基于阿里云MaxCompute实现游戏数据运营
摘要: 一、总览 一个游戏/系统的业务数据分析,总体可以分为图示的几个关键步骤: 1、数据采集:通过SDK埋点或者服务端的方式获取业务数据,并通过分布式日志收集系统,将各个服务器中的数据收集起来并送到指定的地方去,比如HDFS等;(注:本文Demo中,使用flume,也可选用logstash、Flue.
点此查看原文:http://click.aliyun.com/m/42633/
一、总览

二、环境准备
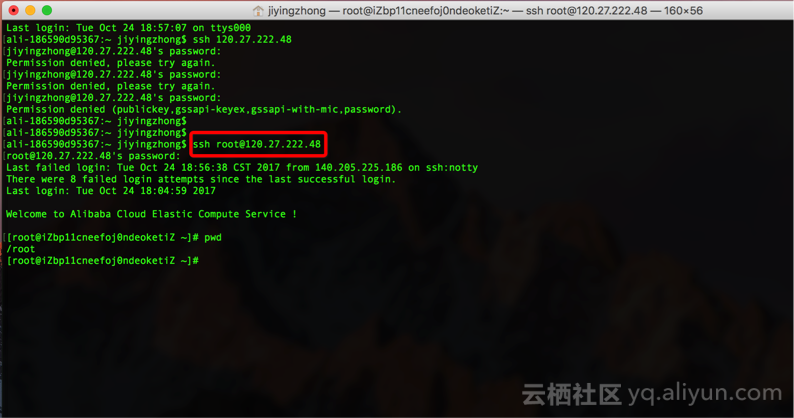
Step1:安装JDK


Step2:安装flume

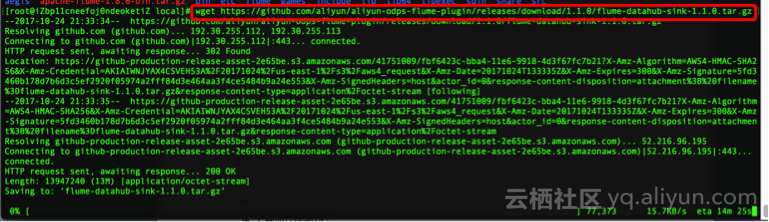
Step3:安装Datahub Sink插件
三、数据开发
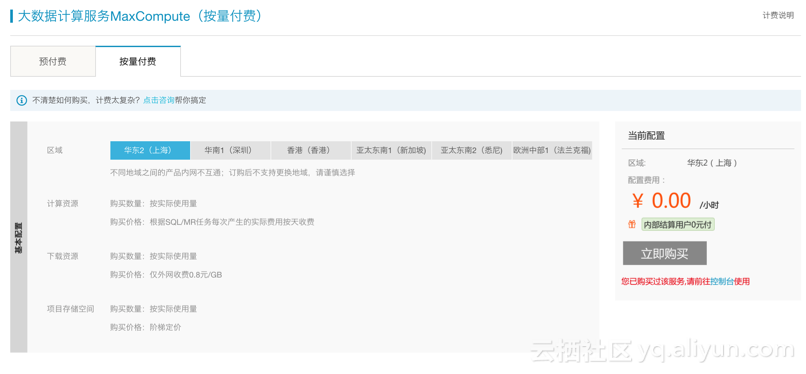
Step1:开通MaxCompute服务
Step2:创建项目及业务模型
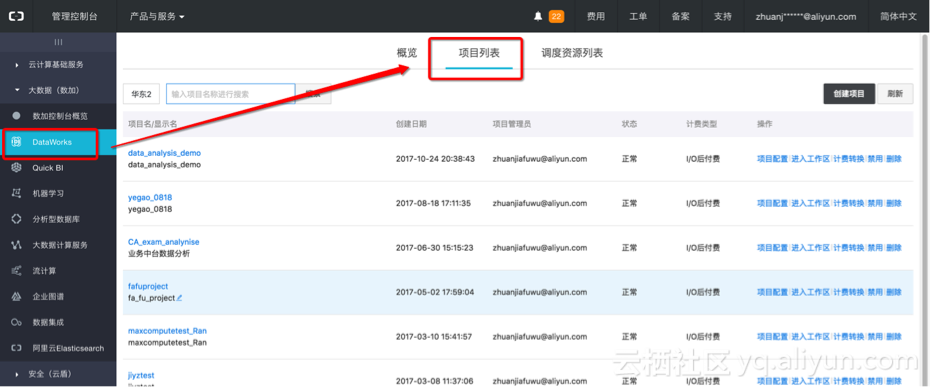
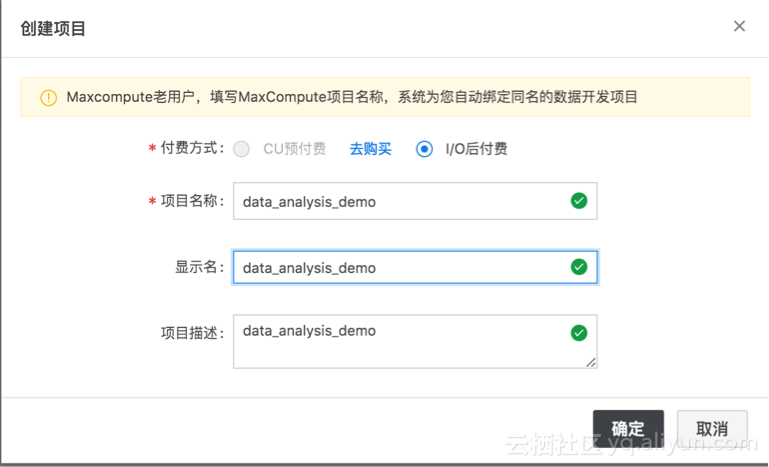

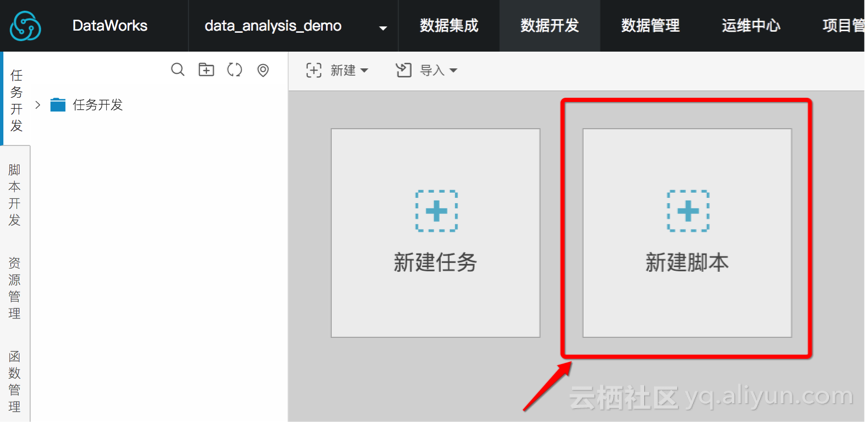
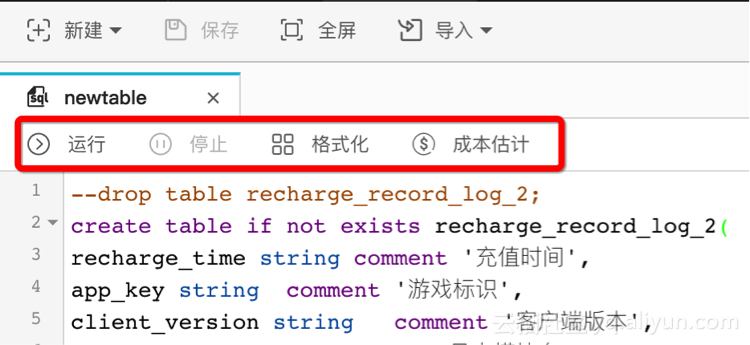
四、数据同步
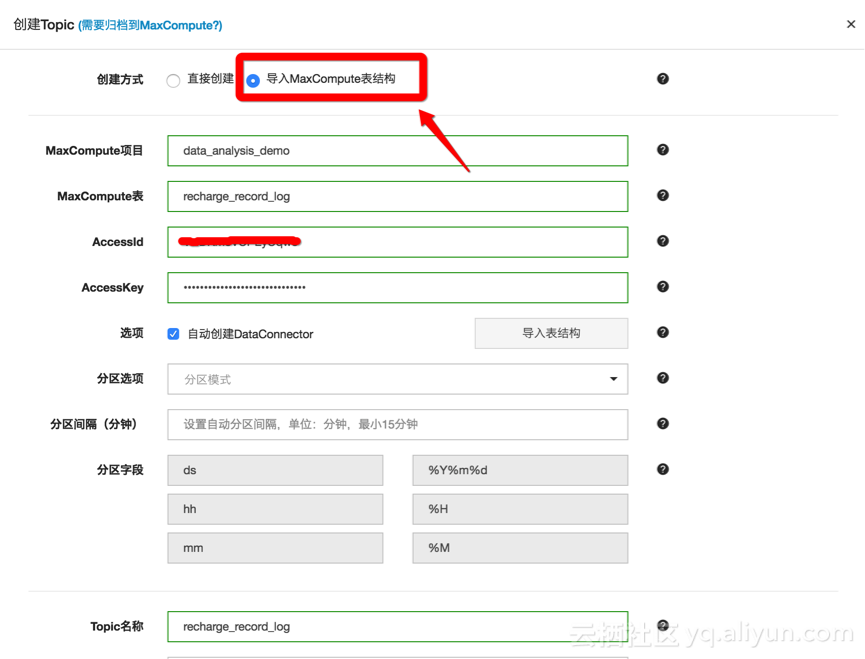
step1:数据通道设置
step2:数据采集agent配置及启动
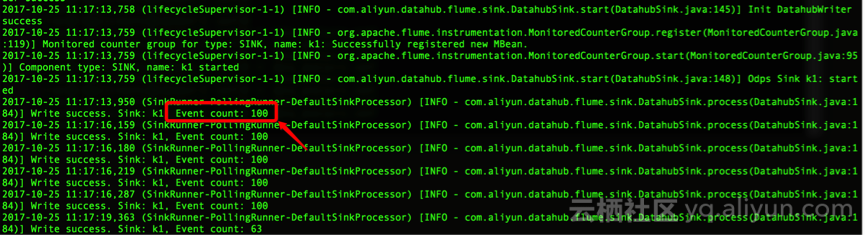
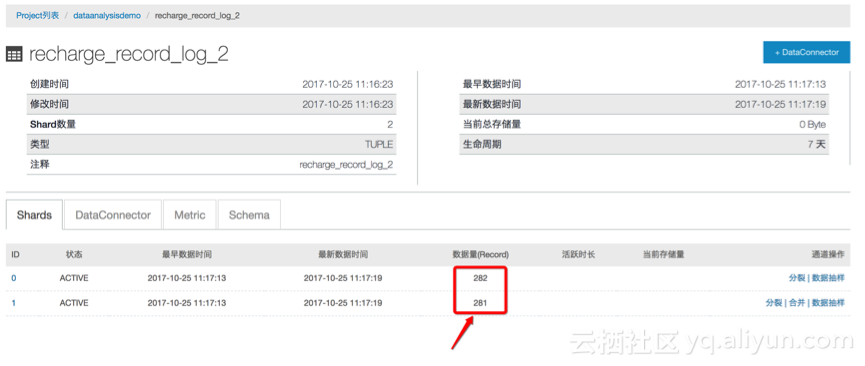
step3:数据检查
可以通过两种方式来检查数据:
1、topic的数据抽样,查看数据格式是否正常;
2、因为已经配置了datahub到MaxCompute的数据链路,可以在MaxCompute中检查数据入库情况;
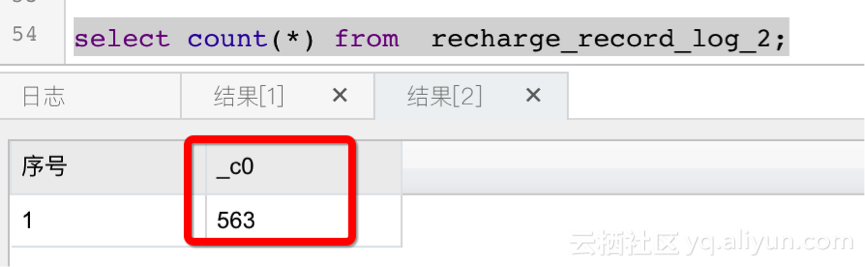
OK,数据同步的工作,到此就基本完成了。
五、数据分析&报表制作
接下来需要基于日志,做业务分析,那么这里我们可以选择quickBI工具,来快速完成多维分析报表、仪表盘等数据产品的配置;
