如何在TensorFlow中训练Boosted Trees模型
在使用结构化数据时,诸如梯度提升决策树和随机森林之类的树集合方法是最流行和最有效的机器学习工具之一。 树集合方法训练速度快,无需大量调整即可正常工作,并且不需要大型数据集进行训练。
在TensorFlow中,梯度增强树可以使用tf.estimator API,它还支持深度神经网络,广泛和深度模型等。 对于增强树,支持具有预定义均方误差损失( BoostedTreesRegressor )的回归和具有交叉熵损失( BoostedTreesClassifier )的分类。 用户还可以选择使用任何两次可区分的自定义丢失(通过将其提供给BoostedTreesEstimator )。
在这篇文章中,我们将展示如何在TensorFlow中训练Boosted Tree模型,然后我们将演示如何解释具有特征重要性的训练模型以及如何解释模型对各个示例的预测。 以下所有代码均为TensorFlow 2.0准备就绪(TensorFlow 2.0 完全支持预制估算器)。 此帖子中的所有代码均可在此处和此处的TensorFlow文档中找到 。
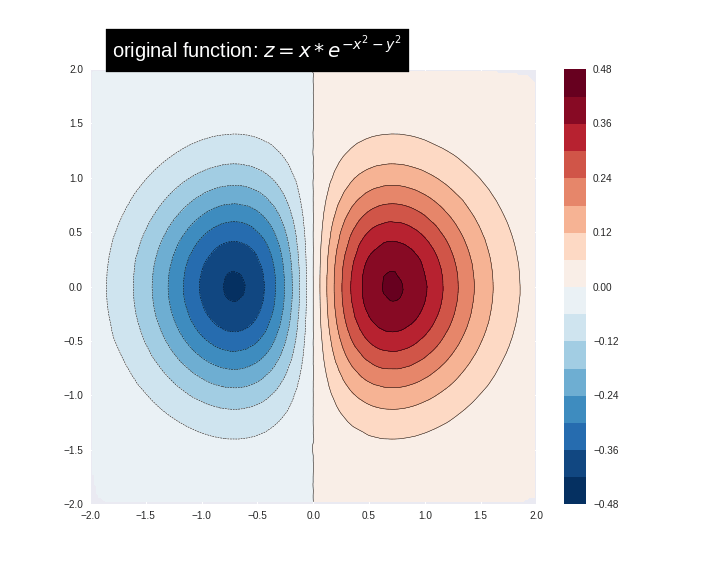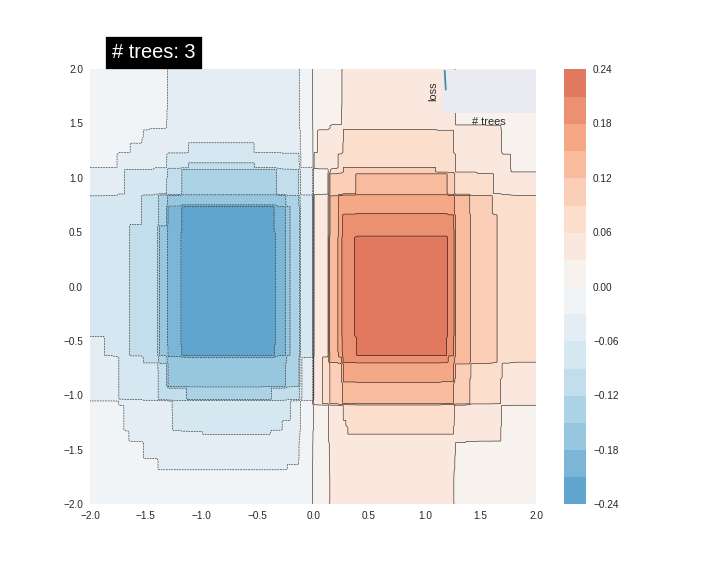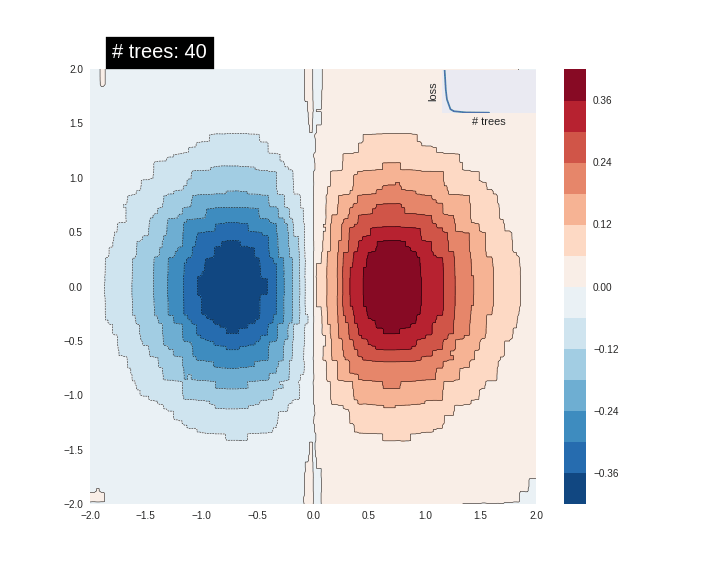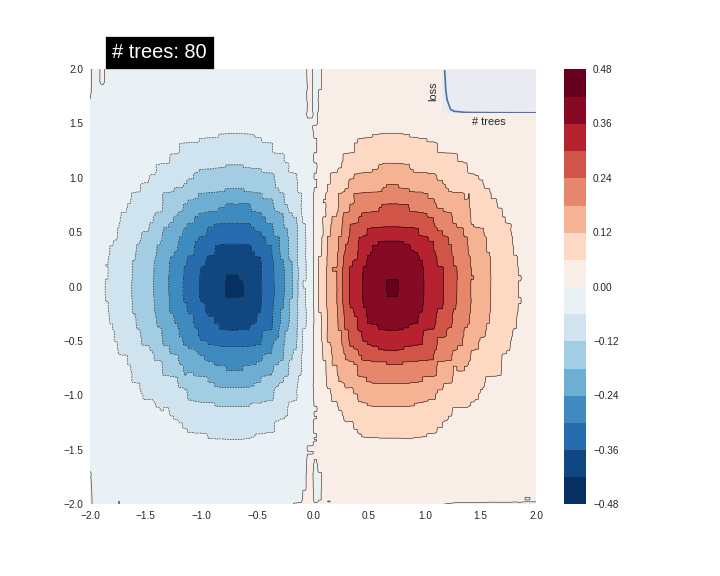
可视化Boosted Trees模型的预测表面。 渐变增强树是一种集合技术,它结合了几种(认为10s,100s甚至1000s)树模型的预测。 增加树木的数量通常会提高适合的质量。 在 这里 试试完整的例子 。
在TensorFlow中训练一个Boosted Trees模型
