网络攻防 横向移动_网络安全101的数据分析:检测横向移动
网络攻防 横向移动
This is the second part of a series of blog posts. You can read the first one on Data Exfiltration.
这是一系列博客文章的第二部分。 您可以阅读有关数据渗透的第一篇文章。
This blog post is structured as follows:
该博客文章的结构如下:
Introduction Lateral Movement (4 mins): a toy example to illustrate what lateral movement is
简介横向运动 (4分钟): 一个玩具例子,说明什么是横向运动
Network Anomaly Detection (7 mins): Statistical and machine learning techniques to detect lateral movement
网络异常检测 (7分钟) :统计和机器学习技术来检测横向运动
CTF Challenges (3 mins): Solution to 3 CTF challenges on finding lateral movement
CTF挑战 (3分钟) :解决 寻找横向运动的3个CTF挑战
Breach Reports (4 mins): Real-life examples and what we can learn from them
违规报告 (4分钟) :实际示例以及我们可以从中学习的内容
Visibility and Sensor Vantage (3 mins): Checking the quality of your data and the extent of your visibility
可见性和传感器优势 (3分钟) :检查数据质量和可见性范围
Dark Space and Honeypots (2 mins): Things to do to make it easier to detect lateral movement
黑暗空间和蜜罐 (2分钟) :要做的事情使它更容易检测到横向运动
前提 (Premise)
Nice! You have successfully been able to detect and stop data exfiltration, but the battle is far from over. We still suspect that there are baddies lurking in your network. Being the responsible network security administrator that you are, you start hunting. Use network flow data to hunt for even more anomalous security events.
真好! 您已经成功地能够检测和阻止 数据泄露 ,但是战斗还没有结束。 我们仍然怀疑您的网络中潜伏着坏人。 作为您负责任的网络安全管理员,您就可以开始寻找。 使用网络流数据寻找更多异常安全事件。
妥协推定 (Presumption of compromise)
A “healthy” mindset to have as a network security administrator is to presume that you have already been compromised, and with that, your objective is to find evidence of the adversary’s post-exploitation activities.
作为网络安全管理员,有一个“健康”的心态是假设您已经受到攻击 ,因此,您的目标是找到对手的利用后活动的证据。
Remember, exploitation is just the first step for the attacker, and they still need to take additional steps to fulfill their primary object.
请记住,剥削只是攻击者的第一步,他们仍然需要采取其他步骤来实现其主要目标。

Recall from the previous blog post, after the initial compromise, in order to steal your data, the attacker needs to go through the following steps:
回想一下先前的博客文章 ,经过最初的妥协之后,为了窃取您的数据,攻击者需要执行以下步骤:
(1) The attacker needs to coordinate with their foothold using some command and control (C2) channel.
(1) 攻击者需要使用一些命令和控制(C2)通道协调其立足点 。

(2) Using the C2, the attacker needs to reach the data by navigating through the network and moving laterally.
(2) 攻击者需要使用C2,通过在网络中导航和横向移动来获取数据 。

(3) Once the attacker has access to the data, the attacker needs to exfiltrate this data out of the network.
(3)一旦攻击者访问了数据, 攻击者便需要将这些数据从网络中泄漏出去。

In this blog post, we will go through some simple ways of detecting lateral movement, and some notes on how we can design our systems to be defensible and monitorable so that we can continuously defend our network.
在此博客文章中,我们将介绍一些检测横向运动的简单方法,并说明如何设计可防御和可监控的系统,从而使我们能够不断防御网络。
横向运动 (Lateral Movement)

玩具案例研究 (Toy Case Study)
When the attacker successfully compromises a host, it is likely that the host doesn’t have the necessary credentials, privileges, and network access to get to the company’s secret data. In that case, the attacker has to utilize their existing foothold to gain higher-levels of access.
当攻击者成功入侵主机后,主机可能没有必要的凭据,特权和网络访问权限来获取公司的机密数据。 在这种情况下,攻击者必须利用他们现有的立足点来获得更高级别的访问权限。
Before we go deeper into detecting lateral movement, let us use a toy case study so that we can “picture” what is really going on.
在深入检测横向运动之前,让我们使用一个玩具案例研究,以便我们可以“描绘”出实际发生的情况。
We have two main departments in our network:
我们的网络中有两个主要部门:
- HR Department: Opens a lot of random emails from job applicants. They only have access to the internal email server.
人力资源部:打开许多求职者发送的随机电子邮件。 他们只能访问内部电子邮件服务器。 - IT Group: Manages production databases and employee desktops
IT组:管理生产数据库和员工桌面
HR employees are an easier target for the bad guy, but, even if an HR employee is tricked into opening a malicious PDF that gives the attacker access to an HR machine, this access won’t immediately give him access to the production data. So what now?
HR员工更容易成为坏人的目标,但是,即使HR员工被欺骗打开了恶意PDF,使攻击者可以访问HR计算机,但这种访问不会立即使他能够访问生产数据。 所以现在怎么办?
Below we illustrate our toy case study and how an attacker might be able to pivot internally to be able to eventually gain access to the production data.
下面我们说明了玩具案例研究,以及攻击者如何能够内部进行枢转以最终能够访问生产数据。

The attacker sends a fake job application email and HR opens the attached CV. This turns out to be a malicious PDF, which helps the attacker establish a foothold in the HR subnet using a reverse shell.
攻击者发送虚假的工作申请电子邮件,然后HR打开附件中的简历。 事实证明这是一个恶意PDF ,它可以帮助攻击者使用反向外壳在HR子网中建立立足点 。
With brute force, the attacker gets the local administrator credentials of the HR machine and is able to escalate his privilege.
利用蛮力, 攻击者可以获得HR计算机的本地管理员凭据,并且能够提升其特权。
Unfortunately, all machines have the same local administrator credentials. Using these credentials, he is able to pivot to a host in the IT group subnet.
不幸的是, 所有计算机都具有相同的本地管理员凭据。 使用这些凭据,他可以转到IT组子网中的主机。
Tunneling through the IT group host, he is able to access all production servers.
通过IT小组的主持人 ,他能够访问所有生产服务器。
How do we detect this lateral movement? There are some things that the diagram above does not show. Think about how the attacker is able to discover the different accounts, hosts, and services that he used to pivot.
我们如何检测这种横向运动? 上图没有显示某些内容。 考虑一下攻击者如何能够发现他过去使用的不同帐户,主机和服务。
主机发现 [1] (Host Discovery [1])

Between step 2 and step 3 above, the bad guy has to somehow know what IP address in the IT subnet he can pivot to. How did he find this IP?
在上面的第2步和第3步之间,坏人必须以某种方式知道他可以转向的IT子网中的IP地址。 他是如何找到该IP的?
One way to do this is by scanning for accessible IP’s doing a network scan. If the scan ends up enumerating all the hosts in a subnet, this can be noisy and easy to detect.
一种方法是通过扫描可访问IP进行网络扫描。 如果扫描最终枚举了子网中的所有主机,则这可能很嘈杂且易于检测。
A telltale sign of this is a single source host attempting to establish connections to numerous destination hosts. This is in TCP, UDP, and ICMP.
一个明显的迹象是单个源主机试图建立与多个目标主机的连接。 这是在TCP,UDP和ICMP中。
Also notice that when scanning for accessible hosts, some connections might not be allowed by the firewall. If your firewall logs these dropped attempts, then this will give us another way of detecting network scanning. Another red flag is when the firewall drops a lot of different connections from a single source host.
另请注意,在扫描可访问的主机时,防火墙可能不允许某些连接。 如果您的防火墙记录了这些丢弃的尝试,那么这将为我们提供另一种检测网络扫描的方法。 另一个危险信号是防火墙从单个源主机断开许多不同的连接时。
In some cases, having a single dropped connection is also a red flag especially if the network is set up well. For example, if a production web server tries to connect to an internal host and this gets dropped by a firewall rule, something weird might be happening.
在某些情况下,断开单个连接也是一个危险信号,尤其是在网络设置良好的情况下。 例如,如果生产Web服务器尝试连接到内部主机,但由于防火墙规则而被丢弃,则可能正在发生奇怪的事情。
服务发现 [2] (Service Discovery [2])

