谷歌TPU研究论文:专注神经网络专用处理器
谷歌TPU研究论文:专注神经网络专用处理器
[纠错] 评论 投稿 订阅
导读: 在去年的谷歌 I/O 开发者大会上,谷歌宣布发布一款新的定制化硬件——张量处理器。但谷歌并没有披露相关成果的细节。近日,谷歌终于打破沉默,以及与其它硬件的比较。谷歌的硬件工程师 Norm Jouppi 也第一时间通过一篇论文介绍了这项研究的相关技术研究成果。文后摘取了原论文部分内容。
OFweek通信网讯 过去十五年里,我们一直在我们的产品中使用高计算需求的机器学习。机器学习的应用如此频繁,以至于我们决定设计一款全新类别的定制化机器学习加速器,它就是 TPU。
TPU 究竟有多快?今天,联合在硅谷计算机历史博物馆举办的国家工程科学院会议上发表的有关 TPU 的演讲中,我们发布了一项研究,该研究分享了这些定制化芯片的一些新的细节,自 2015 年以来,我们数据中心的机器学习应用中就一直在使用这些芯片。第一代 TPU 面向的是推论功能(使用已训练过的模型,而不是模型的训练阶段,这其中有些不同的特征),让我们看看一些发现:
● 我们产品的人工智能负载,主要利用神经网络的推论功能,其 TPU 处理速度比当前 GPU 和 CPU 要快 15 到 30 倍。
● 较之传统芯片,TPU 也更加节能,功耗效率(TOPS/Watt)上提升了 30 到 80 倍。
● 驱动这些应用的神经网络只要求少量的代码,少的惊人:仅 100 到 1500 行。代码以 TensorFlow 为基础。
● 70 多个作者对这篇文章有贡献。这份报告也真是劳师动众,很多人参与了设计、证实、实施以及布局类似这样的系统软硬件。
TPU 的需求大约真正出现在 6 年之前,那时我们在所有产品之中越来越多的地方已开始使用消耗大量计算资源的深度学习模型;昂贵的计算令人担忧。假如存在这样一个场景,其中人们在 1 天中使用谷歌语音进行 3 分钟搜索,并且我们要在正使用的处理器中为语音识别系统运行深度神经网络,那么我们就不得不翻倍谷歌数据中心的数量。
TPU 将使我们快速做出预测,并使产品迅速对用户需求做出回应。TPU 运行在每一次的搜索中;TPU 支持作为谷歌图像搜索(Google Image Search)、谷歌照片(Google Photo)和谷歌云视觉 API(Google Cloud Vision API)等产品的基础的精确视觉模型;TPU 将加强谷歌翻译去年推出的突破性神经翻译质量的提升;并在谷歌 DeepMind AlphaGo 对李世乭的胜利中发挥了作用,这是计算机首次在古老的围棋比赛中战胜世界冠军。
我们致力于打造最好的基础架构,并将其共享给所有人。我们期望在未来的数周和数月内分享更多的更新。
论文题目:数据中心的 TPU 性能分析(In-Datacenter Performance Analysis of a Tensor Processing Unit)

摘要:许多架构师相信,现在要想在成本-能耗-性能(cost-energy-performance)上获得提升,就需要使用特定领域的硬件。这篇论文评估了一款自 2015 年以来就被应用于数据中心的定制化 ASIC,亦即张量处理器(TPU),这款产品可用来加速神经网络(NN)的推理阶段。TPU 的中心是一个 65,536 的 8 位 MAC 矩阵乘法单元,可提供 92 万亿次运算/秒(TOPS)的速度和一个大的(28 MiB)的可用软件管理的片上内存。