spacy实体关系抽取_使用spacy从Wikipedia文章中命名实体识别
spacy实体关系抽取
使用Spacy的Wikipedia文章中的命名实体识别 (Named Entity Recognition From Wikipedia article using Spacy)
In this article we ‘ll try to find names of person in a wikipedia article using python spacy library. I assume that you have already installed spacy and wikipedia api libraries from pypi if you are planning to run source code from this article.
在本文中,我们将尝试使用python spacy库在Wikipedia文章中查找人名。 如果您打算运行本文的源代码,我假设您已经从pypi安装了spacy和Wikipedia api库。
Many a time articles are too long and we are only interested in certain information. We are either interested in summary or major events and major characters associated with the current. Here we are trying to just find person names from different articles. Determining whether a word is name of a person is done using pretrained models. Spacy does a good job of labeling these. We are going to explore that in this article.
很多时间文章太长,我们只对某些信息感兴趣。 我们对摘要或与当前事件相关的主要事件和主要特征感兴趣。 在这里,我们试图从不同的文章中查找人名。 使用预先训练的模型确定单词是否是人的名字。 Spacy在标记这些标签方面做得很好。 我们将在本文中进行探讨。
脚步 (Steps)
- Search for wikipedia articles搜索维基百科文章
- Use spacy to create document object使用spacy创建文档对象
- Iterate for entries and find the ones with label Person迭代条目并找到带有标签“ Person”的条目
- Count the frequency of person and plot them in descending order计算人的频率并按降序排列
In following section we list necessary imports. wikipedia api is python api used to get wikipedia content.
在以下部分中,我们列出了必要的进口。 Wikipedia api是用于获取Wikipedia内容的python API。
import wikipediaimport requestsimport spacyfrom collections import Counterimport matplotlib.pyplot as pltimport spacynlp = spacy.load('en_core_web_lg')在特定页面上搜索 (Search on a specific page)
Here we are trying to search a page for a given article. I have choosen Lord Krishna as our starting point. Let’s see who all are the most frequently occurring persons in wikipedia article relate to Lord Krishna.
在这里,我们试图在页面上搜索给定的文章。 我选择克里希纳勋爵为起点。 让我们看看谁是与克里希纳勋爵相关的维基百科文章中最常出现的人。
result = wikipedia.search("Krishna")result['Krishna', 'Krishna Krishna', 'Krishna Janmashtami', 'Krishna (Telugu actor)', 'Krishna Vamsi', 'Krishna Bhagavaan', 'International Society for Krishna Consciousness', 'Krishna-Krishna', 'Hare Krishna', 'Krishna (TV series)']We get the page content corresponding to the first article related to the first search result of our search term.
我们获得与搜索词的第一个搜索结果相关的第一篇文章所对应的页面内容。
page = wikipedia.page(result[0], preload= True)We get the parced document using spacy module.
我们使用spacy模块获得了经过解析的文档。
doc = nlp(page.content)#from spacy import displacyLets try to find the page url corresponding to first result of our search query
让我们尝试查找与我们的搜索查询的第一个结果相对应的页面网址
page.url'https://en.wikipedia.org/wiki/Krishna'#displacy.serve(doc, style="ent")Lets explore the part of speech taggings of different terms in our page. For illustration purpose I am showing just 10 tokens here.
让我们探索页面中不同术语的语音标记部分。 为了说明目的,我在这里仅显示10个令牌。
max_token_display = 10 for idx , token in enumerate(doc): # Print the token and its part-of-speech tag print(token.text, "-->", token.pos_, ) if idx > max_token_display: break;The --> DETMahābhārata --> PROPN( --> PUNCTUS --> PROPN: --> PUNCT, --> PUNCTUK --> PROPN: --> PUNCT; --> PUNCTSanskrit --> ADJ: --> PUNCTमहाभारतम् --> XHere are some labels corresponding to the words appearing in the document.
以下是与文档中出现的单词相对应的一些标签。
for idx , ent in enumerate(doc.ents): print(ent.text, ent.start_char, ent.end_char, ent.label_) if idx>max_token_display: breakMahābhārata 4 15 PERSONUS 17 19 GPEUK 23 25 GPESanskrit 29 37 LANGUAGEमहाभारतम् 39 48 CARDINALMahābhāratam 50 62 PERSONtwo 108 111 CARDINALSanskrit 118 126 NORPIndia 144 149 GPERāmāyaṇa 171 179 PERSONtwo 214 217 CARDINALthe Kurukshetra War 239 258 EVENTIn the below section we are trying to identify all the entries with label as person.
在下面的部分中,我们尝试将所有带有标签的条目标识为person。
persons = [ent.text for ent in doc.ents if ent.label_=='PERSON' ]Lets count the frequency of person names as identified by spacy on a particular wikipedia page
让我们计算在特定维基百科页面上由空格识别的人员姓名的出现频率
person_count = Counter(persons)print(person_count){'Pandavas': 31, 'Krishna': 25, 'Mahābhārata': 24, 'Mahabharata': 23, 'Pandu': 17, 'Dhritarashtra': 15, 'Yudhishthira': 14, 'Bhishma': 11, 'Kunti': 11, 'Kaurava': 8, 'Satyavati': 6, 'Madri': 6, 'Gandhari': 6, 'Vyasa': 5, 'Kuru': 5, 'Pandava': 5, 'Vichitravirya': 5, 'Vidura': 5, 'Kauravas': 5, 'Rāmāyaṇa': 4, 'Bhima': 4, 'Draupadi': 4, 'Jain': 4, 'Gupta': 3, 'Janamejaya': 3, 'Jaya': 3, 'Minkowski': 3, 'Parikshit': 3, 'Devavrata': 3, 'Amba': 3, 'Karna': 3, 'Yama': 3, 'Yayati': 3, 'Jarasandha': 3, 'Motilal Banarsidass': 3, 'BCE': 2, 'Ugraśrava Sauti': 2, 'Vasu': 2, 'Oberlies': 2, 'Kālidāsa': 2, 'Mahapadma Nanda': 2, 'Adhisimakrishna': 2, 'Shakuni': 2, 'Dushasana': 2, 'Ghatotkacha': 2, 'J. L. Fitzgerald': 2, 'P. Lal': 2, 'Bibek Debroy': 2, 'Shyam Benegal': 2, 'Vasudeva': 2, 'Jaini': 2, 'Oldenberg': 2}sort the persons from maximum to minimum occurrences of a person on a page.
