深度强化学习从入门到大师_深度学习大师的经验教训
深度强化学习从入门到大师
Yoshua Bengio is a Deep Learning legend and won the Turing Award in 2018, along with Geoff Hinton and Yann LeCun.
Yoshua Bengio是深度学习的传奇人物,并与Geoff Hinton和Yann LeCun一起获得了2018年图灵奖 。
In this short post, I want to highlight for you some clever things that Yoshua and his collaborators did to win a Machine Learning competition from a field of 381 competing teams. Perhaps these ideas will be useful for your own work.
在这篇简短的文章中,我想向您强调Yoshua和他的合作者在赢得381个参赛团队的机器学习竞赛中所做的一些聪明的事情。 这些想法可能对您自己的工作有用。
In a world where powerful Deep Learning frameworks (e.g., TensorFlow, PyTorch) are a free download away, their competition-winning approach demonstrates nicely that your edge may come from how well you model the specifics of your problem.
在免费下载功能强大的深度学习框架(例如TensorFlow,PyTorch)的世界中,其屡获殊荣的方法很好地证明了您的优势可能来自于对问题细节的建模能力。
(Caveat: This work was done in 2015. Given all the advancements in Deep Learning and computing hardware since then, Yoshua and team would probably solve the problem differently if the competition were held today)
(注意:这项工作于2015年完成。鉴于此后深度学习和计算硬件的所有进步,如果今天举行比赛,Yoshua和团队可能会以不同的方式解决问题)
The teams participating in the competition were given a dataset of all the taxi trips undertaken over a full year in the city of Porto in Portugal.
参加比赛的团队将获得一个数据集,其中包括在葡萄牙波尔图市全年进行的所有出租车旅行 。
There were 1.7 million trips in the training dataset and for each trip, the important data elements were:
训练数据集中有170万次旅行,每一次旅行的重要数据元素是:
- GPS coordinates — latitude and longitude — of the taxi’s location measured every 15 seconds from the start of the trip to the finish. The first latitude-longitude pair is the starting point of the trip and the final latitude-longitude is the destination of the trip. For example, a taxi’s location at the start of a trip, 15 seconds later and 30 seconds later would look like this: [-8.578719,41.156271],[-8.578629,41.157693],[-8.578521,41.159439].从旅行开始到终点,每15秒测量一次出租车位置的GPS坐标(纬度和经度)。 第一个纬度-经度对是旅程的起点,而最终的纬度-经度是旅程的目的地。 例如,出租车在旅行开始时的位置,分别是15秒后和30秒后,如下所示:[-8.578719,41.156271],[-8.578629,41.157693],[-8.578521,41.159439]。
- the timestamp at the beginning of the trip旅行开始时的时间戳
- taxi ID的士编号
- client ID (if the client requested the taxi by phone) or taxi-stand ID (if they got into the taxi at a taxi stand)客户ID(如果客户通过电话请求出租车)或出租车站ID(如果他们在出租车站乘出租车)
The challenge given to the participants is simply stated:
简单地说,给参与者的挑战是:
Given a partial trip (i.e., the latitude-longitude of the starting point and the next several consecutive points) and time/ID metadata, predict the latitude-longitude of the final destination.
给定部分行程(即,起点和接下来的几个连续点的纬度-经度 )和时间/ ID元数据, 预测最终目的地的纬度-经度。
For example, let’s say a taxi trip started at the Sao Bento Station and ended at the Jardins do Palacio de Cristal, as shown below.
例如,假设出租车之旅始于圣本图站,结束于水晶宫,如下所示。

A partial trip would include the origin point and might be something like this:
部分行程将包括起点,并且可能是这样的:

The test dataset had 320 partial trips. The evaluation metric was the distance between the predicted destination and the actual destination, averaged over the trips in the test dataset.
测试数据集有320次局部行程。 评估指标是在测试数据集中行程中平均的预测目的地与实际目的地之间的距离。
But the predicted and actual destinations are points on the surface of the earth (not points on a plane), so the distance between them is calculated NOT with the euclidean distance but with something called the Haversine distance:
但是预测的目的地和实际的目的地是地球表面上的点(不是平面上的点),因此它们之间的距离不是用欧几里得距离而是用Haversine 距离来计算的 :

Looks simple, right? :-)
看起来很简单,对吧? :-)
This is a structured data problem (i.e., no images, audio etc) so if you want to use a neural network approach, a reasonable starting point would be a basic network (an MLP) with a hidden layer and two output nodes, one for the latitude and one for the longitude of the destination.
