【转载】数据挖掘中所需的概率论与数理统计知识
【转载】数据挖掘中所需的概率论与数理统计知识
(关键词:微积分、概率分布、期望、方差、协方差、数理统计简史、大数定律、中心极限定理、正态分布) https://blog.csdn.net/zbj366112/article/details/62221293?locationNum=2&fps=1
导言:本文从微积分相关概念,梳理到概率论与数理统计中的相关知识,但本文之压轴戏在本文第4节(彻底颠覆以前读书时大学课本灌输给你的观念,一探正态分布之神秘芳踪,知晓其前后发明历史由来),相信,每一个学过概率论与数理统计的朋友都有必要了解数理统计学简史,因为,只有了解各个定理.公式的发明历史,演进历程.相关联系,才能更好的理解你眼前所见到的知识,才能更好的运用之。
- 第一节、介绍微积分中极限、导数,微分、积分等相关概念;
- 第二节、介绍随机变量及其分布;
- 第三节、介绍数学期望.方差.协方差.相关系数.中心极限定理等概念;
- 第四节、依据数理统计学简史介绍正态分布的前后由来;
- 第五节、论道正态,介绍正态分布的4大数学推导。
5部分起承转合,彼此依托,层层递进。且在本文中,会出现诸多并不友好的大量各种公式,但基本的概念.定理是任何复杂问题的根基,所以,你我都有必要硬着头皮好好细细阅读。最后,本文若有任何问题或错误,恳请广大读者朋友们不吝批评指正,谢谢。
第一节、微积分的基本概念
开头前言说,微积分是概数统计基础,概数统计则是DM&ML之必修课”,是有一定根据的,包括后续数理统计当中,如正态分布的概率密度函数中用到了相关定积分的知识,包括最小二乘法问题的相关探讨求证都用到了求偏导数的等概念,这些都是跟微积分相关的知识。故咱们第一节先复习下微积分的相关基本概念。
事实上,古代数学中,单单无穷小、无穷大的概念就讨论了近200年,而后才由无限发展到极限的概念。
1.1、极限
极限又分为两部分:数列的极限和函数的极限。
1.1.1、数列的极限
定义 如果数列{xn}与常a 有下列关系:对于任意给定的正数e (不论它多么小), 总存在正整数N , 使得对于n >N 时的一切xn, 不等式 |xn-a |<e都成立, 则称常数a 是数列{xn}的极限, 或者称数列{xn}收敛于a , 记为
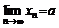 或
或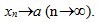
也就是说,
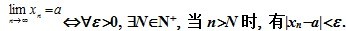
1.1.2、函数的极限
设函数f(x)在点x0的某一去心邻域内有定义. 如果存在常数A, 对于任意给定的正数e (不论它多么小), 总存在正数d, 使得当x满足不等式0<|x-x0|<d 时, 对应的函数值f(x)都满足不等式 |f(x)-A|<e , 那么常数A就叫做函数f(x)时
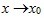 的极限, 记为
的极限, 记为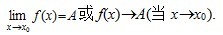
也就是说,
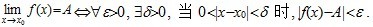
几乎没有一门新的数学分支是某个人单独的成果,如笛卡儿和费马的解析几何不仅仅是他们两人研究的成果,而是若干数学思潮在16世纪和17世纪汇合的产物,是由许许多多的学者共同努力而成。
甚至微积分的发展也不是牛顿与莱布尼茨两人之功。在17世纪下半叶,数学史上出现了无穷小的概念,而后才发展到极限,到后来的微积分的提出。然就算牛顿和莱布尼茨提出了微积分,但微积分的概念尚模糊不清,在牛顿和莱布尼茨之后,后续经过一个多世纪的发展,诸多学者的努力,才真正清晰了微积分的概念。
也就是说,从无穷小到极限,再到微积分定义的真正确立,经历了几代人几个世纪的努力,而课本上所呈现的永远只是冰山一角。
1.2、导数
设有定义域和取值都在实数域中的函数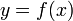 。若
。若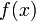 在点
在点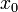 的某个邻域内有定义,则当自变量
的某个邻域内有定义,则当自变量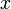 在处取得增量
在处取得增量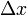 (点
(点 仍在该邻域内)时,相应地函数
仍在该邻域内)时,相应地函数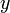 取得增量
取得增量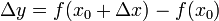 ;如果
;如果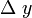 与之比当
与之比当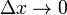 时的极限存在,则称函数
时的极限存在,则称函数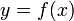 在点处可导,并称这个极限为函数在点处的导数,记为
