NLP模型集锦----pynlp
github 地址
目录
1、Introduction
2、Our Model
2.1 CTR
2.1.1 Models List
2.1.2 Convolutional Click Prediction Model
2.1.2 Factorization-supported Neural Network
2.1.3 Product-based Neural Network
2.1.4 Wide & Deep
2.1.4 DeepFM
2.1.5 Piece-wise Linear Model
2.1.6 Deep & Cross Network
2.1.7 Attentional Factorization Machine
2.1.8 Neural Factorization Machine
2.1.9 xDeepFM
2.1.10 AutoInt
2.1.11 Deep Interest Network
2.1.12 Deep Interest Evolution Network
2.1.13 NFFM
2.1.14 FGCNN
2.1.15 Deep Session Interest Network
2.1.16 FiBiNET
2.1.17 DSTN
2.2 NLU
2.2.1 模型介绍与实现:Joint Model (Intent+Slot)
2.3 TextSimilarity
2.3.1 模型介绍:深度学习之文本相似度Paper总结
2.3.2 模型实现说明:github
2.4 Sequence labeling
2.4.1 介绍
2.4.2 模型实现
2.5 Text classification
2.5.1 介绍
2.5.2 模型实现
2.6 NLG
1、Introduction
pynlp是包含CTR、NLP、NLG、文本相似度、文本序列标注、文本分类等模型的一个Tensorflow实现。
2、Our Model
2.1 CTR
2.1.1 Models List
| Model | Paper |
|---|---|
| Convolutional Click Prediction Model | [CIKM 2015]A Convolutional Click Prediction Model |
| Factorization-supported Neural Network | [ECIR 2016]Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction |
| Product-based Neural Network | [ICDM 2016]Product-based neural networks for user response prediction |
| Wide & Deep | [DLRS 2016]Wide & Deep Learning for Recommender Systems |
| DeepFM | [IJCAI 2017]DeepFM: A Factorization-Machine based Neural Network for CTR Prediction |
| Piece-wise Linear Model | [arxiv 2017]Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction |
| Deep & Cross Network | [ADKDD 2017]Deep & Cross Network for Ad Click Predictions |
| Attentional Factorization Machine | [IJCAI 2017]Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks |
| Neural Factorization Machine | [SIGIR 2017]Neural Factorization Machines for Sparse Predictive Analytics |
| xDeepFM | [KDD 2018]xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems |
| AutoInt | [arxiv 2018]AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks |
| Deep Interest Network | [KDD 2018]Deep Interest Network for Click-Through Rate Prediction |
| Deep Interest Evolution Network | [AAAI 2019]Deep Interest Evolution Network for Click-Through Rate Prediction |
| NFFM | [arxiv 2019]Operation-aware Neural Networks for User Response Prediction |
| FGCNN | [WWW 2019]Feature Generation by Convolutional Neural Network for Click-Through Rate Prediction |
| Deep Session Interest Network | [IJCAI 2019]Deep Session Interest Network for Click-Through Rate Prediction |
| FiBiNET | [RecSys 2019]FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction |
|
DSTN |
Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction |
2.1.2 Convolutional Click Prediction Model
模型结构
![]()
主要思想
通过一个(width, 1)的kernel进行对特征的embedding矩阵进行二维卷积,其中width表示的每次对连续的width个特征进行卷积运算,之后使用一个Flexible pooling机制进行池化操作进行特征聚合和压缩表示,堆叠若干层后将得到特征矩阵作为MLP的输入,得到最终的预测结果。
这里解释两个问题
1.为什么强调是连续的width个特征进行卷积
我们都知道CNN之所以在CV领域大放异彩是由于其具有如下特性
参数共享
通常一个特征检测子(如边缘检测)在图像某一部位有用也在其他部位生效。
- 稀疏连接
每一层的输出只依赖于前一层一小部分的输入
在NLP任务中由于语句天然存在前后依赖关系,所以使用CNN能获得一定的特征表达,那么在CTR任务中使用CNN能获得特征提取的功能吗?
答案是能,但是效果可能没有那么好,问题就出在卷积是对连续的width个特征进行计算,这导致了我们输入特征的顺序发生变化就会引起结果的变化,而在CTR任务中,我们的特征输入是没有顺序的。
这相当于我们给了一个先验在里面,就是连续的width个特征进行组合更具有意义。
虽然我们可以使用类似空洞卷积的思想增加感受野来使得卷积计算的时候跨越多个特征,但是这仍然具有一定的随机性。
所以使用CNN进行CTR任务的特征提取的一个难点就在于其计算的是局部特征组合,无法有效捕捉全局组合特征。
2.Flexible pooliong是什么?
其实就是Max Pooling,只不过每次沿某一维度取p个最大的,不是1个最大的。
p的取值根据当前池化层数和总层数自适应计算,其中i是当前层数,l是总层数
![]()
2.1.2 Factorization-supported Neural Network
2.1.2.1 、摘要:
预测用户回应(user response),例如CTR、CVR(转化率)在网页搜索、个性化推荐、在在线广告起着至关重要的作用;不同于图像和音频领域,网页空间的输入特征通常是离散和类别型的,并且依赖性也基本未知;原来要预测用户响应:线性模型(欠拟合)或手工设计高阶交互特征(计算量大);文章提出通过DNN来自动学习有效的类别特征交互模式,为了使DNN有效工作,利用三个特征转换方法:FM(factorisation machines)、RBM(限制波尔兹曼机)、DAE(降噪自编码器);
2.1.2.2、介绍
一堆balabala,就是讲线性模型不能有效的学习出不明显的模式;FM和GBDT虽然能做特征组合,但是不能利用全部不同特征的组合;许多模型需要依靠特征工程和手工设计特征,并且大多数模型是浅层结构,泛化性能不好;
然后文章提出深度学习在图像、文本等的广泛应用,可以学习出局部特征并进而学习出高阶特征筛。但是对于CTR问题,存在多个领域并且都是类别特征(如城市、设备类型、广告类型),他们的局部依赖性是未知的,通过DNN来学习特征表示是很有前景的;文中提出方法Factorisation Machine supported Neural Network (FNN) 和 Sampling-based Neural Network (SNN)。 其中FNN通过监督学习Embedding并用FM来将稀疏特征变成Dense特征,减少维度;SNN通过负采样方式,基于RBM或者DAE。
2.1.2.3、DNNs for CTR Estimation given Categorical Features
如图所示是一个4层的FNN结构:
![]()
输入类别特征是field-wise 的One-hot编码形式,只有一个值为1,其他为0;
2.1.2.4、Factorisation-machine supported Neural Networks (FNN)![]()
2.1.2.5、Sampling-based Neural Networks (SNN)
基于采样的NN如下图所示:
![]()
SNN和FNN不同的地方在于最底层是不一样的,FNN是基于FM,而SNN是全连接网络,使用sigmoid函数,但由于输入是稀疏的,所以直接训练效果不行,使用上图右边所示的两种方法:基于采样的RBM和基于采样的DAE。
2.1.3 Product-based Neural Network
PNN,全称为Product-based Neural Network,认为在embedding输入到MLP之后学习的交叉特征表达并不充分,提出了一种product layer的思想,既基于乘法的运算来体现特征交叉的DNN网络结构,如下图:
![]()
按照论文的思路,从上往下来看这个网络结构:
输出层
输出层很简单,将上一层的网络输出通过一个全链接层,经过sigmoid函数转换后映射到(0,1)的区间中,得到我们的点击率的预测值:
![]()
l2层
根据l1层的输出,经一个全链接层 ,并使用relu进行激活,得到我们l2的输出结果:
![]()
l1层
l1层的输出由如下的公式计算:
![]()
重点马上就要来了,我们可以看到在得到l1层输出时,我们输入了三部分,分别是lz,lp 和 b1,b1是我们的偏置项,这里可以先不管。lz和lp的计算就是PNN的精华所在了。我们慢慢道来:
Product Layer
product思想来源于,在ctr预估中,认为特征之间的关系更多是一种and“且”的关系,而非add"或”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。
product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。二者的形式如下:
![]()
在这里,我们要使用到论文中所定义的一种运算方式,其实就是矩阵的点乘:
![]()
我们先继续介绍网络结构,有关Product Layer的更详细的介绍,我们在下一章中介绍。
Embedding Layer
Embedding Layer跟DeepFM中相同,将每一个field的特征转换成同样长度的向量,这里用f来表示。
![]()
损失函数
损失函数使用交叉熵:![]()
2.1.3.1、Product Layer详细介绍
前面提到了,product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。它们同维度,其具体形式如下:
![]()
![]()
看上面的公式,我们首先需要知道z和p,这都是由我们的embedding层得到的,其中z是线性信号向量,因此我们直接用embedding层得到:
![]()
论文中使用的等号加一个三角形,其实就是相等的意思,可以认为z就是embedding层的复制。
对于p来说,这里需要一个公式进行映射:![]()
不同的g的选择使得我们有了两种PNN的计算方法,一种叫做Inner PNN,简称IPNN,一种叫做Outer PNN,简称OPNN。
接下来,我们分别来具体介绍这两种形式的PNN模型,由于涉及到复杂度的分析,所以我们这里先定义Embedding的大小为M,field的大小为N,而lz和lp的长度为D1。
2.1.3.2 IPNN
IPNN中p的计算方式如下,即使用内积来代表pij:![]()
所以,pij其实是一个数,得到一个pij的时间复杂度为M,p的大小为N*N,因此计算得到p的时间复杂度为N*N*M。而再由p得到lp的时间复杂度是N*N*D1。因此 对于IPNN来说,总的时间复杂度为N*N(D1+M)。文章对这一结构进行了优化,可以看到,我们的p是一个对称矩阵,因此我们的权重也可以是一个对称矩阵,对称矩阵就可以进行如下的分解:![]()
因此:![]()
因此:![]()
2.1.3.3 OPNN
OPNN中p的计算方式如下:![]()
此时pij为M*M的矩阵,计算一个pij的时间复杂度为M*M,而p是N*N*M*M的矩阵,因此计算p的事件复杂度为N*N*M*M。从而计算lp的时间复杂度变为D1 * N*N*M*M。这个显然代价很高的。为了减少复杂度,论文使用了叠加的思想,它重新定义了p矩阵:
通过元素相乘的叠加,也就是先叠加N个field的Embedding向量,然后做乘法,可以大幅减少时间复杂度,定义p为:![]()
这里计算p的时间复杂度变为了D1*M*(M+N)
2.1.3.4.Discussion
和FNN相比,PNN多了一个product层,和FM相比,PNN多了隐层,并且输出不是简单的叠加;在训练部分,可以单独训练FNN或者FM部分作为初始化,然后BP算法应用整个网络,那么至少效果不会差于FNN和FM;
2.1.4 Wide & Deep
2.1.4.1 背景
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中。wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
2.1.4.2 原理
- 网络结构

