YOLOv3学习——锚框和候选区域
YOLOv3学习之锚框和候选区域
单阶段目标检测模型YOLOv3
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并预测出物体的类别和位置坐标。
与R-CNN系列算法不同,YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,不需要分成两阶段来完成检测任务。另外,YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
Joseph Redmon等人在2015年提出YOLO(You Only Look Once,YOLO)算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。
YOLOv3模型设计思想
YOLOv3算法的基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
YOLOv3算法训练过程的流程图如 图1 所示:
图1:YOLOv3算法训练流程图

- 图1 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的132\frac{1}{32}321。
- 图1 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×3232 \times 3232×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
- 将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
接下来具体介绍流程中各节点的原理和代码实现。
文章目录
- YOLOv3学习之锚框和候选区域
- 单阶段目标检测模型YOLOv3
- YOLOv3模型设计思想
- 一、产生候选区域
- 生成锚框
- 生成预测框
- 二、 对候选区域进行标注
- 标注锚框是否包含物体
- 标注预测框的位置坐标标签
- 标注锚框包含物体类别的标签
- 总结
一、产生候选区域
如何产生候选区域,是检测模型的核心设计方案。目前大多数基于卷积神经网络的模型所采用的方式大体如下:
- 按一定的规则在图片上生成一系列位置固定的锚框,将这些锚框看作是可能的候选区域。
- 对锚框是否包含目标物体进行预测,如果包含目标物体,还需要预测所包含物体的类别,以及预测框相对于锚框位置需要调整的幅度。
生成锚框
将原始图片划分成m×nm\times nm×n个区域,如下图所示,原始图片高度H=640H=640H=640, 宽度W=480W=480W=480,如果我们选择小块区域的尺寸为32×3232 \times 3232×32,则mmm和nnn分别为:
m=64032=20m = \frac{640}{32} = 20m=32640=20
n=48032=15n = \frac{480}{32} = 15n=32480=15
如 图2 所示,将原始图像分成了20行15列小方块区域。
图2:将图片划分成多个32x32的小方块

YOLOv3算法会在每个区域的中心,生成一系列锚框。为了展示方便,我们先在图中第十行第四列的小方块位置附近画出生成的锚框,如 图3 所示。
注意:
这里为了跟程序中的编号对应,最上面的行号是第0行,最左边的列号是第0列。

图3:在第10行第4列的小方块区域生成3个锚框
图11 展示在每个区域附近都生成3个锚框,很多锚框堆叠在一起可能不太容易看清楚,但过程跟上面类似,只是需要以每个区域的中心点为中心,分别生成3个锚框。
图4:在每个小方块区域生成3个锚框

生成预测框
在前面已经指出,锚框的位置都是固定好的,不可能刚好跟物体边界框重合,需要在锚框的基础上进行位置的微调以生成预测框。预测框相对于锚框会有不同的中心位置和大小,采用什么方式能得到预测框呢?我们先来考虑如何生成其中心位置坐标。
比如上面图中在第10行第4列的小方块区域中心生成的一个锚框,如绿色虚线框所示。以小方格的宽度为单位长度,
此小方块区域左上角的位置坐标是:
cx=4c_x = 4cx=4
cy=10c_y = 10cy=10
此锚框的区域中心坐标是:
center_x=cx+0.5=4.5center\_x = c_x + 0.5 = 4.5center_x=cx+0.5=4.5
center_y=cy+0.5=10.5center\_y = c_y + 0.5 = 10.5center_y=cy+0.5=10.5
可以通过下面的方式生成预测框的中心坐标:
bx=cx+σ(tx)b_x = c_x + \sigma(t_x)bx=cx+σ(tx)
by=cy+σ(ty)b_y = c_y + \sigma(t_y)by=cy+σ(ty)
