网页缩放与窗口缩放_功能缩放—不同的Scikit-Learn缩放器的效果:深入研究
网页缩放与窗口缩放
内部AI (Inside AI)
In supervised machine learning, we calculate the value of the output variable by supplying input variable values to an algorithm. Machine learning algorithm relates the input and output variable with a mathematical function.
在有监督的机器学习中,我们通过将输入变量值提供给算法来计算输出变量的值。 机器学习算法将输入和输出变量与数学函数相关联。
Output variable value = (2.4* Input Variable 1 )+ (6*Input Variable 2) + 3.5
输出变量值=(2.4 *输入变量1)+(6 *输入变量2)+ 3.5
There are a few specific assumptions behind each of the machine learning algorithms. To build an accurate model, we need to ensure that the input data meets those assumptions. In case, the data fed to machine learning algorithms do not satisfy the assumptions then prediction accuracy of the model is compromised.
每个机器学习算法背后都有一些特定的假设。 为了建立准确的模型,我们需要确保输入数据符合这些假设。 如果馈送到机器学习算法的数据不满足假设,则模型的预测准确性会受到损害。
Most of the supervised algorithms in sklearn require standard normally distributed input data centred around zero and have variance in the same order. If the value range from 1 to 10 for an input variable and 4000 to 700,000 for the other variable then the second input variable values will dominate and the algorithm will not be able to learn from other features correctly as expected.
sklearn中的大多数监督算法都需要以零为中心的标准正态分布输入数据,并且具有相同顺序的方差。 如果输入变量的值范围是1到10,其他变量的值范围是4000到700,000,则第二个输入变量值将占主导地位,并且该算法将无法正确地从其他功能中学习。
In this article, I will illustrate the effect of scaling the input variables with different scalers in scikit-learn and three different regression algorithms.
在本文中,我将说明在scikit-learn中使用不同的缩放器和三种不同的回归算法来缩放输入变量的效果。
In the below code, we import the packages we will be using for the analysis. We will create the test data with the help of make_regression
在下面的代码中,我们导入将用于分析的软件包。 我们将在make_regression的帮助下创建测试数据
from sklearn.datasets import make_regressionimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import *from sklearn.linear_model import*We will use the sample size of 100 records with three independent (input) variables. Further, we will inject three outliers using the method “np.random.normal”
我们将使用100个记录的样本大小以及三个独立的(输入)变量。 此外,我们将使用“ np.random.normal”方法注入三个异常值
X, y, coef = make_regression(n_samples=100, n_features=3,noise=2,tail_strength=0.5,coef=True, random_state=0)X[:3] = 1 + 0.9 * np.random.normal(size=(3,3))y[:3] = 1 + 2 * np.random.normal(size=3)We will print the real coefficients of the sample datasets as a reference and compare with predicted coefficients.
我们将打印样本数据集的实际系数作为参考,并与预测系数进行比较。
print("The real coefficients are ". coef)
We will train the algorithm with 80 records and reserve the remaining 20 samples unseen by the algorithm earlier for testing the accuracy of the model.
我们将使用80条记录来训练该算法,并保留该算法之前看不到的其余20个样本,以测试模型的准确性。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20,random_state=42)We will study the scaling effect with the scikit-learn StandardScaler, MinMaxScaler, power transformers, RobustScaler and, MaxAbsScaler.
我们将使用scikit-learn StandardScaler,MinMaxScaler,电源变压器,RobustScaler和MaxAbsScaler研究缩放效果。
regressors=[StandardScaler(),MinMaxScaler(),PowerTransformer(method='yeo-johnson'),RobustScaler(quantile_range=(25,75)),MaxAbsScaler()]All the regression model we will be using is mentioned in a list object.
我们将使用的所有回归模型都在列表对象中提到。
models=[Ridge(alpha=1.0),HuberRegressor(),LinearRegression()]In the code below, we scale the training and test sample input variable by calling each scaler in succession from the regressor list defined earlier. We will draw a scatter plot of the original first input variable and scaled the first input variable to get an insight on various scaling. We see each of these plots little later in this article.
