RocksDB源码学习-四-读-三
文章目录
- GetContext
- FilePicker
- GetNextFile
- GetNextLevelIndex
- PrepareNextLevel
- TableCache
注:本篇博客涉及的代码版本均为v7.7.4。
上两篇博客中我们分析了 RocksDB 如何在内存中查找对应的数据,这一篇我们将会详细分析当内存中未找到记录时,RocksDB 如何在磁盘上查找对应的数据。
依旧是从 DBImpl::GetImpl() 开始,当再 memtable 和 immutable memtable 中均没有找到后,会进入如下代码段:
if (!done) {PERF_TIMER_GUARD(get_from_output_files_time);sv->current->Get(read_options, lkey, get_impl_options.value, get_impl_options.columns,timestamp, &s, &merge_context, &max_covering_tombstone_seq,&pinned_iters_mgr,get_impl_options.get_value ? get_impl_options.value_found : nullptr,nullptr, nullptr,get_impl_options.get_value ? get_impl_options.callback : nullptr,get_impl_options.get_value ? get_impl_options.is_blob_index : nullptr,get_impl_options.get_value);RecordTick(stats_, MEMTABLE_MISS);
}
即,会调用 Version::Get() 函数,而这个函数,才真正进入磁盘中开始查找。简单的来说,该函数要先找到可能存在的目标 key 的 sstable,然后再从该 sstable 中查找目标 key,如果没找到,就再找下一个可能存在目标 key 的 sstable,然后继续在其中查找,以此迭代,直到把所有的 level 都找一遍。我们截取它的部分代码,主要分为三个部分,如下:
void Version::Get(const ReadOptions& read_options, const LookupKey& k,PinnableSlice* value, PinnableWideColumns* columns,std::string* timestamp, Status* status,MergeContext* merge_context,SequenceNumber* max_covering_tombstone_seq,PinnedIteratorsManager* pinned_iters_mgr, bool* value_found,bool* key_exists, SequenceNumber* seq, ReadCallback* callback,bool* is_blob, bool do_merge) {// ...GetContext get_context(user_comparator(), merge_operator_, info_log_, db_statistics_,status->ok() ? GetContext::kNotFound : GetContext::kMerge, user_key,do_merge ? value : nullptr, do_merge ? columns : nullptr,do_merge ? timestamp : nullptr, value_found, merge_context, do_merge,max_covering_tombstone_seq, clock_, seq,merge_operator_ ? pinned_iters_mgr : nullptr, callback, is_blob_to_use,tracing_get_id, &blob_fetcher);// ...FilePicker fp(user_key, ikey, &storage_info_.level_files_brief_,storage_info_.num_non_empty_levels_,&storage_info_.file_indexer_, user_comparator(),internal_comparator());FdWithKeyRange* f = fp.GetNextFile();while (f != nullptr) {*status = table_cache_->Get(read_options, *internal_comparator(), *f->file_metadata, ikey,&get_context, mutable_cf_options_.prefix_extractor,cfd_->internal_stats()->GetFileReadHist(fp.GetHitFileLevel()),IsFilterSkipped(static_cast<int>(fp.GetHitFileLevel()),fp.IsHitFileLastInLevel()),fp.GetHitFileLevel(), max_file_size_for_l0_meta_pin_);switch (get_context.State()) {// ...case GetContext::kFound:// ...}f = fp.GetNextFile();// ...}
}
四个部分依次如下:
- 用 get_context 来维护查找过程中的上下文,类似与在 memtable 中查找时的 saver。
- 创建一个文件选择器 FilePicker,名为 fp。
- 通过 fp.GetNextFile() 得到可能存在目标 key 的 sstable。
- 通过 table_cache_->Get() 在上述 sstable 中查找目标 key,如果没找到就重新执行步骤 3 来迭代。
GetContext
首先看查找前的初始化,创建一个变量 get_context,其类型未类 GetContext,该类用来保存查询过程中的一些上下文,比如目标 key、查询状态、时间戳等等,其作用类似于在 memtable 中辅助查找的结构体 Saver。构造函数如下:
GetContext::GetContext(const Comparator* ucmp, const MergeOperator* merge_operator, Logger* logger,Statistics* statistics, GetState init_state, const Slice& user_key,PinnableSlice* pinnable_val, PinnableWideColumns* columns,std::string* timestamp, bool* value_found, MergeContext* merge_context,bool do_merge, SequenceNumber* _max_covering_tombstone_seq,SystemClock* clock, SequenceNumber* seq,PinnedIteratorsManager* _pinned_iters_mgr, ReadCallback* callback,bool* is_blob_index, uint64_t tracing_get_id, BlobFetcher* blob_fetcher): ucmp_(ucmp),merge_operator_(merge_operator),logger_(logger),statistics_(statistics),state_(init_state),user_key_(user_key),pinnable_val_(pinnable_val),columns_(columns),timestamp_(timestamp),value_found_(value_found),merge_context_(merge_context),max_covering_tombstone_seq_(_max_covering_tombstone_seq),clock_(clock),seq_(seq),replay_log_(nullptr),pinned_iters_mgr_(_pinned_iters_mgr),callback_(callback),do_merge_(do_merge),is_blob_index_(is_blob_index),tracing_get_id_(tracing_get_id),blob_fetcher_(blob_fetcher) {if (seq_) {*seq_ = kMaxSequenceNumber;}sample_ = should_sample_file_read();
}
需要留意一下,当 Version::Get() 构造 GetContext 时,第 7 个参数 pinnable_val(PinnableSlice* )的值取决于 do_merge,如果 do_merge 为 true,则传入 value(PinnableSlice*),反之则传入 nullptr。
FilePicker
接下来我们看一下辅助类 FilePicker,类如其名,作用就是通过传入的 user_key (LookupKey 中的)来获取到可能位于的 sstable 里。该类的一些私有字段如下:
class FilePicker {// ...private:unsigned int num_levels_;unsigned int curr_level_;unsigned int returned_file_level_;unsigned int hit_file_level_;int32_t search_left_bound_;int32_t search_right_bound_;autovector<LevelFilesBrief>* level_files_brief_;bool search_ended_;bool is_hit_file_last_in_level_;LevelFilesBrief* curr_file_level_;unsigned int curr_index_in_curr_level_;unsigned int start_index_in_curr_level_;Slice user_key_;Slice ikey_;FileIndexer* file_indexer_;const Comparator* user_comparator_;const InternalKeyComparator* internal_comparator_;// ...