Now that the attacker knows which hosts he can reach, the next question might be, what services do they have? Between steps 3 and 4, the attacker could have first discovered that there is a service running on port 5432 that is why he figured it was probably a PostgreSQL server.
既然攻击者知道了他可以到达的主机,那么下一个问题可能是,他们拥有什么服务? 在步骤3和步骤4之间,攻击者可能首先发现端口5432上正在运行一项服务,这就是为什么他认为它可能是PostgreSQL服务器。
Discovering exposed running services involve trying to find the host’s open ports through a port scan. This can be very noisy as well depending on the attacker’s objective.
发现公开的正在运行的服务涉及尝试通过端口扫描找到主机的开放端口。 这也可能非常嘈杂,具体取决于攻击者的目标。
By default, nmap scans 1000 “interesting” ports [3] of each protocol. However, the attacker might opt to scan all 65535 ports which would be even noisier. Or the attacker might be more covert by opting to scan only a few ports he cares about such as ports 139 and 445 for NetBIOS service scanning.
默认情况下,nmap扫描每个协议的1000个“有趣”端口 [3]。 但是,攻击者可能会选择扫描所有65535个端口,这甚至会更加嘈杂。 否则,攻击者可能会选择只扫描他关心的几个端口,例如用于NetBIOS服务扫描的端口139和445,从而更加隐秘。
For the more covert port scanning, this is closer to looking for signs of host scanning.
对于更隐蔽的端口扫描,这更接近于寻找主机扫描的迹象。
For the noisy port scanning, we are looking for sources that try to connect to a lot of destination ports. Relevant logs are network flow logs or firewall logs.
对于嘈杂的端口扫描,我们正在寻找尝试连接到许多目标端口的源。 相关日志是网络流日志或防火墙日志。
If you set up alerts for this, the first things you should find are your vulnerability scanners. If you don’t find these, then you are doing something wrong.
如果为此设置警报,则首先应该找到的是漏洞扫描程序。 如果找不到这些,则说明您做错了。
端点到端点的连接 (Endpoint to endpoint connections)
The most common connections that you should see in your network are from an endpoint to a server or a server to another server. It shouldn’t be common to see endpoints talk to one another, and even more uncommon to see connections from server to an endpoint. (This especially if you do not expect employees to create their own file shares.)
您应该在网络中看到的最常见的连接是从端点到服务器或从服务器到另一台服务器。 看到端点之间相互通信并不常见,而看到服务器与端点之间的连接则更为常见。 (尤其是在您不希望员工创建自己的文件共享的情况下。)
An example where endpoint to endpoint connection is benign is a connection from IT to different hosts on the net. This might be for maintenance or updates.
端点到端点的连接是良性的一个示例是从IT到网络上不同主机的连接。 这可能是为了维护或更新。

However, an HR machine establishing a connection directly to an IT machine is probably not normal.
但是,直接建立与IT机器的连接的HR机器可能不正常。

The more “intimately” you know your network, the more you can narrow down the types of connections that might be anomalous, and which of those really matter.
您对网络的了解越“亲密”,就越能缩小可能异常的连接的类型以及真正重要的连接的范围。
In the toy example, we can set-up an alert for any connection attempt from an HR machine to any other host except for the email server. We can even block any connection of HR to any internal host except for the email server.
在玩具示例中,我们可以为从HR计算机到除电子邮件服务器以外的任何其他主机的任何连接尝试设置警报。 我们甚至可以阻止HR到除电子邮件服务器之外的任何内部主机的任何连接。
网络异常检测 (Network Anomaly Detection)

The methods we’ve discussed so far are signature-based. Based on our identified mechanisms of how lateral movement might happen, we define business rules and encode them as alerts. With these, we are able to incorporate as much domain expertise and context to our alerts. Done properly, these provide us with alerts with a good signal-to-noise ratio.
到目前为止,我们讨论的方法都是基于签名的。 基于我们确定的横向运动如何发生的机制,我们定义业务规则并将其编码为警报。 有了这些,我们就可以将尽可能多的领域专业知识和上下文纳入我们的警报中。 做得好,这些可以为我们提供具有良好信噪比的警报。
Although these type of rules are necessary to defend our network, they may not be sufficient to properly defend our networks because:
尽管这些类型的规则对于捍卫我们的网络是必要的,但它们可能不足以适当地捍卫我们的网络,因为:
- The complexity of the network scales much faster than the security team’s added manpower
网络的扩展比安全团队增加的人力要快得多 - Enterprise networks are not static, and continuous monitoring and re-baselining is needed
企业网络不是静态的,因此需要连续的监视和重新设定基准 - Business rules are not robust in detecting novel attacks
业务规则在检测新型攻击方面不够强大
If your network is relatively small, then you can survive with rule-based alerts, because you can probably describe all normal connections that you expect to see and create an alert for those that you don’t consider normal. These hosts should only talk to the DNS, and Proxy server. This server should only connect to this database. Only these particular hosts should connect to the production databases…
如果您的网络相对较小,则可以使用基于规则的警报,因为您可以描述您希望看到的所有正常连接,并为那些您认为不正常的警报创建警报。 这些主机应仅与DNS和代理服务器通信。 该服务器应仅连接到该数据库。 仅这些特定主机应连接到生产数据库…
However, as your network grows larger, complexity increases, it becomes almost impossible to keep track of all these. That is why we want to explore some techniques for network anomaly detection.
但是,随着网络规模的扩大,复杂性的增加,几乎无法跟踪所有这些信息。 这就是为什么我们要探索一些用于网络异常检测的技术。
The hypothesis is that a malicious host would deviate from the typical behavior. If we are somehow able to capture the characteristics of “normal” in an automated way, then hopefully we are able to catch malicious activities by sifting through the “abnormal”.
假设是恶意主机将偏离典型行为。 如果我们能够以某种方式自动捕获“正常”的特征,那么希望我们能够通过筛选“异常”来捕获恶意活动。
Good ways to define and model “normal” is an area of on-going research. For this blog post, we will look mainly at two approaches:
定义和建模“正常”的好方法是正在进行的研究领域。 对于此博客文章,我们将主要研究两种方法:
- Finding outliers in hosts’ behavioral signatures.
在主机的行为签名中查找异常值。 - Finding unexpected connections through new edge/link prediction
通过新的边缘/链接预测查找意外连接
主机行为签名中的异常值 (Outliers in Host Behavioral Signatures)
The idea here is to summarize the behavior of hosts for a given time interval into a single vector. With these all of the host vectors, we can identify hosts who seem out of place with the rest of the network.
这里的想法是将给定时间间隔内的主机行为汇总为单个向量。 利用所有这些主机向量,我们可以识别在网络其余部分看来不合时宜的主机。
Feature Engineering
特征工程
The first most important step is to build features for each host in the network.
最重要的第一步是为网络中的每个主机构建功能。

What features should we get? Well, it depends on what is available to you and what the security domain experts of your organization advise.
我们应该获得什么功能? 好吧,这取决于您可以使用的内容以及组织的安全领域专家的建议。
As a starting point, we look at what features the paper [13] used. They used a total of 23 features:
首先,我们看一下论文[13]使用的功能。 他们总共使用了23个功能:
RDP Features: SuccessfulLogonRDPPortCount, UnsuccessfulLogonRDPPortCount, RDPOutboundSuccessfulCount, RDPOutboundFailedCount, RDPInboundCount
RDP功能: SuccessfulLogonRDPPortCount,UnsuccessfulLogonRDPPortCount,RDPOutboundSuccessfulCount,RDPOutboundFailedCount,RDPInboundCount
SQL Features: UnsuccessfulLogonSQLPortCount, SQLOutboundSuccessfulCount, SQLOutboundFailedCount, SQLInboundCount
SQL功能: UnsuccessfulLogonSQLPortCount,SQLOutboundSuccessfulCount,SQLOutboundFailedCount,SQLInboundCount
Successful Logon Features: SuccessfulLogonTypeInteractiveCount, SuccessfulLogonTypeNetworkCount, SuccessfulLogonTypeUnlockCount, SuccessfulLogonTypeRemoteInteractiveCount, SuccessfulLogonTypeOtherCount
成功登录功能: SuccessfulLogonTypeInteractiveCount,SuccessfulLogonTypeNetworkCount,SuccessfulLogonTypeUnlockCount,SuccessfulLogonTypeRemoteInteractiveCount,SuccessfulLogonTypeOtherCount
Unsuccessful Logon Features: UnsuccessfulLogonTypeInteractiveCount, UnsuccessfulLogonTypeNetworkCount, UnsuccessfulLogonTypeUnlockCount, UnsuccessfulLogonTypeRemoteInteractiveCount, UnsuccessfulLogonTypeOtherCount
不成功的登录功能: UnsuccessfulLogonTypeInteractiveCount,UnsuccessfulLogonTypeNetworkCount,UnsuccessfulLogonTypeUnlockCount,UnsuccessfulLogonTypeRemoteInteractiveCount,UnsuccessfulLogonTypeOtherCount
Others: NtlmCount, DistinctSourceIPCount, DistinctDestinationIPCount
其他: NtlmCount,DistinctSourceIPCount,DistinctDestinationIPCount
Other examples of features from [14] are:
[14]中功能的其他示例包括:
- Whether at least one address verification failed over the last 24 hours
最近24小时内是否至少有一次地址验证失败 - The maximum outlier score given to an IP address from which the user has accessed the website
用户访问网站所用的IP地址的最大异常值 - The minimum time from login to checkout
从登录到结帐的最短时间 - The number of different locations from which a user has accessed the website over the last 24 hours.
在过去24小时内,用户访问网站的不同位置的数量。
With these feature vectors, we can build a matrix and start using outlier detection techniques.
有了这些特征向量,我们可以构建矩阵并开始使用异常检测技术。
Principal component analysis
主成分分析
We start with a classical way of finding outliers using principal component analysis (PCA) [15] because it is the most visual, in my opinion.
我们从采用主成分分析(PCA)[15]的异常值的经典方法开始,因为我认为它是最直观的。
In simple terms, you can think of PCA is a way to compress and decompress data, where the data lost during compression in minimized.
简而言之,您可以想到PCA是一种压缩和解压缩数据的方法,其中压缩期间丢失的数据被最小化。
Since most of the data should be normal, then the low-rank approximation from PCA would focus on normal data. How does PCA perform with outliers?
由于大多数数据应该是正常数据,因此PCA的低秩近似将集中在正常数据上。 PCA如何处理异常值?
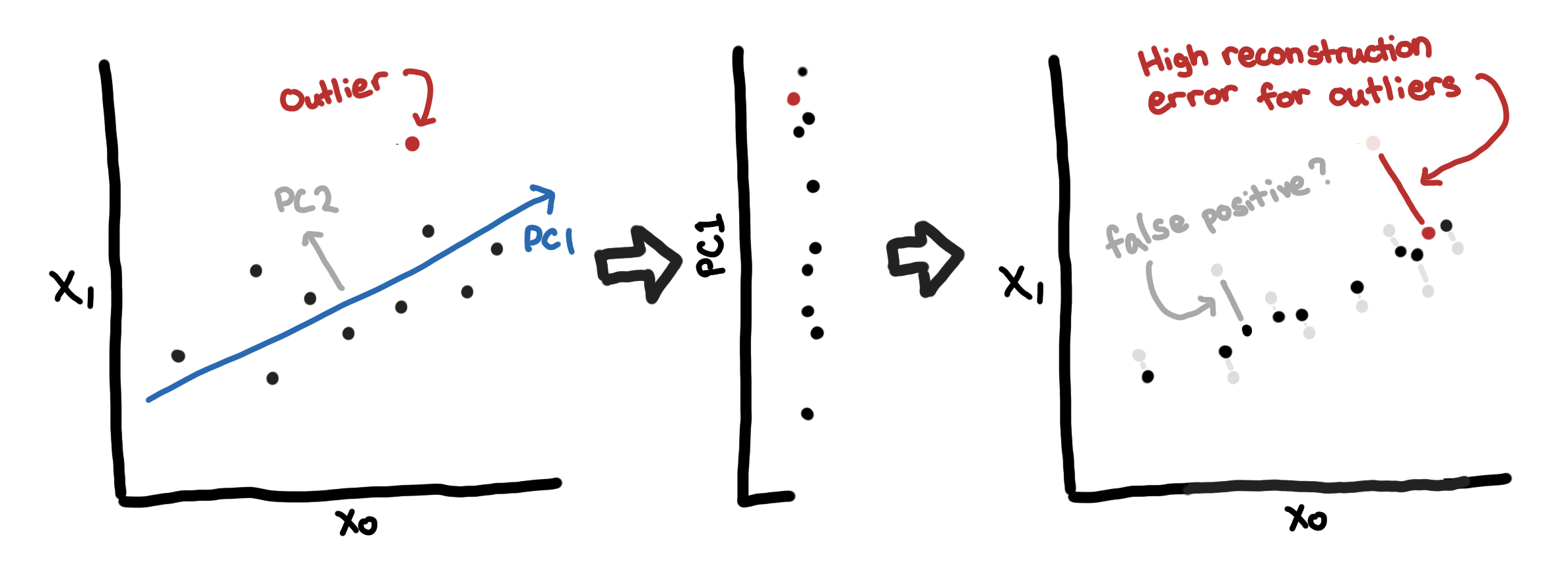
Since the outliers do not conform to the correlation structure of the rest of the data, these would have high reconstruction errors. One way to visualize this is to think of the “normal data” as the background activity of the network.
由于离群值不符合其余数据的相关结构,因此它们将具有较高的重构误差。 可视化的一种方法是将“正常数据”视为网络的后台活动。
Below we see a more visual example from the numerical linear algebra course of fast.ai [12]. They constructed a matrix from the different frames of the video. The image on the left is one frame of the video. The image in the middle is the low-rank approximation using Robust PCA. The image on the right is the difference, the reconstruction error.
下面我们从fast.ai [12]的数值线性代数过程中看到一个更直观的示例。 他们从视频的不同帧构建了一个矩阵。 左侧的图像是视频的一帧。 中间的图像是使用稳健PCA的低秩近似。 右边的图像是差异,即重构误差。

