《R语言数据分析》——3.2 聚集
本节书摘来自华章出版社《R语言数据分析》一书中的第3章,第3.2节,作者盖尔盖伊·道罗齐(Gergely Daróczi),潘怡 译,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.2 聚集
最直接的数据汇总方法应该是调用stats包的aggregate函数,该函数能支持以下我们期望的功能:通过分组变量将数据划分成不同的子集,并分别对这些子集进行统计汇总。调用aggregate函数的最基本方法之一是传递待聚集的数值向量,以及一个因子变量,该因子变量将定义参数FUN的值,以确定划分函数。下面的样例中,我们以每个工作日航班平均转飞率作为划分依据:
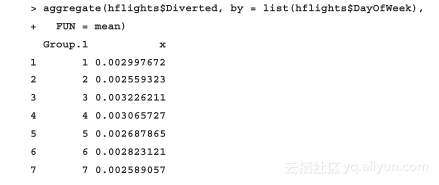
当然,我们需要一定时间来执行上述分析,不过别忘了我们刚刚处理的是将近25万行数据,以分析2011年从休斯顿机场出发的航班日均转非率。
换句话说,这个结果对那些没有纳入日均转飞率统计的数据一样有意义,例如,从结果可知,一周中周三、周四这两天的航班转飞率(0.3%左右)比周末的航班转飞率(0.25%左右)更高一些,至少从休斯顿机场出发的航班是这种情况。
另外一种类似调用上述函数的方法是使用with函数,使用with函数的语法看起来更容易理解一些,因为在with函数里,我们不用重复地引用hflights数据库:

执行结果因和上一种方法完全一致就不再重复显示了。从aggregate函数的指南(参见?aggregate)可知其返回结果比较容易理解。不过,如果要从结果中查看返回数据列名并不容易?我们可以通过使用公式化的标记而不是像之前样例那样采用直接定义数值和因子变量的方法来解决这个问题:
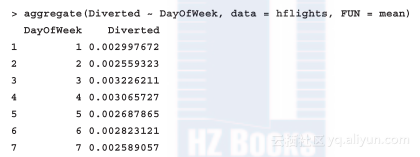
使用公式化标记的好处是两方面的:
输入的字符相对较少
结果中显示的行名称是正确的
函数执行的结果相对之前的函数调用方法要更快一点,请参考3.3节相关内容。
使用公式化标记的唯一不利因素就是我们必须首先掌握这种方法,尽管该方法乍看起来稍显笨拙,但由于很多R函数和包都可以运用这种标记方式,特别是在定义模型的时候,因此毫无疑问从长远角度出发有必要了解好掌握该方法。
公式化标记是从S语言继承下来的,常见语法形式为:response_variable~predictor_variable_1 + … + predictor_variable_n。该标记也包括一些其他记号,例如用“-”去掉变量,用“:”或“*”来包含变量间的相互作用。参见本书第5章建模(由Renata Nemeth和Gergely Tot授权阅读),以及在R控制台使用?formula命令获得更多细节内容。
3.2.1 使用基础的R命令实现快速聚集
还可以通过调用函数tapply或函数by来实现数据聚集,这些方法可以在一个不规则的矩阵上应用R函数。这也意味着我们能够提供一个或多个INDEX变量,这些变量能被强制转换为因子,然后,将相关R函数分别应用于每个数据子集的所有单元上。下面是一个简单的样例说明:

请注意函数tapply返回的是一个array对象,而不是常见的数据框对象。换句话说,也即该函数的执行速度比前面介绍过得的函数都要快。因此,首先使用tapply函数完成计算过程,再将结果增加合适的列名转换为data.frame对象是可行的。
3.2.2 方便的辅助函数
上述转换过程可以很容易地以一种用户容易理解的方式完成,例如,plyr包(dplyr包更常见的一种形式)就是为数据框开发的特殊plyr版本(plyr specialized for data frames)。
plyr包提供了非常多的函数来处理data.frame、list或array类型的对象,返回结果也支持以上各种数据类型。这些函数的命名规则非常容易记忆:函数名的第一个字符代表输入数据的类别,第二个字符代表输出格式,所有的情况都以ply结尾。除了前面提到的三种R数据类型,还存在一些特殊的字符定义:
d代表data.frame
s代表array
l代表list
m为一种特殊的输入类型,它意味着我们以表格方式为函数提供了多个参数
r代表函数希望输入一个整数,以指明函数将要复制的次数
_是一种特殊的输出类型,此时函数将不返回任何结果
以下最常见的组合分别代表着:
ddply以data.frame为输入,返回也为data.frame
ldply以list为输入,返回data.frame
l_ply不返回任何结果,但是在某些情况下非常有用。例如,基于一定元素递归而不使用for循环;作为.progress参数,可以获得当前迭代状态以及剩余时间。
可以在本书第4章找到更多关于plyr包的样例以及用户案例。本章,我们仅关注用该包完成数据统计。接下来,我们将在所有样例中使用ddply(不要与dplyr包混淆)包:采用data.frame框架作为输入参数,返回数据也是data.frame类型。
装载包,并将mean函数作用于由DayofWeek划分的数据子集的Diverted列:


plyr包的.函数为用户提供了一种方便的引用变量(名称)的方法。否则,ddply包将采用其他方式来解释DayofWeek列的内容,导致错误。
这里要说明的重要一点是ddply比之前我们用过的aggregate函数速度更快。但从其他方面而言,我对这个结果还并不十分满意,输出结果使用了V1这样的列名,让我有些受不了。这里我们不再进行更新data.frame的名称这样的再加工,而是调用summarise辅助函数来替代上面用的匿名函数,然后再显式指定相应的列名:

好了,看起来像样多了,不过我们还能做得更好吗?
3.2.3 高性能的辅助函数
Hadley Wickham是ggplot、reshape和其他一些R开发包的作者,自2008年起开发了plyr包的第二代也可以说是特定版本。最基本的起因在于plyr包经常被用于将一类data.frame数据转换成另一类data.frame数据,因此对它的应用需要特别小心。dplyr包是专门针对数据框应用开发的plyr定制版,实现速度更快,开发语言为C++,dplyr包还支持远程数据库。
不过,函数执行效率还是根据具体情况不同而变化。例如,dplyr包的语法与plyr包相比,就有非常大的改变。尽管前面提到的summarise函数在dplyr包里也可以使用,但dplyr包中已经没有单独的ddplyr函数,在dplyr包中所有的函数都是以plyr::ddplyr的组件身份执行的。
无论如何,为了不让理论知识太过复杂,如果希望对某个数据集的子集进行汇总,我们首先要在聚集操作之前定义好分组:
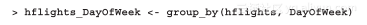
结果对象和data.frame非常类似,只有一点不同:元数据将根据属性的平均值合并到对象中。为了让输出结果短一点,我们不会展示对象的整个数据结构(str),只显示其属性:
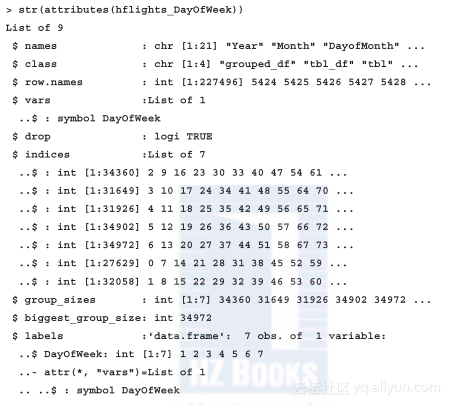
从输出的元数据可知,属性indicies很重要,它包含了每周中每天记录的ID,这样接下来的操作就能很容易地从整个数据集中选择所需的子集。下面,让我们看一下通过使用dplyr包的summairse函数而非plyr在提高操作性能后,转飞航班的比率:
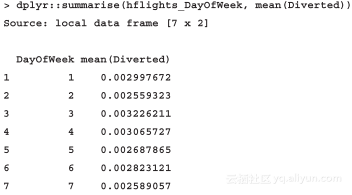
结果差不多,哪个更好呢?读者们有没有比较两种方法执行时间的差别?鉴于这些细微的差别,我们知道dplyr包效率更好。
3.2.4 使用data.table完成聚集
读者们还记得[.data.table的第二个参数吗?我们称之为j,该参数包含了一个SELECT或UPDATE功能的SQL语句,其最重要的特性就是支持R表达式。因此,我们可以不使用函数,而是借助by参数来实现分组。
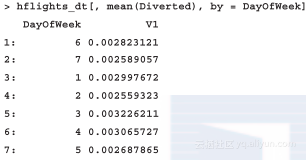
如果不希望采用V1来为结果表格的第二列数据命名,可以将summary对象指定为一个命名list,例如,hf?lights_dt[, list('mean(Diverted)'= mean(Diverted)), by = DayOfWeek],我们可以使用符号“.”而非list,就像在plyr包中的方法一样。
除了将结果按期望顺序排序,在现有键值列上进行数据统计速度也相对较快,下面我们将用一些实际案例对此进行说明。
《R语言数据分析》——3.2 聚集相关推荐
- 三十四、R语言数据分析实战
@Author : By Runsen @Date : 2020/5/14 作者介绍:Runsen目前大三下学期,专业化学工程与工艺,大学沉迷日语,Python, Java和一系列数据分析软件.导致翘 ...