}
先简单的介绍一下各字段的含义:
| 字段 | 含义 |
|---|---|
| num_levels_ | 磁盘中一共有多少层 level |
| curr_level_ | 当前所在的 level |
| returned_file_level_ | 返回的 sstable 所在的 level |
| hit_file_level_ | 命中的 sstable 所在的 level |
| search_left_bound_ | 下一层查找的左边界 sstable 下标 |
| search_right_bound_ | 下一层查找的右边界 sstable 下标 |
| level_files_brief_ | 所有 level 的 LevelFilesBrief 组成的一个 vector |
| search_ended_ | 查找是否结束 |
| is_hit_file_last_in_level_ | 命中的 sstable 是否为当前 level 中的最后一个 |
| curr_file_level_ | LevelFilesBrief 类型,为一个 level 中的所有 sstable 组成的数组的头节点 |
| curr_index_in_curr_level_ | 当前 sstable 位于当前 level 的下标 |
| start_index_in_curr_level_ | 当前 level 的查找起点 sstable 的下标 |
| user_key_ | 目标 user_key(实际就是 ikey_ 中的 user_key) |
| ikey_ | LookupKey |
这里,我们重点关注三个字段:search_left_bound_ 、search_right_bound_ 、level_files_brief_,它们三个均和接下来要介绍的重点函数 GetNextFile() 密不可分。在介绍开始之前,我们先回顾一下 RocksDB 在磁盘中迭代查找 sstable 的逻辑:
level0 是可重叠的,因此迭代时,要把整个 level0 遍历一遍。而在非 level0,每层只需定位到一个 sstable 即可,如果该层查找失败,进入下一层,而这 “定位” 就是问题的关键。当要进入下一个 level 开始查找时,RocksDB 不会把遍历该 level 来查 sstable,而是通过二分查找的方式所有 sstable 的范围。
为了加速二分查找的速度,每次更新 sstable 的时候,RocksDB 都会调用 FileIndexer::UpdateIndex() 来更新一个结构,名为 FileIndexer,它主要是用来保存每一个 level 和 level+1 的 key 范围的关联信息,这样当我们在 level查找的时候,如果没有查找到信息,那么我们将会迅速得到下一个 level 需要查找的 sstable 范围。至于怎么更新的,我们先不管。每一个 key 来进行比较只会有三种情况:
- 小于当前 sstable 的 smallest。
- 大于当前 sstable 的 largest。
- 处于这个范围。
FileIndexer 维护了如下四个字段:
// Point to a left most file in a lower level that may contain a key,// which compares greater than smallest of a FileMetaData (upper level)int32_t smallest_lb;// Point to a left most file in a lower level that may contain a key,// which compares greater than largest of a FileMetaData (upper level)int32_t largest_lb;// Point to a right most file in a lower level that may contain a key,// which compares smaller than smallest of a FileMetaData (upper level)int32_t smallest_rb;// Point to a right most file in a lower level that may contain a key,// which compares smaller than largest of a FileMetaData (upper level)int32_t largest_rb;
官方还给了例子来帮助理解,如下:
// Example:
// level 1: [50 - 60]
// level 2: [1 - 40], [45 - 55], [58 - 80]
// A key 35, compared to be less than 50, 3rd file on level 2 can be
// skipped according to rule (1). LB = 0, RB = 1.
// A key 53, sits in the middle 50 and 60. 1st file on level 2 can be
// skipped according to rule (2)-a, but the 3rd file cannot be skipped
// because 60 is greater than 58. LB = 1, RB = 2.
// A key 70, compared to be larger than 60. 1st and 2nd file can be skipped
// according to rule (3). LB = 2, RB = 2.