按页面上某人的出现次数从大到小排序。
person_count = {k: v for k, v in sorted(person_count.items(), key=lambda item: item[1] , reverse=True) if v>1}print(person_count){'Pandavas': 31, 'Krishna': 25, 'Mahābhārata': 24, 'Mahabharata': 23, 'Pandu': 17, 'Dhritarashtra': 15, 'Yudhishthira': 14, 'Bhishma': 11, 'Kunti': 11, 'Kaurava': 8, 'Satyavati': 6, 'Madri': 6, 'Gandhari': 6, 'Vyasa': 5, 'Kuru': 5, 'Pandava': 5, 'Vichitravirya': 5, 'Vidura': 5, 'Kauravas': 5, 'Rāmāyaṇa': 4, 'Bhima': 4, 'Draupadi': 4, 'Jain': 4, 'Gupta': 3, 'Janamejaya': 3, 'Jaya': 3, 'Minkowski': 3, 'Parikshit': 3, 'Devavrata': 3, 'Amba': 3, 'Karna': 3, 'Yama': 3, 'Yayati': 3, 'Jarasandha': 3, 'Motilal Banarsidass': 3, 'BCE': 2, 'Ugraśrava Sauti': 2, 'Vasu': 2, 'Oberlies': 2, 'Kālidāsa': 2, 'Mahapadma Nanda': 2, 'Adhisimakrishna': 2, 'Shakuni': 2, 'Dushasana': 2, 'Ghatotkacha': 2, 'J. L. Fitzgerald': 2, 'P. Lal': 2, 'Bibek Debroy': 2, 'Shyam Benegal': 2, 'Vasudeva': 2, 'Jaini': 2, 'Oldenberg': 2}Here we are trying to plot the counts corresponding to each person appearing on the page.
在这里,我们试图绘制与页面上出现的每个人对应的计数。
fig = plt.gcf()ax= plt.gca()fig.set_size_inches(25.5, 25.5)plt.barh(list(person_count.keys()), person_count.values())plt.xticks(rotation=0, fontsize=40)plt.yticks(rotation=0, fontsize=25)for i, v in enumerate(person_count.values()): ax.text(v + 2, i + 0, str(v), color='black' ,fontsize = 20)plt.show()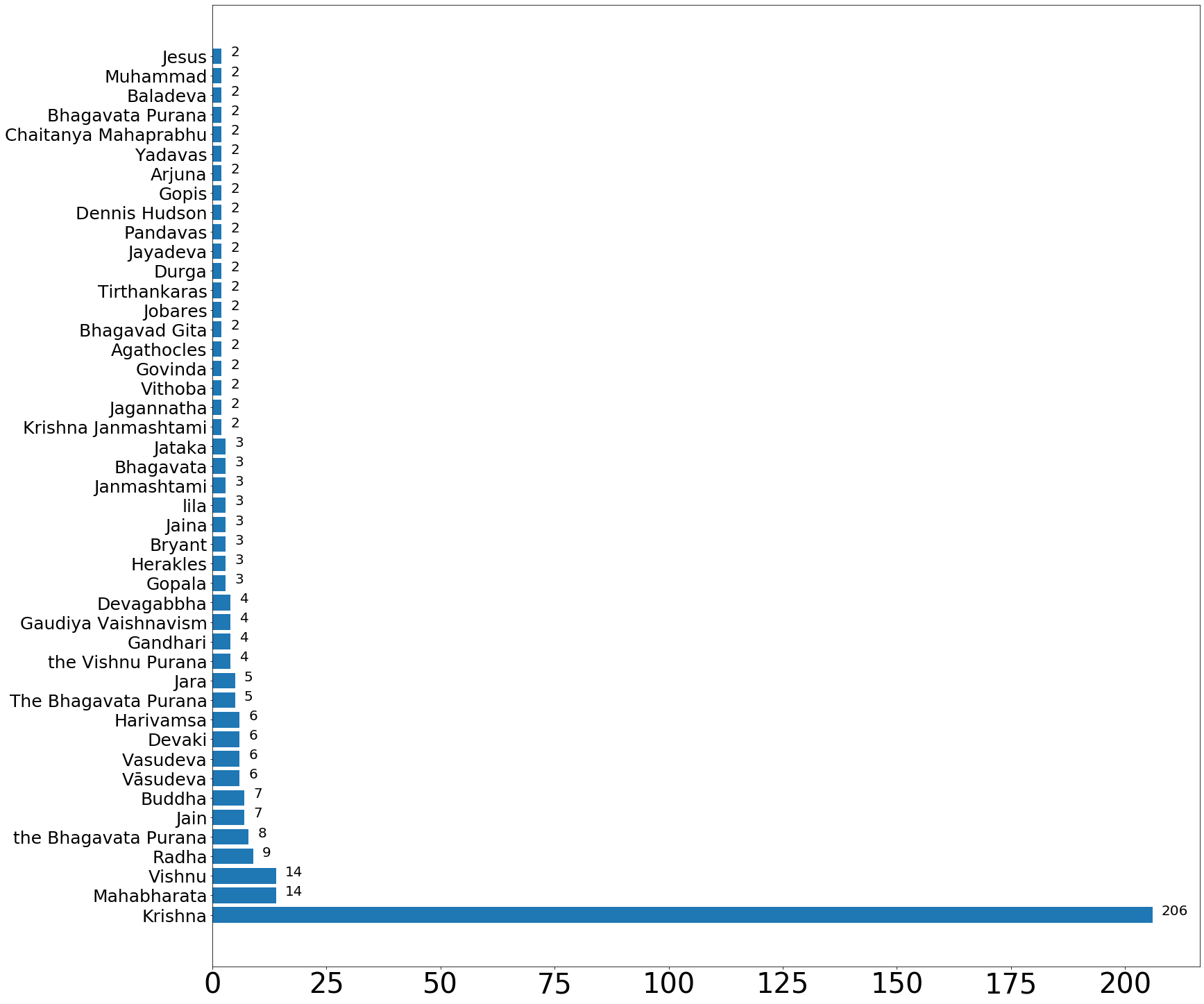
