, EventArgs e)
![]()
![]()
![]() {
{
![]()
![]() }
}
![]()
![]() protected void Application_EndRequest(Object sender, EventArgs e)
protected void Application_EndRequest(Object sender, EventArgs e)
![]()
![]()
![]() {
{
![]()
![]() }
}
![]()
![]() protected void Application_AuthenticateRequest(Object sender, EventArgs e)
protected void Application_AuthenticateRequest(Object sender, EventArgs e)
![]()
![]()
![]() {
{
![]()
![]() }
}
![]()
![]() protected void Application_Error(Object sender, EventArgs e)
protected void Application_Error(Object sender, EventArgs e)
![]()
![]()
![]() {
{
![]()
![]() }
}
![]()
![]() protected void Session_End(Object sender, EventArgs e)//当前用户退出网站时,在线用户数量-1,
protected void Session_End(Object sender, EventArgs e)//当前用户退出网站时,在线用户数量-1,
![]()
![]()
![]() {
{
![]() Application.Lock();
Application.Lock();
![]() Application["CurrentGuests"] =(int)Application["CurrentGuests"] - 1;//总在线用户数量-1
Application["CurrentGuests"] =(int)Application["CurrentGuests"] - 1;//总在线用户数量-1
![]() Application.UnLock();
Application.UnLock();
![]()
![]() }
}
![]()
![]() protected void Application_End(Object sender, EventArgs e)
protected void Application_End(Object sender, EventArgs e)
![]()
![]()
![]() {
{
![]()
![]() }
}
![]()
![]()
![]() Web 窗体设计器生成的代码#region Web 窗体设计器生成的代码
Web 窗体设计器生成的代码#region Web 窗体设计器生成的代码
![]()
![]() /**//// <summary>
/**//// <summary>
![]() /// 设计器支持所需的方法 - 不要使用代码编辑器修改
/// 设计器支持所需的方法 - 不要使用代码编辑器修改
![]() /// 此方法的内容。
/// 此方法的内容。
![]() /// </summary>
/// </summary>
![]() private void InitializeComponent()
private void InitializeComponent()
![]()
![]()
![]() {
{
![]() this.components = new System.ComponentModel.Container();
this.components = new System.ComponentModel.Container();
![]() }
}
![]() #endregion
#endregion
![]() }
}
![]() }
}
![]()
bifek,2007-07-19 15:24:23
(2) WebForm1.aspx private void Page_Load(object sender, System.EventArgs e)
{
this.Label1.Text = "正在访问站点的用户数:" + Application["CurrentGuests"].ToString();
this.Label2.Text ="访问过站点的总用户数:" + Application["AllGuests"].ToString();
}
2.Session对象
Session用于保存每个用户的专用信息.她的生存期是用户持续请求时间再加上一段时间(一般是20分钟左右).S
ession中的信息保存在Web服务器内容中,保存的数据量可大可小.当Session超时或被关闭时将自动释放保存的数据信息.由于用户停止使用应用程序后它仍然在内存中保持一段时间,因此使用Session对象使保存用户数据的方法效率很低.对于小量的数据,使用Session对象保存还是一个不错的选择.使用Session对象保存信息的代码如下: //存放信息
Session["username"]="zhouhuan";
//读取数据
string UserName=Session["username"].ToString();
3.Cookie对象
Cookie用于保存客户浏览器请求服务器页面的请求信息,程序员也可以用它存放非敏感性的用户信息,信息保存的时间可以根据需要设置.如果没有设置Cookie失效日期,它们仅保存到关闭浏览器程序为止.如果将Cookie对象的Expires属性设置为Minvalue,则表示Cookie永远不会过期.Cookie存储的数据量很受限制,大多数浏览器支持最大容量为4096,因此不要用来保存数据集及其他大量数据.由于并非所有的浏览器都支持Cookie,并且数据信息是以明文文本的形式保存在客户端的计算机中,因此最好不要保存敏感的,未加密的数据,否则会影响网站的安全性.使用Cookie对象保存的代码如下: //存放信息
Response.Cookies["UserID"].Value="0001";
//读取信息
string UserID=Response.Cookies["UserID"].Value;