对于 level1 的 [50, 60] 而言,其 smallest 为 50,largest 为 60。smallest_lb 指下一级中恰好包含比 smallest 大的 sstable,故为 1,即 [45, 55]。smallest_rb 指下一级中恰好包含比 smallest 小的 sstable,故为 1,即 [45, 55]。largest_lb 指下一级中恰好包含比 largest 大的 sstable,故为 2,即 [58, 80]。largest_rb 指下一级中恰好包含比 largest 小的 sstable,故为 2,即 [58, 80]。
在 level1 中查找 key 35,没有找到,且在 sstable 左边,因此需要跳到 level2 中的 0 ~ smallest_lb 中去找,即sstable0 和 sstable 1。key 53 没有找到,且在 sstable 内部,因此需要跳到 level2 的重合区间去找,故范围为 smallest_lb ~ largest_rb,即 sstable1 和 sstable 2。 key35 没找到,且在 sstable 右边,因此需要跳到 level2 中的 largest_lb ~ 右边界 中去找,即 sstable2 本身。
明白了这个 level 之间的关系之后,再来看 GetNextFile() 的实现。
GetNextFile
首先要明确 GetNextFile 的作用,它是一个迭代函数,每调用一次,都会返回下一个可能存在目标 key 的 sstable。用图示表明如下:
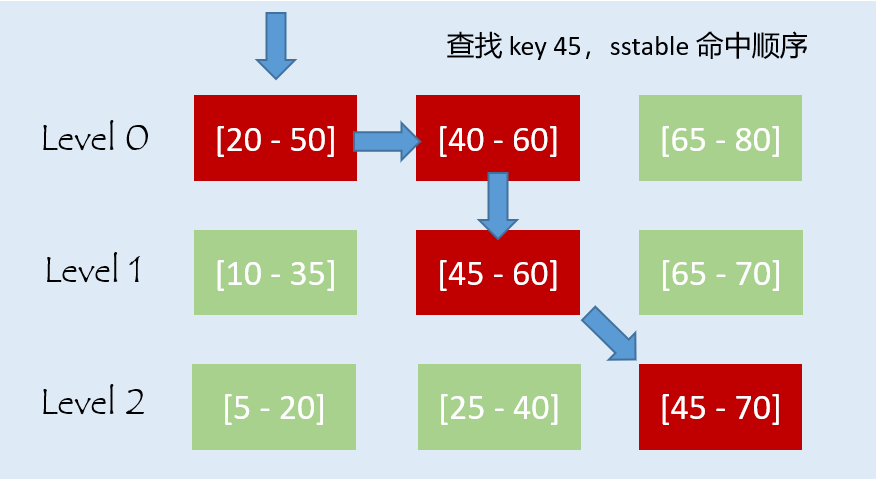
这也就是为什么,在 Version::Get() 中首先通过 GetNextFile() 来获取到一个可能 sstable,然后在其中查找,如果没找到就再调用一次 GetNextFile() 获取下一个可能 sstable,以此循环,直到找到目标 key 或全部 level 都找完。现在来看下该函数的具体实现,其完整源码如下:
FdWithKeyRange* GetNextFile() {while (!search_ended_) { // Loops over different levels.while (curr_index_in_curr_level_ < curr_file_level_->num_files) {// Loops over all files in current level.FdWithKeyRange* f = &curr_file_level_->files[curr_index_in_curr_level_];hit_file_level_ = curr_level_;is_hit_file_last_in_level_ =curr_index_in_curr_level_ == curr_file_level_->num_files - 1;int cmp_largest = -1;// Do key range filtering of files or/and fractional cascading if:// (1) not all the files are in level 0, or// (2) there are more than 3 current level files// If there are only 3 or less current level files in the system, we skip// the key range filtering. In this case, more likely, the system is// highly tuned to minimize number of tables queried by each query,// so it is unlikely that key range filtering is more efficient than// querying the files.if (num_levels_ > 1 || curr_file_level_->num_files > 3) {// Check if key is within a file's range. If search left bound and// right bound point to the same find, we are sure key falls in// range.assert(curr_level_ == 0 ||curr_index_in_curr_level_ == start_index_in_curr_level_ ||user_comparator_->CompareWithoutTimestamp(user_key_, ExtractUserKey(f->smallest_key)) <= 0);int cmp_smallest = user_comparator_->CompareWithoutTimestamp(user_key_, ExtractUserKey(f->smallest_key));if (cmp_smallest >= 0) {cmp_largest = user_comparator_->CompareWithoutTimestamp(user_key_, ExtractUserKey(f->largest_key));}// Setup file search bound for the next level based on the// comparison resultsif (curr_level_ > 0) {file_indexer_->GetNextLevelIndex(curr_level_,curr_index_in_curr_level_,cmp_smallest, cmp_largest,&search_left_bound_,&search_right_bound_);}// Key falls out of current file's rangeif (cmp_smallest < 0 || cmp_largest > 0) {if (curr_level_ == 0) {++curr_index_in_curr_level_;continue;} else {// Search next level.break;}}}returned_file_level_ = curr_level_;if (curr_level_ > 0 && cmp_largest < 0) {// No more files to search in this level.search_ended_ = !PrepareNextLevel();} else {++curr_index_in_curr_level_;}return f;}// Start searching next level.search_ended_ = !PrepareNextLevel();}// Search ended.return nullptr;
}
我们只考虑层数大于 1 的情况,这最普遍。首先,该函数通过 curr_index_in_curr_level_ 来获取当前查找到的 sstable,然后比较目标 key 和 smallest 以及 largest 的大小,结果存在 cmp_smallest 与 cmp_largest 中。因为在 level0 中有重叠,所以需要遍历完整个 level0,只有在 level1 及以上才会启用 FileIndexer 关系。先考虑 level0,跳过 curr_level_ > 0 的判断。如果目标 key 不在 sstable 内,那就 ++curr_index_in_curr_level_ ,然后 continue,此时会进入 level0 的下一个 sstable 中重复,如果在,那么依然 ++ curr_index_in_curr_level_ ,然后返回这个 sstable,在下一次调用 GetNextFile() 的时候会进入下一个 sstable 中重复。
如果在非 level0,那么就需要先通过 file_indexer_->GetNextLevelIndex() 来定位到 level+1 中的 sstable。如果目标 key 不在当前 sstable,那么直接 break,通过 PrepareNextLevel() 来进入 level+1 中,查找点就是刚刚定位的 sstable。这里有两个注意点:
- file_indexer_->GetNextLevelIndex() 就是通过 FileIndexer 来进行的。
- 非 level0 中,判断失败立刻 break,进入下一层。说明每一层只检查一个 sstable,而不是在某一个范围内遍历,这个很重要!
