十分钟理解Transformer
本文转载于知乎文章:十分钟理解Transformer
Transformer是一个利用注意力机制来提高模型训练速度的模型。关于注意力机制可以参看这篇文章,trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。
那什么是transformer呢?
你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。


那么在这个黑盒子里面都有什么呢?
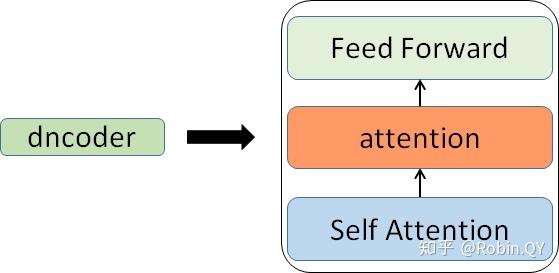
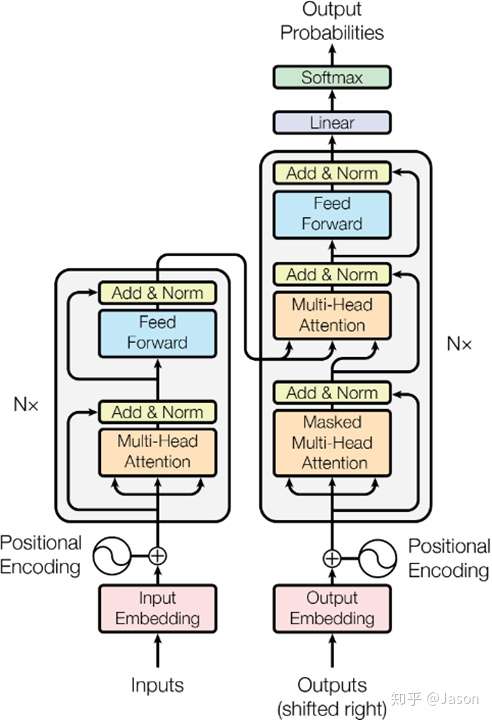
里面主要有两部分组成:Encoder 和 Decoder
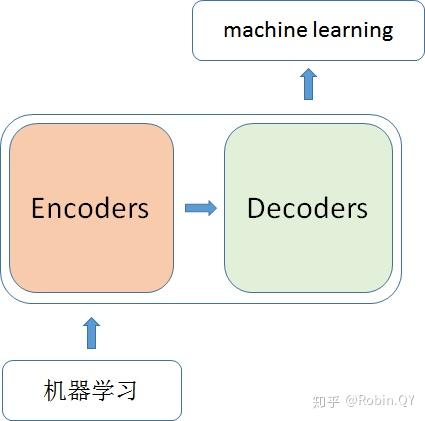
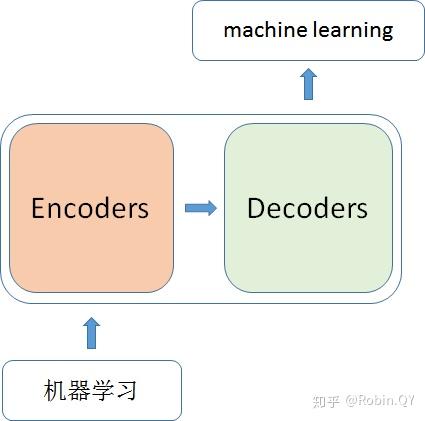
当我输入一个文本的时候,该文本数据会先经过一个叫Encoders的模块,对该文本进行编码,然后将编码后的数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本,对应的我们称Encoders为编码器,Decoders为解码器。
那么编码器和解码器里边又都是些什么呢?