可以认为:WideDeep = LR + DNN
推荐系统

流程:
- query召回 100 个 相关的items;
- 根据query+items+用户日志学习排序模型;
- 利用 2 的模型,对 1 中召回的items排序,先去top10 推荐给用户;
论文主要讲排序的部分,排序时使用到的特征:
- user features (e.g., country, language, demographics);
- contextual features (e.g., device, hour of the day, day of the week);
- impression features (e.g., app age, historical statistics of an app).
2.1.4.3The Wide Component
wide部分就是LR,LR的输入特征包括了原始特征和交叉特征;
交叉特征的定义:

在论文中,当x_i = 1 x_j = 1 其他值都是 0 时,就添加一个交叉特征 1 ,由于输入的x是one-hot类型,交叉特征可以理解为任意两个特征的乘积。
2.1.4.4The Deep Component
Deep部分就是一个MLP,隐藏层的激活函数使用了ReLUs = max(0, a)。MLP的输入包括了连续的特征和 embedding特征,对于每个field embedding特征采样随机初始化的方式。
2.1.4.5 joint training

joint training指同时训练Wide模型和Deep模型,并将两个模型的结果的加权作为最终的预测结果:

在论文实验中,训练部分,Wide使用Follow-the-regularized-learder(FTRL)+L1正则, Deep使用了AdaGrad。
2.1.4 DeepFM
2.1.4.1、背景
特征组合的挑战
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。
之前介绍的因子分解机(Factorization Machines, FM)通过对于每一维特征的隐变量内积来提取特征组合。最终的结果也非常好。但是,虽然理论上来讲FM可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合。
那么对于高阶的特征组合来说,我们很自然的想法,通过多层的神经网络即DNN去解决。
DNN的局限
下面的图片来自于张俊林教授在AI大会上所使用的PPT。
我们之前也介绍过了,对于离散特征的处理,我们使用的是将特征转换成为one-hot的形式,但是将One-hot类型的特征输入到DNN中,会导致网络参数太多:

如何解决这个问题呢,类似于FFM中的思想,将特征分为不同的field:

再加两层的全链接层,让Dense Vector进行组合,那么高阶特征的组合就出来了

但是低阶和高阶特征组合隐含地体现在隐藏层中,如果我们希望把低阶特征组合单独建模,然后融合高阶特征组合。

即将DNN与FM进行一个合理的融合:

二者的融合总的来说有两种形式,一是串行结构,二是并行结构


而我们今天要讲到的DeepFM,就是并行结构中的一种典型代表。
2.1.4.2、DeepFM模型
我们先来看一下DeepFM的模型结构:

DeepFM包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。DeepFM的预测结果可以写为:

FM部分
FM部分的详细结构如下:

FM部分是一个因子分解机。关于因子分解机可以参阅文章[Rendle, 2010] Steffen Rendle. Factorization machines. In ICDM, 2010.。因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM也可以很好的学习。
FM的输出公式为:

深度部分

深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。

嵌入层(embedding layer)的结构如上图所示。当前网络结构有两个有趣的特性,1)尽管不同field的输入长度不同,但是embedding之后向量的长度均为K。2)在FM里得到的隐变量Vik现在作为了嵌入层网络的权重。
这里的第二点如何理解呢,假设我们的k=5,首先,对于输入的一条记录,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
有关模型具体如何操作,我们可以通过代码来进一步加深认识。
2.1.4.3、相关知识
我们先来讲两个代码中会用到的相关知识吧,代码是参考的github上星数最多的DeepFM实现代码。
Gini Normalization
代码中将CTR预估问题设定为一个二分类问题,绘制了Gini Normalization来评价不同模型的效果。这个是什么东西,不太懂,百度了很多,发现了一个比较通俗易懂的介绍。
假设我们有下面两组结果,分别表示预测值和实际值:
predictions = [0.9, 0.3, 0.8, 0.75, 0.65, 0.6, 0.78, 0.7, 0.05, 0.4, 0.4, 0.05, 0.5, 0.1, 0.1]
actual = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
然后我们将预测值按照从小到大排列,并根据索引序对实际值进行排序:
SortedActualValues[0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1]
然后,我们可以画出如下的图片:

接下来我们将数据Normalization到0,1之间。并画出45度线。

橙色区域的面积,就是我们得到的Normalization的Gini系数。
这里,由于我们是将预测概率从小到大排的,所以我们希望实际值中的0尽可能出现在前面,因此Normalization的Gini系数越大,分类效果越好。
embedding_lookup
在tensorflow中有个embedding_lookup函数,我们可以直接根据一个序号来得到一个词或者一个特征的embedding值,那么他内部其实是包含一个网络结构的,如下图所示:

