讲解 Spatial Pyramid Pooling
原文链接:https://zhuanlan.zhihu.com/p/34788333?utm_source=ZHShareTargetIDMore
SPP背景
传统CNN所需要的固定维度输入这一限制,是造成任意尺度的图片识别准确率低的原因.传统的CNN需要先对训练图片进行处理,使其维度相同.具体有两种做法,裁剪(cropping)和扭曲(warping).如下图.
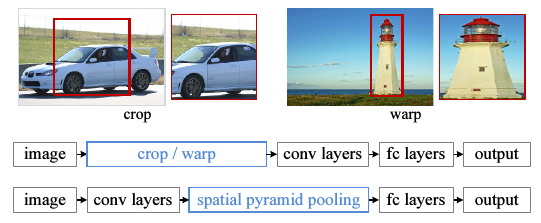
缺点是:裁剪了的区域可能并不包含整个物体,而扭曲则会带入几何方面的失真.另外,即使是裁剪和扭曲,我们仍然是认为规定了一个输入尺度,而真实的物体尺度很多,这个固定维度的输入直接忽略掉了这一点.
为何非要给CNN限制一个固定维度的输入?作者说,CNN就分两块,卷积层和全连层(fully-connected layer),卷积层的输出是特征图(feature map),这个特征图反映出了原始输入图片中对filter(卷积核)激活的空间信息.卷积这一步是不需要固定大小的.是最后的全连层带来的这个限制.
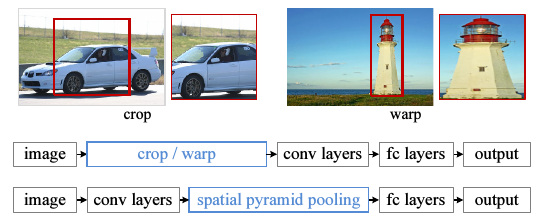
作者针对这个问题,提出了在CNN的最后一个卷积层之后,加入一个SPP层,也就是空间金字塔池化,对之前卷积得到的特征进行”整合”(aggregation),然后得到一个固定长度的特征向量,再传到全连层去.如下图.


SPP是词袋模型(Bag-of-Words)的扩展.为什么说是扩展?词袋模型没有特征的空间信息(就像它只能统计一个句子中每个单词的词频,而不能记录词的位置信息一样).在深层CNN里加入SPP会有3个优势: 1) 相比之前的滑动窗池化(sliding window pooling),SPP可以对不同维度输入得到固定长度输出. 2) SPP使用了多维的spatial bins(我的理解就是多个不同大小的窗),而滑动窗池化只用了一个窗. 3) 因为输入图片尺度可以是任意的,SPP就提取出了不同尺度的特征.作者说这3点可以提高深度网络的识别准确率.
SPP-net既然只在网络的最后几层(深层网络)中加入,而本质上就是池化,所以它可以加入到其他CNN模型中,比如AlexNet.作者的实验表明,加入了SPP的AlexNet效果确实提升了.作者认为SPP应该能提升更复杂的网络的能力.
SPP原理
在输入不同尺寸的图片,经过卷积层会输出的不同大小的feature map.把最以后一次卷积后的池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin(M个不同维度的pyramid),那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了,第二个产生4x256维向量,SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
具体地,在一个CNN里,把最以后一次池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin,那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了.SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
假设原图输入是224x224,对于conv5出来后的输出是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。如果像上图那样将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做max pooling后,出来的特征就是(16+4+1)x256 维度。如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256维度。这样就实现了不管图像尺寸如何 池化n 的输出永远是 (16+4+1)x256 维度。SSP后的全连接是由上图绿色,蓝色,灰色产生的向量拼接而成。
实际运用中只需要根据全连接层的输入维度要求设计好空间金字塔即可。
训练
###单一大小训练
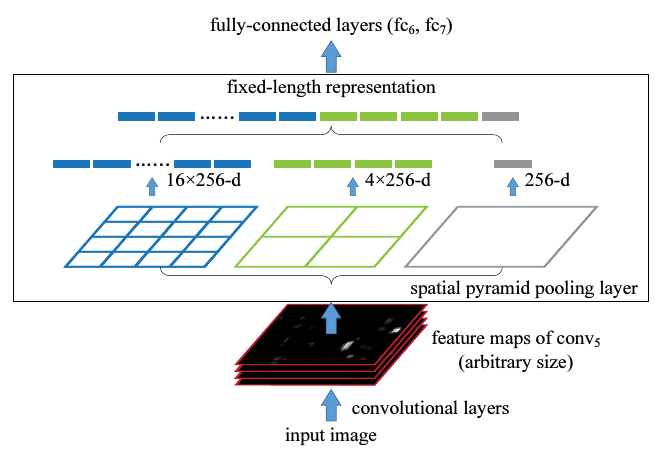
如果一个图片大小固定,比如224x224,那么我们就能计算出它的池化窗口(bin)的大小.比如经过第五个卷积层conv5之后得到的feature map是a x a(13x13),如果金字塔大小n x n,那么窗口大小就是ceil(a / n), 步长是floor(a / n).我们可以用ll个不同大小的窗口,比如3x3, 2x2, 1x1.然后把这ll个输出连接起来,送入之后的全连层.下图是这样3个窗口和最后的全连层的的配置文件.

###多个大小的训练
我们再考虑一种输入大小(180x180),两种大小也算是”多个大小训练”啊.这个180x180的直接取224x224图片的按尺度缩放图片,这两张图除了解析度不同别的都相同.180x180的图片经过第五层卷积后的feature map是10x10,这时我们依然用刚才的公式,窗口大小就是ceil(a / n), 步长是floor(a / n),这样的话后得到的特征长度与之前的224x224的特征长度相同.举个例子,如果金字塔是3*3,即n=3,那么对于第一种大小,窗口长为5,步长4,第二中大小,窗口4,步长3,如下图.
