anchor free:CornerNet解读【目标检测】
CornerNet: Detecting Objects as Paired Keypoints (anchor free)解读
CSDN地址:https://blog.csdn.net/hancoder/article/details/94066206
知乎:https://zhuanlan.zhihu.com/p/71411741
文章目录
- 1.背景
- 1.1 论文亮点:
- 1.2 核心思想cornerNet
- 2.框架
- 2.1 输入
- 2.2 backbone:hourglass沙漏网络
- 2.3 Prediction Module
- 2.3.1 corner pool
- 2.3.2 角点概率+角点分组+位置修正
- 3.loss
- loss总式:
- 3.0 给角点赋label
- 3.1.detection loss
- 3.2.offset loss
- 3.3.group loss
- 3.4.训练
- 4.结果
- 5.cornerNet好处原因:
- 附1:glasshour沙漏网络
- 附2:多人姿态检测
- 附2.1 associative bedding
- 6.参考:
1.背景
之前目标检测器基本都是基于anchor来预测得分和坐标,如faster rcnn等。
cornerNet之前方法使用anchor的缺点:
- 为了有某anchor与gt有足够的IOU,anchor需要anchor太多,但是只有小部分anchor是与gt匹配的,也就是正负样本不平衡问题
- anchor引入了超参,如anchor数量大小、比率与特征图预测的stage。
1.1 论文亮点:
作者Hei Law,Jia Deng
- 将目标检测问题当做关键点检测问题:通过检测目标框的左上角和右下角两个关键点得到预测框,因此CornerNet中没有anchor的概念
- 使用一个分支输出embedding vector,帮助判断top-left与bottom-right之间的匹配关系
- 提出了Corner Pooling,因为检测任务的变化,传统的Pooling方法并不是非常适用该网络框架,自然界的大部分目标是没有边界框也不会有矩形的顶点
- 检测网络的训练是从头开始的,不基于预训练的分类模型。这使用户能够自由设计特征提取网络,不受预训练模型的限制。
1.2 核心思想cornerNet
本文主要思路其实来源于一篇多人姿态估计的论文。简要介绍一下姿态估计:基于CNN的2D多人姿态估计方法,通常有2个思路(Bottom-Up Approaches和Top-Down Approaches):
- Top-Down framework:就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,缺点是受人体检测框影响较大,代表算法有RMPE(alphapose);
- Bottom-Up framework:就是先对整个图片进行每个人体关键点部件的检测,再将检测到的人体部位拼接成每个人的姿态,代表方法就是openpose。
CornerNet中anchor的提出是受了Newell的人体姿态检测的影响。在Newell的Associative Embedding: End-to-End Learning for Joint Detection and Grouping这篇论文里面,他提出了人体姿态检测的一站式的bottom-up方法, 可以用于多人姿态检测和目标分割。Associative Embedding有如下特点:
- 虽然仍然使用的是bottom-up的方式,但是在此之前多人姿态检测方法大多用的是先检测关节点,然后分组;目标分割是检查相关像素然后分组;多目标追踪是检测个体然后分成不同轨迹。所以这些方法一般都是Two-stage的流程。但是这种方法不是最优的,因为检测和分组是密切相关的。比如在多人姿势识别中,相同的特征图被用作识别手腕和肘部,这也暗示了无论是手腕还是肘部都属于同一个肢体。