其中txt_xtx和tyt_yty为实数,σ(x)\sigma(x)σ(x)是我们之前学过的Sigmoid函数,其定义如下:
σ(x)=11+exp(−x)\sigma(x) = \frac{1}{1 + exp(-x)}σ(x)=1+exp(−x)1
由于Sigmoid的函数值在0∼10 \thicksim 10∼1之间,因此由上面公式计算出来的预测框的中心点总是落在第十行第四列的小区域内部。
当tx=ty=0t_x=t_y=0tx=ty=0时,bx=cx+0.5b_x = c_x + 0.5bx=cx+0.5,by=cy+0.5b_y = c_y + 0.5by=cy+0.5,预测框中心与锚框中心重合,都是小区域的中心。
锚框的大小是预先设定好的,在模型中可以当作是超参数,下图中画出的锚框尺寸是
ph=350p_h = 350ph=350
pw=250p_w = 250pw=250
通过下面的公式生成预测框的大小:
bh=phethb_h = p_h e^{t_h}bh=pheth
bw=pwetwb_w = p_w e^{t_w}bw=pwetw
如果tx=ty=0,th=tw=0t_x=t_y=0, t_h=t_w=0tx=ty=0,th=tw=0,则预测框跟锚框重合。
如果给tx,ty,th,twt_x, t_y, t_h, t_wtx,ty,th,tw随机赋值如下:
tx=0.2,ty=0.3,tw=0.1,th=−0.12t_x = 0.2, t_y = 0.3, t_w = 0.1, t_h = -0.12tx=0.2,ty=0.3,tw=0.1,th=−0.12
则可以得到预测框的坐标是(154.98, 357.44, 276.29, 310.42),如 图5 中蓝色框所示。
说明:
这里坐标采用xywhxywhxywh的格式。

图5:生成预测框
这里我们会问:当tx,ty,tw,tht_x, t_y, t_w, t_htx,ty,tw,th取值为多少的时候,预测框能够跟真实框重合?为了回答问题,只需要将上面预测框坐标中的bx,by,bh,bwb_x, b_y, b_h, b_wbx,by,bh,bw设置为真实框的位置,即可求解出ttt的数值。
令:
σ(tx∗)+cx=gtx\sigma(t^*_x) + c_x = gt_xσ(tx∗)+cx=gtx
σ(ty∗)+cy=gty\sigma(t^*_y) + c_y = gt_yσ(ty∗)+cy=gty
pwetw∗=gthp_w e^{t^*_w} = gt_hpwetw∗=gth
pheth∗=gtwp_h e^{t^*_h} = gt_wpheth∗=gtw
可以求解出:(tx∗,ty∗,tw∗,th∗)(t^*_x, t^*_y, t^*_w, t^*_h)(tx∗,ty∗,tw∗,th∗)
如果ttt是网络预测的输出值,将t∗t^*t∗作为目标值,以他们之间的差距作为损失函数,则可以建立起一个回归问题,通过学习网络参数,使得ttt足够接近t∗t^*t∗,从而能够求解出预测框的位置坐标和大小。
预测框可以看作是在锚框基础上的一个微调,每个锚框会有一个跟它对应的预测框,我们需要确定上面计算式中的tx,ty,tw,tht_x, t_y, t_w, t_htx,ty,tw,th,从而计算出与锚框对应的预测框的位置和形状。
二、 对候选区域进行标注
每个区域可以产生3种不同形状的锚框,每个锚框都是一个可能的候选区域,对这些候选区域我们需要了解如下几件事情:
锚框是否包含物体,这可以看成是一个二分类问题,使用标签objectness来表示。当锚框包含了物体时,objectness=1,表示预测框属于正类;当锚框不包含物体时,设置objectness=0,表示锚框属于负类。
如果锚框包含了物体,那么它对应的预测框的中心位置和大小应该是多少,或者说上面计算式中的tx,ty,tw,tht_x, t_y, t_w, t_htx,ty,tw,th应该是多少,使用location标签。
如果锚框包含了物体,那么具体类别是什么,这里使用变量label来表示其所属类别的标签。
选取任意一个锚框对它进行标注,也就是需要确定其对应的objectness, (tx,ty,tw,th)(t_x, t_y, t_w, t_h)(tx,ty,tw,th)和label,下面将分别讲述如何确定这三个标签的值。
标注锚框是否包含物体
如 图6 所示,这里一共有3个目标,以最左边的人像为例,其真实框是(133.96,328.42,186.06,374.63)(133.96, 328.42, 186.06, 374.63)(133.96,328.42,186.06,374.63)。
图6:选出与真实框中心位于同一区域的锚框
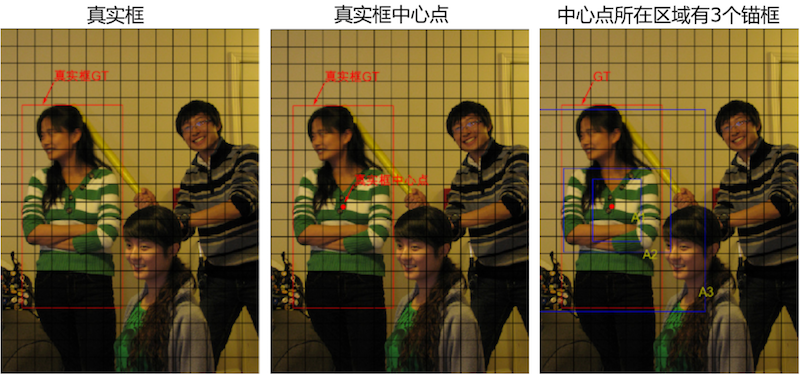
真实框的中心点坐标是:
center_x=133.96center\_x = 133.96center_x=133.96