Boosted Trees估计器支持不适合工人记忆的大型数据集,并且还提供分布式培训。 但是,出于演示目的,让我们在一个小数据集上训练一个Boosted Trees模型:泰坦尼克数据集。 这个(相当病态的)数据集的目标是使用乘客特征(如年龄,性别,等级等)预测乘客在泰坦尼克号坠毁中幸存的概率。
首先,让我们导入必要的包并加载我们的数据集。
接下来,让我们定义要与我们的estimator模型一起使用的feature_column 。 功能列适用于所有TensorFlow估算器,其目的是定义用于建模的功能。 此外,它们还提供了一些功能工程功能,如单热编码, 规范化和bucketization。 CATEGORICAL_COLUMNS中的字段下方从分类列转换为单热编码列(指标列):
您可以查看要素列生成的转换。 例如,以下是在单个示例中使用indicator_column时的输出:
接下来,您需要创建输入函数。 这些将指定如何将数据读入我们的模型以进行训练和推理。 您将使用tf.data API中的from_tensor_slices方法直接从Pandas读取数据。 这适用于较小的内存数据集。 对于较大的数据集,tf.data API支持各种文件格式(包括csv ),以便您可以处理不适合内存的数据集。
让我们首先训练逻辑回归模型以获得基准:
然后训练Boosted Trees模型涉及与上述相同的过程:
模型理解
对于许多最终用户而言,“为什么”和“如何”通常与预测一样重要。 例如,最近的欧盟法规强调了用户的“解释权”,这要求用户应该能够获得对公司决策产生重大影响的解释( 来源 )。 此外,美国公平信用报告法要求各机构披露“所有使用模型中消费者信用评分受到不利影响的关键因素,其总数不得超过4”( 来源 )。
模型可解释性还可以帮助机器学习(ML)从业者在模型开发阶段检测偏差。 这种洞察力有助于ML从业者更好地调试和理解他们的模型。
模型可解释性通常有两个层次:局部可解释性和全局可解释性。 局部可解释性是指在个体范例层面理解模型的预测,而全局可解释性是指理解整个模型。