这是一个结构化的数据问题(即,没有图像,音频等),因此,如果要使用神经网络方法,一个合理的起点应该是具有隐藏层和两个输出节点的基本网络( MLP ),其中一个用于纬度,一为目的地的经度。
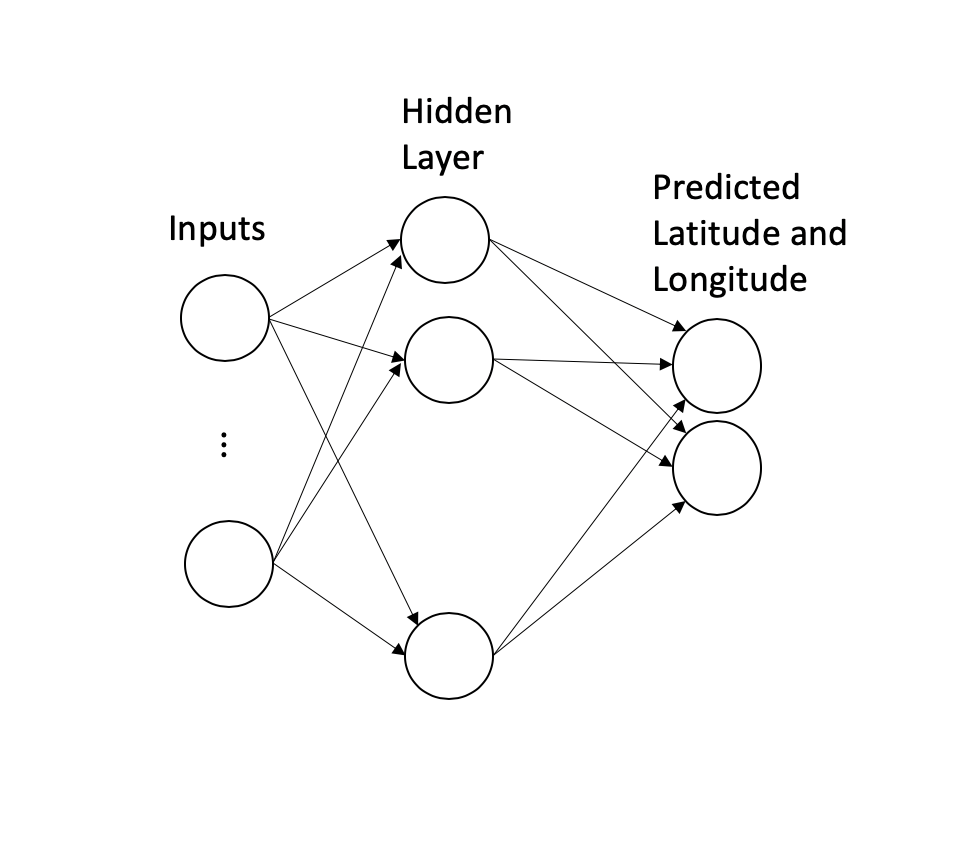
But complications arise immediately:
但是并发症立即出现:
Since different trips may have different durations, the number of latitude-longitude pairs in each trip will vary and therefore each training example has a variable number of inputs. For example, a 10-minute ride will have about 40 latitude-longitude pairs while a 30-minute ride will have an input that is three times as long. How do we handle a varying number of inputs?
由于不同的行程可能具有不同的持续时间,因此每次行程中的纬度-经度对的数量将变化,因此,每个训练示例的输入数量均可变 。 例如,一个10分钟的旅程将有大约40个纬度-经度对,而30分钟的旅程将有一个三倍长的输入。 我们如何处理不同数量的输入?
That Haversine function looks scary. It is differentiable so maybe optimizing it as-is will just work? We will see.
Haversine功能看起来很恐怖。 它具有差异性,因此也许可以按原样对其进行优化? 我们会看到。
Our two output nodes predict latitude and longitude. Maybe this will work just fine but there are only 320 observations in the test dataset so even a few bad predictions can wreck the evaluation metric. Furthermore, predicting latitude and longitude directly doesn’t take into account the fact that popular destinations (e.g., the Sao Bento station) will occur more frequently in the data and therefore getting them right is very important.
我们的两个输出节点可预测纬度和经度。 也许这会很好,但是测试数据集中只有 320个观测值,因此即使是一些错误的预测也会破坏评估指标。 此外,直接预测纬度和经度并没有考虑到热门目的地(例如圣本图站)在数据中会更频繁地发生的事实,因此正确地进行定位非常重要。
Let’s dive in and see how Yoshua and team solved these problems.
