Faster R-CNN理解、讨论
论文 : Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. PAMI2017.
GitHub :
1. matlab version : https://github.com/ShaoqingRen/faster_rcnn
2. python version : https://github.com/rbgirshick/py-faster-rcnn
3. 补充程序Detectron : https://github.com/facebookresearch/Detectron (Detectron is Facebook AI Research's software system that implements state-of-the-art object detection algorithms, including Mask R-CNN. It is written in Python and powered by the Caffe2 deep learning framework.)
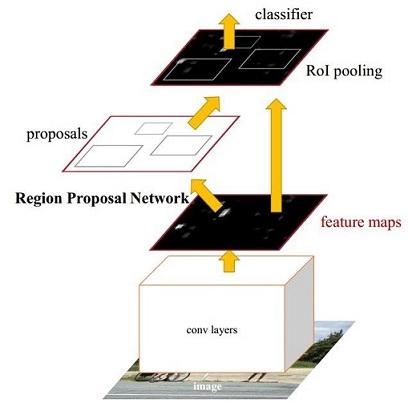
1. 前言
在Faster R-CNN出现之前,已经存在了R-CNN(无法实现End-to-End训练)和Fast R-CNN(Selective Search耗时),Shaoqing Ren在2016年NIP上提出了Faster R-CNN. 从上面的结构上,我们能够看出来,Faster R-CNN将特征提取、proposal提取、Bounding Box Regression、Classification整合到一个网络中,目标检测速度有了很大的提升。与R-CNN、Fast R-CNN相比,Faster R-CNN具体执行步骤如下:
- 特征提取(convolutional layer)。Faster R-CNN首先使用一组基础的conv+relu+pooling层提取候选图像的特征图。该特征图被共享用于后续RPN(Region Proposal Network)层和全连接(fully connection)层。
- 区域候选网络(Region Proposal Network)。RPN网络用于生成区域候选图像块。该层通过softmax判断锚点(anchors)属于前景(foreground)或者背景(background),再利用边界框回归(bounding box regression)修正anchors获得精确的proposals。
- 目标区池化(Roi Pooling)。该层收集输入的特征图和候选的目标区域,综合这些信息后提取目标区域的特征图,送入后续全连接层判定目标类别。
- 目标分类(Classification)。利用目标区域特征图计算目标区域的类别,同时再次边界框回归获得检测框最终的精确位置。
由此,我们也能看出,Faster R-CNN最大的亮点在于提出了一种有效定位目标区域的方法,然后按区域在特征图上进行特征索引,大大降低了卷积计算的时间消耗,所以速度上有了非常大的提升。
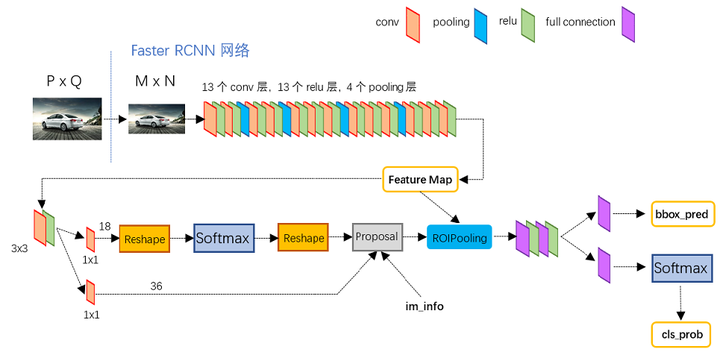
以如上GitHub中Python的项目为例,可以更加直接分析Faster R-CNN的设计思想。
- 对于任意PxQ的图像,首先裁剪到固定大小MxN。然后,利用VGG16全卷积模型计算该图像对应的特征图。
- 特征图的一个分支输入RPN网络用于计算Region Proposal。RPN网络首先经过3x3卷积,再分别生成前景锚点(foreground anchors)与边界框回归(bounding box regression)偏移量,然后计算出候选的目标区域;
- Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作目标分类 和 边界框精细回归。
2. 原理
2.1 卷积网络计算特征图