相对于 CPU 和 GPU 的随时间变化的优化方法(高速缓存、无序执行、多线程、多处理、预取……),这种 TPU 的确定性的执行模型(deterministic execution model)能更好地匹配我们的神经网络应用的 99% 的响应时间需求,因为 CPU 和 GPU 更多的是帮助对吞吐量(throughout)进行平均,而非确保延迟性能。这些特性的缺失有助于解释为什么尽管 TPU 有极大的 MAC 和大内存,但却相对小和低功耗。我们将 TPU 和服务器级的英特尔 Haswell CPU 与现在同样也会在数据中心使用的英伟达 K80 GPU 进行了比较。我们的负载是用高级的 TensorFlow 框架编写的,并是用了生产级的神经网络应用(多层感知器、卷积神经网络和 LSTM),这些应用占到了我们的数据中心的神经网络推理计算需求的 95%。尽管其中一些应用的利用率比较低,但是平均而言,TPU 大约 15-30 倍快于当前的 GPU 或者 CPU,速度/功率比(TOPS/Watt)大约高 30-80 倍。此外,如果在 TPU 中使用 GPU 的 GDDR5 内存,那么速度(TOPS)还会翻三倍,速度/功率比(TOPS/Watt)能达到 GPU 的 70 倍以及 CPU 的 200 倍。
选自 Google Drive
作者:Norman P. Jouppi 等
痴笑@矽说 编译
该论文将正式发表于 ISCA 2017
从去年七月起,Google就号称了其面向深度学习的专用集成电路(ASIC)产品——Tensor Processing Unit (TPU),然而其神秘面纱一直未被揭开。直至本周,Google公开了其向ISCA(国际计算机体系架构年会)投稿的的预录取论文——In Datacenter Performance Analysis of a Tensor Processing Unit,TPU的技术细节才公开发表,令我们才有幸见识其真面目。虽然可能只是“犹抱琵琶半遮面”,但其作为CPU/GPU/FPGA后的另一深度学习选项,特别是TPU和tensorflow间可能存在的微妙联系值得我们特别关注。矽说在第一时间选编、翻译了其中的重要部分,以飨读者。
论文地址:(需翻墙)
https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view
前言
文章具体描述了Tensor Processing Unit (TPU)的体系结构,并与目前主流的CPU(Intel Haswell Xeon)和GPU(Nvidia K80)的性能做出了比较,采用的benchmark包含了CNN,RNN(LSTM)和全链接(MLP)神经网络。其特点包括:
(1) 面向inference的专用app与硬件,强调了吞吐率上的性能
(2) TPU的不仅在面积和功耗上低于GPU,而且在乘累加的数量和存储器容量是K80的25倍和3.5倍
(3) TPU的速度上的优势明显,达到GPU和CPU的15到30倍
(4) 在6个NN架构中,4种神经网络的性能瓶颈在于存储器带宽。若存储器带宽达到K80的性能,作者相信性能能提升到30到50倍
(5) TPU的能效值(TOPS/W)达到在目前其他产品的30到80倍
(6) CNN在TPU中工作量的比列只有5%
起源、架构与实现
早在2006年开始,Google就开始讨论在数据中心部署GPU,FPGA或定制ASIC。在2013年,当DNN已经展露头脚,以致可能会使我们的数据中心的计算需求加倍时,传统的CPU已经被认为不合时宜了。因此,我们开始了一个高度优先的项目,以快速生成用于Inference的定制ASIC,(训练仍使用GPU)。 目标是将性能提升10倍以上。 根据这一任务,Google的TPU的设计和验证在短短15个月内完成,并构建并部署在数据中心。
