Java之一致性hash算法原理及实现
为什么80%的码农都做不了架构师?>>> 
一致性哈希算法是分布式系统中常用的算法。
比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了。
一致性哈希算法,解决了普通余数Hash算法伸缩性差的问题,可以保证在上线、下线服务器的情况下,尽量有多的请求命中原来路由到的服务器。
一、一致性哈希算法
1、原理
算法的具体原理这里再次贴上:
先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值计算得到其Hash值(其分布也为[0, 232-1]),接着在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
(1)环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。
现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
(2)把数据通过一定的hash算法处理后映射到环上
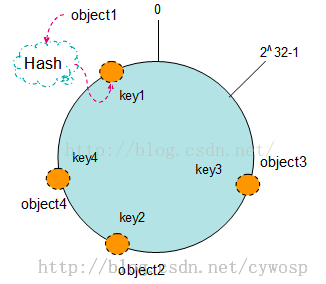
现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。如下图:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
(3)将机器通过hash算法映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中
(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
假设现在有NODE1,NODE2,NODE3三台机器,通过Hash算法得到对应的KEY值,映射到环中,其示意图如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
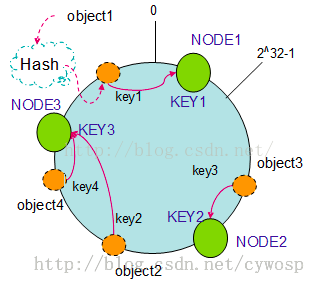
通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。
在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
2、机器的删除与添加
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会造成大量的对象存储位置失效。下面来分析一下一致性哈希算法是如何处理的。
(1)节点(机器)的删除
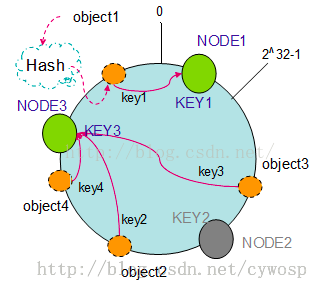
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:
(2)节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中,如下图:
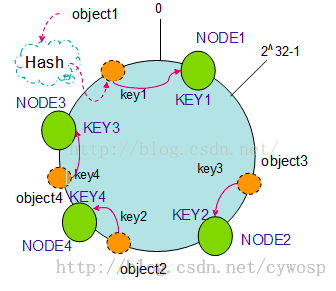
通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持着原有的存储位置。
通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
3、平衡性--虚拟节点
根据上面的图解分析,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,
因为还缺少了平衡性。下面将分析一致性哈希算法是如何满足平衡性的。
hash算法是不保证平衡的,如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样就造成了非常不平衡的状态。在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。
——“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一个实际节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
以上面只部署了NODE1和NODE3的情况(NODE2被删除的图)为例,之前的对象在机器上的分布很不均衡,现在我们以2个副本(复制个数)为例,这样整个hash环中就存在了4个虚拟节点,最后对象映射的关系图如下:
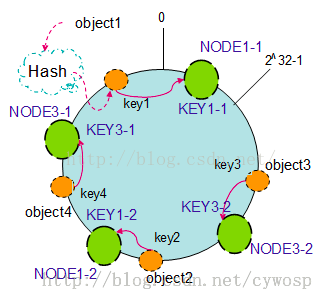
根据上图可知对象的映射关系:object1->NODE1-1,object2->NODE1-2,object3->NODE3-2,object4->NODE3-1。通过虚拟节点的引入,对象的分布就比较均衡了。那么在实际操作中,正真的对象查询是如何工作的呢?对象从hash到虚拟节点到实际节点的转换如下图:
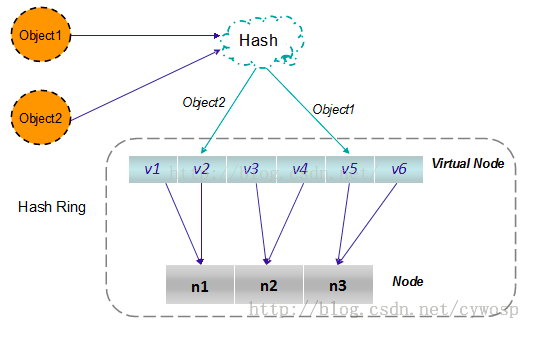
“虚拟节点”的hash计算可以采用对应节点的IP地址加数字后缀的方式。例如假设NODE1的IP地址为192.168.1.100。引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入“虚拟节点”后,计算“虚拟节”点NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1
Hash(“192.168.1.100#2”); // NODE1-2
二、一致性hash算法的Java实现
1、不带虚拟节点的
package hash;import java.util.SortedMap;
import java.util.TreeMap;/*** 不带虚拟节点的一致性Hash算法*/