让我们深入了解Yoshua和团队如何解决这些问题。
Problem: Varying-length input
问题 :可变长度输入
(If you are familiar with Recurrent Neural Networks (RNNs), you would have immediately recognized their applicability to this problem. Indeed, in their paper, Yoshua and co-authors explore a few different variants of RNNs to address this issue but their competition-winning model didn’t use RNNs; it used the simple idea described below)
(如果您熟悉递归神经网络 (RNN),您将立即认识到它们在此问题上的适用性。确实,在他们的论文中 ,Yoshua和合著者探索了RNN的几种不同变体来解决此问题,但他们的竞争是-获胜模型没有使用RNN;它使用了下面描述的简单思想)
Solution:
解决方案 :
The solution that worked best was incredibly simple.
最有效的解决方案非常简单。
Concatenate the first 5 coordinates and the last 5 coordinates of the input. If the input has fewer than 10 coordinates, still take the first 5 and the last 5 — it is ok that they overlap. Finally, if the partial trip has fewer than 5 coordinates, just repeat the first or the last coordinate till you get to 10 coordinates.
连接输入的前5个坐标和后5个坐标。 如果输入的坐标少于10个,则仍取前5个和后5个-可以重叠。 最后,如果部分行程的坐标少于5个,则只需重复第一个或最后一个坐标,直到获得10个坐标即可。
For example, from this ‘raw’ input …
例如,从“原始”输入中…
[[-8.611794,41.140557],[-8.611785,41.140575],[-8.612001,41.140566],[-8.612622,41.140503],[-8.613702,41.140341],[-8.614665,41.140386],[-8.615844,41.140485],[-8.61561,41.140683],[-8.614566,41.141088],[-8.614395,41.141979],[-8.613936,41.142942],[-8.612793,41.143851],[-8.611488,41.144787],[-8.610543,41.144391],[-8.610282,41.143536],[-8.610255,41.143401],[-8.608824,41.143239],[-8.608419,41.143149],[-8.606565,41.142348],[-8.605179,41.143446],[-8.604549,41.144796],[-8.604297,41.1453],[-8.603505,41.145561],[-8.602488,41.145633],[-8.601039,41.145759],[-8.600436,41.146443],[-8.599977,41.147289],[-8.598681,41.14827],[-8.598303,41.148423],[-8.598618,41.149467],[-8.597529,41.151294],[-8.596161,41.153679],[-8.594838,41.155983],[-8.594163,41.157135],[-8.593002,41.159187],[-8.591454,41.161608],[-8.589924,41.163453],[-8.589402,41.163309]]
[[-8.611794,41.140557],[-8.611785,41.140575],[-8.612001,41.140566],[-8.612622,41.140503],[-8.613702,41.140341],[-8.614665,41.140386],[-8.615844,41.140485], [-8.61561,41.140683],[-8.614566,41.141088],[-8.614395,41.141979],[-8.613936,41.142942],[-8.612793,41.143851],[-8.611488,41.144787],[-8.610543,41.144391],[ -8.610282,41.143536],[-8.610255,41.143401],[-8.608824,41.143239],[-8.608419,41.143149],[-8.606565,41.142348],[-8.605179,41.143446],[-8.604549,41.144796],[- 8.604297,41.1453],[-8.603505,41.145561],[-8.602488,41.145633],[-8.601039,41.145759],[-8.600436,41.146443],[-8.599977,41.147289],[-8.598681,41.14827],[-8.598303 ,41.148423],[-8.598618,41.149467],[-8.597529,41.151294],[-8.596161,41.153679],[-8.594838,41.155983],[-8.594163,41.157135],[-8.593002,41.159187],[-8.591454, 41.161608],[-8.589924,41.163453],[-8.589402,41.163309]]
… only the bolded coordinates would be used:
…仅使用粗体坐标:
[[-8.611794,41.140557],[-8.611785,41.140575],[-8.612001,41.140566],[-8.612622,41.140503],[-8.613702,41.140341],[-8.614665,41.140386],[-8.615844,41.140485],[-8.61561,41.140683],[-8.614566,41.141088],[-8.614395,41.141979],[-8.613936,41.142942],[-8.612793,41.143851],[-8.611488,41.144787],[-8.610543,41.144391],[-8.610282,41.143536],[-8.610255,41.143401],[-8.608824,41.143239],[-8.608419,41.143149],[-8.606565,41.142348],[-8.605179,41.143446],[-8.604549,41.144796],[-8.604297,41.1453],[-8.603505,41.145561],[-8.602488,41.145633],[-8.601039,41.145759],[-8.600436,41.146443],[-8.599977,41.147289],[-8.598681,41.14827],[-8.598303,41.148423],[-8.598618,41.149467],[-8.597529,41.151294],[-8.596161,41.153679],[-8.594838,41.155983],[-8.594163,41.157135],[-8.593002,41.159187],[-8.591454,41.161608],[-8.589924,41.163453],[-8.589402,41.163309]]
[[-8.611794,41.140557],[-8.611785,41.140575],[-8.612001,41.140566],[-8.612622,41.140503],[-8.613702,41.140341] ,[-8.614665,41.140386],[-8.615844,41.140485], [-8.61561,41.140683],[-8.614566,41.141088],[-8.614395,41.141979],[-8.613936,41.142942],[-8.612793,41.143851],[-8.611488,41.144787],[-8.610543,41.144391],[ -8.610282,41.143536],[-8.610255,41.143401],[-8.608824,41.143239],[-8.608419,41.143149],[-8.606565,41.142348],[-8.605179,41.143446],[-8.604549,41.144796],[- 8.604297,41.1453],[-8.603505,41.145561],[-8.602488,41.145633],[-8.601039,41.145759],[-8.600436,41.146443],[-8.599977,41.147289],[-8.598681,41.14827],[-8.598303 ,41.148423],[-8.598618,41.149467],[-8.597529,41.151294],[-8.596161,41.153679],[-8.594838,41.155983], [-8.594163,41.157135],[-8.593002,41.159187],[-8.591454, 41.161608],[-8.589924,41.163453],[-8.589402,41.163309]]
In case you are wondering why they picked 5 rather than another number, I suspect that they thought of this as a hyper-parameter k and tried a few different values; k = 5 may have turned out to be the best.