在下面的代码中,我们通过从先前定义的回归列表中依次调用每个缩放器来缩放训练和测试样本输入变量。 我们将绘制原始第一个输入变量的散点图,并缩放第一个输入变量,以了解各种缩放比例。 我们将在本文的稍后部分看到这些图。
Further, we fit each of the models with scaled input variables from different scalers and predict the values of dependent variables for test sample dataset.
此外,我们使用来自不同缩放器的缩放输入变量拟合每个模型,并预测测试样本数据集的因变量值。
for regressor in regressors: X_train_scaled=regressor.fit_transform(X_train) X_test_scaled=regressor.transform(X_test) Scaled =plt.scatter(X_train_scaled[:,0],y_train, marker='^', alpha=0.8) Original=plt.scatter(X_train[:,0],y_train) plt.legend((Scaled, Original),('Scaled', 'Original'),loc='best',fontsize=13) plt.xlabel("Feature 1") plt.ylabel("Train Target") plt.show() for model in models: reg_lin=model.fit(X_train_scaled, y_train) y_pred=reg_lin.predict(X_test_scaled) print("The calculated coeffiects with ", model , "and", regressor, reg_lin.coef_)Finally, the predicted coefficients from the model fit are printed for the comparison with real coefficients.
最后,打印来自模型拟合的预测系数,以便与实际系数进行比较。


On first glance itself, we can deduce that same regression estimator predicts different values of the coefficients based on the scalers.Predicted coefficients with MaxAbsScaler and MinMax scaler is quite far from true coefficient values.We can see the importance of appropriate scalers in the prediction accuracy of the model from this example.
乍一看,我们可以推断出相同的回归估计器基于缩放器预测系数的不同值。使用MaxAbsScaler和MinMax缩放器预测的系数与真实系数值相差很远,我们可以看到合适的缩放器在预测精度中的重要性。此示例中的模型。
As a self-exploration and learning exercise, I will encourage you all to calculate the R2 score and Root Mean Square Error (RMSE) for each of the training and testing set combination and compare it with each other.
作为一项自我探索和学习的练习,我鼓励大家为每种训练和测试集组合计算R2得分和均方根误差(RMSE),并将其相互比较。
Now that we understand the importance of scaling and selecting suitable scalers, we will get into the inner working of each scaler.
现在我们了解了缩放和选择合适的缩放器的重要性,我们将深入研究每个缩放器的内部工作。
Standard Scaler: It is one of the popular scalers used in various real-life machine learning projects. The mean value and standard deviation of each input variable sample set are determined separately. It then subtracts the mean from each data point and divides by the standard deviation to transforms the variables to zero mean and standard deviation of one. It does not bound the values to a specific range, and it can be an issue for a few algorithms.
Standard Scaler:它是在各种现实机器学习项目中使用的流行缩放器之一。 每个输入变量样本集的平均值和标准偏差分别确定。 然后,它从每个数据点减去平均值,然后除以标准差,以将变量转换为零均值和标准差为1。 它不会将值限制在特定范围内,并且对于某些算法而言可能是个问题。

MinMax Scaler: All the numeric values scaled between 0 and 1 with a MinMax Scaler
MinMax Scaler:使用MinMax Scaler在0到1之间缩放所有数值
Xscaled= (X-Xmin)/(Xmax-Xmin)
Xscaled =(X-Xmin)/(Xmax-Xmin)
MinMax scaling is quite affected by the outliers. If we have one or more extreme outlier in our data set, then the min-max scaler will place the normal values quite closely to accommodate the outliers within the 0 and 1 range. We saw earlier that the predicted coefficients with MinMax scaler are approximately three times the real coefficient. I will recommend not to use MinMax Scaler with outlier dataset.
MinMax缩放比例受异常值的影响很大。 如果我们在数据集中有一个或多个极端离群值,则最小-最大缩放器将非常接近地放置正常值以适应0和1范围内的离群值。 前面我们看到,用MinMax缩放器预测的系数大约是实际系数的三倍。 我建议不要对异常数据集使用MinMax Scaler 。

Robust Scaler- Robust scaler is one of the best-suited scalers for outlier data sets. It scales the data according to the interquartile range. The interquartile range is the middle range where most of the data points exist.
