uber大数据_Uber创建了深度神经网络以为其他深度神经网络生成训练数据
uber大数据
A common analogy in artificial intelligence(AI) circles is that training data is the new oil for machine learning models. Just like the precious commodity, training data is scarce and hard to get at scale. Supervised learning models reign supreme in today’s machine learning ecosystem. While these type of models are relatively easy to create compare to other alternatives, they have a strong dependency in training data that results prohibited for most organizations. This problem becomes bigger with the scale of the machine learning models. Recently, Uber engineers published a paper proposing a new method called Generative Teaching Networks(GTNs) that create learning algorithms that automatically generate training data.
人工智能(AI)界的一个常见比喻是,训练数据是机器学习模型的新动力。 就像珍贵的商品一样,培训数据稀缺且难以大规模获取。 监督学习模型在当今的机器学习生态系统中占据统治地位。 尽管与其他选择相比,这些类型的模型相对容易创建,但它们在训练数据上有很强的依赖性,这对于大多数组织来说都是禁止的。 随着机器学习模型的规模,这个问题变得更大。 最近, Uber工程师发表了一篇论文,提出了一种新方法,称为生成教学网络(GTN) ,该方法可以创建自动生成训练数据的学习算法。
The idea of generating training data using machine learning is not exactly novel. Techniques such as semi-supervised and omni-supervised learning rely on that principle to operate in data scarce environments. However the data-dependency challenges in machine learning models are growing faster than the potential solutions. Part of these challenges have their roots in some of the biggest misconceptions in modern machine learning.
使用机器学习生成训练数据的想法并不完全新颖。 半监督学习和全监督学习之类的技术都依靠该原理在数据稀缺的环境中运行。 但是,机器学习模型中的数据依赖性挑战比潜在的解决方案增长得更快。 这些挑战中的一部分源于现代机器学习中的一些最大误解。
关于培训数据的误解 (Misconceptions About Training Data)
The traditional approach to train a machine learning model tells us that models should be trained using large datasets and they should leverage the entire dataset during the process. Although well established, that idea seems counterintuitive as it assumes that all records in the training dataset have equal weight which is certainly rare. New approaches such as curriculum learning and active learning have focused on extracting a distribution from the training dataset based on the examples that generate the best version of the models. Some of these techniques have proven quite useful in the emergence of neural architecture search(NAS) techniques.
训练机器学习模型的传统方法告诉我们,应该使用大型数据集来训练模型,并且在此过程中应该利用整个数据集。 尽管已经很好地建立了,但是这个想法似乎违反直觉,因为它假设训练数据集中的所有记录具有相等的权重,这当然是很少见的。 课程学习和主动学习等新方法的重点是,基于生成最佳版本模型的示例,从训练数据集中提取分布。 这些技术中的某些已被证明在神经体系结构搜索(NAS)技术的出现中非常有用。
NAS are becoming one of the most popular trends in modern machine learning. Conceptually, NAS help to discover the best high performing neural network architectures for a given problems by performing evaluations across thousands of models. The evaluations performed by NAS methods require training data and they can result cost prohibited if they use complete training datasets in each iteration. Instead, NAS methods have become extremely proficient evaluating candidate architectures by training a predictor of how well a trained learner would perform, by extrapolating from previously trained architectures.
NAS正在成为现代机器学习中最受欢迎的趋势之一。 从概念上讲,NAS通过对数千个模型进行评估来帮助发现给定问题的最佳高性能神经网络体系结构。 NAS方法执行的评估需要训练数据,如果每次迭代都使用完整的训练数据集,则可能导致成本高昂。 取而代之的是,NAS方法已通过从先前受过训练的体系结构推断出的训练受训学习者表现的预测器,变得非常熟练地评估候选体系结构。
These two ideas: selecting the best examples from a training set and understanding how a neural network learns were the foundation of Uber’s creative method for training machine learning models.
这两个想法是:从训练集中选择最好的例子,并了解神经网络如何学习,这是Uber训练机器学习模型的创新方法的基础。
进入生成式教学网络 (Enter Generative Teaching Networks)
The core principle of Uber’s GTNs is based on a simple and yet radical idea: allowing machine learning to create the training data itself. GTNs leverage generative and meta-learning models while also driving inspiration from techniques such as generative adversarial neural networks(GANs).