如果您想知道为什么他们选择了5个而不是另一个数字,我怀疑他们认为这是一个超参数k,并尝试了一些不同的值。 k = 5可能已证明是最好的。
Lesson learned:
获得的经验 :
In problems with varying-length inputs, a carefully chosen fixed-length subset of the input may capture the input’s essence.
在输入长度可变的问题中,精心选择的输入固定长度子集可能会抓住输入的本质 。
For a taxi trip, knowing the origin point and the last point of the partial trip is probably all the information you need about the partial trip; knowing the exact path taken by the taxi between those two points is probably unnecessary.
对于出租车旅行,知道部分旅行的起点和终点可能是您需要的关于部分旅行的所有信息; 知道出租车在这两点之间的确切路径可能是不必要的。
But in other problems, knowing the beginning and end may not be enough; representing the entire path in some way may be necessary. In those cases, sampling the entire path at regular intervals may do the trick. Or sampling the more interesting parts of the path more often and sampling the less interesting parts of the path less often may be the right approach.
但是在其他问题上,仅仅知道开始和结束可能还不够。 以某种方式表示整个路径可能是必要的。 在那些情况下,以规则的间隔对整个路径进行采样可能会成功。 或者,更频繁地采样路径中更有趣的部分,而更不频繁地采样路径中不那么有趣的部分可能是正确的方法。
These ideas are not foolproof though: if the input is a sentence, we can’t just look at the first few words or the last few words. And sampling a fixed number of words from every sentence won’t work either; omitting a single word (e.g., the word ‘not’) may change the meaning of the sentence.
这些想法并不是万无一失的:如果输入是一个句子,我们就不能只看前几个单词或最后几个单词。 而且,从每个句子中抽取固定数量的单词也是行不通的; 省略单个单词(例如单词“ not”)可能会更改句子的含义。
Nevertheless, Yoshua’s solution demonstrates that you may be able to come up with a simple approach that is good enough for your specific problem if you think about it carefully.
但是,Yoshua的解决方案表明,如果您仔细考虑一下,您也许可以提出一种简单的方法, 足以解决您的特定问题 。
Problem: How do we handle that intimidating Haversine distance function?
问题 :我们该如何处理吓人的Haversine距离函数?
Solution:
解决方案 :
Turns out that our concern about that distance function was justified. Yoshua and team did run into trouble when they used the Haversine function, so they had to find a simpler alternative.
事实证明,我们对距离函数的关注是合理的。 Yoshua和团队在使用Haversine函数时确实遇到了麻烦,因此他们必须找到一个更简单的替代方法。

Lesson learned:
学过的知识:
Again, this is a good example of problem-specific thinking.
同样,这是特定问题思考的一个很好的例子。
They didn’t try to devise a universal approximation to the Haversine distance. Given that the problem is set in Porto, they just needed something that worked well at the scale of that city. It didn’t have to work for larger distances.
他们没有尝试为Haversine距离设计一个通用近似值。 鉴于问题是在波尔图解决的, 他们只需要在该城市规模上运作良好的东西即可。 它不必工作更远的距离。
Once you realize this, a little Googling can lead you to the equirectangular distance, which looks a lot simpler than the Haversine.
一旦意识到这一点, 稍加谷歌搜索就可以将您引向等角距离,这看起来比Haversine要简单得多。
If you are familiar with machine learning, you have probably learned the importance of making sure that your loss function accurately captures the real-world objectives you care about for your problem.