4.ViewState对象
ViewState 常用于保存单个用户的状态信息,有效期等于页面的生存期。ViewState容器可以保持大量的数据,但是必须谨慎使用,因为过多使用会影响应用程序的性能。所有Web服务器控件都使用ViewState在页面回发期音保存自己的状态信息。如果某个控件不需要在回发期间保存状态信息,最好关闭该对象的ViewState,避免不必要的资源浪费。通过给@Page指令添加“EnableViewState=false”属性可以禁止整个页面的ViewState。使用ViewState对象保存信息的代码如下。
//存放信息
ViewState["nameID"]="0001";
//读取信息
string NameID=ViewState["nameID"].ToString();
5.Cache对象
Cache对象用于在HTTP请求间保存页面或数据。该对象的使用可以极大地提高整个应用程序的效率。它允许将频繁访问的大量服务器资源存储在内存中,当用户发出相同的请求后服务器不再次处理而是将Cache中保存的信息返回给用户,节省了服务器处理请求的时间。此对象的实例是每个应用程序专用的,其生存期依赖于该应用程序的生存期。当重新启动应用程序时,将重新创建其Cache对象的实例。使用Cache对象保存信息的代码如下。 //存放信息
Cache["nameID"]="0001";
//存放信息
Cache.Insert("nameID","0001"1);
//读取信息
string NameID=Cache["nameID"].ToString(); 6.隐藏域
Hidden控件是属于HTML类型的服务器控件,使用此控件可以实现隐藏域的功能。其实此控件和其它服务器控件的使用没有太大区别,只是它不会在用户端的浏览器中显示,始终处于隐藏状态。但是每次页面提交的时候,此控件和其它服务器控件一同提交到服务器端,因此在服务器端可以使用Value属性获取或保存一些数据信息。使用Hidden控件保存信息的代码如下。
//存放信息
Hidden.Value="0001";
//获取信息
string NameID=Hidden.Value; 7.查询字符串
查询字符串的方式是将要传递的值连接在URL后面,然后通过Response.Redirect方法实现客户端的重定向。这种方式可以实现在两个页面之间传递信息。由于URL的长度有一定的限制,因此不能传递太大的信息,加外安全性也不是很好。
传递信息如下。
Response.Redirect("List.aspx?nameID=0001&gradeID=002");
//执行上面的语句后在IE地址栏显示的URL的代码如下。
http://localhost/List.aspx?nameID=0001&grade=002
//当跳转到List.aspx后,可以通过以下代码获得所传递的信息。
string NameID.GradeID;
NameID=Request.Params["nameID"];
GradeID=Request.Params["gradeID"];
6,QueryString多半是地址栏参数,到下一页使用,明文,无所谓安全;
除了以上介绍的几种对象外,还可以使用Context对象和Web.Config配置文件。它们也都可以实现保存用户信息的功能,在这里不再详细介绍。至于使用何种对象保存信息可以根据以下的原则进行选定:
viewstate/session/cache/application
单页级的自身状态的保存建议用viewstate,
用户级的重要的信息的保存建议用session(如每个用户的状态)
用户级的非重要性的信息的保存建议用cache
整个站级的状态的保存建议用application.或用singleton模式的全局对象
cache和session的用法相同,不过cache中的信息在内存紧张时会消失,所以cache的使用时需如下形式
if(cache["key"]==null)
{
//重新检索数据;
cache["key"]=检索到的数据;
}
所需数据=cache["key"]
全局变量的读写建议"加锁",不然会出现不正常的.
我对.NET技术不熟悉,因此对ViewState,Cache这两个功能不清楚,但可以对其他三个Cookie,Session,Application提供一些实践方面的建议.
1)cookie是大家最喜欢的一种存储方式,但不是好的存储方法,我的建议是在商业性网站开发中最好不用.典型的使用方法如下:
<%
Dim strUserID, strPassword, blnAutoLogin
strUserID = Request.Form("txtUserID")
strPassword = Request.Form("txtPassword")
blnAutoLogin = Request.Form("chkAutoLogin")
if blnAutoLogin = "on" then
'Save Username and password to cookie
Response.Cookies("Credentials")("userid") = strUserID
Response.Cookies("Credentials")("password") = strPassword
Response.Cookies("Address") = "123 Main Street"
End If
%>
2)session是一种比较好的使用方式,但是不要使用过大.比如在一个商城的网站中,只有customerID用session保存,其他都从数据库中获得数据.典型代码如下:
<%
Session.Contents("FavColour") = Request.Form("txtColour")
Response.write "Your colour has been saved"
%>
3)Application是一个全程对象,通常的一个应用是做counter,看了国内的许多代码,好象大家不喜欢用这个对象.典型代码如下:
<%
Application.Lock
Application("anotherVariable")=Application("anotherVariable")+1
Application.Unlock
Response.write Application("anotherVariable")
%>
我在开发时只用1个session作为用户的ID.
