深度学习笔记~感受野(receptive field)的计算
以前对CNN中的感受野(receptive field)已经有了一些认识,基本上是从概念理解上得到的。
本篇文章给出了receptive field的计算过程和相应的python代码,对receptive的理解和计算有较好的帮助作用。
转载:https://medium.com/mlreview/a-guide-to-receptive-field-arithmetic-for-convolutional-neural-networks-e0f514068807
备注:全文是英文的,如果需要阅读原文可能需要VPN。
A guide to receptive field arithmetic for Convolutional Neural Networks
author:Dang Ha The Hien
The receptive field is perhaps one of the most important concepts in Convolutional Neural Networks (CNNs) that deserves more attention from the literature. All of the state-of-the-art object recognition methods design their model architectures around this idea. However, to my best knowledge, currently there is no complete guide on how to calculate and visualize the receptive field information of a CNN. This post fills in the gap by introducing a new way to visualize feature maps in a CNN that exposes the receptive field information, accompanied by a complete receptive field calculation that can be used for any CNN architecture. I’ve also implemented a simple program to demonstrate the calculation so that anyone can start computing the receptive field and gain better knowledge about the CNN architecture that they are working with.
To follow this post, I assume that you are familiar with the CNN concept, especially the convolutional and pooling operations. You can refresh your CNN knowledge by going through the paper “A guide to convolution arithmetic for deep learning [1]”. It will not take you more than half an hour if you have some prior knowledge about CNNs. This post is in fact inspired by that paper and uses similar notations.
Note: If you want to learn more about how CNNs can be used for Object Recognition, this post is for you.
The fixed-sized CNN feature map visualization
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by). A receptive field of a feature can be described by its center location and its size. (Edit later) However, not all pixels in a receptive field is equally important to its corresponding CNN’s feature. Within a receptive field, the closer a pixel to the center of the field, the more it contributes to the calculation of the output feature. Which means that a feature does not only look at a particular region (i.e. its receptive field) in the input image, but also focus exponentially more to the middle of that region. This important insight will be explained further in another blog post. For now, we focus on calculating the location and size of a particular receptive field.
Figure 1 shows some receptive field examples. By applying a convolution C with kernel size k = 3x3, padding size p = 1x1, stride s = 2x2 on an input map 5x5, we will get an output feature map 3x3 (green map). Applying the same convolution on top of the 3x3 feature map, we will get a 2x2 feature map (orange map). The number of output features in each dimension can be calculated using the following formula, which is explained in detail in [1].