细心的同学可能已经发现了,上图中的Decoders后边加了个s,那就代表有多个编码器了呗,没错,这个编码模块里边,有很多小的编码器,一般情况下,Encoders里边有6个小编码器,同样的,Decoders里边有6个小解码器。
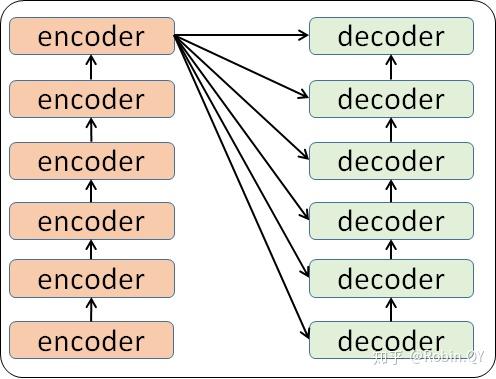
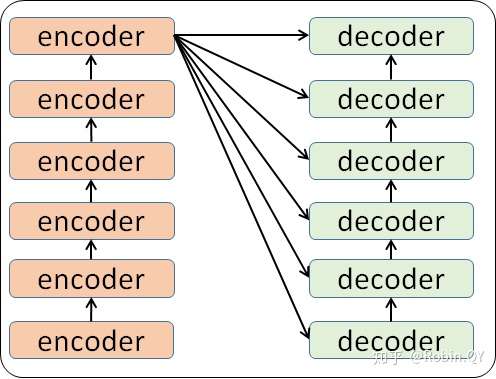
我们看到,在编码部分,每一个的小编码器的输入是前一个小编码器的输出,而每一个小解码器的输入不光是它的前一个解码器的输出,还包括了整个编码部分的输出。
那么你可能又该问了,那每一个小编码器里边又是什么呢?
我们放大一个encoder,发现里边的结构是一个自注意力机制加上一个前馈神经网络。
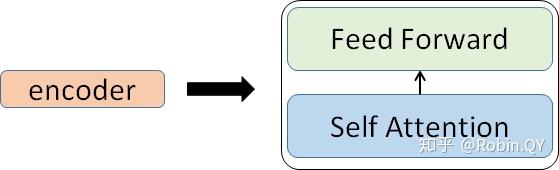
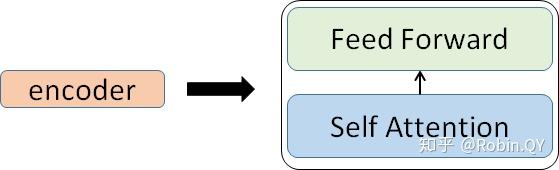
我们先来看下self-attention是什么样子的。
我们通过几个步骤来解释:
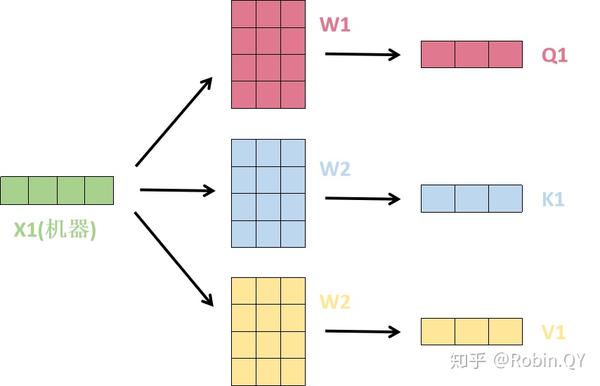
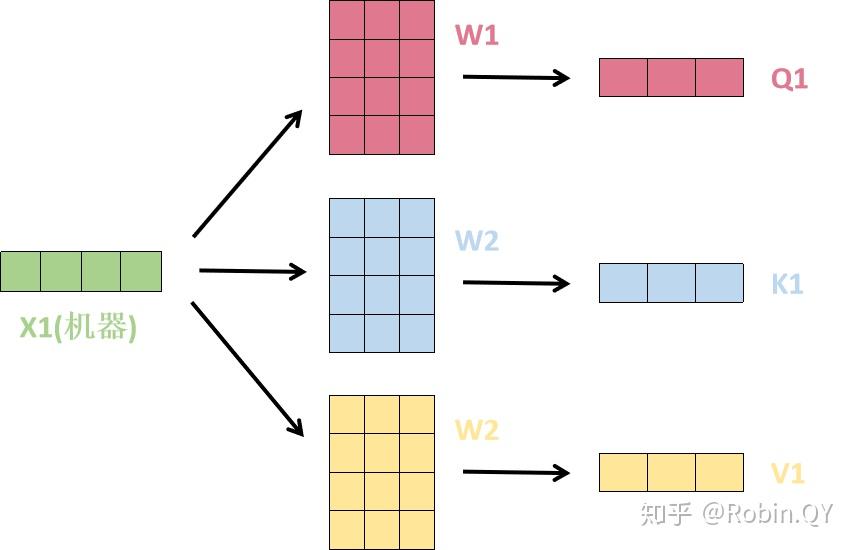
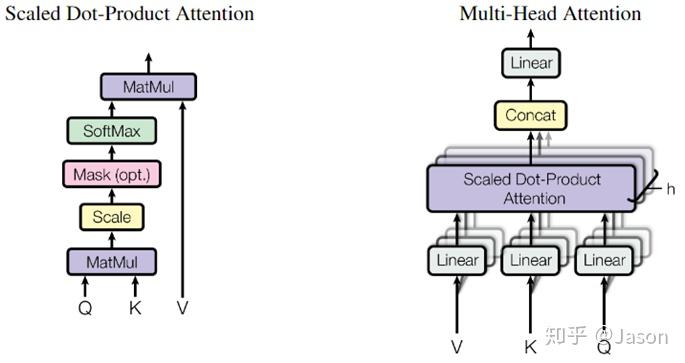
