t-sql语句插入_T-SQL的本机大容量插入基础知识
t-sql语句插入
From troubleshooting many data flow applications designed by others, I’ve seen a common pattern of over complexity with many designs. Putting aside possible risks by introducing too much complexity, troubleshooting these designs often involves opening many different applications – from a notepad file, to SSIS, to SQL Server Management Studio, to a script tool, etc. It may sound like many of these are doing a hundred steps, yet many times, they’re simply importing data from a file, or calling five stored procedures and then a file task of moving a file. This complexity is often unnecessary, as is opening many different tools when we can use a few tools and solve issues faster.
通过对其他人设计的许多数据流应用程序进行故障诊断,我发现许多设计都存在一种过度复杂的常见模式。 通过引入过多的复杂性来排除可能的风险,对这些设计进行故障排除通常涉及打开许多不同的应用程序-从记事本文件,SSIS,SQL Server Management Studio,脚本工具等。听起来好像其中许多正在做一百个步骤,但很多次,它们只是从文件中导入数据,或者调用五个存储过程,然后执行移动文件的文件任务。 这种复杂性通常是不必要的,因为当我们可以使用一些工具并更快地解决问题时,打开许多不同的工具也是如此。
In this part one of this series, we’ll look at a few of the options that we can specify when using BULK INSERT that may reduce our need to use other tools that introduce complex troubleshooting or involve opening multiple applications that aren’t needed. While there may be a time and place to use many tools for one task, we should take opportunities to reduce complexity if complex designs aren’t required or if the requirements allow for reduced tool use.
在本系列的第1部分中,我们将介绍一些在使用BULK INSERT时可以指定的选项,这些选项可能会减少我们使用其他工具的需求,这些工具会引入复杂的故障排除或涉及打开多个不需要的应用程序。 尽管可能有时间和地点将许多工具用于一项任务,但如果不需要复杂的设计或如果要求可以减少工具的使用,我们应该抓住机会降低复杂性。
Bulk Insert Basics With and Without Delimiters
带和不带分隔符的批量插入基础知识
If we’re importing data from a flat file, we may find that bulk insert provides us with a useful tool that we can use for importing the data. We’ll start with entire files that have no delimiters. In the below code snippet, we insert a SQL file of data (in this case, a query) and we’ll notice that we don’t specify any delimiters for rows or columns. The query below the code shows the result – all the data enter one column and one row, as our table is set to handle this amount of data (varchar-max can store up to 2GB of data).
如果要从平面文件导入数据,则可能会发现批量插入为我们提供了一个有用的工具,可用于导入数据。 我们将从没有定界符的整个文件开始。 在下面的代码片段中,我们插入一个数据SQL文件(在这种情况下为查询),我们会注意到我们没有为行或列指定任何分隔符。 代码下方的查询显示了结果–所有数据都输入一行和一行,因为我们的表已设置为处理此数据量(varchar-max最多可存储2GB数据)。
CREATE TABLE etlImport1(etlData VARCHAR(MAX)
)BULK INSERT etlImport1
FROM 'C:\ETL\Files\Read\Bulk\dw_query20180101.sql'SELECT * FROM etlImport1
We insert a SQL file of data, but we could have inserted a wide variety of files, such as text, configurations, etc. Provided that we don’t specify a delimiter for a row or column and the file is within the size allowed, bulk insert will add the data. If our table had a varchar specification of 1, the bulk insert would fail. We’ll see this example next – inserting the same file again in a new table that specifies a varchar of 1 character:
我们插入了一个数据SQL文件,但是我们可以插入各种各样的文件,例如文本,配置等。只要我们不为行或列指定分隔符,并且文件在允许的大小范围内,批量插入将添加数据。 如果我们的表的varchar规范为1,则批量插入将失败。 接下来,我们将看到此示例–将新文件再次插入到指定1个字符的varchar的新表中:
CREATE TABLE etlImport2(etlData VARCHAR(1)
)BULK INSERT etlImport2
FROM 'C:\ETL\Files\Read\Bulk\dw_query20180101.sql'
We will typically be inserting delimited files where characters specify new rows and columns. Delimiters can vary significantly from characters of the alphabet to special characters. Some of the most common characters in files that delimit data are commas, vertical bars, tab characters, new line characters, spaces, dollar or currency symbols, dashes, and zeros. When we specify row and column delimiters, we use the two specifications of FIELDTERMINATOR for the column delimiter and ROWTERMINATOR for the row delimiter. In the below file, our column delimiter is a comma while our row terminator is a vertical bar: our file will be a 3 column, 3 row table when inserted.
