怎样成为知乎大V?爬取张佳玮138w+知乎关注者:数据可视化
一、前言
作为简书上第一篇文章,先介绍下小背景,即为什么爬知乎第一大V张公子的138w+关注者信息?
其实之前也写过不少小爬虫,按照网上各种教程实例去练手,“不可避免”的爬过妹子图、爬过豆瓣Top250电影等等;也基于自身的想法,在浙大120周年校庆前,听闻北美帝国大厦首次给大陆学校亮灯,于是爬取2016-2017年官网上每日的亮灯图并用python的PIL库做了几个小logo,算是一名吃瓜群众自发的庆贺行为;(更多照片见于:Deserts-X 我的相册-北美帝国大厦亮灯图:ZJU_120 logo)
https://www.douban.com/photos/photo/2459391373/
北美帝国大厦亮灯图:ZJU120
也因为喜欢鲁迅的作品,爬过在线鲁迅全集的全部文章标题和链接;另外听说太祖的某卷书是禁书,于是顺带也爬了遍毛选;还帮老同学在某票据网站下线前爬了大部分机构、人员信息,说是蛮值钱,然而也还在留着落灰......
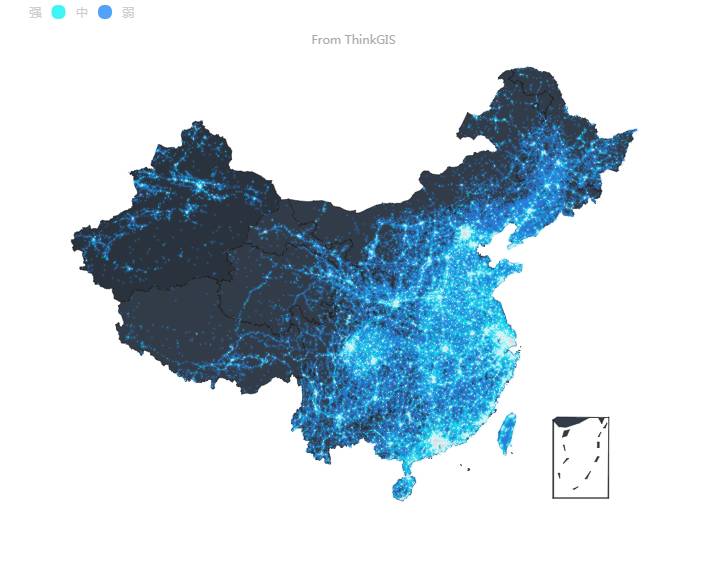
微博签到数据点亮中国
再是知道百度Echarts开源的可视化网站里面的图很酷炫,比如使我着迷的:微博签到数据点亮中国,http://echarts.baidu.com/demo.html#scatter-weibo 于是想着可以爬取微博大明星、小鲜肉的粉丝的居住地,然后搞搞怎么画出全国乃至全球分布情况。但发现几年前微博就限制只能查看200左右粉丝数(具体忘了),蛮扫兴的,于是将目光转向了知乎......
