SQL Server数据挖掘简介
Prediction, is it a new thing for you? You won’t believe you are predicting from the bed to the office and to back to the bed. Just imagine, you have a meeting at 9 AM at the office. If you are using public transport, you need to predict at what time you have to leave so that you can reach the office for the meeting on time. Time may vary by considering the time and the day of the week, and the traffic condition etc. Before you leave your home, you might predict whether it will rain today and you might want to take an umbrella or necessary clothes with you. If you are using your vehicle then the prediction time would be different. If so, you don’t need to worry about the rain but you need to consider the fuel level you need to have to reach to the office. By looking at this simple example, you will understand how critical it is to predict and you understand that all these predictions are done with your experience but not by any scientific method.
预测,对您来说这是新事物吗? 您不会相信您正在预测从床上到办公室再回到床上。 试想一下,您上午9点在办公室开会。 如果您使用的是公共交通工具,则需要预测必须离开的时间,以便可以准时到达办公室开会。 时间可能会因考虑时间和星期几以及交通状况等因素而有所不同。出门前,您可以预测今天是否会下雨,并且可能想带伞或必要的衣服。 如果您使用的是车辆,则预测时间会有所不同。 如果是这样,您不必担心下雨,但您需要考虑必须达到办公室的燃油水平。 通过查看这个简单的示例,您将了解预测的重要性,并且您了解所有这些预测都是根据您的经验完成的,而不是通过任何科学方法完成的。
The next question would be how to implement any data mining solution in a real-world scenario. Well, you might have heard of the famous story of Beer-Nappy at the popular supermarket chain. That is just a simple example of data mining implementation. So let’s see how we define data mining.
下一个问题是如何在实际场景中实现任何数据挖掘解决方案。 好吧,您可能已经在流行的连锁超市听说了比尔-纳皮的著名故事。 那只是数据挖掘实现的一个简单示例。 因此,让我们看看如何定义数据挖掘。
什么是数据挖掘? (What is Data Mining?)
There are several definitions for data mining with respect to business as well as for academics. Data mining is a practice that will automatically search a large volume of data to discover behaviors, patterns, and trends that are not possible with the simple analysis. Data Mining should allow businesses to make proactive, knowledge-driven decisions that will make the place better ahead of their competitors.
关于业务以及学者的数据挖掘有几种定义。 数据挖掘是一种将自动搜索大量数据以发现简单分析无法实现的行为,模式和趋势的实践。 数据挖掘应使企业能够做出主动的,以知识为导向的决策,从而使企业在竞争者面前更胜一筹。
Data warehouse, from its mandate to store a large volume of data including the last years of data. The data warehouse is used for descriptive analysis (What happened) and diagnostic analysis (Why it happened). However, business needs to do analysis beyond that. Data mining can be utilized for Predictive Analysis (What will happen) and Prescriptive Analysis (How can we make it happen).
数据仓库,从其授权来存储大量数据,包括最近几年的数据。 数据仓库用于描述性分析(发生了什么)和诊断分析(为什么发生了)。 但是,企业还需要进行分析。 数据挖掘可用于预测分析(将会发生什么)和指示性分析(我们如何使它发生)。
SQL Server中的数据挖掘 (Data Mining in SQL Server)
SQL Server is mainly used as a storage tool in many organizations. However, with the increase of many businesses’ needs people are looking to different features of SQL Server. People are looking at data warehousing with SQL Server. SQL Server is providing a Data Mining platform which can be utilized for the prediction of data.
SQL Server在许多组织中主要用作存储工具。 但是,随着许多企业需求的增长,人们正在寻找SQL Server的不同功能。 人们正在考虑使用SQL Server进行数据仓库。 SQL Server提供了可用于数据预测的数据挖掘平台。
There are a few tasks used to solve business problems. Those tasks are Classify, Estimate, Cluster, forecast, Sequence, and Associate. SQL Server Data Mining has nine data mining algorithms that can be used to solve the aforementioned business problems. The following are the list of algorithms that are categorized into different problems.
有一些任务可用于解决业务问题。 这些任务是分类,估计,聚类,预测,顺序和关联。 SQL Server数据挖掘具有九种数据挖掘算法,可用于解决上述业务问题。 以下是归类为不同问题的算法列表。
Classify: Categorized depending on the various attributes. For example, whether a customer is a prospect customer depending on other data such as Age, Gender, Marital Status, Occupation, Education Qualification, etc.
