uci数据集中的缺失数据_从uci早期糖尿病风险预测数据集中创建分类器
uci数据集中的缺失数据
To begin we must first go and download the dataset from the UCI dataset repository. The link for the dataset can be found below.
首先,我们必须首先从UCI数据集存储库下载数据集。 数据集的链接可以在下面找到。
https://archive.ics.uci.edu/ml/datasets/Early+stage+diabetes+risk+prediction+dataset.
https://archive.ics.uci.edu/ml/datasets/Early+stage+diabetes+risk+prediction+dataset 。
After downloading the dataset, as long as it is not too big, I like to look at it in a spreadsheet to get a sense of what I am working with.
下载数据集后,只要它不是太大,我就喜欢在电子表格中查看它,以了解自己正在使用什么。

As you can see we have 17 total variables with what appears as binary record values for each field except for ‘Age’. From here we’ll open the dataset in a notebook environment to explore it more. For this project, I used Google Colab which is based on a Jupyter notebook environment and does not require any configuration before using.
如您所见,我们共有17个变量,每个变量的字段都显示为二进制记录值(“年龄”除外)。 从这里,我们将在笔记本环境中打开数据集以进行更多研究。 对于这个项目,我使用了基于Jupyter笔记本环境的Google Colab,并且在使用之前不需要任何配置。
There are a few ways to pull data into Google Colab from a personal location of yours. For this project, I ran the following command which allows you to browse your local computer for a file to upload.
有几种方法可以将数据从您的个人位置提取到Google Colab中。 对于此项目,我运行了以下命令,该命令可让您浏览本地计算机以查找要上传的文件。
From there we’ll load in some necessary libraries.
从那里我们将加载一些必要的库。
The next step is to read in the data to a DataFrame and to explore the variables to see if we will need to do any data imputation.
下一步是将数据读入DataFrame并探究变量,以查看是否需要进行任何数据插补。

We see that there are no NULL values so we will not need to do any imputation on the dataset. However, we will still need to do some reformatting to get the data into a format that a machine learning algorithm can handle.
我们看到没有NULL值,因此我们不需要对数据集进行任何插补。 但是,我们仍然需要进行一些重新格式化,以将数据转换为机器学习算法可以处理的格式。
Before we do that though we will split our data into a training set and a test set. This way we are able to have an idea of how our model will generalize with new data it has not seen before. Then we will split up the training instances and label instances. Since ‘Class’ is the label we are trying to predict we create a series with just that value in it called dia_labels.
在进行此操作之前,我们将数据分为训练集和测试集。 通过这种方式,我们可以对我们的模型如何使用以前从未见过的新数据进行泛化有所了解。 然后,我们将训练实例和标签实例分开。 由于“类别”是标签,我们尝试预测,因此我们创建了一个仅包含该值的系列dia_labels。
As mentioned previously we will need to reformat the data into a structure that can be fed into a machine learning algorithm. To accomplish this we will transform the dia_train DataFrame into a NumPy array. We will need to convert the words into numbers in order to do this. My approach was to convert the ‘Yes’ records to 1’s and the ‘No’ records to 0’s. I could have manually done this, but I wanted to build a Pipeline out of my model so it could be more dynamic in future use. I started with the following Class and Pipeline.
如前所述,我们将需要将数据重新格式化为可以馈入机器学习算法的结构。 为此,我们将dia_train DataFrame转换为NumPy数组。 为此,我们需要将单词转换为数字。 我的方法是将“是”记录转换为1,将“否”记录转换为0。 我本可以手动完成此操作,但是我想用我的模型构建管道,以便将来使用时更加动态。 我从下面的类和管道开始。
This code will allow us to have most of our column values converted once we execute fit_transform(), but we still need to make some changes to the ‘Age’ and ‘Gender’ columns. You may be wondering why we need to make changes to ‘Age’ since it is already filled with numbers. The reason is due to the scale those numbers have compared to everything else. Since the other columns are only values of 1 and 0 the model would place much more significance on the ‘Age’ column. To handle this we can use Sklearns built-in StandardScaler transformer, which is built into sklearn.preprocessing.
一旦执行fit_transform(),此代码将使我们能够转换大多数列值,但是我们仍然需要对“年龄”和“性别”列进行一些更改。 您可能想知道为什么我们需要对“年龄”进行更改,因为它已经充满了数字。 原因是由于这些数字与其他所有数据相比的规模。 由于其他列的值分别为1和0,因此模型在“年龄”列上的重要性更高。 为了解决这个问题,我们可以使用Sklearns内置的StandardScaler转换器,它内置在sklearn.preprocessing中。
Finally, we have the ‘Gender’ column which is categorical. We naively will assume that the ‘Male’ and ‘Female’ hold the same weight when it comes to determining which ‘Class’ they will fall into. We can use another built-in transformer called OneHotEncoder(). This function can also be found in sklearn.preprocessing. OneHotEncoder creates a matrix with a male column and a female column. If someone is male there will be a 1 in the male column and a 0 in the female column. The opposite would be true for a female.