通常,我们将插入分隔的文件,其中字符指定新的行和列。 分隔符从字母字符到特殊字符可能有很大不同。 文件中用于分隔数据的一些最常见的字符是逗号,竖线,制表符,换行符,空格,美元或货币符号,破折号和零。 当指定行和列定界符时,我们将FIELDTERMINATOR的两个规范用作列定界符,将ROWTERMINATOR的两个规范用作行定界符。 在下面的文件中,我们的列定界符是逗号,而行终止符是竖线:插入后,我们的文件将是3列,3行的表格。
CREATE TABLE etlImport3(Column1 VARCHAR(1),Column2 VARCHAR(1),Column3 VARCHAR(1)
)BULK INSERT etlImport3
FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt'
WITH (FIELDTERMINATOR = ',',ROWTERMINATOR = '|'
)SELECT * FROM etlImport3
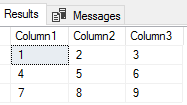
We’ll notice a couple of patterns:
我们会注意到两种模式:
- Our table is designed to only allow 1 character in each column. If the file had a comma-delimited column of 2 or more characters, we would get a truncation error like the one we saw above this. In some cases, developers will prefer to insert any data followed by cleaning the data. In other cases, developers will prefer to have errors thrown if the data don’t match the expectation 我们的表设计为每列只允许包含1个字符。 如果文件中的逗号分隔列包含2个或更多字符,则将出现截断错误,就像上面看到的一样。 在某些情况下,开发人员将更喜欢先插入任何数据,然后再清理数据。 在其他情况下,如果数据与预期不符,开发人员将更倾向于引发错误
- 1,2,3 (5 characters) and that exceeds the varchar of 1. Still, we could specify a vertical bar as the column delimiter, as the delimiters may be any number of characters, but we need to ensure that our table definition matches what we find in the file 1,2,3 (5个字符),并且超出了varchar的值1。竖线作为列定界符,因为定界符可以是任意数量的字符,但是我们需要确保表定义与文件中找到的定义匹配
In our next step, we’ll create a new table with three columns that has a varchar of 5 characters allowed and we’ll use the same file in our previous example, except we’ll specify vertical bars as the column delimiter without specifying a row delimiter (as this would exceed our file size).
在下一步中,我们将创建一个新表,该表具有三列,允许的varchar字符数为5个字符,并且在上一个示例中将使用相同的文件,除了我们将垂直条指定为列定界符而不指定行定界符(因为这会超出我们的文件大小)。
CREATE TABLE etlImport4(Column1 VARCHAR(5),Column2 VARCHAR(5),Column3 VARCHAR(5)
)BULK INSERT etlImport4
FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt'
WITH (FIELDTERMINATOR = '|'
)SELECT * FROM etlImport4
Since our columns in our new table support the length, we see the values inserted. But what would happen if we didn’t have the correct column alignment? We’ll look at this by adding a z character for a new row, but in our second row, only have one column of data 9,8,7 and try inserting it into the same table.
由于新表中的列支持该长度,因此可以看到插入的值。 但是,如果我们没有正确的列对齐会发生什么? 我们将通过在新行中添加z字符来进行查看,但是在第二行中,只有一列数据9,8,7,然后尝试将其插入同一张表中。
BULK INSERT etlImport4
FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt'
WITH (FIELDTERMINATOR = '|',ROWTERMINATOR = 'z'
)
As we see, our bulk insert experiences an abrupt end of line that doesn’t match the expected format of our table – even though the table expects three columns, the last line has one and ends. This error is thrown without any data being inserted. To get around this error, we need three columns in every line of data that matches our table format. Let’s correct this by adding 2 more columns of data so that our file’s column number matches the table specifications:
如我们所见,批量插入遇到的行尾突然与表的预期格式不匹配–即使该表需要三列,最后一行也有一行并结束。 在没有插入任何数据的情况下抛出此错误。 为了解决此错误,我们在与表格式匹配的每一行数据中都需要三列。 让我们通过添加2列数据来更正此问题,以使我们文件的列号与表规范匹配:
BULK INSERT etlImport4
FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt'
WITH (FIELDTERMINATOR = '|',ROWTERMINATOR = 'z'
)SELECT * FROM etlImport4
While we’re looking at a small file in this case – a file with 2 rows of data – these errors will help when you see them in a file with millions of lines and the delimited format doesn’t match. We can prevent bulk insert from throwing an error and terminating though, which we’ll do as an exercise, but if we don’t specify anything further, the expected behavior of bulk insert will be to throw an error without inserting data.