- 而Newell认为可以将两个阶段用嵌入向量(Embedding vector)连接起来,将检测和分组合并到一个过程,构建完全端到端网络的过程(简言之就是可以合并loss)。核心思想是为每个检测(物体)引入一个编码向量,编码被用作分组tag。有相同tag的检测属于同一group。
核心思想1:CornerNet基于Associative Embedding中预测人体关节点的想法,把关节点换成anchor的左上点和右下点,那么我们就将画anchor框的方式转变为左上角(top-left角点)和右下角(bottom-right角点),而之前目标检测算法是用anchor的中心点和宽、高来描述anchor。这个想法的实现不是很难,之前的方法我们可以想到全卷积FCN,不断卷积,输出和输入图像相同大小的卷积图,让通道数等于类别即可,我们就知道了每个像素点对应的类别概率。cornerNet中也是大概这种思路,最后通道数为:有左上角点和右下角点2种可能性×每种角点的每个类别的概率。实际操作的时候不同之处只是把2×C个串联通道分成了两个并联的C通道,即最后预测了两个corner角点heatmaps来确定anchor:在每个角点heatmap有C个通道,代表C个类(不含背景类),heatmap大小是H×W。既然是类,代表就可以通过这个heatmap来表示每个像素上对应类别的概率。如果加上一个mask,即有了真值ground truth,那么我们可以很容易算出预测值与真实值之间的差距,让网络通过loss不断学习从而形成好的预测结果。
核心思想2:那么,这就遇到了另一个问题----哪两个角点组成一个anchor。作者在associative embedding论文中受到了启发,检测环节直接给检测结果编号,表明它属于哪个物体,所得到的这些编号标签就代表了分组。如下图,绿色中最高的概率形成了坐框,橙色中最高的概率形成了右框。这个部分loss的设计初看可能有些困难,但我们现在只需要知道我们的label是很好赋的即可,让loss促使同一物体有相同标签,不同物体标签不同。还需注意的是如果简单地编号123…7,那么如果我们用平方和MSE进行计算的话,1和7的差距明显比1和2的差距大,所以我们需要在loss上面下点功夫,让编号标签统一认为距离超过1即是不同物体,超过1loss不再增加。loss的设计后面再讲。
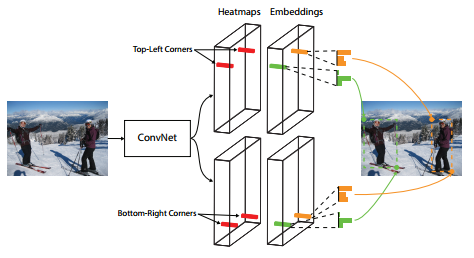
核心思想3:上面的分析似乎是在输入图像大小==输出特征图大小的基础上进行的,这无疑会消耗电脑的内存,增加训练成本,如何让输出图像小一点也能达到差不多的效果呢?作者给出的思路是offset,即让网络学习偏移量大小。详见loss部分。
2.框架
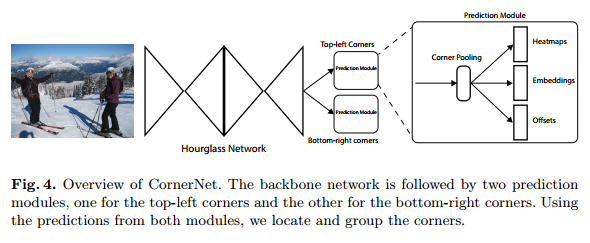
简单看一下框架。最后那个放大框只是放大了左上角点的模块,右下角点也有同样的结构。下面从输入分析框架。
2.1 输入
网络输入的图像大小为511×511,通过stride=2,channel=128的7×7conv和stride=2,channel=256的residual block,共下采样4倍,输入到backbone中的图像大小是128×128×256。这样预测结果像素与像素之间就不对应了,对此解决方法是后面的offset loss
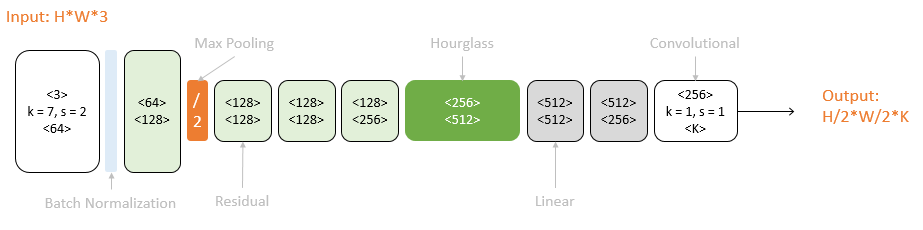
2.2 backbone:hourglass沙漏网络
特征提取网络也就是Backbone使用的是Hourglass网络,这也是从人体姿态估计处借用来的灵感。沙漏网络在关键点检测上已经证明了其有效性。