而不是与CPU紧密集成,为了减少延迟部署的可能性,TPU被设计为PCIe I/O总线上的协处理器,允许它像GPU那样插入现有的服务器。 此外,为了简化硬件设计和调试,主机服务器发送TPU指令来执行,而不是自己提取它们。 因此,TPU在精神上比FPU(浮点单元)协处理器更接近于GPU。
TPU的目标是运行整体深度学习的神经网络模型,以减少与主机CPU的交互,并且具有足够的灵活性,以满足2015年及其后的NN需求,而不仅仅是2013年NN所需。
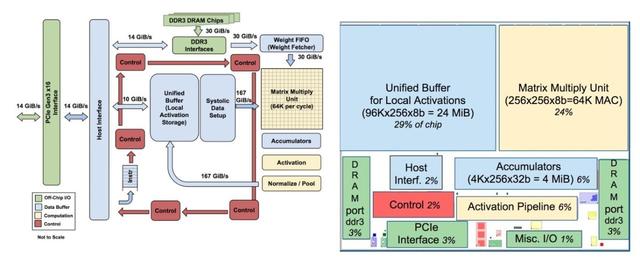
图1是TPU的整体体系架构。TPU指令通过PCIe Gen3 x16总线从主机发送到指令缓冲区。 内部块通常通过256字节宽的路径连接在一起。 从右上角开始,Matrix Multiply Unit是TPU的核心。 它包含256x256个乘累加单元(MAC),可以对有符号或无符号整数执行8位乘法和加法。 求和单元(Accumulator)的输入为16位乘积,输出和的位宽为32,共有4906个,每个的输入个数为256。 因此,矩阵单元每个时钟周期产生一个256元素的部分和。
当使用8位权重和16位激活函数的混合计算结构时,MMU的计算速度将减半,当它们都是16位,计算速度将减为四分之一。 它每个时钟周期读取和写入256个值,并且可以执行矩阵乘法或卷积。 矩阵单元采用两个64KiB的权重tile的双缓冲设计,其中的一个仅在非稀疏模式下才会被激活,这样就提升了TPU对于稀疏网络的性能支持。Google相信稀疏性将在未来的设计中占有优先地位。
矩阵单元的权重通过片上Weight FIFO进行分级,该FIFO从片外8 GiB DRAM读取(在inference中,权重是只读的)。Weight FIFO存储了四个4个tile。 中间结果保存在24 MiB片上Unified Buffer中,可作为未来的Matrix单元的输入。 可编程DMA控制器向CPU主机内存和Unified Buffer传输数据。
图2显示了TPU芯片的布局图。 24 MiB Unified Buffer几乎是芯片的三分之一,Matrix Multiply Unit是四分之一,因此数据路径占到了整个芯片的三分之二。由于开发时间短,部分设计选取了简单的值以简化编译器设计。 控制逻辑占到总面积的只有2%。 图3显示了搭载在PCB上的TPU实现图,期接口类似SATA磁盘,可通过PCIe直接接入数据中心。
TPU的指令是通过PCI额发射的,遵循CISC传统,包括重复字段。 这些CISC指令的每个指令的平均时钟周期(CPI)在10到20之间。它总共有大约十多个指令,这里罗列最关键的五个:
(1) Read_Host_Memory
(2) Read_Weights
(3) MatrixMultiply/Convolve
(6) Activation
(5) Write_Host_Memory
其他指令是备用主机内存读/写,设置配置,两个版本的同步,中断主机,调试Jtag,空操作和停止。 CISC MatrixMultiply指令为12个字节,其中3个为Unified Buffer地址; 2是累加器地址; 4是长度(有时是卷积的2个维度); 其余的是操作码和标志。TPU微架构的理念是保持MMU的繁忙。 因此,MMC的CISC指令使用4级流水线结构,其中每条指令在其中的单独一级执行。 其目标是通过将其执行与MatrixMultiply指令重叠来隐藏其他指令(如Read_Weights等)。但,当激活的输入或权重数据尚未就绪,矩阵单元将进入等待模式。