通过 链接 ,打开quickBI的产品页面,并开通对应服务。
Step1:分析模型设置(数据集)
1、进入数据工作台https://das.base.shuju.aliyun.com/console.htm,点击左侧QuickBI;
2、在引导页,点击“添加数据源”;
3、设置数据源的属性
按demo场景,选择MaxCompute;
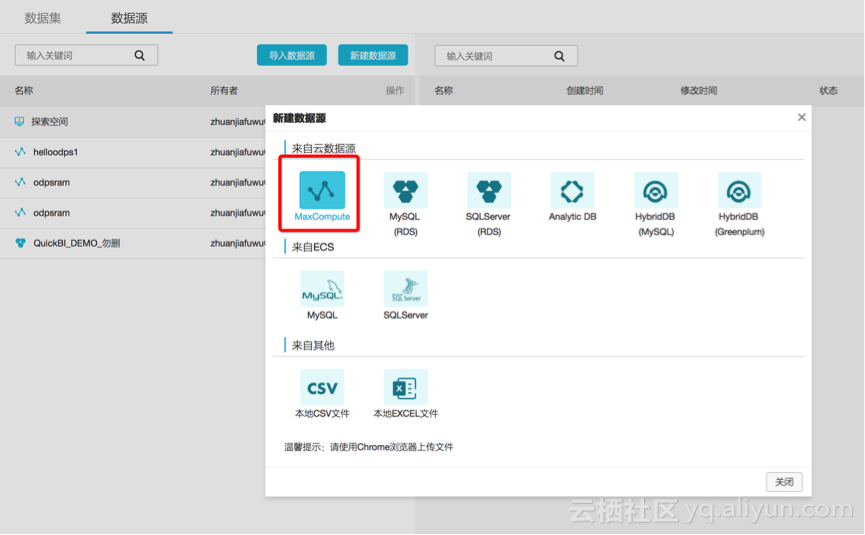
并设置对应的peoject信息:
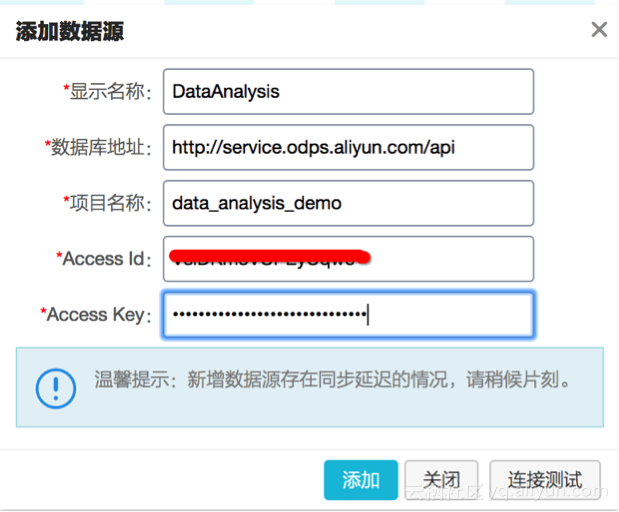
4、数据源连接成功后,可以看到project下的表,选择需要分析的表,创建数据集;
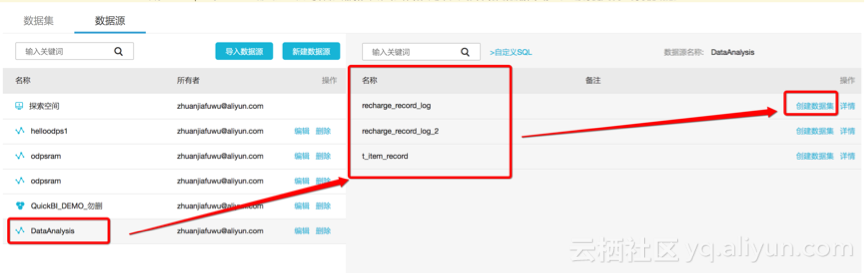
5、按照分析场景需求,可以对数据集的逻辑模型做设置;
demo的分析场景,需要 基于事实表(充值数据,recharge_record_log)和维表(商品信息表,t_item_record)关联,来完成业务分析,因此可以点击编辑数据集:

完成:
1)构建关联模型

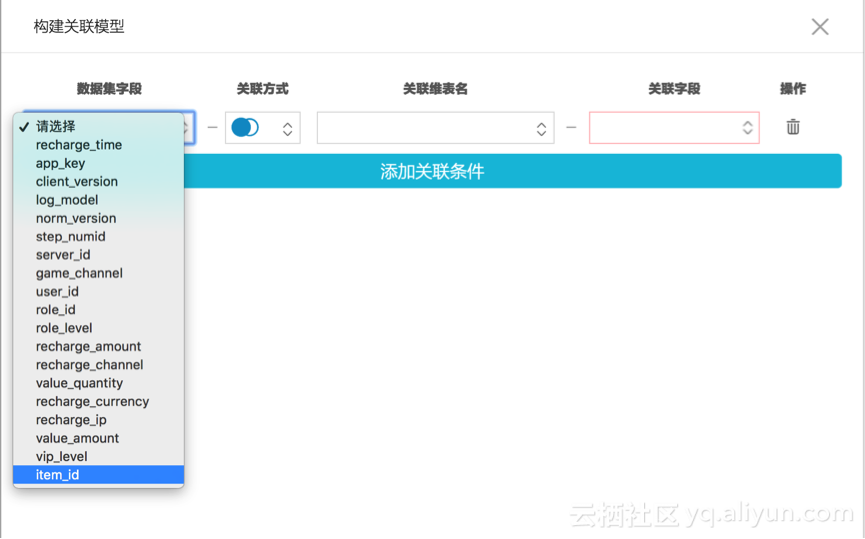
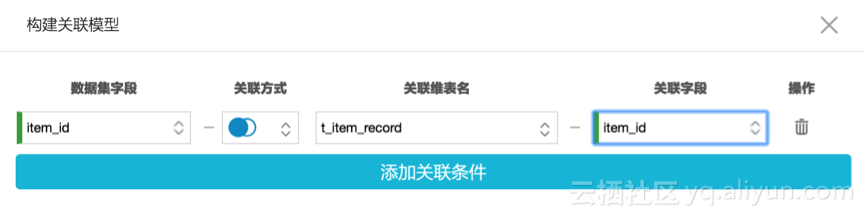
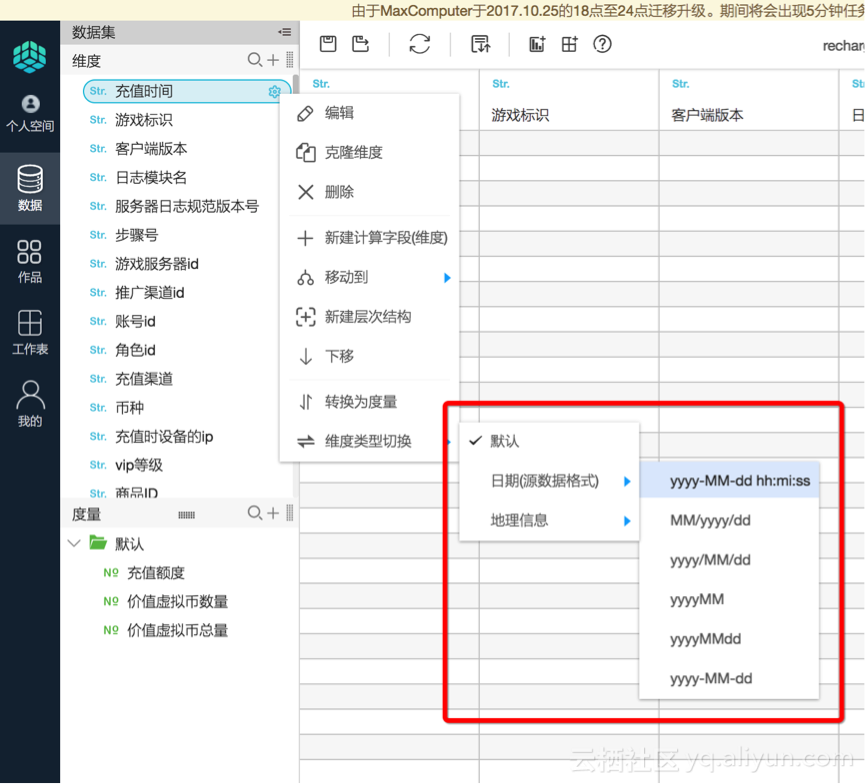
2)可以对时间维度做拆分,会自动生成多个level
Step2:多维分析报表配置
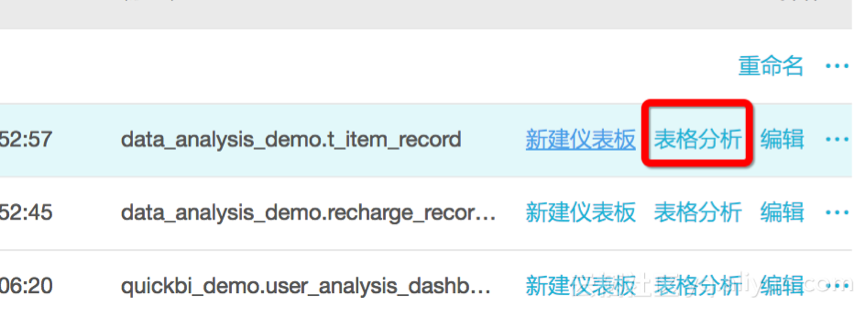
1、分析模型设置好之后,接下来就可以开始分析了,点击“表格分析”:
2、进入多维分析报表的IDE工作台:
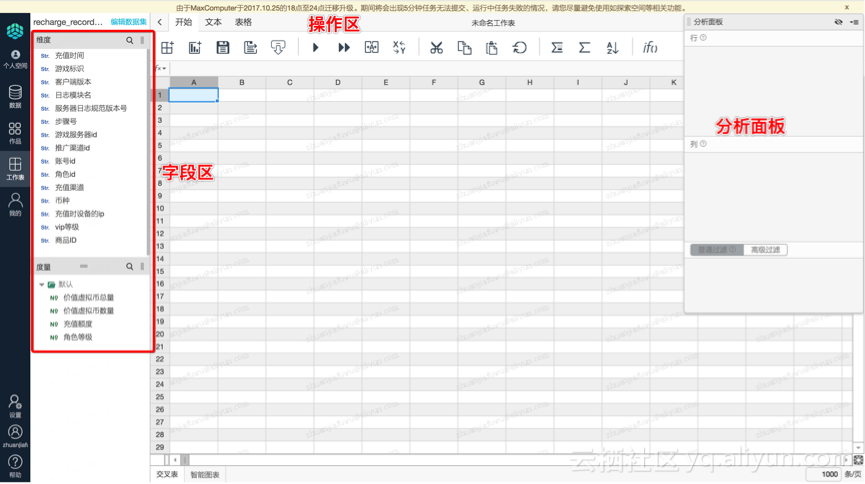
3、可以看到,左侧的字段属性区,会自动加载物理表的对应字段(默认加载comment描述):
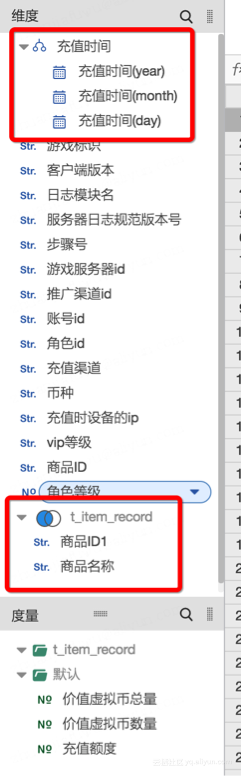
4、具体分析操作,比较简单,按需双击、拖拽需要分析的字段,点击查询即可看到报表,比如:
1)按商品(维度),看充值(计量)的整体情况
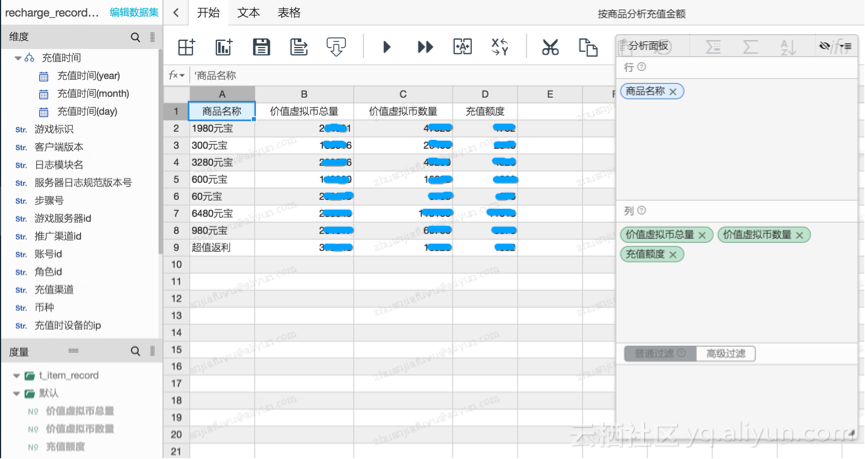