Uber GTN的核心原理基于一个简单而又激进的想法:允许机器学习本身创建训练数据。 GTN在利用生成和元学习模型的同时,还从诸如生成对抗神经网络(GAN)之类的技术中获得启发。
The main idea in GTNs is to train a data-generating network such that a learner network trained on data it rapidly produces high accuracy in a target task. GTNs borrow ideas from GANs but there are also marked differences. In GTN models,the two networks cooperate instead of competing. The networks in a GTN model have their interests aligned towards having the improving the performance of the learner based on the produced training data. The generator network in a GTN model regularly produces completely new artificial data that a never-seen-before learner neural network trains on for a small number of learning steps. After that step, the learner network is evaluated on real data and its performance is optimized.
GTN中的主要思想是训练数据生成网络,以使训练有素的学习者网络快速在目标任务中产生高精度。 GTN向GAN借鉴了想法,但也存在明显差异。 在GTN模型中,两个网络合作而不是竞争。 GTN模型中的网络的兴趣在于根据生成的训练数据来提高学习者的表现。 GTN模型中的生成器网络会定期生成全新的人工数据,在很少的学习步骤中,这是从未见过的学习者神经网络所训练的。 在此步骤之后,将根据真实数据评估学习者网络并优化其性能。
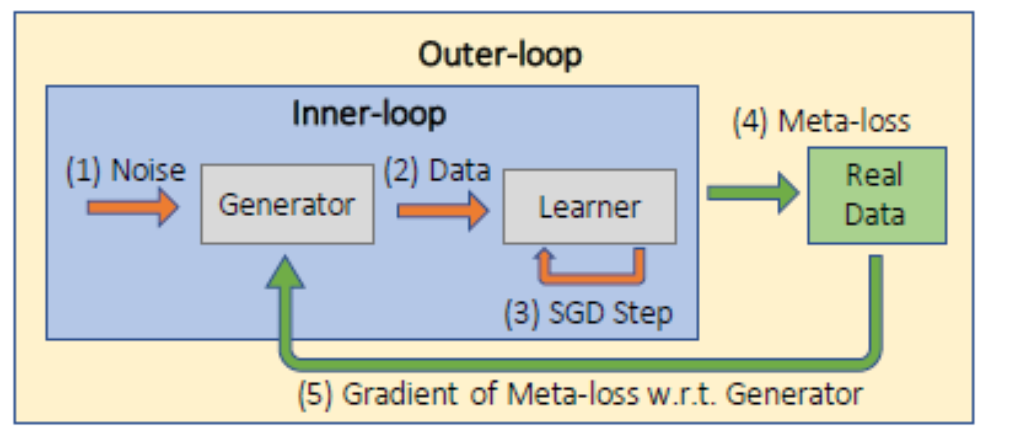
Based on the original research paper, the architecture of GTNs can be explained in five simple steps:
基于原始研究论文,可以通过五个简单步骤来解释GTN的体系结构:
1) Noise is fed to the input generator which is used to create new synthetic data.
1)噪声被馈送到用于生成新的合成数据的输入生成器。
2) The learner is trained to perform well on the generated data.
2)对学习者进行训练,使其在生成的数据上表现出色。
3) The trained learner is then evaluated on the real training data in the outer-loop to compute the outer-loop meta-loss.
3)然后在外环中的实际训练数据上评估受训学习者,以计算外环元损失。
4) The gradients of the generator parameters are computed to the meta-loss to update the generator.
4)计算发电机参数的梯度到亚损失,以更新发电机。
5) Both a learned curriculum and weight normalization substantially improve GTN performance.
5)学习过的课程和体重标准化都可以大大改善GTN的表现。
行动中的GTN (GTNs in Action)
Uber evaluated GTNs across different neural network architectures. One of those scenarios was an image classification model trained using the famous MNIST dataset. After a few iterations, new learners trained using GTN were able to learn faster than the same models using real data. In this specific scenarios, the GTN-trained models achieved a remarkable 98.9 accuracy and did that in just 32 SGD steps (~0.5 seconds), seeing each of the 4,096 synthetic images in the curriculum once, which is less than 10 percent of the images in the MNIST training data set.
Uber在不同的神经网络架构中评估了GTN。 这些场景之一是使用著名的MNIST数据集训练的图像分类模型。 经过几次迭代,使用GTN训练的新学习者比使用实际数据的相同模型学习得更快。 在这种特定情况下,经过GTN训练的模型达到了惊人的98.9精度,并且仅用32个SGD步(约0.5秒)就做到了这一点,一次在课程中看到4,096张合成图像中的每张,均不到图像的10%在MNIST训练数据集中。

One of the surprising findings of using GTNs for image classification is that the synthetic dataset seem unrealistic to the human eye(see image below). Even more interesting is the fact that the recognizability of the images improves towards the end of the curriculum. Despite its alien appearance, the synthetic data proven to be effective when training neural networks. Intuitively, we would think that if neural network architectures were functionally more similar to human brains, GTNs’ synthetic data might more resemble real data. However, an alternate (speculative) hypothesis is that the human brain might also be able to rapidly learn an arbitrary skill by being shown unnatural, unrecognizable data. How crazy is that?