而既然要爬,那就爬关注人数最多的张公子吧,数据量也大,这方面是之前小项目所不及的,此前也看过不少爬知乎数据与分析的文章,因此也想练练手,看看大量访问与获取数据时会不会遇到什么封IP的反爬措施,以及数据可视化能搞成什么样。
不过此文在爬虫部分不做过多展开,看情况后续再另写一文。思路如下:抓包获取张佳玮主页关注者api,然后改变网址中offset参数为20的倍数,一直翻页直到获取138w+关注者信息,其中返回的json数据主要有:关注者的昵称、主页id(即url_token)、性别、签名、被关注人数等,也就是说需要访问所有主页id,才能获取更多信息(个人主页api:以黄继新为例):居住地、所在行业、职业经历、教育经历、获赞数、感谢数、收藏数等等。鉴于还不怎么会多进程爬取,如果把所有id再爬一遍会非常耗时间,于是筛选被关注数100+的id,发现只剩了4.1w+,之后较完整提取了这部分的信息,后续可视化也多基于此。
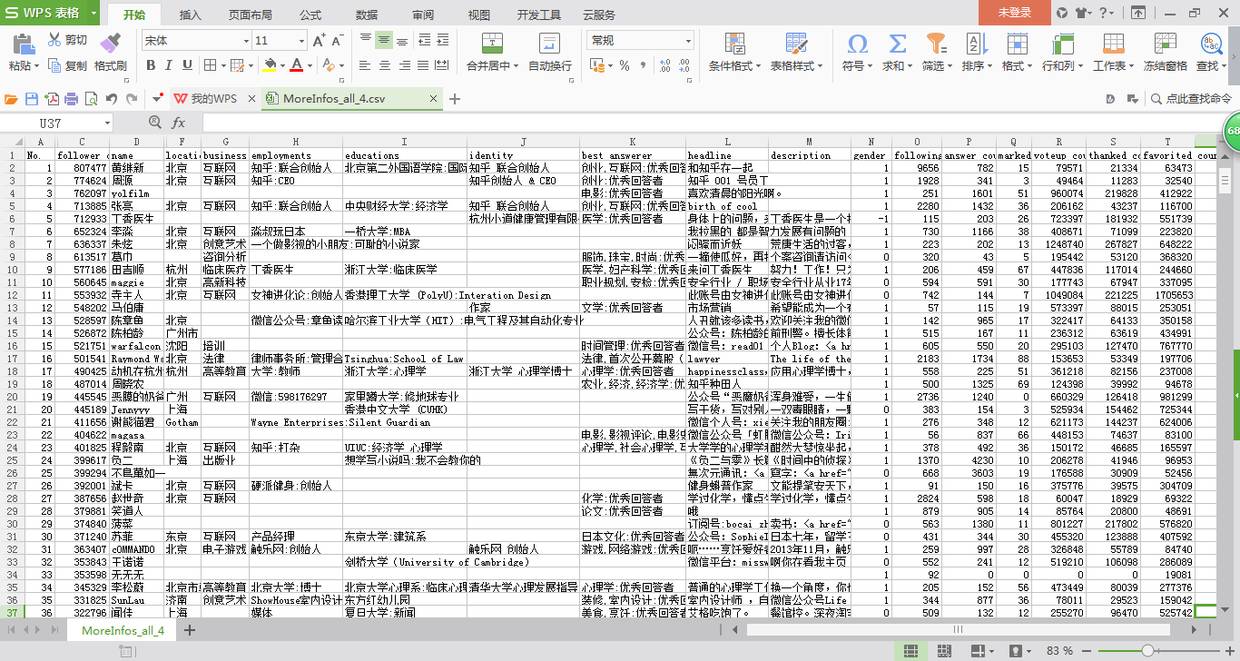
爬取信息一览
二、数据可视化
1、关注人数
大V总是少数的,而小透明到底有多少、分布情况如何呢?将关注人数划分成不同区间,绘制成如下金字塔图:
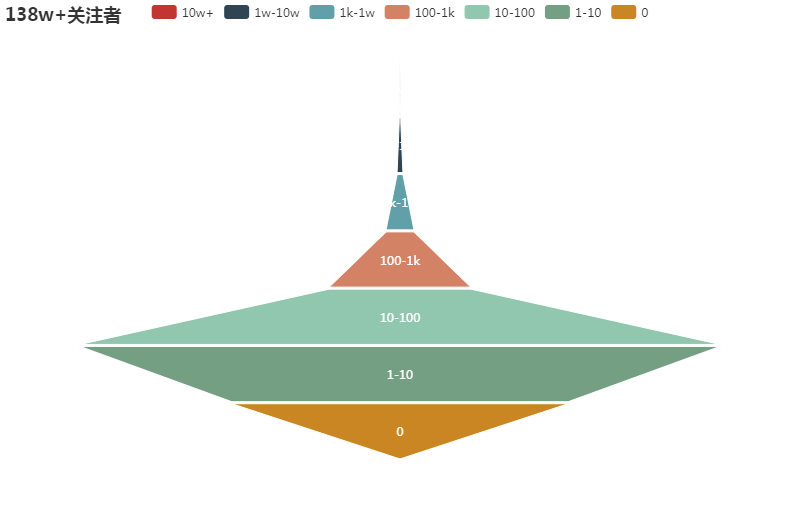
