Spark 【数据挖掘平台介绍】 - Spark 1.1.0(看范式粒度)
一:Spark
Spark已正式申请加入Apache孵化器,从灵机一闪的实验室“电火花”成长为大数据技术平台中异军突起的新锐。本文主要讲述Spark的设计思想。Spark如其名,展现了大数据不常见的“电光石火”。具体特点概括为“轻、快、灵和巧”。
轻:Spark 0.6核心代码有2万行,Hadoop 1.0为9万行,2.0为22万行。一方面,感谢Scala语言的简洁和丰富表达力;另一方面,Spark很好地利用了Hadoop和Mesos(伯克利 另一个进入孵化器的项目,主攻集群的动态资源管理)的基础设施。虽然很轻,但在容错设计上不打折扣。主创人Matei声称:“不把错误当特例处理。”言下 之意,容错是基础设施的一部分。
快:Spark对小数据集能达到亚秒级的延迟,这对于Hadoop MapReduce(以下简称MapReduce)是无法想象的(由于“心跳”间隔机制,仅任务启动就有数秒的延迟)。就大数据集而言,对典型的迭代机器 学习、即席查询(ad-hoc query)、图计算等应用,Spark版本比基于MapReduce、Hive和Pregel的实现快上十倍到百倍。其中内存计算、数据本地性 (locality)和传输优化、调度优化等该居首功,也与设计伊始即秉持的轻量理念不无关系。
灵:Spark提供了不同层面的灵活性。在实现层,它完美演绎了Scala trait动态混入(mixin)策略(如可更换的集群调度器、序列化库);在原语(Primitive)层,它允许扩展新的数据算子 (operator)、新的数据源(如HDFS之外支持DynamoDB)、新的language bindings(Java和Python);在范式(Paradigm)层,Spark支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种 范式。
巧:巧在借势和借力。Spark借Hadoop之势,与Hadoop无缝结合;接着Shark(Spark上的数据仓库实现)借了Hive的势;图计算借 用Pregel和PowerGraph的API以及PowerGraph的点分割思想。一切的一切,都借助了Scala(被广泛誉为Java的未来取代 者)之势:Spark编程的Look'n'Feel就是原汁原味的Scala,无论是语法还是API。在实现上,又能灵巧借力。为支持交互式编 程,Spark只需对Scala的Shell小做修改(相比之下,微软为支持JavaScript Console对MapReduce交互式编程,不仅要跨越Java和JavaScript的思维屏障,在实现上还要大动干戈)。
说了一大堆好处,还是要指出Spark未臻完美。它有先天的限制,不能很好地支持细粒度、异步的数据处理;也有后天的原因,即使有很棒的基因,毕竟还刚刚起步,在性能、稳定性和范式的可扩展性上还有很大的空间。
计算范式和抽象
Spark首先是一种粗粒度数据并行(data parallel)的计算范式。
数据并行跟任务并行(task parallel)的区别体现在以下两方面。
计算的主体是数据集合,而非个别数据。集合的长度视实现而定,如SIMD(单指令多数据)向量指令一般是4到64,GPU的SIMT(单指令多线程)一般 是32,SPMD(单程序多数据)可以更宽。Spark处理的是大数据,因此采用了粒度很粗的集合,叫做Resilient Distributed Datasets(RDD)。
集合内的所有数据都经过同样的算子序列。数据并行可编程性好,易于获得高并行性(与数据规模相关,而非与程序逻辑的并行性相关),也易于高效地映射到底层 的并行或分布式硬件上。传统的array/vector编程语言、SSE/AVX intrinsics、CUDA/OpenCL、Ct(C++ for throughput),都属于此类。不同点在于,Spark的视野是整个集群,而非单个节点或并行处理器。
数据并行的范式决定了 Spark无法完美支持细粒度、异步更新的操作。图计算就有此类操作,所以此时Spark不如GraphLab(一个大规模图计算框架);还有一些应用, 需要细粒度的日志更新和数据检查点,它也不如RAMCloud(斯坦福的内存存储和计算研究项目)和Percolator(Google增量计算技术)。 反过来,这也使Spark能够精心耕耘它擅长的应用领域,试图粗细通吃的Dryad(微软早期的大数据平台)反而不甚成功。
Spark的RDD,采用了Scala集合类型的编程风格。它同样采用了函数式语义(functional semantics):一是闭包,二是RDD的不可修改性。逻辑上,每一个RDD算子都生成新的RDD,没有副作用,所以算子又被称为是确定性的;由于所 有算子都是幂等的,出现错误时只需把算子序列重新执行即可。
Spark的计算抽象是数据流,而且是带有工作集(working set)的数据流。流处理是一种数据流模型,MapReduce也是,区别在于MapReduce需要在多次迭代中维护工作集。工作集的抽象很普遍,如多 迭代机器学习、交互式数据挖掘和图计算。为保证容错,MapReduce采用了稳定存储(如HDFS)来承载工作集,代价是速度慢。HaLoop采用循环 敏感的调度器,保证前次迭代的Reduce输出和本次迭代的Map输入数据集在同一台物理机上,这样可以减少网络开销,但无法避免磁盘I/O的瓶颈。