1、首先,self-attention的输入就是词向量,即整个模型的最初的输入是词向量的形式。那自注意力机制呢,顾名思义就是自己和自己计算一遍注意力,即对每一个输入的词向量,我们需要构建self-attention的输入。在这里,transformer首先将词向量乘上三个矩阵,得到三个新的向量,之所以乘上三个矩阵参数而不是直接用原本的词向量是因为这样增加更多的参数,提高模型效果。对于输入X1(机器),乘上三个矩阵后分别得到Q1,K1,V1,同样的,对于输入X2(学习),也乘上三个不同的矩阵得到Q2,K2,V2。
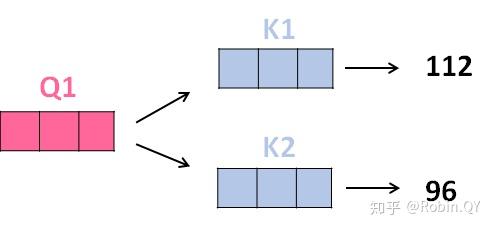
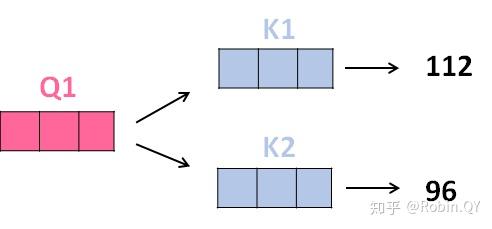
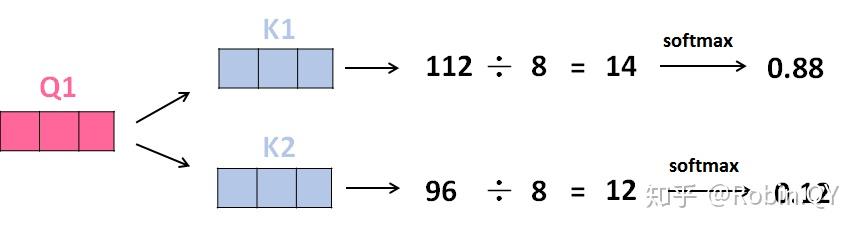
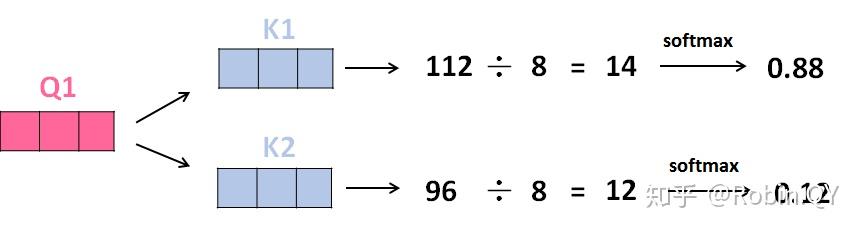
2、那接下来就要计算注意力得分了,这个得分是通过计算Q与各个单词的K向量的点积得到的。我们以X1为例,分别将Q1和K1、K2进行点积运算,假设分别得到得分112和96。
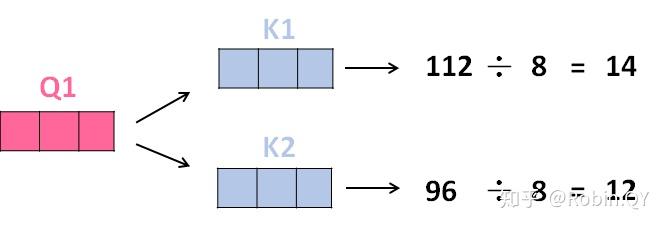
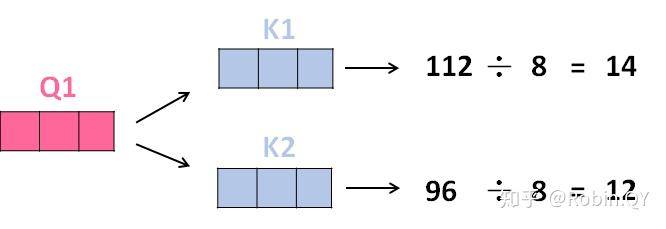
3、将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定,则得到结果如下:
4、将上述结果进行softmax运算得到,softmax主要将分数标准化,使他们都是正数并且加起来等于1。