作为一只小透明,在此过程中发现自己处于前2w的位置,即图中红色区域,还是蛮吃惊的。上文已提到100+关注就超过了134w的用户,而1k+、1w+、10w+就越来越接近塔尖,越来越接近张公子的所在,看上图10w+以上的区域,如同高耸入云,渺然不可见,“乱山合沓,空翠爽肌,寂无人行,止有鸟道”,令小透明很是神往。
上升之路虽然崎岖,但也同样说明只要多增几个关注,就胜过了数以万计的用户,这对于有志于成为大V的人,或许能在艰难的前行之路上,靠此数据透露的信息,拾得些许信心。
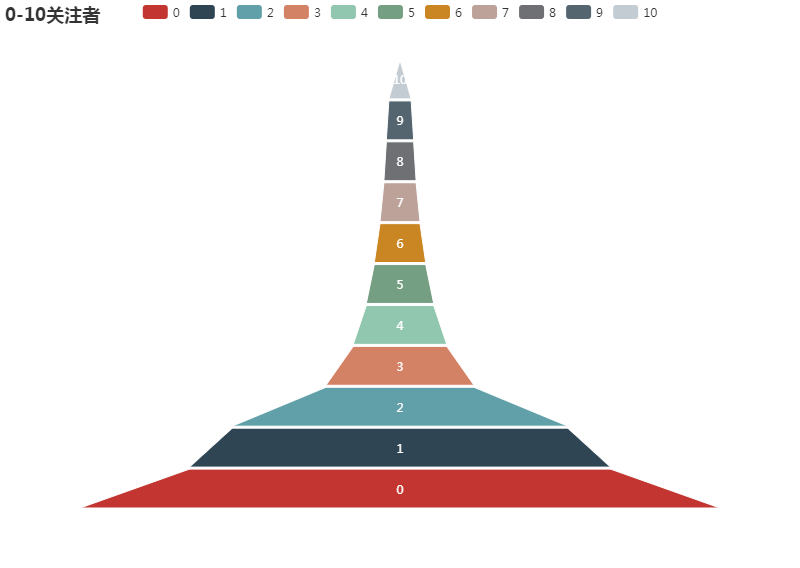
细看底部的区间,0关注有40.2w+,1-10关注有76.6w+,区分度已赫然形成,但小透明可能感受不出,那怕有几百的关注,何尝不会觉得自己依旧是个小透明呢?有谁会相信斩获10人关注,就超过了100w+的用户,数据能告知人经验之外的事实,在此可见一斑。当然知乎大量用户涌入且多数人并不产生优质或有趣的回答,也是一二原因。
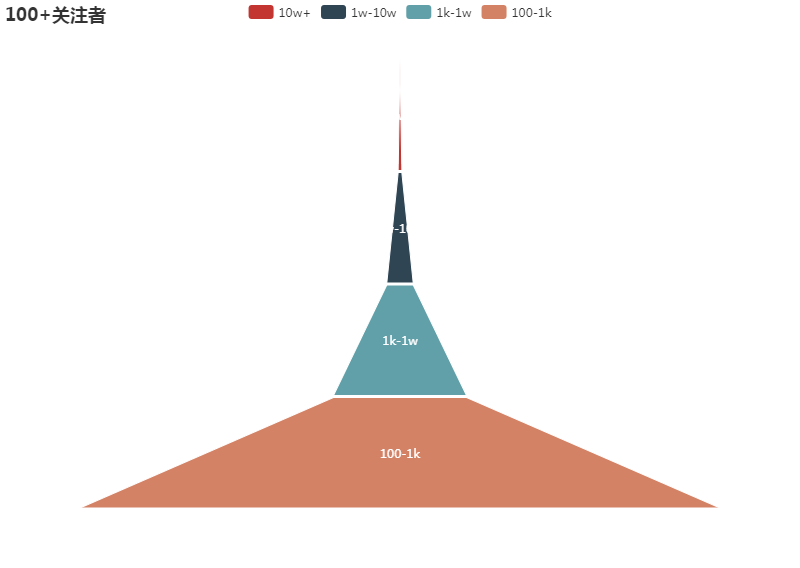
继续看100+以上的数据,底部占比依旧明显,塔尖依然很小。
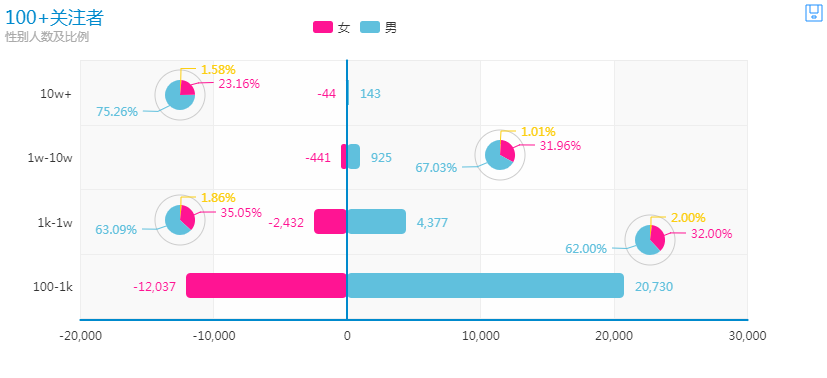
2、性别情况
