python网络爬虫从入门到实践(第2版)_带你读《Python网络爬虫从入门到实践(第2版)》之三:静态网页抓取-阿里云开发者社区...
第3章
静态网页抓取
在网站设计中,纯粹HTML格式的网页通常被称为静态网页,早期的网站一般都是由静态网页制作的。在网络爬虫中,静态网页的数据比较容易获取,因为所有数据都呈现在网页的 HTML代码中。相对而言,使用AJAX动态加载网页的数据不一定会出现在HTML代码中,这就给爬虫增加了困难。本章先从简单的静态网页抓取开始介绍,第4章再介绍动态网页抓取。
在静态网页抓取中,有一个强大的Requests库能够让你轻易地发送HTTP请求,这个库功能完善,而且操作非常简单。本章首先介绍如何安装Requests库,然后介绍如何使用Requests库获取响应内容,最后可以通过定制Requests的一些参数来满足我们的需求。
3.1 安装Requests
Requests库能通过pip安装。打开Windows 的cmd或Mac的终端,键入:

就安装完成了。
3.2 获取响应内容
在Requests中,常用的功能是获取某个网页的内容。现在我们使用Requests获取个人博客主页的内容。

这样就返回了一个名为r的response响应对象,其存储了服务器响应的内容,我们可以从中获取需要的信息。上述代码的结果如图3-1所示。

上例的说明如下:
(1)r.text是服务器响应的内容,会自动根据响应头部的字符编码进行解码。
(2)r.encoding是服务器内容使用的文本编码。
(3)r.status_code用于检测响应的状态码,如果返回200,就表示请求成功了;如果返回的是4xx,就表示客户端错误;返回5xx则表示服务器错误响应。我们可以用r.status_code来检测请求是否正确响应。
(4)r.content是字节方式的响应体,会自动解码gzip和deflate编码的响应数据。
(5)r.json()是Requests中内置的JSON解码器。
3.3 定制Requests
在3.2节中,我们使用Requests库获取了网页数据,但是有些网页需要对Requests的参数进行设置才能获取需要的数据,这包括传递URL参数、定制请求头、发送POST请求、设置超时等。
3.3.1 传递URL参数
为了请求特定的数据,我们需要在URL的查询字符串中加入某些数据。如果你是自己构建URL,那么数据一般会跟在一个问号后面,并且以键/值的形式放在URL中,如http://httpbin.org/get?key1=value1 。
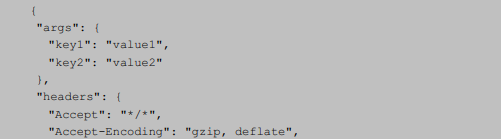
在Requests中,你可以直接把这些参数保存在字典中,用params(参数)构建至URL中。例如,传递key1 = value1和key2=value2到http://httpbin.org/get ,可以这样编写:

通过上述代码的输出结果可以发现URL已经正确编码:
URL已经正确编码:http://httpbin.org/get?key1=value1&key2=value2
字符串方式的响应体:

3.3.2 定制请求头
请求头Headers提供了关于请求、响应或其他发送实体的信息。对于爬虫而言,请求头十分重要,尽管在上一个示例中并没有制定请求头。如果没有指定请求头或请求的请求头和实际网页不一致,就可能无法返回正确的结果。
Requests并不会基于定制的请求头Headers的具体情况改变自己的行为,只是在最后的请求中,所有的请求头信息都会被传递进去。
那么,我们如何找到正确的Headers呢?
还是用到第2章提到过的Chrome浏览器的“检查”命令。使用Chrome浏览器打开要请求的网页,右击网页的任意位置,在弹出的快捷菜单中单击“检查”命令。
如图3-2所示,在随后打开的页面中单击Network选项。
如图3-3所示,在左侧的资源中找到需要请求的网页,本例为www.santostang.com。单击需要请求的网页,在Headers中可以看到Requests Headers的详细信息。
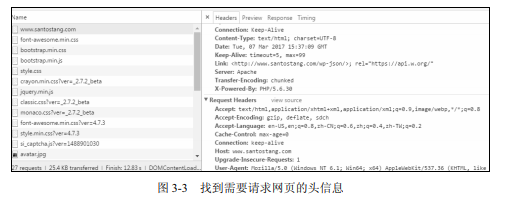
因此,我们可以看到请求头的信息为:
GET / HTTP/1.1
Host: www.santostang.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8 Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW;q=0.2
提取请求头中重要的部分,可以把代码改为:

3.3.3 发送POST请求
除了GET请求外,有时还需要发送一些编码为表单形式的数据,如在登录的时候请求就为POST,因为如果用GET请求,密码就会显示在URL中,这是非常不安全的。如果要实现POST请求,只需要简单地传递一个字典给Requests中的data参数,这个数据字典就会在发出请求的时候自动编码为表单形式。

输出的结果为:
{
"args": {},
"data": "",
"form": {
"key1": "value1",
"key2": "value2"
},
…
}
可以看到,form变量的值为key_dict输入的值,这样一个POST请求就发送成功了。
3.3.4 超时
有时爬虫会遇到服务器长时间不返回,这时爬虫程序就会一直等待,造成爬虫程序没有顺利地执行。因此,可以用Requests在timeout参数设定的秒数结束之后停止等待响应。意思就是,如果服务器在timeout秒内没有应答,就返回异常。
我们把这个秒数设置为0.001秒,看看会抛出什么异常。这是为了让大家体验timeout异常的效果而设置的值,一般会把这个值设置为20秒。

返回的异常为:ConnectTimeout: HTTPConnectionPool(host='www.santostang.com ',
port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(connection.HTTPConnection object at 0x0000000005B85B00>, 'Connection to www.santostang.com timed out. (connect timeout=0.001)'))。
异常值的意思是,时间限制在0.001秒内,连接到地址为www.santostang.com 的时间已到。
3.4 Requests爬虫实践:TOP250电影数据
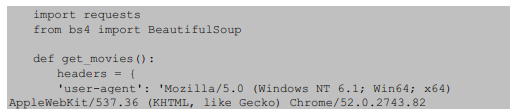
本章实践项目的目的是获取豆瓣电影TOP250的所有电影的名称,网页地址为:https://movie.douban.com/top250 。在此爬虫中,将请求头定制为实际浏览器的请求头。
3.4.1 网站分析
打开豆瓣电影TOP250的网站,使用“检查”功能查看该网页的请求头,如图3-4所示。
按照3.3.2中的方法提取其中重要的请求头:

第一页只有25个电影,如果要获取所有的250页电影,就需要获取总共10页的内容。
通过单击第二页可以发现网页地址变成了:
https://movie.douban.com/top250?start=25
第三页的地址为:https://movie.douban.com/top250?start=50 ,这就很容易理解了,每多一页,就给网页地址的start参数加上25。
3.4.2 项目实践
通过以上分析发现,可以使用requests获取电影网页的代码,并利用for循环翻页。其代码如下:

运行上述代码,得到的结果是:
1 页响应状态码: 200 lang="zh-cmn-Hans" class="ua-windows ua-webkit">
豆瓣电影TOP250
...
这时,得到的结果只是网页的HTML代码,我们需要从中提取需要的电影名称。接下来会涉及第5章解析网页的内容,读者可以先使用下面的代码,至于对代码的理解,可以等到第5章再学习。
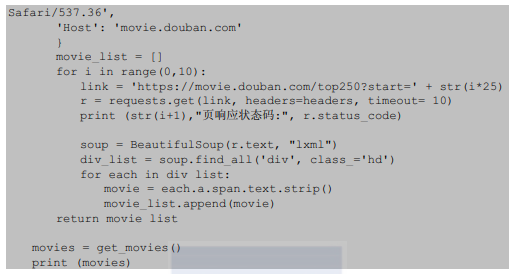
在上述代码中,使用BeautifulSoup对网页进行解析并获取其中的电影名称数据。运行代码,得到的结果是:
1 页响应状态码: 200
2 页响应状态码: 200
3 页响应状态码: 200
4 页响应状态码: 200
5 页响应状态码: 200
6 页响应状态码: 200
7 页响应状态码: 200
8 页响应状态码: 200
9 页响应状态码: 200
10 页响应状态码: 200
['肖申克的救赎', '这个杀手不太冷', '霸王别姬', '阿甘正传', '美丽人生', '千与千寻', '辛德勒的名单', '泰坦尼克号', '盗梦空间', '机器人总动员', '海上钢琴师', '三傻大闹宝莱坞', '忠犬八公的故事', '放牛班的春天', '大话西游之大圣娶亲', '教父', '龙猫', '楚门的世界', '乱世佳人', '天堂电影院', '当幸福来敲门', '触不可及', '搏击俱乐部', '十二怒汉', '无间道', '熔炉', '指环王3:王者无敌', '怦然心动', '天空之城', '罗马假日', ...]
3.4.3 自我实践题
读者若有时间,可以实践进阶问题:获取TOP 250电影的英文名、港台名、导演、主演、上映年份、电影分类以及评分。
python网络爬虫从入门到实践(第2版)_带你读《Python网络爬虫从入门到实践(第2版)》之三:静态网页抓取-阿里云开发者社区...相关推荐
- python序列中各元素之间存在顺序关系_《Python Cookbook(第3版)中文版》——1.10 从序列中移除重复项且保持元素间顺序不变-阿里云开发者社区...
本节书摘来自异步社区<Python Cookbook(第3版)中文版>一书中的第1章,第1.10节,作者[美]David Beazley , Brian K.Jones,陈舸 译,更多章节 ...
- 杭州内推 | 阿里云开发者社区招聘计算机视觉算法工程师(2022年毕业生)
合适的工作难找?最新的招聘信息也不知道? AI 求职为大家精选人工智能领域最新鲜的招聘信息,助你先人一步投递,快人一步入职! 阿里云 阿里巴巴集团拥有海量的图像/视频数据,强大的计算能力和巨大的市场空 ...
- pg数据库生成随机时间_postgresql 时区与时间函数-阿里云开发者社区
postgresql 时区与时间函数 rudygao 2016-02-03 1951浏览量 简介: --把时间戳转成epoch值 postgres=# select extract(epoch fro ...
- 博客同步至阿里云开发者社区,快来帮我涨人气吧
博客同步至阿里云开发者社区,快来帮我涨人气吧! 直达链接! 直达链接! 直达链接! 直达链接! 直达链接! https://developer.aliyun.com/profile/sijaicxpx ...
- freebsd mysql 安装_Freebsd中mysql安装及使用笔记-阿里云开发者社区
Freebsd中mysql安装及使用笔记 x3d 2009-07-31 662浏览量 简介: 1.安装 一开始连mysql的软件包在freebsd中叫什么都不知道: 依稀属于databases类,先到 ...
- mysql join 索引 无效_ORACLE MYSQL中join 字段类型不同索引失效的情况-阿里云开发者社区...
ORACLE MYSQL中join 字段类型不同索引失效的情况 重庆八怪 2016-12-29 780浏览量 简介: 关于JOIN使用不同类型的字段类型,数据库可能进行隐士转换,MYSQL ORACL ...
- db h2 数据类型_H2数据库函数及数据类型概述-阿里云开发者社区
H2数据库函数及数据类型概述 jieforest 2015-01-29 573浏览量 简介: H2数据库函数及数据类型概述 一.H2数据库常用数据类型 INT类型:对应java.lang.Intege ...
- rcs开机启动mysql_linux添加开机自启动脚本示例详解-阿里云开发者社区
linux添加开机自启动脚本示例详解 double2li 2017-04-14 1652浏览量 简介: linux下(以RedHat为范本)添加开机自启动脚本有两种方法,先来简单的;一.在/etc/r ...
- mysql double 存储_关于MYSQL中FLOAT和DOUBLE类型的存储-阿里云开发者社区
关于MYSQL中FLOAT和DOUBLE类型的存储 重庆八怪 2016-04-12 844浏览量 简介: 关于MYSQL中FLOAT和DOUBLE类型的存储 其实在单精度和双精度浮点类型存储中其存储方 ...
最新文章
- C语言判断挂科,并输出挂科学生的全部成绩!_只愿与一人十指紧扣_新浪博客
- 一个简洁OKR是成功的关键因素
- 1.QT元对象系统、信号槽概述、宏Q_OBJECT
- [转]改变UITextField placeHolder颜色、字体
- truncate数据后回收空间_Truncate用法详解
- css3是什么 ptml_CSS3
- php 性能日志,php性能分析之php-fpm慢执行日志slow log用法浅析
- [POJ3096]Surprising Strings
- Wireshark初步入门
- 微信开发之小程序获取手机号授权登录
- CSDN日报20170612 ——《程序员,感觉技术停滞了怎么办?》
- 试题 算法训练 P0704
- 迪士尼无限3.0连接服务器,迪士尼无限3period;0BUG问题解决 | 手游网游页游攻略大全...
- 深信服AC路由部署模式,怎么启用为PN与总部机构为PN连接
- AI化身心脏病“专家” 为心脏健康保驾护航
- C++ 一、C++简介
- 米的换算单位和公式_Excel 怎样进行单位换算,excle怎么把米换算公里
- JS身份证号码校验,JS根据身份证号码获取出生年月日,JS根据出生年月日获取年龄,JS根据身份证号码获取性别
- word两幅图并排并且插入题注不会乱
- 移动视频监控业务技术分析