center_y=328.42center\_y = 328.42center_y=328.42
i=133.96/32=4.18625i = 133.96 / 32 = 4.18625i=133.96/32=4.18625
j=328.42/32=10.263125j = 328.42 / 32 = 10.263125j=328.42/32=10.263125
它落在了第10行第4列的小方块内,如图6所示。此小方块区域可以生成3个不同形状的锚框,其在图上的编号和大小分别是A1(116,90),A2(156,198),A3(373,326)A_1(116, 90), A_2(156, 198), A_3(373, 326)A1(116,90),A2(156,198),A3(373,326)。
用这3个不同形状的锚框跟真实框计算IoU,选出IoU最大的锚框。这里为了简化计算,只考虑锚框的形状,不考虑其跟真实框中心之间的偏移,具体计算结果如 图7 所示。
图7:选出与真实框与锚框的IoU
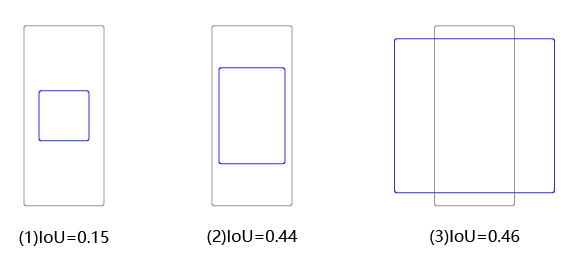
其中跟真实框IoU最大的是锚框A3A_3A3,形状是(373,326)(373, 326)(373,326),将它所对应的预测框的objectness标签设置为1,其所包括的物体类别就是真实框里面的物体所属类别。
依次可以找出其他几个真实框对应的IoU最大的锚框,然后将它们的预测框的objectness标签也都设置为1。这里一共有20×15×3=90020 \times 15 \times 3 = 90020×15×3=900个锚框,只有3个预测框会被标注为正。
由于每个真实框只对应一个objectness标签为正的预测框,如果有些预测框跟真实框之间的IoU很大,但并不是最大的那个,那么直接将其objectness标签设置为0当作负样本,可能并不妥当。为了避免这种情况,YOLOv3算法设置了一个IoU阈值iou_threshold,当预测框的objectness不为1,但是其与某个真实框的IoU大于iou_threshold时,就将其objectness标签设置为-1,不参与损失函数的计算。
所有其他的预测框,其objectness标签均设置为0,表示负类。
对于objectness=1的预测框,需要进一步确定其位置和包含物体的具体分类标签,但是对于objectness=0或者-1的预测框,则不用管他们的位置和类别。
标注预测框的位置坐标标签
当锚框objectness=1时,需要确定预测框位置相对于它微调的幅度,也就是锚框的位置标签。
在前面我们已经问过这样一个问题:当tx,ty,tw,tht_x, t_y, t_w, t_htx,ty,tw,th取值为多少的时候,预测框能够跟真实框重合?其做法是将预测框坐标中的bx,by,bh,bwb_x, b_y, b_h, b_wbx,by,bh,bw设置为真实框的坐标,即可求解出ttt的数值。
令:
σ(tx∗)+cx=gtx\sigma(t^*_x) + c_x = gt_xσ(tx∗)+cx=gtx
σ(ty∗)+cy=gty\sigma(t^*_y) + c_y = gt_yσ(ty∗)+cy=gty
pwetw∗=gtwp_w e^{t^*_w} = gt_wpwetw∗=gtw
pheth∗=gthp_h e^{t^*_h} = gt_hpheth∗=gth
对于tx∗t_x^*tx∗和ty∗t_y^*ty∗,由于Sigmoid的反函数不好计算,我们直接使用σ(tx∗)\sigma(t^*_x)σ(tx∗)和σ(ty∗)\sigma(t^*_y)σ(ty∗)作为回归的目标。
dx∗=σ(tx∗)=gtx−cxd_x^* = \sigma(t^*_x) = gt_x - c_xdx∗=σ(tx∗)=gtx−cx
dy∗=σ(ty∗)=gty−cyd_y^* = \sigma(t^*_y) = gt_y - c_ydy∗=σ(ty∗)=gty−cy
tw∗=log(gtwpw)t^*_w = log(\frac{gt_w}{p_w})tw∗=log(pwgtw)
th∗=log(gthph)t^*_h = log(\frac{gt_h}{p_h})th∗=log(phgth)
如果(tx,ty,th,tw)(t_x, t_y, t_h, t_w)(tx,ty,th,tw)是网络预测的输出值,将(dx∗,dy∗,tw∗,th∗)(d_x^*, d_y^*, t_w^*, t_h^*)(dx∗,dy∗,tw∗,th∗)作为(σ(tx),σ(ty),th,tw)(\sigma(t_x), \sigma(t_y), t_h, t_w)(σ(tx),σ(ty),th,tw)的目标值,以它们之间的差距作为损失函数,则可以建立起一个回归问题,通过学习网络参数,使得ttt足够接近t∗t^*t∗,从而能够求解出预测框的位置。