接着对100+关注人群的性别组成进行分析,发现男女比例基本维持在2:1,与138w+用户的男女比例差别不大。当然10w+关注由于人数较少,比例超过3:1,是否能得出男性在这方面更为优秀就不得而知了。
3、10w+大V
前文已多次提到10w+大V,那么这190人里到底都有谁呢?这里以关注人数为权重,生成词云如下:

大家上知乎的话应该也有关注一些大V,许多名字应该并不陌生,比如马伯庸、动机在杭州、葛巾、朱炫、丁香医生等等,当然也会发现并不是所有大V都关注了张公子,哪怕他是知乎第一人,目前已交出了3026个回答,135个知乎收录回答的傲人成绩(据说也是豆瓣和虎扑第一人)。
4、居住地分布
终于到了我最初开始这个项目时,最想获取的的信息了。虽然由于爬取效率而筛选掉了100关注以下的id共134w,数据量方面不如标题所示的那么多,略有遗憾,但其实真的拿到4.1w+条较优质数据时,发现处理起来也并不容易。
比如这里的居住地信息,有乱填水星、火星、那美克星,也有填国家、省份、县市、街道格式不一的,还有诸如老和山之类外行人不明白的“哑谜”等等,数据之脏令人头疼,且纯文本的数据又不像数字类可以筛选、排序,还没想到好的方式应对。再者Echarts官网虽然有不少可以套用的模板,但有很多地方的经纬度需要重新获取,这样就在数据处理和地图上定位有两处难题需要解决。
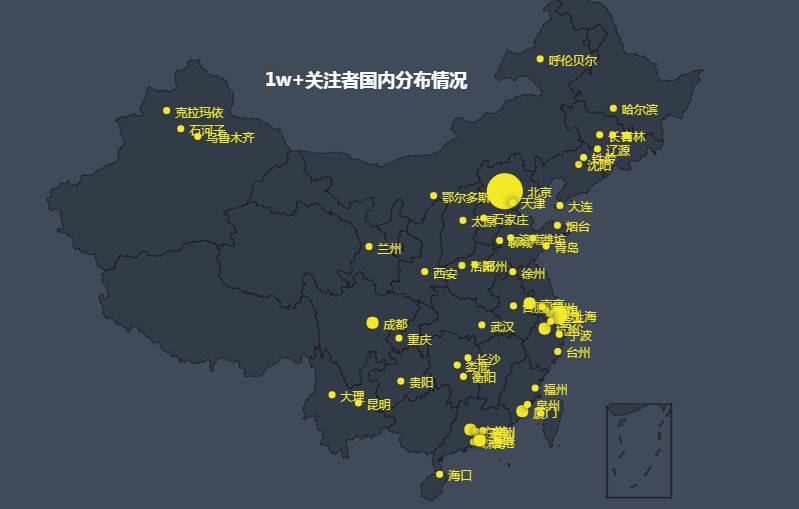