可解释性技术通常特定于模型类型(例如,树方法,神经网络等)并且利用所学习的参数。 例如,基于增益的特征重要性特定于树方法,而集成梯度技术利用神经网络中的梯度。
相比之下,还有模型不可知的方法,如LIME和shap 。 LIME通过构建训练本地代理模型来近似预测底层黑匣子模型。 shap方法通过将每个特征归因于对该特征进行调节时预期模型预测的变化,将博弈论与局部解释联系起来。
了解个人预测:定向特征贡献
我们已经实施了Palczewska等人和 Saabas在解释随机森林中概述的本地特征贡献方法。 此方法也可用于scikit-learn的treeinterpreter包中。
简而言之,该技术允许人们通过分析在添加分割时预测如何变化来理解模型如何对单个实例进行预测。 从初始预测开始(通常称为偏差并且通常被定义为训练标签的平均值),该技术遍历预测路径,在分割特征之后计算预测的变化。 对于每个分割,预测的变化归因于用于分割的特征。 在所有分割和所有树木中,将这些属性相加以指示每个特征的总贡献。
该方法返回与每个要素关联的数值。 我们将这些值称为方向特征贡献(DFC),以区别于评估特征影响的其他方式,例如通常指全局特征重要性的特征重要性。 DFC允许检查各个示例,并提供对模型为什么对特定示例进行预测的见解。 使用此技术,您可以创建如下可视化:
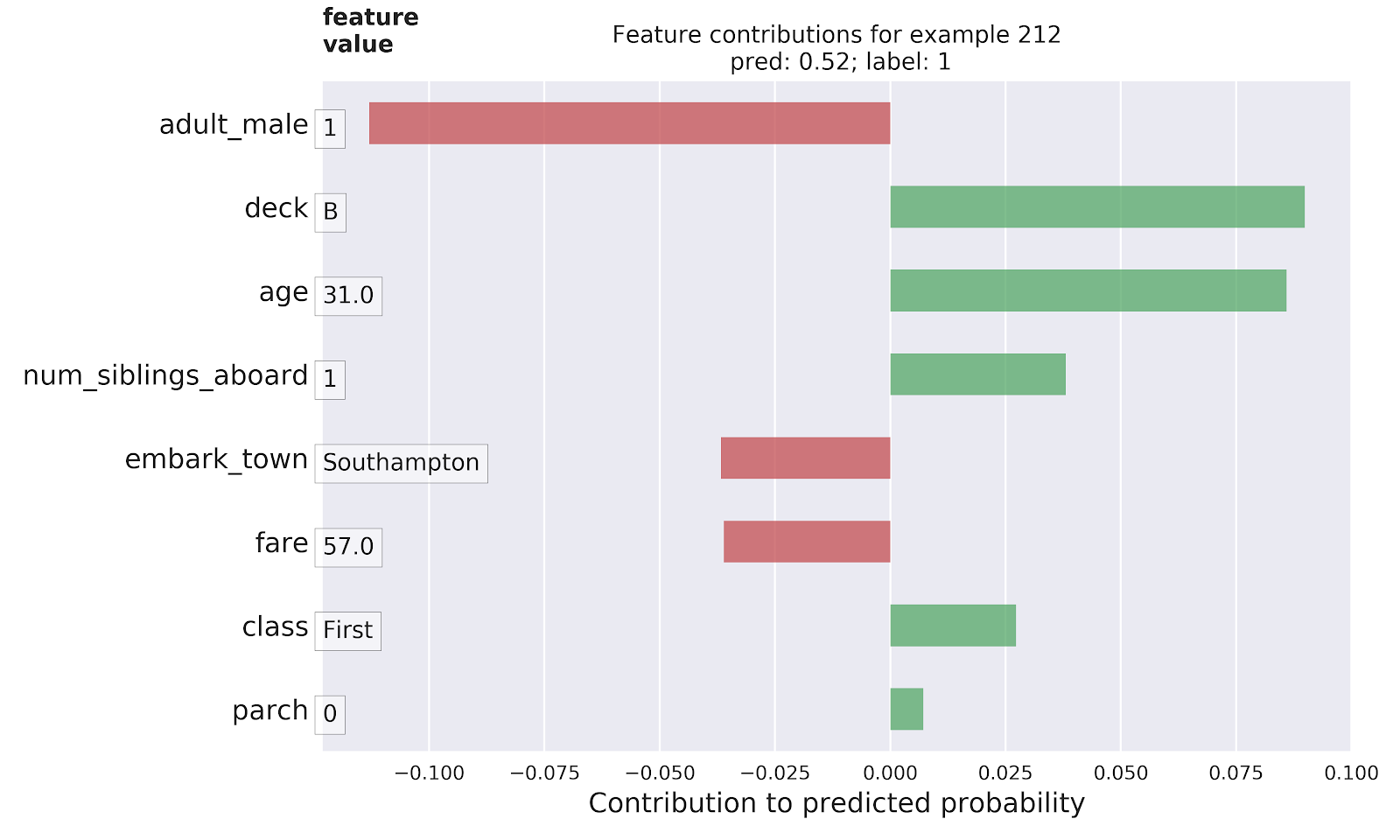
Tianic数据集中实例的DFC。 非正式地,这可以被解释为“ adult_male 是真的”贡献“约-0.11到最终概率,而 Deck 为B对最终概率贡献约+0.08,依此类推。”
DFC的一个很好的特性是每个特征的贡献总和将总和到实际预测。 例如,如果模型中有五个要素,并且对于给定的实例,则为DFC
{sex_female:0.2,年龄:0.05,票价= -0.02,num_siblings_aboard = -0.1,票价:0.09}