5、将V向量乘上softmax的结果,这个思想主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词(例如将他们乘上很小的数字)
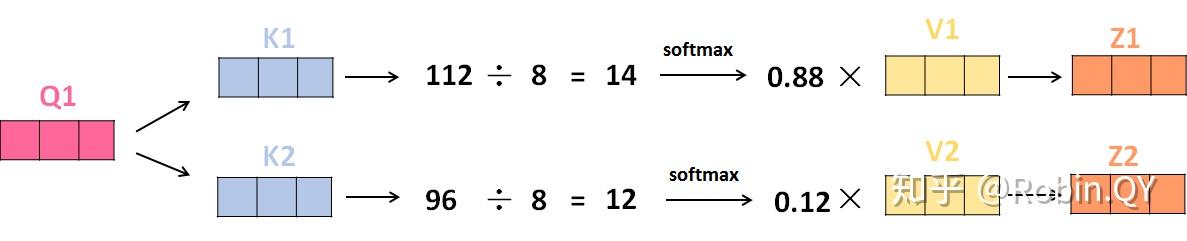
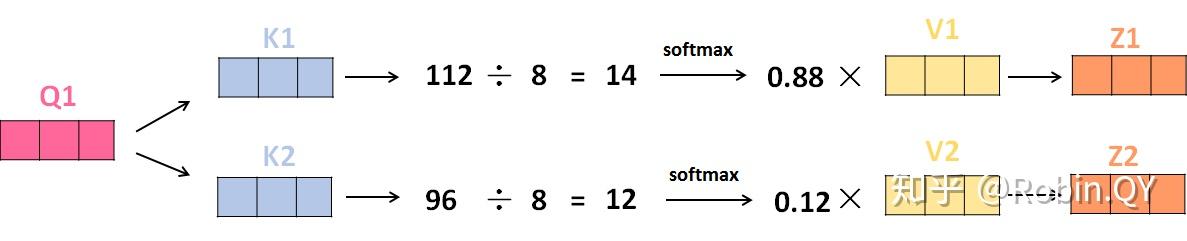
6、将带权重的各个V向量加起来,至此,产生在这个位置上(第一个单词)的self-attention层的输出,其余位置的self-attention输出也是同样的计算方式。


将上述的过程总结为一个公式就可以用下图表示:
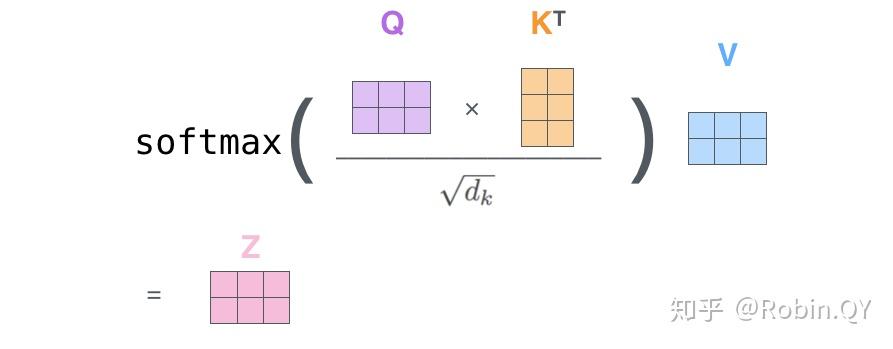
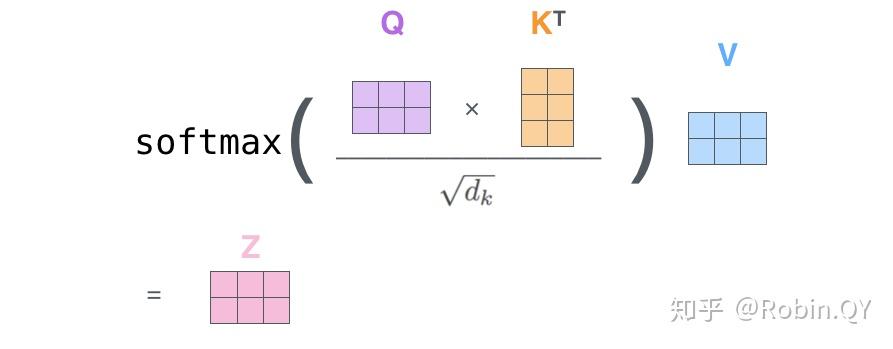
self-attention层到这里就结束了吗?
还没有,论文为了进一步细化自注意力机制层,增加了“多头注意力机制”的概念,这从两个方面提高了自注意力层的性能。
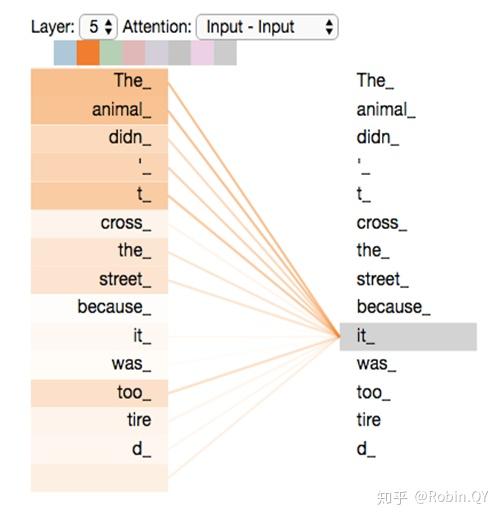
第一个方面,他扩展了模型关注不同位置的能力,这对翻译一下句子特别有用,因为我们想知道“it”是指代的哪个单词。

第二个方面,他给了自注意力层多个“表示子空间”。对于多头自注意力机制,我们不止有一组Q/K/V权重矩阵,而是有多组(论文中使用8组),所以每个编码器/解码器使用8个“头”(可以理解为8个互不干扰自的注意力机制运算),每一组的Q/K/V都不相同。然后,得到8个不同的权重矩阵Z,每个权重矩阵被用来将输入向量投射到不同的表示子空间。