由于第一次处理这类数据并可视化,第一次用Echarts就打算画这个酷炫的地图,因此最终先缩小数据量,还是以1w+大V的数据来可视化,目前先完成国内分布情况,以后看情况再扩大数据量和绘制全球分布情况。
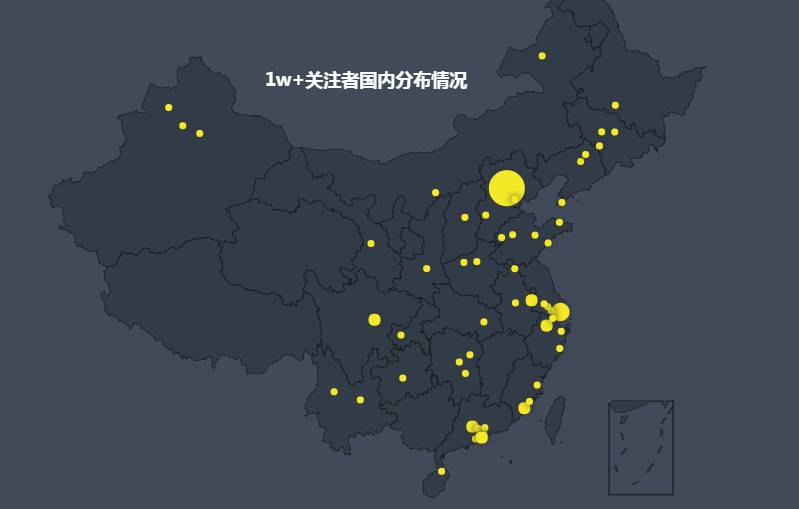
其中出现次数排名前几的城市依次为:北京 360,上海 183,深圳 55,杭州 52,广州 47,成都 26,南京 20......应该算是意料之中的。考虑到并不是每个人对这些点所代表的城市都熟悉,加上城市名,效果如下,重叠较为严重,显示效果不够好,仍需解决。
5、Top20 系列
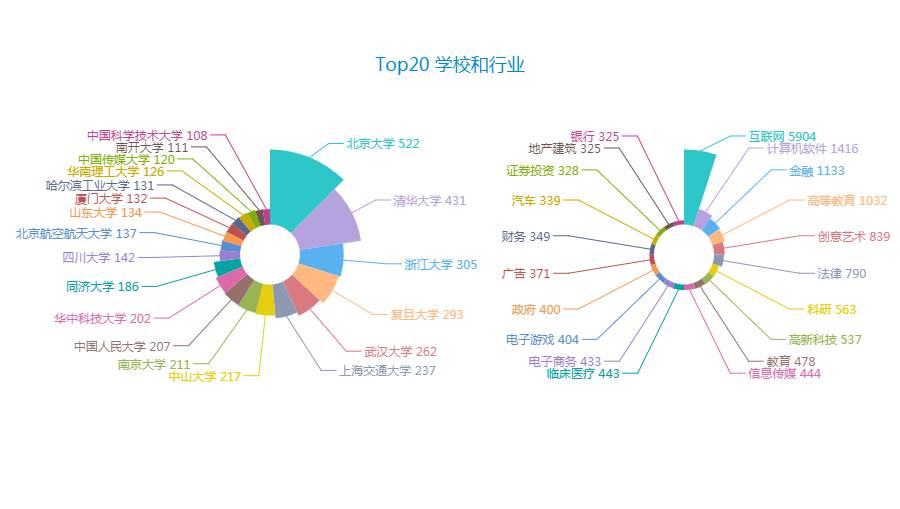
接下来分别对所在行业、职业经历、教育经历等进行分析,结果如下(注:用户有多条职业经历或教育经历的,仅爬取了最新的一条数据):
学校方面几乎全为985、211高校,当然拿得出手的会乐于写上,略微差些的可能不会填写,而且涌入用户多了后,这类数据也就只是调侃知乎人人都是985高校,年薪百万的点了。所在行业方面,互联网遥遥领先,计算机软件、金融、高等教育位居前四。
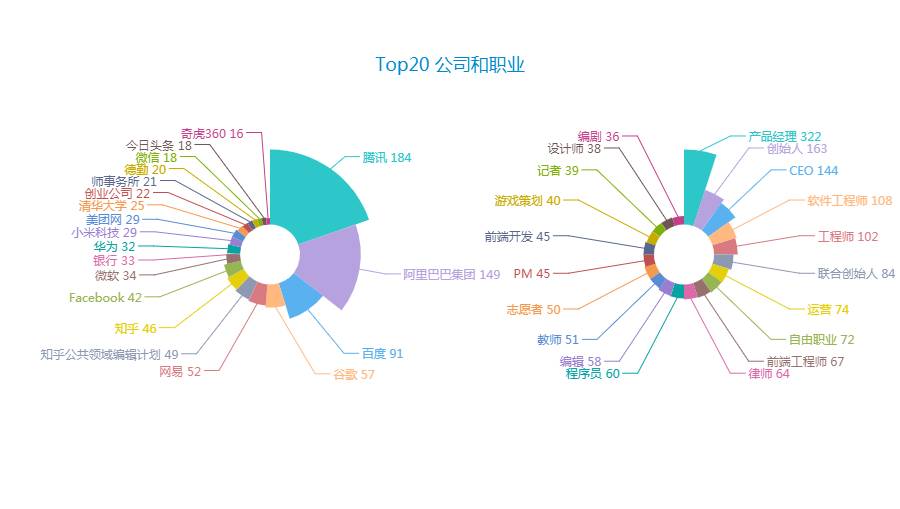