沙漏网络即一系列降采样+一系列上采样恢复到输入尺寸,下采样使计算复杂度降低,上采样采用的是最近邻上采样,其中还包含了skip layer,即residual模块用以补充下采样maxpooling丢失的信息。其中没有使用最大池化,而是使用了步长为2的卷积进行下采样了5倍。通道数依次是{256,384,384,384,512}。整个hourglass network的深度是104层。
沙漏结构![]()
本文的backbone是两个Hourglass网络进行串联拼接stack,两个网络的总深度是104。在第一个沙漏网络的输入和输出上添加了3×3的conv+BN,对应元素相加后接着一个Relu和residual。这个结果作为第二个沙漏网络的输入。这里读起来有点混乱,未能弄清。我猜测是不是输入作用3×3作为res分支,另外一个分支经过一系列conv后最后用3×3,然后两个分支相加,不过这不是什么重点。了解其思想借鉴了resnet即可。
不像FPN等,沙漏网络只使用最好一层特征图进行预测,没有在多层上预测。
沙漏模块残差结构![]()
2.3 Prediction Module
网络有两个分支,一个分支预测Top-left Corners,另一个预测Bottom-right corners。下面图相当于只画出了Top-left Corners。
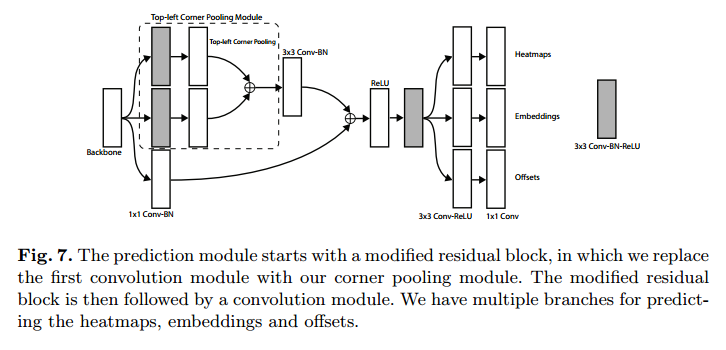
首先一条分支进入Top-left Corners,另一条分支是右下角点。每个分支又分为3个分支:1个分支的作用类似于res模块,另外两个分支是corner pool。
2.3.1 corner pool
CornerPool这是一种新型的池化层,可帮助卷积网络更好地定位边界框的角点。 原理:边界框的一角通常在目标之外,参考下图圆形典型的情况,角点明显不在物体上。

在很多情况下,角点不能根据当前的信息进行定位。相反,为了确定像素位置是否有左上角,我们需要水平地向右看目标的最上面边界,垂直地向底部看物体的最左边边界,这样才能判断当前点能不能代表框的坐上点。 这个过程即corner pooling layer:
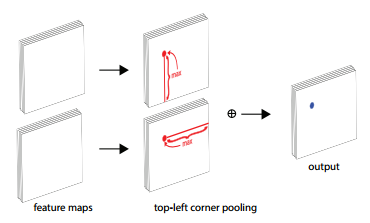
简单概括即当前点的值=max{ 该点右面/下面的所有点 }。有个方向计算后的特征图元素相加。可以结合下图验证一下。
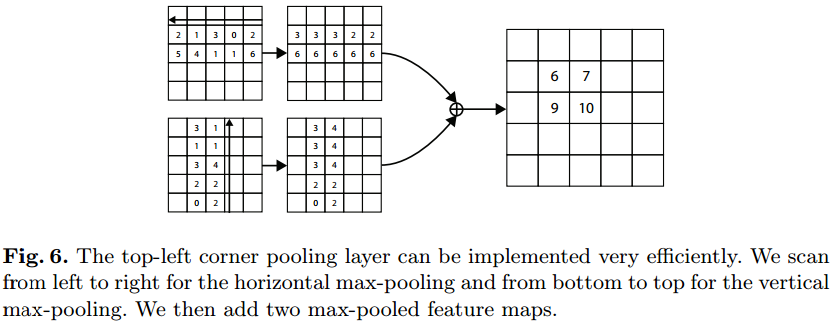
2.3.2 角点概率+角点分组+位置修正
在上面corner pool相加的结果上,即上面三个分支合并后又重新分为3个分支:heatmaps用于预测哪些点最有可能是Corners点;embeddings主要预测每个点所属的目标;最后的offsets用于对点的位置进行修正,下面进行详细介绍
- heatmaps:输出预测顶点信息,可以用维度为C×H×W的特征图表示,其中C表示目标的类别(注意:没有背景类),这个特征图的每个通道都是一个mask,mask的每个值(范围为0到1)表示该点是顶点的分数;
- embeddings:用来对预测的corner点做group,也就是找到属于同一个目标的左上角角点和右下角角点,预测每个点所属的目标;受启发于 在人体姿势识别中,Associative Embedding:先检测出人的身体组件joint和每个组件joint的编码向量embedding。组合组件joint的依据编码向量的距离。如果坐上角点和右下角点同属于一个物体,那么他俩直接的编码距离应该小。不属于一个物体编码距离应该大。
- offsets:用来对预测框做微调,这是因为从输入图像中的点映射到特征图时有量化误差,offsets就是用来输出这些误差信息。
可以结合loss函数理解
3.loss
loss总式:
用的是Adam算法
L=Ldet+αLpull+βLpush+γLoffL=L_{det}+\alpha L_{pull}+\beta L_{push}+\gamma L_{off} L=Ldet+αLpull+βLpush+γLoff