提取图像特征的卷积网络使用了最常见的模块,如卷积convolution、池化pooling、激活函数ReLUctant。在使用Python实现的FasterR-CNN模型,直接采用了VGG16计算图像的特征图。所以卷积网络包括13个卷积层,13个激活层,4个池化层。原文作者在进行卷子操作的时候进行了图像边缘补充操作,并使用了3x3的卷积核。具体信息为conv=3x3, padding=1, striide=1; Pooling=2x2, padding = 0, stride=2; 这样做简化了计算复杂性。也就是说3x3的卷积操作后,图像的尺寸不变; 2x2的池化操作后,图像的尺寸变为原图的0.5x0.5。所以,一张MxN大小的图像经过VGG16计算后,特征图像尺寸变为(M/16)x(N/16)。因此,特征图和原始图像就可以对应。
2.2 区域候选网络
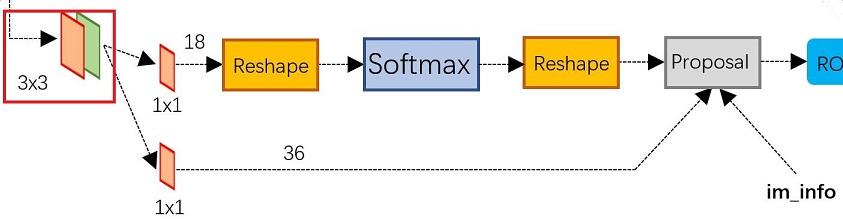
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用SS(Selective Search)方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
上图就是原文作者提出的Region Proposal Network示意图,这个网络实际分为2条线,上面的网络分支通过softmax分类anchors获得前景和背景(实际应用过程中,我们将目标默认为前景);下面的网络分支用于计算对于anchors的边界框回归的偏移量,以获得精确的目标候选区。
跟随的Proposal层综合前景锚点和边界框回归偏移量获取目标的候选区,同时剔除太小和超出边界的目标区域。所以,RPN实际就是实现了目标定位功能。
2.2.1 anchors
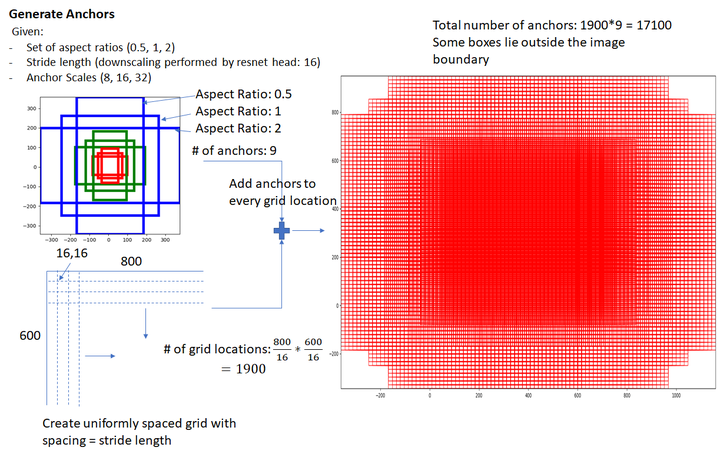
在Python实现的Faster R-CNN项目中,所谓anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形。直接运行作者demo中的generate_anchors.py可以得到以下输出:
[[ -84. -40. 99. 55.][-176. -88. 191. 103.][-360. -184. 375. 199.][ -56. -56. 71. 71.][-120. -120. 135. 135.][-248. -248. 263. 263.][ -36. -80. 51. 95.][ -80. -168. 95. 183.][-168. -344. 183. 359.]]其中每行的4个值(x1, y1, x2, y2) 表矩形左上和右下角点坐标。9个矩形共有3种形状,长宽比为大约为with:height∈{1:1, 1:2, 2:1}三种,如下图所示。实际上通过anchors就引入了检测中常用到的多尺度方法。
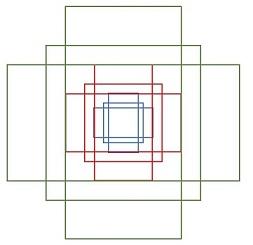
注:关于上面的anchors size,其实是根据检测图像设置的。在python demo中,会把任意大小的输入图像reshape成800x600。anchors中长宽1:2中最大为352x704,长宽2:1中最大736x384,基本是覆盖了800x600的各个尺度和形状。
那么这9个anchors是做什么的呢?借用Faster RCNN论文中的原图,如下所示,遍历卷积网络计算获得的特征图,为每一个点都配备这9种anchors作为初始的检测框。这样做获得检测框很不准确,不用担心,后面还有2次bounding box regression可以修正检测框位置。
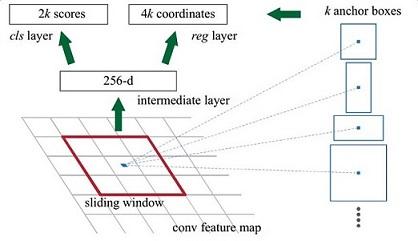
解释一下上面这张图的数字。
- 原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
- 在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息,同时256-d不变
- 假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
- 补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练
Comment:其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud。所以,仅仅是个二分类而已!
