python 简单网页_Python爬虫 (一):爬取一个简单的静态网页
版本:python3.7
平台:windows10
工具 :pycharm
断断续续学习了py3爬虫2周左右的时间,发现自己学习的过于零散化,所以想通过这个专栏系统的整理下自己所学过的知识。如有错误,欢迎指出。
在学习爬虫的时候,静态网页是最适合入门练手的项目。这是一个练习的网页:http://www.pythonscraping.com/pages/page3.html
学习python最好的方式就是查看官方文档https://docs.python.org/3/library
urllib.request是一个库, 隶属urllib。
我们再点击urllib.request就会发现这条语句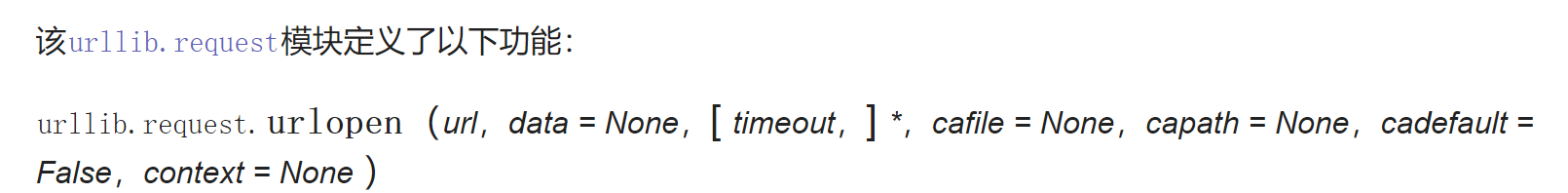
urlopen 用来打开并读取一个从网络获取的远程对象。返回一个 http.client.HTTPResponse 对象, 这个对象又有各种方法, 比如我们用到的read()方法返回的网页内容实际上是没有被解码或的。在read()得到内容后通过指定decode()函数参数,可以使用对应的解码方式。
代码如下
from urllib.request import urlopen
if __name__ == "__main__":
url = ("http://www.pythonscraping.com/pages/page3.html")
html = urlopen(url).read().decode()
print(html)
执行完毕后我们就可以通过审查元素(F12)发现html代码已经被我们打印出来了。但是我们想要的是其中我们感兴趣的数据该怎么办?比如之想要其中的列表部分的内容。
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,主要的功能是从网页抓取数据,相对于正则表达式来说,更简便。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
Beautiful Soup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html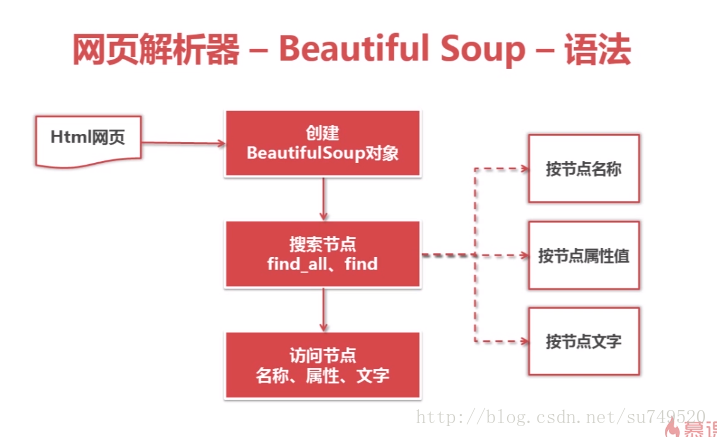
findAll ()返回的是所有符合结果的列表,find()返回的是符合的第一个值。
代码如下:
if __name__ == "__main__":
url = ("http://www.pythonscraping.com/pages/page3.html")
html = urlopen(url)
soup = BeautifulSoup(html,'lxml')
gifts = soup.findAll('tr',{'class':'gift'})
for gift in gifts:
print(gift.get_text())
.get_text()函数是将标签去掉,只返回内容。
soup = BeautifulSoup(html,'lxml')默认的解析器是html.parse,这里使用的是另外一个解析器lxml解析器
经测试需要gifts = soup.findAll('tr',{'class':'gift'})这样以字典的形式给attrs参数赋值才可以。
这篇文章就到此结束了,虽然看着很简单,但是这才刚刚入门。有句话送给所有喜欢学习的人:仰之弥高,钻之弥坚,努力,共勉。
ps:题外话,第一次写专栏,B站专栏的连接只可以用站内连接吗.......???
python 简单网页_Python爬虫 (一):爬取一个简单的静态网页相关推荐
- python访问多个网页_Python 爬虫 2 爬取多页网页
本文内容: Requests.get 爬取多个页码的网页 例:爬取极客学院课程列表 爬虫步骤 打开目标网页,先查看网页源代码 get网页源码 找到想要的内容,找到规律,用正则表达式匹配,存储结果 Re ...