GetNextLevelIndex
分点来看,首先是 GetNextLevelIndex(),其完整源码如下:
void FileIndexer::GetNextLevelIndex(const size_t level, const size_t file_index,const int cmp_smallest,const int cmp_largest, int32_t* left_bound,int32_t* right_bound) const {assert(level > 0);// Last level, no hintif (level == num_levels_ - 1) {*left_bound = 0;*right_bound = -1;return;}assert(level < num_levels_ - 1);assert(static_cast<int32_t>(file_index) <= level_rb_[level]);const IndexUnit* index_units = next_level_index_[level].index_units;const auto& index = index_units[file_index];if (cmp_smallest < 0) {*left_bound = (level > 0 && file_index > 0)? index_units[file_index - 1].largest_lb: 0;*right_bound = index.smallest_rb;} else if (cmp_smallest == 0) {*left_bound = index.smallest_lb;*right_bound = index.smallest_rb;} else if (cmp_smallest > 0 && cmp_largest < 0) {*left_bound = index.smallest_lb;*right_bound = index.largest_rb;} else if (cmp_largest == 0) {*left_bound = index.largest_lb;*right_bound = index.largest_rb;} else if (cmp_largest > 0) {*left_bound = index.largest_lb;*right_bound = level_rb_[level + 1];} else {assert(false);}assert(*left_bound >= 0);assert(*left_bound <= *right_bound + 1);assert(*right_bound <= level_rb_[level + 1]);
}
逻辑很简单,就是结合比较结果与 FileIndexer 中的四个字段,计算出 search_left_bound_ 与 search_right_bound_,即下一层的查找范围。
PrepareNextLevel
这样一来,第二个注意点就出问题了。search_left_bound_ 和 search_right_bound_ 明明代表的是一个范围,比如前文示例中 key 35 的下一层查找范围为 [0, 1],但为什么在 GetNextFile() 每一层只查找一个 sstable 呢?这个问题困扰了我大概一天,甚至怀疑过是不是源码写错了。
// Key falls out of current file's range
if (cmp_smallest < 0 || cmp_largest > 0) {if (curr_level_ == 0) {++curr_index_in_curr_level_;continue;} else {// Search next level.break;}
}
实际上,RocksDB 对下一个 level 中 sstable 的定位,就是直接定到其中一个。只不过它分了两步。第一步通过 FileIndexer 来确定 search_left_bound_ 和 search_right_bound_ ,第二步就是在这个范围内具体定到某一个 sstable 中。而第二步的实现,就是在 PrepareNextLevel() 中,我们看一下它的源码:
bool PrepareNextLevel() {curr_level_++;while (curr_level_ < num_levels_) {curr_file_level_ = &(*level_files_brief_)[curr_level_];if (curr_file_level_->num_files == 0) {// When current level is empty, the search bound generated from upper// level must be [0, -1] or [0, FileIndexer::kLevelMaxIndex] if it is// also empty.assert(search_left_bound_ == 0);assert(search_right_bound_ == -1 ||search_right_bound_ == FileIndexer::kLevelMaxIndex);// Since current level is empty, it will need to search all files in// the next levelsearch_left_bound_ = 0;search_right_bound_ = FileIndexer::kLevelMaxIndex;curr_level_++;continue;}// Some files may overlap each other. We find// all files that overlap user_key and process them in order from// newest to oldest. In the context of merge-operator, this can occur at// any level. Otherwise, it only occurs at Level-0 (since Put/Deletes// are always compacted into a single entry).int32_t start_index;if (curr_level_ == 0) {// On Level-0, we read through all files to check for overlap.start_index = 0;} else {// On Level-n (n>=1), files are sorted. Binary search to find the// earliest file whose largest key >= ikey. Search left bound and// right bound are used to narrow the range.if (search_left_bound_ <= search_right_bound_) {if (search_right_bound_ == FileIndexer::kLevelMaxIndex) {search_right_bound_ =static_cast<int32_t>(curr_file_level_->num_files) - 1;}// `search_right_bound_` is an inclusive upper-bound, but since it was// determined based on user key, it is still possible the lookup key// falls to the right of `search_right_bound_`'s corresponding file.