Note that in this post, to simplify things, I assume the CNN architecture to be symmetric, and the input image to be square. So both dimensions have the same values for all variables. If the CNN architecture or the input image is asymmetric, you can calculate the feature map attributes separately for each dimension.
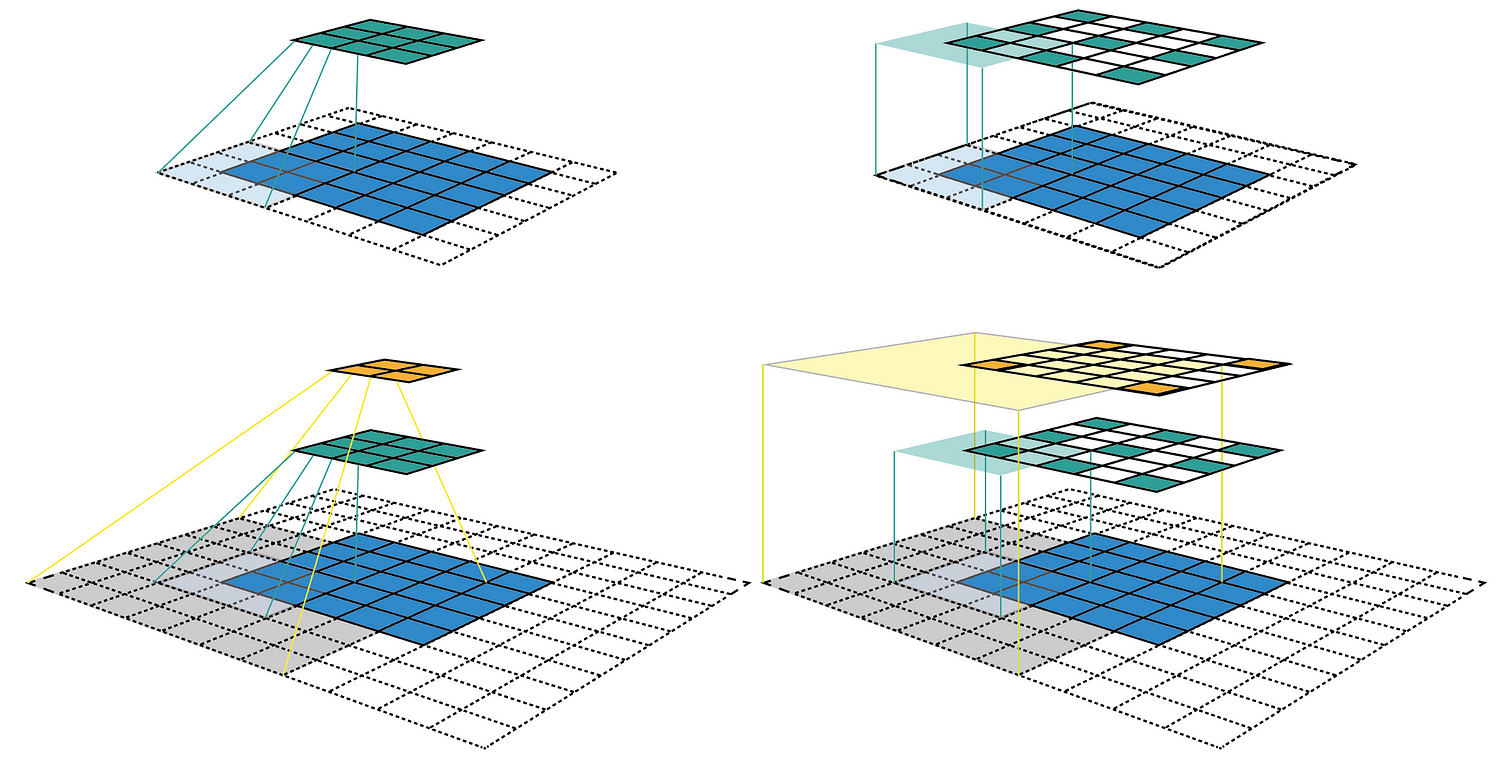
Figure 1: Two ways to visualize CNN feature maps. In all cases, we uses the convolution C with kernel size k = 3x3, padding size p = 1x1, stride s = 2x2. (Top row) Applying the convolution on a 5x5 input map to produce the 3x3 green feature map. (Bottom row) Applying the same convolution on top of the green feature map to produce the 2x2 orange feature map. (Left column) The common way to visualize a CNN feature map. Only looking at the feature map, we do not know where a feature is looking at (the center location of its receptive field) and how big is that region (its receptive field size). It will be impossible to keep track of the receptive field information in a deep CNN. (Right column) The fixed-sized CNN feature map visualization, where the size of each feature map is fixed, and the feature is located at the center of its receptive field.
The left column of Figure 1 shows a common way to visualize a CNN feature map. In that visualization, although by looking at a feature map, we know how many features it contains. It is impossible to know where each feature is looking at (the center location of its receptive field) and how big is that region (its receptive field size). The right column of Figure 1 shows the fixed-sized CNN visualization, which solves the problem by keeping the size of all feature maps constant and equal to the input map. Each feature is then marked at the center of its receptive field location. Because all features in a feature map have the same receptive field size, we can simply draw a bounding box around one feature to represent its receptive field size. We don’t have to map this bounding box all the way down to the input layer since the feature map is already represented in the same size of the input layer. Figure 2 shows another example using the same convolution but applied on a bigger input map — 7x7. We can either plot the fixed-sized CNN feature maps in 3D (Left) or in 2D (Right). Notice that the size of the receptive field in Figure 2 escalates very quickly to the point that the receptive field of the center feature of the second feature layer covers almost the whole input map. This is an important insight which was used to improve the design of a deep CNN.