Top20 公司中BAT、网易、华为、小米科技、美团网以及谷歌、Facebook、微软等大厂都悉数在列。再看Top20 职业里除了各种名号的程序员、产品经理、运营等互联网职业,创始人、CEO等占据前排,不可谓不令人大惊从早到晚失色。
6、认证信息
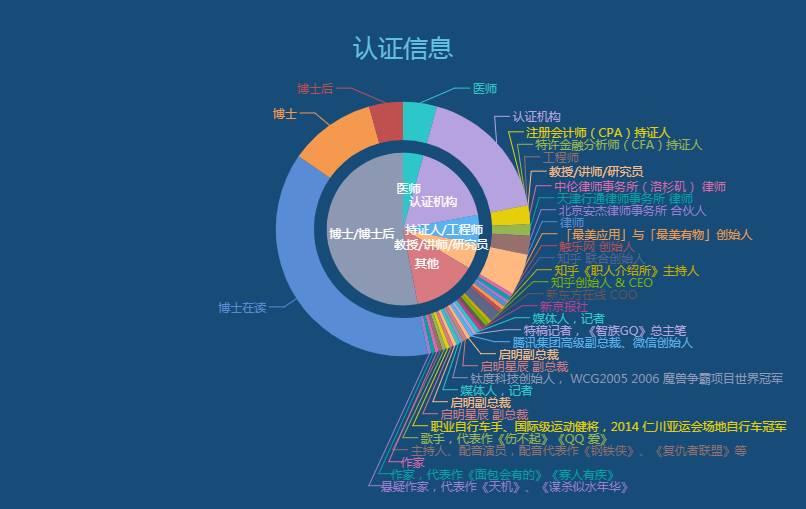
原本只知道博士可以提供信息得到认证,知乎也会给予其回答更好的显示途径,使其更容易成长为大V,以此作为对高学历人群、优质用户的奖励。
此次抓取的100+关注4.1w+条数据中有208条认证信息。除却各种专业的博士、博士后外,还有37家公司、机构,9条医师,11条教授/讲师/研究员,13条CFA、CPA持证人或工程师、建筑师,以及副总裁、创始人、记者、律师、WCG2005-2006魔兽争霸项目世界冠军、职业自行车手、主持人、作家等等。看来还是有不少可以后续去了解下优质用户的。
7、优秀回答者
除了认证信息外,优秀回答者这是鉴别某用户是否为优质用户,是否值得关注的一个重要指标。包含张佳玮在内,共有468位优秀回答者,涉及257个话题,共出现768人次优秀回答者标签。

涉及的257话题词云
而所有优秀回答者贡献的回答和知乎收录回答情况如下:
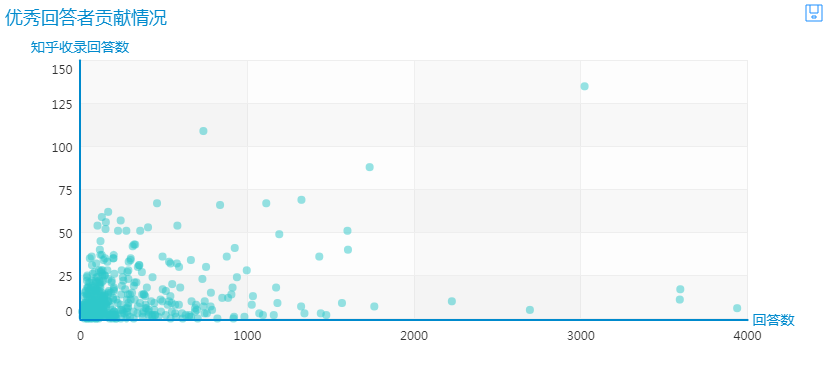