经过多头注意力机制后,就会得到多个权重矩阵Z,我们将多个Z进行拼接就得到了self-attention层的输出:


上述我们经过了self-attention层,我们得到了self-attention的输出,self-attention的输出即是前馈神经网络层的输入,然后前馈神经网络的输入只需要一个矩阵就可以了,不需要八个矩阵,所以我们需要把这8个矩阵压缩成一个,我们怎么做呢?只需要把这些矩阵拼接起来然后用一个额外的权重矩阵与之相乘即可。
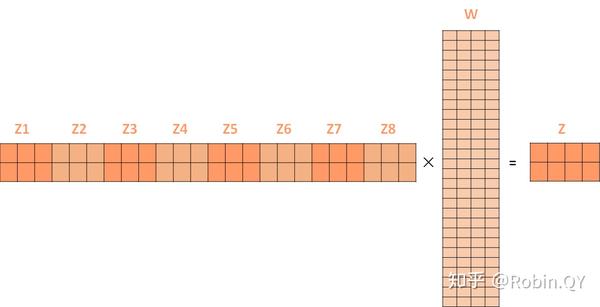
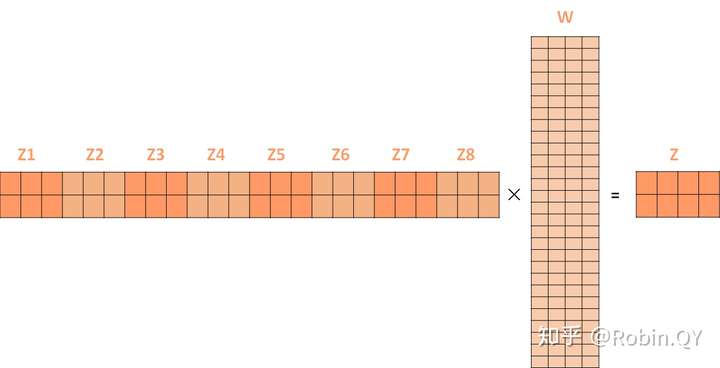
最终的Z就作为前馈神经网络的输入。
接下来就进入了小编码器里边的前馈神经网模块了,关于前馈神经网络,网上已经有很多资料,在这里就不做过多讲解了,只需要知道,前馈神经网络的输入是self-attention的输出,即上图的Z,是一个矩阵,矩阵的维度是(序列长度×D词向量),之后前馈神经网络的输出也是同样的维度。
以上就是一个小编码器的内部构造了,一个大的编码部分就是将这个过程重复了6次,最终得到整个编码部分的输出。
然后再transformer中使用了6个encoder,为了解决梯度消失的问题,在Encoders和Decoder中都是用了残差神经网络的结构,即每一个前馈神经网络的输入不光包含上述self-attention的输出Z,还包含最原始的输入。