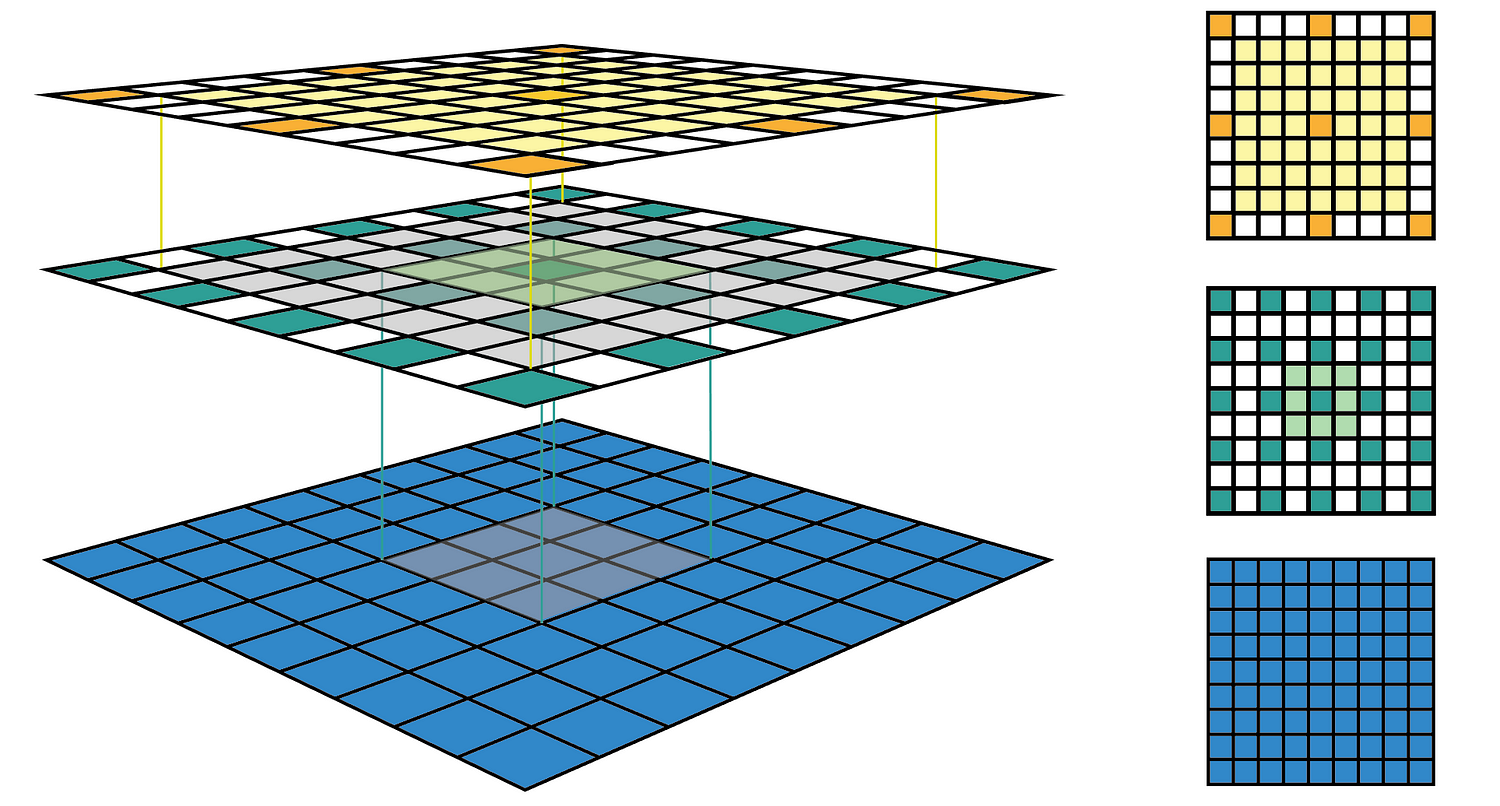
Figure 2: Another fixed-sized CNN feature map representation. The same convolution C is applied on a bigger input map with i = 7x7. I drew the receptive field bounding box around the center feature and removed the padding grid for a clearer view. The fixed-sized CNN feature map can be presented in 3D (Left) or 2D (Right).
Receptive Field Arithmetic
To calculate the receptive field in each layer, besides the number of features n in each dimension, we need to keep track of some extra information for each layer. These include the current receptive field size r , the distance between two adjacent features (or jump) j, and the center coordinate of the upper left feature (the first feature) start. Note that the center coordinate of a feature is defined to be the center coordinate of its receptive field, as shown in the fixed-sized CNN feature map above. When applying a convolution with the kernel size k, the padding size p, and the stride size s, the attributes of the output layer can be calculated by the following equations:

- The first equation calculates the number of output features based on the number of input features and the convolution properties. This is the same equation presented in [1].
- The second equation calculates the jump in the output feature map, which is equal to the jump in the input map times the number of input features that you jump over when applying the convolution (the stride size).