假设我们想要找到2的embedding值,这个值其实是输入层第二个神经元与embedding层连线的权重值。
之前有大佬跟我探讨word2vec输入的问题,现在也算是有个比较明确的答案,输入其实就是one-hot Embedding,而word2vec要学习的是new Embedding。
2.1.5 Piece-wise Linear Model
2.5.1.1、算法介绍
现阶段各CTR预估算法的不足
我们这里的现阶段,不是指的今时今日,而是阿里刚刚公开此算法的时间,大概就是去年的三四月份吧。
业界常用的CTR预估算法的不足如下表所示:
| 方法 | 简介 | 不足 |
|---|---|---|
| 逻辑回归 | 使用了Sigmoid函数将函数值映射到0~1区间作为CTR的预估值。LR这种线性模型很容易并行化,处理上亿条训练样本不是问题。 | 线性模型的学习能力有限,需要引入大量的领域知识来人工设计特征以及特征之间的交叉组合来间接补充算法的非线性学习能力,非常消耗人力和机器资源,迁移性不够友好。 |
| Kernel方法 | 将低维特征映射到高维特征空间 | 复杂度太高而不易实现 |
| 树模型 | 如Facebook的GBDT+LR算法,有效地解决了LR模型的特征组合问题 | 是对历史行为的记忆,缺乏推广性,树模型只能学习到历史数据中的特定规则,对于新规则缺乏推广性 |
| FM模型 | 自动学习高阶属性的权值,不用通过人工的方式选取特征来做交叉 | FM模型只能拟合特定的非线性模式,常用的就是二阶FM |
| 深度神经网络 | 使用神经网络拟合数据之间的高阶非线性关系,非线性拟合能力足够强 | 适合数据规律的、具备推广性的网络结构业界依然在探索中,尤其是要做到端到端规模化上线,这里面的技术挑战依然很大 |
那么挑战来了,如何设计算法从大规模数据中挖掘出具有推广性的非线性模式?
MLR算法
2011-2012年期间,阿里妈妈资深专家盖坤创新性地提出了MLR(mixed logistic regression)算法,引领了广告领域CTR预估算法的全新升级。MLR算法创新地提出并实现了直接在原始空间学习特征之间的非线性关系,基于数据自动发掘可推广的模式,相比于人工来说效率和精度均有了大幅提升。
MLR可以看做是对LR的一个自然推广,它采用分而治之的思路,用分片线性的模式来拟合高维空间的非线性分类面,其形式化表达如下:

其中u是聚类参数,决定了空间的划分,w是分类参数,决定空间内的预测。这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长,相应所需的训练样本也随之增长。因此实际应用中m需要根据实际情况进行选择。例如,在阿里的场景中,m一般选择为12。下图中MLR模型用4个分片可以完美地拟合出数据中的菱形分类面。

在实际中,MLR算法常用的形式如下,使用softmax作为分片函数:

在这种情况下,MLR模型可以看作是一个FOE model:

关于损失函数的设计,阿里采用了 neg-likelihood loss function以及L1,L2正则,形式如下:

由于加入了正则项,MLR算法变的不再是平滑的凸函数,梯度下降法不再适用,因此模型参数的更新使用LBFGS和OWLQN的结合,具体的优化细节大家可以参考论文(https://arxiv.org/pdf/1704.05194.pdf).
MLR算法适合于工业级的大规模稀疏数据场景问题,如广告CTR预估。背后的优势体现在两个方面:
端到端的非线性学习:从模型端自动挖掘数据中蕴藏的非线性模式,省去了大量的人工特征设计,这 使得MLR算法可以端到端地完成训练,在不同场景中的迁移和应用非常轻松。
稀疏性:MLR在建模时引入了L1和L2,1范数正则,可以使得最终训练出来的模型具有较高的稀疏度, 模型的学习和在线预测性能更好。当然,这也对算法的优化求解带来了巨大的挑战。
2.1.6 Deep & Cross Network
背景
探索具有预测能力的组合特征对提高CTR模型的性能十分重要,这也是大量人工特征工程存在的原因。但是数据高维稀疏(大量离散特征one-hot之后)的性质,对特征探索带来了巨大挑战,进而限制了许多大型系统只能使用线性模型(比如逻辑回归)。线性模型简单易理解并且容易扩展,但是表达能力有限,对模型表达能力有巨大作用的组合特征通常需要人工不断的探索。深度学习的成功激发了大量针对它的表达能力的理论分析,研究显示给定足够多隐藏层或者隐藏单元,DNN能够在特定平滑假设下以任意的精度逼近任意函数。实践中大多数函数并不是任意的,所以DNN能够利用可行的参数量达到很好的效果。DNN凭借Embedding向量以及非线性激活函数能够学习高阶的特征组合,并且残差网络的成功使得我们能够训练很深的网络。
相关工作
由于数据集规模和维度的急剧增加,为了避免针对特定任务的大规模特征工程,涌现了很多方法,这些方法主要是基于Embedding和神经网络技术。
- FM将稀疏特征映射到低维稠密向量上,通过向量内积学习特征组合,也就是通过隐向量的内积来建模组合特征。
- FFM在FM的基础上引入Field概念,允许每个特征学习多个向量,针对不同的Field使用不同的隐向量。
- DNN依靠神经网络强大的学习能力,能够自动的学习特征组合,但是它隐式的学习了所有的特征组合,这对于模型效果和学习效率可能是不利的。
遗憾的是FM和FFM的浅层结构限制了它们的表达能力(两者都是针对低阶的特征组合进行建模),也有将FM扩展到高阶的方法,但是这些方法拥有大量的参数产生了额外的计算开销。Kaggle竞赛中,很多取胜的方法中人工构造的组合特征都是低阶的,并且是显性(具有明确意义)高效的。而DNN学习到的都是高度非线性的高阶组合特征,含义难以解释。是否有一种模型能够学习有限阶数的特征组合,并且高效可理解呢?本文提出的DCN就是一种。W&D也是这种思想,组合特征作为线性模型的输入,同时训练线性模型和DNN,但是该模型的效果取决于组合特征的选择。
主要贡献
交叉网络是个多层网络,能够有效的学习特定阶数的特征组合,特征组合的最高阶数取决于网络层数。通过联合(jointly)训练交叉网络和DNN,DCN保留了DNN捕获复杂特征组合的能力。DCN不需要人工特征工程,而且相对于DNN来说增加的复杂度也是微乎其微。实验表明DCN在模型准确度和内存使用方面具有优势,需要比DNN少一个数量级的参数。
- 支持稀疏、稠密输入,能够高效的学习特定阶数限制下的特征组合以及高阶非线性特征组合,并且不需要人工特征工程,拥有较低的计算开销;
- 交叉网络简单有效,特征组合的最高阶数取决于网络层数,网络中包含了1价到特定阶数的所有项的组合并且它们的系数不同;
- 节省内存并且易于实现,拥有比DNN低的logloss,而且参数量少了近一个数量级。
核心思想
![]()
Embedding和Stacking层
模型的输入大部分是类别特征,这种特征通常会进行one-hot编码,这就导致了特征空间是高维稀疏的(比如ID特征经过one-hot编码之后)。为了降低维度,通常会利用Embedding技术将这些二值特征转变成实值的稠密向量(Embedding向量)。Embedding过程用到的参数矩阵会和网络中的其它参数一块进行优化。最后将这些Embedding向量和经过归一化的稠密特征组合(stack)到一起作为网络的输入。
X0=[XTembed,1,…,XTembed,k,XTdense]X0=[Xembed,1T,…,Xembed,kT,XdenseT]
交叉网络(Cross Network)
![]()
![]()
DCN主要有以下几点贡献:
- 提出一种新型的交叉网络结构,可以用来提取交叉组合特征,并不需要人为设计的特征工程;
- 这种网络结构足够简单同时也很有效,可以获得随网络层数增加而增加的多项式阶(polynomial degree)交叉特征;
- 十分节约内存(依赖于正确地实现),并且易于使用;
- 实验结果表明,DCN相比于其他模型有更出色的效果,与DNN模型相比,较少的参数却取得了较好的效果。
2.1.7 Attentional Factorization Machine
2.1.7.1、摘要:
提出一个Attentional FM,Attention模型+因子分解机,其通过Attention学习到特征交叉的权重。因为很显然不是所有的二阶特征交互的重要性都是一样的,如何通过机器自动的从中学习到这些重要性是这篇论文解决的最重要的问题,
比如:作者举了一个例子,在句子"US continues taking a leading role on foreign payment transparency"中,除了"foreign payment transparency",其它句子明显与财经新闻无关,它们之间的交叉作用可认为对主题预测是一种噪音。
2.1.7.2、FM
![]()
2.1.7.3、注意力机制
AFM模型架构:
![]()
![]()
2.1.8 Neural Factorization Machine
NFM(Neural Factorization Machines) 又是在 FM 上的一个改进工作,出发点是 FM 通过隐向量可以对完成一个很好的特征组合工作,并且还解决了稀疏的问题,但是 FM 对于它对于 non-linear 和higher-order 特征交叉能力不足,而 NFM 则是结合了 FM 和 NN 来弥补这个不足。模型框架如下(图里没画一阶的回归):