标注锚框包含物体类别的标签
对于objectness=1的锚框,需要确定其具体类别。正如上面所说,objectness标注为1的锚框,会有一个真实框跟它对应,该锚框所属物体类别,即是其所对应的真实框包含的物体类别。这里使用one-hot向量来表示类别标签label。比如一共有10个分类,而真实框里面包含的物体类别是第2类,则label为(0,1,0,0,0,0,0,0,0,0)(0,1,0,0,0,0,0,0,0,0)(0,1,0,0,0,0,0,0,0,0)
对上述步骤进行总结,标注的流程如 图8 所示。
图8:标注流程示意图
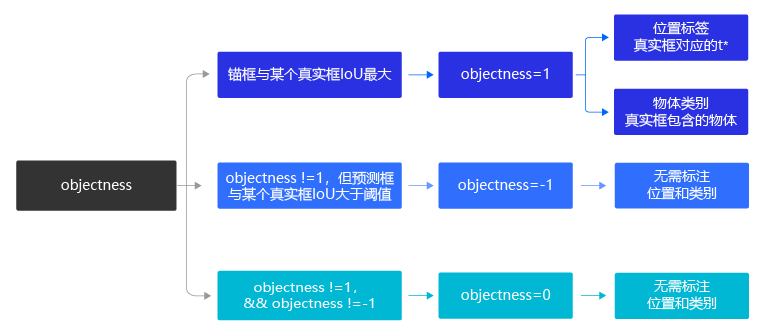
通过这种方式,我们在每个小方块区域都生成了一系列的锚框作为候选区域,并且根据图片上真实物体的位置,标注出了每个候选区域对应的objectness标签、位置需要调整的幅度以及包含的物体所属的类别。位置需要调整的幅度由4个变量描述(tx,ty,tw,th)(t_x, t_y, t_w, t_h)(tx,ty,tw,th),objectness标签需要用一个变量描述objobjobj,描述所属类别的变量长度等于类别数C。
对于每个锚框,模型需要预测输出(tx,ty,tw,th,Pobj,P1,P2,...,PC)(t_x, t_y, t_w, t_h, P_{obj}, P_1, P_2,... , P_C)(tx,ty,tw,th,Pobj,P1,P2,...,PC),其中PobjP_{obj}Pobj是锚框是否包含物体的概率,P1,P2,...,PCP_1, P_2,... , P_CP1,P2,...,PC则是锚框包含的物体属于每个类别的概率。接下来让我们一起学习如何通过卷积神经网络输出这样的预测值。
# 标注预测框的objectness
def get_objectness_label(img, gt_boxes, gt_labels, iou_threshold = 0.7,anchors = [116, 90, 156, 198, 373, 326],num_classes=7, downsample=32):"""img 是输入的图像数据,形状是[N, C, H, W]gt_boxes,真实框,维度是[N, 50, 4],其中50是真实框数目的上限,当图片中真实框不足50个时,不足部分的坐标全为0真实框坐标格式是xywh,这里使用相对值gt_labels,真实框所属类别,维度是[N, 50]iou_threshold,当预测框与真实框的iou大于iou_threshold时不将其看作是负样本anchors,锚框可选的尺寸anchor_masks,通过与anchors一起确定本层级的特征图应该选用多大尺寸的锚框num_classes,类别数目downsample,特征图相对于输入网络的图片尺寸变化的比例"""img_shape = img.shapebatchsize = img_shape[0]num_anchors = len(anchors) // 2input_h = img_shape[2]input_w = img_shape[3]# 将输入图片划分成num_rows x num_cols个小方块区域,每个小方块的边长是 downsample# 计算一共有多少行小方块num_rows = input_h // downsample# 计算一共有多少列小方块num_cols = input_w // downsamplelabel_objectness = np.zeros([batchsize, num_anchors, num_rows, num_cols])label_classification = np.zeros([batchsize, num_anchors, num_classes, num_rows, num_cols])label_location = np.zeros([batchsize, num_anchors, 4, num_rows, num_cols])scale_location = np.ones([batchsize, num_anchors, num_rows, num_cols])# 对batchsize进行循环,依次处理每张图片for n in range(batchsize):# 对图片上的真实框进行循环,依次找出跟真实框形状最匹配的锚框for n_gt in range(len(gt_boxes[n])):gt = gt_boxes[n][n_gt]gt_cls = gt_labels[n][n_gt]gt_center_x = gt[0]gt_center_y = gt[1]gt_width = gt[2]gt_height = gt[3]if (gt_width < 1e-3) or (gt_height < 