如果您熟悉机器学习,则可能已经了解确保损失函数准确地捕捉您关心的现实目标的重要性。
But what you may not have learned is that when your loss function is complex (as it often is), you don’t have to find an approximation that’s good everywhere. It just has to be good enough within the scope of your problem.
但是您可能没有学到,当损失函数很复杂(通常如此)时,您不必找到在任何地方都适用的近似值。 在问题范围内,它必须足够好。
Problem: Does having two simple output nodes — one for latitude and one for longitude — work?
问题 :具有两个简单的输出节点(一个用于纬度,一个用于经度)是否可以工作?
As the destination we aim to predict is composed of two scalar values (latitude and longitude), it is natural to have two output neurons. However, we found that it was difficult to train such a simple model because it does not take into account any prior information on the distribution of the data.(emphasis mine) Source: https://arxiv.org/abs/1508.00021
由于我们要预测的目标是由两个标量值(纬度和经度)组成的,因此自然会有两个输出神经元。 但是,我们发现很难训练这样一个简单的模型,因为它没有考虑任何有关数据分布的先验信息。 (强调我的)来源: https : //arxiv.org/abs/1508.00021
By “prior information on the distribution of the data”, Yoshua and team are referring to the varying popularity of different destinations (e.g., the Sao Bento train station will be more popular than a particular residential address).
Yoshua和团队通过“有关数据分布的现有信息”指的是不同目的地的流行程度不同(例如,圣本图火车站将比特定的住所地址更受欢迎)。
Let’s see what they did! This is my favorite part of their paper.
让我们看看他们做了什么! 这是他们论文中我最喜欢的部分。
Solution:
解决方案 :
They ran a clustering algorithm on all the final destinations in the training set and grouped them into a few thousand clusters (3,392 to be exact).
他们在训练集中的所有最终目的地上运行了聚类算法,并将它们分组为数千个聚类(准确地说是3,392个)。
Conceptually, they went from this …
从概念上讲,他们从此出发……

… to something like this.
……像这样

(This is just for illustration. The actual clusters were probably not all of the same size and shape)
(这只是为了说明。实际的簇可能并非都具有相同的大小和形状)
Now, instead of directly predicting the latitude-longitude of the final destination, we can think of this as a multi-class classification problem where the task is to classify the input into one of those 3,392 clusters.
现在,代替直接预测最终目的地的经度,我们可以将其视为多类分类问题,其中的任务是将输入分类为这3392个聚类之一。

The final layer for a multi-class classification problem is usually a softmax layer, which gives you a probability distribution over all the possible output classes. In our example, the softmax layer will generate a probability for every one of the 3,392 clusters.
多类分类问题的最后一层通常是softmax层,它为您提供了所有可能的输出类的概率分布。 在我们的示例中,softmax层将为3,392个群集中的每一个生成概率。
It is standard practice in multi-class classification to pick the class with the highest probability as the predicted output. Accordingly, we can pick the highest-probability cluster and use the latitude-longitude of its center point as the predicted destination.
在多类别分类中,标准做法是选择概率最高的类别作为预测输出。 因此,我们可以选择最高概率的聚类,并使用其中心点的经纬度作为预测的目的地。
Notice how this transformation neatly takes into account the ‘prior information on the distribution of the data’: the clusters containing popular destinations will occur more frequently in the training set and will therefore, on average, have higher predicted probabilities.
请注意,此转换如何巧妙地考虑“ 关于数据分布的先验信息” :包含受欢迎目的地的聚类在训练集中会更频繁地出现,因此平均而言具有更高的预测概率。
This sounds pretty good, right?
听起来不错,对吗?
But what if an actual destination is at the corner of a cluster, far from the cluster center? Since we are using the cluster center as the prediction, the distance between our prediction and the actual destination will be non-zero for sure and may be sizable.
但是,如果实际目的地在集群的一角,远离集群中心,该怎么办? 由于我们将聚类中心用作预测,因此我们的预测与实际目的地之间的距离肯定不会为零,并且可能相当大。
One way to get around this issue is to increase the number of clusters we use. By generating (say) 5000 clusters, each cluster gets smaller and and every point in a cluster will be closer to its center. But we now have a multi-class classification problem with many more output classes. Without sufficient training data for every cluster, we won’t be able to train a good model.
解决此问题的一种方法是增加我们使用的群集数量。 通过生成(比如说)5000个群集,每个群集将变得更小,并且群集中的每个点都将更靠近其中心。 但是我们现在有一个多类分类问题,其中有更多的输出类。 没有每个集群的足够训练数据,我们将无法训练一个好的模型。
Yoshua and team devised a better way.