![]()
2.1.9 xDeepFM
2.1.9.1 Compressed Interaction Network
为了实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上,文中首先提出了一种新的名为压缩交互网络(Compressed Interaction Network,简称CIN)的神经模型。在CIN中,隐向量是一个单元对象,因此我们将输入的原特征和神经网络中的隐层都分别组织成一个矩阵,记为X0和Xk。CIN中每一层的神经元都是根据前一层的隐层以及原特征向量推算而来,其计算公式如下:

其中点乘的部分计算如下:

我们来解释一下上面的过程,第k层隐层含有H_k条神经元向量。隐层的计算可以分成两个步骤:(1)根据前一层隐层的状态Xk和原特征矩阵X0,计算出一个中间结果Z^k+1,它是一个三维的张量,如下图所示:

在这个中间结果上,我们用Hk+1个尺寸为m*Hk的卷积核生成下一层隐层的状态,该过程如图2所示。这一操作与计算机视觉中最流行的卷积神经网络大体是一致的,唯一的区别在于卷积核的设计。CIN中一个神经元相关的接受域是垂直于特征维度D的整个平面,而CNN中的接受域是当前神经元周围的局部小范围区域,因此CIN中经过卷积操作得到的特征图(Feature Map)是一个向量,而不是一个矩阵。

如果你觉得原文中的图不够清楚的话,希望下图可以帮助你理解整个过程:

CIN的宏观框架可以总结为下图:

可以看出,它的特点是,最终学习出的特征交互的阶数是由网络的层数决定的,每一层隐层都通过一个池化操作连接到输出层,从而保证了输出单元可以见到不同阶数的特征交互模式。同时不难看出,CIN的结构与循环神经网络RNN是很类似的,即每一层的状态是由前一层隐层的值与一个额外的输入数据计算所得。不同的是,CIN中不同层的参数是不一样的,而在RNN中是相同的;RNN中每次额外的输入数据是不一样的,而CIN中额外的输入数据是固定的,始终是X^0。
可以看到,CIN是通过(vector-wise)来学习特征之间的交互的,还有一个问题,就是它为什么是显式的进行学习?我们先从X1来开始看,X1的第h个神经元向量可以表示成:

进一步,X^2的第h个神经元向量可以表示成:

最后,第k层的第h个神经元向量可以表示成:

因此,我们能够通过上面的式子对特征交互的形式进行一个很好的表示,它是显式的学习特征交叉。
2.1.9.2 xDeepFM
将CIN与线性回归单元、全连接神经网络单元组合在一起,得到最终的模型并命名为极深因子分解机xDeepFM,其结构如下图:

集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。值得一提的是,为了提高模型的通用性,xDeepFM中不同的模块共享相同的输入数据。而在具体的应用场景下,不同的模块也可以接入各自不同的输入数据,例如,线性模块中依旧可以接入很多根据先验知识提取的交叉特征来提高记忆能力,而在CIN或者DNN中,为了减少模型的计算复杂度,可以只导入一部分稀疏的特征子集。
2.1.9.3 Tensorflow充电
在介绍xDeepFM的代码之前,我们先来进行充电,学习几个tf的函数以及xDeepFM关键过程的实现。
tf.split
首先我们要实现第一步:
如何将两个二维的矩阵,相乘得到一个三维的矩阵?我们首先来看一下tf.split函数的原理:
tf.split(value,num_or_size_splits,axis=0,num=None,name='split'
)
其中,value传入的就是需要切割的张量,axis是切割的维度,根据num_or_size_splits的不同形式,有两种切割方式:
- 如果num_or_size_splits传入的是一个整数,这个整数代表这个张量最后会被切成几个小张量。此时,传入axis的数值就代表切割哪个维度(从0开始计数)。调用tf.split(my_tensor, 2,0)返回两个10 * 30 * 40的小张量。
- 如果num_or_size_splits传入的是一个向量,那么向量有几个分量就分成几份,切割的维度还是由axis决定。比如调用tf.split(my_tensor, [10, 5, 25], 2),则返回三个张量分别大小为 20 * 30 * 10、20 * 30 * 5、20 * 30 * 25。很显然,传入的这个向量各个分量加和必须等于axis所指示原张量维度的大小 (10 + 5 + 25 = 40)。
好了,从实际需求出发,我们来体验一下,假设我们的batch为2,embedding的size是3,field数量为4。我们先来生成两个这样的tensor(假设X^k的field也是4 ):
arr1 = tf.convert_to_tensor(np.arange(1,25).reshape(2,4,3),dtype=tf.int32)
arr2 = tf.convert_to_tensor(np.arange(1,25).reshape(2,4,3),dtype=tf.int32)
生成的矩阵如下:

在经过CIN的第一步之后,我们目标的矩阵大小应该是2(batch) * 3(embedding Dimension) * 4(X^k的field数) * 4(X^0的field数)。如果只考虑batch中第一条数据的话,应该形成的是 1 * 3 * 4 * 4的矩阵。忽略第0维,想像成一个长宽为4,高为3的长方体,长方体横向切割,第一个横截面对应的数字应该如下:

那么想要做到这样的结果,我们首先按输入数据的axis=2进行split:
split_arr1 = tf.split(arr1,[1,1,1],2)
split_arr2 = tf.split(arr2,[1,1,1],2)
print(split_arr1)
print(sess.run(split_arr1))
print(sess.run(split_arr2))
分割后的结果如下:

通过结果我们可以看到,我们现在对每一条数据,得到了3个4 * 1的tensor,可以理解为此时的tensor大小为 3(embedding Dimension) * 2(batch) * 4(X^k 或X^0的field数) * 1。
此时我们进行矩阵相乘:
res = tf.matmul(split_arr1,split_arr2,transpose_b=True)
这里我理解的,tensorflow对3维及以上矩阵相乘时,矩阵相乘只发生在最后两维。也就是说,3 * 2 * 4 * 1 和 3 * 2 * 1 * 4的矩阵相乘,最终的结果是3 * 2 * 4 * 4。我们来看看结果:

可以看到,不仅矩阵的形状跟我们预想的一样,同时结果也跟我们预想的一样。
最后,我们只需要进行transpose操作,把batch转换到第0维就可以啦。
res = tf.transpose(res,perm=[1,0,2,3])
这样,CIN中的第一步就大功告成了,明白了这一步如何用tensorflow实现,那么代码你也就能够顺其自然的看懂啦!
这一块完整的代码如下:
import tensorflow as tf
import numpy as nparr1 = tf.convert_to_tensor(np.arange(1,25).reshape(2,4,3),dtype=tf.int32)
arr2 = tf.convert_to_tensor(np.arange(1,25).reshape(2,4,3),dtype=tf.int32)with tf.Session() as sess:sess.run(tf.global_variables_initializer())split_arr1 = tf.split(arr1,[1,1,1],2)split_arr2 = tf.split(arr2,[1,1,1],2)print(split_arr1)print(sess.run(split_arr1))print(sess.run(split_arr2))res = tf.matmul(split_arr1,split_arr2,transpose_b=True)print(sess.run(res))res = tf.transpose(res,perm=[1,0,2,3])print(sess.run(res))2.1.10 AutoInt
2.1.10.1 简介
这篇论文提出使用multi-head self attention(类似Transformer里的那个) 机制来进行自动特征交叉学习以提升CTR预测任务的精度。
废话不多说,先看下主要结构。典型的四段式深度学习CTR模型结构:输入,嵌入,特征提取,输出。这里我们重点看下嵌入和特征提取部分
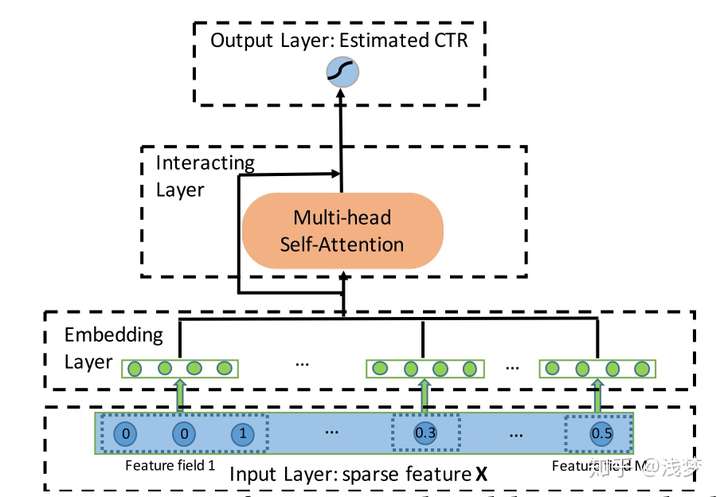
核心结构
输入和嵌入
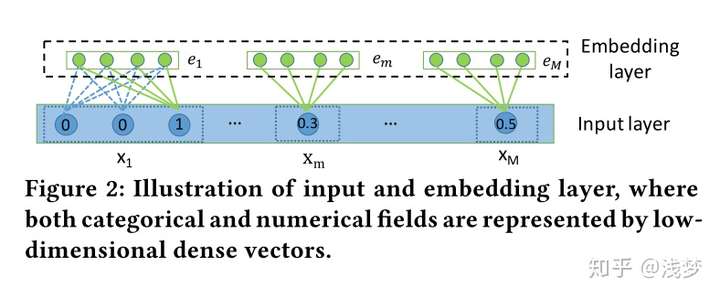
输入和嵌入层结构
针对类别特征,通过embedding方式转换为低维稠密向量 其中,
是特征组
对应的嵌入字典(嵌入矩阵),
是特征组特征的独热编码表示向量(通常出于节省空间的考虑,只存储非零特征对应的索引)
对于连续特征有, 其中
是一个嵌入向量,
是一个标量值
通常在CTR任务中我们对连续值特征的处理方式有三种:
- 进行归一化处理拼接到embedding向量侧
- 进行离散化处理作为类别特征
- 赋予其一个embedding向量,每次用特征值与embedding向量的乘积作为其最终表示
本文采取的是第三种方式,具体这三种方式孰优孰劣,要在具体场景具体任务下大家自己去验证了~
从实现的角度看第三种是比较便捷的。
InteractingLayer(交互层)
交互层使用多头注意力机制将特征投射到多个子空间中,在不同的子空间中可以捕获不同的特征交互模式。通过交互层的堆叠,可以捕获更高阶的交互模式。
下面展示在特定子空间 下,对于特征组
下的特征
,交互层是如何计算与其相关的交互特征
的
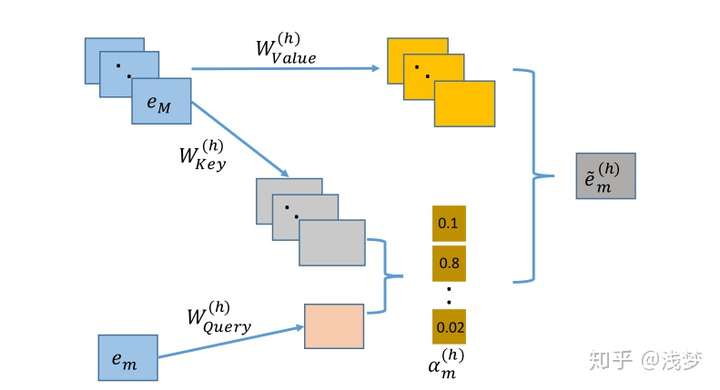
- 首先输入特征通过矩阵乘法线性变换为在注意力空间下的向量表示,对于每个特征
在特定的注意力空间
中,都有三个表示向量
,
,
- 计算
的相似度,本文使用向量内积表示:
- 计算softmax归一化注意力分布:
- 通过加权求和的方式得到特征
及其相关的特征组成的一个新特征
假设有 个注意力子空间,将每个子空间下的结果进行拼接,得到特征
最终的结果表示 :
我们可以选择使用残差网络保留一些原始特征的信息留给下一层继续学习
最后,将每个特征的结果拼接,计算最终的输出值
一层交互层捕获的阶数有限,通过堆叠若干交互层可以捕获高阶交互,提升注意力空间向量维度和提高子空间个数均能提升模型的表达能力。该模型也可以联合传统的MLP进行联合训练进一步提升表达能力。
我不想看数学,我想看代码:OK
下面就是核心代码啦,可以看到其实很短。 我们使用tensorflow进行实现的时候,可以充分利用矩阵运算的特性来简化实现。
先说明一些定义,fieldsize为特征组的个数,embedding_size为嵌入层单个特征的嵌入维度,att_embedding_size为注意力空间下隐向量的长度,head_num为注意力空间的个数,use_res为一个布尔变量,表示是否使用残差连接。
首先假设输入inputs的shape为(batch_size,field_size,embedding_size),四个投影矩阵 的shape均为
(embedding_size, att_embedding_size * head_num)
- 通过矩阵乘法得到注意力空间下的三组向量表示
querys = tf.tensordot(inputs, W_Query, axes=(-1, 0)) # (batch_size,field_size,att_embedding_size*head_num)
keys = tf.tensordot(inputs, W_key, axes=(-1, 0))
values = tf.tensordot(inputs, W_Value, axes=(-1, 0))2. 为了同时在不同的子空间下计算特征相似度,需要先进行一些变换
querys = tf.stack(tf.split(querys, self.head_num, axis=2)) # (head_num,batch_size,field_size,att_embedding_size)
keys = tf.stack(tf.split(keys, self.head_num, axis=2))
values = tf.stack(tf.split(values, self.head_num, axis=2))3. 计算相似度及归一化注意力分布
inner_product = tf.matmul(querys, keys, transpose_b=True) # (head_num,batch_size,field_size,field_size)
normalized_att_scores = tf.nn.softmax(inner_product)4. 计算加权和
result = tf.matmul(normalized_att_scores, values) # (head_num,batch_size,field_size,att_embedding_size)5. 将不同子空间下的结果进行拼接
result = tf.concat(tf.split(result, self.head_num, ), axis=-1)
result = tf.squeeze(result, axis=0)# (batch_size,field_size,att_embedding_size*head_num)6. 使用残差连接保留原始信息,
if use_res:result += tf.tensordot(inputs, self.w_res, axes=(-1, 0))
result = tf.nn.relu(result)# (batch_size,field_size,att_embedding_size*head_num)我不想看代码,我想直接拿来用:没问题
首先确保你的python版本>=3.4,然后pip install deepctr, 再去下载一下demo数据 然后直接运行下面的代码吧!