分类:根据各种属性进行分类。 例如,客户是否是潜在客户取决于其他数据,例如年龄,性别,婚姻状况,职业,学历等。
Estimate: Estimation will be done using the parameters. For example, house prices will be predicted depending on the house location, house size, etc.
估计:将使用参数进行估计。 例如,将根据房屋位置,房屋大小等预测房价。
Cluster: also named as segmentation. Depending on the various attribute natural grouping is done. Customer Segmentation is the classical business example for the clustering.
群集:也称为细分。 根据各种属性,可以完成自然分组。 客户细分是集群的经典业务示例。
Forecast: Predict continuous variable for with the time. Predicting sales volume for the next couple of years is a very common scenario in the industry.
预测:预测随时间变化的连续变量。 预测未来几年的销量是行业中非常普遍的情况。
Associate: Finding common items or groups in one transaction. The transaction can be a supermarket sales, or medicine or online sales.
关联:在一项交易中查找共同的项目或组。 交易可以是超市销售,也可以是药品或在线销售。
Sequence: Predicting the Sequence of events.
顺序:预测事件的顺序。
平台 (Platform)
SQL Server 2017 is used in this article but if you have SQL Server 2012 onwards you can still follow this.
本文使用了SQL Server 2017,但如果您具有SQL Server 2012及更高版本,则仍然可以按照此步骤进行操作。
In this article series, we will be using a sample data set which you can download and run through with the article. You can download AdventureWorks database and install it to your SQL Server instance.
在本系列文章中,我们将使用一个样本数据集,您可以下载该样本数据并贯穿本文。 您可以下载AdventureWorks数据库并将其安装到SQL Server实例。
There are fact and dimension tables in the sample database. However, we will be using the below-listed views predominantly here.
示例数据库中有事实和维度表。 但是,这里我们将主要使用下面列出的视图。
During the article series, we will look at these views in detail.
在本系列文章中,我们将详细介绍这些视图。
数据挖掘项目 (Data Mining Project)
Let us create a data mining project. Open Microsoft Visual Studio and create a Multidimensional project under Analysis Service and select Analysis Services Multidimensional and Data Mining project. Following is the Solution Explorer for the created project.
让我们创建一个数据挖掘项目。 打开Microsoft Visual Studio并在Analysis Service下创建一个多维项目,然后选择Analysis Services多维和数据挖掘项目。 以下是创建的项目的解决方案资源管理器 。
For data mining, we will be using three nodes, Data Sources, Data Source Views, and Data Mining.
对于数据挖掘,我们将使用三个节点: 数据源,数据源视图和数据挖掘。
数据源 (Data Sources)
We need to configure the data source to the project as shown below. The data source makes a connection to the sample database, AdventureWorksDW2017.
我们需要为项目配置数据源,如下所示。 数据源连接到示例数据库AdventureWorksDW2017。
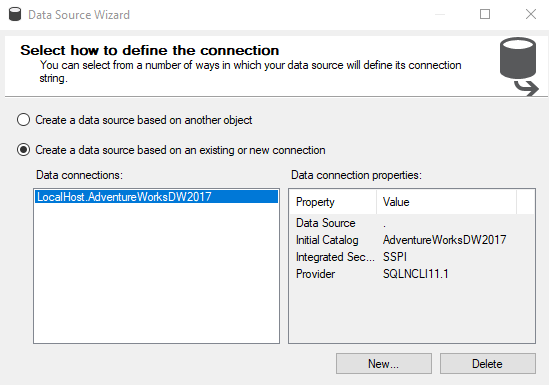
After providing the credential to the source database, next is to provide the credentials to the Analysis service to connect to the database.
在将凭证提供给源数据库之后,接下来是将凭证提供给Analysis服务以连接到数据库。
Analysis service will be used to store the data mining models and analysis service only use windows authentication. Any of the four options can be used to provide the necessary connection.
分析服务将用于存储数据挖掘模型,而分析服务仅使用Windows身份验证。 四个选项中的任何一个都可以用来提供必要的连接。
With this, you have configured the data source to the project and of course, you can modify them later. Also, you can create multiple sources for a project.
这样,您就为项目配置了数据源,当然,您以后可以修改它们。 另外,您可以为一个项目创建多个源。
数据源视图 (Data Source View)
Next step is to select a data source view. The data source view is a subset of the tables or views. Since you might not require all the tables and views for the project, from the data source view, you can choose the needed objects.
下一步是选择数据源视图。 数据源视图是表或视图的子集。 由于您可能不需要项目的所有表和视图,因此可以从数据源视图中选择所需的对象。
There should be one selected data source for a given data source view. Though you can create multiple data sources, you can attach only data source for one data source view. Also, if you haven’t created a data source before, from the Data Source View wizard, you can create the data source.