Yoshua和团队设计了一种更好的方法。
They multiplied the predicted cluster probabilities (i.e., the output of the softmax) by the coordinates of the cluster centers and added them up to calculate a weighted average latitude …
他们将预测的群集概率(即softmax的输出)乘以群集中心的坐标,并将它们相加,以计算加权平均纬度……

… and a weighted average longitude.
……以及加权平均经度。
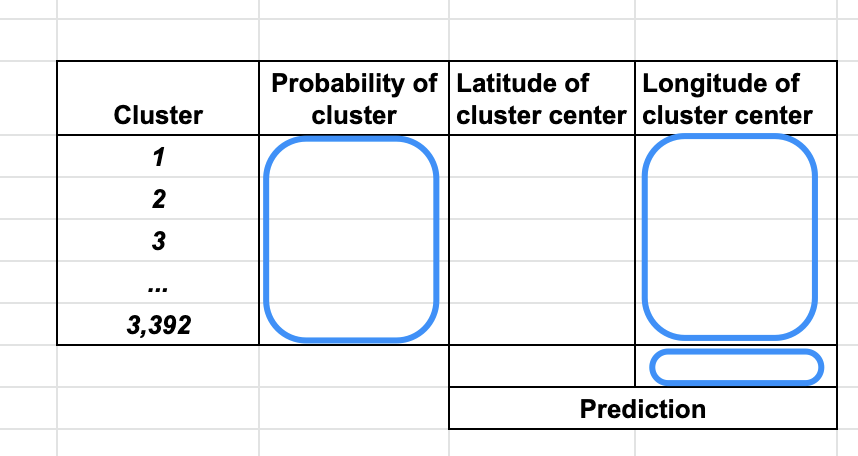
This (probability-weighted) latitude-longitude pair is the predicted destination.
此(概率加权)纬度-经度对是预测的目的地。

This means, for example, that if the model thinks that two adjacent clusters are equally likely to be the final destination, the midpoint of their centers will be predicted as the final destination.
例如,这意味着,如果模型认为两个相邻聚类同样有可能成为最终目的地,则将其中心的中点预测为最终目的地。
It is important to note that this final weighted-averaging step is not a post-processing step. It has to be part of the network — only then, the predicted latitude-longitude pair can be fed into the loss function, which, in turn, can be optimized to train the network.
重要的是要注意,这个最终的加权平均步骤不是后处理步骤。 它必须是网络的一部分-只有这样,预测的纬度-经度对才能被输入到损失函数中,而损失函数又可以被优化以训练网络。
To make this part of the network, they add a single linear layer after the softmax layer. This, in my opinion, was a master move :-)
为了使其成为网络的一部分, 他们在softmax层之后添加了一个线性层 。 我认为这是一个主要举措:-)

The weight matrix of this linear layer is just the cluster centers …
这个线性层的权重矩阵只是聚类中心……

… but with an important twist: the weights are kept fixed during training.
…但有一个重要的转折: 训练过程中重量保持固定。
After all, we already know what they are (i.e,, they aren’t randomly initialized weights, they come from the clustering algorithm) and don’t need to learn them.
毕竟,我们 已经知道它们是什么(即它们不是随机初始化的权重,它们来自聚类算法)并且不需要学习它们。
In summary, Yoshua and team:
总而言之,Yoshua和团队:
- first changed the problem from a two-output regression problem to a multi-class classification problem首先将问题从两输出回归问题变为多分类问题
- and then changed it back to a two-output regression problem by adding a final linear layer and two output nodes然后通过添加最终线性层和两个输出节点将其更改为两输出回归问题
- by making the cluster centers as the weight matrix for the linear layer but freezing the weights of this layer, they brought the weighted-averaging step inside the network and made end-to-end training of the network possible.通过将群集中心作为线性层的权重矩阵,但冻结该层的权重,他们将加权平均步骤引入了网络内部,并使网络的端到端训练成为可能。
Neat, right?
整洁吧?
BTW, if you are curious about which clustering algorithm was used:
顺便说一句,如果您对使用哪种聚类算法感到好奇:
The clusters were calculated with a mean-shift clustering algorithm on the destinations of all the training trajectories, returning a set of C = 3392 clusters. Source: https://arxiv.org/abs/1508.00021
使用均值漂移聚类算法在所有训练轨迹的目的地上计算聚类,返回一组C = 3392聚类。 资料来源: https : //arxiv.org/abs/1508.00021
Lessons learned:
得到教训:
- It is important to consider the prior distribution of the output values when thinking about the output layer. For classification problems, this is usually straightforward (and even automatic) but for regression problems like this one, it requires paying more attention than we normally do.在考虑输出层时,必须考虑输出值的先验分布。 对于分类问题,这通常是直接的(甚至是自动的),但是对于像这样的回归问题,它需要比我们通常注意的更多。
If the specifics of the problem require a particular kind of computation, define a layer to do it and include it in the network (rather than do it in an ad hoc manner outside the network) so that you can learn its parameters as part of the training process. As long as its derivative can be calculated, it is worth a try.