在点处可导,并称这个极限为函数在点处的导数,记为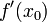 。
即:
。
即: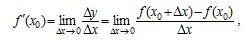
也可记为:
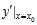 ,
,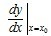 或
或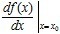 。
。1.3、微分
设函数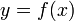 在某区间
在某区间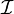 内有定义。对于内一点
内有定义。对于内一点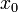 ,当变动到附近的
,当变动到附近的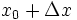 (也在此区间内)时。如果函数的增量
(也在此区间内)时。如果函数的增量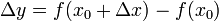 可表示为
可表示为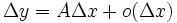 (其中
(其中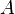 是不依赖于
是不依赖于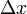 的常数),而
的常数),而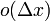 是比
是比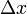 高阶的无穷小,那么称函数
高阶的无穷小,那么称函数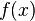 在点是可微的,且
在点是可微的,且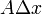 称作函数在点相应于自变量增量的微分,记作
称作函数在点相应于自变量增量的微分,记作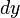 ,即
,即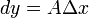 ,是
,是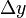 的线性主部。通常把自变量
的线性主部。通常把自变量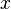 的增量称为自变量的微分,记作
的增量称为自变量的微分,记作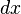 ,即
,即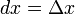 。
实际上,前面讲了导数,而微积分则是在导数的基础上加个后缀,即为:
。
实际上,前面讲了导数,而微积分则是在导数的基础上加个后缀,即为: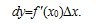 。
。
1.4、积分
积分是微积分学与数学分析里的一个核心概念。通常分为定积分和不定积分两种。不定积分的定义一个函数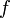 的不定积分,也称为原函数或反导数,是一个导数等于的函数
的不定积分,也称为原函数或反导数,是一个导数等于的函数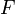 ,即
,即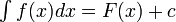 不定积分的有换元积分法,分部积分法等求法。定积分的定义直观地说,对于一个给定的正实值函数
不定积分的有换元积分法,分部积分法等求法。定积分的定义直观地说,对于一个给定的正实值函数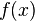 ,在一个实数区间
,在一个实数区间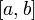 上的定积分
上的定积分:
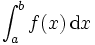 定积分与不定积分区别在于不定积分便是不给定区间,也就是说,上式子中,积分符号没有a、b。下面,介绍定积分中值定理。如果函数f(x)在闭区间[a,b]上连续, 则在积分区间[a,b]上至少存在一个点,
定积分与不定积分区别在于不定积分便是不给定区间,也就是说,上式子中,积分符号没有a、b。下面,介绍定积分中值定理。如果函数f(x)在闭区间[a,b]上连续, 则在积分区间[a,b]上至少存在一个点,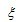 使下式成立:
使下式成立:
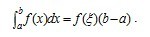 这个公式便叫积分中值公式。牛顿-莱布尼茨公式接下来,咱们讲介绍微积分学中最重要的一个公式:牛顿-莱布尼茨公式。如果函数F (x)是连续函数f(x)在区间[a, b]上的一个原函数, 则