由于读取大型SRAM数据的功耗比算术功耗高的多,所以MMU通过systolic方式减少对Unified Buffer的方位,节省功耗。 图4显示了TPU数据流程,输入从左侧流入,权重从顶部加载。 给定的256元乘法累加运算通过矩阵作为对角波前移动。 此过程中权重是预先加载的,并且与数据同步。通过对控制逻辑和数据流水线操作,使得对于MMU而言,256个输入一次读取的,并且它们立即更新到256个累加器中的一个个具体位置。 从正确的角度来看,软件不知道硬件的systoli特性,但是却需要对于systoilc引起的延时效果有正确的评估。
TPU软件堆栈必须与为CPU和GPU开发的软件栈兼容,以便应用程序可以快速移植到TPU。在TPU上运行的应用程序的一部分通常写在TensorFlow中,并被编译成可以在GPU或TPU上运行的API。像GPU一样,TPU堆栈分为用户空间驱动程序和内核驱动程序。内核驱动程序是轻量级的且长期稳定的,只处理内存管理和中断。用户空间驱动程序频繁更改。它设置和控制TPU执行,将数据重新格式化为TPU命令,将API调用转换为TPU指令,并将其转换为应用程序二进制文件。用户空间驱动程序在首次评估模型时编译模型,缓存程序映像并将重量映像写入TPU的重量存储器; 第二次和以下评估全速运行。 对于大部分模型,TPU可以从输入到输出完整实现。实际操作中,同一时间通常每次进行一层的MMC计算,而其非关键路径操作将被隐藏在MMU操作下。
CPU、GPU与TPU的性能比较
在TPU与CPU和GPU的性能比较部分,Google选择了两款并非最新但具有代表性的平台——Intel Haswell架构的Xeon 5处理器和Nvidia的K80处理器,其集成板卡后的性能对比如下:
以MLP0为例子,7ms的反应时间内TPU可得到的数据处理吞吐率是CPU和GPU的数十倍(但值得指出的是,该benchmark下TPU的计算占用率要远远高于GPU和CPU)。
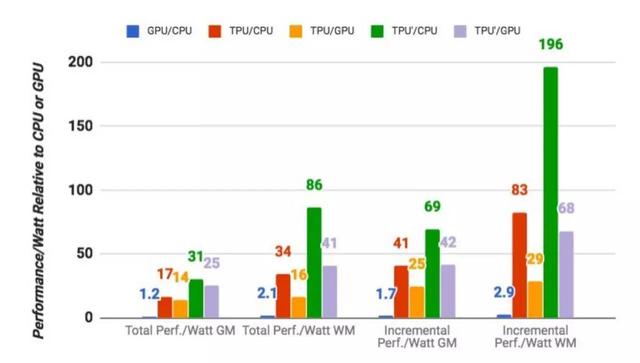
图9将K80 GPU和TPU相对于Haswell CPU的几何平均功耗性能进行了对比,包括两种计算量程——第一个是“总计”性能/瓦,包括在计算GPU和TPU的性能/瓦特时由主机CPU服务器消耗的功率。;第二个“增量”性能/瓦,仅包括预先从GPU和TPU中减去主机CPU服务器的电源余下的功耗。TPU服务器的总性能/瓦特比Haswell高出17到34倍,这使得TPU服务器的性能/ Katt服务器的功率是14到16倍。 TPU的相对增量性能/瓦特(Google致力于定制ASIC的核心价值)为41到83,这将TPU提升到GPU的性能/瓦特的25到29倍。
在去年5月中旬的Google I/O大会上,Google就已经透露了自己的Tensor Processing Unit(Tensor处理单元)处理器,简称TPU。但相关细节,Google却迟迟没有公布,直到这次TPU论文的发布。
TPU的最新细节
首先需要指出,TPU是一个人工智能技术专用处理器,在种类上归属于ASIC(Application Specific Integrated Circuit,为专门目的而设计的集成电路)。