那么Anchor一共有多少个?原图800x600,VGG下采样16倍,feature map每个点设置9个Anchor,所以:ceil(800/16) * ceil(600/16) * 6=17100个候选框。
2.2.2 前景锚点背景锚点分类

一副MxN大小的矩阵送入Faster RCNN网络后,到RPN网络变为(M/16)x(N/16),不妨设 W=M/16,H=N/16。在进入reshape与softmax之前,先做了1x1卷积,如上图所示。可以看到其num_output=18,也就是经过该卷积的输出图像为WxHx18大小。这也就刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又有可能是foreground和background,所有这些信息都保存WxHx(9*2)大小的矩阵。为何这样做?后面接softmax分类获得foreground anchors,也就相当于初步提取了检测目标候选区域box(一般认为目标在foreground anchors中)。
2.3 边界框回归原理与实现方法

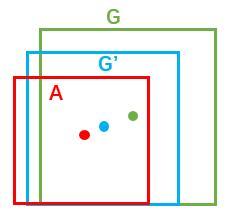
如图所示绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近
对于窗口一般使用四维向量 (x, y, w, h)表示,分别表示窗口的中心点坐标和宽高。对于图 11,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G',即:
- 给定:anchor
和
- 寻找一种变换F,使得:
,其中
那么经过何种变换F才能从图10中的anchor A变为G'呢? 比较简单的思路就是:
- 先做平移
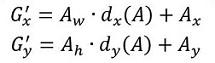
- 再做缩放
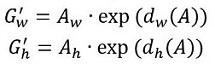
观察上面4个公式发现,需要学习的是 这四个变换。当输入的anchor A与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors A和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。
接下来的问题就是如何通过线性回归获得 了。线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值Y非常接近,即
。对于该问题,输入X是cnn feature map,定义为Φ;同时还有训练传入A与GT之间的变换量,即
。输出是
四个变换。那么目标函数可以表示为:
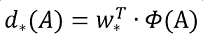
其中Φ(A)是对应anchor的feature map组成的特征向量,w是需要学习的参数,d(A)是得到的预测值(*表示 x,y,w,h,也就是每一个变换对应一个上述目标函数)。为了让预测值与真实值差距最小,设计损失函数:
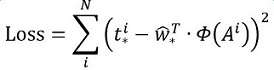
函数优化目标为:
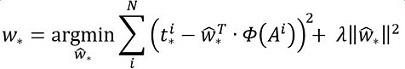
需要说明,只有在GT与需要回归框位置比较接近时,才可近似认为上述线性变换成立。
说完原理,对应于Faster RCNN原文,foreground anchor与ground truth之间的平移量 与尺度因子
如下:
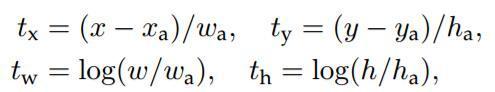
对于训练bouding box regression网络回归分支,输入是cnn feature Φ,监督信号是Anchor与GT的差距 ,即训练目标是:输入 Φ的情况下使网络输出与监督信号尽可能接近。
那么当bouding box regression工作时,再输入Φ时,回归网络分支的输出就是每个Anchor的平移量和变换尺度 ,显然即可用来修正Anchor位置了。

在了解bounding box regression后,再回头来看RPN网络的边界框回归部分,如上图所示。
2.2.3 Proposal Layer
Proposal Layer负责综合所有 变换量和foreground anchors,计算出精准的proposal,送入后续RoI Pooling Layer。
Proposal Layer有3个输入:fg/bg anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的变换量rpn_bbox_pred,以及im_info;另外还有参数feat_stride=16。
对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。然后经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。整个流程可以解释为:生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals。
2.3. RoI pooling
RoI Pooling层负责收集proposal,并计算出proposal feature maps,送入后续网络。Rol pooling层有2个输入:
- 原始的feature maps
- RPN输出的proposal boxes(大小各不相同)
2.4 分类
分类部分利用已经获得的proposal feature maps,通过full connection层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。Classification部分网络结构如下图所示。
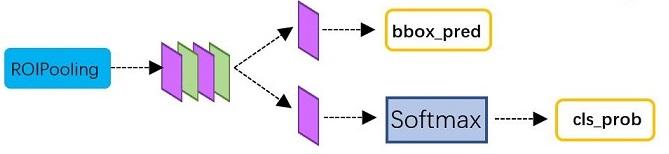
2.5 Faster R-CNN训练
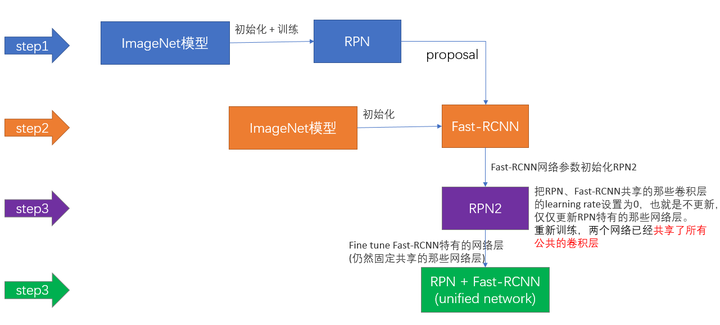
Faster R-CNN的训练,是在已经训练好的model(如VGG_CNN_M_1024,VGG,ZF)的基础上继续进行训练。实际中训练过程分为6个步骤:
- 在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
- 利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
- 第二训练RPN网络,对应stage2_rpn_train.pt
- 再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
可以看到训练过程类似于一种“迭代”的过程,不过只循环了2次。至于只循环了2次的原因是应为作者提到:"A similar alternating training can be run for more iterations, but we have observed negligible improvements",即循环更多次没有提升了。接下来本章以上述6个步骤讲解训练过程。
下面是一张训练过程流程图,应该更加清晰。
3. 参考资源
1. http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
2. https://zhuanlan.zhihu.com/p/24916624
3. https://zhuanlan.zhihu.com/p/31426458 (极力推荐,值得仔细阅读)
Faster R-CNN理解、讨论相关推荐
- Faster R CNN
Faster R CNN 3 FASTER R-CNN 我们的Faster R CNN 由两个模块组成,第一个模块是 proposes regions 的全卷积网络,第二个是使用 proposed r ...