对于给定的数据源视图,应该有一个选定的数据源。 尽管可以创建多个数据源,但是对于一个数据源视图,只能附加数据源。 另外,如果您之前从未创建过数据源,则可以从“ 数据源视图”向导中创建数据源。
In the data source view, you can select the objects you need from the available objects. You can filter the objects. If you have selected tables that have foreign key constraints, you can automatically select the related tables by selecting Add Related Table.
在数据源视图中,可以从可用对象中选择所需的对象。 您可以过滤对象。 如果选择了具有外键约束的表,则可以通过选择“ 添加相关表”来自动选择相关表。
Similar to the data sources, you can create multiple data source views. However, you can have only one data source for a given data source view.
与数据源类似,您可以创建多个数据源视图。 但是,一个给定的数据源视图只能有一个数据源。
数据挖掘 (Data Mining)
Now you have done the basic setup to start the data mining project. Next is to create a data mining project. Similar to other configurations, data mining structure creation will be done with the help of a wizard.
现在,您已完成基本设置以启动数据挖掘项目。 接下来是创建一个数据挖掘项目。 与其他配置类似,将在向导的帮助下完成数据挖掘结构的创建。
The following will be the wizard for the data mining model creation.
以下将是创建数据挖掘模型的向导。
In the above dialog box, there are two types of sources, whether it is from a relational database or an OLAP cube.
在上面的对话框中,有两种类型的源,无论是来自关系数据库还是来自OLAP多维数据集。
Next, the technique or algorithm is selected.
接下来,选择技术或算法。
Nine data mining algorithms are supported in the SQL Server which is the most popular algorithm. However, you would have noticed that there is a Microsoft prefix for all the algorithms which means that there can be slight deviations or additions to the well-known algorithms.
SQL Server支持9种数据挖掘算法,这是最流行的算法。 但是,您可能已经注意到,所有算法都有一个Microsoft前缀,这意味着众所周知的算法可能会有一些偏差或增加。
The next correct data source view should be selected from which you have created before.
应该从之前创建的下一个正确的数据源视图中进行选择。
Next is to choose the Case and Nested options. The case table is the table that contains entities to analyze and the nested table is the table that contains additional information about the case.
接下来是选择“案例”和“嵌套”选项。 案例表是包含要分析的实体的表,嵌套表是包含有关案例的其他信息的表。
Sometimes, you do not need all the attributes for the purposes. For example, customer address attributes do not make any sense to appear as an impacted attribute for the final decision. From the following screen, you can select only the attributes that you would think will make an impact.
有时,您不需要所有属性即可。 例如,客户地址属性毫无意义地显示为最终决策的受影响属性。 在以下屏幕中,您只能选择您认为会产生影响的属性。
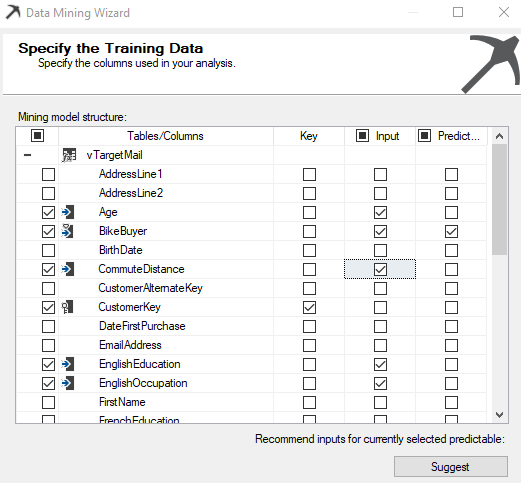
In the above screenshot, Customer Key is the key column while Age, Bike Buyer, Commute Distance, Education, and Occupation are the inputs to predict whether a Bike Buyer or not.
在上面的屏幕截图中,“客户密钥”是关键列,而“年龄”,“自行车购买者”,“通勤距离”,“教育程度”和“职业”是输入,以预测是否是“自行车购买者”。
If you don’t have any clue about your data set, you can use the Suggest button and get some idea about the key impacted attributes.
如果您对数据集一无所知,则可以使用“建议”按钮并获得有关关键影响属性的一些信息。
In the next screen, Content-Type and Data types are listed and users can modify them if needed.
在下一个屏幕中,列出了Content-Type和Data类型,用户可以根据需要对其进行修改。
Some algorithms will not be working with some content type. For example, Microsoft Naïve Bayes will not be possible if you have selected a Continuous content type.