预测概率将是这些值的总和:0.22。
我们还可以在整个数据集中聚合DFC,以深入了解整个模型的全局解释:
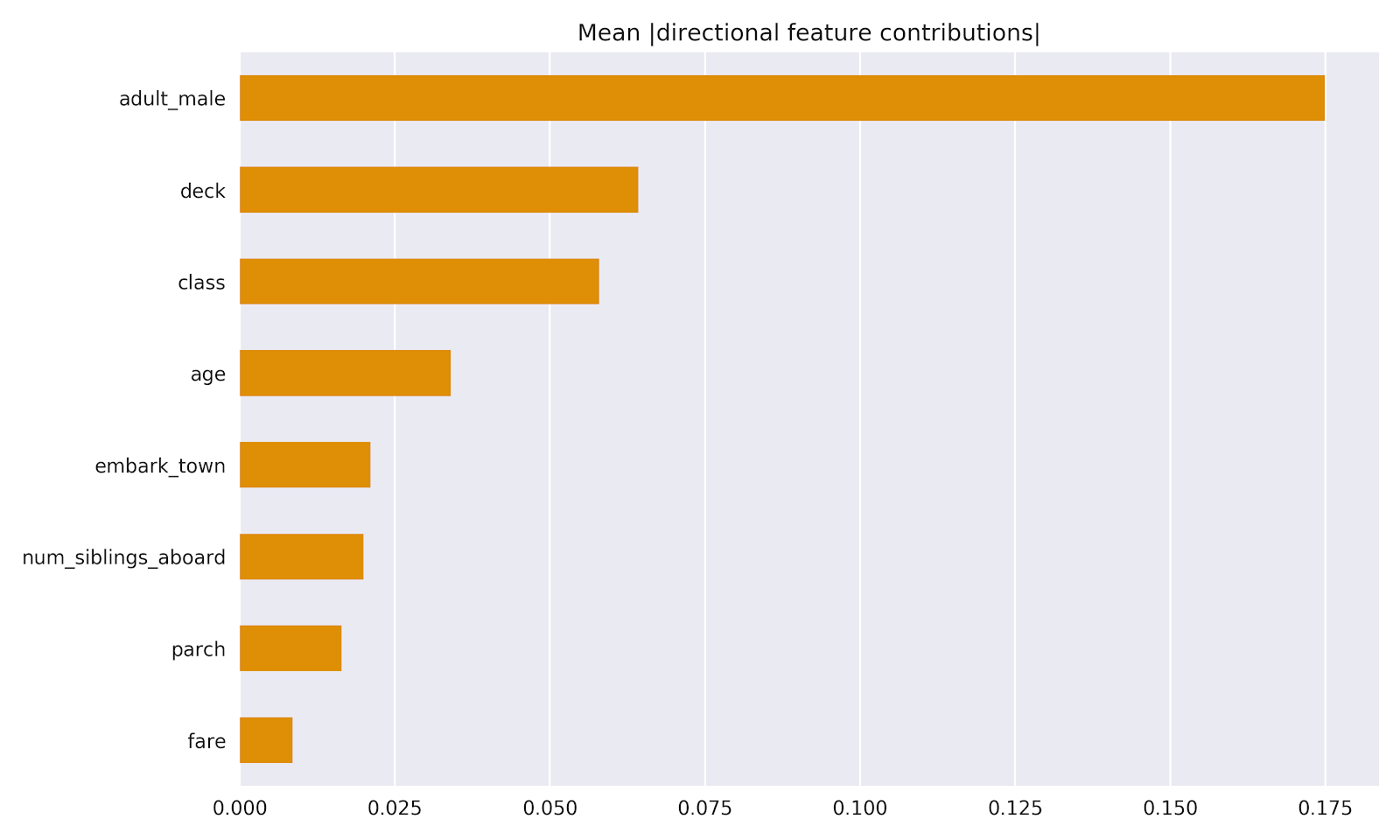
整个评估数据集中顶部DFC的平均绝对值。
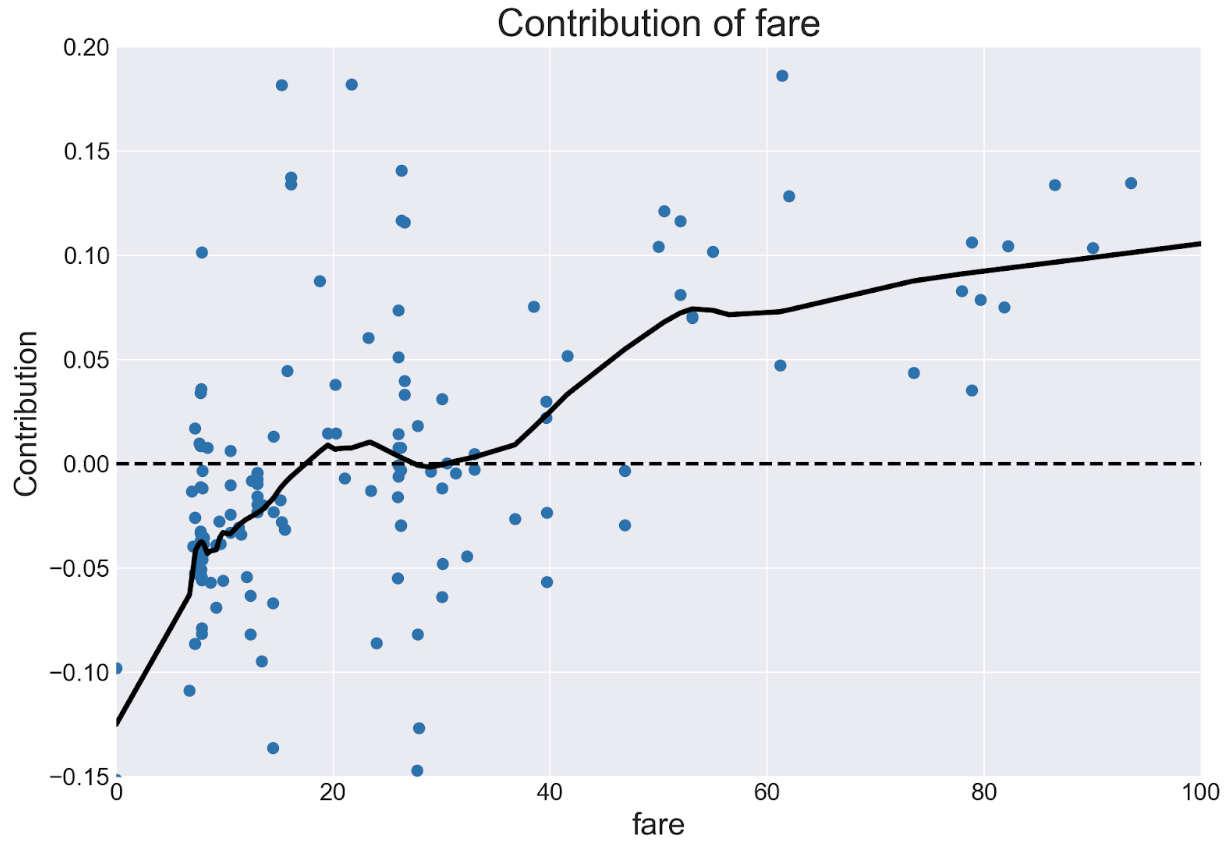
fare 与对比度低的贡献。 跨例子的贡献提供了比单个特征重要性度量更细粒度的信息。 通常,较高的票价特征导致模型推测预测接近1.0(增加生存机会)。
如何:TensorFlow中的方向特征贡献
下面的所有代码都可以在Boosted Trees模型理解笔记本中找到 。
首先,您需要使用如上所述的tf.estimator API训练Boosted Trees估算器。
在训练我们的模型之后,我们可以使用est.experimental_predict_with_explanations检索模型解释。 (注意:该方法被命名为experimental,因为我们可能会在删除实验前缀之前修改API。)
使用pandas,您可以轻松地显示DFC:
在我们的Colab中,我们添加了一些示例,它添加了贡献分布,以了解特定实例的DFC如何与评估集的其余部分进行比较:
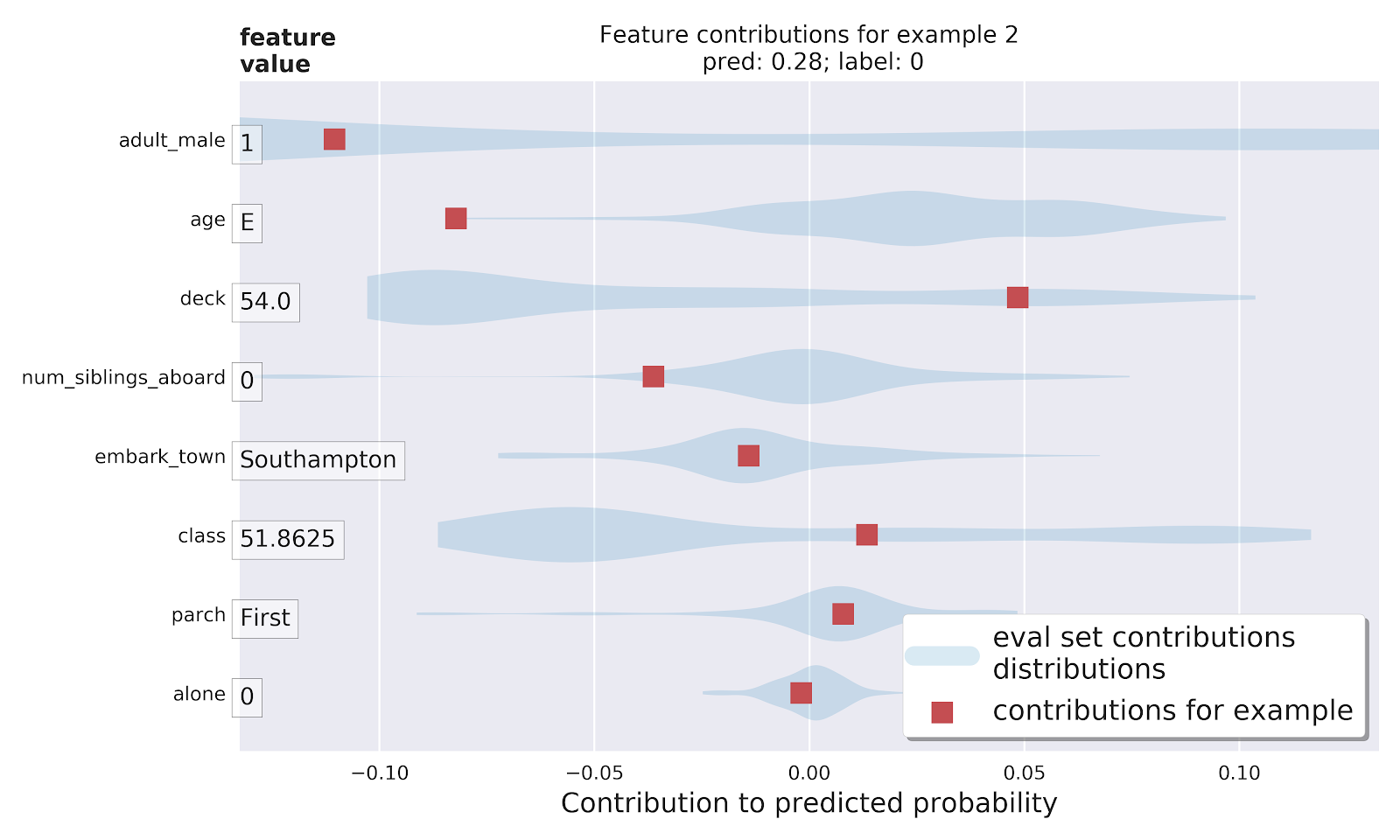
红色单个示例的贡献。 阴影蓝色区域显示整个验证集中功能的贡献分布。
我们还注意到还有其他与TensorFlow一起使用的第三方模型不可知解释方法,例如LIME和shap 。 有关更多链接,请参阅下面的其他资源。
模型级可解释性:基于增益和排列特征的重要性
有许多方法可以实现Boosted Tree模型的模型级理解(即全局可解释性)。 之前我们展示了您可以跨数据集聚合DFC以获得全局可解释性。 这也可以通过聚合其他局部解释值(例如从LIME或shap(如上所述)生成的那些)来工作。
