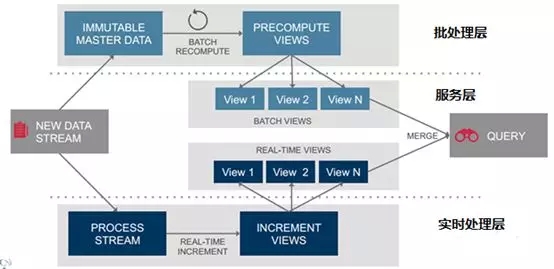
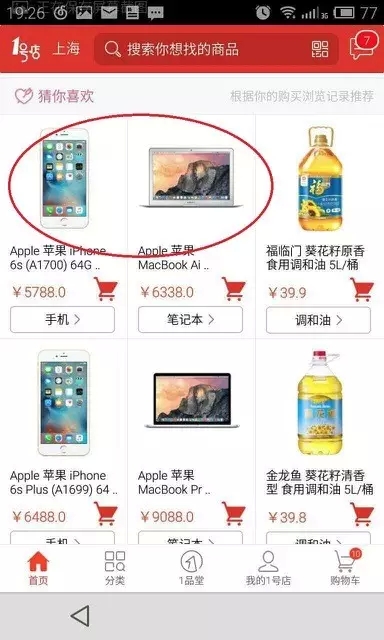
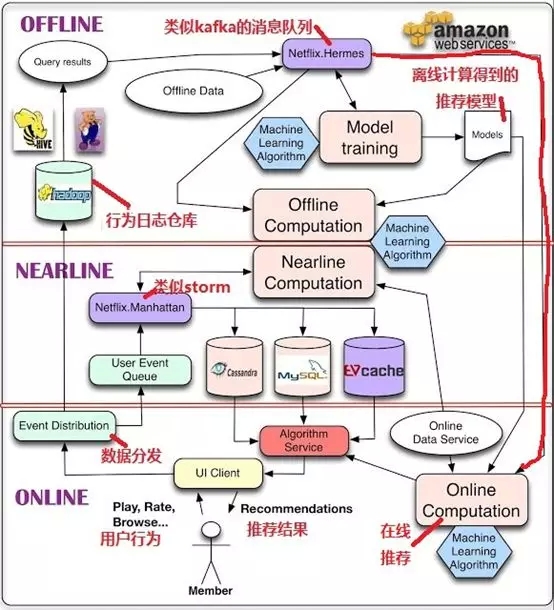
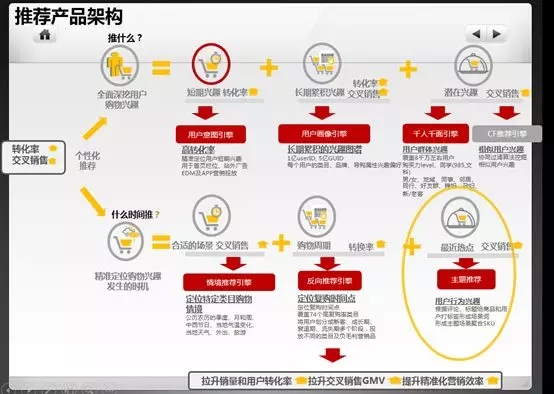
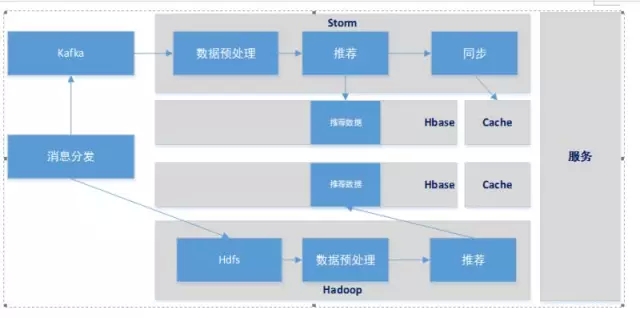
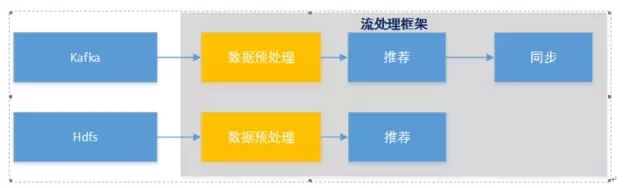
Lambda架构与推荐在电商网站实践

转载于:https://www.cnblogs.com/davidwang456/articles/8360497.html
Lambda架构与推荐在电商网站实践相关推荐
- 电商详情页缓存架构(一)电商网站的商品详情页架构
小型电商网站的商品详情页的页面静态化架构以及其缺陷 小型电商网站,一般使用页面静态化的方案,提前将数据渲染到模板中. 问题:每次模板变更,模板对应的所有数据需要全部重新渲染 大型电商网站的异步多级缓存 ...