某些算法不适用于某些内容类型。 例如,如果您选择了“连续”内容类型,将无法使用MicrosoftNaïveBayes。
There are five types of Content-Type such as Continuous, Cyclical, Discrete, Discretized and Ordered. Discrete data can take only integer values whereas continuous data can take any value. For instance, the number of patients treated by a hospital each year is discrete whereas hospital income is continuous. Discretization means transferring continuous variables into discrete variables.
内容类型有五种类型,例如连续,循环,离散,离散和有序。 离散数据只能采用整数值,而连续数据可以采用任何值。 例如,医院每年接受治疗的患者人数是离散的,而医院的收入却是连续的。 离散化意味着将连续变量转换为离散变量。
Whenever the data mining model is created, it is always important to test your model with a valid data set. Train data set will be used to train the model while the test data set is used to test the built model. The following screen will show how to configure test and train data set.
每当创建数据挖掘模型时,使用有效的数据集测试模型始终很重要。 训练数据集将用于训练模型,而测试数据集用于测试构建的模型。 以下屏幕将显示如何配置测试和训练数据集。
Typically 70/30 is the split for train/test data set. Input data will be randomly split into two sets, a training set and a testing set, based on the percentage of data for testing and a maximum number of cases in testing data set you to provide. The training set is used to create the mining model. The testing set is used to check model accuracy.
通常,火车/测试数据集是70/30。 根据要测试的数据百分比和要提供的测试数据集中的最大案例数,输入数据将随机分为两组,即训练集和测试集。 训练集用于创建挖掘模型。 测试集用于检查模型的准确性。
The percentage of data for testing specifies percentages of cases reserved for the testing set. The Maximum number of cases in testing data set limits the total number of cases in the testing set. If both values are specified, both limits are enforced.
用于测试的数据百分比指定为测试集保留的案例的百分比。 测试数据集中的最大案例数限制了测试集中的案例总数。 如果同时指定了两个值,则将同时执行两个限制。
模型处理 (Model Processing)
After the data Mining model is created, it has to be processed. We will discuss the processing option in a separate article. However, for the moment let us say, processing the data mining model will deploy the data mining model to the SQL Server Analysis Service so that end users can consume the data mining model.
创建数据挖掘模型后,必须对其进行处理。 我们将在另一篇文章中讨论处理选项。 但是,就目前而言,处理数据挖掘模型会将数据挖掘模型部署到SQL Server Analysis Service,以便最终用户可以使用数据挖掘模型。
Once the model is processed, it will be shown as follows.
处理完模型后,将显示如下。
Once the model is processed it is ready, next is to consume the data mining model.
处理完模型后,就可以使用数据挖掘模型了。
挖掘模型视图 (Mining Model Views)
After the model is created, the next is to visualize the model. There are five tabs to views these models. There are Mining Structure, Mining Models, Mining Model Views, Mining Accuracy chart, and Mining Model Prediction.
创建模型后,接下来是可视化模型。 有五个选项卡可查看这些模型。 有挖掘结构,挖掘模型,挖掘模型视图,挖掘精度图表和挖掘模型预测。
Most of the tabs are relevant to the Data Mining algorithms that were selected before. Therefore, that discussion will be saved for incoming articles. Mining Model tab is common for all the other mining algorithms.
大多数选项卡与之前选择的数据挖掘算法有关。 因此,该讨论将保存为传入文章。 “挖掘模型”选项卡在所有其他挖掘算法中通用。
There can be multiple mining models in this tab.
此选项卡中可以有多个挖掘模型。
As we know, prediction can go wrong. However, we need to know what is the accuracy level of the data mining model that we provide. Accuracy chart will provide you multiple options to measure the accuracy of the model that you built, which will be discussed in a separate article.
众所周知,预测可能会出错。 但是,我们需要知道我们提供的数据挖掘模型的准确度是多少。 精度图表将为您提供多个选项来衡量所构建模型的精度,这将在另一篇文章中进行讨论。
下一步是什么 (What’s Next)
I hope this article helped you gain some basic understanding of data mining. If you are willing to join the journey to learn data mining with SQL Server, setup the environment and get your hand dirty with this, stay tuned to explore Microsoft Naive Bayes algorithm in my next article on SQLShack.