检查其他页面 (Check for the other page)
Following piece of code consolidates everything and uses a different search query for word ‘Jesus’
以下代码整合了所有内容,并对单词“耶稣”使用了不同的搜索查询
result = wikipedia.search("Jesus")page = wikipedia.page(result[0], preload= True)doc = nlp(page.content)persons = [ent.text for ent in doc.ents if ent.label_=='PERSON' ]person_count = Counter(persons)person_count = {k: v for k, v in sorted(person_count.items(), key=lambda item: item[1] , reverse=True) if v>1}fig = plt.gcf()ax= plt.gca()fig.set_size_inches(25.5, 25.5)plt.barh(list(person_count.keys()), person_count.values())plt.xticks(rotation=0, fontsize=40)plt.yticks(rotation=0, fontsize=25)for i, v in enumerate(person_count.values()): ax.text(v + 2, i + 0, str(v), color='black' ,fontsize = 20)plt.show()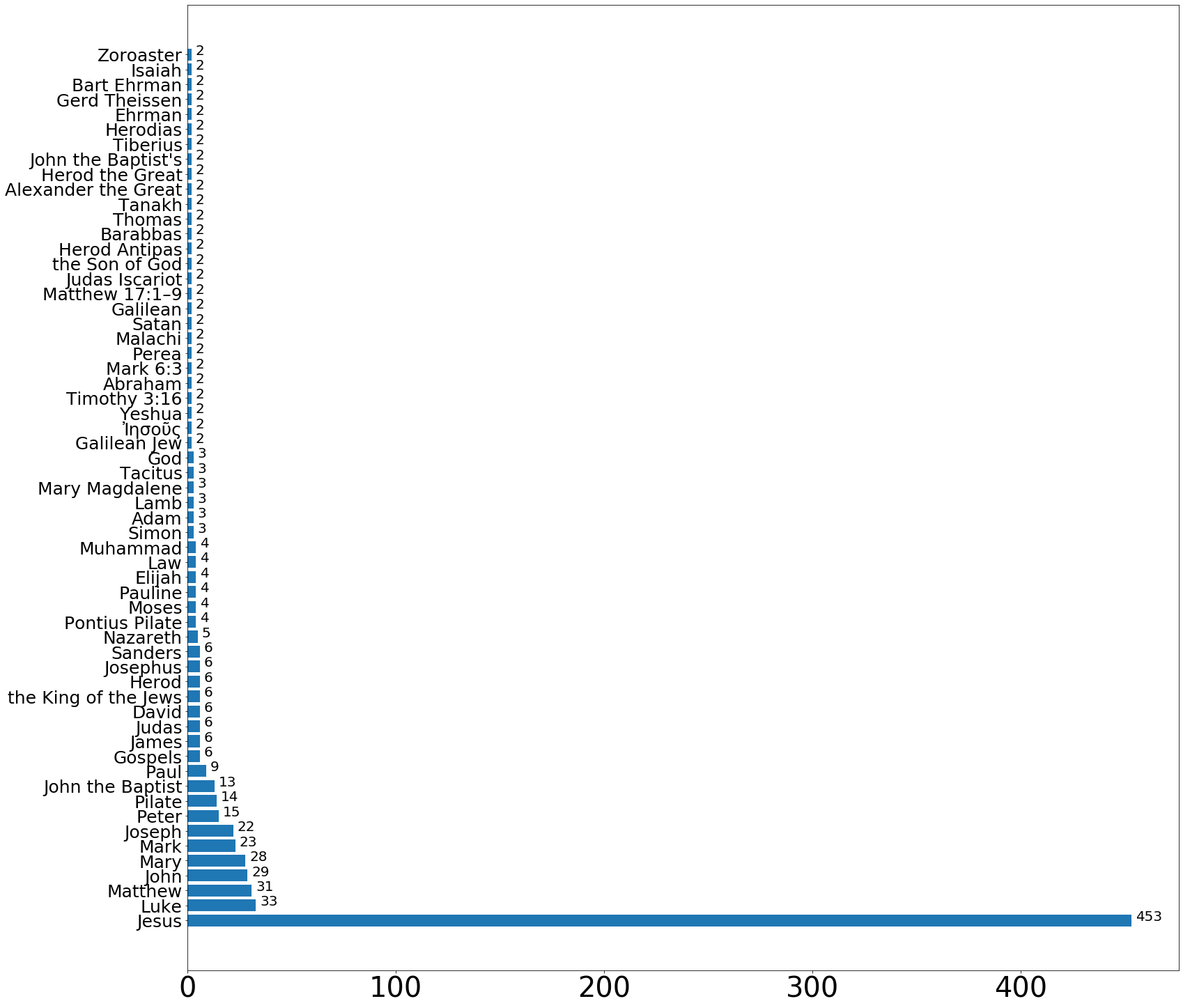
result = wikipedia.search("Mahabharat")page = wikipedia.page(result[0], preload= True)doc = nlp(page.content)persons = [ent.text for ent in doc.ents if ent.label_=='PERSON' ]person_count = Counter(persons)person_count = {k: v for k, v in sorted(person_count.items(), key=lambda item: item[1] , reverse=True) if v>1}fig = plt.gcf()ax= plt.gca()fig.set_size_inches(25.5, 25.5)plt.barh(list(person_count.keys()), person_count.values())plt.xticks(rotation=0, fontsize=40)plt.yticks(rotation=0, fontsize=25)for i, v in enumerate(person_count.values()): ax.text(v + 2, i + 0, str(v), color='black' ,fontsize = 20)plt.show()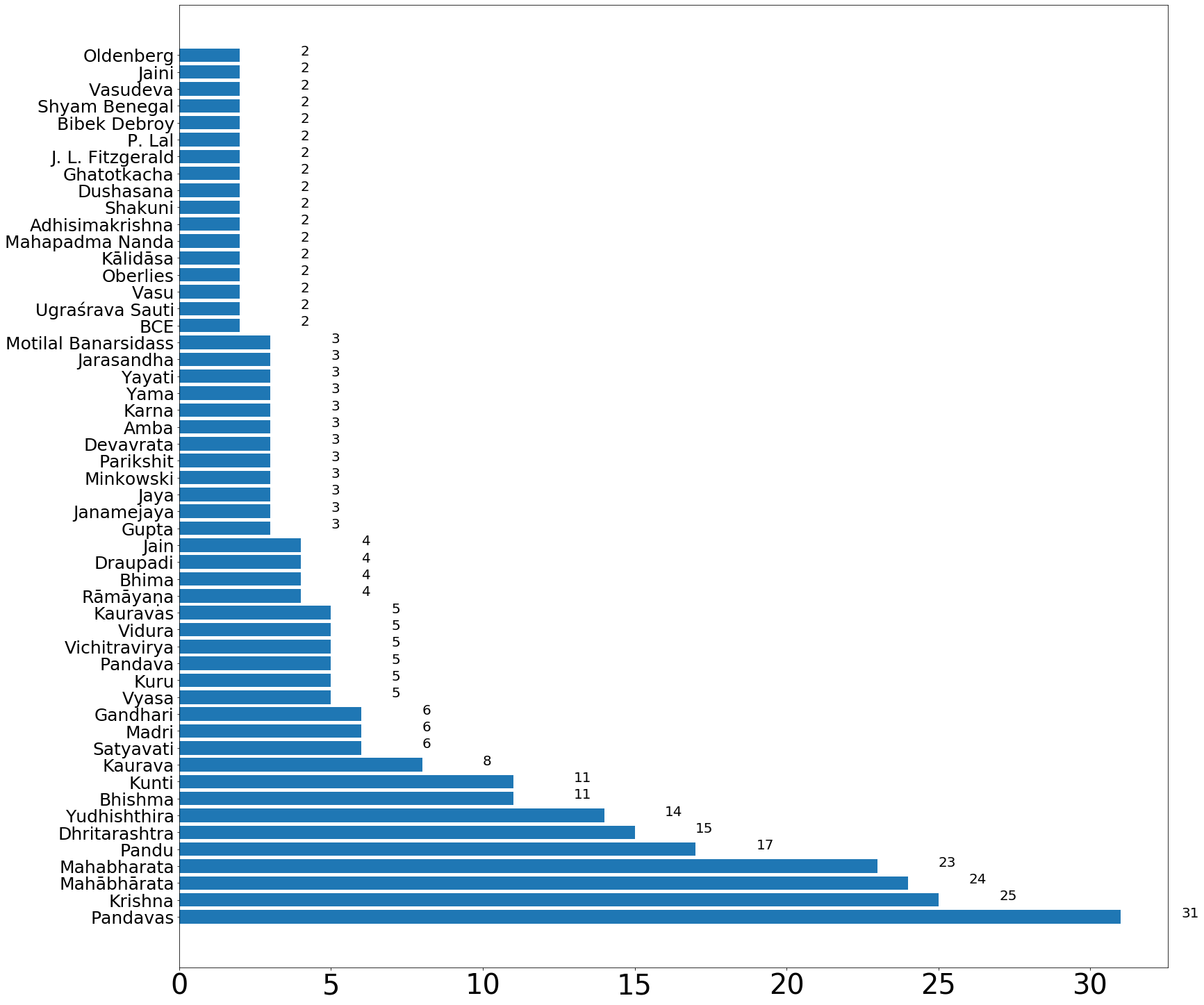