Application
1. Application用来保存所有用户共用的信息
2. 在Asp时代,如果要保存的数据在应用程序生存期内不会或者很少发生改变,那么使用Application是理想的选择。但是在Asp.net开发环境中我们把类似的配置数据放在Web.config中。
3. 如果要使用Application 要注意的是所有的写操作都要在Application_OnStart事件中完成(global.Asax),尽管可以使用Application.Lock()避免了冲突,但是它串行化了对Application的请求,会产生严重的性能瓶颈。
4. 不要使用Application保存大数据量信息
5. 代码:Application[“UserID”]=”test”;
String UserName=Application[“UserID”].ToString();
Session
1. Session用来保存每一个用户的专有信息
2. Session的生存期是用户持续请求时间加上一段时间(一般是20分钟左右)
3. Session信息是保存在Web服务器内存中的,保存数据量可大可小
4. Session超时或者被关闭将自动释放数据信息
5. 由于用户停止使用应用程序之后它仍在内存中存留一段时间,因此这种方法效率较低
6. 代码:Session[“UserID”]=”test”;
String UserName=Session[“UserID”].ToString();
Cookie
1. Cookie用来保存客户浏览器请求服务器页面的请求信息
2. 我们可以存放非敏感的用户信息,保存时间可以根据需要设置
3. 如果没有设置Cookie失效日期,它的生命周期保存到关闭浏览器为止
4. Cookie对象的Expires属性设置为MinValue表示永不过期
5. Cookie存储的数据量受限制,大多数的浏览器为4K因此不要存放大数据
6. 由于并非所有的浏览器都支持Cookie,数据将以明文的形式保存在客户端
7. 代码:Resopnse.Cookies[“UserID”]=”test”;
String UserName= Resopnse.Cookies [“UserID”].ToString();
ViewState
1. ViewState用来保存用户的状态信息,有效期等于页面的生命周期
2. 可以保存大量数据但是要慎用,因为会影响程序性能
3. 所有的Web服务器控件都是用ViewState在页面PostBack期间保存状态
4. 不需要则关闭 @page 里面设置EnableViewState=false
5. 代码:ViewState[‘”ID”]=”yiner”;
String ID =ViewState[“ID”].ToString();
Cache
1. Cache用于在Http请求期间保存页面或者数据
2. Cache的使用可以大大的提高整个应用程序的效率
3. 它允许将频繁访问的服务器资源存储在内存中,当用户发出相同的请求后
服务器不是再次处理而是将Cache中保存的数据直接返回给用户
4. 可以看出Cache节省的是时间—服务器处理时间
5. Cache实例是每一个应用程序专有的,其生命周期==该应用程序周期
应用程序重启将重新创建其实例
6. 注意:如果要使用缓存的清理、到期管理、依赖项等功能必须使用Insert 或者Add方法方法添加信息
7. 代码:Cache[‘”ID”]=”yiner”;或者Cache.Insert(“ID”,”test”);
String ID =Cache[“ID”].ToString();
Hidden
1. Hidden控件属于Html类型的服务器控件,始终处于隐藏状态
2. 每一次提交的时候它会和其他服务器控件一起提交到服务器端
3. 代码如下:Hidden.Value=”king”;
string id=Hidden.Value; 要使用Runat=server
1,ViewState多半存储本页内的信息,适用少量数据,具有基本安全性; 使用视图状态的优点是: a, 不需要任何服务器资源。视图状态包含在页代码内的结构中。 b, 简单的实现。 c, 页和控件状态的自动保持。 d, 增强的安全功能。视图状态中的值是散列的、压缩的并且是为 Unicode 实现而编码的,这意味着比隐藏域具有更高的安全性状态。 使用视图状态的缺点是: a, 性能。由于视图状态存储在页本身,因此如果存储较大的值,在用户显示页和发送页时,页的速度就可能会减慢。 b, 安全性。视图状态存储在页上的隐藏域中。虽然视图状态以哈希格式存储数据,但它可以被篡改。如果直接查看页输出源,可以看到隐藏域中的信息,这导致潜在的安全性问题。
2,QueryString多半是地址栏参数,到下一页使用,明文,无所谓安全;