这个公式便叫积分中值公式。牛顿-莱布尼茨公式接下来,咱们讲介绍微积分学中最重要的一个公式:牛顿-莱布尼茨公式。如果函数F (x)是连续函数f(x)在区间[a, b]上的一个原函数, 则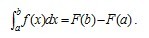 此公式称为牛顿-莱布尼茨公式, 也称为微积分基本公式。这个公式由此便打通了原函数与定积分之间的联系,它表明:一个连续函数在区间[a, b]上的定积分等于它的任一个原函数在区间[a, b]上的增量,如此,便给定积分提供了一个有效而极为简单的计算方法,大大简化了定积分的计算手续。下面,举个例子说明如何通过原函数求取定积分。如要计算
此公式称为牛顿-莱布尼茨公式, 也称为微积分基本公式。这个公式由此便打通了原函数与定积分之间的联系,它表明:一个连续函数在区间[a, b]上的定积分等于它的任一个原函数在区间[a, b]上的增量,如此,便给定积分提供了一个有效而极为简单的计算方法,大大简化了定积分的计算手续。下面,举个例子说明如何通过原函数求取定积分。如要计算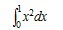 ,由于
,由于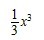 是
是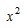 的一个原函数,所以
的一个原函数,所以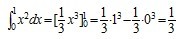 。
。
1.5、偏导数
对于二元函数z = f(x,y) 如果只有自变量x 变化,而自变量y固定 这时它就是x的一元函数,这函数对x的导数,就称为二元函数z = f(x,y)对于x的偏导数。
定义 设函数z = f(x,y)在点(x0,y0)的某一邻域内有定义,当y固定在y0而x在x0处有增量时,相应地函数有增量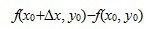 ,
如果极限
,
如果极限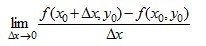 存在,则称此极限为函数z = f(x,y)在点(x0,y0)处对 x 的偏导数,记作:
存在,则称此极限为函数z = f(x,y)在点(x0,y0)处对 x 的偏导数,记作: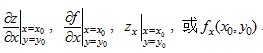 例如
例如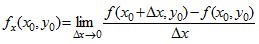 。类似的,二元函数对y求偏导,则把x当做常量。
此外,上述内容只讲了一阶偏导,而有一阶偏导就有二阶偏导,这里只做个简要介绍,具体应用具体分析,或参看高等数学上下册相关内容。接下来,进入本文的主题,从第二节开始。
。类似的,二元函数对y求偏导,则把x当做常量。
此外,上述内容只讲了一阶偏导,而有一阶偏导就有二阶偏导,这里只做个简要介绍,具体应用具体分析,或参看高等数学上下册相关内容。接下来,进入本文的主题,从第二节开始。第二节、离散.连续.多维随机变量及其分布
2.1、几个基本概念点
(一)样本空间
定义:随机试验E的所有结果构成的集合称为E的 样本空间,记为S={e},
称S中的元素e为样本点,一个元素的单点集称为基本事件.(二)条件概率
- 条件概率就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。
- 联合概率表示两个事件共同发生的概率。A与B的联合概率表示为
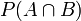 或者
或者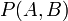 。
。 - 边缘概率是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
在同一个样本空间Ω中的事件或者子集A与B,如果随机从Ω中选出的一个元素属于B,那么这个随机选择的元素还属于A的概率就定义为在B的前提下A的条件概率。从这个定义中,我们可以得出P(A|B) = |A∩B|/|B|分子、分母都除以|Ω|得到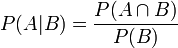 有时候也称为后验概率。同时,P(A|B)与P(B|A)的关系如下所示:
有时候也称为后验概率。同时,P(A|B)与P(B|A)的关系如下所示: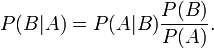 。
。(三)全概率公式和贝叶斯公式
1、全概率公式假设{ Bn : n = 1, 2, 3, … } 是一个概率空间的有限或者可数无限的分割,且每个集合Bn是一个可测集合,则对任意事件A有全概率公式: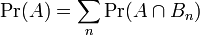 又因为
又因为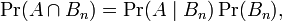 所以,此处Pr(A | B)是B发生后A的条件概率,所以全概率公式又可写作:
所以,此处Pr(A | B)是B发生后A的条件概率,所以全概率公式又可写作: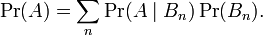 在离散情况下,上述公式等于下面这个公式:
在离散情况下,上述公式等于下面这个公式: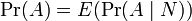 。但后者在连续情况下仍然成立:此处N是任意随机变量。这个公式还可以表达为:”A的先验概率等于A的后验概率的先验期望值。
2、贝叶斯公式贝叶斯定理(Bayes’ theorem),是概率论中的一个结果,它跟随机变量的条件概率以及边缘概率分布有关。在有些关于概率的解说中,贝叶斯定理(贝叶斯更新)能够告知我们如何利用新证据修改已有的看法。
。但后者在连续情况下仍然成立:此处N是任意随机变量。这个公式还可以表达为:”A的先验概率等于A的后验概率的先验期望值。
2、贝叶斯公式贝叶斯定理(Bayes’ theorem),是概率论中的一个结果,它跟随机变量的条件概率以及边缘概率分布有关。在有些关于概率的解说中,贝叶斯定理(贝叶斯更新)能够告知我们如何利用新证据修改已有的看法。
通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯定理就是这种关系的陈述。如此篇blog第二部分所述“据维基百科上的介绍,贝叶斯定理实际上是关于随机事件A和B的条件概率和边缘概率的一则定理。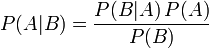
如上所示,其中P(A|B)是在B发生的情况下A发生的可能性。在贝叶斯定理中,每个名词都有约定俗成的名称:
- P(A)是A的先验概率或边缘概率。之所以称为”先验”是因為它不考虑任何B方面的因素。
- P(A|B)是已知B发生后A的条件概率(直白来讲,就是先有B而后=>才有A),也由于得自B的取值而被称作A的后验概率。
- P(B|A)是已知A发生后B的条件概率(直白来讲,就是先有A而后=>才有B),也由于得自A的取值而被称作B的后验概率。
- P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)。
按这些术语,Bayes定理可表述为:后验概率 = (相似度*先验概率)/标准化常量,也就是說,后验概率与先验概率和相似度的乘积成正比。另外,比例P(B|A)/P(B)也有时被称作标准相似度(standardised likelihood),Bayes定理可表述为:后验概率 = 标准相似度*先验概率。”
综上,自此便有了一个问题,如何从从条件概率推导贝叶斯定理呢?根据条件概率的定义,在事件B发生的条件下事件A发生的概率是
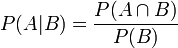
同样地,在事件A发生的条件下事件B发生的概率
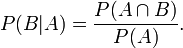
整理与合并这两个方程式,我们可以找到
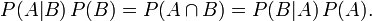
这个引理有时称作概率乘法规则。上式两边同除以P(B),若P(B)是非零的,我们可以得到贝叶斯定理:
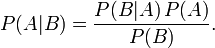
2.2、随机变量及其分布
2.2.1、何谓随机变量
何谓随机变量?即给定样本空间
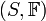 ,其上的实值函数
,其上的实值函数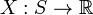 称为(实值)随机变量。如果随机变量
称为(实值)随机变量。如果随机变量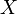 的取值是有限的或者是可数无穷尽的值
的取值是有限的或者是可数无穷尽的值,则称
为离散随机变量(用白话说,此类随机变量是间断的)。
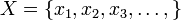 如果由全部实数或者由一部分区间组成,则称为连续随机变量,连续随机变量的值是不可数及无穷尽的(用白话说,此类随机变量是连续的,不间断的):
如果由全部实数或者由一部分区间组成,则称为连续随机变量,连续随机变量的值是不可数及无穷尽的(用白话说,此类随机变量是连续的,不间断的):
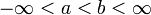
也就是说,随机变量分为离散型随机变量,和连续型随机变量,当要求随机变量的概率分布的时候,要分别处理之,如:
- 针对离散型随机变量而言,一般以加法的形式处理其概率和;
- 而针对连续型随机变量而言,一般以积分形式求其概率和。
再换言之,对离散随机变量用求和得全概率,对连续随机变量用积分得全概率。这点包括在第4节中相关期望.方差.协方差等概念会反复用到,望读者注意之。
2.2.2、离散型随机变量的定义
定义:取值至多可数的随机变量为离散型的随机变量。概率分布(分布律)为 且
且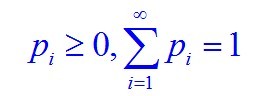
(一)(0-1)分布
若X的分布律为: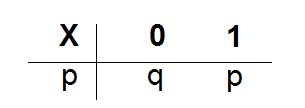 同时,p+q=1,p>0,q>0,则则称X服从参数为p的0-1分布,或两点分布。此外,(0-1)分布的分布律还可表示为:
同时,p+q=1,p>0,q>0,则则称X服从参数为p的0-1分布,或两点分布。此外,(0-1)分布的分布律还可表示为: 或