// So, pass a limit one higher, which allows us to detect this case.start_index =FindFileInRange(*internal_comparator_, *curr_file_level_, ikey_,static_cast<uint32_t>(search_left_bound_),static_cast<uint32_t>(search_right_bound_) + 1);if (start_index == search_right_bound_ + 1) {// `ikey_` comes after `search_right_bound_`. The lookup key does// not exist on this level, so let's skip this level and do a full// binary search on the next level.search_left_bound_ = 0;search_right_bound_ = FileIndexer::kLevelMaxIndex;curr_level_++;continue;}} else {// search_left_bound > search_right_bound, key does not exist in// this level. Since no comparison is done in this level, it will// need to search all files in the next level.search_left_bound_ = 0;search_right_bound_ = FileIndexer::kLevelMaxIndex;curr_level_++;continue;}}start_index_in_curr_level_ = start_index;curr_index_in_curr_level_ = start_index;return true;}// curr_level_ = num_levels_. So, no more levels to search.return false;
}
该函数作用很明确,首先是 curr_level_ ++,指进入了下一层,其次就是通过 search_left_bound_ 和 search_right_bound_ 来确定 start_index,这个 start_index 就是下一层中定位的 sstable 下标。官方对其的解释如下:
On Level-n (n>=1), files are sorted. Binary search to find the earliest file whose largest key >= ikey. Search left bound and right bound are used to narrow the range.
意思是,startIndex 就是最早的满足 largest >= 目标 key 的 sstable 下标,其由如下代码块确定:
start_index =FindFileInRange(*internal_comparator_, *curr_file_level_, ikey_,static_cast<uint32_t>(search_left_bound_),static_cast<uint32_t>(search_right_bound_) + 1);
进入该函数看一看,源码如下:
// Find File in LevelFilesBrief data structure
// Within an index range defined by left and right
int FindFileInRange(const InternalKeyComparator& icmp,const LevelFilesBrief& file_level,const Slice& key,uint32_t left,uint32_t right) {auto cmp = [&](const FdWithKeyRange& f, const Slice& k) -> bool {return icmp.InternalKeyComparator::Compare(f.largest_key, k) < 0;};const auto &b = file_level.files;return static_cast<int>(std::lower_bound(b + left,b + right, key, cmp) - b);
}
这就很明确了,该函数其实就是个 lower_bound,核心是比较器。可以看出,比较器会将 sstable 中的 largest 与目标 key 来进行比较,小于在返回 true。故该函数就是返回最早的满足 largest >= 目标 key 的 sstable 下标。仍然拿官方的列子来看:
// Example:
// level 1: [50 - 60]
// level 2: [1 - 40], [45 - 55], [58 - 80]
level1 查找完 key 35 时,level2 对应范围为 [0,1],但显然 35 只可能落在 [1 - 40] 中,因为它是最早的满足 largeset >= 35 的 sstable,所以 start_index 为 0,[45 - 55] 就没必要去搜索了 。level1 查找完 key 53 时,level2 对应范围为 [1,2],但显然 53 只可能落在 [45 - 55] 中,理由同上,故 stat_index 为 1。
至此就是解释了第二个注意点的问题了,因为 PrepareNextLevel() 会直接定位到 level+1 中一个具体的 sstable 上,而不是一个范围,所以每一层只检查一个 sstable 就行。
TableCache
当 FilePicker 找到一个 sstable 后,RocksDB 会调用 TableCache::Get() 来在这个 sstable 中查找,并把一些信息保存在 get_context 中·
*status = table_cache_->Get(read_options, *internal_comparator(), *f->file_metadata, ikey,&get_context, mutable_cf_options_.prefix_extractor,cfd_->internal_stats()->GetFileReadHist(fp.GetHitFileLevel()),IsFilterSkipped(static_cast<int>(fp.GetHitFileLevel()),fp.IsHitFileLastInLevel()),fp.GetHitFileLevel(), max_file_size_for_l0_meta_pin_);
当返回后,通过 get_context 来判断返回的结果是否符合预期。
switch (get_context.State()) {case GetContext::kNotFound:// Keep searching in other filesbreak;case GetContext::kMerge:// TODO: update per-level perfcontext user_key_return_count for kMergebreak;case GetContext::kFound:// ... 主要在这return;case GetContext::kDeleted:*status = Status::NotFound();return;case GetContext::kCorrupt:*status = Status::Corruption("corrupted key for ", user_key);return;case GetContext::kUnexpectedBlobIndex:ROCKS_LOG_ERROR(info_log_, "Encounter unexpected blob index.");*status = Status::NotSupported("Encounter unexpected blob index. Please open DB with ""ROCKSDB_NAMESPACE::blob_db::BlobDB instead.");return;case GetContext::kUnexpectedWideColumnEntity:*status =Status::NotSupported("Encountered unexpected wide-column entity");return;}
如果不符合预期,那么会重新调用 GetNextLevelIndex() 重复上述过程。
f = fp.GetNextFile();
接下来,我们进入最核心的 TableCache::Get(),该函数的主要工作为两点:
- cache 相关的信息,分为两个 cache:
- row_cache,用来 cache <key, vlaue>
- table_cache,用来 cache <key,sstable>
- 从 sstable 中查找目标 key。
我们源码中主要的部分,如下:
Status TableCache::Get(const ReadOptions& options,const InternalKeyComparator& internal_comparator,const FileMetaData& file_meta, const Slice& k, GetContext* get_context,const std::shared_ptr<const SliceTransform>& prefix_extractor,HistogramImpl* file_read_hist, bool skip_filters, int level,size_t max_file_size_for_l0_meta_pin) { // ...// Check row cache if enabled. Since row cache does not currently store// sequence numbers, we cannot use it if we need to fetch the sequence.if (ioptions_.row_cache && !get_context->NeedToReadSequence()) {auto user_key = ExtractUserKey(k);CreateRowCacheKeyPrefix(options, fd, k, get_context, row_cache_key);done = GetFromRowCache(user_key, row_cache_key, row_cache_key.Size(),get_context);if (!done) {row_cache_entry = &row_cache_entry_buffer;}}// ...Status s;TableReader* t = fd.table_reader;Cache::Handle* handle = nullptr;if (!done) {if (t == nullptr) {s = FindTable(options, file_options_, internal_comparator, file_meta,&handle, prefix_extractor,options.read_tier == kBlockCacheTier /* no_io */,true /* record_read_stats */, file_read_hist, skip_filters,level, true /* prefetch_index_and_filter_in_cache */,max_file_size_for_l0_meta_pin, file_meta.temperature);if (s.ok()) {t = GetTableReaderFromHandle(handle);}}// ...if (s.ok()) {get_context->SetReplayLog(row_cache_entry); // nullptr if no cache.s = t->Get(options, k, get_context, prefix_extractor.get(), skip_filters);get_context->SetReplayLog(nullptr);}// ...}// Put the replay log in row cache only if something was found.if (!done && s.ok() && row_cache_entry && !row_cache_entry->empty()) {size_t charge = row_cache_entry->capacity() + sizeof(std::string);void* row_ptr = new std::string(std::move(*row_cache_entry));// If row cache is full, it's OK to continue.ioptions_.row_cache->Insert(row_cache_key.GetUserKey(), row_ptr, charge,&DeleteEntry<std::string>).PermitUncheckedError();}// ...
}
首先,它会判断 row_cache 是否打开,如果打开,则会在 row_cache 中进行一次查找,并把查找结果记录在 get_context 中。在进入 row_cache 前,会先将 key 包装成 row_cache 中形式的 key。通过下面的代码我们可以看到 row_cache 的 key 就是 fd_number+seq_no+user_key。
void TableCache::CreateRowCacheKeyPrefix(const ReadOptions& options,const FileDescriptor& fd,const Slice& internal_key,GetContext* get_context,IterKey& row_cache_key) {// ...// Compute row cache key.row_cache_key.TrimAppend(row_cache_key.Size(), row_cache_id_.data(),row_cache_id_.size());AppendVarint64(&row_cache_key, fd_number);AppendVarint64(&row_cache_key, seq_no);
}bool TableCache::GetFromRowCache(const Slice& user_key, IterKey& row_cache_key,size_t prefix_size, GetContext* get_context) {// ...row_cache_key.TrimAppend(prefix_size, user_key.data(), user_key.size());// ...
}
GetFromRowCache() 的具体实现我们先不分析。如果在 row_cache 中找到,那么 done 就是 true,后面的查找就全部跳过。如果没有找到,那么就会进入 sstable 中查找。
TableReader* t = fd.table_reader;
// ...
if (s.ok()) {get_context->SetReplayLog(row_cache_entry); // nullptr if no cache.s = t->Get(options, k, get_context, prefix_extractor.get(), skip_filters);get_context->SetReplayLog(nullptr);
}
在分析函数之前,我们先分析一下 sstable 的结构,一个 sstable 对应一个 FileMetaData,类的主要成员如下:
struct FileMetaData {FileDescriptor fd;InternalKey smallest; // Smallest internal key served by tableInternalKey largest; // Largest internal key served by table// ...
}
其中,smallest 和 largest 就是 sstable 的两个边界 key。主要来看一下成员 fd:
// A copyable structure contains information needed to read data from an SST
// file. It can contain a pointer to a table reader opened for the file, or
// file number and size, which can be used to create a new table reader for it.
// The behavior is undefined when a copied of the structure is used when the
// file is not in any live version any more.
struct FileDescriptor {// Table reader in table_reader_handleTableReader* table_reader;uint64_t packed_number_and_path_id;uint64_t file_size; // File size in bytesSequenceNumber smallest_seqno; // The smallest seqno in this fileSequenceNumber largest_seqno; // The largest seqno in this file// ...