我们在下面讨论的另外两种技术是基于增益的特征重要性和排列特征重要性。 基于增益的特征重要性测量特定特征分割时的损失变化,而排列特征重要性通过评估集合评估模型性能,通过逐个改变每个特征并将模型性能损失归因于混洗特征来计算。 排列特征重要性具有与模型无关的优点,但是在潜在预测变量的测量尺度或类别数量( 来源 )不同的情况下,这两种方法都不可靠。
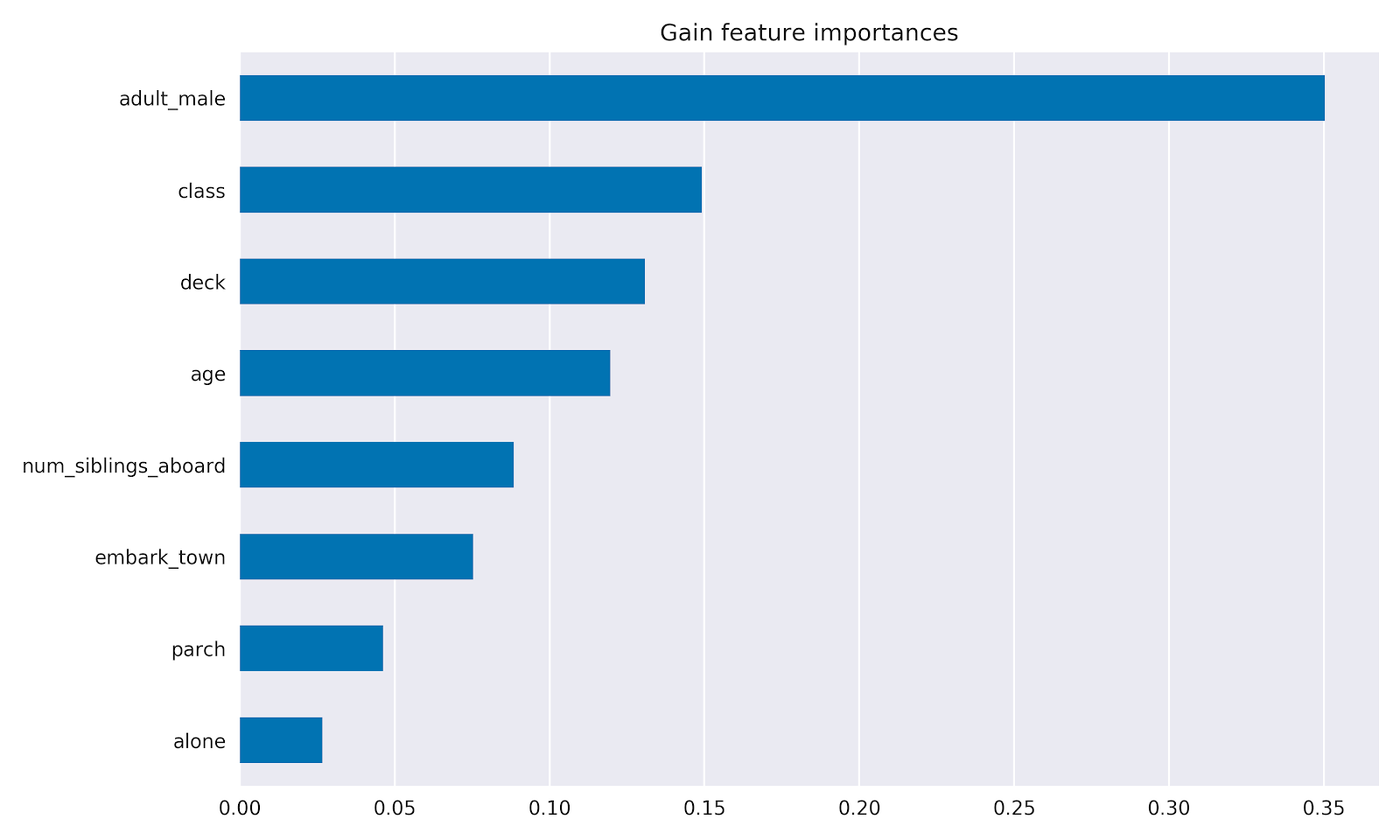
在TensorFlow中的Boosted Trees估计器中,使用est.experimental_feature_importances检索基于增益的要素重要性。 以下是绘图的完整示例:
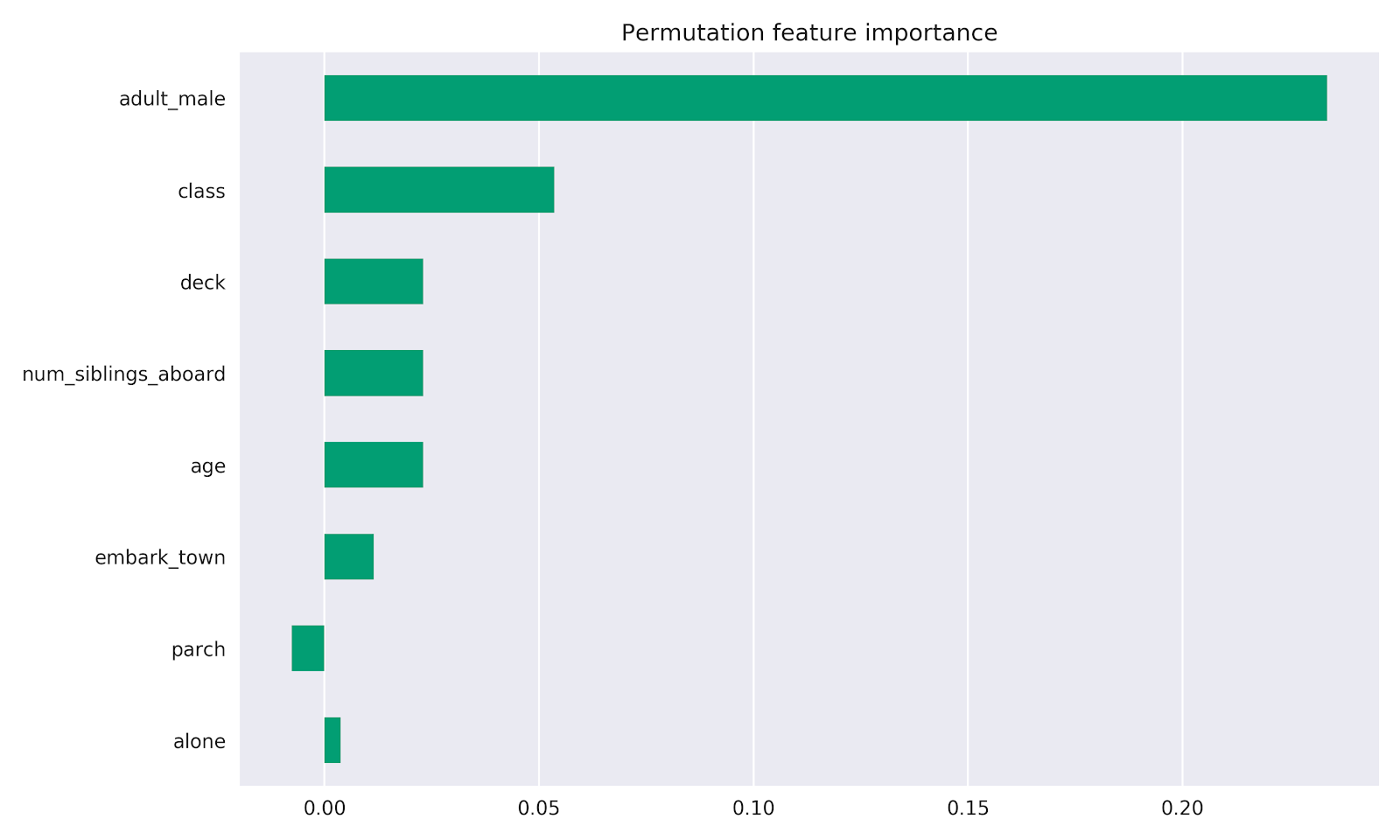
排列特征重要性可以按如下方式计算:
相关变量和其他考虑因素
当两个或多个要素相关时,许多模型解释工具将提供对特征影响的扭曲视图。 例如,如果训练包含两个非常相关的特征的集合树模型,则与仅包括任一特征相比,两个特征的基于增益的特征重要性将更少。
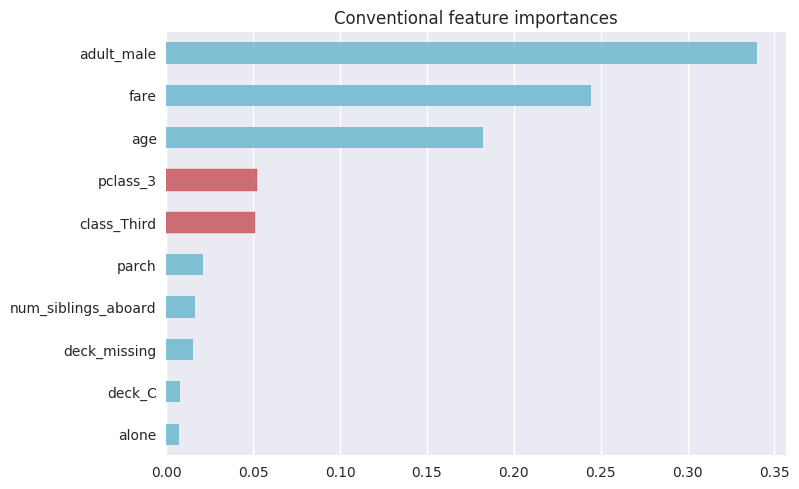
在泰坦尼克数据集中,假设我们偶然编码了两次乘客的类 - 以两个变量class和pclass的形式。 在使用单热编码对这些分类特征进行编码并对模型进行训练之后,观察到第三类乘客具有预测能力 - 我们可以看到这两次。
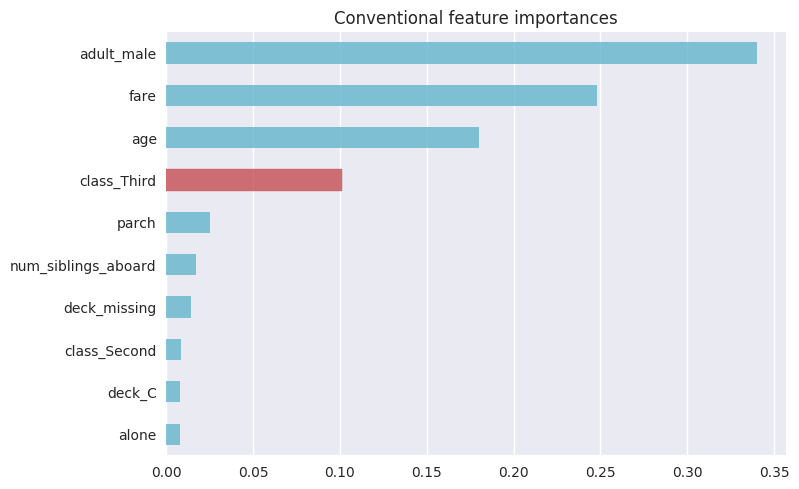
在我们删除其中一个特征(pclass)并重新检查特征重要性之后,乘客在第三类中的重要性大约翻了一番。
在这种情况下,两个特征是完全相关的,但是即使具有部分相关的特征也会发生相同的现象,仅在较小程度上。
因此,对于我们上面讨论过的技术,建议删除高度相关的特征。 这不仅可以帮助解释,还可以加快模型培训。 另外,维护较少的功能比维护大量功能更容易。