- ASP.NET三层架构全站开发的电商网站
这里写自定义目录标题 欢迎使用Markdown编辑器 新的改变 功能快捷键 合理的创建标题,有助于目录的生成 如何改变文本的样式 插入链接与图片 如何插入一段漂亮的代码片 生成一个适合你的列表 创建一 ...
- 大型网站的架构演进从一个电商网站开始
为了更好的理解,我们用电商网站来举例,作为一个交易类型的网站,一定会具备用户(用户注册.用户管理).商品(商品展示.商品管理).交易(下单.支付)这些功能假如我们只需要支持这几个基本功能,那么我们最开 ...
- 大型电商网站架构案例和技术架构【推荐】
大型网站架构是一个系列文档,欢迎大家关注.本次分享主题:电商网站架构案例.从电商网站的需求,到单机架构,逐步演变为常用的,可供参考的分布式架构的原型.除具备功能需求外,还具备一定的高性能,高可用,可伸 ...
- 大型网站电商网站架构案例和技术架构的示例
大型网站架构是一个系列文档,欢迎大家关注.本次分享主题:电商网站架构案例.从电商网站的需求,到单机架构,逐步演变为常用的,可供参考的分布式架构的原型.除具备功能需求外,还具备一定的高性能,高可用,可伸 ...
- 大型网站架构系列:电商网站架构案例(1)
大型网站架构系列:电商网站架构案例(1) 大型网站架构是一个系列文档,欢迎大家关注.本次分享主题:电商网站架构案例.从电商网站的需求,到单机架构,逐步演变为常用的,可供参考的分布式架构的原型.除具备功 ...
- 大型电商网站架构分析
电商网站架构案例.从电商网站的需求,到单机架构,逐步演变为常用的,可供参考的分布式架构的原型.除具备功能需求外,还具备一定的高性能,高可用,可伸缩,可扩展等非功能质量需求(架构目标). 根据实际需要, ...
- 关于大型网站架构系列:电商网站架构案例(目前最有深意喜欢的文章)
算法与数据结构C++精解 ThinkPHP5.0+小程序商城构建全栈应用 AngularJS仿拉勾网WebApp开发移动端单页应用 Thinkphp 5.0实战 仿百度糯米开发多商家电商平台 原文出处 ...
- 电商总结(八)如何打造一个小而精的电商网站架构
前面写过一些电商网站相关的文章,这几天有时间,就把之前写得网站架构相关的文章,总结整理一下.把以前的一些内容就连贯起来,这样也能系统的知道,一个最小的电商平台是怎么一步步搭建起来的.对以前的文章感兴趣 ...
最新文章
- mysql 字段必填 属性_如何判断数据库中的字段是否具有必填属性(50分)
- sap oracle 内存参数,ORACLE 25个需要深思熟虑重要的初始化参数
- windows server 2012 添加中文语言包(英文转为中文)(离线)
- Apache/Nginx Cache Last-Modified、Expires和Etag相关工作原理
- Linux怎么删除虚拟硬盘,2017.05.10 qemu-nbd 全自动挂载/卸载 虚拟硬盘中所有可用分区 的 脚本...
- ruby hash方法_Ruby中带有示例的Hash.rehash方法
- 查询MySQL字段注释的 5 种方法!
- python是语言还是软件_程序开发语言之Python:是追逐还是坚守?
- 【连载】如何掌握openGauss数据库核心技术?秘诀三:拿捏存储技术(4)
- 基于大数据平台的异常检测场景分析方案
- CondaVerificationError;conda install verifying transactions一直在转
- 使用 vue-pdf 以及Lodop实现pdf打印预览功能
- Python--小游戏俄罗斯方块
- HNUST 1581 聚宝盆
- 【命名规则】小驼峰?大驼峰?
- win2003下php环境搭建,win2003下搭建PHP环境教程(上) | 网络菜鸟学习园地
- “制服大姨妈”对症调理
- 通往WinDbg的捷径
- 计算机是如何存储数据的?
- 稻草人项目--项目的数据处理流程-- ( day03 )
热门文章
- 服务器不响应Ajax,web前端:解决在IE11浏览器下,JQuery的AJAX方法不响应问题
- c#客户端 通过用户名密码访问服务器文件,C#如何连接服务器共享文件夹
- java统计多个线程的请求次数_Web并发页面访问量统计实现
- tilemap 导入unity_教程|Unity中使用Tilemap快速创建2D游戏世界
- linux 删除o开头的文件,linux实现除了某个文件或某个文件夹以外的全部删除
- 剪切工具怎么用_原创度检测工具是怎么用的?优质的内容更容易获得平台推荐...
- tensorflow和python不兼容_tensorflow与numpy的版本兼容性问题的解决
- mysql 开启断线重连_[BUG反馈]MYSQL长连接中(SWOOLE) 使用事务提交开启断线重连接抛出异常...
- java osgi web开发_基于 OSGi 和 Spring 开发 Web 应用
- mock模拟的数据能增删改查吗_使用Swager API Docs和easy-mock生成模拟数据