创建一个包含以上所有功能的函数 (Create a function including all above)
Finally we can create a function that plots all the names present on the first page from the list of pages from search result of a given term. Here the search title is given as an argument. Details for this Method can be found in previous sections.
最后,我们可以创建一个函数,该函数从给定术语的搜索结果的页面列表中绘制出出现在首页上的所有名称。 在此,搜索标题作为参数给出。 该方法的详细信息可以在前面的部分中找到。
def plot_names_from_page(title = "Mahabharat"): result = wikipedia.search(title) page = wikipedia.page(result[0], preload= True) doc = nlp(page.content) persons = [ent.text for ent in doc.ents if ent.label_=='PERSON' ] person_count = Counter(persons) person_count = {k: v for k, v in sorted(person_count.items(), key=lambda item: item[1] , reverse=True) if v>1} print(page.url) fig = plt.gcf() ax= plt.gca() fig.set_size_inches(25.5, 25.5) plt.barh(list(person_count.keys()), person_count.values()) plt.xticks(rotation=0, fontsize=40) plt.yticks(rotation=0, fontsize=25) #plt.title(page.url, fontdict={size:20}) for i, v in enumerate(person_count.values()): ax.text(v + 2, i + 0, str(v), color='black' ,fontsize = 20) plt.show()Finally we can use above function to get occurrences of different names on a wikipedia page. I tried to find names in article for variety of topics. First one is related to the books Illiad by homer. Most of the names are characters in the book. It may also include writer’s name.