上述说到的encoder是对输入(机器学习)进行编码,使用的是自注意力机制+前馈神经网络的结构,同样的,在decoder中使用的也是同样的结构。也是首先对输出(machine learning)计算自注意力得分,不同的地方在于,进行过自注意力机制后,将self-attention的输出再与encoders模块的输出计算一遍注意力机制得分,之后,再进入前馈神经网络模块。

以上,就讲完了Transformer编码和解码两大模块,那么我们回归最初的问题,将“机器学习”翻译成“machine learing”,解码器输出本来是一个浮点型的向量,怎么转化成“machine learing”这两个词呢?
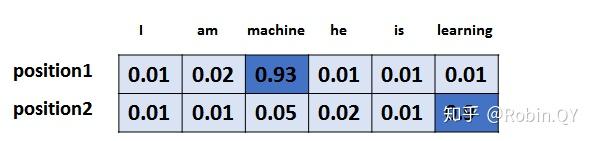
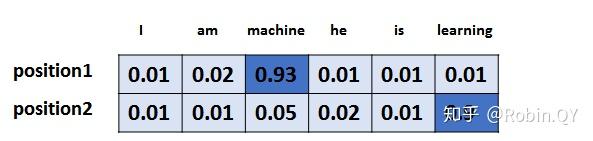
是个工作是最后的线性层接上一个softmax,其中线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更高维度的向量(logits)上,假设我们模型的词汇表是10000个词,那么logits就有10000个维度,每个维度对应一个唯一的词的得分。之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!!