- 《R语言数据分析与挖掘实战》——3.2 数据特征分析
本节书摘来自华章计算机<R语言数据分析与挖掘实战>一书中的第3章,第3.2节,作者 张良均,云伟标,王路,刘晓勇,更多章节内容可以访问云栖社区"华章计算机"公众号查看. ...
- 赠书!《R语言数据分析与可视化从入门到精通》
专注系列化.高质量的R语言教程 R语言是一个自由.免费.源代码开放的编程语言和环境,是S语言的一个分支,多个操作系统都能方便且免费地使用它.R语言不仅具有众多经常更新的统计分析函数,还具有完整的编程功 ...
- 《R语言数据分析》作业答案
<R语言数据分析>作业答案 数据赋人工系统以智能.北邮<R语言数据分析>课程从问道.执具.博术三个方面,阐述机器学习/数据挖掘的方法论(道).编程工具R语言(具)以及经典算法模 ...
- R语言数据分析-练习题【学习总结20201030】[1-20]
前言 1-20题 1.创建数据框 一般用data.frame,Python中也是,只不过是pd.DataFrame #######R语言数据分析############# ###1.创建数据框## d ...
- R语言数据分析120题
文章目录 R语言数据分析120题 P1-20 1(创建数据框):将下面的字典创建为DataFrame 2(筛选行):提取含有字符串"Python"的行 整个 包含部分字符 3(查看 ...
- 《R语言数据分析》期末试题
<R语言数据分析>期末试题 数据赋人工系统以智能.北邮<R语言数据分析>课程从问道.执具.博术三个方面,阐述机器学习/数据挖掘的方法论(道).编程工具R语言(具)以及经典算法模 ...
- R语言数据分析系列之五
R语言数据分析系列之五 -- by comaple.zhang 本节来讨论一下R语言的基本图形展示,先来看一张效果图吧. 这是一张用R语言生成的,虚拟的wordcloud云图,具体实现细节请参见我的g ...
- 2020互联网数据分析师教程视频 统计学分析与数据实战 r语言数据分析实战 python数据分析实战 excel自动化报表分析实战 excel数据分析处理实战
2020互联网数据分析师教程视频 统计学分析与数据实战 r语言数据分析实战 python数据分析实战 excel自动化报表分析实战 excel数据分析处理实战
最新文章
- 基于Accord.Audio和百度语言识别
- 【计算机网络复习 数据链路层】3.4.3 后退N帧协议(GBN)
- 安装ntop及快速安装rrdtool的方法
- 函数无法识别_Halcon OCR识别
- [dig]使用dig查看当前网络连通情况
- 设计模式------享元模式和组合模式
- L2TP连接尝试失败,因为安全层在初始化与远程计算机的协商时遇到了一个处理错误
- [Pytorch系列-42]:工具集 - torchvision常见预训练模型的下载地址
- Android开发之音乐播放器所遇到的问题
- 解决“ 故障模块名称: clr.dll ”
- 攀藤 5003粉尘激光传感器arduino使用
- 《这才是马云》读书笔记
- 让你的站点(Web)一键变成APP(应用程序)(上)
- 个人大数据征信查询浅谈与撸待现象
- mysql需要费用_mysql到底是不是免费的
- 《公司的力量》第一集 公司!公司!
- 朝代更替中的上下五千年
- 初链(true)混合共识算法分析与评估
- C++string中replace()替换函数
- 分享一个简繁字体转换的站点