使用GTN进行图像分类的令人惊讶的发现之一是合成数据集对人眼来说似乎是不现实的(请参见下图)。 更有趣的是,图像的可识别性在课程结束时会有所改善。 尽管看起来很陌生,但是综合数据在训练神经网络时被证明是有效的。 直觉上,我们认为如果神经网络架构在功能上更类似于人的大脑,则GTN的合成数据可能更类似于真实数据。 但是,另一种(推测性的)假设是,人脑也可能通过显示不自然,无法识别的数据来快速学习任意技能。 那有多疯狂?

GTNs are a novel approach to improve the training of machine learning models using synthetic data. Theoretically, GTNs could have applications beyond traditional supervised learning in areas such as NAS methods. Certainly, applying GTNs in Uber’s massive machine learning infrastructure should yield amazing lessons that will help to improve this technique.
GTN是一种使用合成数据来改进机器学习模型训练的新颖方法。 从理论上讲,GTN可以在诸如NAS方法之类的领域中获得超越传统监督学习的应用。 当然,在Uber的大规模机器学习基础架构中应用GTN应该会产生令人惊讶的教训,这将有助于改进该技术。
翻译自: https://medium.com/dataseries/uber-creates-deep-neural-networks-to-generate-training-data-for-other-deep-neural-networks-553fedcaa74d
uber大数据
http://www.taodudu.cc/news/show-1874143.html
相关文章:
- http 响应消息解码_响应生成所需的解码策略
- 永久删除谷歌浏览器缩略图_“暮光之城”如何永久破坏了Google图片搜索
- 从头实现linux操作系统_从头开始实现您的第一个人工神经元
- 语音通话视频通话前端_无需互联网即可进行数十亿视频通话
- 优先体验重播matlab_如何为深度Q网络实施优先体验重播
- 人工智能ai以算法为基础_为公司采用人工智能做准备
- ieee浮点数与常规浮点数_浮点数如何工作
- 模型压缩_模型压缩:
- pytorch ocr_使用PyTorch解决CAPTCHA(不使用OCR)
- pd4ml_您应该在本周(7月4日)阅读有趣的AI / ML文章
- aws搭建深度学习gpu_选择合适的GPU进行AWS深度学习
- 证明神经网络的通用逼近定理_在您理解通用逼近定理之前,您不会理解神经网络。...
- ai智能时代教育内容的改变_人工智能正在改变我们的评论方式
- 通用大数据架构-_通用做法-第4部分
- 香草 jboss 工具_使用Tensorflow创建香草神经网络
- 机器学习 深度学习 ai_人工智能,机器学习和深度学习。 真正的区别是什么?...
- 锁 公平 非公平_推荐引擎也需要公平!
- 创建dqn的深度神经网络_深度Q网络(DQN)-II
- kafka topic:1_Topic️主题建模:超越令牌输出
- dask 于数据分析_利用Dask ML框架进行欺诈检测-端到端数据分析
- x射线计算机断层成像_医疗保健中的深度学习-X射线成像(第4部分-类不平衡问题)...
- r-cnn 行人检测_了解用于对象检测的快速R-CNN和快速R-CNN。
- 语义分割空间上下文关系_多尺度空间注意的语义分割
- 自我监督学习和无监督学习_弱和自我监督的学习-第2部分
- 深度之眼 alexnet_AlexNet带给了深度学习的世界
- ai生成图片是什么技术_什么是生成型AI?
- ai人工智能可以干什么_我们可以使人工智能更具道德性吗?
- pong_计算机视觉与终极Pong AI
- linkedin爬虫_这些框架帮助LinkedIn大规模构建了机器学习
- 词嵌入生成词向量_使用词嵌入创建诗生成器
uber大数据_Uber创建了深度神经网络以为其他深度神经网络生成训练数据相关推荐
- 深度学习,怎么知道你的训练数据真的够了?
最近有很多关于数据是否是新模型驱动 [1] [2] 的讨论,无论结论如何,都无法改变我们在实际工作中获取数据成本很高这一事实(人工费用.许可证费用.设备运行时间等方面). 因此,在机器学习项目中,一个 ...