稳健的缩放器-稳健的缩放器是离群数据集最适合的缩放器之一。 它根据四分位数范围缩放数据。 四分位数范围是存在大多数数据点的中间范围。
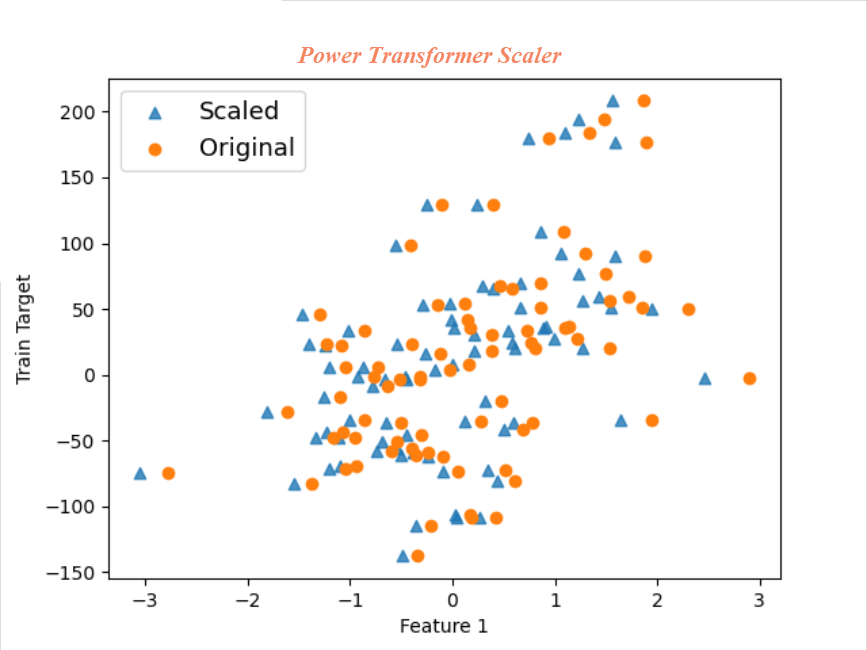
Power Transformer Scaler: Power transformer tries to scale the data like Gaussian. It attempts optimal scaling to stabilize variance and minimize skewness through maximum likelihood estimation. Sometimes, Power transformer fails to scale Gaussian-like results hence it is important to check the plot the scaled data
电力变压器缩放器:电力变压器尝试缩放像高斯这样的数据。 它尝试最佳缩放以通过最大似然估计来稳定方差并使偏斜最小化。 有时,电源变压器无法缩放类似高斯的结果,因此检查绘图的缩放数据很重要
MaxAbs Scaler: MaxAbsScaler is best suited to scale the sparse data. It scales each feature by dividing it with the largest maximum value in each feature.
MaxAbs Scaler: MaxAbsScaler最适合缩放稀疏数据。 它通过将每个特征除以每个特征中的最大值来缩放每个特征。

For example, if an input variable has the original value [2,-1,0,1] then MaxAbs will scale it as [1,-0.5,0,0.5]. It divided each value with the highest value i.e. 2. It is not advised to use with large outlier dataset.
例如,如果输入变量的原始值为[2,-1,0,1],则MaxAbs会将其缩放为[1,-0.5,0,0.5]。 它将每个值除以最高值,即2。不建议将其用于大型离群数据集。
We have learnt that scaling the input variables with suitable scaler is as vital as selecting the right machine learning algorithm. Few of the scalers are quite sensitive to outlier dataset, and others are robust. Each of the scalers in Scikit-Learn has its strengths and limitations, and we need to be mindful of it while using it.
我们已经知道,使用合适的缩放器缩放输入变量与选择正确的机器学习算法一样重要。 很少有缩放器对异常数据集非常敏感,而其他缩放器则很健壮。 Scikit-Learn中的每个定标器都有其优势和局限性,我们在使用它时需要谨记。
It also highlights the importance of performing the exploratory data analysis (EDA) initially to identify the presence or absence of outliers and other idiosyncrasies which will guide the selection of appropriate scaler.
它还强调了首先进行探索性数据分析(EDA)的重要性,以识别异常值和其他特质的存在与否,这将指导选择合适的定标器。
In my article, 5 Advanced Visualisation for Exploratory data analysis (EDA) you can learn more about this area.
在我的文章5探索性数据分析的高级可视化(EDA)中,您可以了解有关此领域的更多信息。
In case, you would like to learn a structured approach to identify the appropriate independent variables to make accurate predictions then read my article “How to identify the right independent variables for Machine Learning Supervised.