2)增加角色等级(维度),做交叉表
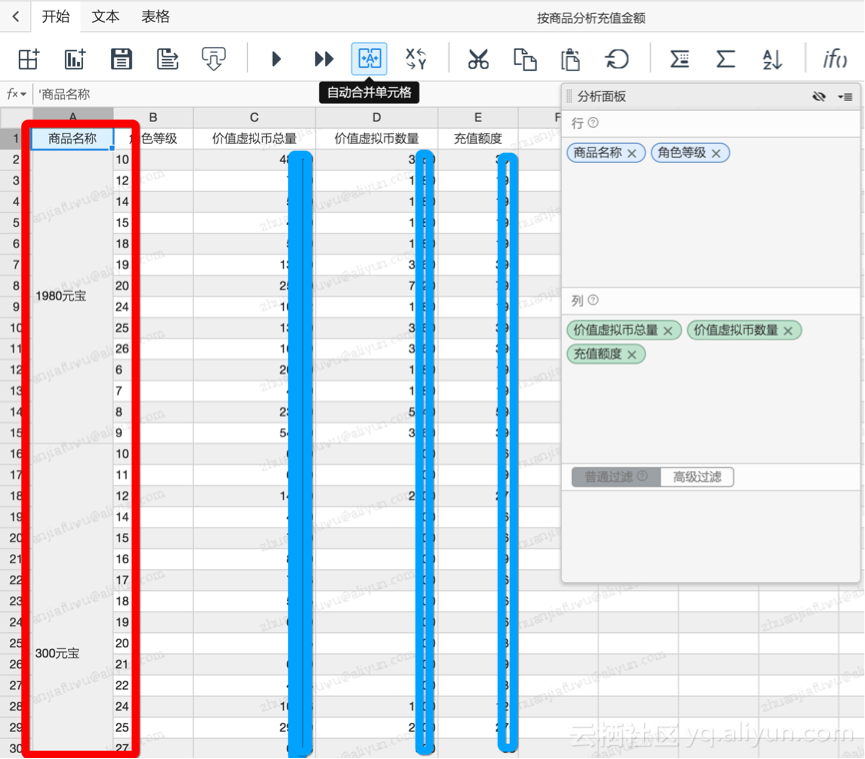
3)同时也支持各种查询条件的设置
按时间
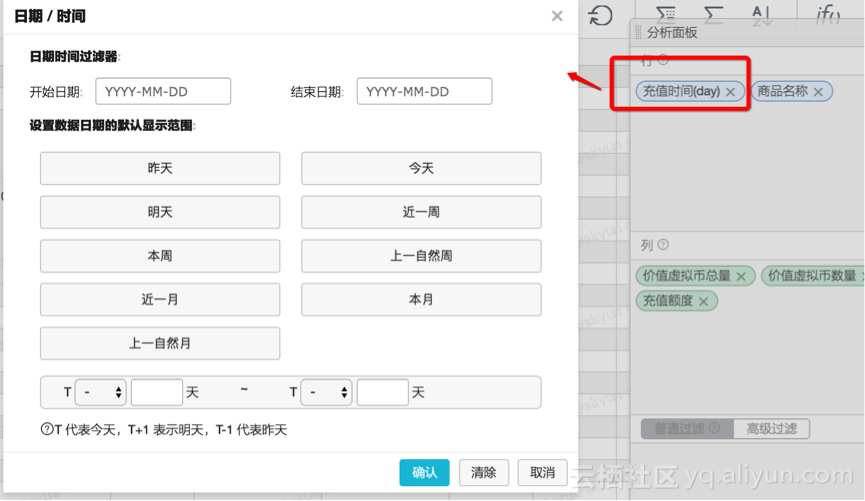
多层嵌套的高级查询
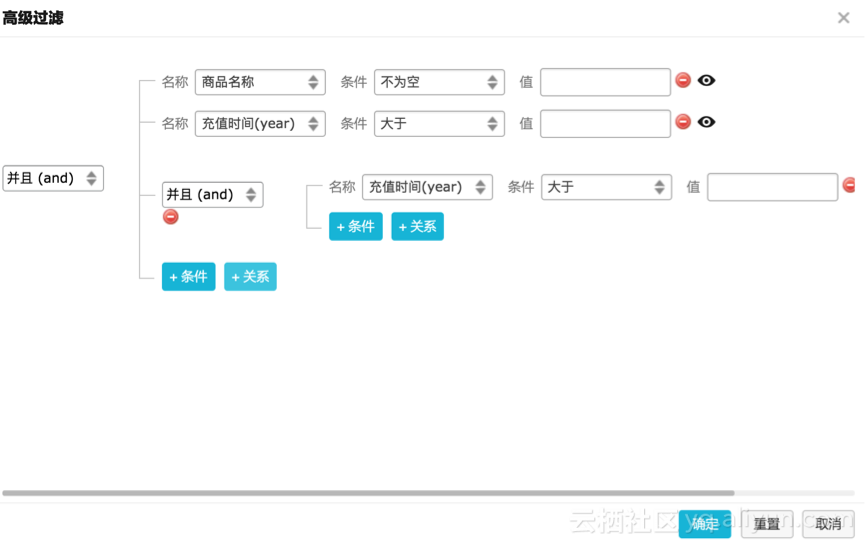
Step3:仪表盘、数据产品配置
灵活性较强的数据探查类场景,可以通过多维报表支撑,对于展现形式要求较高的,可以通过仪表盘来灵活实现;
1、数据集List页面,点击“新建仪表盘”:

2、进入仪表盘的IDE工作台,页面分为左、中、右三栏:
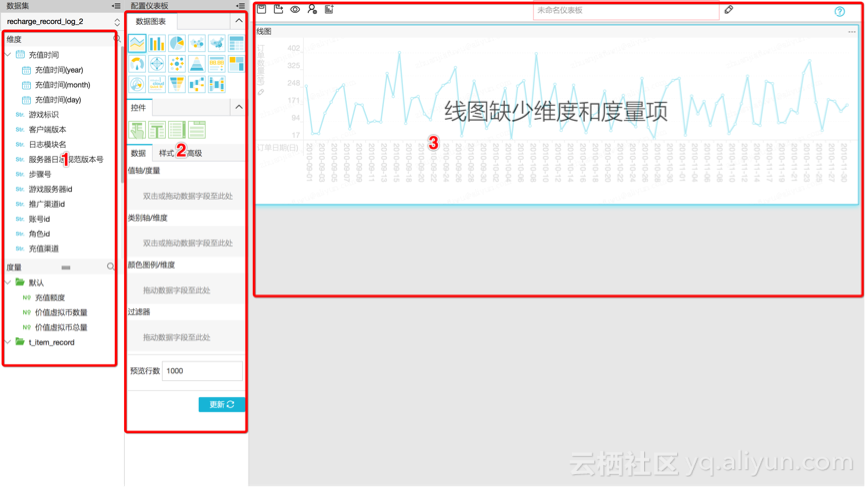
3、同样,可以通过拖拽的方式,快速完成仪表盘页面的配置:
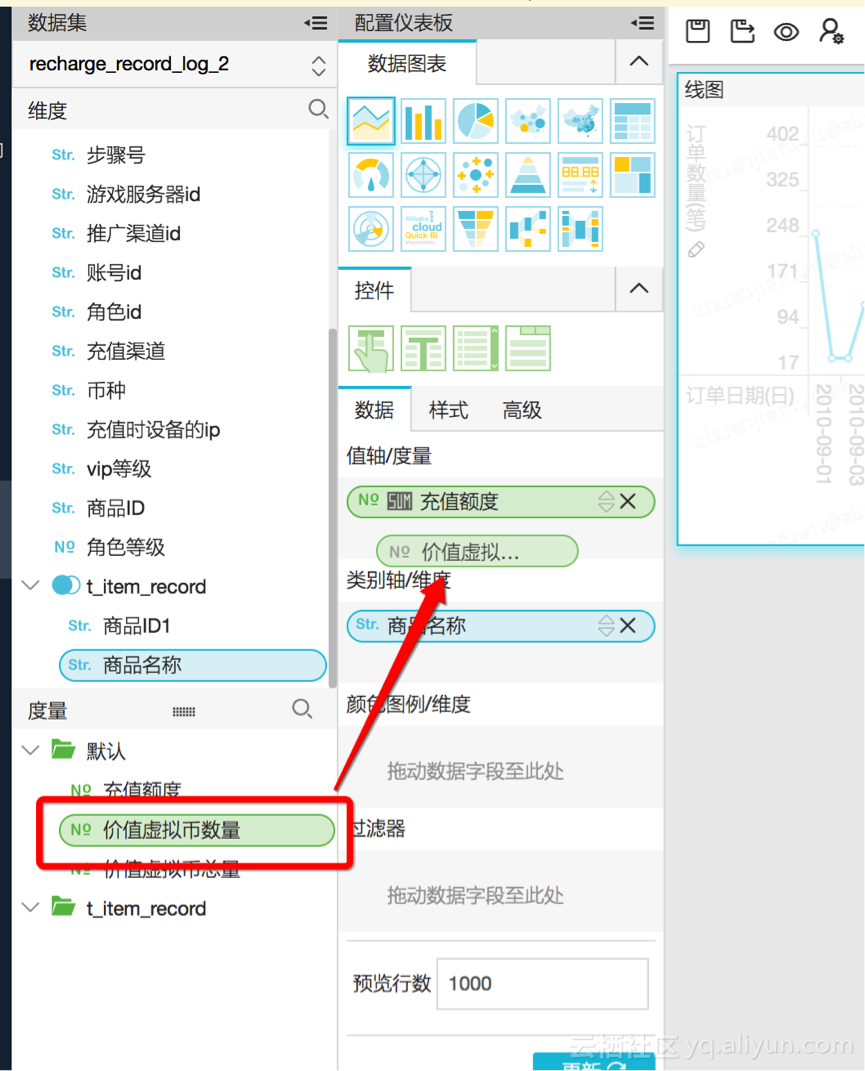
1)拖拽/双击 选择需要作图的字段:
2)点击更新,刷新图表,同时可以自由设置图表的样式
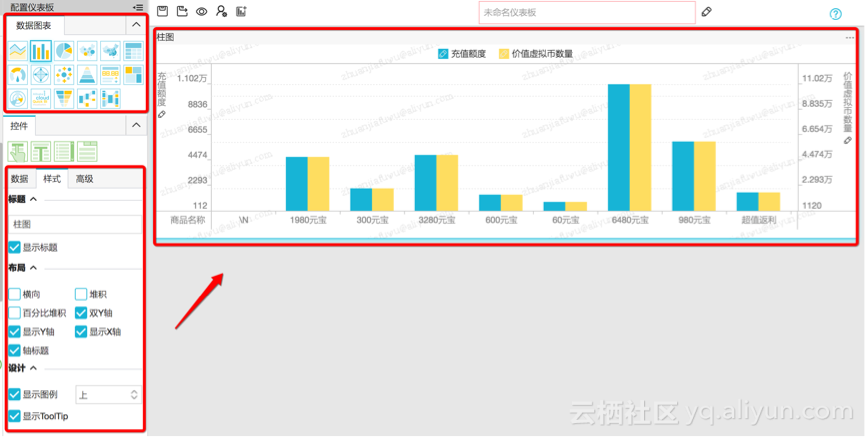
3)拖拽设置页面布局
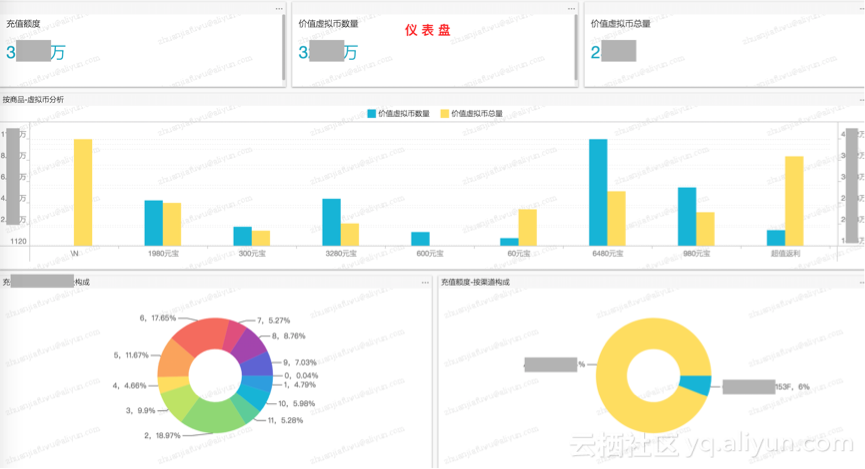
比如,可以做一个专门的充值分析页面,效果示例:
数据产品是类似于分析专题、报表门户,具体配置就不再赘述:
六、架构总结
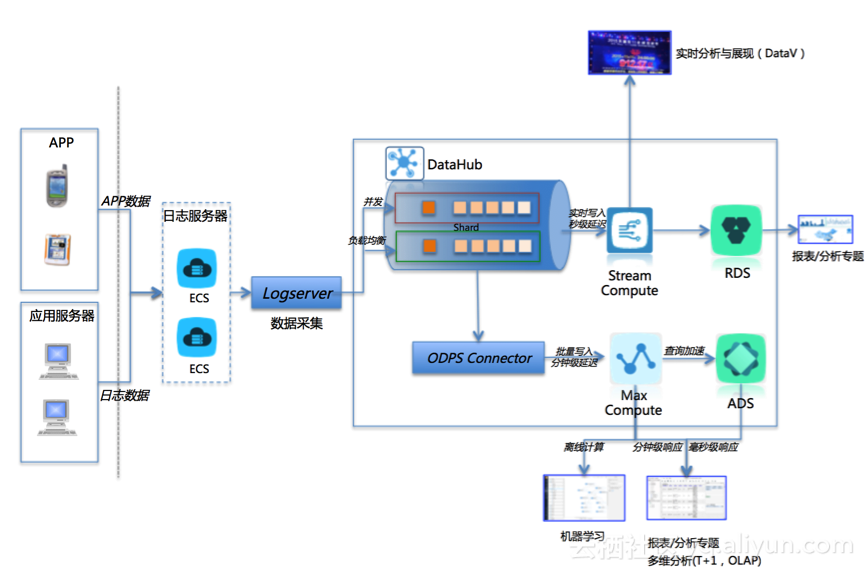
一、Demo涉及的产品 以及 数据流
如图所示:

二、如何实现生产场景下的动态数据采集及常见问题处理
和Demo不同的是,在生产场景下,我们的日志文件是动态的,因此需要实现如下逻辑:
1、 监控日志目录下的文件变化;
2、 根据配置的频率,采集日志;
1、flume1.7及以上版本
包含TaildirSource组件,可以实现监控目录,并且使用正则表达式匹配该目录中的文件名进行实时收集。
Flume作业配置:
1)在Flume安装目录的conf文件夹下,创建任务的conf文件;
vi {任务名称}.conf
2)输入任务的配置信息(注意,此处差异较大)
#示例如下(重点关注{}中的内容)
#a1是要启动的agent的名字
a1.sources = r1 #命名agent的sources为r1