α=0.1,β=0.1,γ=1\alpha=0.1,\beta=0.1,\gamma=1α=0.1,β=0.1,γ=1
但是算loss之前必须先了解label是如何赋的,才能计算预测值与真值之间的差距:
3.0 给角点赋label
在论文第六页有如下描述:
对于各个角点,只有一个真值gt是“正位置”positive location,而其他所有的位置(角点)都是负的。在训练过程中,我们并不是同等地惩罚负位置,而是减少了在正位置附近(一个圆半径范围)的负位置的惩罚。这么做的原因是如果一对角点接近他们各自的真值位置,即使没有和正位置完全一对一像素匹配,但在正位置附近也可以推测出来一个好的框,这个框与gt框的IOU足够大。而这个半径r是一个变值,他的作用类似于faster rcnn中的赋label规则:anchor如果与真值box的IOU大于一个阈值0.7,那么认为这个anchor就是正的。
如下图,红色实线框是ground truth,绿色虚线是一个预测框,可以看出这个预测框的两个角点和ground truth并不重合,但是该预测框基本框住了目标,因此也是很好的预测框。我们要将“还不错的框”和“错的框”区别,这就是为什么要对不同负样本点的损失函数采取不同权重值的原因。

实现思路是只要真值框与预测框的交并比IOU大于一个阈值t就可以认为他是不错的角点,这个过程是通过在真值像素上设置半径r实现的。这样只要让阈值t大于0.7,即可求得半径r。即半径是根据圆圈内的角点组成的框和ground truth的IOU值大于0.7而设定的。在半径范围内的y值符合高斯分布:
另σ=13rσ=\frac13rσ=31r,即可根据 e−x2+y22σ2e^{-\frac {x^2+y^2}{2σ^2}}e−2σ2x2+y2给正位置附近的负位置赋label。(简单验证一下x=0,y=0时应该赋label=1)
3.1.detection loss
检测loss即第一个分支的分类loss借鉴了focal loss。
Ldet=−1N∑c=1C∑i=1H∑j=1W={(1−pcij)αlog(pcij)if:ycij=1(1−ycij)β(pcij)αlog(1−pcij)otherwiseL_{det}=\frac {-1}N\sum_{c=1}^C\sum_{i=1}^H\sum_{j=1}^W= \begin{cases} (1-p_{cij})^α log(p_{cij}) & if :y_{cij} = 1 \\ (1-y_{cij})^β (p_{cij})^α log(1-p_{cij})& otherwise \end{cases} Ldet=N−1c=1∑Ci=1∑Hj=1∑W={(1−pcij)αlog(pcij)(1−ycij)β(pcij)αlog(1−pcij)if:ycij=1otherwise
- pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,
- ycij表示对应位置的ground truth,
- N表示图中目标的数量。
- ycij=1时候的损失函数容易理解,就是focal loss,α参数用来控制难易分类样本的损失权重;有focal loss成分不懂的可以读几行下下段的内容。
- ycij等于其他值时即表示(i,j)点不是类别c真值的目标角点,照理说此时ycij应该是0(大部分算法都是这样处理的),但是这里ycij不是0,而是如之前介绍的用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和focal loss的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积IOU,
focal loss理解:
- y=1时,
- p越大,log越小,1-p越小,loss越小。被正确样本小的权重,大概效率相当于学习率变小。