Spark的突破在于,在保证容错的前提下,用内存来承载工作集。内存的存取速度快于磁盘多个数量级,从而可以极大提升性能。关键是实现容错,传统上有两种方法:日 志和检查点。考虑到检查点有数据冗余和网络通信的开销,Spark采用日志数据更新。细粒度的日志更新并不便宜,而且前面讲过,Spark也不擅长。 Spark记录的是粗粒度的RDD更新,这样开销可以忽略不计。鉴于Spark的函数式语义和幂等特性,通过重放日志更新来容错,也不会有副作用。
编程模型
来看一段代码:textFile算子从HDFS读取日志文件,返回“file”(RDD);filter算子筛出带“ERROR”的行,赋给 “errors”(新RDD);cache算子把它缓存下来以备未来使用;count算子返回“errors”的行数。RDD看起来与Scala集合类型 没有太大差别,但它们的数据和运行模型大相迥异。

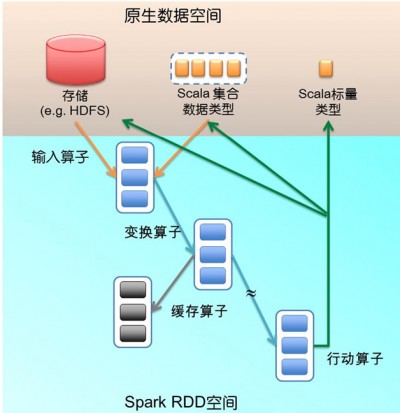
输入输出一对一(element-wise)的算子,且结果RDD的分区结构不变,主要是map、flatMap(map后展平为一维RDD);
输入输出一对一,但结果RDD的分区结构发生了变化,如union(两个RDD合为一个)、coalesce(分区减少);
从输入中选择部分元素的算子,如filter、distinct(去除冗余元素)、subtract(本RDD有、它RDD无的元素留下来)和sample(采样)。
另一部分变换算子针对Key-Value集合,又分为:
对单个RDD做element-wise运算,如mapValues(保持源RDD的分区方式,这与map不同);
对单个RDD重排,如sort、partitionBy(实现一致性的分区划分,这个对数据本地性优化很重要,后面会讲);
对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
对两个RDD基于key进行join和重组,如join、cogroup。
后三类操作都涉及重排,称为shuffle类操作。
从RDD到RDD的变换算子序列,一直在RDD空间发生。这里很重要的设计是lazy evaluation:计算并不实际发生,只是不断地记录到元数据。元数据的结构是DAG(有向无环图),其中每一个“顶点”是RDD(包括生产该RDD 的算子),从父RDD到子RDD有“边”,表示RDD间的依赖性。Spark给元数据DAG取了个很酷的名字,Lineage(世系)。这个 Lineage也是前面容错设计中所说的日志更新。
Lineage一直增长,直到遇上行动(action)算子(图1中的绿色箭头),这时 就要evaluate了,把刚才累积的所有算子一次性执行。行动算子的输入是RDD(以及该RDD在Lineage上依赖的所有RDD),输出是执行后生 成的原生数据,可能是Scala标量、集合类型的数据或存储。当一个算子的输出是上述类型时,该算子必然是行动算子,其效果则是从RDD空间返回原生数据 空间。
行动算子有如下几类:生成标量,如count(返回RDD中元素的个数)、reduce、fold/aggregate(见 Scala同名算子文档);返回几个标量,如take(返回前几个元素);生成Scala集合类型,如collect(把RDD中的所有元素倒入 Scala集合类型)、lookup(查找对应key的所有值);写入存储,如与前文textFile对应的saveAsText-File。还有一个检 查点算子checkpoint。当Lineage特别长时(这在图计算中时常发生),出错时重新执行整个序列要很长时间,可以主动调用 checkpoint把当前数据写入稳定存储,作为检查点。
这里有两个设计要点。首先是lazy evaluation。熟悉编译的都知道,编译器能看到的scope越大,优化的机会就越多。Spark虽然没有编译,但调度器实际上对DAG做了线性复 杂度的优化。尤其是当Spark上面有多种计算范式混合时,调度器可以打破不同范式代码的边界进行全局调度和优化。下面的例子中把Shark的SQL代码 和Spark的机器学习代码混在了一起。各部分代码翻译到底层RDD后,融合成一个大的DAG,这样可以获得更多的全局优化机会。


第三行filter对errors.count()的依赖是由(cnt-1)这个原生数据运算产生的,但调度器看不到这个运算,那就会出问题了。
由于Spark并不提供控制流,在计算逻辑需要条件分支时,也必须回退到Scala的空间。由于Scala语言对自定义控制流的支持很强,不排除未来Spark也会支持。
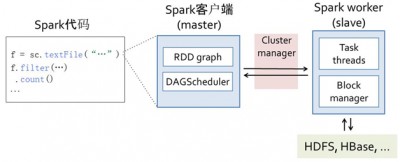
最有趣的部分是DAGScheduler。下面详解它的工作过程。RDD的数据结构里很重要的一个域是对父RDD的依赖。如图3所示,有两类依赖:窄(Narrow)依赖和宽(Wide)依赖。
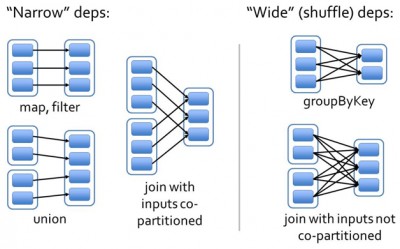
宽依赖指子RDD的分区依赖于父RDD的所有分区,这是因为shuffle类操作,如图3中的groupByKey和未经协同划分的join。
要深究两个问题:一,分区如何划分;二,分区该放到集群内哪个节点。这正好对应于RDD结构中另外两个域:分区划分器(partitioner)和首选位置(preferred locations)。
MLlib is Apache Spark's scalable machine learning library.