最后,我们有一个“性别”列,它是分类的。 我们天真地假设,“男性”和“女性”在决定他们属于哪个“班级”时具有相同的权重。 我们可以使用另一个名为OneHotEncoder()的内置转换器。 此功能也可以在sklearn.preprocessing中找到。 OneHotEncoder创建一个具有公列和母列的矩阵。 如果某人是男性,则男性列中将为1,而女性列中将为0。 对于女性而言,情况恰恰相反。
Since there are only 2 different categories in the ‘Gender’ column we could have used normal encoding, so we could make the ‘Male’ instances 1’s and the ‘Female’ instances 0, all within the same column. This essentially would just be using one value to perform the math behind the scenes. Since theoretically in the future, there could be an ‘Other’ option for the ‘Gender’ column I decided to use OneHotEncoding.
由于“性别”列中只有2个不同的类别,我们可以使用常规编码,因此我们可以将“男性”实例1和“女性”实例0都设置在同一列中。 本质上,这只是使用一个值在后台执行数学运算。 由于从理论上讲,我决定使用OneHotEncoding,因此在“性别”列中可能会有“其他”选项。
OneHotEncoding helps to eliminate unfair bias if there is not a natural order between categorical values in a column.
如果列中的分类值之间没有自然顺序,OneHotEncoding有助于消除不公平的偏见。
Now we will wrap all of these techniques into one pipeline to handle all of our columns.
现在,我们将所有这些技术包装到一个管道中以处理所有列。
By calling dia_prepared we can ensure that everything transformed as planned.
通过调用dia_prepared,我们可以确保一切都按计划进行了转换。

At last, we have our data in a spot to use a machine learning algorithm. Since we are building a classifier we will want to use a classifying algorithm such as a Decision Tree, Logistic Regression, or a Support Vector Machine Classifier. It’s fairly easy to experiment with these different algorithms built into Sklearn to find one that performs well.
最后,我们将数据存储在一个地点以使用机器学习算法。 由于我们正在构建分类器,因此我们将要使用分类算法,例如决策树,逻辑回归或支持向量机分类器。 尝试使用Sklearn中内置的这些不同算法来找到性能良好的算法是相当容易的。
I ultimately went with the Support Vector Machine Classifier using the code below. You can experiment by importing different algorithms instead of SVC from Sklearn.
我最终使用下面的代码选择了支持向量机分类器。 您可以通过导入不同的算法而不是从Sklearn导入SVC进行试验。
With our model fit it is now time to do some evaluation on how it performed on our training data.
通过我们的模型拟合,现在是时候对其在训练数据上的表现进行一些评估了。
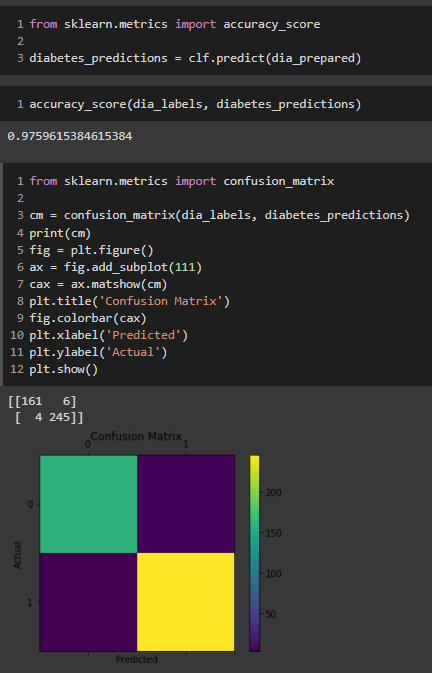
We received an accuracy of 97.6% with 4 False Negatives and 6 False Positives.
我们收到4个假阴性和6个假阳性的准确性为97.6%。
With our metrics in a good spot, we can move on to testing the test_set data to get a feel for how well our model will generalize.
有了合适的指标,我们就可以继续测试test_set数据,以了解模型的一般化程度。
We’ll first drop the label from the test set similar to how we dropped it from the training set.
我们将首先从测试集中删除标签,就像我们从训练集中删除标签一样。
Since the test set has all the same variable names as the training set we are able to run it straight through our ‘full_pipeline’ to get it in the correct format for our trained model to make predictions with it.
由于测试集具有与训练集相同的变量名,因此我们可以直接通过“ full_pipeline”运行它,以正确的格式获取它,以供训练后的模型进行预测。
We can now make predictions by calling predict in our ‘clf’ model and passing in ‘X_test_prepared’.