最右上角的便是张佳玮的贡献情况,令人望尘莫及。也有不少用户贡献了上千个回答,可以说是非常高产。但大部分用户回答数<1000,收录数<50。因此对此区域放大,可见:
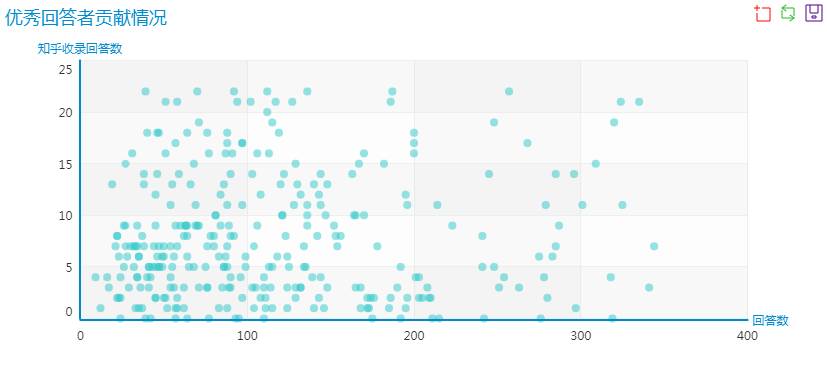
有不少数据收录回答为0,因为还不知道知乎优秀回答者的评判标准,所以此处还需进一步了解。另外这些数据点,对应的加上一些大V名字可能显示起来能好,但一直在摸索,还不得要领。
三、小结
本项目是个人第一次百万级数据的爬取,当然由于爬取效率方面需要改进,所以详细用户信息选择性的只爬了100+关注人数共4.1w+的id。另外也是第一次数据可视化,从完全不懂Echarts的各种参数,硬刚配置项,到勉强获得了上述还算能看的一些数据图,不少地方还需进一步学习、改进,以求获得更合乎要求的、理想的、自定义的可视化图。
另外,除却上述数据外,还有点赞数、感谢数、收藏数、关注数和被关注数、签名、个人简介等等数据并未处理,但基本想要获取的图都得到了,算是完成了此项目,也学到了很多东西。
怎样成为知乎大V?爬取张佳玮138w+知乎关注者:数据可视化相关推荐
- 爬取张佳玮138w+知乎关注者:数据可视化
前言 作为博客上第一篇文章,先介绍下小背景,即为什么爬知乎第一大V张公子的138w+关注者信息? 其实之前也写过不少小爬虫,按照网上各种教程实例去练手,"不可避免"的爬过妹子图.爬 ...