In the example above, the “subjects” of the video typically appear in the reconstruction error. Similarly, we are hoping that anomalous hosts would stand out from the background and have high reconstruction errors.
在上面的示例中,视频的“主题”通常出现在重建错误中。 同样,我们希望异常主机能够在后台脱颖而出,并具有较高的重构错误。
Note: Classical PCA can be sensitive to outliers (unfortunately), so it might be better to use Robust PCA discussed in [12]
注意:经典PCA可能对异常值敏感(不幸的是),因此最好使用[12]中讨论的健壮PCA。
自动编码器 (Autoencoders)
I won’t go into much detail on Autoencoders, but you can think of autoencoders as a non-linear version of PCA.
我不会详细介绍自动编码器,但是您可以将自动编码器视为PCA的非线性版本。
The neural network is constructed such that there is an information bottleneck in the middle. By forcing the network to go through a small number of nodes in the middle, it forces the network to prioritize the most meaningful latent variables, which is like the principal components in PCA.
构造神经网络以使中间存在信息瓶颈。 通过迫使网络经过中间的少量节点,它迫使网络对最有意义的潜在变量进行优先级排序,就像PCA中的主要组件一样。

Similar to the PCA, if the autoencoder is trained on normal data, then it can have a hard to reconstructing the outlier data. The reconstruction error can be used as an “anomaly score”.
与PCA相似,如果对自动编码器进行常规数据训练,则很难重构异常数据。 重建误差可以用作“异常分数”。
PCA and autoencoder are some of the components used by [14] for detecting malicious hosts in an unsupervised manner.
PCA和自动编码器是[14]用于以无监督方式检测恶意主机的某些组件。
Isolation forests and other methods
隔离林和其他方法
Another popular way to find anomalous hosts is by using isolation forests, which has been shown to this performed better than other methods [13]. Just like many tree-based algorithms, this can handle both numerical and categorical data and there are few assumptions on the distribution and shape of the data.
另一种流行的查找异常主机的方法是使用隔离林,这种隔离林比其他方法表现更好[13]。 就像许多基于树的算法一样,它可以处理数值和分类数据,并且对数据的分布和形状的假设很少。
In the end, we want to use our historical data to learn a function that can aid us in distinguishing what is normal and not normal.
最后,我们希望使用历史数据来学习一个函数,该函数可以帮助我们区分正常情况和非正常情况。
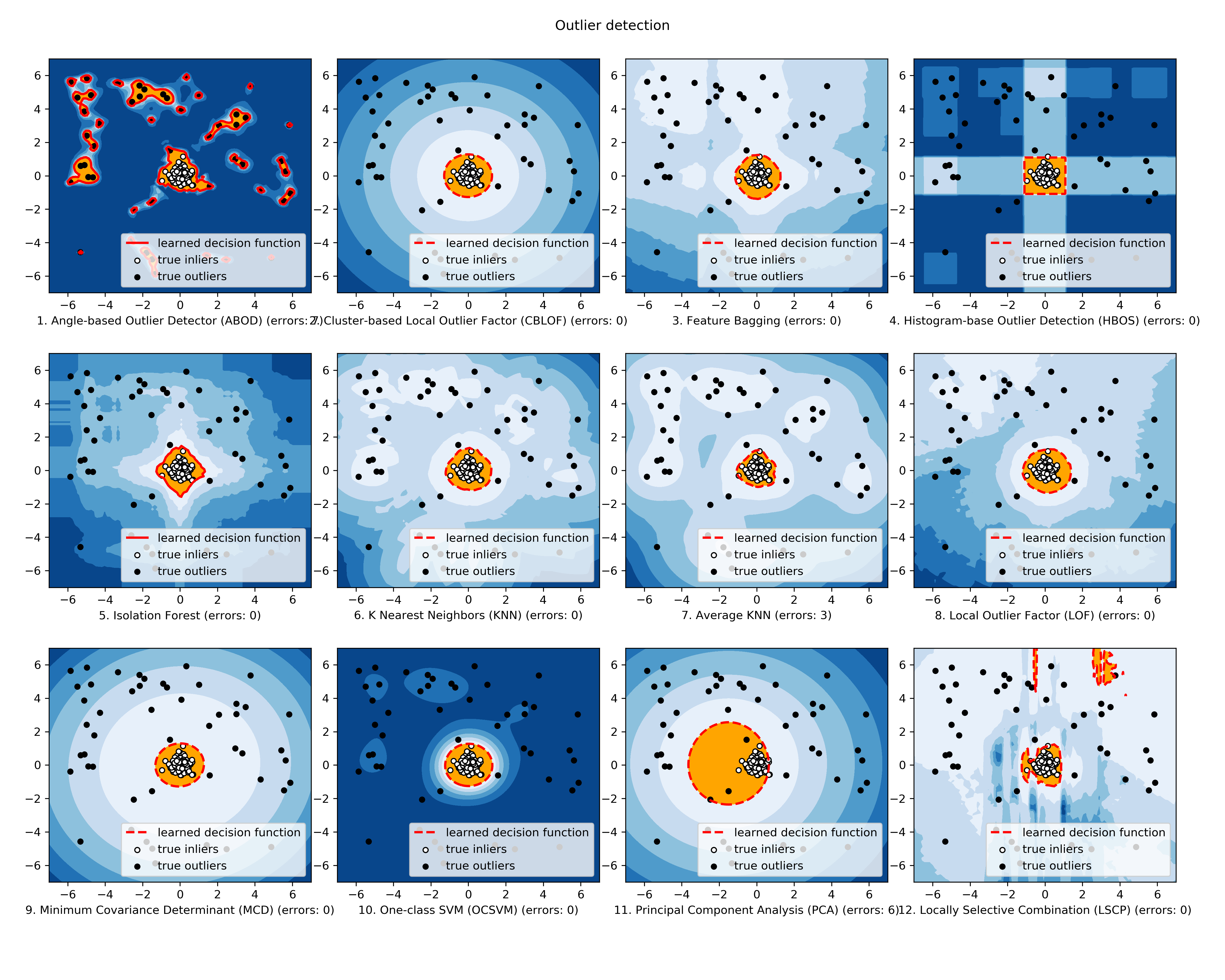
If you want to explore different methods for outlier detection, I recommend going through PyOD [16] and go through the implemented algorithms and the papers that they cite.
如果您想探索用于异常值检测的不同方法,我建议您仔细阅读PyOD [16],并仔细阅读已实现的算法及其引用的论文。
If you are interested in learning more about this I would recommend watching Anomaly Detection: Algorithms, Explanations, Applications [17].
如果您有兴趣了解更多有关此的知识,我建议您观看“ 异常检测:算法,解释,应用程序” [17]。
新的边缘/链接预测 (New Edge/Link Prediction)
This is an oversimplification of [11]
这是[11]的过分简化
Unlike the previous methods, where we try to find malicious hosts. Here, we try to find anomalous edges, where an edge is a connection between a client and a server, or source and destination. The source/client can also be usernames and the edges represent authentication.
与以前的方法不同,我们尝试查找恶意主机。 在这里,我们尝试找到异常边缘,其中边缘是客户端与服务器之间或源与目标之间的连接。 源/客户端也可以是用户名,边缘代表身份验证。