最后,我们可以使用上面的函数在Wikipedia页面上获取不同名称的出现。 我试图在文章中找到涉及多个主题的名称。 第一个与荷马的《伊利亚德》有关。 大部分名称是书中的字符。 它还可能包括作者的名字。
plot_names_from_page('Illiad')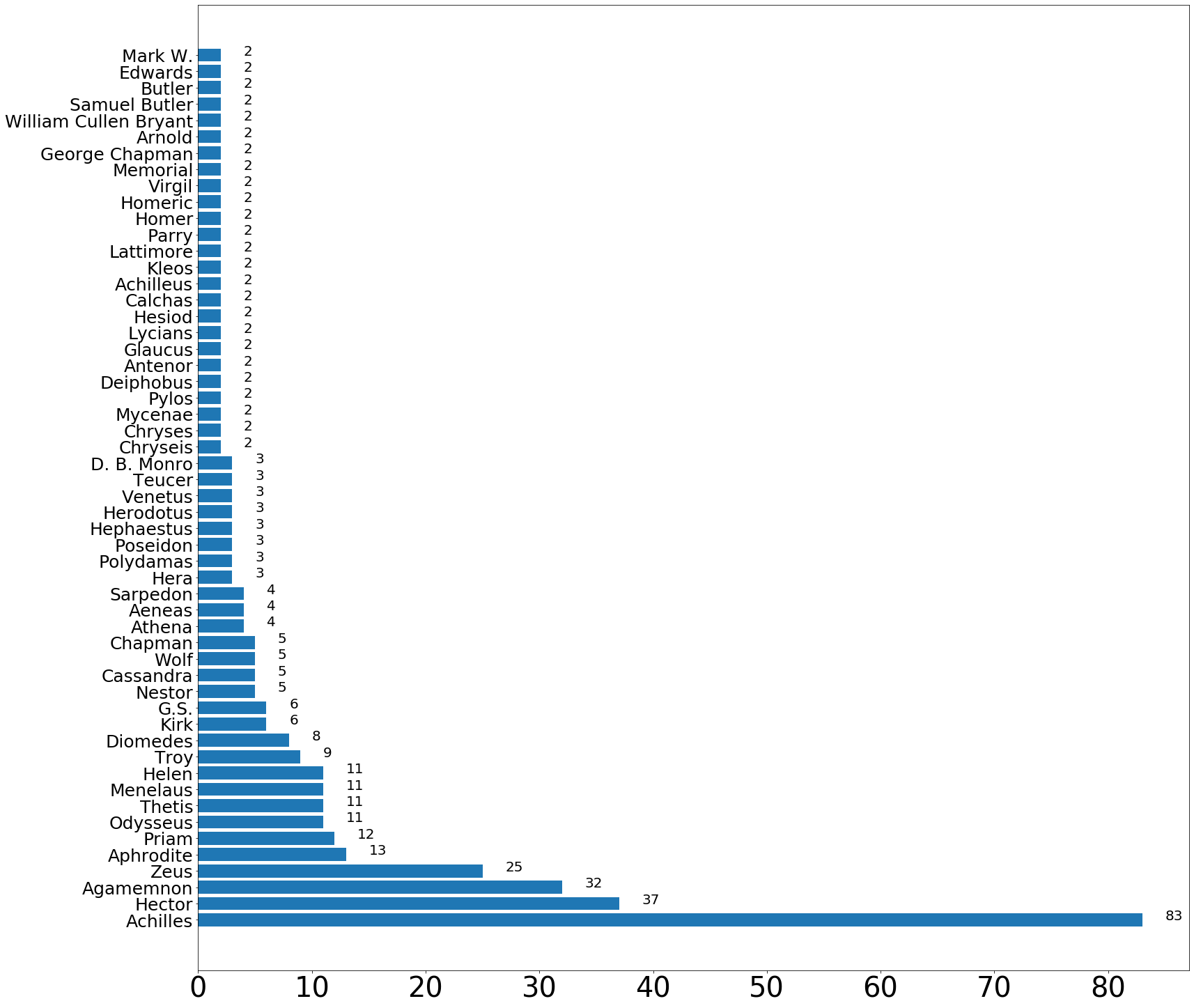
Following are the names corresponding to the article for great Hindu epic Ramayan. As we can expect name of Lord Rama appears most of the times here.
以下是与伟大印度教史诗《 Ramayan》的文章相对应的名称。 可以预见,拉玛勋爵的名字在这里经常出现。
plot_names_from_page('Ramayan')
plot_names_from_page('World_War_I')https://en.wikipedia.org/wiki/World_War_I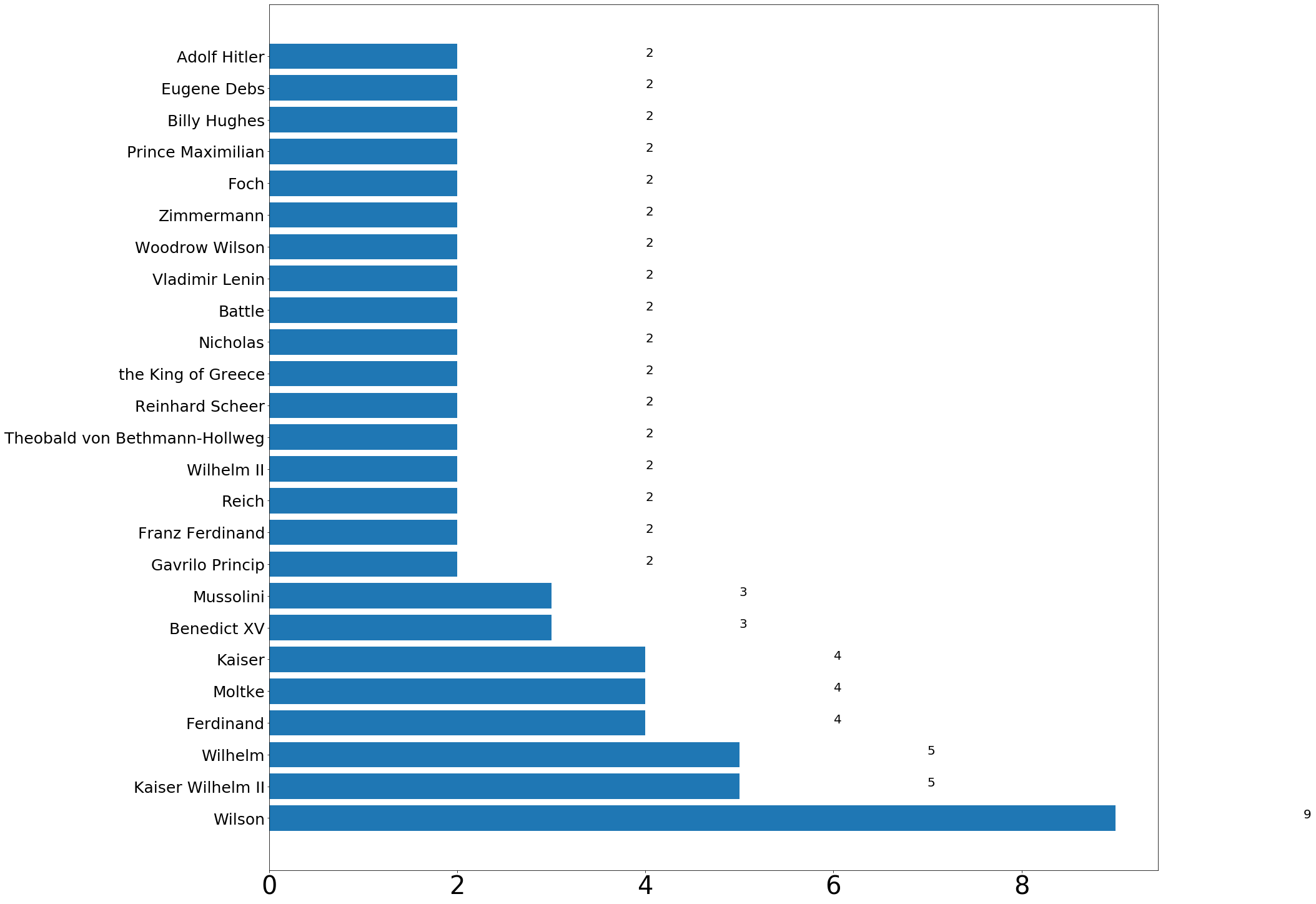
