Spark SQL 1.3.0 DataFrame介绍、使用及提供了些完整的数据写入
问题导读
1.DataFrame是什么?
2.如何创建DataFrame?
3.如何将普通RDD转变为DataFrame?
4.如何使用DataFrame?
5.在1.3.0中,提供了哪些完整的数据写入支持API?

DataFrame

- # 从Hive中的users表构造DataFrame
- users = sqlContext.table("users")
- # 加载S3上的JSON文件
- logs = sqlContext.load("s3n://path/to/data.json", "json")
- # 加载HDFS上的Parquet文件
- clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
- # 通过JDBC访问MySQL
- comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
- # 将普通RDD转变为DataFrame
- rdd = sparkContext.textFile("article.txt") \
- .flatMap(lambda line: line.split()) \
- .map(lambda word: (word, 1)) \
- .reduceByKey(lambda a, b: a + b) \
- wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"])
- # 将本地数据容器转变为DataFrame
- data = [("Alice", 21), ("Bob", 24)]
- people = sqlContext.createDataFrame(data, ["name", "age"])
- # 将Pandas DataFrame转变为Spark DataFrame(Python API特有功能)
- sparkDF = sqlContext.createDataFrame(pandasDF)
复制代码
- # 创建一个只包含"年轻"用户的DataFrame
- young = users.filter(users.age < 21)
- # 也可以使用Pandas风格的语法
- young = users[users.age < 21]
- # 将所有人的年龄加1
- young.select(young.name, young.age + 1)
- # 统计年轻用户中各性别人数
- young.groupBy("gender").count()
- # 将所有年轻用户与另一个名为logs的DataFrame联接起来
- young.join(logs, logs.userId == users.userId, "left_outer")
复制代码
- young.registerTempTable("young")
- sqlContext.sql("SELECT count(*) FROM young")
复制代码
- # 追加至HDFS上的Parquet文件
- young.save(path="hdfs://path/to/data.parquet",
- source="parquet",
- mode="append")
- # 覆写S3上的JSON文件
- young.save(path="s3n://path/to/data.json",
- source="json",
- mode="append")
- # 保存为SQL表
- young.saveAsTable(tableName="young", source="parquet" mode="overwrite")
- # 转换为Pandas DataFrame(Python API特有功能)
- pandasDF = young.toPandas()
- # 以表格形式打印输出
- young.show()
复制代码
幕后英雄:Spark SQL查询优化器与代码生成
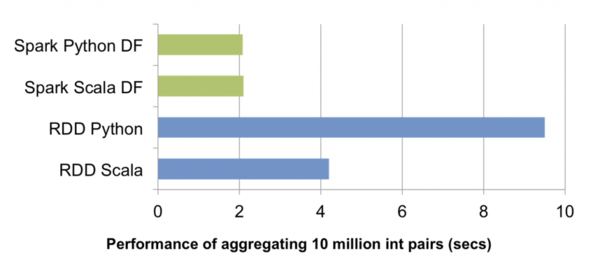
外部数据源API增强