Now suppose this the first time we are seeing this edge. We might ask, what is the probability of observing this new edge?
现在假设这是我们第一次看到此优势。 我们可能会问, 观察到这一新优势的可能性是多少?

For the function above, we need to have some sort of representation for both the client and the server. We can have categorical covariates for example:
对于上面的功能,我们需要对客户端和服务器都有某种表示形式。 我们可以使用分类协变量,例如:
- The subnet of the host
主机的子网 - The type of host (endpoint or server)
主机类型(端点或服务器) - Job title of the user
用户的职务 - Location of the user
用户位置
With categorical covariates, represented by a binary indicator variable, we can use the interactions of the source and destination to get an idea of how likely the new edge is.
使用以二进制指示符变量表示的分类协变量,我们可以使用源和目标之间的相互作用来了解新边的可能性。
Getting embeddings for source and destination
获取源和目标的嵌入
One other way to represent a host is to generate some sort of embeddings.
表示主机的另一种方法是生成某种嵌入。
Let us say from the historical data, we have previously observed the following edges. A host can be both a source in some connections and a destination in some other connection.
让我们根据历史数据说,我们以前已经观察到以下方面。 主机既可以是某些连接中的源,也可以是某些其他连接中的目的地。

From this, we can construct an adjacency matrix, where each cell represents a possible edge, and edges that have been observed have a value of 1.
据此,我们可以构造一个邻接矩阵,其中每个像元代表一个可能的边,并且观察到的边的值为1。

Using this matrix, we can perform some non-negative matrix factorization. This is something that we see in other applications such as recommender systems and collaborative filtering. Through the factorization, we are able to get embeddings for both source and destination.
使用此矩阵,我们可以执行一些非负矩阵分解。 这是我们在其他应用程序(例如推荐系统和协作过滤)中看到的。 通过分解,我们能够获得源和目标的嵌入。

Link prediction
链接预测
The paper [18] shows how to be able to the factorization while incorporating the categorical covariates. This is done through Poisson Matrix Factorization (PMF).
论文[18]展示了如何在合并分类协变量的同时进行因式分解。 这是通过泊松矩阵分解(PMF)完成的。
After estimating the embeddings and some necessary coefficients , we can estimate how likely observing new edges are.
在估计嵌入和一些必要的系数之后,我们可以估计观察新边缘的可能性。

I hope you get a high-level idea of what we’re trying to do, but of course, estimating the values for α,β, and ɸ in a computationally efficient way is the crux of the problem. Details can be seen [18] and there are. Another paper that is also on edge prediction is [11].
我希望您对我们正在尝试做的事情有一个高层次的了解,但是,当然,以计算有效的方式估算α,β和values的值是问题的症结所在。 可以看到细节[18] 。 另一篇关于边缘预测的论文是[11]。
If you are interested in more applications of statistics in cyber security I suggest watching Nick Heard’s talk Data Science in Cyber-Security and Related Statistical Challenges [19].
如果您对统计学在网络安全中的更多应用感兴趣,建议您观看Nick Heard的演讲《网络安全中的数据科学和相关统计挑战》 [19]。
CTF挑战 (CTF Challenges)

The following is a(very late) partial walkthrough of Wildcard 400 challenge in the 2019 Trend Micro CTF specific to lateral movement. Try out the challenges here, and solutions can be found in this kernel.
以下是2019年趋势科技CTF中针对横向移动的Wildcard 400挑战的部分(非常晚)演练。 在这里尝试挑战,就可以在此内核中找到解决方案。
Data here is synthetic and does not model typical network protocols and behavior. So deep knowledge of network protocols is not needed for these challenges.
这里的数据是综合性的,不能模拟典型的网络协议和行为。 因此,对于这些挑战不需要深入了解网络协议。
侧蛮 (Lateral Brute)
Question 9: Once a machine is popped, it’s often used to explore what else can be reached. One host is being used to loudly probe the entire enterprise, trying to find ways onto every other host in the enterprise. What is its IP?
问题9:机器弹出后,通常会用来探索还能达到的目标。 一个主机正被用来大声探查整个企业,试图找到进入企业中其他主机的方式。 它的IP是什么?
We see that the host is scanning the entire network. This probably means that we are looking for signs of host scanning.
我们看到主机正在扫描整个网络。 这可能意味着我们正在寻找主机扫描的迹象。
To do this we get the source IP addresses that have a lot of unique destination IPs.
为此,我们获得具有很多唯一目标IP的源IP地址。

Here it is clear that 13.42.70.40 is scanning and trying to move laterally. For completeness, we look at its network activities and see a spike in network activity due to scanning on off-hours.
在这里很明显13.42.70.40正在扫描并试图横向移动。 为了完整起见,我们查看了其网络活动,并发现由于非工作时间扫描导致网络活动激增。

Scanning that is not throttled is very noisy and generates a lot of traffic. So if the attacker doesn’t try to be covert with their network scanning, this is something we expect to see.
没有节流的扫描非常嘈杂,并且会产生大量流量。 因此,如果攻击者不试图对其网络扫描进行隐蔽,这是我们期望看到的。
横向间谍 (Lateral Spy)
Question 10: One host is trying to find a way onto every other host more quietly. What is its IP?
问题10:一个主机正在尝试更安静地找到通往其他主机的方法。 它的IP是什么?
This is a trickier question. After excluding 13.42.70.40, it is hard to find any other host that stands out in terms of count of unique destination IPs or destination ports.
这是一个棘手的问题。 在排除13.42.70.40之后,很难找到其他任何在唯一目标IP或目标端口的数量方面脱颖而出的主机。
Thus, the following plots are useless. The bad host is blending in with the background activities of normal hosts.
因此,以下图无用。 不良主机与普通主机的后台活动混在一起。


We have to find a more creative way to find the scanning activity. If we had more context of the network, then we can focus on:
我们必须找到一种更具创造性的方式来找到扫描活动。 如果我们拥有更多的网络环境,那么我们可以专注于:
- connection to ports that are not used in the network
连接到网络中未使用的端口 - connections to endpoints
与端点的连接
This is something that we know from baselining our network, but we did not have that kind of context in our network. To infer what ports were “normal”, we assumed that if multiple source hosts connected to a particular IP address and port, then it is probably normal.
从网络的基线可以知道这一点,但是我们的网络中没有这种上下文。 为了推断哪些端口是“正常”端口,我们假设如果多个源主机连接到特定的IP地址和端口,则可能是正常的。

For example, we see multiple hosts connect to 12.37.117.51:56 then this is probably a normal connection.
例如,我们看到多个主机连接到12.37.117.51:56那么这可能是正常连接。
For 12.32.36.56:68 , we see that only 12.49.123.62 attempted to connect to it. This is probably abnormal.
对于12.32.36.56:68 ,我们看到只有12.49.123.62尝试连接到它。 这可能是异常的。
After filtering out the normal destination IP and ports, the only source host left is 12.49.123.62 . This is our bad IP.
过滤掉正常的目标IP和端口后,剩下的唯一源主机是12.49.123.62 。 这是我们的不良IP。
奖金(可选):内部P2P (Bonus (Optional): Internal P2P)
Question 5: Sometimes our low-grade infection is visible in other ways. One particular virus has spread through a number of machines, which now are used to relay commands to each other. The malware has created an internal P2P network. What unique port is used by the largest internal clique, of all hosts talking to each other?
问题5:有时我们的低度感染可以通过其他方式看到。 一种特定的病毒已经通过许多机器传播,这些机器现在用于相互传递命令。 该恶意软件创建了一个内部P2P网络。 最大的内部团体在互相交谈的主机中使用哪个独特的端口?
This is related to detecting lateral movement but the solution involves using analysis techniques from graph theory.
这与检测横向运动有关,但是解决方案涉及使用图论的分析技术。
This problem is pretty straightforward since the question directly asks for the largest clique. A clique is a set of hosts that all have connections to one another.
这个问题非常简单,因为问题直接要求最大的派系 。 团体是一组彼此之间都具有连接的主机。