其定为为基于Apache Spark的四大子组件,并且权重极大。在目前而言,Spark 0.9.1 MLLIB 包含了如下的算法:
Spark 【数据挖掘平台介绍】 - Spark 1.1.0(看范式粒度)相关推荐
- ITTC数据挖掘平台介绍(综述)——平台简介
数据挖掘方兴未艾,大量新事物层出不穷.本系列将介绍我们自主设计的数据挖掘软件平台.与大家共同分享对知识,微博,人际等复杂网络的分析,以及对自然语言处理的见解. 一.我们需要怎样的数据挖掘系统 一直以来 ...
- ITTC数据挖掘平台介绍(四) 框架改进和新功能
本数据挖掘框架在这几个月的时间内,有了进一步的功能增强 一. 超大网络的画布显示虚拟化 如前几节所述,框架采用了三级层次实现,分别是数据,抽象Node和绘图的DataPoint,结构如下: 在界面显示 ...
- Spark RDD算子介绍
Spark学习笔记总结 01. Spark基础 1. 介绍 Spark可以用于批处理.交互式查询(Spark SQL).实时流处理(Spark Streaming).机器学习(Spark MLlib) ...
- spark MLlib平台的协同过滤算法---电影推荐系统
又好一阵子没有写文章了,阿弥陀佛...最近项目中要做理财推荐,所以,回过头来回顾一下协同过滤算法在推荐系统中的应用. 说到推荐系统,大家可能立马会想到协同过滤算法.本文基于Spark MLlib平台实 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.Spark Streaming简介 1.1 概述 Spark Streaming 是Sp ...
- spark数据挖掘 - 基于 Audioscrobbler 数据集音乐推荐实战
基于 Audioscrobbler 数据集音乐推荐实战 1. 数据集 这个例子将使用 Audioscrobbler 公开的数据集.Audioscrobbler是http://www.last.fm/z ...
- Spark数据挖掘实例1:基于 Audioscrobbler 数据集音乐推荐
本实例来源于<Spark高级数据分析>,这是一个很好的spark数据挖掘的实例.从经验上讲,推荐引擎属于大规模机器学习,在日常购物中大家或许深有体会,比如:你在淘宝上浏览了一些商品,或者购 ...
- Spark基础【介绍、入门WordCount案例】
文章目录 一 概述 0 Spark和Hadoop的关系 (1)从时间节点上来看 (2)从功能上来看 1 Hadoop 0.x 1.x的问题 2 Hadoop 2.x 3 Spark 4 Spark 和 ...
- Spark数据挖掘-基于 K 均值聚类的网络流量异常检测(1): 数据探索、模型初探
Spark数据挖掘-基于 K 均值聚类的网络流量异常检测(1): 数据探索.模型初探 1 前言 分类和回归是强大易学的机器学习技术.需要注意的是:为了对新的样本预测未知的值, 必须从大量已知目标值的样 ...
最新文章
- python3.5.3安装完后什么样子_python3.5安装python3-tk详解
- 2.1、spring属性注入-Set方法注入
- vs2017c语言图像界面库,C語言中在VS2017中構建圖形界面基礎知識點
- 安装配置Mysql主从
- 博客园电子月刊[第一期]
- java输出链表的值_[剑指offer] 从尾到头打印链表(三种方法) java
- 赋予用户最高权限的一点“挫折”
- luogu1082 [NOIp2012]同余方程 (扩展欧几里得)
- C# 读取excel
- hpuoj--校赛--特殊的比赛日期(素数判断+模拟)
- Android AsyncTask源代码浅析
- 深入理解Linux网络技术内幕学习笔记第二章:一些重要的数据结构
- 微信小程序-敏感内容检测 文本过滤 图片检测
- 时间管理方法分享 - 时间管理四象限法则
- linux 查询dhcp服务,查找局域网中的DHCP服务器
- 电脑IE图标删不掉怎么办
- 74cms|骑士cms|开源招聘系统,目录结构
- C语言学习笔记——调用函数时提示警告
- P60 整型数据类型讲解
- 汽车软件设计的变化趋势