- p越小,log越大,1-p越大,loss越大。给错误样本更大的权重,大概效果相当于学习率变大。
- y=otherwise时,
- p越小,1-p越大趋近1(log越小),p×log(1-p)越小。即正确分类loss小
- p越大,1-p越小趋近0(log越大),p×log(1-p)越大。即错误分类loss大
- 如果y接近gt,y越大,1-y越小,即loss变小,gt附近的模棱两可都可以,因为预测box和gt的IOU大于一个阈值即可
- 如果y远离gt,y越小,1-y越大,即loss变大,离gt 远的像素要准确分类,一旦原理gt角点太远,会造成预测box与gtbox的IOU太少
3.2.offset loss
这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而这里的offset是表示在取整计算时丢失的精度信息:
从输入图像到特征图之间会有尺寸缩小,取整会带来精度丢失,这尤其影响小尺寸目标的回归,Faster RCNN中的 ROI Pooling也是有类似的精度丢失问题,在Faster rcnn中的解决方式是:保留小数+插值=AlignPool。
假设缩小倍数是n(下采样因子),那么输入图像上的(x,y)点对应到特征图上位置为:(⌊xkn⌋,⌊ykn⌋)(\left\lfloor\frac{x_k}n\right\rfloor,\left\lfloor\frac{y_k}n\right\rfloor)(⌊nxk⌋,⌊nyk⌋)
角点k的精度损失o_k为:
ok=(xkn−⌊xkn⌋,ykn−⌊ykn⌋)o_k=(\frac{x_k}n-\left\lfloor\frac{x_k}n\right\rfloor, \frac{y_k}n-\left\lfloor\frac{y_k}n\right\rfloor) ok=(nxk−⌊nxk⌋,nyk−⌊nyk⌋)
所以通过公式2计算offset,然后通过公式3的smooth L1损失函数监督学习该参数,和常见的目标检测算法中的回归支路类似。L1函数能防止梯度爆炸。
Loff=1N∑k=1nSmoothL1Loss(ok,o^k)L_{off}=\frac 1N \sum_{k=1}^n SmoothL_1Loss(o_k,\hat o_k) Loff=N1k=1∑nSmoothL1Loss(ok,o^k)
N是目标个数,预测了一套左上角点的offset,还有一套右上角点的offset
3.3.group loss
这部分是受associative embedding那篇文章的启发,简而言之就是**基于不同角点的embedding vector之间的距离找到每个目标的一对角点,如果一个左上角角点和一个右下角角点属于同一个目标,那么二者的embedding vector之间的距离应该很小。**不同目标预测出来的embedding值应当尽可能地远 。
下面的引用的意思是计算量应该尽可能地少;不同物体的标签只要表明不同即可,即之前提到的MSE大小的问题。
associative embedding:为了减少计算量,我们应该避免直接计算每一对关节点之间的损失,相应的,我们对每个人都产生了一个reference embedding,reference embedding的生成方法就是对人的关节点的embedding值取平均。有了reference embedding后,
对于单个人来说,我们计算每个关节点预测的embedding和reference embedding的平方距离;
对于两个不同的人来说,我们比较他们之间的reference embedding,
随着它们之间距离的增加,惩罚将以指数方式降为0. 接下来,我们对这一过程进行形式化。
embedding这部分的训练是通过两个损失函数实现的,