1e-3):continuei = int(gt_center_y * num_rows)j = int(gt_center_x * num_cols)ious = []for ka in range(num_anchors):bbox1 = [0., 0., float(gt_width), float(gt_height)]anchor_w = anchors[ka * 2]anchor_h = anchors[ka * 2 + 1]bbox2 = [0., 0., anchor_w/float(input_w), anchor_h/float(input_h)]# 计算iouiou = box_iou_xywh(bbox1, bbox2)ious.append(iou)ious = np.array(ious)inds = np.argsort(ious)k = inds[-1]label_objectness[n, k, i, j] = 1c = gt_clslabel_classification[n, k, c, i, j] = 1.# for those prediction bbox with objectness =1, set label of locationdx_label = gt_center_x * num_cols - jdy_label = gt_center_y * num_rows - idw_label = np.log(gt_width * input_w / anchors[k*2])dh_label = np.log(gt_height * input_h / anchors[k*2 + 1])label_location[n, k, 0, i, j] = dx_labellabel_location[n, k, 1, i, j] = dy_labellabel_location[n, k, 2, i, j] = dw_labellabel_location[n, k, 3, i, j] = dh_label# scale_location用来调节不同尺寸的锚框对损失函数的贡献,作为加权系数和位置损失函数相乘scale_location[n, k, i, j] = 2.0 - gt_width * gt_height# 目前根据每张图片上所有出现过的gt box,都标注出了objectness为正的预测框,剩下的预测框则默认objectness为0# 对于objectness为1的预测框,标出了他们所包含的物体类别,以及位置回归的目标return label_objectness.astype('float32'), label_location.astype('float32'), label_classification.astype('float32'), \scale_location.astype('float32')
# 计算IoU,矩形框的坐标形式为xywh
def box_iou_xywh(box1, box2):x1min, y1min = box1[0] - box1[2]/2.0, box1[1] - box1[3]/2.0x1max, y1max = box1[0] + box1[2]/2.0, box1[1] + box1[3]/2.0s1 = box1[2] * box1[3]x2min, y2min = box2[0] - box2[2]/2.0, box2[1] - box2[3]/2.0x2max, y2max = box2[0] + box2[2]/2.0, box2[1] + box2[3]/2.0s2 = box2[2] * box2[3]xmin = np.maximum(x1min, x2min)ymin = np.maximum(y1min, y2min)xmax = np.minimum(x1max, x2max)ymax = np.minimum(y1max, y2max)inter_h = np.maximum(ymax - ymin, 0.)inter_w = np.maximum(xmax - xmin, 0.)intersection = inter_h * inter_wunion = s1 + s2 - intersectioniou = intersection / unionreturn iou
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
YOLOv3学习——锚框和候选区域相关推荐
- [飞桨] 目标检测篇 YOLO-V3 学习笔记(一)
学习这一篇课程之前,就听说过YOLO的大名.在疫情期间,有up主就通过yolo训练出了对行人口罩的检测并且大获成功,没成想今天有幸学习到.废话不多说,直接开始学习. 目标检测中的基础概念 在开始学习Y ...