- 点云语义分割标注工具及生成训练数据
1.软件的安装 (1)下载后随便你解压到那个文件夹下(软件github地址) github链接 (2)在终端中运行: curl https://install.meteor.c ...
- 谷歌新大招UDG|直接生成训练数据送给你
卷友们好,我是rumor. 最近我越来越相信Prompt概念了,不光是paper数量越来越多,关键是用过的都说好.比如我的同事,比如我面试到的同学,再比如我看到的一些实践博客.估计在它席卷所有任务和d ...
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?...
2019独角兽企业重金招聘Python工程师标准>>> 科言君 每周六提供一份高质量回答. 首先,我感觉不必像 @李Shawn 同学一样认为DNN.CNN.RNN完全不能相提并论.从 ...
- 干货丨揭秘深度学习的核心:掌握训练数据的方法
来源:云栖社区 概要:今天我们将讨论深度学习中最核心的问题之一:训练数据. Hello World! 今天我们将讨论深度学习中最核心的问题之一:训练数据.深度学习已经在现实世界得到了广泛运用,例如:无 ...
- 深度学习的核心:掌握训练数据的方法
来源:云栖社区 概要:今天我们将讨论深度学习中最核心的问题之一:训练数据. Hello World! 今天我们将讨论深度学习中最核心的问题之一:训练数据.深度学习已经在现实世界得到了广泛运用,例如:无 ...
- 深度学习与围棋:神经网络入门
本文主要内容 介绍人工神经网络的基础知识. 指导神经网络学习如何识别手写数字. 组合多个层来创建神经网络. 理解神经网络从数据中学习的原理. 从零开始实现一个简单的神经网络. 本章介绍人工神经网络(A ...
- 深度学习必备---用Keras和直方图均衡化---数据增强
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 一.俺.遇到了啥子问题撒~? 我现在写的文章都是因为遇到问题了,然 ...
- 深度学习初学者,如何下载常用公开数据集并使用呢?
深度学习初学者,如何下载常用公开数据集并使用呢? 1.前言 2.官方文档怎样看 3.动手写代码 4.如何可视化 遇到问题:ssl.SSLCertVerificationError: [SSL: CER ...
- 《深度学习》之 前馈神经网络 原理 详解
前馈神经网络 1. 深度学习: **定义:**深度学习是机器学习的一个研究方向,它基于一种特殊的学习机制.其特点是建立一个多层学习模型,深层级将浅层级的输出作为输入,将数据层层转化,使之越来越抽象.是 ...
最新文章
- Bulk_Collect_Performance 比较
- 机器人建图、感知和交互的语义研究综述
- C# 多线程 线程池(ThreadPool) 2 如何控制线程池?
- codevs 2865 天平系统1
- Andorid开发学习---ubuntu 12.04下搭建超好用的安卓模拟器genymotion 安装卸载virtualbox 4.3...
- python 爬虫 ~ 查看收发包的情况
- CrtInvertedIdx
- 139.00.007 Git学习-Cheat Sheet
- oracle 磁盘不分区吗,LINUX停ORACLE软件、数据文件等所在的磁盘分区空间不足的解决思路...
- 使用Sqlite数据库存储数据
- 多个if-else语句执行顺序、if-else与if-else if-else不同执行顺序、switch执行顺序
- 移动Web UI库(H5框架)有哪些,看这里就够了
- linux开pulseaudio服务,PulseAudio
- 明尼苏达大学 计算机学院 教授,美国明尼苏达大学David Du教授学术报告
- Router的路由表
- eclipseme插件安装的一点心得
- 本土战略 Ubuntu创始人宣布将发中国版
- cpolar+ipad+windows远程桌面控制
- adb 查看手机的ip地址
- DPU网络开发SDK——DPDK(二)
热门文章
- BT 与 Magnet 的下载方式及原理
- Rad Software Regular Expression Designer 正则表达式工具软件
- 深度学习CNN系列笔记
- Web of science(WOS)引文跟踪
- Atitit 集合分组聚合操作sum count avg java版本groovy版本 目录 1. //按性别统计用户数 1 7. //按性别获取用户名称 1 16. //按性别求年龄的总和 1 2
- Atitit 算法之道 attilax著 1. 第二部分(Part II) 排序与顺序统计(Sorting and Order Statistics) 1 2. 第六章 堆排序(Heapsort)
- Atitit 图像处理的摩西五经attilax总结
- Atitit 作用域的理解attilax总结
- Atitit.wrmi web rmi框架新特性
- atitit.软件gui按钮and面板---os区-----软链接,快捷方式