- The third equation calculates the receptive field size of the output feature map, which is equal to the area that covered by k input features (k-1)*j_inplus the extra area that covered by the receptive field of the input feature that on the border.
- The fourth equation calculates the center position of the receptive field of the first output feature, which is equal to the center position of the first input feature plus the distance from the location of the first input feature to the center of the first convolution (k-1)/2*j_in minus the padding spacep*j_in. Note that we need to multiply with the jump of the input feature map in both cases to get the actual distance/space.
The first layer is the input layer, which always has n = image size, r = 1, j = 1, and start = 0.5. Note that in Figure 3, I used the coordinate system in which the center of the first feature of the input layer is at 0.5. By applying the four above equations recursively, we can calculate the receptive field information for all feature maps in a CNN. Figure 3 shows an example of how these equations work.
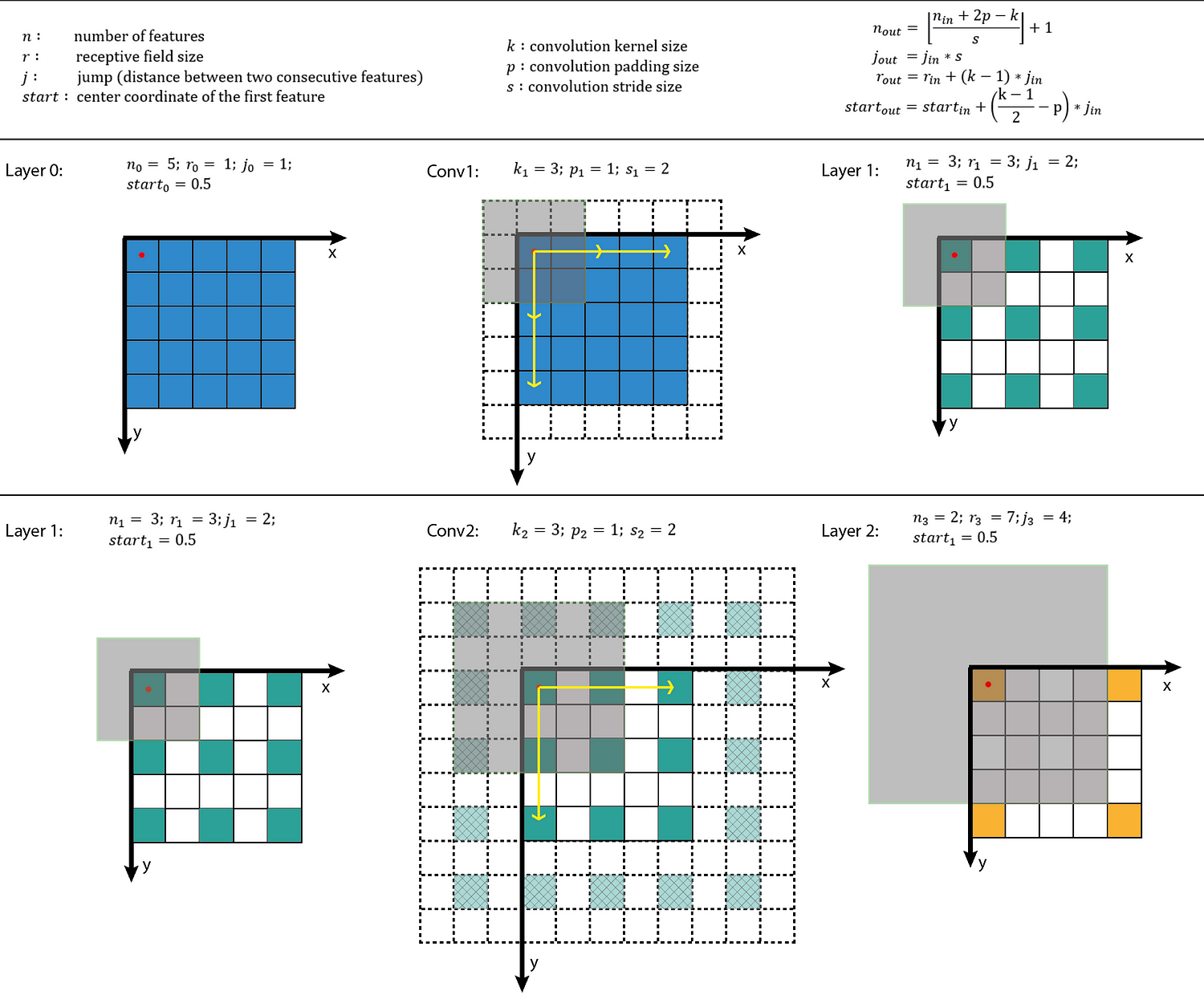
Figure 3: Applying the receptive field calculation on the example given in Figure 1. The first row shows the notations and general equations, while the second and the last row shows the process of applying it to calculate the receptive field of the output layer given the input layer information.