现在,我们可以通过在“ clf”模型中调用预测并传递“ X_test_prepared”来进行预测。

Our model performs with an accuracy of 96.2% with 1 False Negative and 3 False Positives.
我们的模型在1个假阴性和3个假阳性的情况下的准确度为96.2%。
Now that we have trained and tested our model we can wrap the preparation and the predictor into one pipeline and test it out.
现在我们已经训练和测试了我们的模型,我们可以将准备和预测变量包装到一个管道中并进行测试。
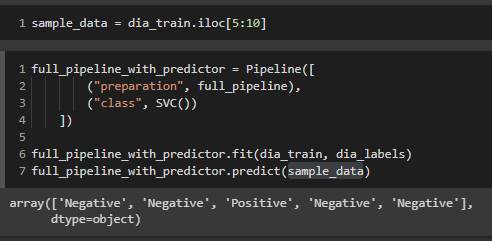
The above code takes a small sample of our training data, prepares it for an algorithm, and then makes a final prediction based on the training weights from our training data.
上面的代码获取了我们训练数据的一小部分样本,将其准备用于算法,然后根据来自我们训练数据的训练权重做出最终预测。
Lastly, we can save the weights of our trained model into a pickle file. This will allow us to use the model in future code without having to retrain our model. While our model did not take very long to train some can take hours or even days, so using it for predictions would not hold a lot of utility if you had to train it every time. This can be done using ‘dump’ from the library joblib.
最后,我们可以将经过训练的模型的权重保存到一个pickle文件中。 这将使我们能够在将来的代码中使用该模型,而不必重新训练我们的模型。 虽然我们的模型训练不需要很长时间,但是有些模型可能要花费数小时甚至数天,因此,如果您每次都必须训练它,那么将其用于预测就不会发挥太大的作用。 可以使用库joblib中的“ dump”来完成。
You can then bring the model into your new code and make predictions by using the following code.
然后,您可以将模型引入新代码中,并使用以下代码进行预测。
This was an example of how we can use machine learning to make predictions on data we do not know a lot about. Fortunately for us, the dataset we used was quite clean and did not require a lot of data preprocessing. Most real-world projects would have more time devoted to that step of the project. For the full notebook of this code, check out the link below.
这是一个示例,说明了我们如何使用机器学习对不太了解的数据进行预测。 对我们来说幸运的是,我们使用的数据集非常干净,不需要大量的数据预处理。 大多数现实世界的项目将有更多的时间专门用于该步骤。 有关此代码的完整笔记本,请查看下面的链接。
https://github.com/jjevans25/UCI-Diabetes-Data/blob/master/Diabetes_Model.ipynb
https://github.com/jjevans25/UCI-Diabetes-Data/blob/master/Diabetes_Model.ipynb
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
I would like to note that I am not a medical professional and would not recommend using this model to make any health-related decisions.
我想指出,我不是医学专家,不建议使用此模型来做出任何与健康相关的决定。
翻译自: https://medium.com/analytics-vidhya/creating-a-classifier-from-the-uci-early-stage-diabetes-risk-prediction-dataset-43b584822805
uci数据集中的缺失数据
http://www.taodudu.cc/news/show-2971007.html
相关文章:
- 关于【天池精准医疗大赛——人工智能辅助糖尿病遗传风险预测】的思考
- 肺癌新易感位点的发现及多基因遗传评分在肺癌风险预测中的应用--基于中国超大型前瞻性队列研究
- 一战成名,用户贷款风险预测 参赛代码与数据集分享
- 交通事故风险预测——《TA-STAN: A Deep Spatial-Temporal Attention Learning Framework...》
- python数据分析实战之信用卡违约风险预测
- 2020CCF BDCI 企业非法集资风险预测-线上0.848(水哥的baseline),在此基础已做到线上0.848,排名前1%(参赛队伍3000+))。
- 怎样判断一个诊断(风险预测)模型的好坏?
- 客户信用风险预测——基于logit模型
- 天池精准医疗大赛——人工智能辅助糖尿病遗传风险预测
- 银行信用风险预测分析
- 利用随机森林算法实现Bank风险预测
- 用户贷款风险预测之Top10初体验
- LSTM案例——动态和可解释的ICU死亡风险预测
- CCF2020企业非法集资风险预测-季军方案
- 企业非法集资风险预测
- 系统认证风险预测方案总结
- 风险预测模型_慢性肾脏病孕妇妊娠风险预测模型的构建及验证
- 贷后评分模型的三种细分应用
- 贷款风险预测
- js实现省市区三级联动(三个下拉框实现)
- 非常不错的地区三级联动,js简单易懂。封装起来了(转)
- IDS入侵检测IPS入侵防御
- HCSA-08 威胁防护介绍、ARP防护、网络攻击防护、病毒过滤、入侵防御、边界流量过滤
- 如何建设企业入侵防御体系
- 安全防御(三)--- IDS、防火墙入侵防御
- 防火墙用户管理和入侵防御简介
- 入侵防御之防火墙
- SAP中QM和MM在质检流程应用中的区别应用问题实例
- ipqc的工作流程图_品质部各人员工作流程图
- ipqc的工作流程图_过程质量控制IPQC的介绍及流程
uci数据集中的缺失数据_从uci早期糖尿病风险预测数据集中创建分类器相关推荐
- 数据可视化机器学习工具在线_为什么您不能跳过学习数据可视化
数据可视化机器学习工具在线 重点 (Top highlight) There's no scarcity of posts online about 'fancy' data topics like ...