或 我们常说的抛硬币实验便符合此(0-1)分布。
我们常说的抛硬币实验便符合此(0-1)分布。(二)、二项分布
二项分布是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为p。这样的单次成功/失败试验又称为伯努利试验。举个例子就是,独立重复地抛n次硬币,每次只有两个可能的结果:正面,反面,概率各占1/2。设A在n重贝努利试验中发生X次,则 并称X服从参数为p的二项分布,记为:
并称X服从参数为p的二项分布,记为: 与此同时,
与此同时,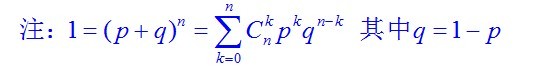
(三)、泊松分布(Poisson分布)
Poisson分布(法语:loi de Poisson,英语:Poisson distribution),即泊松分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。若随机变量X的概率分布律为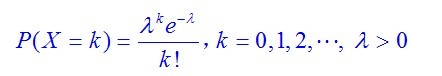 称X服从参数为λ的泊松分布,记为:
称X服从参数为λ的泊松分布,记为: 有一点提前说一下,泊松分布中,其数学期望与方差相等,都为参数λ。泊松分布的来源在二项分布的伯努力试验中,如果试验次数n很大,二项分布的概率p很小,且乘积λ= n p比较适中,则事件出现的次数的概率可以用泊松分布来逼近。事实上,二项分布可以看作泊松分布在离散时间上的对应物。证明如下。首先,回顾e的定义:
有一点提前说一下,泊松分布中,其数学期望与方差相等,都为参数λ。泊松分布的来源在二项分布的伯努力试验中,如果试验次数n很大,二项分布的概率p很小,且乘积λ= n p比较适中,则事件出现的次数的概率可以用泊松分布来逼近。事实上,二项分布可以看作泊松分布在离散时间上的对应物。证明如下。首先,回顾e的定义: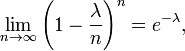 二项分布的定义:
二项分布的定义: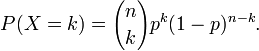 如果令
如果令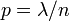 ,
,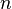 趋于无穷时
趋于无穷时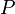
的极限:
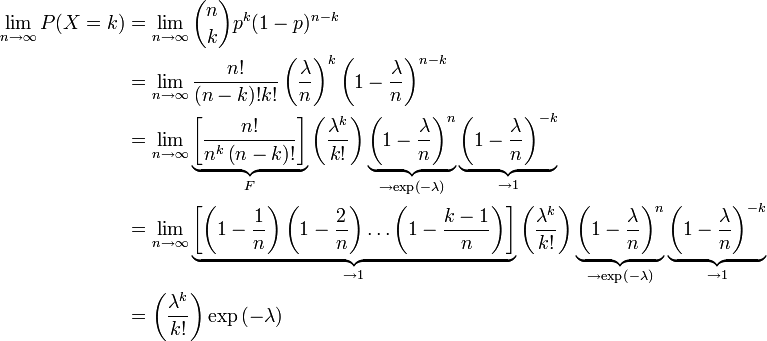 上述过程表明:Poisson(λ) 分布可以看成是二项分布 B(n,p) 在 np=λ,n→∞ 条件下的极限分布。最大似然估计给定n个样本值ki,希望得到从中推测出总体的泊松分布参数λ的估计。为计算最大似然估计值, 列出对数似然函数:
上述过程表明:Poisson(λ) 分布可以看成是二项分布 B(n,p) 在 np=λ,n→∞ 条件下的极限分布。最大似然估计给定n个样本值ki,希望得到从中推测出总体的泊松分布参数λ的估计。为计算最大似然估计值, 列出对数似然函数: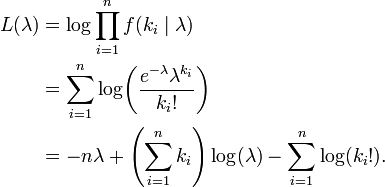
对函数L取相对于λ的导数并令其等于零:
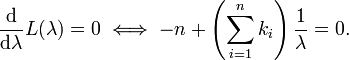 解得λ从而得到一个驻点(stationary point):
解得λ从而得到一个驻点(stationary point):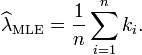 检查函数L的二阶导数,发现对所有的λ 与ki大于零的情况二阶导数都为负。因此求得的驻点是对数似然函数L的极大值点:
检查函数L的二阶导数,发现对所有的λ 与ki大于零的情况二阶导数都为负。因此求得的驻点是对数似然函数L的极大值点: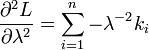 证毕。OK,上面内容都是针对的离散型随机变量,那如何求连续型随机变量的分布律呢?请接着看以下内容。
证毕。OK,上面内容都是针对的离散型随机变量,那如何求连续型随机变量的分布律呢?请接着看以下内容。2.2.3、随机变量分布函数定义的引出
实际中,如上2.2.2节所述,- 对于离散型随机变量而言,其所有可能的取值可以一一列举出来,
- 可对于非离散型随机变量,即连续型随机变量X而言,其所有可能的值则无法一一列举出来,
故连续型随机变量也就不能像离散型随机变量那般可以用分布律来描述它,那怎么办呢(事实上,只有因为连续,所以才可导,所以才可积分,这些东西都是相通的。当然了,连续不一定可导,但可导一定连续)?既然无法研究其全部,那么我们可以转而去研究连续型随机变量所取的值在一个区间(x1,x2] 的概率:P{x1 < X <=x2 },同时注意P{x1 < X <=x2 } = P{X <=x2} - P{X <=x1},故要求P{x1 < X <=x2 } ,我们只需求出P{X <=x2} 和 P{X <=x1} 即可。针对随机变量X,对应变量x,则P(X<=x) 应为x的函数。如此,便引出了分布函数的定义。定义:随机变量X,对任意实数x,称函数F(x) = P(X <=x ) 为X 的概率分布函数,简称分布函数。F(x)的几何意义如下图所示: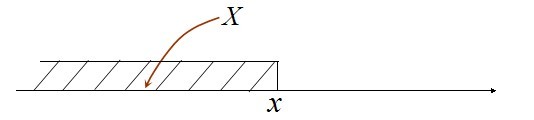 且对于任意实数x1,x2(x1<x2),有P{x1<X<=x2} = P{X <=x2} - P{X <= x1} = F(x2) - F(x1)。同时,F(X)有以下几点性质:
且对于任意实数x1,x2(x1<x2),有P{x1<X<=x2} = P{X <=x2} - P{X <= x1} = F(x2) - F(x1)。同时,F(X)有以下几点性质:
2.2.4、连续型随机变量及其概率密度
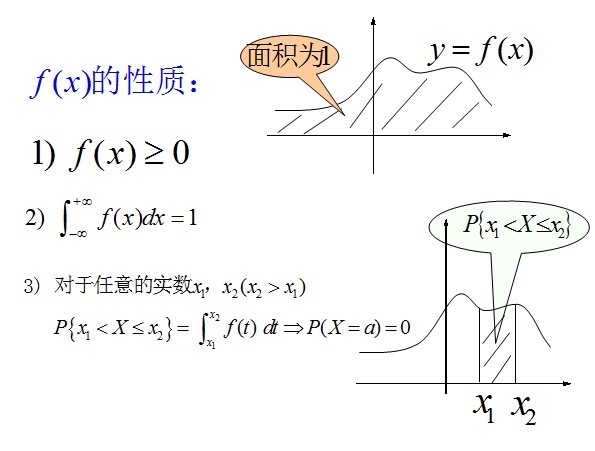
定义:对于随机变量X的分布函数F(x),若存在非负的函数f(x),使对于任意实数x,有: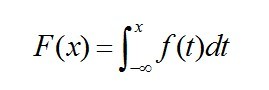 则称X为连续型随机变量,其中f(x)称为X的概率密度函数,简称概率密度。连续型随机变量的概率密度f(x)有如下性质:
则称X为连续型随机变量,其中f(x)称为X的概率密度函数,简称概率密度。连续型随机变量的概率密度f(x)有如下性质: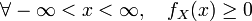 ;
;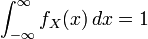 ;
;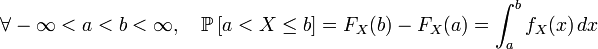
(针对上述第3点性质,我重点说明下:
- 在上文第1.4节中,有此牛顿-莱布尼茨公式:如果函数F (x)是连续函数f(x)在区间[a, b]上的一个原函数, 则;
- 在上文2.2.3节,连续随机变量X 而言,对于任意实数a,b(a<b),有P{a<X<=b} = P{X <=b} - P{X <= a} = F(b) - F(a);
故结合上述两点,便可得出上述性质3)
且如果概率密度函数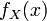 在一点
在一点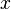 上连续,那么累积分布函数可导,并且它的导数:
上连续,那么累积分布函数可导,并且它的导数: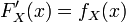 。如下图所示:
。如下图所示:
 接下来,介绍三种连续型随机变量的分布,由于均匀分布及指数分布比较简单,所以,一图以概之,下文会重点介绍正态分布。(一)、均匀分布若连续型随机变量X具有概率密度
接下来,介绍三种连续型随机变量的分布,由于均匀分布及指数分布比较简单,所以,一图以概之,下文会重点介绍正态分布。(一)、均匀分布若连续型随机变量X具有概率密度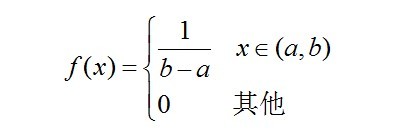 则称X 在区间(a,b)上服从均匀分布,记为X~U(a,b)。
则称X 在区间(a,b)上服从均匀分布,记为X~U(a,b)。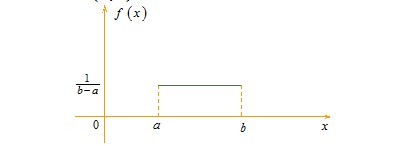 易知,f(x) >= 0,且其期望值为(a + b)/ 2。(二)、指数分布若连续型随机变量X 的概率密度为
易知,f(x) >= 0,且其期望值为(a + b)/ 2。(二)、指数分布若连续型随机变量X 的概率密度为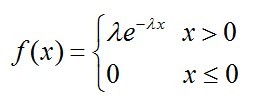 其中λ>0为常数,则称X服从参数为λ的指数分布。记为
其中λ>0为常数,则称X服从参数为λ的指数分布。记为 (三)、正态分布在各种公式纷至沓来之前,我先说一句:正态分布没有你想的那么神秘,它无非是研究误差分布的一个理论,因为实践过程中,测量值和真实值总是存在一定的差异,这个不可避免的差异即误差,而误差的出现或者分布是有规律的,而正态分布不过就是研究误差的分布规律的一个理论。OK,若随机变量
(三)、正态分布在各种公式纷至沓来之前,我先说一句:正态分布没有你想的那么神秘,它无非是研究误差分布的一个理论,因为实践过程中,测量值和真实值总是存在一定的差异,这个不可避免的差异即误差,而误差的出现或者分布是有规律的,而正态分布不过就是研究误差的分布规律的一个理论。OK,若随机变量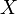 服从一个位置参数为
服从一个位置参数为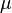 、尺度参数为
、尺度参数为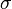 的概率分布,记为:
的概率分布,记为:
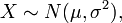 则其概率密度函数为
则其概率密度函数为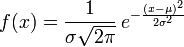 我们便称这样的分布为正态分布或高斯分布,记为:
我们便称这样的分布为正态分布或高斯分布,记为: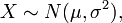 正态分布的数学期望值或期望值等于位置参数,决定了分布的位置;其方差