相比人工智能技术常见的另外几种处理器CPU(中央处理器)、GPU(图像处理器)、FPGA(阵列可编程逻辑门阵列),ASIC天生就是为了应用场景而生,所以在性能表现和工作效率上都更加突出。以下是Google硬件工程师 Norm Jouppi 在Google云计算博客上透露的部分性能信息:
1、在神经网络层面的操作上,处理速度比当下GPU和CPU快15到30倍;
2、在能效比方面,比GPU和CPU高30到80倍;
3、在代码上也更加简单,100到1500行代码即可以驱动神经网络;
这要归功于ASIC本身的特点:处理器的计算部分专门为目标数据设计,100%利用;不需要考虑兼容多种情况,控制配套结构非常简单,间接提升了能效比;可以在硬件层面对软件层面提前进行优化,优化到位的情况下可以极大减少API接口的工作量。
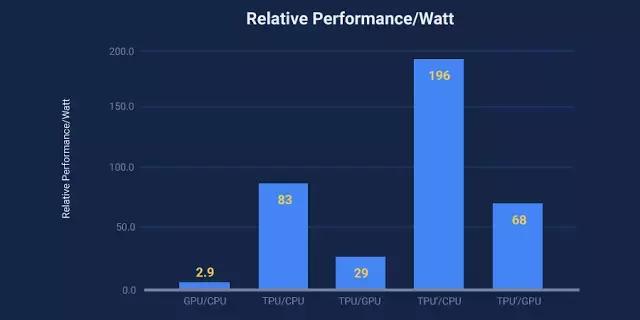
Google也专门对比了在人工智能场景下TPU相对于CPU/GPU的能效比表现,不同颜色分别对应不同对比对象的结果(注:TPU'是改进版TPU)。可以看到GPU相对于CPU的领先倍数最多只有2.9,而TPU'对CPU的领先幅度已经达到了196倍,对GPU的领先幅度也达到了68倍。能效比上的突出表现也能直接进行转化,为用户带来更低的使用成本。
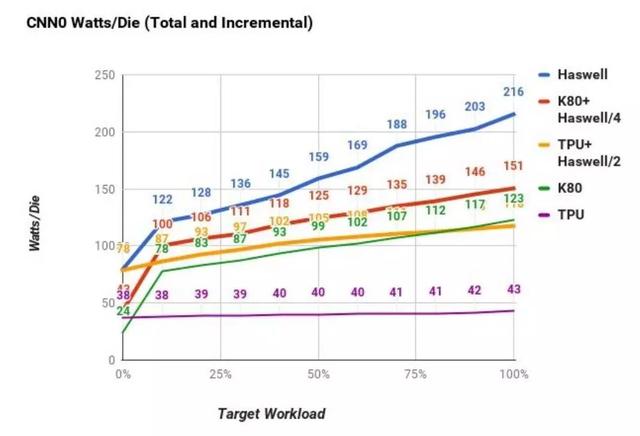
Google另外还对比了单芯片的平台单位功耗,可以看到TPU在计算任务逐渐加重情况下,功耗浮动不过10%左右。而单CPU服务器的功耗波动接近300%,绝对功耗数字的更高也让服务器需要配备更多散热资源,无形中也增加成本。

Google这次也公布了TPU的真实长相,通过板载的DDR3颗粒、PCIE接口可以看出实际尺寸并不算很大。PCB布局看上去也并不复杂,TPU在中间,上下是DDR3颗粒阵列,左侧是供电部分,右侧是剩余配套零件。
值得注意的是,Google还在论文中增加了一段描述:“这块电路板也可以安装在服务器预留的SATA盘位中,但是目前这款卡使用的是 PCIe Gen3 X16接口”。这一方面透露出了TPU的数据吞吐能力,同时也让人遐想,Google是否会尝试将其打造成更加通用化的硬件产品,比如适配SATA接口之后对外出售。
业内人士告诉你怎么看TPU
TPU一出,数倍于CPU、GPU的性能技惊四座。但也有业内人士向Xtecher说出了自己的看法:这个芯片没有什么太神奇的地方,虽然性能很惊艳,但是成本也会很高,而且目前TPU并不能单独使用,还是要配套CPU/GPU。

华登国际合伙人王林也在朋友圈贴出了自己的看法(Xtecher已经获得了许可):
1、芯片本身设计难度并不大,以floor plan看,data buffe加上乘加器阵列占了2/3面积,再去掉比较大的两个DDR3的PHY,一个PCIE Gen3 x16接口,控制电路只有2%。
2、为了降低功耗,提高性能,目前这款TPU的几个设计指导原则是:增加数据带宽,减少和host CPU的交互,不让乘加器阵列闲着。所以用了24MB的片上Memory,多DDR3接口用于数据交换,4阶CISC指令流水线保证MatrixMultiply优先级。带来的代价就是大的die size,主频不高。
3、考虑现有生态环境,TPU软件要和CPU/GPU兼容。
4、稀疏化应是TPU以后的开发重点,论文来头就提到压缩到8位整数用于inference已经足够好了。
5、这么贵的芯片,我也就是看看......