Using NetworkX, we can get the exact answer by enumerating all cliques and finding the largest one. However, this does not scale well.
使用NetworkX ,我们可以通过列举所有群体并找到最大的群体来获得确切的答案。 但是,这不能很好地扩展。
We opt to use the fast approximate method large_clique_size(G).
我们选择使用快速近似方法large_clique_size(G) 。
G = networkx.Graph()G.add_nodes_from(internal_nodes)for l, r in zip(internal_edges.src, internal_edges.dst): G.add_edge(l, r)
_size = large_clique_size(G)With the code above we can get the large cliques for a particular port but this is too slow to run for all ports. To speed up the search, we filter out the ports where the maximal clique is guaranteed to be small.
通过上面的代码,我们可以获得特定端口的大量信息,但这对于所有端口都运行太慢。 为了加快搜索速度,我们过滤掉了保证最大团团很小的端口。
It is easy to show that if a clique of size K exists inside graph G, then there should exist at least K nodes in G with degree greater than or equal to K-1. Given this fact, we can compute an upper bound for the clique size for each port. The code to do this is in the solutions kernel.
这是很容易证明,如果尺寸的集团K存在内部图表G ,那么就应该至少存在K节点G度数大于或等于K-1 鉴于这一事实,我们可以为每个端口计算集团大小的上限。 执行此操作的代码在解决方案内核中 。
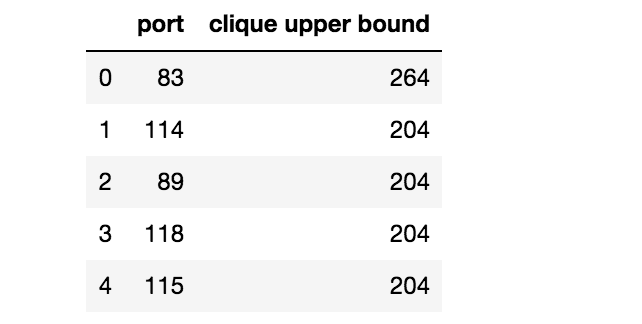
Processing these ports we find that port 83 has a maximal clique of 264.
处理这些端口后,我们发现端口83的最大派系为264 。
违规报告 (Breach Reports)

In this section, we will go through historical “shipwrecks” from previous data breaches.
在本节中,我们将经历以前的数据泄露带来的历史“沉船”。
2018 SingHealth数据泄露 [5] (2018 SingHealth Data Breach [5])
The 2018 SingHealth data breach had data of 1.5 million patients of the Singapore Health Services was stolen. This incident is closest to our toy case study.
2018年SingHealth数据泄露事件中有150万新加坡医疗服务患者的数据被盗。 此事件最接近我们的玩具案例研究。

Briefly, the key events are:
简要地说,主要事件是:
Although it is not clear in the report exactly how it happened, we know that the attacker was able to install malware on Workstation A through a phishing attack.
尽管报告中还不清楚确切的发生方式,但我们知道攻击者能够通过网络钓鱼攻击在Workstation A上安装恶意软件。
Using access to Workstation A, the attacker was able to compromise multiple endpoints and servers. According to the report, the attacker is likely to have compromised the Windows authentication system and obtained administrator and user credentials from the domain controllers.
攻击者使用对Workstation A的访问权限,可以破坏多个端点和服务器。 根据该报告,攻击者可能已经破坏了Windows身份验证系统,并从域控制器获取了管理员和用户凭据。
Eventually, the attacker was able to control Workstation B, which was a workstation that had access to the SCM application. With it, the attacker was able to find the proper credentials to compromise the SCM system
最终,攻击者能够控制工作站B,工作站B是可以访问SCM应用程序的工作站。 有了它,攻击者便能够找到适当的凭据来破坏SCM系统
- Ran numerous queries on SCM database
在SCM数据库上运行大量查询 Exfiltrated the data through Workstation A
通过工作站A提取数据
Here are some of the contributing factors that were identified in the report.
以下是报告中确定的一些促成因素。
Network connections between the SGH Citrix servers and the SCM database were allowed.
允许SGH Citrix服务器和SCM数据库之间的网络连接。
The network connections between Citrix server farm to the SCM database server were allowed. A basic security review of the network architecture could have shown that this open network connection created a security vulnerability.
允许Citrix服务器场与SCM数据库服务器之间的网络连接。 对网络体系结构的基本安全检查可能表明,这种开放的网络连接创建了一个安全漏洞。
Had the two systems been isolated, the attacker would not have been able to access the SCM database as easily.
如果将两个系统隔离开,攻击者将无法轻松访问SCM数据库。
Based on the report, one of the reasons for keeping this open network connection between the two systems is for operational efficiency. The administrators wanted to be able to use the Citrix Server and the tools installed there to manage the multiple databases of the different systems.
根据该报告,在两个系统之间保持这种开放网络连接的原因之一是为了提高运营效率。 管理员希望能够使用Citrix服务器及其中安装的工具来管理不同系统的多个数据库。
SGH Citrix servers were not adequately secured against unauthorized access
SGH Citrix服务器的安全性不足,无法防止未经授权的访问
A lot of the factors here are related to authentication and credential management, which is beyond the scope of this blog post. One that is relevant to us now is, Lack of firewalls to prevent unauthorized remote access using RDP to the SGH Citrix servers.
这里的许多因素与身份验证和凭据管理有关,这超出了本博客文章的范围。 现在与我们有关的一个问题是, 缺少防火墙,以防止使用RDP对SGH Citrix服务器进行未经授权的远程访问。
2018年NASA JPL违规 [6] (2018 NASA JPL Breach [6])
The 2018 NASA JPL breach was famous for having the headline of “NASA hacked because of unauthorized raspberry pi”. The final report does not go into a lot of detail on what the initial point of entry was, how exactly did the attacker gain access to the raspberry pi, and where the raspberry pi is situated.
2018年NASA JPL违规事件的标题是“ NASA因未授权的树莓派而被黑客入侵 ”。 最终报告没有详细介绍最初的入口点是什么,攻击者如何确切地获得了树莓派的访问权限以及树莓派的位置。
What I find interesting is the finding “Inadequate Segmentation of Network Environment Shared with External Partners”.
我发现有趣的发现是“ 与外部合作伙伴共享的网络环境细分不足”。
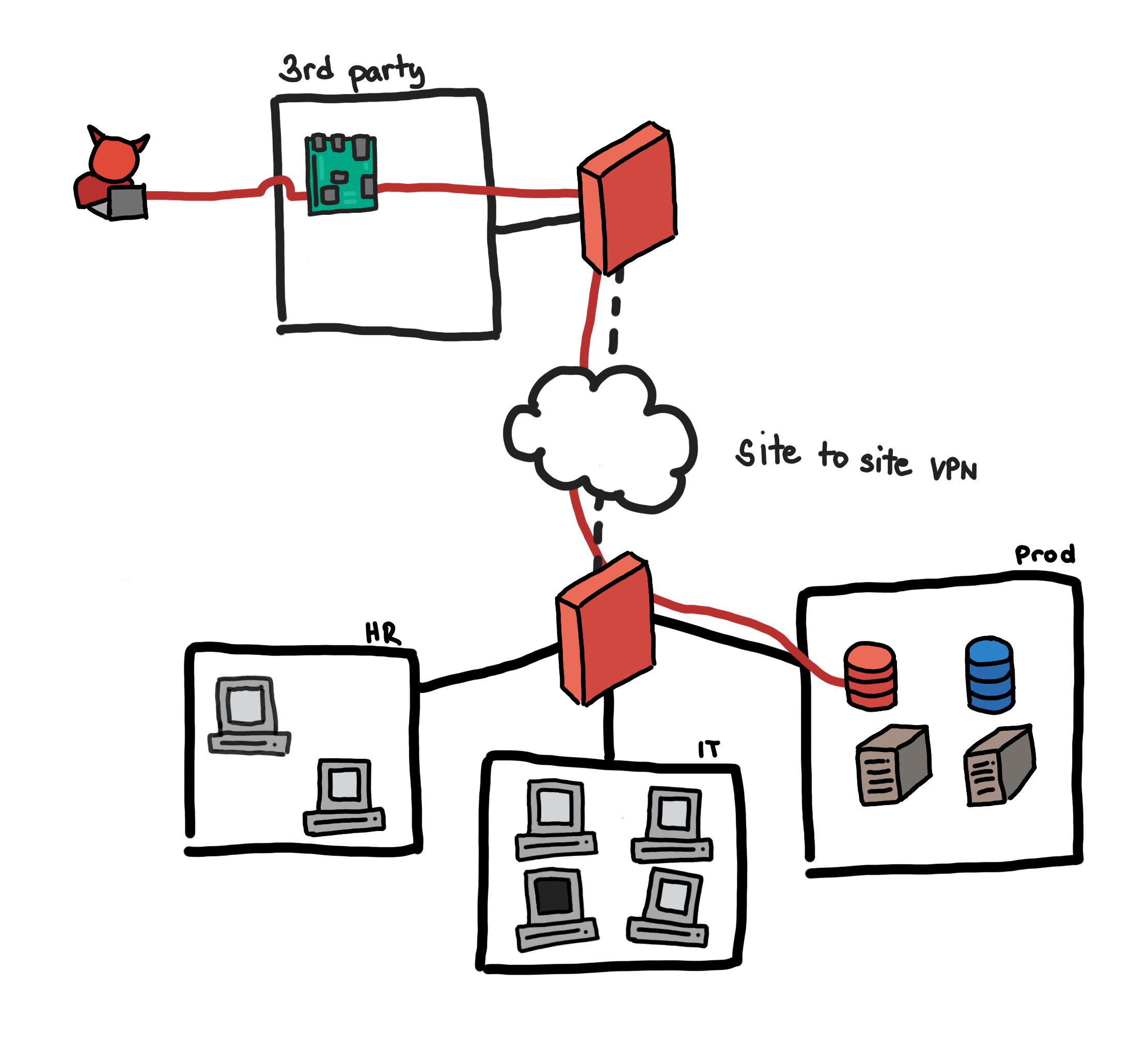
JPL established a network gateway to allow external users and its partners, including foreign space agencies, contractors, and educational institutions, remote access to a shared environment for specific missions and data. However, JPL did not properly segregate individual partner environments to limit users only to those systems and applications for which they had approved access… The cyberattacker from the April 2018 incident exploited the JPL network’s lack of segmentation to move between various systems connected to the gateway, including multiple JPL mission operations and the DSN.
JPL建立了一个网络网关,以允许外部用户及其合作伙伴 (包括外国太空机构,承包商和教育机构)远程访问特定任务和数据的共享环境。 但是, JPL并未正确隔离各个合作伙伴环境,以仅将用户限制在他们已批准访问的系统和应用程序中。... 2018年4月事件的网络攻击者利用JPL网络的缺乏分段性,无法在连接到网关的各种系统之间移动 ,包括多个JPL任务操作和DSN。
Lateral movement can result to access across organizations. Enforce a strict trust boundary for external parties, and make sure to restrict their access to your network to only the essential connections. External parties may not have security posture as your organization and might be the weak link. Make sure to fine-tune your IDS or IPS to treat traffic from these subnets as external.
横向移动可能导致跨组织访问。 对外部各方强制执行严格的信任边界,并确保将他们对网络的访问限制为仅基本连接。 外部方可能没有您组织的安全状态,并且可能是薄弱环节。 确保微调您的IDS或IPS,以将来自这些子网的流量视为外部流量。
2017年Equifax数据泄露 [7] (2017 Equifax Data Breach [7])
The 2017 Equifax breach is a data breach resulted in leakage of the data of approximately 143 million U.S. consumers.
2017年的Equifax泄露是一项数据泄露,导致约1.43亿美国消费者的数据泄露。
The point of entry was the ACIS application which was not patched for the now-famous critical Apache Struts vulnerability. Using this vulnerability, the attackers were able to get a web shell on the server and run arbitrary commands.
切入点是ACIS应用程序,该应用程序未针对现在著名的关键Apache Struts漏洞进行修补。 使用此漏洞,攻击者能够在服务器上获取Web Shell并运行任意命令。
Given that the ACIS server was compromised, it would have been ideal that the impact of the attack is isolated to the ACIS system alone. Attempts to access resources outside would be blocked by either the network or host firewall.
鉴于ACIS服务器已受到攻击,理想的是将攻击的影响仅隔离到ACIS系统。 尝试访问外部资源将被网络或主机防火墙阻止。