criteo sample
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScalerfrom deepctr.models import AutoInt
from deepctr.inputs import SparseFeat, DenseFeat,get_fixlen_feature_namesif __name__ == "__main__":data = pd.read_csv('./criteo_sample.txt')sparse_features = ['C' + str(i) for i in range(1, 27)]dense_features = ['I' + str(i) for i in range(1, 14)]data[sparse_features] = data[sparse_features].fillna('-1', )data[dense_features] = data[dense_features].fillna(0, )target = ['label']# 1.Label Encoding for sparse features,and do simple Transformation for dense featuresfor feat in sparse_features:lbe = LabelEncoder()data[feat] = lbe.fit_transform(data[feat])mms = MinMaxScaler(feature_range=(0, 1))data[dense_features] = mms.fit_transform(data[dense_features])# 2.count #unique features for each sparse field,and record dense feature field namefixlen_feature_columns = [SparseFeat(feat, data[feat].nunique())for feat in sparse_features] + [DenseFeat(feat, 1,)for feat in dense_features]dnn_feature_columns = fixlen_feature_columnslinear_feature_columns = fixlen_feature_columnsfixlen_feature_names = get_fixlen_feature_names(linear_feature_columns + dnn_feature_columns)# 3.generate input data for modeltrain, test = train_test_split(data, test_size=0.2)train_model_input = [train[name] for name in fixlen_feature_names]test_model_input = [test[name] for name in fixlen_feature_names]# 4.Define Model,train,predict and evaluatemodel = AutoInt( dnn_feature_columns, task='binary')model.compile("adam", "binary_crossentropy",metrics=['binary_crossentropy'], )history = model.fit(train_model_input, train[target].values,batch_size=256, epochs=10, verbose=2, validation_split=0.2, )pred_ans = model.predict(test_model_input, batch_size=256)print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))2.1.11 Deep Interest Network
2.1.11.1 背景
经典MLP不能充分利用结构化数据,本文提出的DIN可以(1)使用兴趣分布代表用户多样化的兴趣(不同用户对不同商品有兴趣)(2)与attention机制一样,根据ad局部激活用户兴趣相关的兴趣(用户有很多兴趣,最后导致购买的是小部分兴趣,attention机制就是保留并激活这部分兴趣)。
2.1.11.2 评价指标
![]()
按照user聚合样本,累加每个user组的sum(shows*AUC)/sum(shows)。paper说实验表明GAUC比AUC准确稳定。
2.1.11.3 DIN算法
![]()
左边是基础模型,也是实验的对照组,paper介绍大部分线上模型使用的是左面的base model。user和ad的特征做one_hot编码,为了定长采用池化层,网络结构是全连接的MLP。
右边是DIN,不同是为了处理上述两个数据结构,输入层增加了激活单元。
2.1.11.4 激活函数
激活函数g如下所示。
![]()
其中,vi代表用户的行为编码id,vu代表用户的兴趣编码id,va代表ad的编码id,wi代表对于某个候选广告,attention机制中行为id对总体兴趣编码id的贡献度。
激活函数采用本文提出的Dice,如下yi所示。
其中,pi和 mini batch数据的期望和方差,如下所示。
![]()
![]()
Dice激活函数的优点是根据minibatch的期望方差自适应调整校正点,而Relu采用硬校正点0。
对照组的PRelu(又叫leaky Relu)激活函数如下所示。
![]()
2.1.11.5 正则化
优化方法梯度下降法,如下所示。
![]()
其中,Ii如下所示。
![]()
2.1.11.6 架构实现
实现基于XDL平台,分为三部分:分布式特征编码层,本地后台(Tensorflow)和沟通机制(MPI)。如下图所示。
![]()
2.1.11.7 实验结果
1)特征编码:聚类效果明显,而且红色的CTR最高,DIN模型能够正确的辨别商品是否符合用户的兴趣,如下图所示。
![]()
2)局部激活效果:与候选广告越相关的行为的attention分数越高,如下图所示。
![]()
3)正则化效果:DIN效果最好,如下图所示。
![]()
4)与基础MLP模型相比:DIN最佳,如下图所示。
![]()
2.1.11.8 model网络搭建
# -- 嵌入层 start ---ic = tf.gather(cate_list, self.i) # [B]i_emb = tf.concat(values=[tf.nn.embedding_lookup(item_emb_w, self.i), # [B ,hidden_units // 2]tf.nn.embedding_lookup(cate_emb_w, ic), # [B ,hidden_units // 2] = [B, H // 2]], axis=1) # [B ,H]i_b = tf.gather(item_b, self.i)hc = tf.gather(cate_list, self.hist_i) # [B , T]h_emb = tf.concat([ # 在shape【0,1,2】某一个维度上连接tf.nn.embedding_lookup(item_emb_w, self.hist_i), # [B, T, hidden_units // 2]tf.nn.embedding_lookup(cate_emb_w, hc), # [B, T, hidden_units // 2]], axis=2) # [B, T, H]# -- 嵌入层 end ---# -- attention start ---hist = attention(i_emb, h_emb, self.sl)# [B, 1, H]# -- attention end ---hist = tf.layers.batch_normalization(inputs=hist)hist = tf.reshape(hist, [-1, hidden_units]) # [B, hidden_units]hist = tf.layers.dense(hist, hidden_units)# [B, hidden_units]u_emb = hist# -- fcn begin -------# -- 训练集全连接层 开始 -------din_i = tf.concat([u_emb, i_emb], axis=-1)din_i = tf.layers.batch_normalization(inputs=din_i, name='b1')d_layer_1_i = tf.layers.dense(din_i, 80, activation=tf.nn.sigmoid, name='f1') # 全连接层 [B, 80]# if u want try dice change sigmoid to None and add dice layer like following two lines. You can also find model_dice.py in this folder.# d_layer_1_i = tf.layers.dense(din_i, 80, activation=None, name='f1')# d_layer_1_i = dice(d_layer_1_i, name='dice_1_i')d_layer_2_i = tf.layers.dense(d_layer_1_i, 40, activation=tf.nn.sigmoid, name='f2')# d_layer_2_i = dice(d_layer_2_i, name='dice_2_i')d_layer_3_i = tf.layers.dense(d_layer_2_i, 1, activation=None, name='f3')d_layer_3_i = tf.reshape(d_layer_3_i, [-1]) # 展开成行向量self.logits = i_b + d_layer_3_i