Xtecher也专门采访了国内创业公司纵目科技CEO唐悦:
这个东西实际跟视频解码一个道理,人工智能你能够拿CPU来做也可以拿GPU来做,当它算法相对固定之后,你就可以专门去打造专用硬件。实际上各种各样的东西都能够实现一个目标,问题在于灵活度和专业性两个方向如何把握。如果当前算法没有固定,那就应该多用CPU和GPU,如果算法固定了,那么就可以尝试打造专用芯片。而事实上,人工智能恰巧处于这两个方向的变化当中。
因为之前神经网络一直在变,完全可编程的GPU更加适合用来探索,CPU以为并行能力比较弱还是定位在通用处理器。但随着人工智能技术的推进,我们就能够根据目前人工智能的需求来专门打造芯片,它比本身为图像运算打造的GPU更加专注,自然效果更好。
这跟很多人现在用FPGA去运算也是一样的,因为专用的硬件比通用的硬件性能一定更好。反过来说,究竟这个负责人工智能的处理器叫什么完全没有所谓。同样的,这件事Google可以做,高通也在做,这并不是什么特别的神奇的东西。
Google自己怎么说?

去年年中,谷歌全球数据中心网络主管乌尔斯·霍勒泽(Urs H lzle)就曾在公开场合对TPU的一系列问题进行了公开解答:
Google今后还将研发更多这样的芯片。
Google不会把这种芯片出售给其他公司,不会直接与英特尔或NVIDIA进行竞争。但Google拥有庞大的数据中心,是这两家公司迄今为止最大的潜在客户。与此同时,随着越来越多的企业使用谷歌提供的云计算服务,它们自己购买服务器(和芯片)的数量就会越来越少,也就给芯片市场带来进一步的冲击。
TPU目前(当时)主要用来处理Android手机语音识别所需要的“一部分计算”。GPU已经在一点点出局。GPU太通用了,对于机器学习针对性不强。机器学习本来就不是GPU的设计初衷 。
之所以不采用更加方便的方式——直接在FPGA基础上固化算法,是因为ASIC快得多。
TPU背后的人工智能趋势?

既然TPU只不过是一颗带有人工智能“光环”的ASIC,那么它究竟反映出了什么趋势?
首先是专注人工智能领域硬件的市场巨大,虽然CPU/GPU已经提供了通用运算能力,但是性能更好,能效比更高的FPGA、ASIC需求日趋强烈。
二个是随着人工智能技术的进一步发展,硬件专业化趋势不可避免。就像比特币挖矿一样,主力挖矿设备从CPU到GPU,从GPU到FPGA,最后再到ASIC。
除了Google,很多公司其实也在进行着类似的专业化硬件开发工作,相信不久的将来,一大批专业化硬件的出现将会为人工智能的发展再次注入动力,促进更多应用场景和更优质服务的出现。
总的来看,TPU的确算是人工智能发展历程中的一个“小里程碑”,但真的没有什么好大惊小怪的。
谷歌TPU研究论文:专注神经网络专用处理器相关推荐
- 神经网络算法处理器设计,神经网络是机器算法吗
TCL电视神经网络处理器是什么? npu.1.tcl电视专攻NPU(神经网络处理器)的海思Hi3516DV300芯片是神经网络处理器.2.神经网络处理器,也就是通常说的AI处理器. 它可以是手机更聪明 ...