在这种情况下,我们正在查看的是一个小文件(一个包含2行数据的文件),当您在具有数百万行的文件中看到它们并且分隔格式不匹配时,这些错误将有所帮助。 我们可以通过练习来防止批量插入引发错误并终止操作,但是,如果我们不做进一步指定,批量插入的预期行为将是在不插入数据的情况下抛出错误。
We’ll add a new line of data to our file with the sentence of “Thisline|is|bad” after the z character that specifies a new line. We see that the sentence does match the character length in the first column even though it has the correct number of column delimiters.
我们将在指定新行的z字符后用“ Thisline | is | bad”的句子向数据添加新行。 我们看到该句子的确与第一列中的字符长度匹配,即使该句子具有正确的列定界符数量也是如此。
Instead of failing, we’ll have bulk insert add as much data as it can before it experiences an error. In the below code, we first truncate our table to empty it, bulk insert the data by allowing an error, and selecting from our table:
不会失败,我们将在发生错误之前将大量插入添加尽可能多的数据。 在下面的代码中,我们首先截断我们的表以清空它,通过允许一个错误批量插入数据,然后从我们的表中进行选择:
TRUNCATE TABLE etlImport4BULK INSERT etlImport4
FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt'
WITH (FIELDTERMINATOR = '|',ROWTERMINATOR = 'z',MAXERRORS = 1
)SELECT * FROM etlImport4
We get the first two rows of data and we see the failure from bulk insert because the first column in the third row exceeds the varchar character limit of 5. Relative to the format of the file (valid delimiters, even if the specifications may be wrong), we may still be able to pass on a few errors. We still wouldn’t get around an error if the file had lines that didn’t match the expected column number format (like the above example where a line of data has no delimiters when a number are expected). Do we always want to pass on a few errors and get all the data from a file? It depends on the context, though as a general rule, I view bad data as much more of a concern than no data, so I tend to keep bad data out of a table and review the file if an error is experienced. This may not be appropriate in all data contexts.
我们获得了数据的前两行,并且看到批量插入失败,因为第三行中的第一列超出了varchar字符限制5。相对于文件格式(有效的定界符,即使规范可能是错误的) ),我们仍然可以传递一些错误。 如果文件中的行与预期的列号格式不匹配,我们仍然不会遇到错误(例如,上面的示例,当期望一个数字时,数据行没有定界符)。 我们是否总是要传递一些错误并从文件中获取所有数据? 这取决于上下文,尽管作为一般规则,我认为不良数据比无数据更受关注,因此我倾向于将不良数据排除在表之外,如果遇到错误,则检查文件。 这可能不适用于所有数据上下文。
摘要 (Summary)
We’ve looked at using bulk insert for inserting an entire file of data, which may be useful in some contexts like storing configuration or code files for resource management and we’ve seen that we can store up to 2GB of data using the varchar maximum specification. We’ve also looked at inserting delimited data by specifying new columns and new rows and we’ve seen failures if a file doesn’t match this format. We’ve also looked at how to overcome some errors by specifying a maximum error amount that allows bulk insert to continue even if an error is experienced.