- Faster RCNN代码理解(Python) ---训练过程
最近开始学习深度学习,看了下Faster RCNN的代码,在学习的过程中也查阅了很多其他人写的博客,得到了很大的帮助,所以也打算把自己一些粗浅的理解记录下来,一是记录下自己的菜鸟学习之路,方便自己过后 ...
- CNN理解比较好的文章
什么是卷积神经网络?为什么它们很重要? 卷积神经网络(ConvNets 或者 CNNs)属于神经网络的范畴,已经在诸如图像识别和分类的领域证明了其高效的能力.卷积神经网络可以成功识别人脸.物体和交通信 ...
- Faster R-CNN 深入理解 改进方法汇总
Faster R-CNN 从2015年底至今已经有接近两年了,但依旧还是Object Detection领域的主流框架之一,虽然推出了后续 R-FCN,Mask R-CNN 等改进框架,但基本结构变化 ...
- [目标检测] Faster R-CNN 深入理解 改进方法汇总
Faster R-CNN 从2015年底至今已经有接近两年了,但依旧还是Object Detection领域的主流框架之一,虽然推出了后续 R-FCN,Mask R-CNN 等改进框架,但基本结构变化 ...
- faster rcnn 论文理解
目录(?)[-] 思想 区域生成网络结构 特征提取 候选区域anchor Region Proposal Networks Translation-Invariant Anchors 窗口分类和位置精 ...
- faster rcnn的理解
结构: faster rcnn是fast rcnn的改进版,一个更快的算法.为了理解faster rcnn,建议读者先理解fast rcnn, fast rcnn结构的理解,可以参考我的一篇博客:fa ...
- 对Faster R-CNN的理解(1)
目标检测是一种基于目标几何和统计特征的图像分割,最新的进展一般是通过R-CNN(基于区域的卷积神经网络)来实现的,其中最重要的方法之一是Faster R-CNN. 1. 总体结构 Faster R-C ...
- 用R语言理解洛必达法则
文章目录 5 洛必达法则 极限的种类 洛必达法则作用于幂函数 5 洛必达法则 极限的种类 令NNN为常数,则常规的极限运算大致有以下几种 ∞±N=∞∞⋇N=∞(N≠0)N∔∞=∞N−∞=−∞N/∞= ...
- 用R语言理解连续性和导数
文章目录 微分 1 连续性 2 求导 微分 1 连续性 众所周知微分的几何意义是斜率,然而斜率最初的定义只涉及直线,指的是y=kx+by=kx+by=kx+b中的kkk,而对任意曲线y=f(x)y=f ...
最新文章
- 【openfst样例1】Tokenization
- 404 Note Found 团队会议纪要
- Linux Socket TCP/IP通信
- apache配置文件详解与优化
- 判断C语言变量名是否合法
- es6 Generator函数的this
- filter2D函数的.depth()变量的设定
- python笔记05_多线程
- java 字符单词匹配_如何使用Java RegEx匹配单词字符?
- 基于NFC的Android读写软件,NFC读写(android代码)
- 淘宝客CMS,公众号,小程序,淘客APP,外卖返利系统
- CAD转CAD注意事项
- 腾讯云cdn怎样接入域名
- 刷手机二维码轻松登机(仅限移动用户)
- WHAT、HOW、WHY
- echarts 制作图表固定的三个步骤
- MATLAB算法实战应用案例精讲-【深度学习工具篇】sift特征提取
- backtrader FAQ:什么是一篮子订单Bracket Orders optMaster
- 数据可视化之matplotlib实战:plt.stem()函数 绘制棉棒图
- 【LEETCODE】【史密斯数】