如果您想学习一种结构化的方法来识别适当的独立变量以做出准确的预测,然后阅读我的文章“如何为受监督的机器学习确定正确的独立变量” 。
"""Full Code"""from sklearn.datasets import make_regressionimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import *from sklearn.linear_model import*import matplotlib.pyplot as pltimport seaborn as snsX, y, coef = make_regression(n_samples=100, n_features=3,noise=2,tail_strength=0.5,coef=True, random_state=0)print("The real coefficients are ", coef)X[:3] = 1 + 0.9 * np.random.normal(size=(3,3))y[:3] = 1 + 2 * np.random.normal(size=3)X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.20,random_state=42)regressors=[StandardScaler(),MinMaxScaler(),PowerTransformer(method='yeo-johnson'),RobustScaler(quantile_range=(25, 75)),MaxAbsScaler()]models=[Ridge(alpha=1.0),HuberRegressor(),LinearRegression()]for regressor in regressors: X_train_scaled=regressor.fit_transform(X_train) X_test_scaled=regressor.transform(X_test) Scaled =plt.scatter(X_train_scaled[:,0],y_train, marker='^', alpha=0.8) Original=plt.scatter(X_train[:,0],y_train) plt.legend((Scaled, Original),('Scaled', 'Original'),loc='best',fontsize=13) plt.xlabel("Feature 1") plt.ylabel("Train Target") plt.show() for model in models: reg_lin=model.fit(X_train_scaled, y_train) y_pred=reg_lin.predict(X_test_scaled) print("The calculated coeffiects with ", model , "and", regressor, reg_lin.coef_)翻译自: https://towardsdatascience.com/feature-scaling-effect-of-different-scikit-learn-scalers-deep-dive-8dec775d4946
网页缩放与窗口缩放
http://www.taodudu.cc/news/show-997405.html
相关文章:
- 未越狱设备提取数据_从三星设备中提取健康数据
- 分词消除歧义_角色标题消除歧义
- 在加利福尼亚州投资于新餐馆:一种数据驱动的方法
- 近似算法的近似率_选择最佳近似最近算法的数据科学家指南
- 在Python中使用Seaborn和WordCloud可视化YouTube视频
- 数据结构入门最佳书籍_最佳数据科学书籍
- 多重插补 均值插补_Feature Engineering Part-1均值/中位数插补。
- 客户行为模型 r语言建模_客户行为建模:汇总统计的问题
- 多维空间可视化_使用GeoPandas进行空间可视化
- 机器学习 来源框架_机器学习的秘密来源:策展
- 呼吁开放外网_服装数据集:呼吁采取行动
- 数据可视化分析票房数据报告_票房收入分析和可视化
- 先知模型 facebook_Facebook先知
- 项目案例:qq数据库管理_2小时元项目:项目管理您的数据科学学习
- 查询数据库中有多少个数据表_您的数据中有多少汁?
- 数据科学与大数据技术的案例_作为数据科学家解决问题的案例研究
- 商业数据科学
- 数据科学家数据分析师_站出来! 分析人员,数据科学家和其他所有人的领导和沟通技巧...
- 分析工作试用期收获_免费使用零编码技能探索数据分析
- 残疾科学家_数据科学与残疾:通过创新加强护理
- spss23出现数据消失_改善23亿人口健康数据的可视化
- COVID-19研究助理
- 缺失值和异常值的识别与处理_识别异常值-第一部分
- 梯度 cv2.sobel_TensorFlow 2.0中连续策略梯度的最小工作示例
- yolo人脸检测数据集_自定义数据集上的Yolo-V5对象检测
- 图深度学习-第2部分
- 量子信息与量子计算_量子计算为23美分。
- 失物招领php_新奥尔良圣徒队是否增加了失物招领?
- 客户细分模型_Avarto金融解决方案的客户细分和监督学习模型
- 梯度反传_反事实政策梯度解释
网页缩放与窗口缩放_功能缩放—不同的Scikit-Learn缩放器的效果:深入研究相关推荐
- 网页缩放与窗口缩放_为什么即使缩放会议说加密会议也没有加密?
网页缩放与窗口缩放 缩放加密 (Zoom Encryption) End-to-end encryption on Zoom is what the world is criticising Zoom ...