最后,我们注意到Strobl等人。 引入了另一种称为条件变量重要性的技术,利用特征置换,可以在存在相关变量的情况下帮助提供更真实的特征影响估计。 查看论文了解更多详情。
结论
使用tf.estimator API在TensorFlow中提供梯度提升决策树,允许用户快速尝试不同的机器学习模式。 对于梯度提升的决策树,TensorFlow中提供了本地模型可解释性(使用Palczewska等人和 Saabas( 解释随机森林 )通过experimental_predict_with_explanations概述的方法的每个实例可解释性)和全局性可解释性(基于增益和排列特征重要性) 。 这些方法可以帮助从业者更好地理解他们的模型。
TensorFlow Boosted Trees的发布得益于很多人,包括但不限于Soroush Radpour,Younghee Kwon,Mustafa Ispir,Salem Haykal和Yan Facai。
其他资源
与TensorFlow一起使用的其他模型可解释方法
- 酸橙
- 十八
- 集成渐变 (仅限神经网络)
- SmoothGrad (仅限神经网络)
- TensorFlow中的格子方法
排列特征重要性(Brieman,2001 )
https://medium.com/tensorflow/how-to-train-boosted-trees-models-in-tensorflow-ca8466a53127
如何在TensorFlow中训练Boosted Trees模型相关推荐
- python tensorflow 文本提取_如何在tensorflow中保存文本分类模型?
阅读tensorflow documentation进行文本分类时,我在下面建立了一个脚本,用于训练文本分类模型(正/负).有一件事我不确定.如何保存模型以便以后重用?另外,如何测试我拥有的输入测试集 ...
