大数据开发:剖析Hadoop和Spark的Shuffle过程差异
一、前言
对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交、并、差、聚合、排序等过程。而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么要想求得某个key对应的全量数据,那就必须把相同key的数据汇集到同一个Reduce任务节点来处理,那么Mapreduce范式定义了一个叫做Shuffle的过程来实现这个效果。
二、编写本文的目的
本文旨在剖析Hadoop和Spark的Shuffle过程,并对比两者Shuffle的差异。
三、Hadoop的Shuffle过程
Shuffle描述的是数据从Map端到Reduce端的过程,大致分为排序(sort)、溢写(spill)、合并(merge)、拉取拷贝(Copy)、合并排序(merge sort)这几个过程,大体流程如下:
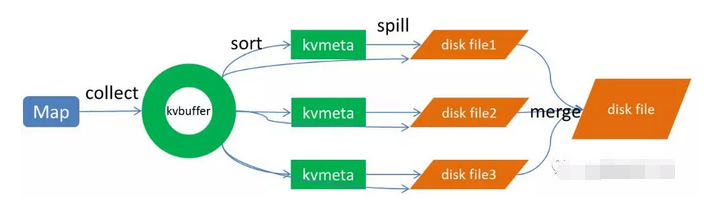 上图的Map的输出的文件被分片为红绿蓝三个分片,这个分片的就是根据Key为条件来分片的,分片算法可以自己实现,例如Hash、Range等,最终Reduce任务只拉取对应颜色的数据来进行处理,就实现把相同的Key拉取到相同的Reduce节点处理的功能。下面分开来说Shuffle的的各个过程。
Map端做了下图所示的操作:
1、Map端sort
Map端的输出数据,先写环形缓存区kvbuffer,当环形缓冲区到达一个阀值(可以通过配置文件设置,默认80),便要开始溢写,但溢写之前会有一个sort操作,这个sort操作先把Kvbuffer中的数据按照partition值和key两个关键字来排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
2、spill(溢写) 当排序完成,便开始把数据刷到磁盘,刷磁盘的过程以分区为单位,一个分区写完,写下一个分区,分区内数据有序,最终实际上会多次溢写,然后生成多个文件 3、merge(合并) spill会生成多个小文件,对于Reduce端拉取数据是相当低效的,那么这时候就有了merge的过程,合并的过程也是同分片的合并成一个片段(segment),最终所有的segment组装成一个最终文件,那么合并过程就完成了,如下图所示
大数据开发:剖析Hadoop和Spark的Shuffle过程差异 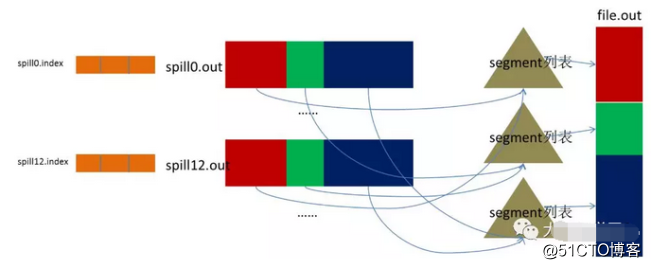
至此,Map的操作就已经完成,Reduce端操作即将登场
Reduce操作
总体过程如下图的红框处:
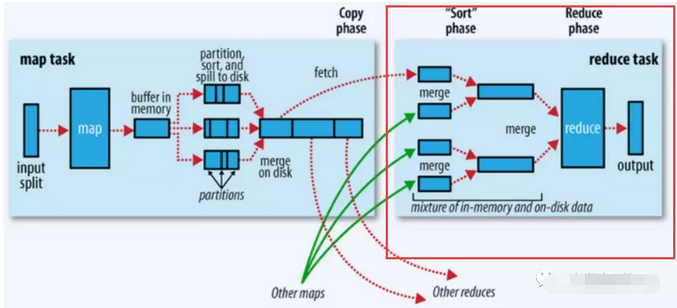 1、拉取拷贝(fetch copy) Reduce任务通过向各个Map任务拉取对应分片。这个过程都是以Http协议完成,每个Map节点都会启动一个常驻的HTTP server服务,Reduce节点会请求这个Http Server拉取数据,这个过程完全通过网络传输,所以是一个非常重量级的操作。
2、合并排序 Reduce端,拉取到各个Map节点对应分片的数据之后,会进行再次排序,排序完成,结果丢给Reduce函数进行计算。
四、总结
至此整个shuffle过程完成,最后总结几点:
shuffle过程就是为了对key进行全局聚合
排序操作伴随着整个shuffle过程,所以Hadoop的shuffle是sort-based的
Spark shuffle相对来说更简单,因为不要求全局有序,所以没有那么多排序合并的操作。Spark shuffle分为write和read两个过程。我们先来看shuffle write。
一、shuffle write
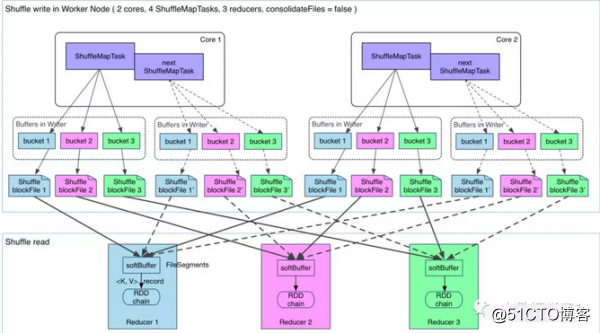
shuffle write的处理逻辑会放到该ShuffleMapStage的最后(因为spark以shuffle发生与否来划分stage,也就是宽依赖),final RDD的每一条记录都会写到对应的分区缓存区bucket,如下图所示:
说明:
上图有2个CPU,可以同时运行两个ShuffleMapTask
每个task将写一个buket缓冲区,缓冲区的数量和reduce任务的数量相等
每个buket缓冲区会生成一个对应ShuffleBlockFile
ShuffleMapTask 如何决定数据被写到哪个缓冲区呢?这个就是跟partition算法有关系,这个分区算法可以是hash的,也可以是range的
最终产生的ShuffleBlockFile会有多少呢?就是ShuffleMapTask 数量乘以reduce的数量,这个是非常巨大的
那么有没有办法解决生成文件过多的问题呢?有,开启FileConsolidation即可,开启FileConsolidation之后的shuffle过程如下:
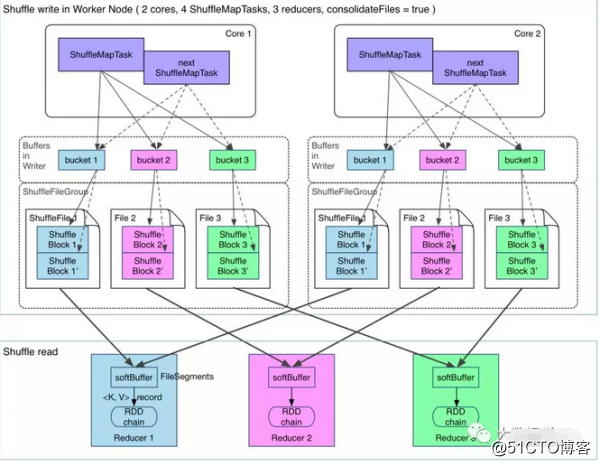
在同一核CPU执行先后执行的ShuffleMapTask可以共用一个bucket缓冲区,然后写到同一份ShuffleFile里去,上图所示的ShuffleFile实际上是用多个ShuffleBlock构成,那么,那么每个worker最终生成的文件数量,变成了cpu核数乘以reduce任务的数量,大大缩减了文件量。
二、Shuffle read
Shuffle write过程将数据分片写到对应的分片文件,这时候万事具备,只差去拉取对应的数据过来计算了。
那么Shuffle Read发送的时机是什么?是要等所有ShuffleMapTask执行完,再去fetch数据吗?理论上,只要有一个 ShuffleMapTask执行完,就可以开始fetch数据了,实际上,spark必须等到父stage执行完,才能执行子stage,所以,必须等到所有 ShuffleMapTask执行完毕,才去fetch数据。fetch过来的数据,先存入一个Buffer缓冲区,所以这里一次性fetch的FileSegment不能太大,当然如果fetch过来的数据大于每一个阀值,也是会spill到磁盘的。
fetch的过程过来一个buffer的数据,就可以开始聚合了,这里就遇到一个问题,每次fetch部分数据,怎么能实现全局聚合呢?以word count的reduceByKey(《Spark RDD操作之ReduceByKey 》)为例,假设单词hello有十个,但是一次fetch只拉取了2个,那么怎么全局聚合呢?Spark的做法是用HashMap,聚合操作实际上是map.put(key,map.get(key)+1),将map中的聚合过的数据get出来相加,然后put回去,等到所有数据fetch完,也就完成了全局聚合。
三、总结
Hadoop的MapReduce Shuffle和Spark Shuffle差别总结如下:
Hadoop的有一个Map完成,Reduce便可以去fetch数据了,不必等到所有Map任务完成,而Spark的必须等到父stage完成,也就是父stage的map操作全部完成才能去fetch数据。
Hadoop的Shuffle是sort-base的,那么不管是Map的输出,还是Reduce的输出,都是partion内有序的,而spark不要求这一点。
Hadoop的Reduce要等到fetch完全部数据,才将数据传入reduce函数进行聚合,而spark是一边fetch一边聚合。
觉得不错请点赞支持,欢迎留言或进我的个人群855801563领取【架构资料专题目合集90期】、【BATJTMD大厂JAVA面试真题1000+】,本群专用于学习交流技术、分享面试机会,拒绝广告,我也会在群内不定期答题、探讨。
转载于:https://blog.51cto.com/13981400/2383557
大数据开发:剖析Hadoop和Spark的Shuffle过程差异相关推荐
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 《Spark与Hadoop大数据分析》——1.2 大数据科学以及Hadoop和Spark在其中承担的角色...