Lpull=1N∑k=1N[(etk−ek)2+(ebk−ek)2],Lpush=1N(N−1)∑kN∑j=1J≠kNmax(0,△−∣ek−ej∣)L_{pull}=\frac 1N\sum_{k=1}^N [(e_{tk}-e_k)^2 + (e_{bk}-e_k)^2],\\ L_{push}=\frac 1{N(N-1)}\sum_k^N\sum_{j=1 \\J≠k}^Nmax(0,△-|e_k-e_j|) Lpull=N1k=1∑N[(etk−ek)2+(ebk−ek)2],Lpush=N(N−1)1k∑Nj=1J̸=k∑Nmax(0,△−∣ek−ej∣)
- etk表示属于k类目标的左上角角点的embedding vector,
- ebk表示属于k类目标的右下角角点的embedding vector,
- ek表示etk和ebk的均值。
- 实验中△=1
- Lpull用来缩小属于同一个目标(k类目标)的两个角点的embedding vector(etk和ebk)距离。
- Lpush用来扩大不属于同一个目标的两个角点的embedding vector距离。
embedding loss的理解:
为了更透彻理解这部分,我想先给出人体姿势associative embedding论文的loss函数,同本文一样这部分loss分别pull和push两部分。图中有n个人,每个人有k个节点标签组成姿势。xnk代表第n个人第k个节点的坐标值。k代表每个人有k个节点,hˉn\bar hnhˉn为代表第n个人节点标签的平均值。虽然我没有看这部分代码,但我想hˉn\bar hnhˉn应该是学习处理的吧?但也通过gt给了一些group的信息。这样loss的前半部分就通过训练使hnk与hˉn\bar hnhˉn接近,即第n个人的节点的预测标签值应该趋近于第n个人标签的真值平均值。而后半部分联想e-x图像,x越大总体越小,即想让任两个人的标签的平均值尽可能相差地大。但e-x的斜率是逐渐减少的,x到一定程度后就已经接近0了,所以训练会让两个人的标签平均值相差一些即可(超过1)。

继续分析本文的loss函数
Lpull=1N∑k=1N[(etk−ek)2+(ebk−ek)2],Lpush=1N(N−1)∑kN∑j=1J≠kNmax(0,△−∣ek−ej∣)L_{pull}=\frac 1N\sum_{k=1}^N [(e_{tk}-e_k)^2 + (e_{bk}-e_k)^2],\\ L_{push}=\frac 1{N(N-1)}\sum_k^N\sum_{j=1 \\J≠k}^Nmax(0,△-|e_k-e_j|) Lpull=N1k=1∑N[(etk−ek)2+(ebk−ek)2],Lpush=N(N−1)1k∑Nj=1J̸=k∑Nmax(0,△−∣ek−ej∣)
N代表gt框的个数,ek代表第k个框左上和右下编码向量(标签值)平均值。△=1。
对于pull函数:即让etk和ebk接近于ek,趋向于相同值,这样左上和右下标签值指向同一标签,被分作一个框。
对于push函数:有N个gt框,作者想让gt框两两作差,实现不同框的标签值不同,即有N(N-1)个差值。△=1,k和j是不同值,那么训练让不同的框的左上右下标签【平均值】|ek-ej|相差最少1以上。因为两个框之间标签的距离大小是无必要很大的,只要距离大于1让网络可以得出不是相同框的结论即可。即,如果ek和ej相差1以内,那么max函数的结果是1-|ek-ej|是一个大于0的数,loss还会让训练继续使loss趋向于0。当ek和ej相差1以上,1-|ek-ej|小于0,max整体的结果恒为0,所以相当于ek和ej相差1以后网络不再关心这两者的差值,转为关心其他两两框的差值。但其实这个过程是同步的。
3.4.训练
没有预训练,输入511×511,输出128×128
α=0.1,β=0.1,γ=1是各个L的权重。α和β比1大效果会不好
49batchsize,10GPU。
4.结果
在MS COCO上实现了42.1%的AP