- 一周AI回顾 | 特斯拉AI负责人说神经网络正在改变编程,机器学习大神Bengio新论文专注RNN优化
本期一周AI看点包括行业热点.投融资.业界观点.技术前沿以及应用等方面. 行业 英特尔将同AMD合作PC芯片 共同对抗英伟达 <华尔街日报>援引知情人士的消息称,英特尔将发布一款移动处理器 ...
- 读论文——专用处理器比较分析
论文引用:鄢贵海, 卢文岩, 李晓维, 等. 专用处理器比较分析. 中国科学: 信息科学, 2022, 52: 358–375, doi: 10.1360/SSI-2021-0274 Yan G H, ...
- 傅里叶变换取代Transformer自注意力层,谷歌这项研究GPU上快7倍、TPU上快2倍
视学算法报道 转载自:机器之心 机器之心编辑部 来自谷歌的研究团队表明,将傅里叶变换取代 transformer 自监督子层,可以在 GLUE 基准测试中实现 92% 的准确率,在 GPU 上的训练时 ...
- 傅里叶变换才是本质?谷歌这项研究GPU上快7倍、TPU上快2倍
转载自:机器之心 来自谷歌的研究团队表明,将傅里叶变换取代 transformer 自监督子层,可以在 GLUE 基准测试中实现 92% 的准确率,在 GPU 上的训练时间快 7 倍,在 TPU 上的 ...
- 神经网络图谱研究进展论文,图神经网络研究方向
为什么有图卷积神经网络? 本质上说,世界上所有的数据都是拓扑结构,也就是网络结构,如果能够把这些网络数据真正的收集.融合起来,这确实是实现了AI智能的第一步. 所以,如何利用深度学习处理这些复杂的拓扑 ...
- 基于神经网络集成学习的5篇研究论文推荐
Evaluating Deep Neural Network Ensembles by Majority Voting cum Meta-Learning scheme https://arxiv.o ...
- 谷歌量子霸权论文;13项NLP任务夺冠的小模型ALBERT
机器之心整理 参与:一鸣.杜伟 本周重要论文很多,特别是谷歌的研究非常耀眼,有量子霸权论文和参数小 BERT 很多但性能超 XLNe 的模型 ALBERTt.此外还有北大等的论文. 目录: Gate ...
- 史上最快AI计算机发布!谷歌TPU V3的1/5功耗、1/30体积,首台实体机已交付
大数据文摘 昨天 大数据文摘作品 还记得8月份占据各家科技头条的有史以来最大芯片吗? 这个名为Cerebras Wafer Scale Engine(WSE)的"巨无霸"面积达到4 ...
最新文章
- Django学习笔记(5)---ForeignKey
- Linux防火墙详解(二)
- 【HTTP】之HTTP 错误 401.3 - 访问被资源 ACL 拒绝
- oracle带输出参数存储,oracle带输入输出参数存储过程(包括sql分页功能)
- python-1day
- redis单线程原理___Redis为何那么快-----底层原理浅析
- 【数字逻辑设计】基本逻辑门
- 万元华为旗舰新机超21万人预约,网友:有钱人真的多!
- Updates were rejected because the tip of your current branch is behind
- jquery选择器之过滤选择器
- 文本编辑框鼠标丢失问题
- 科学计算机要用的电池是几号,科学的使用笔记本电池操作指南_硬件教程
- python自动交易 缠论_缠论自动交易系统实现了
- JavaScript网页特效
- 【洞幺邦】基于python的咖啡店的销售额
- LigerUi中表(Grid)控件的相关属性笔记(持续添加中)
- oracle调用web severs,Oracle调用C#开发web services
- 聊聊ClickHouse中的低基数LowCardinality类型
- 带附件/密送/抄送的 javaMail 邮件发送 -- java_demo(两种实现方式)
- 编程马拉松(英语:hackathon,又译为黑客松)