- 使用TensorFlow训练Boosted Trees model
How to train Boosted Trees models in TensorFlow 官方文档链接 这篇tutorial使用tf.estimator完整的训练一个Gradient Boost ...
- 在 C/C++ 中使用 TensorFlow 预训练好的模型—— 直接调用 C++ 接口实现
现在的深度学习框架一般都是基于 Python 来实现,构建.训练.保存和调用模型都可以很容易地在 Python 下完成.但有时候,我们在实际应用这些模型的时候可能需要在其他编程语言下进行,本文将通过直 ...
- 如何在Keras中检查深度学习模型(翻译)
本文翻译自:How to Check-Point Deep Learning Models in Keras 深度学习模型可能需要数小时,数天甚至数周才能进行训练. 如果意外停止运行,则可能会丢失大量 ...
- 转载:tensorflow保存训练后的模型
训练完一个模型后,为了以后重复使用,通常我们需要对模型的结果进行保存.如果用Tensorflow去实现神经网络,所要保存的就是神经网络中的各项权重值.建议可以使用Saver类保存和加载模型的结果. 1 ...
- 如何在TensorFlow中通过深度学习构建年龄和性别的多任务预测器
by Cole Murray 通过科尔·默里(Cole Murray) In my last tutorial, you learned about how to combine a convolut ...
- 如何在Keras中训练大型数据集
https://www.toutiao.com/a6670173759829180936/ 在本文中,我们将讨论如何使用Keras在不适合内存的大数据集上训练我们的深度学习网络. 介绍 深度学习算法优 ...