假设词汇表维度是6,那么输出最大概率词汇的过程如下:
以上就是Transformer的框架了,但是还有最后一个问题,我们都知道RNN中的每个输入是时序的,是有先后顺序的,但是Transformer整个框架下来并没有考虑顺序信息,这就需要提到另一个概念了:“位置编码”。
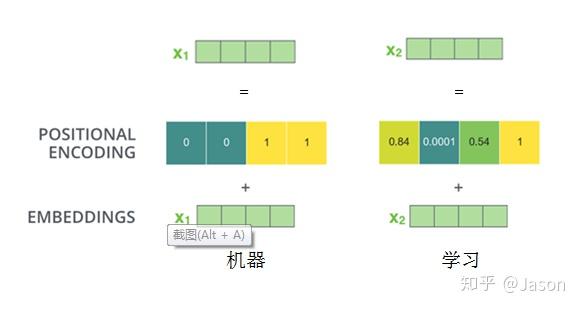
Transformer中确实没有考虑顺序信息,那怎么办呢,我们可以在输入中做手脚,把输入变得有位置信息不就行了,那怎么把词向量输入变成携带位置信息的输入呢?
我们可以给每个词向量加上一个有顺序特征的向量,发现sin和cos函数能够很好的表达这种特征,所以通常位置向量用以下公式来表示:
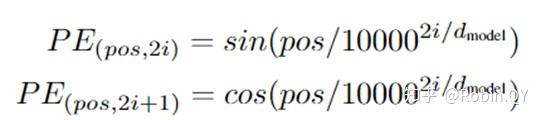
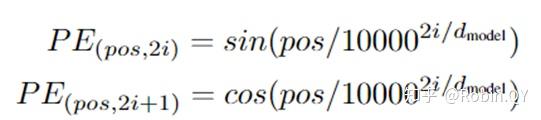

最后祭出这张经典的图,最初看这张图的时候可能难以理解,希望大家在深入理解Transformer后再看这张图能够有更深刻的认识。
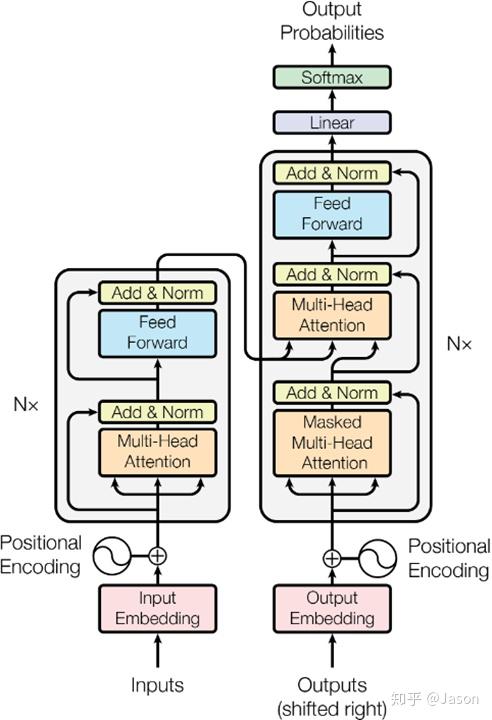

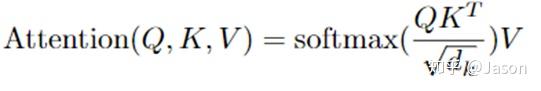
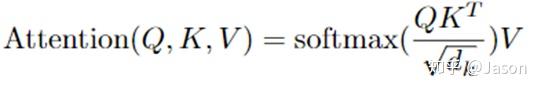
Transformer就介绍到这里了,后来的很多经典的模型比如BERT、GPT-2都是基于Transformer的思想。我们有机会再详细介绍这两个刷新很多记录的经典模型。
引用:
https://arxiv.org/abs/1706.03762 原论文
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
喜欢 收藏 申请转载
十分钟理解Transformer相关推荐
- java弱引用怎么手动释放,十分钟理解Java中的弱引用,十分钟java引用
十分钟理解Java中的弱引用,十分钟java引用 本篇文章尝试从What.Why.How这三个角度来探索Java中的弱引用,帮助大家理解Java中弱引用的定义.基本使用场景和使用方法.由于个人水平有限 ...