Unfortunately, according to the report, the Equifax network was flat! This is the worst-case scenario because a compromise of any host can lead to the compromise of any host in the network.
不幸的是,根据该报告,Equifax网络是平坦的! 这是最坏的情况,因为任何主机的危害都可能导致网络中任何主机的危害。

Security Concern 1. There is no segmentation between the Sun application servers and the rest of the [Equifax] network. An attacker that gains control of the application server from the internet can pivot to any other device, database, or server within the [Equifax] network, globally… If an attacker breaches the network perimeter of an organization with a flat, unsegmented network, they can move laterally throughout the network and gain access to critical systems or valuable data.
安全问题1. Sun应用程序服务器与[Equifax]网络的其余部分之间没有分段 。 从Internet获得对应用程序服务器的控制的攻击者可以在全球范围内转向[Equifax]网络内的任何其他设备,数据库或服务器 ……如果攻击者破坏了具有扁平无分段网络的组织的网络范围,则它们可以在整个网络中横向移动并获得对关键系统或有价值数据的访问权限。
With remote access to the ACIS web server, the attackers were able to:
通过远程访问ACIS Web服务器,攻击者能够:
- Mount a file share containing unencrypted application credentials
挂载包含未加密的应用程序凭据的文件共享 - Run 9,000 queries on 51 different databases.
在51个不同的数据库上运行9,000个查询。 - Exfiltrate all the data
提取所有数据
To put it into context, the ACIS only used 3 databases but had network access to 48 unrelated databases. Had the ACIS system been isolated to only the relevant databases, then the breach wouldn’t have been as bad.
综上所述,ACIS仅使用了3个数据库,但可以访问48个不相关的数据库。 如果仅将ACIS系统隔离到相关数据库中,那么入侵就不会那么糟糕。
网络细分 (Network Segmentation)
A common theme that we see across all the different breaches is that network segmentation plays a big role in preventing lateral movement.
我们在所有不同的漏洞中看到的一个共同主题是,网络分段在防止横向移动方面起着重要作用。
If the network is properly segmented, the blast radius is limited to the specific system, and the attacker will have a harder time navigating across the network.
如果对网络进行了适当的分段,则爆炸半径将限制在特定的系统上,攻击者将很难在网络上导航。
However, for traditional networks, very granular segmentation might be too cost-prohibitive and you might be restricted by the physical topology of the network. But for cloud deployments, because everything is virtualized and can be automated, we can apply micro-segmentation to our systems [4]. You can isolate machines on a per-workload basis as opposed to a per-network basis.
但是,对于传统网络,非常精细的分段可能会过于昂贵,并且可能会受到网络物理拓扑的限制。 但是对于云部署,由于所有内容都是虚拟化的并且可以自动化,所以我们可以将微细分应用于我们的系统[4]。 您可以基于每个工作负载而不是每个网络来隔离计算机。
可见性和传感器优势 (Visibility and Sensor Vantage)