public class ConsistentHashingWithoutVirtualNode {//待添加入Hash环的服务器列表private static String[] servers = { "192.168.0.0:111", "192.168.0.1:111","192.168.0.2:111", "192.168.0.3:111", "192.168.0.4:111" };//key表示服务器的hash值,value表示服务器private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>();//程序初始化,将所有的服务器放入sortedMap中static {for (int i=0; i<servers.length; i++) {int hash = getHash(servers[i]);System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);sortedMap.put(hash, servers[i]);}System.out.println();}//得到应当路由到的结点private static String getServer(String key) {//得到该key的hash值int hash = getHash(key);//得到大于该Hash值的所有MapSortedMap<Integer, String> subMap = sortedMap.tailMap(hash);if(subMap.isEmpty()){//如果没有比该key的hash值大的,则从第一个node开始Integer i = sortedMap.firstKey();//返回对应的服务器return sortedMap.get(i);}else{//第一个Key就是顺时针过去离node最近的那个结点Integer i = subMap.firstKey();//返回对应的服务器return subMap.get(i);}}//使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别private static int getHash(String str) {final int p = 16777619;int hash = (int) 2166136261L;for (int i = 0; i < str.length(); i++)hash = (hash ^ str.charAt(i)) * p;hash += hash << 13;hash ^= hash >> 7;hash += hash << 3;hash ^= hash >> 17;hash += hash << 5;// 如果算出来的值为负数则取其绝对值if (hash < 0)hash = Math.abs(hash);return hash;}public static void main(String[] args) {String[] keys = {"太阳", "月亮", "星星"};for(int i=0; i<keys.length; i++)System.out.println("[" + keys[i] + "]的hash值为" + getHash(keys[i])+ ", 被路由到结点[" + getServer(keys[i]) + "]");}
}执行结果:
[192.168.0.0:111]加入集合中, 其Hash值为575774686
[192.168.0.1:111]加入集合中, 其Hash值为8518713
[192.168.0.2:111]加入集合中, 其Hash值为1361847097
[192.168.0.3:111]加入集合中, 其Hash值为1171828661
[192.168.0.4:111]加入集合中, 其Hash值为1764547046
[太阳]的hash值为1977106057, 被路由到结点[192.168.0.1:111]
[月亮]的hash值为1132637661, 被路由到结点[192.168.0.3:111]
[星星]的hash值为880019273, 被路由到结点[192.168.0.3:111]
2、带虚拟节点的
package hash; import java.util.LinkedList; import java.util.List; import java.util.SortedMap; import java.util.TreeMap; import org.apache.commons.lang.StringUtils; /** * 带虚拟节点的一致性Hash算法 */ public class ConsistentHashingWithoutVirtualNode { //待添加入Hash环的服务器列表 private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111", "192.168.0.3:111", "192.168.0.4:111"}; //真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好 private static List<String> realNodes = new LinkedList<String>(); //虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称 private static SortedMap<Integer, String> virtualNodes = new TreeMap<Integer, String>(); //虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应5个虚拟节点 private static final int VIRTUAL_NODES = 5; static{ //先把原始的服务器添加到真实结点列表中 for(int i=0; i<servers.length; i++) realNodes.add(servers[i]); //再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高 for (String str : realNodes){ for(int i=0; i<VIRTUAL_NODES; i++){ String virtualNodeName = str + "&&VN" + String.valueOf(i); int hash = getHash(virtualNodeName); System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash); virtualNodes.put(hash, virtualNodeName); } } System.out.println(); } //使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别 private static int