2.1.12 Deep Interest Evolution Network
2.1.12.1 背景
在大多数非搜索电商场景下,用户并不会实时表达目前的兴趣偏好。因此通过设计模型来捕获用户的动态变化的兴趣,是提升CTR预估效果的关键。阿里之前的DIN模型将用户的历史行为来表示用户的兴趣,并强调了用户兴趣的多样性和动态变化性,因此通过attention-based model来捕获和目标物品相关的兴趣。虽然DIN模型将用户的历史行为来表示兴趣,但存在两个缺点:
1)用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性
2)通过用户的显式的行为来表达用户隐含的兴趣,这一准确性无法得到保证。
基于以上两点,阿里提出了深度兴趣演化网络DIEN来CTR预估的性能。DIEN模型的主要贡献点在于:
1)模型关注电商系统中兴趣演化的过程,并提出了新的网络结果来建模兴趣进化的过程,这个模型能够更精确的表达用户兴趣,同时带来更高的CTR预估准确率。
2)设计了兴趣抽取层,并通过计算一个辅助loss,来提升兴趣表达的准确性。
3)设计了兴趣进化层,来更加准确的表达用户兴趣的动态变化性。
接下来,我们来一起看一下DIEN模型的原理。
2.1.12.2 DIEN模型原理
- 模型总体结构
我们先来对比一下DIN和DIEN的结构。
DIN的模型结构如下:
DIEN的模型结构如下:
可以看到,DIN和DIEN的最底层都是Embedding Layer,User profile, target AD和context feature的处理方式是一致的。不同的是,DIEN将user behavior组织成了序列数据的形式,并把简单的使用外积完成的activation unit变成了一个attention-based GRU网络。
2.1.12.3 兴趣抽取层Interest Extractor Layer
兴趣抽取层Interest Extractor Layer的主要目标是从embedding数据中提取出interest。但一个用户在某一时间的interest不仅与当前的behavior有关,也与之前的behavior相关,所以作者们使用GRU单元来提取interest。GRU单元的表达式如下:

GRU表达式
这里我们可以认为ht是提取出的用户兴趣,但是这个地方兴趣是否表示的合理呢?文中别出心裁的增加了一个辅助loss,来提升兴趣表达的准确性:

这里,作者设计了一个二分类模型来计算兴趣抽取的准确性,我们将用户下一时刻真实的行为e(t+1)作为正例,负采样得到的行为作为负例e(t+1)',分别与抽取出的兴趣h(t)结合输入到设计的辅助网络中,得到预测结果,并通过logloss计算一个辅助的损失:

2.1.12.4 兴趣进化层Interest Evolution Layer
兴趣进化层Interest Evolution Layer的主要目标是刻画用户兴趣的进化过程。举个简单的例子:
以用户对衣服的interest为例,随着季节和时尚风潮的不断变化,用户的interest也会不断变化。这种变化会直接影响用户的点击决策。建模用户兴趣的进化过程有两方面的好处:
1)追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息。
2)可以根据interest的变化趋势更好地进行CTR预测。
而interest在变化过程中遵循如下规律:
1)interest drift:用户在某一段时间的interest会有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服。
2)interest individual:一种interest有自己的发展趋势,不同种类的interest之间很少相互影响,例如买书和买衣服的interest基本互不相关。
为了利用这两个时序特征,我们需要再增加一层GRU的变种,并加上attention机制以找到与target AD相关的interest。
attention的计算方式如下:

而Attention和GRU结合起来的机制有很多,文中介绍了一下三种:
GRU with attentional input (AIGRU)
这种方式将attention直接作用于输入,无需修改GRU的结构:

Attention based GRU(AGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:

GRU with attentional update gate (AUGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:

2.1.13 NFFM
NFFM结构
![]()
2.1.14 FGCNN
文章的主要贡献点有2个:
使用重组层进行特征生成缓解了CCPM中CNN无法有效捕获全局组合特征的问题
FGCNN作为一种特征生成方法,可以和任意模型进行组合
模型结构
![]()
![]()
分组嵌入
由于原始特征既要作为后续模型的输入,又要作为FGCNN模块的输入,所以原始特征的embedding向量可能会遇到梯度耦合的问题。
这里对于FGCNN模块使用一套独立的embedding向量,避免梯度耦合的问题。
卷积层和池化层
卷积和池化和CCPM类似,池化层使用的是普通的Max Pooling。
重组层![]()
拼接层
经过若干重组后,将重组后生成的特征拼接上原始的特征作为新的输入,后面可以使用各种其他的方法,如LR,FM,DeepFM等。
2.1.15 Deep Session Interest Network
2.1.15.1 背景
从用户行为中呢,我们发现,在每个会话中的行为是相近的,而在不同会话之间差别是很大的,如下图的例子:

这里会话的划分和airbnb一样,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。可以看上图,第一个session中,用户查看的都是跟裤子相关的物品,第二个session中,查看的是戒指相关的物品,第三个则是上衣相关。
基于此,阿里提出了深度会话兴趣网络Deep Session Interest Network,来建模用户这种跟会话密切相关的行为。接下来,我们就来介绍模型的结构。
2.1.15.2、模型结构
Base Model
Base Model就是一个全连接神经网络,其输入的特征的主要分为三部分,用户特征,待推荐物品特征,用户历史行为序列特征。用户特征如性别、城市、用户ID等等,待推荐物品特征包含商家ID、品牌ID等等,用户历史行为序列特征主要是用户最近点击的物品ID序列。
这些特征会通过Embedding层转换为对应的embedding,拼接后输入到多层全连接中,并使用logloss指导模型的训练。
DSIN
DSIN模型的总体框架如下图:

DSIN在全连接层之前,分成了两部分,左边的那一部分,将用户特征和物品特征转换对应的向量表示,这部分主要是一个embedding层,就不再过多的描述。右边的那一部分主要是对用户行为序列进行处理,从下到上分为四层:
1)序列切分层session division layer
2)会话兴趣抽取层session interest extractor layer
3)会话间兴趣交互层session interest interacting layer
4)会话兴趣激活层session interest acti- vating layer
接下来,我们主要介绍这4层。
Session Division Layer
这一层将用户的行文进行切分,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。
切分后,我们可以将用户的行为序列S转换成会话序列Q。第k个会话Qk=[b1;b2;...;bi;...;bT],其中,T是会话的长度,bi是会话中第i个行为,是一个d维的embedding向量。所以Qk是T * d的。而Q,则是K * T * d的
Session Interest Extractor Layer
这里对每个session,使用transformer对每个会话的行为进行处理。有关Transformer的内容,可以参考文章https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w。
在Transformer中,对输入的序列会进行Positional Encoding。Positional Encoding对序列中每个物品,以及每个物品对应的Embedding的每个位置,进行了处理,如下:

但在我们这里不一样了,我们同时会输入多个会话序列,所以还需要对每个会话添加一个Positional Encoding。在DSIN中,这种对位置的处理,称为Bias Encoding,它分为三块:

BE是K * T * d的,和Q的形状一样。BE(k,t,c)是第k个session中,第t个物品的嵌入向量的第c个位置的偏置项,也就是说,每个会话、会话中的每个物品有偏置项外,每个物品对应的embedding的每个位置,都加入了偏置项。所以加入偏置项后,Q变为:

随后,是对每个会话中的序列通过Transformer进行处理:

这里的过程和Transformer的Encoding的block处理是一样的,不再赘述。感兴趣的同学可以看一下上文提到的文章。
这样,经过Transformer处理之后,每个Session是得到的结果仍然是T * d,随后,我们经过一个avg pooling操作,将每个session兴趣转换成一个d维向量。

这样,Ik就代表第k个session对应的兴趣向量。
Session Interest Interacting Layer
用户的会话兴趣,是有序列关系在里面的,这种关系,我们通过一个双向LSTM(bi-LSTM)来处理:

每个时刻的hidden state计算如下

相加的两项分别是前向传播和反向传播对应的t时刻的hidden state。这里得到的隐藏层状态Ht,我们可以认为是混合了上下文信息的会话兴趣。
Session Interest Activating Layer
用户的会话兴趣与目标物品越相近,那么应该赋予更大的权重,这里使用注意力机制来刻画这种相关性:

这里XI是带推荐物品向量。
同样,混合了上下文信息的会话兴趣,也进行同样的处理:

后面的话,就是把四部分的向量:用户特征向量、待推荐物品向量、会话兴趣加权向量UI、带上下文信息的会话兴趣加权向量UH进行横向拼接,输入到全连接层中,得到输出。
2.1.16 FiBiNET
2.1.16.1 简介
文章指出当前的许多通过特征组合进行CTR预估的工作主要使用特征向量的内积或哈达玛积来计算交叉特征,这种方法忽略了特征本身的重要程度。提出通过使用Squeeze-Excitation network (SENET) 结构动态学习特征的重要性以及使用一个双线性函数来更好的建模交叉特征。
2.1.16.2 模型结构
![]()
图中可以看到相比于我们熟悉的基于深度学习的CTR预估模型,主要增加了SENET Layer和Bilinear-Interaction Layer两个结构。下面就针对这两个结构进行简单的说明。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
2.1.17 DSTN
CTR预估问题在广告领域十分重要,吸引了工业界和学术界学者的研究。之前我们也介绍过许多比较成功的方法,如LR、FM、Wide & Deep、DeepFM等。
总结一下,辅助广告总共有三种类型:上下文广告、用户点击过的广告、用户未点击的广告,如下图所示:

本文提出了DSTN(Deep Spatio-Temporal neural Networks)模型来处理和融合各种辅助广告信息,下一节,咱们就来介绍一下模型的结构。

单值离散特征:如用户ID、广告ID等,这类特征直接转换为对应的Embedding。
多值离散特征:如广告的标题,经过分词之后会包含多个词,每个词在转换为对应的Embedding之后,再经过sum pooling的方式转换为单个向量。
连续特征:对于连续特征如年龄,这里会进行分桶操作转换为离散值,然后再转换为对应的Embedding。
第一种结构称为DSTN - Pooling Model,其模型结构如下:

这种方式就是对上下文广告序列、点击广告序列和未点击广告序列中的vector进行简单的sum-pooling,转换为一个vector:

然后各部分进行拼接,经过全连接神经网络之后,在输出层经过一个sigmoid转换为点击的概率:




如果是上下文广告之间进行Self-Attention,其最终输出为:


通过公式可以看出,这里并不是我们所熟知的Transformer里面的self-attention,第一次看也没注意,第二次细看才发现,所以有时候尽管名字一样,但内容也许千差万别。
DSTN - Interactive Attention Model
因此,再针对上面的不足,提出了DSTN - Interactive Attention Model。其模型结构如下:

相对于self-attention,这里的权重aci没有经过归一化,其计算过程加入了目标广告的信息,计算公式如下:


这样,针对不同的目标广告,不同类型的辅助广告信息的权重会不断变化,同时权重也没有进行归一化,避免了归一化带来的种种问题。

看论文的时候,比较关心的一点就是模型的性能问题,因为模型中的一部分输入是上下文广告信息,更准确的前面推荐的广告的信息。假设我们有5个广告位需要推荐,比较容易想到的做法过程如下:
我们通过第2步得到了第一个位置的广告,重复执行3和4步4次得到剩下4个位置的广告。
这么做无疑是十分耗时的,线上性能难以保证。因此,文中提到了一种折中的做法,每次从候选集中选择2-3个广告。其示意图如下:

2.2 NLU
2.2.1 模型介绍与实现:Joint Model (Intent+Slot)
2.3 TextSimilarity
2.3.1 模型介绍:深度学习之文本相似度Paper总结
2.3.2 模型实现说明:github
2.4 Sequence labeling
2.4.1 介绍
2.4.2 模型实现
2.5 Text classification
2.5.1 介绍
2.5.2 模型实现
2.6 NLG
NLP模型集锦----pynlp相关推荐
- 收藏 | Tensorflow实现的深度NLP模型集锦(附资源)
来源:深度学习与NLP 本文约2000字,建议阅读5分钟. 本文收集整理了一批基于Tensorflow实现的深度学习/机器学习的深度NLP模型. 收集整理了一批基于Tensorflow实现的深度学习/ ...
- Tensorflow实现的深度NLP模型集锦(附资源)
https://www.toutiao.com/a6685688607191073294/ 本文约2000字,建议阅读5分钟. 本文收集整理了一批基于Tensorflow实现的深度学习/机器学习的深度 ...
- ACL最佳论文提出最新NLP模型测试方法,最佳论文提名也不可小觑
译者 | 刘畅 出品 | AI科技大本营(ID:rgznai100) 导读:近日,ACL 2020公布了最佳论文奖,另有两篇最佳论文荣誉提名奖也各自提出了解决NLP领域问题的创新方法. 最佳论文:Be ...
- 5300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品
点击上方"视学算法",选择加"星标"或"置顶" 重磅干货,第一时间送达 丰色 发自 凹非寺 量子位 报道 | 公众号 QbitAI 5300 ...
- 性能媲美BERT,但参数量仅为1/300,这是谷歌最新的NLP模型
选自Google AI Blog 作者:Prabhu Kaliamoorthi 机器之心编译 机器之心编辑部 在最新的博客文章中,谷歌公布了一个新的 NLP 模型,在文本分类任务上可以达到 BERT ...
- 刘铁岩:如何四两拨千斤,高效地预训练NLP模型?
智源社区 & AI科技评论 作者 | 熊宇轩 智源导读:2020 年 11 月 1 日,微软亚洲研究院副院长.IEEE会士.ACM杰出科学家刘铁岩博士在第十九届中国计算语言学大会(CCL)上发 ...
- 谷歌的最新NLP模型,现在能陪你从诗词歌赋谈到人生哲学
继BERT之后,谷歌在NLP模型上又有大动作! 在今天的谷歌I/O大会上,一口气发布了2个新模型: LaMDA和MUM,均基于Transformer架构. LaMDA(对话应用程序的语言模型),相比B ...
- 性能媲美BERT,参数量仅为1/300,谷歌最新的NLP模型
在最新的博客文章中,谷歌公布了一个新的 NLP 模型,在文本分类任务上可以达到 BERT 级别的性能,但参数量仅为 BERT 的 1/300. 在过去的十年中,深度神经网络从根本上变革了自然语言处理( ...
- 谷歌最强 NLP 模型 BERT 解读
谷歌最强 NLP 模型 BERT 解读 https://mp.weixin.qq.com/s/N7Qp_Fx0rAFbvrpLSETi8w 本文是追一科技潘晟锋基于谷歌论文为 AI 科技评论提供的解读 ...
最新文章
- vue-router使用next()跳转到指定路径时会无限循环
- [Android] 给图像添加相框、圆形圆角显示图片、图像合成知识
- Cosmos OpenSSD--greedy_ftl1.2.0(一)
- JAVA编程心得-JAVA实现CRC-CCITT(XMODEM)算法
- OpenJudge NOI 1.7 08:字符替换
- Android 如何使用juv-rtmp-client.jar向Red5服务器发布实时视频数据
- 威纶触摸屏EB8000编程软件V4.65.14 官方最新版
- 操作系统学习之windows发展史
- SSLOJ·马蹄印【DFS】
- 计算机内存空间为何不能无限扩容,空间是否可以无限扩张?
- 西门子smart plc远程监控应用实例
- 支付宝陷“隐私门”:加强监管避免隐私不当收集
- linux三种网络模式
- 俞敏洪:在一个动荡的时代做不动荡的自己
- 教你如何批量新建文件夹并命名?
- 石油管道泄漏在线监测系统,原来可以这么简单
- 使用BERT fine-tuning 用于推特情感分析
- R语言-matrix生成矩阵
- linux控制台单人五子棋简书,实现一个质量过硬五子棋
- sonar java_如何正确配置属性“sonar.java.binaries”?