Facebook 开源的快速文本分类器 FastTex
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
- fastText 原理
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。下面我们一一介绍。
1.1 模型架构
fastText 模型架构如下图所示。fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
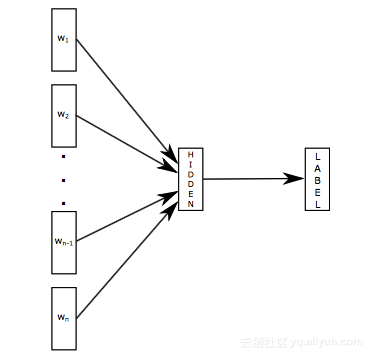
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
1.2 层次 Softmax
在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。具体细节参见 文章 。
1.3 N-gram 特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然啦,为了提高效率,我们需要过滤掉低频的 N-gram。
- fastText VS Tagspace
Mikolov 在 fastTetxt 的论文中报告了两个实验,其中一个实验和 Tagspace 模型进行对比。实验是在 YFCC100M 数据集上进行的, YFCC100M 数据集包含将近 1 亿张图片以及摘要、标题和标签。实验使用摘要和标题去预测标签。Tagspace 模型是建立在 Wsabie 模型的基础上的。Wsabie 模型除了利用 CNN 抽取特征之外,还提出了一个带权近似配对排序 (Weighted Approximate-Rank Pairwise, WARP) 损失函数用于处理预测目标数量巨大的问题。
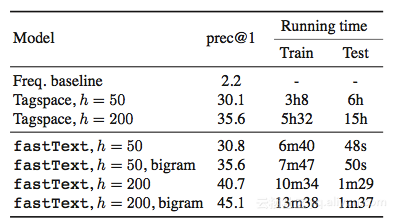
上面就是实验结果,从实验结果来看 fastText 能够取得比 Tagspace 好的效果,并拥有无以伦比的训练测试速度。但严格来说,这个实验对 Tagspace 有些不公平。YFCC100M 数据集是关于多标记分类的,即需要模型能从多个类别里预测出多个类。Tagspace 确实是做多标记分类的;但 fastText 只能做多类别分类,从多个类别里预测出一个类。而评价指标 prec@1 只评价一个预测结果,刚好能够评价多类别分类。
- 总结
Facebook Research 已经在 Github 上公布了 fastText 的 项目代码 。不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类,另一部分是词嵌入学习。按论文来说只有文本分类部分才是 fastText,但也有人把这两部分合在一起称为 fastText,比如这篇文章 Comparison of FastText and Word2Vec 。fastText 的词嵌入学习比 word2vec 考虑了词组成的相似性。比如 fastText 的词嵌入学习能够考虑 english-born 和 british-born 之间有相同的后缀,但 word2vec 却不能。fastText 的词嵌入学习的具体原理可以参照 论文 。
文章转载自 开源中国社区[http://www.oschina.net]
Facebook 开源的快速文本分类器 FastTex相关推荐
- [转]Facebook 开源的快速文本分类器 FastText
比深度学习快几个数量级,详解Facebook最新开源工具--fastText 导读:Facebook声称fastText比其他学习方法要快得多,能够训练模型"在使用标准多核CPU的情况下10 ...
- fastrtext︱R语言使用facebook的fasttext快速文本分类算法
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的.理论介绍可见博客:NLP︱高级词向量表达(二)--FastTex ...
- FastText:快速的文本分类器
转载请注明作者和出处:http://blog.csdn.net/john_bh/ 一.简介 二.FastText原理 2.1 模型架构 2.2 层次SoftMax 2.3 N-gram特征 三. 基于 ...
- Facebook开源了超大规模图嵌入算法,上亿个节点也能快速完成
https://www.toutiao.com/a6675562914365047300/ 图,是很有用的数据结构,用节点 (Node) 和边 (Edge) 织成一张网.比如,知识图谱就是这样的网. ...
- Faiss:Facebook 开源的相似性搜索类库
Facebook 在今年 3 月份发布了 Facebook AI 相似性搜索(简称 Faiss)项目,该项目提供的类库可以从多媒体文档中快速搜索出相似的条目--这个场景下的挑战是基于查询的传统搜索引擎 ...
- Facebook开源多款AI工具,支持游戏、翻译等
翻译 | 林椿眄 编辑 | 阿司匹林 出品 | AI科技大本营(公众号ID:rgznai100) 近日,Facebook 在年度开发者大会 F8 上宣布开源多款 AI 工具,除了 PyTorch.Ca ...
- Facebook 开源聊天机器人Blender,经94 亿个参数强化训练,更具“人情味”
来源:AI前线 作者 | Kyle Wiggers 编译 | Sambodhi 策划 & 编辑 | 刘燕 不久前,Facebook 开源了号称是全球最强大的聊天机器人 Blender,它标志着 ...
- Facebook开源NLP建模框架PyText,从论文到产品部署只需数天
选自code.fb 作者:AHMED ALY HEGAZY.CHRISTOPHER DEWAN 机器之心编译 参与:淑婷.张倩 Facebook AI Research(FAIR)今天宣布推出 PyT ...
- Facebook开源 PyTorch版 fairseq,准确性最高、速度比循环神经网络快9倍
今年5月,Facebook AI研究院(FAIR)发表了他们的研究成果fairseq,在fairseq中,他们使用了一种新型的卷积神经网络来做语言翻译,比循环神经网络的速度快了9倍,而且准确性也是现有 ...
最新文章
- Freebsd10上部署open*** 服务器
- java数据结构库函数_Java8 内置函数(api)总结
- java求阶乘的程序_按要求编写Java程序(阶乘)
- 如何在VisualStudio中加入你自己的assembly的Intellisense?
- 被利用达数百万次、瞄准 Linux 系统的 Top 15漏洞
- 覆盖的面积 HDU - 1255 (扫描线, 面积交)
- echarts折线图鼠标悬浮竖线_设置Echarts鼠标悬浮样式
- 三维空间 点线面解析
- 如何把身份证扫描成电子版?证件转电子版,这3个方法超好用
- 万用表测量二极管方法
- 深夜,想到今天学的linux内容,太值了
- 关于TCP乱序和重传的问题
- 如何使用AMR M分析rtp流中的amr语音
- MOOC哈工大2020C语言程序设计精髓编程题在线测试第五周
- 做了个小程序,广告收益2.60元广告费
- Linux文件、目录——鸟哥的Linux私房菜
- oracle exists
- java设计模式-动态代理(InvocationHandler)
- 学计算机随堂笔记,随堂笔记 计算机网络原理 自考 自学考试 4741.doc
- tp5 PHPExcel数据导出