正态分布的数学期望值或期望值等于位置参数,决定了分布的位置;其方差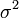 的开平方,即标准差等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。它有以下几点性质,如下图所示:
的开平方,即标准差等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。它有以下几点性质,如下图所示:
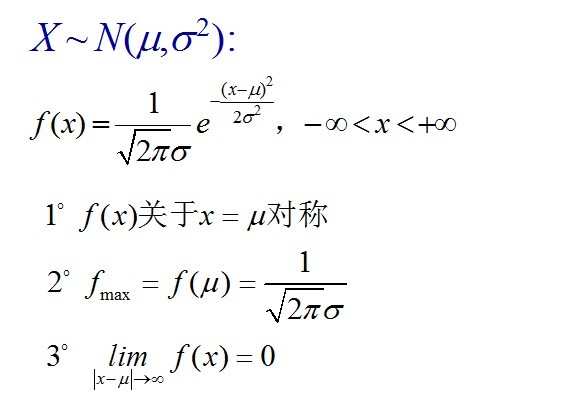 正态分布的概率密度曲线则如下图所示:
正态分布的概率密度曲线则如下图所示: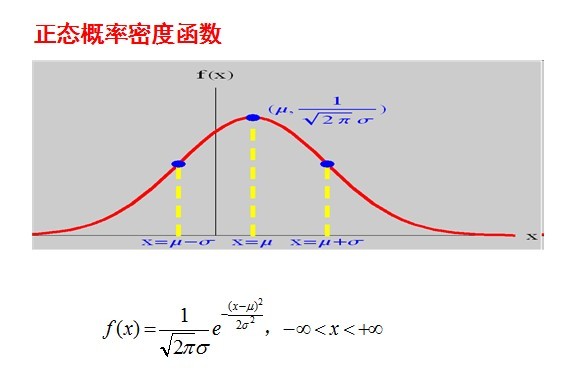 当固定尺度参数,改变位置参数的大小时,f(x)图形的形状不变,只是沿着x轴作平移变换,如下图所示:
当固定尺度参数,改变位置参数的大小时,f(x)图形的形状不变,只是沿着x轴作平移变换,如下图所示:
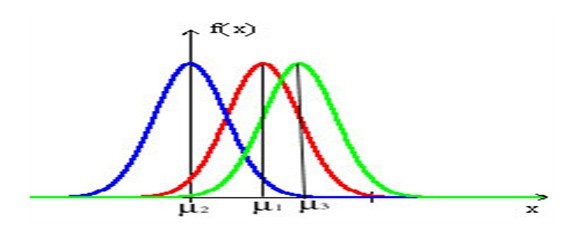 而当固定位置参数,改变尺度参数的大小时,f(x)图形的对称轴不变,形状在改变,越小,图形越高越瘦,越大,图形越矮越胖。如下图所示:
而当固定位置参数,改变尺度参数的大小时,f(x)图形的对称轴不变,形状在改变,越小,图形越高越瘦,越大,图形越矮越胖。如下图所示:
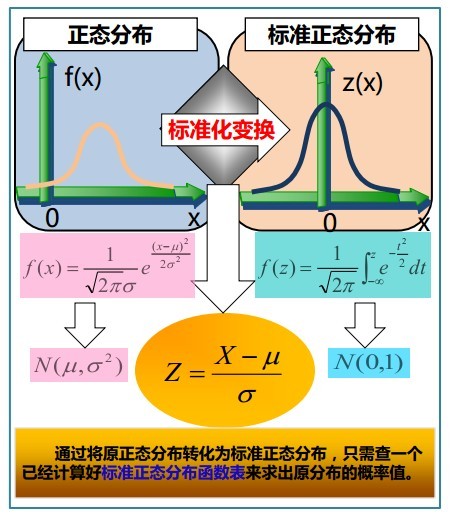
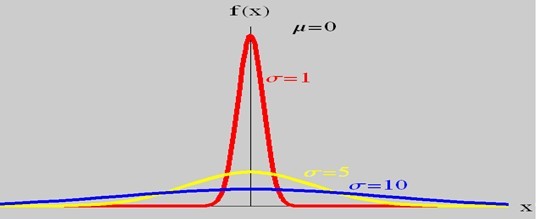 故有咱们上面的结论,在正态分布中,称μ为位置参数(决定对称轴位置),而 σ为尺度参数(决定曲线分散性)。同时,在自然现象和社会现象中,大量随机变量服从或近似服从正态分布。而我们通常所说的标准正态分布是位置参数
故有咱们上面的结论,在正态分布中,称μ为位置参数(决定对称轴位置),而 σ为尺度参数(决定曲线分散性)。同时,在自然现象和社会现象中,大量随机变量服从或近似服从正态分布。而我们通常所说的标准正态分布是位置参数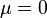 , 尺度参数
, 尺度参数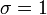 的正态分布,记为:
的正态分布,记为:
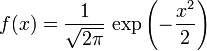 相关内容如下两图总结所示(来源:大嘴巴漫谈数据挖掘):
相关内容如下两图总结所示(来源:大嘴巴漫谈数据挖掘):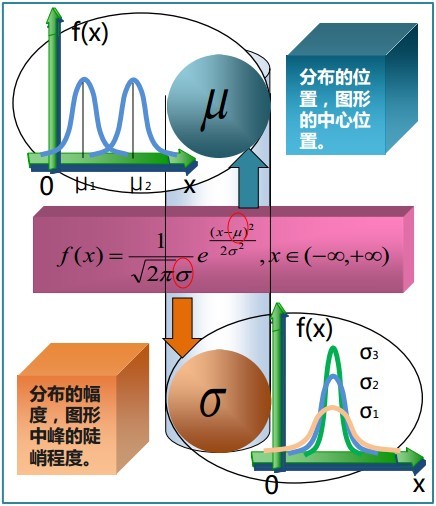
2.2.5、各种分布的比较
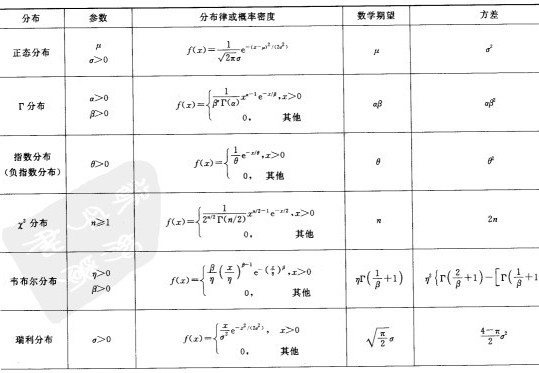
上文中,从离散型随机变量的分布:(0-1)分布、泊松分布、二项分布,讲到了连续型随机变量的分布:均匀分布、指数分布、正态分布,那这么多分布,其各自的期望.方差(期望方差的概念下文将予以介绍)都是多少呢?虽说,还有不少分布上文尚未介绍,不过在此,提前总结下,如下两图所示(摘自盛骤版的概率论与数理统计一书后的附录中):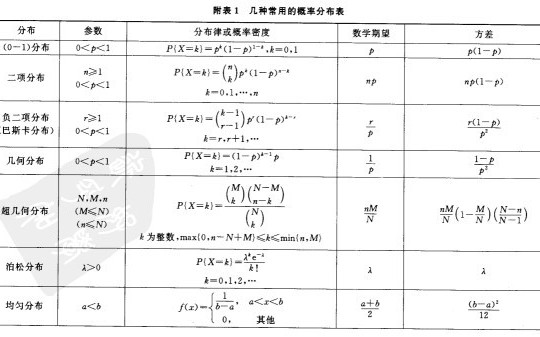
 本文中,二维.多维随机变量及其分布不再论述。
本文中,二维.多维随机变量及其分布不再论述。第三节、从数学期望、方差、协方差到中心极限定理
3.1、数学期望、方差、协方差
3.1.1、数学期望
如果X是在概率空间(Ω, P)中的一个随机变量,那么它的期望值E[X]的定义是: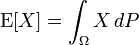 并不是每一个随机变量都有期望值的,因为有的时候这个积分不存在。如果两个随机变量的分布相同,则它们的期望值也相同。在概率论和统计学中,数学期望分两种(依照上文第二节相关内容也可以得出),一种为离散型随机变量的期望值,一种为连续型随机变量的期望值。
并不是每一个随机变量都有期望值的,因为有的时候这个积分不存在。如果两个随机变量的分布相同,则它们的期望值也相同。在概率论和统计学中,数学期望分两种(依照上文第二节相关内容也可以得出),一种为离散型随机变量的期望值,一种为连续型随机变量的期望值。- 一个离散性随机变量的期望值(或数学期望、或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。换句话说,期望值是随机试验在同样的机会下重复多次的结果计算出的等同“期望”的平均值。
例如,掷一枚六面骰子,得到每一面的概率都为1/6,故其的期望值是3.5,计算如下: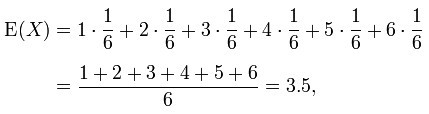 承上,如果X 是一个离散的随机变量,输出值为x1, x2, …, 和输出值相应的概率为p1, p2, …(概率和为1),若级数
承上,如果X 是一个离散的随机变量,输出值为x1, x2, …, 和输出值相应的概率为p1, p2, …(概率和为1),若级数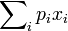 绝对收敛,那么期望值E[X]是一个无限数列的和:
绝对收敛,那么期望值E[X]是一个无限数列的和:
 上面掷骰子的例子就是用这种方法求出期望值的。