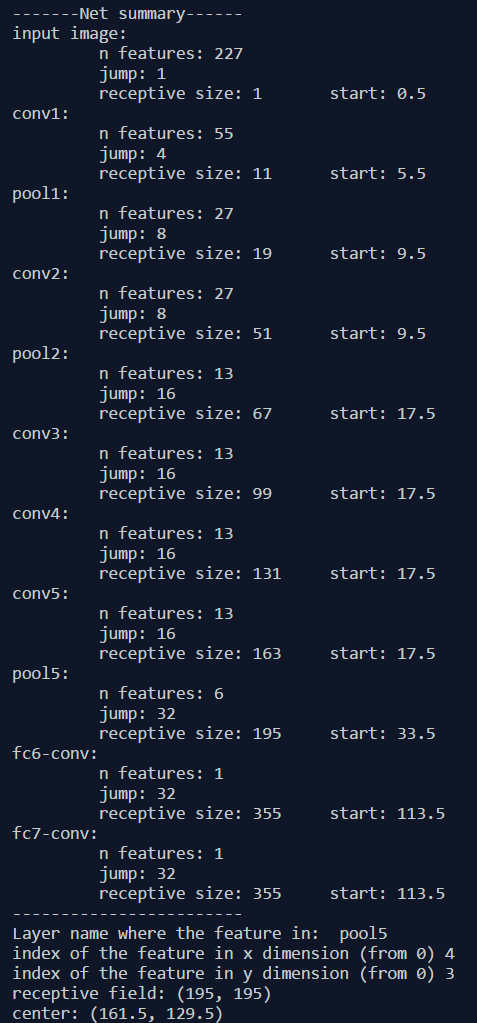
I’ve also created a small python program that calculates the receptive field information for all layers in a given CNN architecture. It also allows you to input the name of any feature map and the index of a feature in that map, and returns the size and location of the corresponding receptive field. The following figure shows an output example when we use the AlexNet. The code is provided at the end of this post.
# [filter size, stride, padding]
#Assume the two dimensions are the same
#Each kernel requires the following parameters:
# - k_i: kernel size
# - s_i: stride
# - p_i: padding (if padding is uneven, right padding will higher than left padding; "SAME" option in tensorflow)
#
#Each layer i requires the following parameters to be fully represented:
# - n_i: number of feature (data layer has n_1 = imagesize )
# - j_i: distance (projected to image pixel distance) between center of two adjacent features
# - r_i: receptive field of a feature in layer i
# - start_i: position of the first feature's receptive field in layer i (idx start from 0, negative means the center fall into padding)import math
convnet = [[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0],[6,1,0], [1, 1, 0]]
layer_names = ['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5','fc6-conv', 'fc7-conv']
imsize = 227def outFromIn(conv, layerIn):n_in = layerIn[0]j_in = layerIn[1]r_in = layerIn[2]start_in = layerIn[3]k = conv[0]s = conv[1]p = conv[2]n_out = math.floor((n_in - k + 2*p)/s) + 1actualP = (n_out-1)*s - n_in + k pR = math.ceil(actualP/2)pL = math.floor(actualP/2)j_out = j_in * sr_out = r_in + (k - 1)*j_instart_out = start_in + ((k-1)/2 - pL)*j_inreturn n_out, j_out, r_out, start_outdef printLayer(layer, layer_name):print(layer_name + ":")print("\t n features: %s \n \t jump: %s \n \t receptive size: %s \t start: %s " % (layer[0], layer[1], layer[2], layer[3]))layerInfos = []
if __name__ == '__main__':
#first layer is the data layer (image) with n_0 = image size; j_0 = 1; r_0 = 1; and start_0 = 0.5print ("-------Net summary------")currentLayer = [imsize, 1, 1, 0.5]printLayer(currentLayer, "input image")for i in range(len(convnet)):currentLayer = outFromIn(convnet[i], currentLayer)layerInfos.append(currentLayer)printLayer(currentLayer, layer_names[i])print ("------------------------")layer_name = raw_input ("Layer name where the feature in: ")layer_idx = layer_names.index(layer_name)idx_x = int(raw_input ("index of the feature in x dimension (from 0)"))idx_y = int(raw_input ("index of the feature in y dimension (from 0)"))n = layerInfos[layer_idx][0]j = layerInfos[layer_idx][1]r = layerInfos[layer_idx][2]start = layerInfos[layer_idx][3]assert(idx_x < n)assert(idx_y < n)print ("receptive field: (%s, %s)" % (r, r))print ("center: (%s, %s)" % (start+idx_x*j, start+idx_y*j))computeReceptiveField.py hosted with ❤ by GitHub
深度学习笔记~感受野(receptive field)的计算相关推荐
- 深度CNN感受野(Receptive Field)的计算
参考 如何计算感受野(Receptive Field)--原理 FOMORO AI -> 可视化计算感受野的网站,可以用来验证自己计算的结果 Python代码 这里使用的是从后向前的计算方法,简 ...