3,Cookies需要在客户端存储少量信息,不需要较高的安全性; 使用 Cookie 的优点是: a, 不需要任何服务器资源。Cookie 存储在客户端并在发送后由服务器读取。 b, 简单。Cookie 是具有简单键值对的轻量的、基于文本的结构。 c,可配置到期时间。Cookie 可以在浏览器会话结束时到期,或者可以在客户端计算机上无限期存在,这取决于客户端的到期规则。 使用 Cookie 的缺点是: a, 大小受到限制。 b, 用户配置为拒绝接受。有些用户禁用了浏览器或客户端设备接收 Cookie 的能力,因此限制了这一功能。 c, 安全性。Cookie 可能会受到篡改。用户可能会操纵其计算机上的 Cookie,这可能意味着安全性会受到影响或者导致依赖于 Cookie 的应用程序失败。 d, 持久性。客户端计算机上 Cookie 的持久性受到客户端 Cookie 到期进程以及用户干预的制约。 e, Cookie 通常用于为已知用户自定义内容的个性化情况。在大多数此类情况中,Cookie 是作为“标识”而不是“身份验证”,所以在 Cookie 中只存储用户名、账户名或唯一用户 ID(例如 GUID)并使用它来访问站点的用户个性化结构是足够的了。
4,Session存储在会话状态变量中的理想数据是特定于单独的、短期的、敏感的数据,应该是安全的,但过多使用会降低服务其性能; 使用会话状态的优点是: a, 易于实现。会话状态功能易于使用。 b, 会话特定的事件。会话管理事件可以由应用程序引发和使用。 c, 持久性。放置于会话状态变量中的数据可以经受得住 Internet 信息服务 (IIS) 重新启动和辅助进程重新启动,而不丢失会话数据,这是因为这些数据存储在另一个进程空间中。 d, 平台可缩放性。会话状态对象可在多计算机和多进程配置中使用,因而优化了可缩放性方案。 e, 尽管会话状态最常见的用途是与 Cookie 一起向 Web 应用程序提供用户标识功能,但会话状态可用于不支持 HTTP Cookie 的浏览器。 使用会话状态的缺点是: a, 性能。会话状态变量在被移除或替换前保留在内存中,因而可能降低服务器性能。如果会话状态变量包含类似大型数据集的信息块,则可能会因服务器负荷的增加影响 Web 服务器的性能。
5,Application插入到应用程序状态变量的理想数据是那些由多个会话共享并且不经常更改的数据使用应用程序状态的优点是: a, 易于实现。应用程序状态易于使用。 b, 全局范围。由于应用程序状态可供应用程序中的所有页来访问,因此在应用程序状态中存储信息可能意味着仅保留信息的一个副本(例如,相对于在会话状态或在单独页中保存信息的多个副本)。 使用应用程序状态的缺点是: a, 全局范围。应用程序状态的全局性可能也是一项缺点。在应用程序状态中存储的变量仅对于该应用程序正在其中运行的特定进程而言是全局的,并且每一应用程序进程可能具有不同的值。因此,不能依赖应用程序状态来存储唯一值或更新网络园和网络场配置中的全局计数器。 b, 持久性。因为在应用程序状态中存储的全局数据是易失的,所以如果包含这些数据的 Web 服务器进程被损坏(最有可能是因服务器崩溃、升级或关闭而损坏),将丢失这些数据。 c, 资源要求。应用程序状态需要服务器内存,这可能会影响服务器的性能以及应用程序的可缩放性。应用程序状态的精心设计和实现可以提高 Web 应用程序性能。例如,如果将常用的、相关的静态数据集放置到应用程序状态中,则可以通过减少对数据库的数据请求总数来提高站点性能。但是,这里存在一种性能平衡。当服务器负载增加时,包含大块信息的应用程序状态变量就会降低 Web 服务器的性能。在移除或替换值之前,将不释放在应用程序状态中存储的变量所占用的内存。因此,最好只将应用程序状态变量用于更改不频繁的小型数据集。
6,Cache,.NET 为您提供了一个强大的、便于使用的缓存机制,允许您将需要大量的服务器资源来创建的对象存储在内存中。其生存期依赖于该应用程序的生存期。重新启动应用程序后,将重新创建 Cache 对象。他的作用比较丰富,机制也比较多,请参阅相关的资料。
Web Service安全机制探讨
http://hi.baidu.com/%D3%F1%D3%E3/blog/item/99f3ec4ac8fe832608f7ef57.html
net面试题大全(有答案) & asp.net面试集合
C#基础概念二十五问(转)
http://www.cnblogs.com/jiayong/archive/2008/01/07/1029138.html
.net工程师必懂题(笔试题目)转
http://www.cnblogs.com/jiayong/archive/2008/01/08/1030175.html
面向对象的3个基本对象相关推荐
- javascript”面向对象编程”- 1万物皆对象
javascript几乎成了如今web开发人员必学必会的一门语言,但很多人却只停在了一些表单验证等基础操作层面上,在面向对象语言大行其道的当下,我们需要去学习javascript的面向对象的知识,以便 ...