- 大数据项目开发hadoop集群搭建 python爬取前程无忧招聘网信息以及进行数据分析和数据可视化
大数据项目开发实训报告 一.Hadoop环境搭建 1: jdk的安装 1):在linux系统下的opt目录下创建software 和 module 两个目录 2):利用filezilla工具将 jdk ...
- Python爬取B站历史观看记录并用Bokeh做数据可视化
待爬取的数据 爬虫代码 import os import time import requests import pandas as pd# cookie 用浏览器登录B站,按F12打开开发人员工具 ...
- 374名10万+知乎大V(一):相互关注情况
一.前言 两个月前,今日头条签约了300多名知乎大V,随后引发广大关注和讨论,具体可见:如何看待今日头条一口气签了 300 多个知乎大 V 的传闻? 现在虽然热度已消逝,但一些困惑依然存在,到底知乎有 ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件...
爬取知乎大v张佳玮的文章"标题"."摘要"."链接",并存储到本地文件 1 # 爬取知乎大v张佳玮的文章"标题".&qu ...
- python数据分析 知乎_Python数据分析揭秘知乎大V的小秘密
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 清风小筑 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python数据分析练手:分析知乎大V
知乎,可以说是国内目前最大的问答类社区.与微博.贴吧等产品不同,知乎上面的内容更多是用户针对特定的问题分享知识.经验和见解.咱们编程教室就有不少读者是从知乎上了解到我们的. 那么,知乎上都有哪些&qu ...
- 知网关键词搜索爬取摘要信息
知网关键词搜索爬取摘要信息 由于技术不成熟,代码冗余度较高.同时代码也可能会存在错误,也请各路高人指正. 本篇文章应用范围为期刊搜索(不包括外文文献),其他内容,没有进行测试!!! 本次爬虫所采用到的 ...
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
最新文章
- could not export python function call python_value. Remove calls to Python functions before export
- tomcat设置自动监听替换class文件
- 万能写入sql语句,并且防注入
- 智能合约重构社会契约 (2)雅阁项目智能合约
- 想要求职Web安全相关的岗位,你就必须要懂的知识
- C# 图片文件文本string格式 传输问题
- centos 安装rar 和 unrar
- ExpandableListView 箭头靠右
- [js高手之路] 跟GhostWu一起封装一个字符串工具库-扩展字符串位置方法(4)
- Scikit-learn的分类器算法:k-近邻及案例
- 硬解析和软解析 mysql_Oracle学习之shared pool--硬解析和软解析
- 65 年来,全英国向他道歉三次,图灵,计算机人不能忘记的男人
- Redis-与spring的集成(XML形式)
- 三种Windows版本下教你如何卸载Oracle
- html页面小宠物代码大全,宠物店网页设计html代码
- cad剪裁地形图lisp_CAD怎么在完整地形图里截取需要的部分地形图
- Mac -- 插入移动硬盘后没有显示
- mac系统 彻底删除安全助手
- 使用fiddler实现苹果ios手机抓包
- 基于JSP的犯罪数据可视化系统