getHash(String str){ final int p = 16777619; int hash = (int)2166136261L; for (int i = 0; i < str.length(); i++) hash = (hash ^ str.charAt(i)) * p; hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) hash = Math.abs(hash); return hash; } //得到应当路由到的结点 private static String getServer(String key){ //得到该key的hash值 int hash = getHash(key); // 得到大于该Hash值的所有Map SortedMap<Integer, String> subMap = virtualNodes.tailMap(hash); String virtualNode; if(subMap.isEmpty()){ //如果没有比该key的hash值大的,则从第一个node开始 Integer i = virtualNodes.firstKey(); //返回对应的服务器 virtualNode = virtualNodes.get(i); }else{ //第一个Key就是顺时针过去离node最近的那个结点 Integer i = subMap.firstKey(); //返回对应的服务器 virtualNode = subMap.get(i); } //virtualNode虚拟节点名称要截取一下 if(StringUtils.isNotBlank(virtualNode)){ return virtualNode.substring(0, virtualNode.indexOf("&&")); } return null; } public static void main(String[] args){ String[] keys = {"太阳", "月亮", "星星"}; for(int i=0; i<keys.length; i++) System.out.println("[" + keys[i] + "]的hash值为" + getHash(keys[i]) + ", 被路由到结点[" + getServer(keys[i]) + "]"); } } 执行结果:
虚拟节点[192.168.0.0:111&&VN0]被添加, hash值为1686427075
虚拟节点[192.168.0.0:111&&VN1]被添加, hash值为354859081
虚拟节点[192.168.0.0:111&&VN2]被添加, hash值为1306497370
虚拟节点[192.168.0.0:111&&VN3]被添加, hash值为817889914
虚拟节点[192.168.0.0:111&&VN4]被添加, hash值为396663629
虚拟节点[192.168.0.1:111&&VN0]被添加, hash值为1032739288
虚拟节点[192.168.0.1:111&&VN1]被添加, hash值为707592309
虚拟节点[192.168.0.1:111&&VN2]被添加, hash值为302114528
虚拟节点[192.168.0.1:111&&VN3]被添加, hash值为36526861
虚拟节点[192.168.0.1:111&&VN4]被添加, hash值为848442551
虚拟节点[192.168.0.2:111&&VN0]被添加, hash值为1452694222
虚拟节点[192.168.0.2:111&&VN1]被添加, hash值为2023612840
虚拟节点[192.168.0.2:111&&VN2]被添加, hash值为697907480
虚拟节点[192.168.0.2:111&&VN3]被添加, hash值为790847074
虚拟节点[192.168.0.2:111&&VN4]被添加, hash值为2010506136
虚拟节点[192.168.0.3:111&&VN0]被添加, hash值为891084251
虚拟节点[192.168.0.3:111&&VN1]被添加, hash值为1725031739
虚拟节点[192.168.0.3:111&&VN2]被添加, hash值为1127720370
虚拟节点[192.168.0.3:111&&VN3]被添加, hash值为676720500
虚拟节点[192.168.0.3:111&&VN4]被添加, hash值为2050578780
虚拟节点[192.168.0.4:111&&VN0]被添加, hash值为586921010
虚拟节点[192.168.0.4:111&&VN1]被添加, hash值为184078390
虚拟节点[192.168.0.4:111&&VN2]被添加, hash值为1331645117
虚拟节点[192.168.0.4:111&&VN3]被添加, hash值为918790803
虚拟节点[192.168.0.4:111&&VN4]被添加, hash值为1232193678
[太阳]的hash值为1977106057, 被路由到结点[192.168.0.2:111]
[月亮]的hash值为1132637661, 被路由到结点[192.168.0.4:111]
[星星]的hash值为880019273, 被路由到结点[192.168.0.3:111]
原文:
http://blog.csdn.net/cywosp/article/details/23397179/ 一致性哈希算法
http://www.open-open.com/lib/view/open1455374048042.html 一致性哈希算法的Java实现
转载于:https://my.oschina.net/90888/blog/1645123
Java之一致性hash算法原理及实现相关推荐
- Java算法之 一致性hash算法原理及实现
为什么80%的码农都做不了架构师?>>> 一致性hash算法原理及实现 转载于:https://my.oschina.net/90888/blog/1645131
- 一致性 Hash 算法原理总结
一致性 Hash 算法是解决分布式缓存等问题的一种算法,本文介绍了一致性 Hash 算法的原理,并给出了一种实现和实际运用的案例: 一致性 Hash 算法背景 考虑这么一种场景: 我们有三台缓存服务器 ...