}
如注释所述,该结构记录了 sstable 的信息,比如大小、seq 范围等等。但最重要的就是 TableReader,它才是 sstable 的核心数据结构,所有的读取均在其中进行。官方解释如下:
A Table (also referred to as SST) is a sorted map from strings to strings. Tables are immutable and persistent. A Table may be safely accessed from multiple threads without external synchronization. Table readers are used for reading various types of table formats supported by rocksdb including BlockBasedTable, PlainTable and CuckooTable format.
也即,TableReader 实际上是一个抽象类,RocksDB 有多个不同的 sstable 实现,每一个 TableReader 的派生类都是一种实现,包括 BlockBasedTable、CuckooTable、MockTable、PlainTable 这四种。
![]()
RocksDB 默认采用的数据结构为 BlockBasedTable,这也是大部分资料都在讨论的基于 block 的 sstable,那我们就只关注它,其余实现都不看。
// Create default block based table factory.
extern TableFactory* NewBlockBasedTableFactory(const BlockBasedTableOptions& table_options = BlockBasedTableOptions());
这个结构的实现这里就不讨论了。针对该结构我曾做过一篇简要博客:sstable 简要分析,不过那一篇没有进入源码层面,后面我会另出一篇对 sstable 源码进行详细分析:sstable实现—BlockBasedTable (待填坑
在 row_cahce 中读取失败后,会拿到 sstable 的 TableReader,如果为空,那么就会在 table_cache 中找。
TableReader* t = fd.table_reader;
if (t == nullptr)s = FindTable(options, file_options_, internal_comparator, file_meta,&handle, prefix_extractor,options.read_tier == kBlockCacheTier /* no_io */,true /* record_read_stats */, file_read_hist, skip_filters,level, true /* prefetch_index_and_filter_in_cache */,max_file_size_for_l0_meta_pin, file_meta.temperature);
TableCache::FindTable 的主要源码如下:
Status TableCache::FindTable(const ReadOptions& ro, const FileOptions& file_options,const InternalKeyComparator& internal_comparator,const FileMetaData& file_meta, Cache::Handle** handle,const std::shared_ptr<const SliceTransform>& prefix_extractor,const bool no_io, bool record_read_stats, HistogramImpl* file_read_hist,bool skip_filters, int level, bool prefetch_index_and_filter_in_cache,size_t max_file_size_for_l0_meta_pin, Temperature file_temperature) {// ...std::unique_ptr<TableReader> table_reader;Status s =GetTableReader(ro, file_options, internal_comparator, file_meta,false /* sequential mode */, record_read_stats,file_read_hist, &table_reader, prefix_extractor,skip_filters, level, prefetch_index_and_filter_in_cache,max_file_size_for_l0_meta_pin, file_temperature);if (!s.ok()) {assert(table_reader == nullptr);RecordTick(ioptions_.stats, NO_FILE_ERRORS);// We do not cache error results so that if the error is transient,// or somebody repairs the file, we recover automatically.} else {s = cache_->Insert(key, table_reader.get(), 1, &DeleteEntry<TableReader>,handle);if (s.ok()) {// Release ownership of table reader.table_reader.release();}}return s;
}
逻辑很简单,就是一般的 cache 逻辑,读取然后判断是否存在,不存在则创建一个插入 cache。上面的函数会调用 TableCache::GetTableReader(),我们来简单看下这个函数:
Status TableCache::GetTableReader(const ReadOptions& ro, const FileOptions& file_options,const InternalKeyComparator& internal_comparator,const FileMetaData& file_meta, bool sequential_mode, bool record_read_stats,HistogramImpl* file_read_hist, std::unique_ptr<TableReader>* table_reader,const std::shared_ptr<const SliceTransform>& prefix_extractor,bool skip_filters, int level, bool prefetch_index_and_filter_in_cache,size_t max_file_size_for_l0_meta_pin, Temperature file_temperature) {// ...s = ioptions_.table_factory->NewTableReader(ro,TableReaderOptions(ioptions_, prefix_extractor, file_options,internal_comparator, skip_filters, immortal_tables_,false /* force_direct_prefetch */, level,block_cache_tracer_, max_file_size_for_l0_meta_pin,db_session_id_, file_meta.fd.GetNumber(),expected_unique_id, file_meta.fd.largest_seqno),std::move(file_reader), file_meta.fd.GetFileSize(), table_reader,prefetch_index_and_filter_in_cache);
}
即,通过相关的参数创建了一个 TableReader。该函数的具体实现先不深入分析,重新回到 TableCache::Get() 中。当获取到 TableReader 中后,RocksDB 就要在其中查找目标 key 了。
if (s.ok()) {get_context->SetReplayLog(row_cache_entry); // nullptr if no cache.s = t->Get(options, k, get_context, prefix_extractor.get(), skip_filters);get_context->SetReplayLog(nullptr);} else if (options.read_tier == kBlockCacheTier && s.IsIncomplete()) {// Couldn't find Table in cache but treat as kFound if no_io setget_context->MarkKeyMayExist();s = Status::OK();done = true;}
查找的入口就是 TableReader::Get(),其也是一个抽象,不同的 sstable 数据结构对其的实现方式均不一样。
![]()
当然,默认的就是 BlockBasedTable::Get(),这里我们就不深入了,放在对 sstable 单独分析的那篇博客中讲:sstable实现—BlockBasedTable (待填坑
当从 sstable 中找到后,将会把 <key, value> 缓存进 row_cache 中。
if (!done && s.ok() && row_cache_entry && !row_cache_entry->empty()) {size_t charge = row_cache_entry->capacity() + sizeof(std::string);void* row_ptr = new std::string(std::move(*row_cache_entry));// If row cache is full, it's OK to continue.ioptions_.row_cache->Insert(row_cache_key.GetUserKey(), row_ptr, charge,&DeleteEntry<std::string>).PermitUncheckedError();}
至此,从 sstable 中的读流程分析完毕,意味着 RocksDB 的整个读流程分析完毕。虽然忽略了一些重要实现,但它们会在后续对数据结构的专讲中详细说明。
RocksDB源码学习-四-读-三相关推荐
- Java 源码学习系列(三)——Integer
Integer 类在对象中包装了一个基本类型 int 的值.Integer 类型的对象包含一个 int 类型的字段. 此外,该类提供了多个方法,能在 int 类型和 String 类型之间互相转换,还 ...