5.cornerNet好处原因:
我们假设了两个原因,为什么检测角点会比检测边界框中心或proposals更好。
- 1)anchor boxes的中心点难以确定,是依赖于目标的四条边的,但是顶点却只需要目标框的两个边,所以角点更容易提取,而且还使用了corner pooling,因而表现比anchor好。
- 2)采用了更加高效的空间检测框机制,顶点可以更有效地提取离散的边界空间,这里只使用O(w∗h)个角点就代表了O(W2∗h2)的可能检测框anchor box。
附录:
附1:glasshour沙漏网络
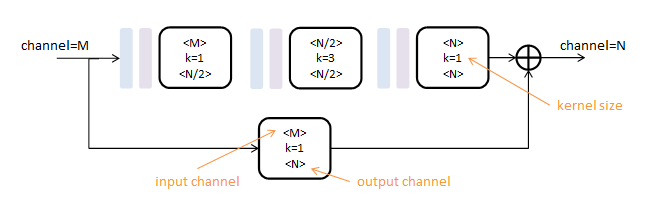
本文使用的初级模块称为Residual Module,得名于其中的旁路相加结构(在这篇论文中2称为residual learning)
第一行为卷积路,由三个核尺度不同的卷积层(白色)串联而成,间插有Batch Normalization(浅蓝)和ReLU(浅紫);
第二行为跳级路,只包含一个核尺度为1的卷积层;如果跳级路的输入输出通道数相同,则这一路为单位映射。
所有卷积层的步长为1,pading为1,不改变数据尺寸,只对数据深度(channel)进行变更。
Residual Module由两个参数控制:输入深度M和输出深度N。可以对任意尺寸图像操作。
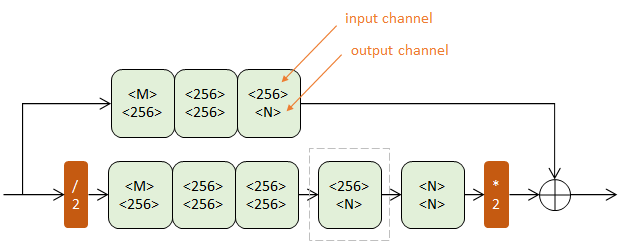
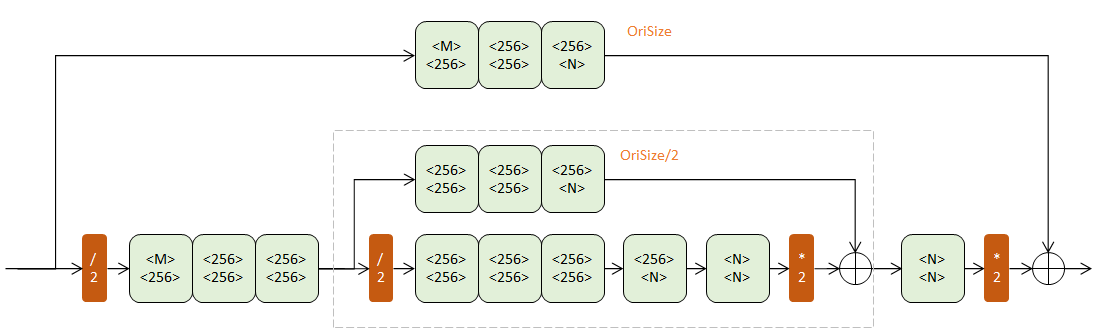
上下两个半路都包含若干Residual模块(浅绿),逐步提取更深层次特征。但上半路在原尺度进行,下半路经历了先降采样(红色/2)再升采样(红色*2)的过程。
降采样使用max pooling,升采样使用最近邻插值。
一阶Hourglass
二阶Hourglass
四阶Hourglass
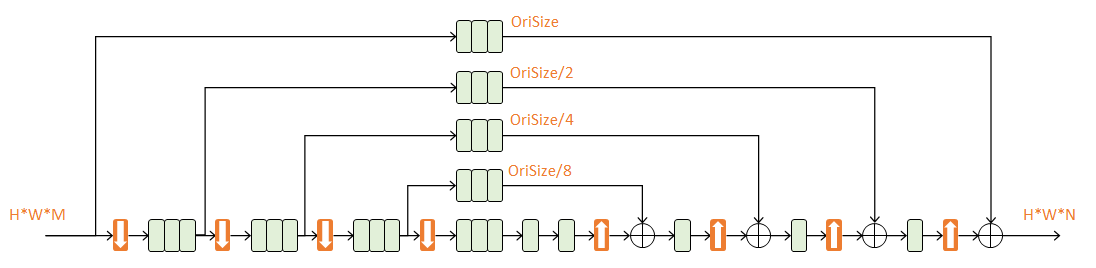
每次降采样之前,分出上半路保留原尺度信息;
每次升采样之后,和上一个尺度的数据相加;
两次降采样之后,使用三个Residual模块提取特征;
两次相加之间,使用一个Residual模块提取特征。
附2:多人姿态检测
附2.1 associative bedding
这里主要引用其他解读文章较为出色的总体话语。
为了将检测结果对应到个人,作者使用非极大值抑制(non-maximun suppression)来取得每个关节heatmap峰值,然后检索其对应位置的标签,再比较所有身体位置的标签,找到足够接近的标签分为一组,这样就将关节点匹配单个人身上
为了减少运算量,我们应该避免直接计算每一对关节点之间的损失,相应的,我们对每个人都产生一个reference embedding,reference embedding的生成方法就是对人的关节点的embedding值取平均。有了reference embedding后,对于单个人来说,我们计算每个关节点预测的embedding和reference embedding的平方距离;对于两个不同的人来说,我们比较他们之间的reference embedding,随着它们之间距离的增加,惩罚将以指数方式降为0. 接下来,我们对这一过程进行形式化。
6.参考:
Hourglass:https://blog.csdn.net/shenxiaolu1984/article/details/51428392
https://zhuanlan.zhihu.com/p/53407590
anchor free:CornerNet解读【目标检测】相关推荐
- 解读目标检测新范式:Segmentations is All You Need
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 多年来,基于候选区域网络(RPN)的现有模型在目标检测任务中得到了 ...