plot_names_from_page('great depression')https://en.wikipedia.org/wiki/Great_Depression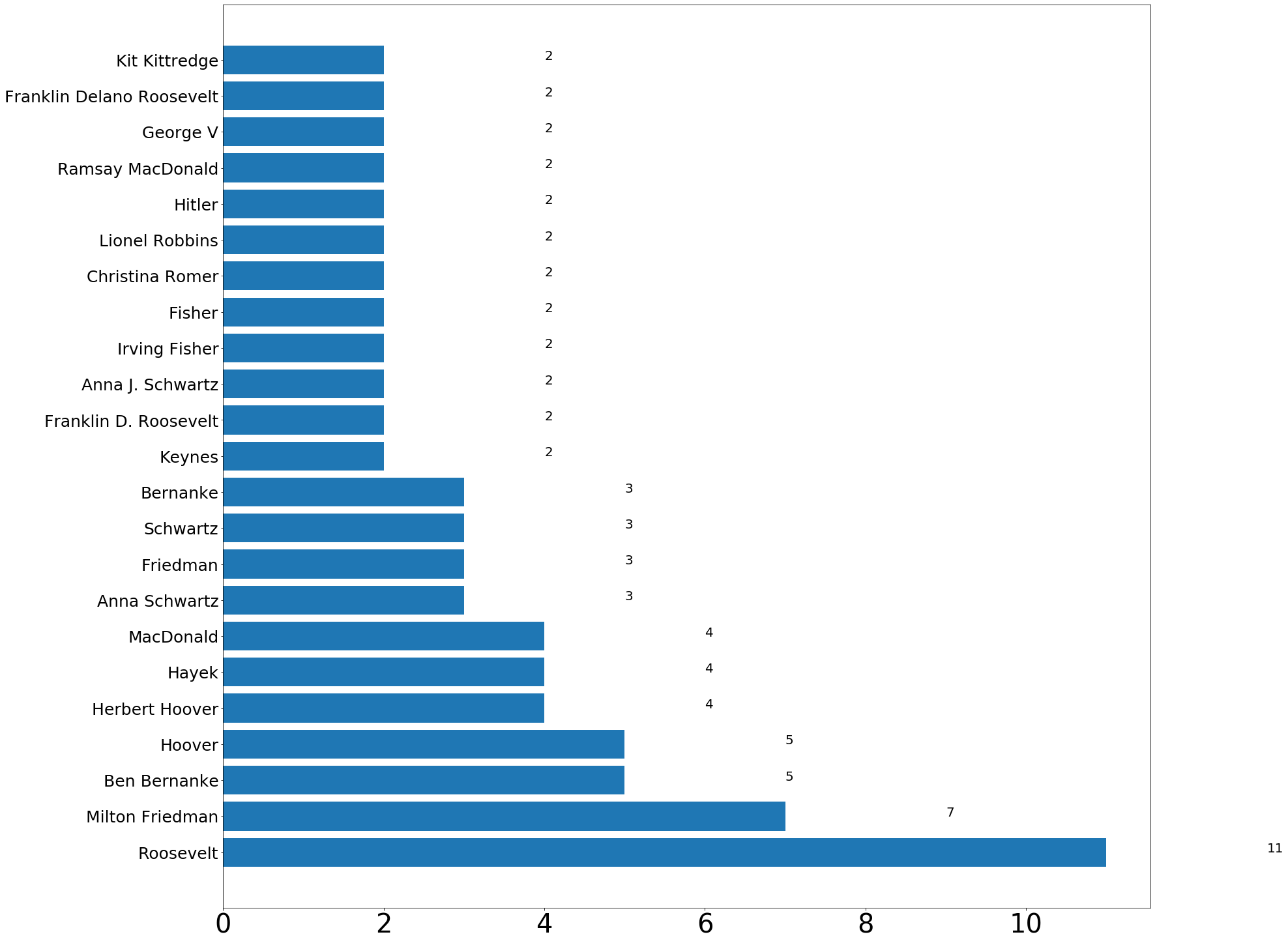
plot_names_from_page('higgs boson')https://en.wikipedia.org/wiki/Higgs_boson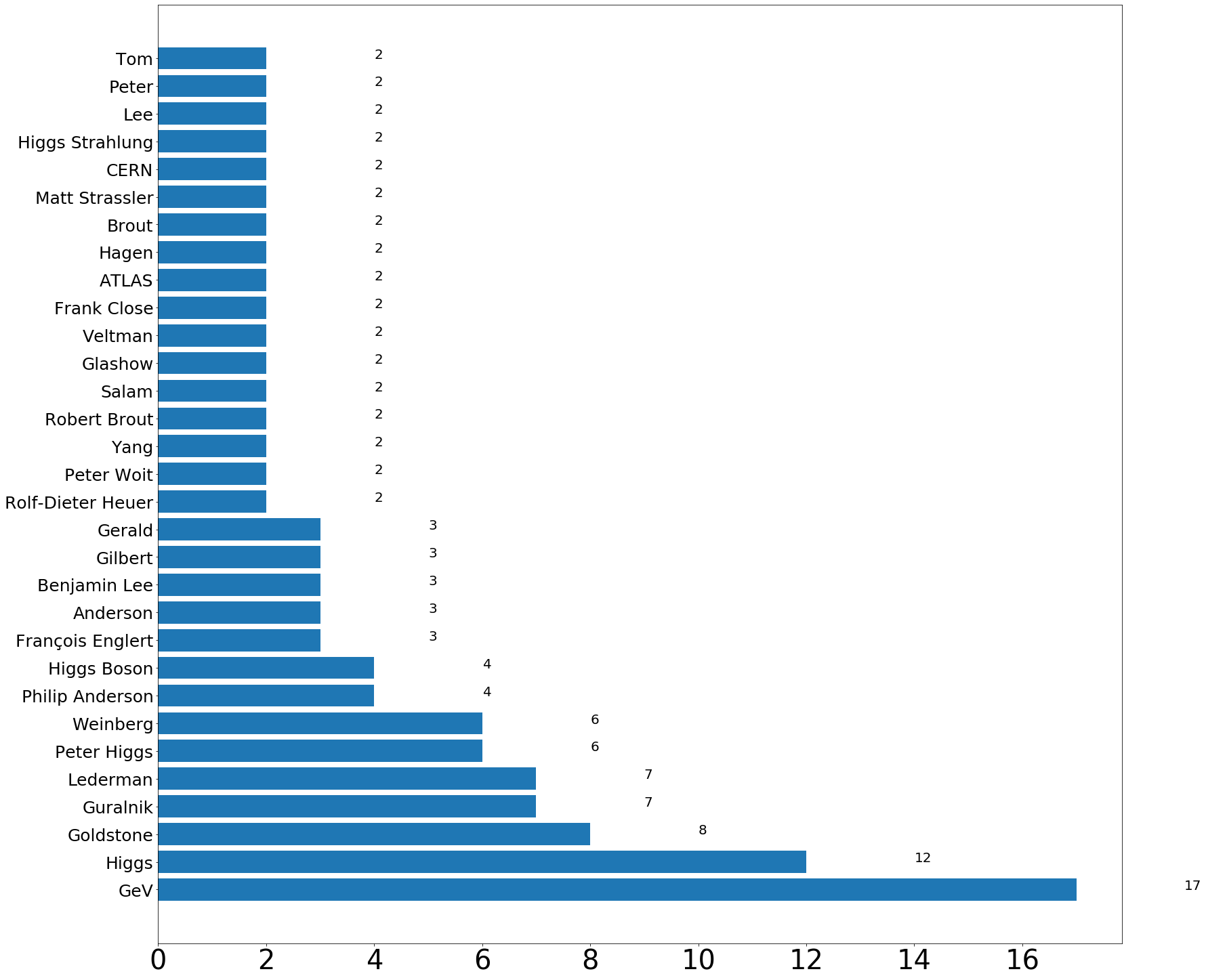
References :
参考文献:
https://www.mediawiki.org/wiki/API:Main_page
https://www.mediawiki.org/wiki/API:Main_page
翻译自: https://medium.com/@pankaj.tiwari2/named-entity-recognition-from-wikipedia-article-using-spacy-73f8cbdc9851
spacy实体关系抽取
http://www.taodudu.cc/news/show-2599058.html
相关文章:
- 产品读书《谷歌和亚马逊如何做产品》
- 计算机英语(王艺)翻译(unit1-unit5)
- 区块链知识转载博文1: 共识算法之争(PBFT,Raft,PoW,PoS,DPoS,Ripple)