- Vue源码学习 - 组件化(三) 合并配置
Vue源码学习 - 组件化(三) 合并配置 合并配置 外部调用场景 组件场景 总结 学习内容和文章内容来自 黄轶老师 黄轶老师的慕课网视频教程地址:<Vue.js2.0 源码揭秘>. 黄轶 ...
- Dubbo源码学习总结系列三 dubbo-cluster集群模块
Dubbo集群模块的目的是将集群Invokers构造一个透明的Invoker对象,其中包含了容错机制.负载均衡.目录服务(服务地址集合).路由机制等,为RPC层提供高可用.高并发.自动发现.可治理的S ...
- 【Qt】通过QtCreator源码学习Qt(三):linux平台的信号、程序崩溃处理
崩溃处理设置:CrashHandlerSetup 1.原理 在堆中为信号处理函数分配一块区域,作为该函数的栈使用,当系统默认的栈空间用尽时,调用信号处理函数使用的栈是在堆中分配的空间,而不是系统默认的 ...
- dubbo源码学习(四):暴露服务的过程
dubbo采用的nio异步的通信,通信协议默认为 netty,当然也可以选择 mina,grizzy.在服务端(provider)在启动时主要是开启netty监听,在zookeeper上注册服务节点, ...
- 通过jQuery源码学习javascript(三)
序 承接上两篇继续写下去.我尽量把我明白的地方给大家说清楚.有些大家的提问我也有点搞不明白,如果有人能解答,再好不过了. 疑问 第一篇中有位博友提出了以下的问题,我也不太明白,如果有明白的,能否告知一 ...
- 菜鸟的jQuery源码学习笔记(三)
1 each: function(callback, args) { 2 return jQuery.each(this, callback, args); 3 }, each:这个调用了jQuery ...
- JDK源码学习笔记——Integer
一.类定义 public final class Integer extends Number implements Comparable<Integer> 二.属性 private fi ...
- mutations vuex 调用_Vuex源码学习(六)action和mutation如何被调用的(前置准备篇)...
前言 Vuex源码系列不知不觉已经到了第六篇.前置的五篇分别如下: 长篇连载:Vuex源码学习(一)功能梳理 长篇连载:Vuex源码学习(二)脉络梳理 作为一个Web前端,你知道Vuex的instal ...
- 读文章笔记(三):从源码学习Transformer
读文章笔记(三):从源码学习Transformer encoder分为两部分: decoder 公众号机器学习算法工程师 文章链接: https://mp.weixin.qq.com/s/0NajB_ ...
最新文章
- iframe中的奇怪现象
- linux查看是否有用户在使用分区,在Linux服务器中有几种查看分区表的方法
- MS CRM 2011 Form与Web Resource在JScript中的相互调用
- 测试连接oracle数据库耗时
- js怎么调用wasm_对于WebAssembly编译出来的.wasm文件js如何调用
- 信息学奥赛C++语言: 扫雷游戏
- 华为Mate 20 X 5G版打通5G电话:音质饱满画面清晰
- 2021.01.04
- CAS3.5.x(x1)支持OAuth2 server
- IV 估计:工具变量不外生时也可以用!
- cad卸载_CAD卸载后为什么安装不了?解决方法原来是这样!
- 算法的陷阱:超级平台、算法垄断与场景欺骗
- cad安装计算机丢失无法启动不了,Win10无法打开CAD2006提示“计算机中丢失ac1st16.dll”怎么办...
- 2020TB618喵币挂机自动获取脚本(jsapp)
- 【View基础知识】TouchSlop、VelocityTracker、GestureDetector、Scroller
- 学C++就学服务端,先把apue和unp两卷看了,接着libevent,出来找工作应该没问题
- 什么使格瓦拉风行至今
- 第二讲:项目运行环境 事业环境因素 (EEF) 和组织过程资产 (OPA)
- Cypress-should()常见断言
- iOS 使用Zebra打印机打印标签