- 【深度学习】CornerNet: 将目标检测问题视作关键点检测与配对
前言: CornerNet于2019年3月份提出,CW近期回顾了下这个在当时引起不少关注的目标检测模型,它的亮点在于提出了一套新的方法论--将目标检测转化为对物体成对关键点(角点)的检测.通过将目标物 ...
- ECCV 2018 | CornerNet:目标检测算法新思路
本文为极市平台原创文章,转载请附原文链接: https://blog.csdn.net/Extremevision/article/details/82799308 ----------------- ...
- python ssd目标检测_解读目标检测之SSD:Single Shot MultiBox Detector
注:md文件,Typora书写,md兼容程度github=CSDN>知乎,若有不兼容处麻烦移步其他平台,github文档供下载. 发表在CSDN:https://blog.csdn.net/ha ...
- CornerNet: 将目标检测问题视作关键点检测与配对
前言: CornerNet于2019年3月份提出,CW近期回顾了下这个在当时引起不少关注的目标检测模型,它的亮点在于提出了一套新的方法论--将目标检测转化为对物体成对关键点(角点)的检测.通过将目标物 ...
- 详细解读目标检测经典算法-SSD
学习目标: 知道SSD的多尺度特征图的网络 知道SSD中先验框的生成方式 知道SSD的损失函数的设计 目标检测算法主要分为两类: Two-stage方法:如R-CNN系列算法,主要思路就是通过Sele ...
- FoveaBox:目标检测新纪元,无Anchor时代来临!
点击我爱计算机视觉标星,更快获取CVML新技术 目标检测的任务是"分类"并从图像中"定位"出物体,但长久以来,该领域的工作大多是这样:生成可能包含目标的区域,然 ...
- 13篇基于Anchor free的目标检测方法
内容简介:作者 | 黄浴 本文转载自:http://mp.weixin.qq.com/s?__biz=MzI5MDUyMDIxNA==&mid=2247489025&idx=2& ...
- FoveaBox:目标检测新纪元,无Anchor时代来临 | 技术头条
作者 | CV君 转载自我爱计算机视觉(ID:aicvml) 目标检测的任务是"分类"并从图像中"定位"出物体,但长久以来,该领域的工作大多是这样:生成可能包含 ...
- 目标检测系列(七)——CornerNet:detecting objects as paired keypoints
文章目录 摘要 1.引言 2.相关工作 3.CornerNet 3.1 概况 3.2 检测角点 3.3 角点的分组 3.4 Corner Pooling 3.5 沙漏网络 论文链接: https:// ...
最新文章
- Spring Hibernate JPA 联表查询 复杂查询
- 使用eclipse创建Struts2项目
- io在Linux,在Linux进行IO的正确姿势
- 建设有竞争力的APP开发团队
- ocp 042 第六章:管理用户安全性
- es6箭头函数(墙裂推荐)
- hadoop安全模式
- app.vue里使用data_在电脑使用讯飞有声,通过python自动化朗读
- ff7重制版青魔法_狂父重制版发布+妖精的尾巴首次打折¥244+最终幻想4解锁国区新增中文...
- js 验证文本框为数字的正则表达式
- 计算机端口详解(总结)
- 送示波器?送各色示波器设计!
- Minecraft 1.12.2模组开发(二十一) 物品点击事件(发射火球、召唤生物)
- Daftart.ai:人工智能专辑封面生成器
- html格式转换word清除格式,Word2010怎么清除格式?word清除格式(图文)教程
- 20180818牛客小白月赛6.A
- 计算机视觉到底需要学什么?怎么快速入门?
- 世纪性难题:剪不断、理还乱的开发测试关系
- 淘宝小部件在 2021 双十一中的规模化应用
- 微积分小课堂:积分(从微观趋势了解宏观变化)