如果问题的具体内容需要特定类型的计算,则定义一个要执行的层并将其包含在网络中(而不是以网络外部的临时方式),以便您可以将其参数作为培训过程。 只要 可以计算其导数,就值得一试 。
If the above lesson makes you wonder why Yoshua and team did the clustering outside the network, instead of defining a layer for it in the network and learning the best clusters as part of training the network:
如果以上课程使您想知道Yoshua和团队为何在网络外部进行集群,而不是在网络中为其定义层并在训练网络时学习最佳集群:
One potential limitation of our clustering-based output layer is that the final prediction can only fall in the convex hull of the clusters. A potential solution would be to learn the clusters as parameters of the network and initialize them either randomly or from the mean-shift clusters. (emphasis mine)
我们基于聚类的输出层的一个潜在限制是最终预测只能落在聚类的凸包中。 一种可能的解决方案是将群集作为网络的参数进行学习,并随机地或从均值漂移群集中对其进行初始化 。 (强调我的)
Source: https://arxiv.org/abs/1508.00021
资料来源: https : //arxiv.org/abs/1508.00021
I hope you enjoyed this peek into how a Deep Learning master thinks. If none of these lessons were new to you, congratulations — you are well on your way to Deep Learning mastery!
我希望您喜欢深度学习大师的想法。 如果这些课程对您来说都不是新鲜事物,那么恭喜您-您已掌握深度学习!
(If you found this article helpful, you may find these of interest)
(如果您发现本文有帮助,你会发现这些利息)
翻译自: https://towardsdatascience.com/lessons-from-a-deep-learning-master-1e38404dd2d5
深度强化学习从入门到大师
http://www.taodudu.cc/news/show-1874018.html
相关文章:
- 自然语言处理 入门_自然语言处理入门指南
- 变形金刚图纸_变形金刚救援
- 传感器数据 数据库_丰富的数据,不良的数据:充分利用传感器
- 使用高德地图打车软件实现_强化学习:使用Q学习来打车!
- aws fargate_使用AWS Fargate部署PyCaret和Streamlit应用程序-无服务器基础架构
- ai-人工智能的本质和未来_带有人工智能的动画电子设备-带来难以想象的结果...
- 世界第一个聊天机器人源代码_这是世界上第一个“活着”的机器人
- pytorch深度学习入门_立即学习AI:01 — Pytorch入门
- 深度学习将灰度图着色_使用DeOldify着色和还原灰度图像和视频
- 深度神经网络 卷积神经网络_改善深度神经网络
- 采矿协议_采矿电信产品推荐
- 机器人控制学习机器编程代码_机器学习正在征服显式编程
- 强化学习在游戏中的作用_游戏中的强化学习
- 你在想什么?
- 如何识别媒体偏见_面部识别,种族偏见和非洲执法
- openai-gpt_GPT-3 101:简介
- YOLOv5与Faster RCNN相比。 谁赢?
- 句子匹配 无监督_在无监督的情况下创建可解释的句子表示形式
- 科技创新 可持续发展 论坛_可持续发展时间
- Pareidolia — AI的艺术教学
- 个性化推荐系统_推荐系统,个性化预测和优点
- 自己对行业未来发展的认知_我们正在建立的认知未来
- 汤国安mooc实验数据_用漂亮的汤建立自己的数据集
- python开发助理s_如何使用Python构建自己的AI个人助理
- 学习遗忘曲线_级联相关,被遗忘的学习架构
- 她玩游戏好都不准我玩游戏了_我们可以玩游戏吗?
- ai人工智能有哪些_进入AI有多么简单
- 深度学习分类pytorch_立即学习AI:02 —使用PyTorch进行分类问题简介
- 机器学习和ai哪个好_AI可以使您成为更好的运动员吗? 使用机器学习分析网球发球和罚球...
- ocr tesseract_OCR引擎之战— Tesseract与Google Vision
深度强化学习从入门到大师_深度学习大师的经验教训相关推荐
- 深度置信网络预测算法matlab代码_深度学习双色球彩票中的应用研究资料
点击蓝字关注我们 AI研习图书馆,发现不一样的世界 深度学习在双色球彩票中的应用研究 前言 人工神经网络在双色球彩票中的应用研究网上已经有比较多的研究论文和资料,之前比较火的AlphaGo中用到的深度 ...
- 华南理工深度学习与神经网络期末考试_深度学习算法地图
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的. 其它机器学习.深度学习算法的全面系统讲解可以阅读<机器学习-原理.算法与应用>,清华大学出版社,雷明 ...