- mysql数据转存到时序数据库_干货丨如何高速迁移MySQL数据到时序数据库DolphinDB...
DolphinDB提供了两种导入MySQL数据的方法:ODBC插件和MySQL插件.我们推荐使用MySQL插件导入MySQL数据,因为它的速度比ODBC导入更快,导入6.5G数据,MySQL插件的速度 ...
- 大数据产品开发流程规范_华为内部资料流出!揭秘华为数据湖:3大特点、6个标准、入湖流程...
点蓝色字关注"云技术" 导读:数据湖:实现企业数据的"逻辑汇聚". 作者:华为公司数据管理部来源:大数据DT(ID:hzdashuju)01 华为数据湖的3个特 ...
- 监管数据治理治什么?1104、EAST、客户风险系统数据简介
近年来,随着经济社会数字化发展,商业银行逐步向数字化.智能化转型,监管部门对商业银行数据报送质量也越来越重视.自2020年5月9日工行.农行.中行.建行.交行.邮储.中信.光大8家商业银行因监管标准化 ...
- 8数据提供什么掩膜产品_工业轨式1-8路RS485数据(MODBUS RTU协议)厂家产品说明...
产品描述 工业级数点对点光猫提供1-8路RS485(MODBUS RTU协议): 在光纤中传输,该产品突破了传统串行接口通讯距离与通讯速率的矛盾,同时,也解决了电磁干扰.地环干扰和雷电破坏的难题,大大 ...
- 用python玩转数据慕课答案第四周_大学慕课用Python玩转数据章节测试答案
大学慕课用Python玩转数据章节测试答案 更多相关问题 渗透泵型片剂控释的基本原理是A.减小溶出B.减慢扩散C.片剂膜外渗透压大于片剂膜内,将片内药物从 语义学批评是什么? As usual, __ ...
- 西部数据移动硬盘哪个型号好_就目前来说希捷和西部数据哪家1T以上的移动硬盘质量更好?...
正好关注这个问题,正好发现一篇比较实用的统计,所以就顺势当一波大自然的搬运工. 以下是搬运内容: 云备份服务商BackBlaze每个季度都会基于其产品使用状态,公布一份(机械)硬盘故障率报告.虽然是一 ...
- 数据专员面试说什么_您说什么:如何备份数据?
数据专员面试说什么 With an increasing amount of our lives stored in digital format-financial documents, famil ...
- mysql删除重复数据只保留一条_【SQL】mysql删除重复数据只保留一条
清洗数据的时候,发现有重复数据. 之前多用EXCEL处理数据,一键就可以delete了.这次因为数据量相对较大换了mysql. 按照百度搜到的一个高票代码,运行了半天都不对. 一直报错: 即按照mys ...
最新文章
- Google Scholar公司科研实力大比拼:谷歌1161,华为110,为何差10倍?
- python图像分割重组_通过PYTHON来实现图像分割详解
- 网络通讯程序整理(一)
- 接口测试用例设计思路_接口测试平台设计思路10:成品总览白盒模块
- 系统讲解——更好的实施专案(Porject)
- java向指定文件写入内容
- 同花顺崩了上热一!网友:早盘血亏,你还不让我跑 官方回应...
- 被阿里带火的数据中台:“大中台、小前台”战略是什么?
- JSONObject和JSONArray使用
- python接受前端传递的参数
- wifi已连接不可上网服务器无响应,wifi已连接不可上网是什么原因?
- 快冲!淘宝无货源副业,傻瓜式操作,日赚300-500元!!
- SVN冲突的原因和解决
- 看两宋风云,搞清了4个之前对两宋历史认识错误的地方
- 设置jupyter notebook默认浏览器
- prometheus-容器健康状况监控
- 546家企业被列为建议支持的国家级专精特新“小巨人”企业
- ZZULIOJ1086: ASCII码排序(多实例测试)
- SpringBoot全局异常处理
- 中兴设备电话人工服务器,中兴刀片服务器 ATCA机柜 中兴 6008002200 网络服务器机柜...