我希望本文能帮助您对数据挖掘有一些基本的了解。 如果您愿意参加学习使用SQL Server进行数据挖掘,设置环境并为此而烦恼的旅程,请继续关注我的下一篇关于SQLShack的文章 ,以探索Microsoft Naive Bayes算法。
目录 (Table of contents)
| Introduction to SQL Server Data Mining |
| Naive Bayes Prediction in SQL Server |
| Microsoft Decision Trees in SQL Server |
| Microsoft Time Series in SQL Server |
| Association Rule Mining in SQL Server |
| Microsoft Clustering in SQL Server |
| Microsoft Linear Regression in SQL Server |
| Implement Artificial Neural Networks (ANNs) in SQL Server |
| Implementing Sequence Clustering in SQL Server |
| Measuring the Accuracy in Data Mining in SQL Server |
| Data Mining Query in SSIS |
| Text Mining in SQL Server |
| SQL Server数据挖掘简介 |
| SQL Server中的朴素贝叶斯预测 |
| SQL Server中的Microsoft决策树 |
| SQL Server中的Microsoft时间序列 |
| SQL Server中的关联规则挖掘 |
| SQL Server中的Microsoft群集 |
| SQL Server中的Microsoft线性回归 |
| 在SQL Server中实现人工神经网络(ANN) |
| 在SQL Server中实现序列聚类 |
| 在SQL Server中测量数据挖掘的准确性 |
| SSIS中的数据挖掘查询 |
| SQL Server中的文本挖掘 |
翻译自: https://www.sqlshack.com/introduction-to-sql-server-data-mining/
SQL Server数据挖掘简介相关推荐
- 第三篇——第二部分——第一文 SQL Server镜像简介
原文: 第三篇--第二部分--第一文 SQL Server镜像简介 原文出处:http://blog.csdn.net/dba_huangzj/article/details/26951563 镜像是 ...
- sql server 循环_学习SQL:SQL Server循环简介
sql server 循环 Loops are one of the most basic, still very powerful concepts in programming – the sam ...
- SQL Server 数据挖掘在企业中的应用
SQL Server 数据挖掘在企业中的应用 作者: IT168 陈亮 2009-02-17 网友评论 2 条 [IT168 专稿] 什么是数据挖掘? 对于数据挖掘有两个常见的误区,一个是认 ...
- SQL Server商业智能–简介
BL的负担 (What a load of Bl-) 您可能想知道什么是商业智能. 如果您正在阅读本文,则您可能具有Microsoft SQL Server或至少一个其他关系数据库管理系统(RDBMS ...
- SQL Server数据挖掘–如何将数据转化为有价值的信息
介绍 (Introduction) In a past chat back in January 2015, we started looking at the fantastic suite of ...
- 第一文 SQL Server镜像简介
原文出处:http://blog.csdn.net/dba_huangzj/article/details/26951563 镜像是什么?说白了就是个镜子(没用过镜子?没镜子你总要小便吧?开个玩笑.. ...
- SQL Server数据库简介
一.系统数据库 SQL Server有5个系统数据库. 1.master数据库 Master数据库是主系统数据库,记录了所有系统级信息(登录账户.端点.链接服务器.系统配置设备.其他数据库信息).ma ...
- sql server序列_SQL Server中的Microsoft时间序列
sql server序列 The next topic in our Data Mining series is the popular algorithm, Time Series. Since b ...
- sql server 关联_SQL Server中的关联规则挖掘
sql server 关联 Association Rule Mining in SQL Server is the next article in our data mining article s ...
最新文章
- R语言数值累加函数cumsum实战
- mysql中find_in_set_mysql中find_in_set()函数的使用详解
- 博客园T恤PP泄漏版(附图)
- 导入Excel表里的数据时产生【定义了过多字段】,但有时又是成功的
- 复调制细化分析matlab,基于复调制的细化全矢谱分析研究
- OCS (错误代码: 0-1-492)
- 10+知识图谱开放下载,让你的学习效率提升5倍! | “右脑”开发套餐
- 1.4编程基础之逻辑表达式与条件分支 18 点和正方形的关系
- 【Siddhi】Flink Siddhi房间温度上升5度报警案例
- MimeType文件格式速查表
- 把prn文件输出到网络打印机
- VTK点云数据如何导入MeshLab
- 计算机cpu温度显示原理,电脑cpu温度怎么看
- maya如何查看资源大纲_干货|Maya入门到精通完全自学教程大纲(建模篇)
- TheChroniclesOfNarnia写作年代
- 100个深度图像分割算法,纽约大学UCLA等最新综述论文
- wifi网络为什么总是断线 (by quqi99)
- 35 - 用正则表达式分别提取电话号的区号、电话号和分机号
- 邮件营销(群发邮件)
- html+css模仿微信主页面