Kafka Consumer端的一些解惑
2019独角兽企业重金招聘Python工程师标准>>> 
最近一直忙着各种设计和文档,终于有时间来更新一点儿关于kafka的东西。之前有一篇文章讲述的是kafka Producer端的程序,也就是日志的生产者,这部分比较容易理解,业务系统将运行日志或者业务日志发送到broker中,由broker代为存储。那讲的是如何收集日志,今天要写的是如何获取日志,然后再做相关的处理。
之前写过kafka是讲日志按照topic的形式存储,一个topic会按照partition存在同一个文件夹下,目录在config/server.properties中指定,具体的存储规则可以查看之前的文章:
# The directory under which to store log files
log.dir=/tmp/kafka-logsConsumer端的目的就是为了获取log日志,然后做进一步的处理。在这里我们可以将数据的处理按照需求分为两个方向,线上和线下,也可以叫实时和离线。实时处理部分类似于网站里的站短,有消息了马上就推送到前端,这是一种对实时性要求极高的模式,kafka可以做到,当然针对站短这样的功能还有更好的处理方式,我主要将kafka线上消费功能用在了实时统计上,处理一些如实时流量汇总、各系统实时吞吐量汇总等。
这种应用,一般采用一个consumer中的一个group对应一个业务,配合多个producer提供数据,如下图模
式:

采用这种方式处理很简单,采用官网上给的例子即可解决,只是由于版本的问题,代码稍作更改即可:
package com.a2.kafka.consumer;import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.Message;
import kafka.message.MessageAndMetadata;public class CommonConsumer {public static void main(String[] args) {// specify some consumer propertiesProperties props = new Properties();props.put("zk.connect", "192.168.181.128:2181");props.put("zk.connectiontimeout.ms", "1000000");props.put("groupid", "test_group");// Create the connection to the clusterConsumerConfig consumerConfig = new ConsumerConfig(props);ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig);Map<String, Integer> map=new HashMap<String,Integer>();map.put("test", 2);// create 4 partitions of the stream for topic “test”, to allow 4 threads to consumeMap<String, List<KafkaStream<Message>>> topicMessageStreams = consumerConnector.createMessageStreams(map);List<KafkaStream<Message>> streams = topicMessageStreams.get("test");// create list of 4 threads to consume from each of the partitions ExecutorService executor = Executors.newFixedThreadPool(4);// consume the messages in the threadsfor(final KafkaStream<Message> stream: streams) {executor.submit(new Runnable() {public void run() {for(MessageAndMetadata<Message> msgAndMetadata: stream) {// process message (msgAndMetadata.message())System.out.println(msgAndMetadata.message());} }});}}
}这是一个user level的API,还有一个low level的API可以从官网找到,这里就不贴出来了。这个consumer是底层采用的是一个阻塞队列,只要一有producer生产数据,那consumer就会将数据打印出来,这是不是十分符合实时性的要求。
当然这里会产生一个很严重的问题,如果你重启一下上面这个程序,那你连一条数据都抓不到,但是你去log文件中明明可以看到所有数据都好好的存在。换句话说,一旦你消费过这些数据,那你就无法再次用同一个groupid消费同一组数据了。我已经把结论说出来了,要消费同一组数据,你可以采用不同的group。
简单说下产生这个问题的原因,这个问题类似于transaction commit,在消息系统中都会有这样一个问题存在,数据消费状态这个信息到底存哪里。是存在consumer端,还是存在broker端。对于这样的争论,一般会出现三种情况:
- At most once—this handles the first case described. Messages are immediately marked as consumed, so they can't be given out twice, but many failure scenarios may lead to losing messages.
- At least once—this is the second case where we guarantee each message will be delivered at least once, but in failure cases may be delivered twice.
- Exactly once—this is what people actually want, each message is delivered once and only once.