- 对马的幽灵是关于人的
- 光子晶体的应用背景和研究历史
- 如何用数据说话-《数据化决策(美)道格拉斯·W.哈伯德》笔记与心得
- 软件随想录(local.joelonsoftware.com/wiki)-2002年12月11日 程序设计领域的帕麦尔斯顿勋爵 - Lord Palmerston on Programming
- 随手练——小米OJ 高弗雷勋爵
- 小米全国高校编程大赛 高弗雷勋爵
- mioj高弗雷勋爵
- python 随机产生一个整数 并猜测该数字小游戏
- 关于VSCode编码:自动猜测编码字符集
- C语言 猜数游戏 首先由计算机产生一个随机数,并给出这个随机数所在的区间,然后有游戏者猜测这个数。猜中游戏结束,并可以重新挑战,猜错重新给出提示,如果猜测超过八次游戏失败。
- 生成1-100随机数并进行猜测
- VSCode猜测字符编码
- 【Java】猜数字,程序随机分配给客户一个1-100之间的整数,用户在输入对话框中输入自己的猜测,程序返回提示信息,提示信息分别是:“猜大了”、“猜小了”和“猜对了”,用户可根据提示信息再次输入猜测
- 猜测随机数
- [java/初学者] 猜测随机数字的大小
- 基于双服务器的抗关键词猜测攻击的公钥可搜索加密方案
- 什么是错误猜测法?