a1.sinks = k1 #命名agent的sinks为k1
a1.channels = c1 #命名agent的channels为c1
# TaildirSource配置
a1.sources.r1.type = org.apache.flume.source.taildir.TaildirSource
a1.sources.r1.channels = memory_channel
a1.sources.r1.positionFile = /tmp/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = {/usr/logfile/s51/mylog/*}
a1.sources.r1.batchSize = 100
a1.sources.r1.backoffSleepIncrement = 1000
a1.sources.r1.maxBackoffSleep = 5000
a1.sources.r1.recursiveDirectorySearch = true
# Describe/configure the source
a1.sources.r1.type = exec #指定r1的类型为exec
a1.sources.r1.command =cat {日志文件的位置} #写入本地文件路径
# Describe the sink
a1.sinks.k1.type = com.aliyun.datahub.flume.sink.DatahubSink #指定k1的类型
a1.sinks.k1.datahub.accessID ={ accessID }
a1.sinks.k1.datahub.accessKey ={ accessKey }
a1.sinks.k1.datahub.endPoint = http://dh-cn-hangzhou.aliyuncs.com
a1.sinks.k1.datahub.project = {datahub_project_name}
a1.sinks.k1.datahub.topic ={datahub_ topic _name}
a1.sinks.k1.batchSize = 100 #一次写入文件条数