- python接收弹幕_Python爬虫自动化爬取b站实时弹幕实例方法
最近央视新闻记者王冰冰以清除可爱和专业的新闻业务水平深受众多网友喜爱,b站也有很多up主剪辑了关于王冰冰的视频.我们都是知道b站是一个弹幕网站,那你知道如何爬取b站实时弹幕吗?本文以王冰冰视频弹幕为例 ...
- python音乐相册_python爬虫之爬取网易云音乐的歌曲图片和歌词
0.目录 1.分析页面 2.获取歌曲的id 3.获取歌曲信息 4.获取歌曲图片url 5.获取歌词 6.总结 7.完整代码 1.分析页面 这一次我们来爬取网易云音乐,爬取歌单内的所有歌曲的图片和歌词, ...
- python医药数据_python爬虫:爬取医药数据库drugbank
import os import time import datetime import codecs from lxml import etree from selenium import webd ...
- python爬取多页_Python 爬虫 2 爬取多页网页
本文内容: Requests.get 爬取多个页码的网页 例:爬取极客学院课程列表 爬虫步骤 打开目标网页,先查看网页源代码 get网页源码 找到想要的内容,找到规律,用正则表达式匹配,存储结果 Re ...
- python批量访问网页保存结果_Python爬虫(批量爬取某网站图片)
1.需要用到的库有: Requests re os time 如果没有安装的请自己安装一下,pycharm中打开终端输入命令就可以安装 2.IDE : pycharm 3.python 版本: 3.8 ...
- python爬虫贴吧_Python爬虫如何爬取贴吧内容
爬取贴吧内容 先了解贴吧url组成: 每个贴吧url都是以'https://tieba.baidu.com/f?'开头,然后是关键字 kw=''贴吧名字'',再后面是 &pn=页数 (pn=0 ...
- python爬虫爬取豆瓣电影信息城市_python爬虫,爬取豆瓣电影信息
hhhhh开心,搞了一整天,查了不少python基础资料,终于完成了第一个最简单的爬虫:爬取了豆瓣top250电影的名字.评分.评分人数以及短评. 代码实现如下:#第一个最简单的爬虫 #爬取了豆瓣to ...
- python爬虫知乎图片_python爬虫(爬取知乎答案图片)
python爬虫(爬取知乎答案图片) 1.⾸先,你要在电脑⾥安装 python 的环境 我会提供2.7和3.6两个版本的代码,但是本⽂只以python3.6版本为例. 安装完成后,打开你电脑的终端(T ...
- python爬取豆瓣小组_Python 爬虫实例+爬取豆瓣小组 + wordcloud 制作词云图
目标 利用PYTHON爬取如下图中所有回答的内容,并且制作词云图. 用到的库 import requests # import json from PIL import Image from pyqu ...
最新文章
- HashMap 与 HashTable的区别
- 8.2.1.3 Range 优化
- windows 搭建kms服务器激活_自建KMS激活服务器的两种方法
- html静态页面到jsp文件css错误
- java poi excel 生成表格的工具封装
- 三分钟掌握Go mod常用与高级操作
- UI设计干货素材|滑动动效设计模板
- AWS 与 Elastic 矛盾再升级!
- Android App应用包增量升级(one)
- pandas合并数据集-【老鱼学pandas】
- cmd命令行开启windows远程桌面服务
- 开机需要手动启动无线
- 新一代报表工具FastReport VCL 6.9发布!
- openwrt下如何生成ipk包到对应的开发板上运行 以helloword为例(三)
- MOSFET手册解读MOS管参数解读(转)
- 第一个微信小程序的诞生
- 梧桐计划发布!百度智能云携手合作伙伴共创“云智一体”繁荣新生态
- 设置透明主题引起动画失效以及打开其他应用闪现桌面图标的问题
- 《程序员必读之软件架构》作者Simon Brown:架构师与程序员的区别
- python应用之Word生成