- 说话人识别中训练通用背景模型(UBM)的研究
摘要: 以高斯分布为基础的说话人识别系统使用通用背景的模型(UBM)需要广泛的数据资源尤其是多信道和多个麦克风种类下采集语音.本研究主要是对训练UBM模型数据的选择对整个系统性能的影响做一个系统的分析 ...
- 数据不够,Waymo用GAN来凑:生成逼真相机图像,在仿真环境中训练无人车模型...
鱼羊 发自 凹非寺 量子位 报道 | 公众号 QbitAI 疫情当下,Waymo等自动驾驶厂商暂时不能在现实世界的公共道路上进行训练.测试了. 不过,工程师们还可以在GTA,啊不,在仿真环境里接着跑车 ...
最新文章
- endnote能自动翻译吗_人工智能能翻译古文吗?跟小编点评专业翻译PK人工智能翻译...
- Web服务器指纹识别工具httprint
- 50.什么是内部碎片?什么是外部碎片?
- 余额宝利率破2.4%,你还会把钱放在余额宝里面吗?
- 杨森翔的书法【斗方】
- cvtcolor python opencv_二值分析 | OpenCV + skimage如何提取中心线
- python每周小测验答案_python第一周小测验答案Centos下更新Python版本
- java wps_通过WPS和WID方便地使用Java构件
- 查看MySQL数据库中每个表占用的空间大小
- Nand_ECC_校验和纠错_详解
- 习题2.2 数组循环左移(20 分)浙大版《数据结构(第2版)》题目集
- http各类攻击及tcpcopy工具
- IDEA中将WEB-INF\lib下的Jar包添加到项目中
- ZZULIOJ1010
- 获取鼠标图片和鼠标位置的方法
- 思维导图带你看遍花样百出的各类月饼?
- 交友项目【手机号登录注册功能】实现
- Summit Wireless全新低成本空间音频模块现已震撼上市
- thymeleaf模板引擎的优势何在?
- Python爬取新闻动态评论