a1.sinks.k1.serializer = DELIMITED
a1.sinks.k1.serializer.delimiter = {字段间隔符}
a1.sinks.k1.serializer.fieldnames= {字段 “,” 隔开,注意需要与日志文件的顺序、datahub topic的顺序保持一致}
a1.sinks.k1.serializer.charset = {文字编码格式}
a1.sinks.k1.shard.number = {分片数,需要与datahub 的topic配置一致}
a1.sinks.k1.shard.maxTimeOut = 60
# Use a channel which buffers events in memory
a1.channels.c1.type = memory #指定channel的类型为memory
a1.channels.c1.capacity = 1000 #设置channel的最大存储数量为1000
a1.channels.c1.transactionCapacity = 1000 #每次最大可从source中拿到或送到sink中的event数量是1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、检查无误后,启动flume日志采集agent;
bin/flume-ng agent -n a1 -c conf -f conf/ {任务名称}
.conf -Dflume.root.logger=INFO,console
2、flume 1.6
原生不支持TaildirSource,需要自行下载集成:
下载地址:http://7xipth.com1.z0.glb.clouddn.com/flume-taildirfile-source.zip
将源码单独编译,打成jar包,上传到$FLUME_HOME/lib/目录下,之后配置方法可以参考上文;
3、常见问题:
1、日志文件解析错误
异常信息截图:
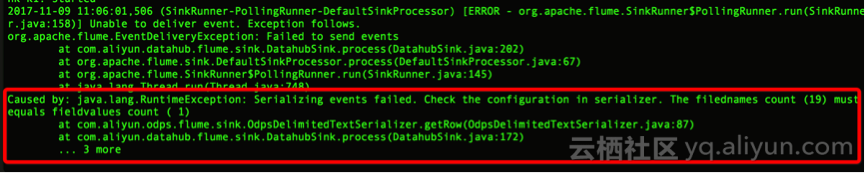
原因分析及解决方法
出现图示异常的原因,一般是因为解析日志文件得到的属性数量和配置文件不一致所致,此时需要重点排查:
1) 配置文件的间隔符、属性是否正确