- 1090: 哥德巴赫猜测
- Java模拟猜数字小游戏,有次数限制,并且输出猜测次数。
- 猜数字游戏:随机生成一个1-100之间的数据,提示用户猜测,猜大提示过大,猜小提示过小,直到猜中结束游戏
- 猜测商品价格小游戏
- Python猜数字游戏(包含异常处理,可自定义随机数产生范围、最大猜测次数,如果用户猜错的话可根据输入情况缩小猜测范围)
- 猜数游戏,随机生成一个1~100的数进行猜测。
- 防止vps上SSH被猜测密码
- 猜单词游戏。计算机随机产生一个单词,打乱字母顺序,供玩家去猜 a.准备一组单词,随机抽取一个b.将抽取的单词作为答案,打乱字母顺序,显示给玩家,供其猜测c.猜测错误继续猜测或以空字符串.
- 【c语言】产生一个1到1000的随机整数,用户进行猜测
- python实现猜测随机数
spacy实体关系抽取_使用spacy从Wikipedia文章中命名实体识别相关推荐
- python实体关系抽取_【关系抽取】从文本中进行关系抽取的几种不同的方法
关系提取是指从文本中提取语义关系,这种语义关系通常发生在两个或多个实体之间.这些关系可以是不同类型的." Paris is in France "表示巴黎与法国之间的" ...
- 命名实体识别 实体抽取_您的公司为什么要关心命名实体的识别
命名实体识别 实体抽取 Named entity recognition is the task of categorizing text into entities, such as people, ...
- 《面向对话的融入交互信息的实体关系抽取》--中文信息学报
实体关系抽取旨在从文本中抽取出实体之间的语义关系,是自然语言处理的一项基本任务.在新闻报道,维基百科等规范文本上,该任务的研究相对丰富且已取得了一定的效果,但面对对话文本的相关研究的还处于起始阶段.相 ...
- 基于主体掩码的实体关系抽取方法
点击上方蓝字关注我们 基于主体掩码的实体关系抽取方法 郑慎鹏1, 陈晓军1, 向阳1, 沈汝超2 1 同济大学电子与信息工程学院,上海 201804 2 上海国际港务(集团)股份有限公司,上海 200 ...
- 【论文阅读笔记】面向医学文本的实体关系抽取研究综述
面向医学文本的实体关系抽取研究综述 写在前面 深度学习方法 监督学习 基于简单的CNN模型 基于CNN模型的改进 基于RNN模型 基于注意力机制的模型 远程监督的多实例学习 分段卷积神经网络模型及改进 ...
- 深度学习实体关系抽取研究综述笔记
鄂海红,张文静,肖思琪,程瑞,胡莺夕,周筱松,牛佩晴.深度学习实体关系抽取研究综述.软件学报,2019,30(6): 1793−1818. http://www.jos.org.cn/1000-982 ...
- 知识图谱--实体关系抽取,依存句法分析
我爱自然语言处理 https://www.52nlp.cn/tag/%E4%BE%9D%E5%AD%98%E5%8F%A5%E6%B3%95%E5%88%86%E6%9E%90 基于Hanlp的依存句 ...
- 阿里云医疗实体关系抽取大赛
1.本项目是基于阿里云比赛开放的医疗数据集去做的实体关系抽取.下面会从数据的详情,模型的选取,模型的训练,模型的验证和模型的预测去讲述. 2.数据准备阶段 1.数据来源是阿里云医疗大赛,选取的是其中一 ...
- PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
相关文章: 1.快递单中抽取关键信息[一]----基于BiGRU+CR+预训练的词向量优化 2.快递单信息抽取[二]基于ERNIE1.0至ErnieGram + CRF预训练模型 3.快递单信息抽取[ ...
- spacy spaCy主要功能包括分词、词性标注、词干化、命名实体识别、名词短语提取等等
spaCy主要功能包括分词.词性标注.词干化.命名实体识别.名词短语提取等等https://zhuanlan.zhihu.com/p/51425975
最新文章
- mysql主键始终从小到大_Mysql从入门到入神之(四)B+树索引
- python画二维散点图-python3怎样画二维点图
- C#中的非托管资源释放(FinalizeDispose)
- Flutter开发-iOS报错Trying to embed a platform view but the PrerollContext does not s
- 3pc_three phase commit protocol协议理解
- 基于小程序的Token身份权限体系
- 机器学习任务的一般步骤
- 数据库导出Excel乱码 解决
- Promise 与 RXJS的区别
- 魔兽名字显示服务器,魔兽世界怀旧服服务器名称
- Vista中运行软件的兼容性测试(转)
- Photoshop Cs5上经常使用的快捷键汇总
- CSS基础班笔记(二)
- 解决ubantu 安装gitlab 失败 Unable to locate package gitlab-ce
- java计算机毕业设计智慧农业水果销售系统MyBatis+系统+LW文档+源码+调试部署
- JSONViewer下载路径
- [超详细]微信小程序使用iconfont教程及解决真机无法显示问题
- ARMV8体系结构简介:预备知识
- from pdfminer.pdfinterp import PDFResourceManager, process_pdf ImportError: cannot import name 'proc
- 使用QGIS配准无人机航片
热门文章
- Oracle linux7.2安装11g RAC
- 无法访问网址的最基本原因分析,让你永远无法访问淘宝/京东
- JPEG与jpg的区别
- 女生适合做产品经理吗?
- ckfinder 配置 php,CKEditor4+CKFinder3(php版本)安装及配置方法
- FFMPEG视频编码 NVIDIA 和 INTEL 硬件加速 x265 8bit 和 10bit
- 项目管理:名词解释、区别联系、案例分析
- python random函数sample_Python random.sample()用法及代码示例
- 计算机 中职生学情分析,信息技术学情分析
- 没人教的项目管理方法之(练好你的站桩) 一、 干系人分析应该怎么做