- python面向对象编程从零开始_Python面向对象编程从零开始,从没对象到有对象
原标题:Python面向对象编程从零开始,从没对象到有对象 欢迎关注天善智能 hellobi.com,我们是专注于商业智能BI,大数据,数据分析领域的垂直社区,学习.问答.求职,一站式搞定! 对商业智 ...
- java面向对象数组_Java面向对象的构造器与数组对象
Java开发离不开面相对象,那么面向对象如何来的?什么又是数组对象?今天小编就来与大家共同学习一下Java的面向对象的构造器与数组对象. 构造器:用于创建对象时执行初始化.当创建一个对象时eg:new ...
- Python快速入门(八)面向对象1:类、对象和封装
Python快速入门(八)面向对象1:类.对象和封装 1.类和对象 1)类的定义 2)对象的定义 3)类和对象的关系 4)类的设计 2.第一个面向对象案列 代码1 代码2 3.设置对象属性 4.ini ...
- Java_面向对象基础(类、对象、方法和构造函数)
Java的面向对象基础(类.对象.方法和构造函数) 面向对象的基本概念 面向对象的设计思想 什么是类 什么是对象 类的定义 设计面向对象的例子 步骤一:设计动物这个类 步骤二:创建具体的动物 步骤三: ...
- day16 初识面向对象编程(类与对象、构造函数与对象,类与类)
目录 一.面向对象和面向过程的区别 二.类与对象的概念 三.构造函数和对象的关系 三.类与类的关系:组合 四.类与类的关系:依赖 一.面向对象和面向过程的区别 面向过程:强调过程步骤 面向对象:强调对 ...
- 八、Java面向对象编程(类、对象、方法、重载、可变参数、作用域、构造器、this本质)
文章目录 Java面向对象编程(类.对象.方法.重载.可变参数.作用域.构造器.this本质) 一.类与对象 1. 类与对象的引出 2. 使用现有技术解决 3. 现有技术解决的缺点分析 4. 类与对象 ...
- Perl面向对象(3):解构——对象销毁
本系列: Perl面向对象(1):从代码复用开始 Perl面向对象(2):对象 Perl面向对象(3):解构--对象销毁 第3篇依赖于第2篇,第2篇依赖于1篇. perl中使用引用计数的方式管理内存, ...
- 面向对象的程序设计1 理解对象—— JS学习笔记2015-7-4(第75天)
面向对象的程序设计一-- 理解对象 转载于:https://www.cnblogs.com/zhangxg/p/4621520.html
- 子对象是什么java_面向对象编程(什么是对象)——java
一.什么是面向对象,什么是面向过 二.引入对象和类的概念 对象:是具体事物 如:小明 汽车 类: 是对对象的抽象(抽象 抽出象的部分) Person 先有具体的对象,然后抽象各个对象之间的部分,归纳出 ...
最新文章
- baidumaptrace.php,鹰眼Web API v2.0 | 百度地图API SDK
- RabbitMQ学习系列(五): RPC 远程过程调用
- ext js IE9显示白板 页面浏览器模式强制渲染IE8
- No-5.变量的命名
- ubuntu系统设置开机自启动
- android unable to instantiate activity componentinfo
- python通过函数类属性_函数作为类属性的赋值如何成为Python中的一个方法?
- 正则表达式确实是一种考验
- RK px30 配置ap6212 wifi bt流程记录
- 微信小程序:全新强大的恋爱话术微信小程序源码土味情话视频号or自媒体操作项目
- 【时间序列】时序资料及工具汇总:模型和常见库对比
- 微信公众平台 微接口 接口100 API100 接口大全
- Python OpenCV 读取USB摄像头报错问题解决
- JavaScript提取非行间样式
- 全志芒果派麻雀开发板----新建一个分区并挂载(1)
- 微信查询天气公众账号小记
- ssm毕设项目大学生比赛信息管理系统38iiq(java+VUE+Mybatis+Maven+Mysql+sprnig)
- 家族关系查询系统程序设计算法思路_数据结构课程设计--
- 如何写论文中的引言?
- E-Lin通用微服务平台介绍及性能比较
热门文章
- NanoHTTPD----SimpleWebServer处理请求过程
- Halcon形态学梯度
- autoware下ndt_mapping节点解读
- 伪静态URLRewrite学习笔记
- 计算机技术与移动支付的关系,移动支付的破与立
- 实现电路阻抗匹配的两个方法
- request.getLocale()
- Transformer最详细的原理加代码解读
- python 连接mysql报错:mysql.connector.errors.NotSupportedError: Authentication plugin ‘caching_sha2_passw
- Vector-常用CAN工具 - CANoe入门到精通_01