a1.sinks.k1.serializer.delimiter = {字段间隔符}
a1.sinks.k1.serializer.fieldnames= {字段 “,” 隔开,注意需要与日志文件的顺序、datahub topic的顺序保持一致}
a1.sinks.k1.serializer.charset = {文字编码格式}
2) 日志文件格式是否符合预期、是否包含特殊字符
2、文件适配符模式下,找不到文件
异常信息截图:
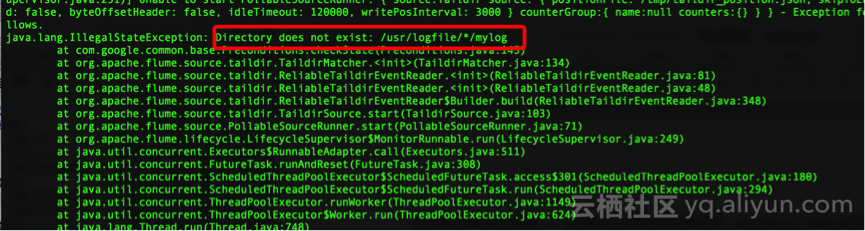

原因分析及解决方法
出现图示异常的原因,一般是因为按照通配符设置,未找到文件导致异常退出,此时需要重点检查配置文件中的日志路径设置:
a1.sources.r1.filegroups.f1 = {/usr/logfile/s51/mylog/*}
3、 修改配置文件后,重新启动,无异常信息但是不加载数据
异常信息截图:
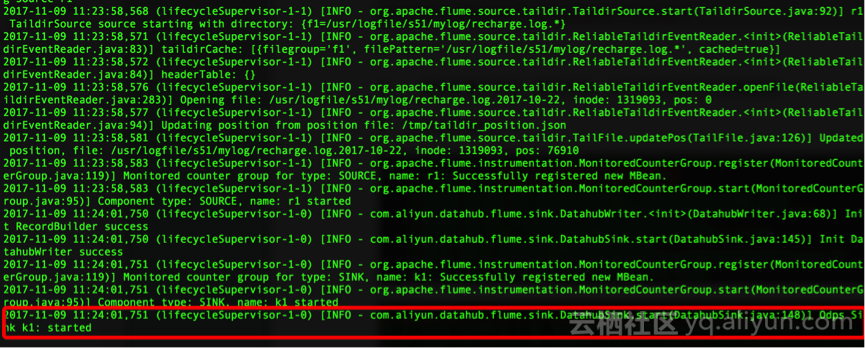
原因分析及解决方法
该问题比较隐秘,任务可以启动,没有明显的异常日志,但是到sink环节后不再加载数据,一般是因为修改了配置文件设置,但是没有删除对应的描述文件,需要:
1) 找到配置的描述文件路径
a1.sources.r1.positionFile = /tmp/taildir_position.json
2) 删除描述文件,重启任务
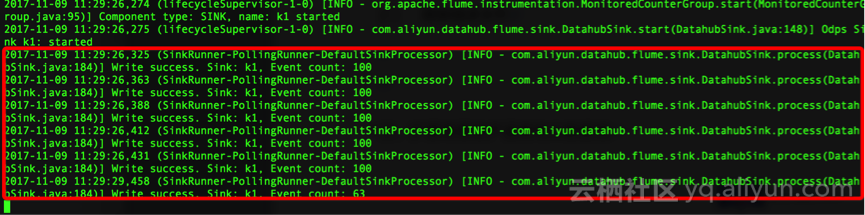
可正常加载数据;
三、扩展场景的产品架构&数据流
扫码获取更多资讯:
![]()
基于阿里云MaxCompute实现游戏数据运营相关推荐
- 基于阿里云 MaxCompute 构建企业云数据仓库CDW
在本文中阿里云资深产品专家云郎分享了基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议. 本文内容根据演讲视频以及PPT整理而成. 大家下午好,我是云郎,之前在甲骨文做企业架构师 ...
- 基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议
简介: 通过我们背后的指导思想和我们给出的技术解决方案,希望与大家能够一起探索一些新的基于云上的数据仓库构建的最佳实践,从而尽量避免走弯路.这就是我今天想跟大家分享的内容与目的. 在本文中阿里云资深产 ...