数据写入支持
- CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
- <table-name> [(col-name data-type [, ...)]
- USING <source> [OPTIONS ...]
- [AS <select-query>]
复制代码
统一的load/save API
- rdd.saveAsParquetFile(...)
- rdd.saveAsTextFile(...)
- rdd.toJSON.saveAsTextFile(...)
- rdd.saveAsTable(...)
- ....
Parquet数据源增强
- // 创建两个简单的DataFrame,将之存入两个独立的分区目录
- val df1 = (1 to 5).map(i => (i, i * 2)).toDF("single", "double")
- df1.save("data/test_table/key=1", "parquet", SaveMode.Append)
- val df2 = (6 to 10).map(i => (i, i * 2)).toDF("single", "double")
- df2.save("data/test_table/key=2", "parquet", SaveMode.Append)
- // 在另一个DataFrame中引入一个新的列,并存入另一个分区目录
- val df3 = (11 to 15).map(i => (i, i * 3)).toDF("single", "triple")
- df3.save("data/test_table/key=3", "parquet", SaveMode.Append)
- // 一次性读入整个分区表的数据
- val df4 = sqlContext.load("data/test_table", "parquet")
- // 按分区进行查询,并展示结果
- val df5 = df4.filter($"key" >= 2) df5.show()
复制代码
- 6 12 null 2
- 7 14 null 2
- 8 16 null 2
- 9 18 null 2
- 10 20 null 2
- 11 null 33 3
- 12 null 36 3
- 13 null 39 3
- 14 null 42 3
- 15 null 45 3
复制代码
小结
Spark SQL 1.3.0 DataFrame介绍、使用及提供了些完整的数据写入相关推荐
- Spark SQL之RDD转DataFrame
准备文件 首先准备好测试文件info.txt,内容如下: 1,vincent,20 2,sarah,19 3,sofia,29 4,monica,26 将RDD转成DataFrame 方式一:反射 可 ...
- spark sql定义RDD、DataFrame与DataSet
RDD 优点: 编译时类型安全 编译时就能检查出类型错误 面向对象的编程风格 直接通过类名点的方式来操作数据 缺点: 序列化和反序列化的性能开销 无论是集群间的通信, 还是IO操作都需要对对象的结构和 ...
- spark sql 1.2.0 测试
1:启动shell master=spark://feng02:7077 ./bin/spark-shell [jifeng@feng02 spark-1.2.0-bin-2.4.1]$ master ...
- Spark SQL: Relational Data Processing in Spark
Spark SQL: Relational Data Processing in Spark Spark SQL : Spark中关系型处理模块 说明: 类似这样的说明并非是原作者的内容翻译,而是本篇 ...
- dataframe记录数_大数据系列之Spark SQL、DataFrame和RDD数据统计与可视化
Spark大数据分析中涉及到RDD.Data Frame和SparkSQL的操作,本文简要介绍三种方式在数据统计中的算子使用. 1.在IPython Notebook运行Python Spark程序 ...
- Spark Sql优化之3.0特性AQE
前言 这一篇来介绍Spark3.0版本中Spark Sql新增的重要特性AQE AQE全称Adaptive Query Execution,在3.0版本中主要包含以下三个功能 (1)Dynamical ...
- Spark15:Spark SQL:DataFrame常见算子操作、DataFrame的sql操作、RDD转换为DataFrame、load和save操作、SaveMode、内置函数
前面我们学习了Spark中的Spark core,离线数据计算,下面我们来学习一下Spark中的Spark SQL. 一.Spark SQL Spark SQL和我们之前讲Hive的时候说的hive ...
- Spark SQL应用解析
一 Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用 ...
- 「Spark从入门到精通系列」4.Spark SQL和DataFrames:内置数据源简介
来源 | Learning Spark Lightning-Fast Data Analytics,Second Edition 作者 | Damji,et al. 翻译 | 吴邪 大数据4年从业经 ...
最新文章
- 好渴望 wacom Intuos3
- 分布式事务 dtc 的使用
- Delphi中预想不到的代码楼主zswang(伴水清清)(专家门诊清洁工)2002-05-16 14:20:38 在 Delphi / VCL组件开发及应用 提问
- AI理论知识基础(23)-齐次坐标
- python编程规则_python编程规则
- 【报告分享】中国城市人工智能发展指数报告.pdf(附下载链接)
- 新西兰储备银行数据遭泄露
- java web开发需要学习哪些知识_java web开发需要学习哪些知识?
- 完全掌握1级日本与能力考试语法问题对策
- matplotlib plot 分组_Python数据分析模块二:Matplotlib
- 如何设置EditPlus的默认编码utf-8方式
- Euraka学习笔记
- ps打开曲线的快捷键,ps合并图层的快捷键,ps色相饱和度快捷键,组合键【CTRL】+【B】,该组合键是用于调整色彩平衡。
- 计算机word窗口的组成,word文件的组成
- 八月实施:电动自行车3c认证,电动自行车CCC认证费用周期,办理电动自行车ccc认证机构
- 英语口语收集(二十六)
- 性能测试---搬运自Performance Testing Guidance for Web Applications,作者J.D. Meier, Carlos Farre, Prashant Ban
- thinkpad t440安装os小记
- Oracle误删除表空间的恢复
- ICPR 2022 | 第一届卫星视频运动目标检测与跟踪挑战赛正式开赛