- 华南理工深度学习与神经网络期末考试_深度学习基础:单层神经网络之线性回归...
3.1 线性回归 线性回归输出是一个连续值,因此适用于回归问题.回归问题在实际中很常见,如预测房屋价格.气温.销售额等连续值的问题.与回归问题不同,分类问题中模型的最终输出是一个离散值.我们所说的图像 ...
- seo从入门到精通_新手学习SEO一个月能学会吗?
很多刚接触学习SEO的朋友都会问:"新手学习SEO需要多久,一个月能学会SEO吗?"这个问题,首先我想在这里问的:"学会"是怎样的一个定义?如果你想学习编辑刚刚 ...
- 谁的python入门教程好_怎样学习Python?Python入门必看
Python目前可以用一个字来描述那就是"火",问题来了,这么火的语言零基础小白到底该怎样学习Python? 首先,从基础开始学习,切勿毛躁. 刚开始学习Python的时候,我们可 ...
- 深度学习这么调参训练_深度学习调参技巧
训练技巧对深度学习来说是非常重要的,作为一门实验性质很强的科学,同样的网络结构使用不同的训练方法训练,结果可能会有很大的差异.这里我总结了近一年来的炼丹心得,分享给大家,也欢迎大家补充指正. 参数初始 ...
- 深度学习这么调参训练_深度学习训练的小技巧,调参经验(转)
经常会被问到你用深度学习训练模型时怎么样改善你的结果呢?然后每次都懵逼了,一是自己懂的不多,二是实验的不多,三是记性不行忘记了.所以写这篇博客,记录下别人以及自己的一些经验. Ilya Sutskev ...
- 深度学习与无人车导论_深度学习导论
深度学习与无人车导论 改变游戏规则 图片的信誉归功于: https : //www.digitalocean.com/ 深度学习 已经成为许多新应用程序的主要驱动力,是时候真正了解为什么会这样了. 我 ...
- 深度学习这么调参训练_深度学习调参及训练技巧(转)
深度学习调参及训练技巧(转) 作者:婉儿飞飞 链接:https://www.jianshu.com/p/0b116c43eb16 来源:简书 简书著作权归作者所有,任何形式的转载都请联系作者获得授权并 ...
- 手机桌面隐藏大师_应用隐藏大师手机版下载-应用隐藏大师下载 v1.2-说说手游网...
应用隐藏大师怎么用,免root隐藏应用程序.应用隐藏大师app是一款无需root,即可轻松隐藏手机应用的软件,软件界面简约清爽,体积小巧便携,没有复杂繁琐的操作,极大程度保护你的隐私安全,不想让人看到 ...
最新文章
- JVM - 内存管理
- 用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。...
- Spark数据倾斜-采样倾斜key并分拆join操作-详细图解与代码
- python字符串输入_python如何输入字符串
- 使用sun misc Unsafe及反射对内存进行内省 introspection
- MTK 驱动(49)---TP测试规范
- 如何提高计算机网络速度,如何提高电脑网速?
- android极光推送被杀,关于APP进程被杀死,极光推送收不到消息的解决办法
- matlab怎么做线性插值,[MATLAB]领域插值和线性插值
- 高通Android Q(android10)设置默认锁屏壁纸
- python画图入门——for循环及调色盘的应用
- html5手机端纵向时间轴,html5触屏手机端响应式时间轴内容切换特效
- 开放数据资产估值白皮书,首创“数据势能”估值模型【附下载链接】
- 进阶高级自动化测试测试,Docker 常遇问题整理(带解决方案)
- 【openstack一键安装与部署】
- 新概念英语学习笔记-1
- 查看路由器中宽带的账号密码等
- 兰伯特(Lambert)方程的求解算法1
- 实体店防盗,RFID技术作用巨大
- 手机软件无法打开或一直闪退,黑屏的原因及解决方案?
热门文章
- [转] 如何快速掌握一门新技术/语言/框架
- Ext4文件系统架构分析(三) ——目录哈希、扩展属性与日志
- sql server 2000数据库 最近经常出现某进程一直占用资源,阻塞?死锁?
- readonly strong nonatomic 和IBOutlet
- ubuntu 程序卡主解决方案
- jupyter notebook 中文乱码问题解决
- Atitit Cookie安全法 目录 1. cookie分为 会话cookie 和 持久cookie , 1 1.1. 安全措施 1 1.2. 3. cookie的同源策略 2 1.3. 安全类库
- Atitit 把项目外包的面临的风险attilax总结
- Atitit 图像处理之编程之类库调用的接口api cli gui ws rest attilax大总结.docx
- Atitit onvif 协议截图 getSnapshotUri 使用java