- 【案例】“1GB1年1毛钱“——使用 Backup exec 基于阿里云OSS 实现企业数据异地备份 【服务器管理】【云备份】
[案例]"1GB1年1毛钱"--使用 Backup exec 基于阿里云OSS 实现企业数据异地备份 [服务器管理][云备份] 1.使用环境 如图所示 资源 配置 备注 File ...
- 阿里云MaxCompute(大数据)公开数据集---带你玩转人工智能
摘要: 目前阿里云大数据产品已经免费向全部用户开放了多种公用数据集.开放的数据类别包括:股票价格数据,房产信息,影视及其票房数据. 点此查看原文:http://click.aliyun.com/m/4 ...
- 阿里云MaxCompute(大数据)公开数据集---带你玩转人工智能 1
摘要: 目前阿里云大数据产品已经免费向全部用户开放了多种公用数据集.开放的数据类别包括:股票价格数据,房产信息,影视及其票房数据. 点此查看原文:http://click.aliyun.com/m/4 ...
- 高德地图基于阿里云MaxCompute的最佳实践
原文链接:点击打开链接 摘要: 云计算带来的变革不言而喻,作为一种新型的IT交付模式,切实为企业节省IT成本.加快IT与企业业务结合效率.提升创新能力.加强管理水平以及增强系统本身的可靠性等方面提供巨 ...
- 演讲实录|OpenMLDB 与阿里云 MaxCompute 生态集成
在 OpenMLDB 第 8 期 Meetup 中,OpenMLDB PMC 陈迪豪以出租车行车时间预测问题为例,使用 OpenMLDB 基于阿里云 MaxCompute 的 Serverless 服 ...
- 基于阿里云实现游戏数据运营(附Demo)
摘要: 原作者:阿里云解决方案架构师,陆宝.通过阅读本文,您可以学会怎样使用阿里云的maxcompute搭建一套数据分析系统. 一.总览 一个游戏/系统的业务数据分析,总体可以分为图示的几个关键步骤: ...
- 阿里云MaxCompute,用计算力让数据发声
摘要: 计算的价值绝不止计算本身,而是让本不会说话的数据发声. 从玛雅历法到圆周率,从万有引力定律到二进制,从固化的物体到虚拟的思维都由数据注入.阿里云大数据计算服务MaxCompute以技术驱动产品 ...