- 十分钟理解线性代数的本质_数学对于编程来说到底有多重要?来看看编程大佬眼里的线性代数!...
本文提出了一种观点:从应用的角度,我们可以把线性代数视为一门特定领域的程序语言.我们一起来看看!文章有点偏理论讨论,可能比较枯燥,对于一名程序员,你如果看下去,你将会有不一样的收获! 线性代数是什么? ...
- 5分钟理解transformer模型位置编码
Bert模型是自然语言处理方面里程碑式的进步,其核心是transformer层, 而transformer采用自注意力编码器摒弃了循环网络,循环网络天生的顺序信息在自注意力编码器中没有了,而语言往往是 ...
- 十分钟理解Java泛型擦除
泛型信息只存在于代码编译阶段,但是在java的运行期(已经生成字节码文件后)与泛型相关的信息会被擦除掉,专业术语叫做类型擦除. 今天我们来讲解泛型中另一个重要知识点--泛型擦除! 泛型擦除概念 泛型信 ...
- 十分钟理解线性代数的本质_复习线性代数的正确方式
有同学对我讲现在复习线性代数遇到了瓶颈,在历年的复习过程中,有许多同学完全找不到复习的感觉,线性代数这门学科的学习方法和高等数学完全不一样,也就是说你学习线性代数首先你得换学习思想,它完全是一套全新的 ...
- 十分钟理解线性代数的本质_“线性代数的本质”整理笔记1
只能说现在的学习环境实在是太太太又友好了. 第一讲:向量.在线性代数中,向量通常都是从原点出发的箭头,而不是物理中理解的,只要方向和长度相同,向量都是等同的.You should think the ...
- 十分钟理解javascript中的this对象
最近在参加的几场面试中都涉及到了对于js中this对象的理解,那么怎样去理解this呢?这里针对不同的场景通过代码来帮助我们理解好this. this到底指向什么? this指向什么呢?一言以蔽之: ...
- 十分钟理解logistic回归原理
关于逻辑回归的分类算法,很多书籍都有介绍,比较来看,还是**李航老师的书<统计学习方法>**里介绍的更清楚,若大家有时间,请不要偷懒,还是建议从头开始看李航老师的书,这本书简洁明了,适合入 ...
- c语言ascii码表_新手小白整理C语言笔记备忘,带你十分钟理解C语言
一.C语言数据类型 1.基本类型:整型.浮点型(单精度.双精度).字符型和枚举类型: 2.构造类型:数组类型.结构体类型和共用体类型: 3.指针类型: 4.空类型.二.数值数据的表示 1.整数:十进制 ...
最新文章
- 面试官:我想用Nginx提升系统10倍性能,你有哪些建议?
- SparkSql官方文档中文翻译(java版本)
- 基于决策树的多分类_R中基于决策树的糖尿病分类—一个零博客
- c语言中变量的值十进制,C语言中介绍的整型变量 即十进制 十六进制什么的是什么意思 能具体解释一下吗 还有换算什么的 谢谢...
- LinuxShell脚本之利用rsync+ssh实现Linux文件系统远程备份
- 项目管理工程师:第二章信息系统服务管理
- 抓包分析360浏览器和360搜索配对使用的安全性-WEB服务端分析
- linux重定向权限不够,linux – 如何使用sudo将输出重定向到一个我没有权限写入的位置?...
- OSPF OVER FR HUB-SPPKE
- 连接和关闭资源工具类
- 电脑升级Win11后不流畅卡顿怎么解决
- python经典案例:64格棋盘与麦粒
- 尚品汇_第4章_ 商品spu保存
- android 启动高德导航规划
- 西门子精智系列HMI屏幕用户管理密码组态示例(页面+IO域)
- html网页主题有哪些,网站的专题页面是什么?
- 惠普linux进入bios设置u盘启动,惠普bios,小编教你惠普bios怎么设置u盘启动
- 熊逸《唐诗50讲》羁旅篇 - 学习笔记与感想
- 小红书招聘计算机视觉算法工程师!
- 淘宝卖家软件哪个好呢?看看这6款你就知道了