1.2 大数据科学以及Hadoop和Spark在其中承担的角色 数据科学的工作体现在以下这两个方面: 要从数据中提取其深层次的规律性,意味着要使用统计算法提炼出有价值的信息.数据产品则是一种软件系统, ...
- hadoop大数据开发基础_Java大数据开发(三)Hadoop(2)经典的Hadoop
点击蓝字关注我 1 什么是大数据 1.Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2.主要解决,海量数据的存储和海量数据的分析计算问题. 3.广义上来说,HADOOP通常是指一个 ...
- 数据分析师、大数据开发、Hadoop开发工程师、数据挖掘、算法工程师的工资薪水到底怎么样?
据最新发布的<大数据人才报告>显示,目前全国的大数据人才仅46万,未来3-5年内大数据人才的缺口将高达150万. 领英报告表明,数据分析人才的供给指数最低,仅为0.05,属于高度稀缺.数据 ...
- 《大数据基础——基于Hadoop与Spark》课后习题——第一章部分答案
仅用于我个人的学习.书籍为人民邮电出版社的<大数据技术基础--基于Hadoop与Spark>.课后习题选择是我个人认为有用的.记录下来是为了督促我学习:) 共好 1.请指出以下术语的基本含 ...
- 大数据开发实战系列之Spark电商平台
源于企业级电商网站的大数据统计分析平台,该平台以 Spark 框架为核心,对电商网站的日志进行离线和实时分析. 该大数据分析平台对电商网站的各种用户行为(访问行为.购物行为.广告点击行为等)进行分析, ...
- 搭建大数据开发环境-Hadoop篇
前期准备 操作系统 hadoop目前对linux操作系统支持是最好的,可以部署2000个节点的服务器集群:在hadoop2.2以后,开始支持windows操作系统,但是兼容性没有linux好.因此,建 ...
- 大数据开发方向分享:春招获蚂蚁金服、拼多多、华为(终端)、远景能源、华泰证券等offer
大数据开发方向分享:春招获蚂蚁金服.拼多多.华为(终端).远景能源.华泰证券等offe 一.背景 2020届985硕士,投的基本是上海岗位,非科班转行大数据开发方向和Java后端开发. 参加了2020 ...
- 从后端开发转大数据开发怎么样?
你为什么从后端开发(Java/golang)转到大数据开发(Hadoop/Spark)?转大数据的最初原因很简单,就是好几个同事都转了,他们的收入瞬间提高了好多,于是在同事的内推我也就跟着转了,转完以 ...
最新文章
- 常用快捷键整理,提升工作效率!
- Codeforces 524F And Yet Another Bracket Sequence 哈希
- 中国网闸市场调研分析与发展战略建议报告2022版
- [react] react中可以在render访问refs吗?为什么?
- Datawhale组队-pandas(上)基础(自学)
- SFTP多用户权限 linux环境 一站式解决方案
- Git Flow工作流图
- 关于今日头条小程序(字节跳动小程序)相关问题
- swagger的使用
- C语言error2005,关于ERROR LNK 2005错误
- 安装完成后打开CAXACAD时出现的找不到mfc100u.dll等无法执行的问题
- JCMsuite 纳米光学仿真分析
- jy-10-SPRINGMYBATIS01——Spring-成恒
- github下载慢的两种解决方式
- Yandex-好用的以图搜图网站
- TensorFlow 2 实现线性回归和非线性回归
- 2019 中文互联网资源碎碎念
- 8年京东大数据架构师推荐的大数据开发学习路线
- 四扫客户接口——接口测试完成文档
- FFMPEG音频视频开发: 开发本地视频播放器(单线程解码)