最新文章
- 64位系统上使用*** Client端
- 24.Interpreter-解释器模式
- MySQL 到PostgreSQL 的数据迁移工具
- MySQL 数据存储文件
- SQL Server的镜像是基于物理块变化的复制 镜像Failover之后数据的预热问题
- List实现类性能和特点分析
- 万字详述 MySQL ProxySQL
- Java基本数据类型及其包装类
- BHIOT-833物联网智能网关
- linq to sql 行转列_n套SQL面试题--行转列、留存、日活等
- 如何将矩阵化为约旦标准型_【解题方法】矩阵初等变换的应用
- 资源过于硬核,8h删!这波福利....请笑纳~
- 服务器清洗项目,服务器带电清洗流程和注意事项
- 【css】各个字号大小对照表
- 数学与应用数学考研计算机方向,数学专业考研方向解析:应用数学
- lammps自带命令create_atoms实现水分子建模
- linux无法识别NIC,linux – 为什么ethtool没有向我显示NIC的所有属性?
- AI记者上岗,百度数字人度晓晓云上采访全国五一劳动奖获得者
- 华为mate20 android,华为mate20pro开箱
- ARGOX CP-2140MPPLB18X60药柜
热门文章
- 用c语言编程参赛信息查询,确定参赛者名单(C语言实现)
- python process_Python Process/Thread 概念整理
- python中提供怎样的内置库、可以用来创建用户界面_使用外部GUI库在Autodesk中创建用户界面可能会...
- navigator工具_Javascript常用工具类
- docker安装elasticsearch_Elasticsearch amp; Kibana 部署安装 (Docker)
- linux jdk bin下载,Linux下安装jdk-6u45-linux-x64.bin
- 颜宁谈院士增选:导师施一公让我特别受益的是:纯粹,做事情的纯粹
- 干货福利:AI人工智能学习资料教程包.zip
- AI算法连载04:数学基础之蒙特卡洛方法与MCMC采样
- 德国院士:“工业4.0”概念升级了,包含人工智能和5G