One critical activity you’d want to do before even setting up alerts and rules is to check what logs are you actually collecting. It has to be clear to you and your team what the limits of your visibility are.
在设置警报和规则之前,您要做的一项重要活动是检查您实际收集的日志。 您和您的团队必须清楚可见性的限制。
- What data sources do I collect logs from?
我从哪些数据源收集日志? - What kinds of logs do I have enabled in each data source?
我在每个数据源中启用了哪些日志? - What does my data source/sensor actually “see”?
我的数据源/传感器实际上“看到了”什么? - Have I tested it?
我测试过了吗?
我从哪些数据源收集日志? (What data sources do I collect logs from?)
Check what data sources you collect from.
检查您从中收集什么数据源。
For traditional on-premises, you can just list down all the usual stuff from your appliances and vendors, DNS, DHCP, Active Directory, Firewall, Proxy, SQL, etc. You can also check Security Onion. It’s free and you are able to leverage the knowledge and the tools of the community that have grown around it.
对于传统的内部部署,您可以仅列出设备和供应商提供的所有常见内容,DNS,DHCP,Active Directory,防火墙,代理,SQL等。您还可以检查安全洋葱。 它是免费的,您可以利用围绕它发展起来的社区的知识和工具。
For cloud deployment, make sure you are collecting the audit and access logs of the critical services that you use in your cloud provider. Also, collect network flow logs.
对于云部署,请确保您正在收集在云提供商中使用的关键服务的审核和访问日志。 另外,收集网络流日志。
我在每个数据源中启用了哪些日志? (What kinds of logs do I have enabled in each data source?)
Some data sources do not save all the necessary logs by default and you would need to turn it on.
某些数据源默认情况下不会保存所有必要的日志,因此您需要将其打开。
You might find that some firewall rules are not logged because of a misconfiguration. “I turned off all the logging of X because it was filling up the disk.”
您可能会发现由于配置错误而未记录某些防火墙规则。 “我关闭了X的所有日志记录,因为它正在填满磁盘。”
In Google Cloud Platform, for example, firewall logs, VPC flow logs, and GCS Data Access logs are not turned on by default.
例如,在Google Cloud Platform中,默认情况下不会打开防火墙日志,VPC流日志和GCS数据访问日志。
我的数据源/传感器实际上“看到了”什么? (What does my data source/sensor actually “see”?)
A sensor’s vantage describes the packets that a sensor will be able to observe. Vantage is determined by an interaction between the sensor’s placement and the routing infrastructure of a network [8].
传感器的优势描述了传感器将能够观察到的数据包。 优势取决于传感器的位置和网络的路由基础设施之间的相互作用[8]。
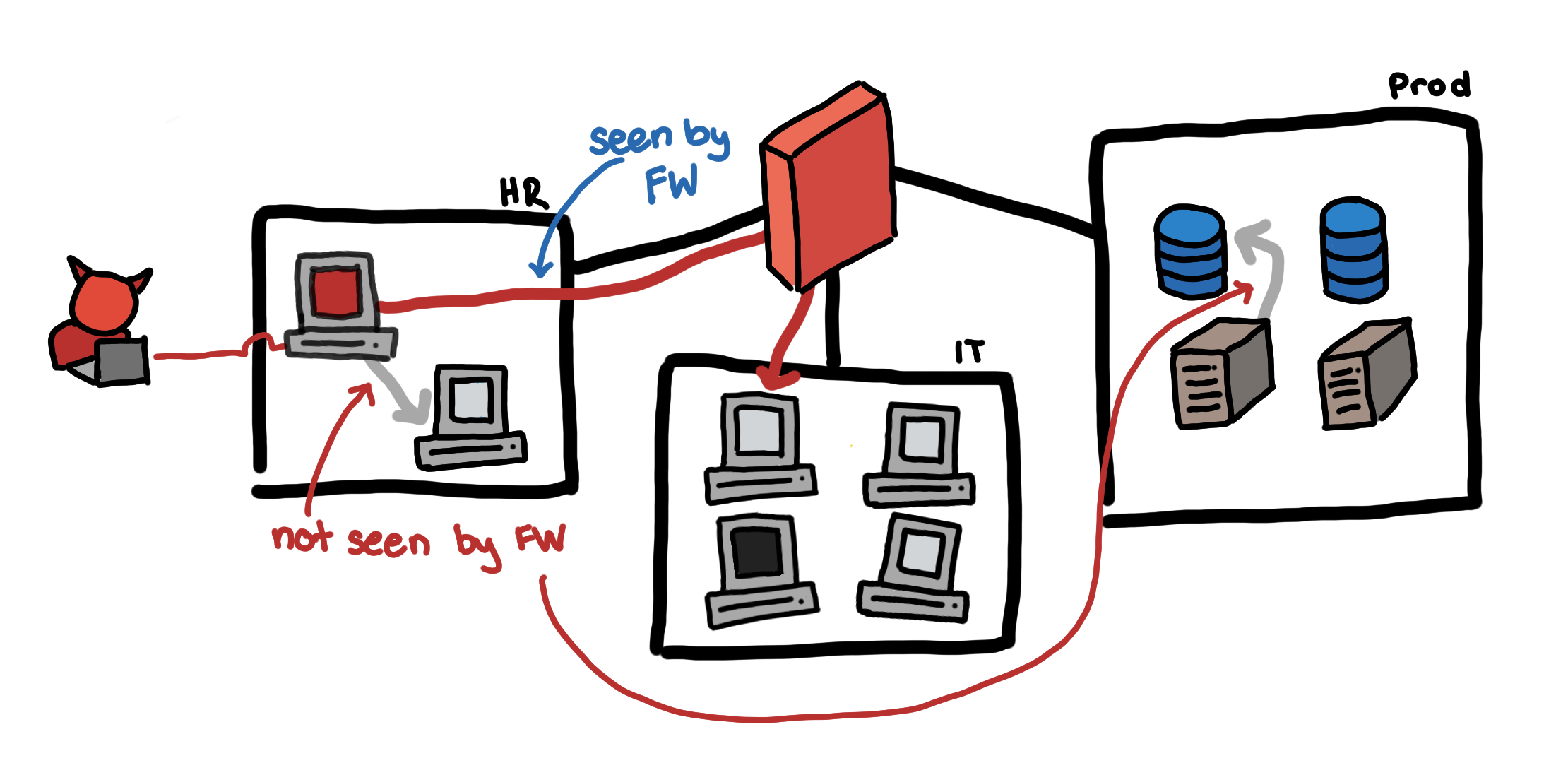
For our toy use case, it may be the case that connections within the same subnet won’t need to pass through the firewall. If we analyze our firewall logs, the only connections that we see are from hosts in two different subnets.
对于我们的玩具用例,可能是同一子网内的连接不需要通过防火墙。 如果我们分析防火墙日志,我们看到的唯一连接来自两个不同子网中的主机。
Some enterprises may have separate appliances for the perimeter firewall and the internal firewall. Let’s say you are only collecting logs from the perimeter firewall, then it is likely that any internal to internal connections would not appear on your SIEM.
一些企业可能具有用于外围防火墙和内部防火墙的单独设备。 假设您只从外围防火墙收集日志,那么内部到内部的任何连接都可能不会出现在您的SIEM上。
Be careful with this. You have to know where your blind spots are. Using logs that do not give you sufficient visibility on your network can give you a false sense of security. You might think that no one is scanning the network, when in fact, there is and you just don’t see it!
请注意这一点。 您必须知道您的盲点在哪里。 使用无法在网络上提供足够可视性的日志可能会给您带来错误的安全感。 您可能会认为没有人在扫描网络,而实际上却在扫描,却根本看不到!
For cloud infrastructures, it depends on what your cloud service providers give you. Since everything is virtualized, you are no longer restricted by the physical topology of your network, and there is a potential having uniform visibility across the IaaS. But if you are using PaaS, and especially for SaaS, you have less control over what kind of logs you get.
对于云基础架构,这取决于您的云服务提供商为您提供的服务。 由于所有内容都是虚拟化的,因此您不再受网络物理拓扑的限制,并且有可能在IaaS上具有统一的可见性。 但是,如果您使用的是PaaS,尤其是对于SaaS,则对获取哪种日志的控制较少。
我测试过了吗? (Have I tested it?)
The only way to be sure that your data sources are working and you are getting the logs is to test it!
确保您的数据源正常运行并获取日志的唯一方法是对其进行测试!
Formulate several simple scenarios from your threat modeling and simulate it. Try to actually run a network scan on different subnets or try to use certain honey credentials. See if these will generate the logs and alerts you want. See if your new machine learning model will detect this.
根据您的威胁建模制定几种简单的方案并进行仿真。 尝试在不同的子网中实际运行网络扫描,或者尝试使用某些Honey凭据。 查看这些是否会生成所需的日志和警报。 看看您的新机器学习模型是否可以检测到这一点。
When you are running simulations you are able to test your detection systems from end to end, from log collection, data transformations, ingestion of SIEM, rules and alerts, and perhaps even investigation and incident response.
运行模拟时,您可以从端到端,从日志收集,数据转换,SIEM提取,规则和警报,甚至调查和事件响应来端对端测试系统。
It will also give you the chance to catch instances where your data sources are failing or were misconfigured. Maybe the service died, its storage got filled up or its license expired. Maybe a change in the firewall configuration inadvertently disabled logging for a set of firewall rules.
它还将使您有机会捕获数据源出现故障或配置错误的实例。 也许服务死了,存储空间已满或许可证已过期。 也许更改防火墙配置会无意中禁用了一组防火墙规则的日志记录。
Do not think that everything is okay just because you are not receiving alerts from your NIDS or DLP; What if the NIDS host was accidentally turned off 3 months ago?
不要仅仅因为您没有收到来自NIDS或DLP的警报就认为一切都很好。 如果NIDS主机在3个月前意外关闭,该怎么办?
Equifax did not see the data exfiltration because the device used to monitor ACIS network traffic had been inactive for 19 months due to an expired security certificate. [7]
Equifax看不到数据泄漏,因为用于监视ACIS网络流量的设备由于安全证书过期而已停用了19个月。 [7]
Test, test, test!
测试,测试,测试!
黑暗空间和蜜罐 (Dark Space and Honeypots)

Here are some things that might be useful for those who have more mature networks and security posture.
Here are some things that might be useful for those who have more mature networks and security posture.
Dark space (Dark space)
An unused address or port number is called dark space, and legitimate users rarely try to access dark space. Most users do not enter IP addresses manually and often rely on DNS or applications to connect for them. Attackers, on the other, will likely end up accessing them when trying to move laterally [8].
An unused address or port number is called dark space, and legitimate users rarely try to access dark space. Most users do not enter IP addresses manually and often rely on DNS or applications to connect for them. Attackers, on the other, will likely end up accessing them when trying to move laterally [8].
We can alert on internal hosts that try to access these dark spaces. This can be noisy, but can be easy to investigate in some cases. One common reason for the alert is misaddressing or misconfiguration.
We can alert on internal hosts that try to access these dark spaces. This can be noisy, but can be easy to investigate in some cases. One common reason for the alert is misaddressing or misconfiguration.
According to [8], here are some things you can do to make it more likely that the attacker would access dark spaces, making it a bit easier to detect:
According to [8], here are some things you can do to make it more likely that the attacker would access dark spaces, making it a bit easier to detect:
Rearrange addresses: Most scanning is linear/sequential, and rearranging addresses so that they’re scattered evenly across the network, or leaving large empty gaps in the network is a simple method that creates dark space.
Rearrange addresses: Most scanning is linear/sequential, and rearranging addresses so that they're scattered evenly across the network, or leaving large empty gaps in the network is a simple method that creates dark space.
Move targets: If the port assigned to a service is non-standard, the attacker will find it only after enumerating a lot more ports, making them more visible. Of course, there is a trade-off with since changing the ports around too much might confuse everyone.
Move targets: If the port assigned to a service is non-standard, the attacker will find it only after enumerating a lot more ports, making them more visible. Of course, there is a trade-off with since changing the ports around too much might confuse everyone.
Honey Things (Honey Things)
Honey things are similar to dark spaces in which we don’t expect these things to come up in our logs.
Honey things are similar to dark spaces in which we don't expect these things to come up in our logs.
Unlike dark spaces, these things do exist in our network, but they do not have any legitimate use. Regular employees do not know about these and should not ever need to use or access these. An attacker, on the other hand, might encounter these while they are moving about the network, and if these honey things look valuable or useful, they might try to do something with them.
Unlike dark spaces, these things do exist in our network, but they do not have any legitimate use. Regular employees do not know about these and should not ever need to use or access these. An attacker, on the other hand, might encounter these while they are moving about the network, and if these honey things look valuable or useful, they might try to do something with them.
Examples of these are:
Examples of these are:
- Honey credentials:
Honey credentials: - Honey tokens
Honey tokens - Honey file shares
Honey file shares - Honey servers
Honey servers
We want them to look valuable, and once any of these come up in our logs, we investigate. Tim Medin discusses this in more detail in his recent webcast “Dirty Defense, Done Dirt Cheap: Make Your Life Easier By Making Mine Harder” [9].
We want them to look valuable, and once any of these come up in our logs, we investigate. Tim Medin discusses this in more detail in his recent webcast “ Dirty Defense, Done Dirt Cheap: Make Your Life Easier By Making Mine Harder ” [9].
其他 (Others)
This is related but I will just mention this very briefly (because this blog post is already long enough, sorry).
This is related but I will just mention this very briefly (because this blog post is already long enough, sorry).
Although NIDS and NIPS, are sometimes deployed at the perimeter. If properly positioned and configured, they can help detect lateral movement. It would be able to detect client-side exploits over the network, possible file transfers, and usage of uncommon unauthorized network protocols. You can also use NIDS to detect honey tokens when they are transferred in plaintext over the wire.
Although NIDS and NIPS, are sometimes deployed at the perimeter. If properly positioned and configured, they can help detect lateral movement. It would be able to detect client-side exploits over the network, possible file transfers, and usage of uncommon unauthorized network protocols. You can also use NIDS to detect honey tokens when they are transferred in plaintext over the wire.
Check that it is configured to ignore internal to internal connections.
Check that it is configured to ignore internal to internal connections.
Up Next: Command and Control, Beaconing (Up Next: Command and Control, Beaconing)