- win32 禁用缩放功能_Firefox 73 将引入全局缩放功能,在所有网站都可适用
Firefox 好久都没有用过了,刚刚无意中刷到又有新版本更新了(Firefox 73),好像很厉害的样子分享给大家. Firefox 用户可能很快就能在浏览器中为所有网站设置全局缩放级别.目前,用户 ...
- Android 百度地图开发(三)--- 实现比例尺功能和替换自带的缩放组件
转载请注明出处:http://blog.csdn.net/xiaanming/article/details/11821523 貌似有些天没有写博客了,前段时间在忙找工作的事,面试了几家公司,表示反响 ...
- 微信公众平台后台编辑器上线图片缩放和封面图裁剪功能
今日,微信公众平台后台编辑器又上线了两个更新,图片缩放和封面图裁剪功能,微信团队真喜欢深夜放毒,不想让人睡的节奏.[微信公众平台编辑器可以剪裁和替换正文图片了] 两个新增的功能如下 1.图片缩放 插入 ...
- 点击图片放大,实现移动端双指缩放,单指拖拽功能
记录一下最近项目中用到的点击图片出现一个遮罩层,同时放大图片显示,移动端可双指缩放图片并单指拖拽图片.再次点击遮罩层透明区域,遮罩层消失 一.实现效果: 页面原图展示: 点击图片后: 二.代码实现: ...
- Vue 实现移动端在线选座功能(支持miniMap,支持缩放)
Vue 实现在线选座功能(支持miniMap,支持缩放) 前言 一.功能介绍 二.选座页面效果 三.实现原理 布局设计方面 交互实现方面 四.在线例子 总结 前言 前段时间写了一个在线选座功能,现在分 ...
- html5图片裁剪控件原型【含缩放,旋转,拖动功能】---2、核心代码
推荐 这一篇文章是早年为了解决图片裁剪的探索性文章,现在已经开放出了falsh版及html5版本的图片裁剪插件,各位有时间可以看看: 浮士德html5图片裁剪器2016开源版 浮士德头像裁剪flash ...
- abaqus质量缩放系数取值_后处理时的变形缩放系数
用户在后处理模块显示分析结果时,有时会发现模型的位移量很大,与预期的情况不符,仔细检查模型,没有发现任何问题,这究竟是什么原因造成的呢? 当发现位移或变形异常时,应首先查看视窗底部所显示的变形缩放系数 ...
- html苹果怎么缩放,iPhone手机屏幕变大了怎么办?iPhone设置屏幕缩放的方法
有的小伙伴在玩 iPhone 手机时,可能由于一时不小心,打开 iPhone 上的缩放功能,然后又不小心触发了这个功能,使得屏幕的图标变大了.如果当前是在锁屏输入密码的时候触发了放大的话,会导致输入密 ...
最新文章
- HRNet-Facial-Landmark-Detection 人脸关键点
- Interview:算法岗位面试—10.29下午上海某电子(偏传统ML算法,外企)数据结构算法+晚上国内某保险公司(偏AI算法,世界500强)技术面试之分类算法、回归算法、聚类算法等细节考察
- linux deb文件安装_如何在 Ubuntu 上安装 VirtualBox | Linux 中国
- Sublime Text 2 代码片断
- 下午回来才后知百密于一疏忽
- 人工智能(1)---从0开始搭建产品经理的AI认知体系
- AttributeError: 'dict' object has no attribute 'iteritems' .iteritems(): 修改为items()
- html中的a标签、img标签、iframe标签、列表标签
- lombok slfj 中_lombok @Slf4j注解
- Linux_free(buffer与cache区别)
- 飞机大战小游戏2.0
- 【C语言函数调用详解】——传值调用传址调用
- 模式识别算法:SVM支持向量机
- 射频功率dbm-w换算表
- SVO 论文与代码分析总结
- 使用OpenCV合成训练图片,同时生成labelme兼容格式的标注文件
- 台式计算机文件打不开怎么回事,电脑打不开文件是怎么回事 电脑打不开文件是什么原因...
- C++ 11中的Lambda表达式
- java pdf域插入img_java实现在pdf模板的指定位置插入图片
- 用NEON intrinsic实现RGB转YUV420SP(NV12)