第一种情况是将消费的状态存储在了broker端,一旦消费了就改变状态,但会因为网络原因少消费信息,第二种是存在两端,并且先在broker端将状态记为send,等consumer处理完之后将状态标记为consumed,但也有可能因为在处理消息时产生异常,导致状态标记错误等,并且会产生性能的问题。第三种当然是最好的结果。
Kafka解决这个问题采用high water mark这样的标记,也就是设置offset:
Kafka does two unusual things with respect to metadata. First the stream is partitioned on the brokers into a set of distinct partitions. The semantic meaning of these partitions is left up to the producer and the producer specifies which partition a message belongs to. Within a partition messages are stored in the order in which they arrive at the broker, and will be given out to consumers in that same order. This means that rather than store metadata for each message (marking it as consumed, say), we just need to store the "high water mark" for each combination of consumer, topic, and partition. Hence the total metadata required to summarize the state of the consumer is actually quite small. In Kafka we refer to this high-water mark as "the offset" for reasons that will become clear in the implementation section.所以在每次消费信息时,log4j中都会输出不同的offset:
[FetchRunnable-0] INFO : kafka.consumer.FetcherRunnable#info : FetchRunnable-0 start fetching topic: test part: 0 offset: 0 from 192.168.181.128:9092[FetchRunnable-0] INFO : kafka.consumer.FetcherRunnable#info : FetchRunnable-0 start fetching topic: test part: 0 offset: 15 from 192.168.181.128:9092除了采用不同的groupid去抓取已经消费过的数据,kafka还提供了另一种思路,这种方式更适合线下的操作,镜像。
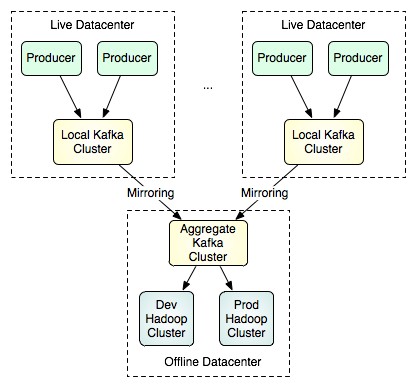
通过一些配置,就可以将线上产生的数据同步到镜像中去,然后再由特定的集群区处理大批量的数据,这种方式可以采用low level的API按照不同的partition和offset来抓取数据,以获得更好的并行处理效果。
转载于:https://my.oschina.net/ielts0909/blog/110280
Kafka Consumer端的一些解惑相关推荐
- Kafka consumer
Kafka consumer consumer概览 消费者组 消费者组定义:消费者使用一个消费者组名(即group.id)来标记自己,topic的每条消息都只会被发送到每个订阅它的消费者组的一个消费者 ...
- SAP Data Intelligence Modeler里的Kafka Producer和Kafka Consumer
首先本地将kafka的docker容器镜像下载到本地并运行: docker search kafka docker pull spotify/kafka docker run --name kafka ...
- kafka 服务端消费者和生产者的配置
在kafka的安装目录下,config目录下有个名字叫做producer.properties的配置文件 #指定kafka节点列表,用于获取metadata,不必全部指定 #需要kafka的服务器地址 ...
- 【kafka】Kafka consumer处理大消息数据过大导致消费停止问题
文章目录 1.概述 2.案例分析 3.kafka的设计初衷 3.1 broker 配置 3.2 Consumer 配置 M.扩展 1.概述 转载:https://www.cnblogs.com/wyn ...
- kafka服务端版本号0.10.2,客户端版本号2.0 如何发送消息
项目中用到kafka,应用作为生产者,发送消息时,报错: Magic v1 does not support record headers 网上也有很多同样的博客记录这个错误,如:https://zh ...
- Spring boot 项目Kafka Error connecting to node xxx:xxx Kafka项目启动异常 Failed to construct kafka consumer
Spring boot 项目Kafka Error connecting to node xxx:xxx Spring boot Kafka项目启动异常 新建了一个springBoot集成Kafka的 ...
- 吐血之作 | 流系统Spark/Flink/Kafka/DataFlow端到端一致性实现对比
长文预警, 全文两万五千多字, 37页word文档的长度 (略有杂乱,有些非常复杂的地方可能需要更多的例子来说明,使得初学者也能很容易看懂,但是实在花的时间已经太多太多了,留待后边利用起碎片时间一点点 ...
- 鉴权kafka生产端(SCRAM)
前言 kafka官网关于sasl_scram 鉴权Kafka消费端配置 创建SCRAM Credentials 依赖zk,需要先启动zk,然后在zk中创建存储SCRAM 凭证: cd kafkaclu ...
- kafka配置文件 中文乱码_使用kafka consumer api时,中文乱码问题
使用Intelli idea调试kafka low consumer时,由于broker存储的message有中文, idea中console端是可以正确显示的 然后mvn package打包到服务器 ...
最新文章
- 不用恐惧AI的高速发展,论击败阿法狗(零)最简单的方法
- 解决IDEA快捷键 Alt+Insert 失效的问题
- IE6下fixed失效的解决方法
- 芬兰高性能图表控件-免费试用并提供技术支持
- 去除标签_有效去除“狗皮膏药”标签,快学起来吧
- 深度学习训练出来的损失不收敛_学习率设置技巧,使用学习率来提升我们的模型...
- 可悲的外企Infrastructure - 些须感触(杂)
- SNMP学习(2)——SNMP实战
- Scrapy爬取起点小说网数据导入MongoDB数据库
- FAQ:sorry,too many clients already
- 核电工程能源行业案例 | 达索系统百世慧®
- 还在为 520 发愁吗?教你用 Python 写个表白神器
- python循环代码优化技巧_记一次优化python循环代码逻辑的过程
- i7-10700K和i7-9700KF哪个好
- 汪延谈王志东离职问题 (转)
- 计算机基础(笔记)——计算机网络(链路层)
- SQL查询cross join 的用法(笛卡尔积)
- css3实现border渐变色
- kiwix Android 地址,Kiwix 将Wikipedia下载到您的计算机或Android上以进行离线访问
- 做外贸究竟要怎么利用好海关数据?这里给你最好的方案