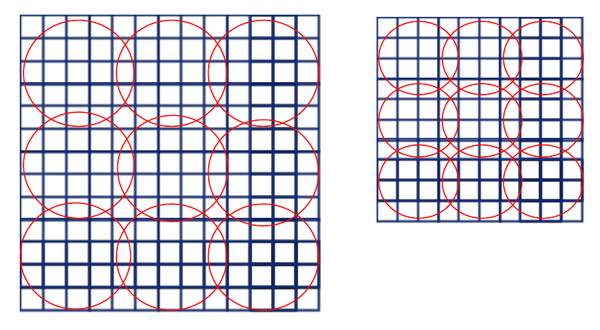
红色区域代表窗口,经过最大池化后,两张图得到的特征向量长度均为3x3=9.所以180的网络和224的网络参数完全一样,于是SPP训练阶段,对于这两种网络只要共享参数即可.
实际训练时,为了减少不停转换网络带来的开销,需要使用全部数据一次训练一个网络,然后再换成第二个,作为一次迭代.所以作者根本没有实现训练不同大小输入的CNN的BP算法,只是针对各种各样大小不同的输入,定义出不同的网络,但这些网络实际上参数都相同,于是就可以用现有工具来训练.
这个是训练阶段,需要不停转化网络,当训练好模型用于测试时,只要输入图片就行了.
该文主要参考:
[论文笔记]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognitionsinb.github.io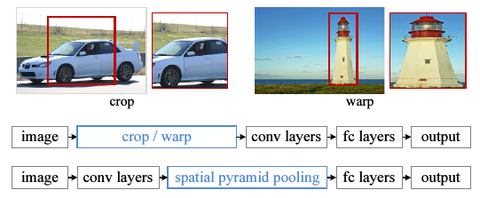 晓雷:SPPNet-引入空间金字塔池化改进RCNNzhuanlan.zhihu.com
晓雷:SPPNet-引入空间金字塔池化改进RCNNzhuanlan.zhihu.com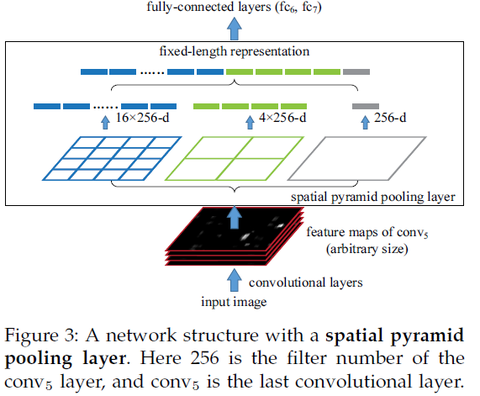
讲解 Spatial Pyramid Pooling相关推荐
- Spatial Pyramid Pooling(SPP)原理简介
b站这个Up主讲的挺好,就是莫名其妙搞个背景音乐怪怪的...视频讲解 Spatial Pyramid Pooling(SPP)中文叫空间金字塔池化 SPP目的:这个原理要解决的是传统CNN网络对输入图 ...
- [SPP-NET]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
基于空间金字塔池化的卷积神经网络物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187655 作者:hjimce 一.相关理论 本篇博文 ...
- Paper8:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 还未读
- Spatial Pyramid Pooling(空间金字塔池化)-变尺度CNN训练
1. 需求创造好的产品,产品拓宽原始的需求 当前的深度神经网络一般都需要固定的输入图像尺寸(如224*224). 这种需求很明显是人为的,潜在性的弊端会降低识别精度(为了使图像尺寸相同,一定会涉及到图 ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- 语义分割——Spatial Pyramid Pooling (SPP)的作用
1 前言 我们在DeepLabV3+中学习到了ASPP算法,ASPP就是使用了膨胀卷积的Spatial Pyramid Pooling (SPP)- 2 SPP的作用 --多尺度特征融合: --将不同 ...
- SPP(Spatial Pyramid Pooling)解读
1.为什么会出现SPP结构,其作用是什么? 通过Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognitio ...
- SPP: Spatial Pyramid Pooling
paper: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition code: https: ...
- 空间金字塔池化Spatial Pyramid Pooling
1. 概述 通常在卷积神经网络CNN中主要是由卷积层(包括Convolution和Pooling两部分组成)和全连接层组成,对于任意一张大小的图片,通常需要通过裁剪或者拉伸变形的方式将其转换成固定大小 ...
最新文章
- php获取头像,WordPress中用于获取及自定义头像图片的PHP脚本详解
- Lync 小技巧-34-通过Lync Server 2013的URI批量启用UM
- python下载文件到本地-Python下载网络文本数据到本地内存的四种实现方法示例
- linux 脚本详解,shell脚本分析日志
- Apache Kafka简介
- gitee如何搭建mysql_MySQL高可用架构集群环境搭建手册.md
- python 散点图 分类_Python | 分类图
- 用html5做一个介绍自己家乡的页面_厚溥资讯 | HTML5的小知识点小集合(上)
- Linux 终端显示 Git 当前所在分支 1
- html表单左侧文字对齐,CSS图标文字对齐和表单输入框文字对齐兼容
- 统计信号处理基础_0基础学Python,就业中你需要建立360度无死角技能树
- Node.js与V8引擎
- 查看docker镜像内部端口号_Docker 安装部署
- 使用Jenkins实现自动化构建!
- 小巧机身 性能强悍 正睿第三代可扩展1U机架式服务器
- JavaScript 排他思想
- LeetCode38——Count and Say
- 网站index.php,网站 index of
- python模拟自动填充(一)
- Pandas 安装与教程