- 【从零开始学Mask RCNN】四,RPN锚框生成和Proposal生成
1. Mask RCNN Anchor框 生成 Mask RCNN的锚框生成和SSD的锚框生成策略类似(SSD的锚框生成策略见:[资源分享]从零开始学习SSD教程) ,都遵循以下规则: Anchor的 ...
- 目标检测之锚点与锚框
导读:目标检测模型使用锚框去预测物体的位置框,它对于目标检测任务具有关键意义.理解并仔细地微调模型的锚框是对于提升检测性能非常重要,特别是数据集具有不规则的物体时. 锚框与目标检测任务 目标检测,不同 ...
- 【目标检测算法-锚框公式推导及代码详解】
目标检测算法-锚框公式推导及代码详解 0 沐神对锚框的宽高计算并未推导以及讲解 1 锚框宽高公式推导 1.1 基础概念 1.2 锚框宽高公式推导 1.3 图片验证计算 1.4 小结 2 代码详解 2. ...
- 深度学习笔记(41) 候选区域
深度学习笔记(41) 候选区域 1. 无对象区域 2. 候选区域 3. Faster R-CNN 1. 无对象区域 记得滑动窗法吧,使用训练过的分类器 在这些窗口中全部运行一遍,然后运行一个检测器,看 ...
- R-CNN算法学习(步骤一:候选区域生成)
R-CNN算法学习(步骤一:候选区域生成) 论文链接:https://arxiv.org/abs/1311.2524 源码链接:https://github.com/rbgirshick/rcnn 算 ...
- 3.10 候选区域-深度学习第四课《卷积神经网络》-Stanford吴恩达教授
←上一篇 ↓↑ 下一篇→ 3.9 YOLO 算法 回到目录 3.11 总结 候选区域 (Region proposals) 如果你们阅读一下对象检测的文献,可能会看到一组概念,所谓的候选区域,这在计算 ...
- 动手学深度学习之锚框
锚框 锚框就是一个框,边缘框就是一个物体的真实的位置的一个框,锚框是对这个边缘框位置的一个猜测.算法先给我们画出一个框,然后看这个框里面有没有物体.如果有的话,算法就基于这个物体进行预测,它到我们真实 ...
- 《动手学深度学习》(七) -- 边界框和锚框
1 边界框 在目标检测中,我们通常使用边界框(bounding box)来描述对象的空间位置.边界框是矩形的,由矩形左上角的以及右下角的xxx和yyy坐标决定.另一种常用的边界框表示方法是边界框中心的 ...
最新文章
- 计算机专业美国最好的学校排名,美国计算机专业大学排名
- Mozilla两款火狐插件包含恶意代码被紧急喊停
- BestCoder-Round#33
- gpio 树莓派3a+_树莓派4正式发布!硬件性能大提升:CPU提升3倍,支持USB3.0、蓝牙5.0、千兆以太网、4G LPDDR4、H.265...
- [转贴]玩你没商量:ADSL速率数字游戏解密
- 【系统设计】发现类的方法
- radio默认选中并显示相应信息 php,php实现select、radio、checkbox默认选择示例
- mysql数据库文件结构同步,[数据库的表同步mysql]MySQL表结构同步
- 【React】react实现前端播放m3u8格式视频
- 中小学教师计算机培训心得,小学教师信息技术培训心得体会2篇
- 相机参数标定+透视变换
- 移动端H5的js操作
- 项目风险常见清单列表库
- VS2022编译libpng库
- 【JNLP】什么是JNLP
- 虚拟局域网VLAN实验操作
- CSP VICTALL 荣获久负盛名的 JEC 创新奖
- Python 入门学习10 —— 文件操作的应用及升级版三级菜单
- 怎么查看电脑cuda版本
- 使用html语言检测鼠标微动是否发生双击
热门文章
- MMI笔记 virtual environments, audio for virtual environments 知识点总结
- java 图片 转像素_使用Java改变图片的像素
- 总账科目 前台操作关事务代码及操作要点
- 华为HCIA认证考试简介
- 计算机应用基础自学手写笔记,计算机应用基础第一章笔记.docx
- 支付宝微信的数字经营项目是风口还是割韭菜(带项目评测)
- sasl java_java SASL_SSL 帐号密码 方式访问 kafka
- 【BJOI2019】排兵布阵 DP
- 面试系列——爱奇艺Andromeda 跨进程通信组件分析
- wampserver图标为绿色,打开localhost页面错误提示:The requested URL / was not found on this server