We’ve barely scratched the surface. You can dive deeper with logs such as Active Directory to be more precise in your search for lateral movement, but we have to move on for now.
We've barely scratched the surface. You can dive deeper with logs such as Active Directory to be more precise in your search for lateral movement, but we have to move on for now.
In the next blog post, we will go through some of the questions on finding evidence of command and control.
In the next blog post, we will go through some of the questions on finding evidence of command and control.
The attacker needs to be able to establish control over their foothold to navigate through your network. As they say, to kill a snake cut off its head.
The attacker needs to be able to establish control over their foothold to navigate through your network. As they say, to kill a snake cut off its head.
Photos by Artem Saranin from Pexels, Denis Yudin from Pexels, Ignacio Palés from Pexels, Tom Swinnen from Pexels, Igor Goryachev on Unsplash, Eleonora Patricola on Unsplash, Ammie Ngo on Unsplash
Photos by Artem Saranin from Pexels , Denis Yudin from Pexels , Ignacio Palés from Pexels , Tom Swinnen from Pexels , Igor Goryachev on Unsplash , Eleonora Patricola on Unsplash , Ammie Ngo on Unsplash
翻译自: https://towardsdatascience.com/data-analysis-for-cyber-security-101-detecting-lateral-movement-2026216de439
网络攻防 横向移动
相关文章:
- HTTP/2 简介
- Linux IO体系、零拷贝和虚拟内存关系的重新思考
- Pipes-and-Filters模式
- Azure设计模式之管道过滤器模式
- 微服务模式笔记:服务分解策略
- HCIP-Datacom 分解实验1:访问控制列表
- NAT 穿透是如何工作的
- ESB工作机制
- 期望货币价值
- 货币流通产生价值
- 信息系统项目管理师计算题(期望值)
- 【高项备考】多种类型计算题学习
- 带宽 与 货币
- 密码货币的来历
- 区块链数字货币应用场景不同决定了价值空间
- 数字货币的价值基础
- 降息为什么会导致货币贬值呢,为啥货币贬值利于出口
- 了解区块链(一)——加密货币以及区块链的价值
- 货币的时间价值
- 生活中的货币时间价值 网课答案
- 货币信息高于货币价值而存在
- 加密货币为什么有价值?
- 货币时间价值(学习笔记)
- 马哲概述 如何理解商品的使用价值与价值以及货币,纸币
- 一分钟让你明白货币贬值现象
- 模拟魔方还原
- WPS文字 JSA 学习笔记 - 转PDF后要带自定义目录
- 参考文献起止页码怎么写_【求助】有全文参考文献但没有起止页码如何办
- 前端样式--------页码中间两个省略号
- USACO:2.2.1 Preface Numbering 序言页码
网络攻防 横向移动_网络安全101的数据分析:检测横向移动相关推荐
- 收益 网络安全域建设_网络安全建设方案实施.doc
专业技术资料分享 WORD文档下载可编辑 专业技术资料分享 WORD文档下载可编辑 网络安全建设方案 2016年7月 TOC \o "1-3" \h \u HYPERLINK \l ...
- android安全攻防实践_网络攻防小组招新,等待优秀的你!
河南警察学院 网络攻防小组 网络安全系 01 实验室介绍 河南警察学院网络攻防小组于2016年4月成立,面向网络空间安全技术交流,研究方向包括Web安全.渗透测试.二进制漏洞挖掘与利用等,选拔培养对网 ...
- 戴红计算机网络安全,我校举办第二届信息安全与网络攻防竞赛
11月28日,我校第二届信息安全与网络攻防竞赛在我校计算机学院实验中心举办.来自全校的十组选手同台竞技,各显神通.最终,计算机学院"戴着小红帽的大灰狼"."黑曼巴&quo ...
- 北风网--网络安全系列课程之网络攻防全面实战(涉及加密、解密)
讲师简单介绍:讲师龙飞为北风网网络安全领域讲师,讲师曾经先后在国内各大网站,如黑鹰.甲壳虫之类的黑客网站从事网络安全教育!本系列课程由龙飞讲师主讲,共60课时,全面讲述网络安全方面各大知识,是一个不错 ...
- 局域网网络流量监控_【干货】Linux网络安全运维:网络流量监控与分析工具Ntop和Ntopng...
本文授权转载自微信公众号:计算机与网络安全,转载请联系授权.对于单台服务器网络故障的排查,iftop工具可以轻松实现,但是在监控一个庞大的服务器网络,并且要分析每台主机以及端口的网络状态时,iftop ...
- 网络攻防中监控某个IP的流量和数据分析
网络攻防中监控某个IP的流量和数据分析. Windows 可以使用 tcpview 工具监控某个IP的流量信息,Linux 可以使用iftop 工具. 新版本的 tcpview 带过滤功能,可以对 I ...
- 网络攻防演练.网络安全.学习
第一部分 概述 网络安全攻防演练是指通过模拟各种网络攻击手段,来测试自身安全防御能力和应对能力的一种演练活动.本文总结了网络安全攻防演练的重要性.准备工作以及演练过程中需要注意的事项. 一.网络安全攻 ...
- 久其软件怎么样_久其软件助力中国电信顺利完成网络攻防演练
随着科技及信息技术的高速发展,网络及信息系统的安全也显得愈发重要,久其软件在信息安全上始终秉承客户至上.安全第一的理念,为用户打造安全可靠的信息系统.日前,久其软件协同中国电信云网运营部参加了一场国家 ...
- 攻防世界 适合做桌面_网络安全工程师教你:如何使用Kali Linux进行渗透测试与攻防实战...
课前声明: 1.本分享仅做学习交流,请自觉遵守法律法规! 2.搜索:Kali与编程,学习更多网络攻防干货! 一.背景介绍 在我们日常使用Kali Linux时,我们通常在进行模拟攻防演练的时候,我们如 ...
最新文章
- Docker入门与七牛kirk工具
- 线性八叉树_基于三维点云数据的线性八叉树编码压缩算法(权毓舒, 何明一,).pdf...
- Cpp / 空指针对象调用函数的不同结果
- Qt Creator使用命令行选项
- Flex 与 JavaScript 交互
- java memorystream 包_存储在MemoryStream中的裁剪图像中心
- php 7 class 初始化 销毁_在 PHP 中使用和管理 Session
- 【…感激2008,部署我的2009…】
- Bootstrap3 排版-地址
- 对比学习还能这样用:字节推出真正的多到多翻译模型mRASP2
- VMware Workstation安装RedHat Linux 9
- 5G 之战让运营商备受冷落?! | 极客头条
- Maria DB windows 安装
- flask使用pymysql连接MySQL,生成xls文件并下载到本地
- 最有效率地戒掉晚睡强迫症(熬夜强迫症、假象失眠症等等)
- 【LeetCode】马三来刷题之Permutations
- Unity 3D模型展示之拖拽
- 中冠百年|家庭中短期理财攻略
- 高级计算机网络 外文文献,计算机网络新技术外文文献翻译
- Adlik Deer版本发布,模型推理加速就靠它啦
热门文章
- 梦幻诛仙linux纯端架设教程,梦幻诛仙 一键端搭建iOS安卓双端+完整后台源码+各种工具附带视频架设教程...
- 【历史上的今天】5 月 17 日:面向对象编程之父出生;国内全面接入互联网;惠普收购 Cray
- 开屏展示图的优化与理解
- 道路驾驶技能计算机评判项目,2017最新科目二和科目三考试评判标准变动情况...
- 关于固定总价合同的建设工程项目审计的几点思考
- 【Unity3D日常开发】Unity中的资源加载与文件路径
- 0xc0000225无法进系统_Win10无法开机0xc0000225错误代码解决方法
- HTML+JavaScript拖拽进度条和点击进度条(显示进度条百分比)
- 百度网盘下载速度慢的解决方式
- python做交易软件_我用Python做了个量化交易工具!