我们已经研究了使用批量插入来插入整个数据文件,这在某些情况下(例如存储配置文件或代码文件以进行资源管理)可能很有用,并且我们已经看到最大可以使用varchar来存储2GB的数据规范。 我们还研究了通过指定新的列和新的行来插入分隔的数据,并且我们发现如果文件与该格式不匹配,则会失败。 我们还研究了如何通过指定最大错误量来克服某些错误,该最大错误量即使在遇到错误时也允许批量插入。
目录 (Table of contents)
| T-SQL’s Native Bulk Insert Basics |
| Working With Line Numbers and Errors Using Bulk Insert |
| Considering Security with SQL Bulk Insert |
| SQL Bulk Insert Concurrency and Performance Considerations |
| Using SQL Bulk Insert With Strict Business Rules |
| T-SQL的本机大容量插入基础知识 |
| 使用批量插入处理行号和错误 |
| 考虑使用SQL批量插入的安全性 |
| SQL批量插入并发和性能注意事项 |
| 使用具有严格业务规则SQL批量插入 |
翻译自: https://www.sqlshack.com/t-sqls-native-bulk-insert-basics/
t-sql语句插入
t-sql语句插入_T-SQL的本机大容量插入基础知识相关推荐
- sql语句往某个字段指定位置追加或者插入值
sql语句往某个字段指定位置追加或者插入值 **业务场景:**需要对数据表中某个字段的值进行修改(对该字段的值进行插入字符串操作) 需要将materiel_features_pic字段值的'.png' ...
- mysql高效sql语句_高效SQL优化 非常好用的SQL语句优化34条
高效SQL优化 非常好用的SQL语句优化34条 相关软件相关文章发表评论 来源:2011/2/13 9:38:43字体大小: 作者:佚名点击:576次评论:0次标签: 类型:电子教程大小:8.5M语言 ...
- sql语句优化之SQL Server
MS SQL Server查询优化方法 查询速度慢的原因很多,常见如下几种 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成 ...
- mysql删除字段sql语句_用SQL语句添加删除修改字段
用SQL语句添加删除修改字段 1.增加字段 alter table docdsp add dspcode char(200) 2.删除字段 ALTER TABLE table_NAME DROP CO ...
- SQL语句学习之SQL基础的表创建以及添加数据
SQL语句学习之SQL基础的表创建以及添加数据 学习目标1: 一周内掌握SQL基础语句 tip:主要是在牛客网(牛客网)上进行练习,里面有在线编程,可以直接运行,而且有解题的思路,比较清晰,而且容易了 ...
- 在Oracle中不通过存储过程一次执行多条SQL语句Oracle PL/SQL
PL/SQL是ORACLE对标准数据库语言的扩展,ORACLE公司已经将PL/SQL整合到ORACLE 服务器和其他工具中了,近几年中更多的开发人员和DBA开始使用PL/SQL,本文将讲述PL/SQL ...
- Java中如何解析SQL语句、格式化SQL语句、生成SQL语句?
昨天在群里看到有小伙伴问,Java里如何解析SQL语句然后格式化SQL,是否有现成类库可以使用? 之前TJ没有做过这类需求,所以去研究了一下,并找到了一个不过的解决方案,今天推荐给大家,如果您正要做类 ...
- tp5获取sql_tp5 sql语句 tp5 获取sql语句
tp5 sql语句 tp5 获取sql语句以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧! sql语句转换成tp5执行,求 ...
- oracle 执行带参数的sql语句_Oracle动态SQL语句的简单执行
在使用ODP.NET进行Oracle编程时,有时候SQL语句非常复杂,需要采用动态构造查询语句的情况,有两种方法可以构造动态的SQL语句,并执行返回结果集. 1.在数据访问层构造SQL语句 例如下面的 ...
最新文章
- 吉特仓库管理系统-- 后台管理开源啦,源码大放送
- golang中的strings.HasPrefix
- oracle错误12518,ORA-12518: 错误 客户端连接不上
- sql 合并相同条件的字段
- hog特征提取python代码_hog特征提取-python实现
- 【转】超酷的 mip-infinitescroll 无限滚动(无限下拉)
- mysql 多表联合查询怎么一行显示_使用 explain 优化你的 mysql 性能
- 蓝桥杯 ADV-239 算法提高 P0102
- Java开发设计——UML类图
- VC知识库的离线包整合
- 单片机c32语言,单片机课件c32IO口.ppt
- Verilog学习笔记 (四)QPSK调制实现
- 数字图像处理 冈萨雷斯 (内含算法链接)
- icm20602姿态解算
- 传奇清理服务器信息,传奇行会信息等清除问题
- 达梦MPP 环境搭建
- 咸蛋超人的CxImage学习之路(一)
- python打印26个英文字母和数字
- php 可视化模板编辑,MetInfo
- 计算机应用系统统考配书光盘,统考配书光盘计算机应用基础使用手册