- 深度学习之学习(1-2)感受野(receptive field)
参见:原始图片中的ROI如何映射到到feature map? - 知乎 1 感受野的概念 在卷积神经网络中,感受野的定义是 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像 ...
- 深度学习笔记(一)—— 计算梯度[Compute Gradient]
这是深度学习笔记第一篇,完整的笔记目录可以点击这里查看. 有两种方法来计算梯度:一种是计算速度慢,近似的,但很简单的方法(数值梯度),另一种是计算速度快,精确的,但更容易出错的方法,需要 ...
- 深度学习笔记其五:卷积神经网络和PYTORCH
深度学习笔记其五:卷积神经网络和PYTORCH 1. 从全连接层到卷积 1.1 不变性 1.2 多层感知机的限制 1.2.1 平移不变性 1.2.2 局部性 1.3 卷积 1.4 "沃尔多在 ...
- 李宏毅深度学习笔记——呕心整理版
李宏毅深度学习笔记--呕心整理版 闲谈叨叨叨: 之前看过吴恩达的一部分课程,所以有一定理论基础,再看李宏毅的课程会有新的理解.我先以有基础的情况写完学习过程,后续再以零基础的角度补充细节概念(估计不会 ...
- 【动手深度学习-笔记】注意力机制(四)自注意力、交叉注意力和位置编码
文章目录 自注意力(Self-Attention) 例子 Self-Attention vs Convolution Self-Attention vs RNN 交叉注意力(Cross Attenti ...
- 深度学习笔记之关于常用模型或者方法
九.Deep Learning的常用模型或者方法 9.1.AutoEncoder自动编码器 Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(ANN)本身就是具有层次结 ...
- 深度学习笔记之关于常用模型或者方法(四)
不多说,直接上干货! 九.Deep Learning的常用模型或者方法 9.1.AutoEncoder自动编码器 Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(AN ...
- 【深度学习笔记】神经网络模型及经典算法知识点问答巩固(算法工程师面试笔试)
文章目录 前言 一.前馈神经网络模型 1.请说说你对前馈神经网络中"前馈"二字的理解. 2.记忆和知识是存储在_____上的.我们通常是通过逐渐改变_____来学习新知识. 3.在 ...
最新文章
- 野指针与内存泄漏那些事
- 服务器传感器不显示,服务器传感器不显示
- unef螺纹_小螺纹大学问,11种螺纹类型,你都使用过吗,了解它的使用方法吗
- BNUOJ 4215 最长公共连续子序列
- Optical_Flow(1)
- 如何维持手机电池寿命_延长手机电池寿命终极技巧教学,iPhone和安卓手机皆适合...
- 使用ZooKeeper编程 - 一个基本教程
- vs code没有代码提示
- 第三章:变量与字符串等基础知识
- 如何在C ++中使用std :: getline()?
- 【转】vista下SMB共享的解决办法
- Java自学视频整理
- MySQL数据库介绍
- telnet如何测试端口?
- 【OpenCV 例程200篇】203. 伪彩色图像处理
- python生成倒计时图片_用Python自动化生成新年倒计时图片
- 博客-需求说明答辩总结
- laydate-v5.0.9自定义小时范围和分钟间隔(半小时)
- C#实现屏幕键盘(软键盘 ScreenKeyboard)
- Python在cmd下pip快速下载安装包的国内安装镜像