- JAVA实现一致性Hash算法
介绍 一致性Hash算法是实现负载均衡的一种策略,后续会写如何实现负载均衡 一致哈希是一种特殊的哈希算法. 在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n个关键字重新映射,其中K ...
- 一致性hash算法虚拟节点_一致性Hash算法原理详解
数据分片 先让我们看一个例子吧: 我们经常会用 Redis 做缓存,把一些数据放在上面,以减少数据的压力. 当数据量少,访问压力不大的时候,通常一台Redis就能搞定,为了高可用,弄个主从也就足够了: ...
- 一致性hash算法原理
集群容错 在分布式网络通信中,容错能力是必须要具备的,什么叫容错呢? 从字面意思来看:容:是容忍, 错:是错误. 就是容忍错误的能力. 我们知道网络通信会有很多不确定因素,比如网络延迟.网络中断.服务 ...
- java hash取模,一致性hash算法及其java实现
目录 背景 随着业务系统越来越大,我们需要对API的访问进行更多的缓存,使用Redis是一个很好的解决方案. 但是单台Redis性能不足够且迟早要走向集群的,那么怎么才能良好的利用Redis集群来进行 ...
- 一致性 Hash 算法学习(分布式或均衡算法)
简介: 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的 ...
- hash oracle 分表_一致性Hash算法在数据库分表中的实践
最近有一个项目,其中某个功能单表数据在可预估的未来达到了亿级,初步估算在90亿左右.与同事详细讨论后,决定采用一致性Hash算法来完成数据库的自动扩容和数据迁移.整个程序细节由我同事完成,我只是将其理 ...
- 一致性hash环原理
转自信仰<一致性hash环原理>(知乎), 吴帝永<一致性Hash算法(hash环)> 1. 为什么需要一致性Hash环 假设我们有N个Cache服务器的Node,我们的要求就 ...
最新文章
- 希捷推2TB 2.5英寸SSHD和5TB 2.5英寸机械硬盘
- Fabric--简单的资产Chaincode
- NYOJ 658 字符串右移
- ASP.NET Core 对Controller进行单元测试
- MySQL的复制:MySQL系列之十三
- 安装SQLServer2008后Windows防火墙上的端口开放
- 优雅的处理Exception
- java 读写文件乱码_Java 解决读写本地文件中文乱码的问题
- 2509-Druid监控功能的深入使用与配置-基于SpringBoot-完全使用 .properties配置文件
- 干货·Doherty功放设计
- Linux chromium弹出your preferences can not be read
- Chrome 89 新功能一览,性能提升明显,大量 DevTools 新特性!
- 笔记 GWAS 操作流程2-4:哈温平衡检验
- day03微信测试功能点思维导图
- 传智播客JDBC视频教程
- 《每个人的商学院》思维导图整理
- CSS 添加上标(用CSS伪类解决js无法赋值实现诸如单位平方的2上标)
- 【Zookeeper】基本使用:Curator操作Zookeeper
- java string 转 object_java 类型转换 Object和String互转
- c语言中除法怎么取模,c语言如何取模运算
热门文章
- vue地址栏输入路由跳转到首页_Vue路由跳转到新页面时 默认在页面最底部 而不是最顶部 的解决...
- 文件服务器登入,密钥文件登录云服务器
- arm-linux-gcc 没有那个文件或目录
- java数组实验心得体会_学习JAVA之数组小结
- p10可以适配鸿蒙吗,鸿蒙系统支持旧机型吗
- php朋友圈上传多个图片不显示不出来,求教!文章分享到微信朋友圈,链接的缩略图不显示怎么解决?...
- mysql控制台导出查询结果_MySQL 命令行导出、导入Select 查询结果
- linux自定义model,关于modelarts自定义镜像使用心得
- 运行到手机_清理手机垃圾的三个方法,让手机恢复流畅运行
- C语言 FileStreaming buffer