上面掷骰子的例子就是用这种方法求出期望值的。- 而对于一个连续型随机变量来说,如果X的概率分布存在一个相应的概率密度函数f(x),若积分
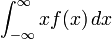 绝对收敛,那么X 的期望值可以计算为:
绝对收敛,那么X 的期望值可以计算为:
 实际上,此连续随机型变量的期望值的求法与离散随机变量的期望值的算法同出一辙,由于输出值是连续的,只不过是把求和改成了积分。
实际上,此连续随机型变量的期望值的求法与离散随机变量的期望值的算法同出一辙,由于输出值是连续的,只不过是把求和改成了积分。3.1.2、方差与标准差
方差在概率论和统计学中,一个随机变量的方差(Variance)描述的是它的离散程度,也就是该变量离其期望值的距离。一个实随机变量的方差也称为它的二阶矩或二阶中心动差,恰巧也是它的二阶累积量。方差的算术平方根称为该随机变量的标准差。其定义为:如果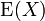 是随机变量X的期望值(平均数) 设
是随机变量X的期望值(平均数) 设为服从分布
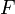
【转载】数据挖掘中所需的概率论与数理统计知识相关推荐
- 数据挖掘中所需的概率论与数理统计知识,上
http://www.cnblogs.com/v-July-v/archive/2012/12/17/3125418.html 数据挖掘中所需的概率论与数理统计知识.上 ( 关键词:微积分.概率分布. ...
- 据挖掘中所需的概率论与数理统计知识
据挖掘中所需的概率论与数理统计知识 ( 关键词:微积分.概率分布.期望.方差.协方差.数理统计简史.大数定律.中心极限定理.正态分布) 导言:本文从微积分相关概念,梳理到概率论与数理统计中的相关知识, ...
- 概率论与数理统计知识
导言:本文从微积分相关概念,梳理到概率论与数理统计中的相关知识,但本文之压轴戏在本文第4节(彻底颠覆以前读书时大学课本灌输给你的观念,一探正态分布之神秘芳踪,知晓其前后发明历史由来),相信,每一个学过 ...
- 概率论与数理统计知识总结——纵向分布式
文章目录 概率论与数理统计知识总结 概率论与数理统计知识总结 泊松分布及其性质 指数分布及其性质 正态分布及其性质 负指数分布及其性质 超几何分布及其性质
- 【个人学习笔记】概率论与数理统计知识梳理【一】
作为一门基础学科,概率论应用太广泛了,由于总有遗忘,翻看教材又太麻烦,于是打算记下笔记与自己的一些思考,参考用书是浙江大学盛骤编写的<概率论与数理统计>. 第一章 概率论的基本概念 一.随 ...
- 自学考试之概率论与数理统计知识框架
看了下软考成绩,上午49,下午51,没有什么意外的话,通过了!其实完全可以考的更好,但当时太紧张了,也没有调整好心态,还是缺乏相应的锻炼!还有一点,基础的东西,还是要再强化一下. 学历的意义在于基础, ...
- 数据挖掘中最容易犯的几个错误,你知道吗?
按照Elder博士的总结,这10大易犯错误包括: 0. 缺乏数据(Lack Data) 1. 太关注训练(Focus on Training) 2. 只依赖一项技术(Rely on One Techn ...
- 深度学习在轨迹数据挖掘中的应用研究综述
深度学习在轨迹数据挖掘中的应用研究综述 人工智能技术与咨询 来源:< 计算机科学与应用> ,作者李旭娟等 关键词: 深度学习:数据挖掘:轨迹挖掘:长短时记忆:序列到序列 摘要: 在过去十年 ...
- 易信推专线电话 通话双方中只需一方安装即可免费通话
上周微信电话本着实火了一把,通话双方都下载此APP并开通免费通话功能就能使用微信电话本拨打免费网络电话.这个相对有些局限性,易信就抓住这一点于昨日高调发布了3.0预览版,新版本首次新增了专线电话功能, ...
最新文章
- mysql优化说明_MySQL性能优化各个参数解释说明
- 如何在后台运行 Linux 命令
- delete if only one note header
- springMVC 相对于 Structs 的优势
- 1056. 组合数的和(15)
- asp.net core 集成 prometheus
- Hadoop之YARN介绍
- Python字符串常用方法(split,partition,maketrans,strip...)
- torch使用cudnn7
- 如日中天的Uber到底是用什么开发语言做到的?
- 此时不应有 \Common
- 【Python基础 | 文件】小实验:将古诗写入一个文件,并复制到另一个文件中
- Android工程中方法数超过65536解决方法
- Turbo Autoencoder: Deep learning based channel code for point-to-point communication channels
- 如何让图片保持原比例,占满整个盒子
- 什么是NETBIOS?
- 操作系统 - Linux - Ubuntu
- Android9 电池优化,Android 9 Pie正式发布!手势操作+优化电池,谷歌“亲儿子”尝...
- Nginx-虚拟主机
- catia过载属性使用方法_catia属性自动提取