文本分类入门(六)训练Part 3
SVM算法支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中[10]。
支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力[14](或称泛化能力)。
SVM 方法有很坚实的理论基础,SVM 训练的本质是解决一个二次规划问题(Quadruple Programming,指目标函数为二次函数,约束条件为线性约束的最优化问题),得到的是全局最优解,这使它有着其他统计学习技术难以比拟的优越性。 SVM 分类器的文本分类效果很好,是最好的分类器之一。同时使用核函数将原始的样本空间向高维空间进行变换,能够解决原始样本线性不可分的问题。其缺点是核函数的选择缺乏指导,难以针对具体问题选择最佳的核函数;另外SVM 训练速度极大地受到训练集规模的影响,计算开销比较大,针对SVM 的训练速度问题,研究者提出了很多改进方法,包括Chunking 方法、Osuna 算法、SMO 算法和交互SVM 等等[14]。
SVM分类器的优点在于通用性较好,且分类精度高、分类速度快、分类速度与训练样本个数无关,在查准和查全率方面都优于kNN及朴素贝叶斯方法[8]。
与其它算法相比,SVM算法的理论基础较为复杂,但应用前景很广,我打算专门写一个系列的文章,详细的讨论SVM算法,stay tuned!
介绍过了几个很具代表性的算法之后,不妨用国内外的几组实验数据来比较一下他们的优劣。
在中文语料上的试验,文献[6]使用了复旦大学自然语言处理实验室提供的基准语料对当前的基于词向量空间文本模型的几种分类算法进行了测试,这一基准语料分为20个类别,共有9804篇训练文档,以及9833篇测试文档。在经过统一的分词处理、噪声词消除等预处理之后,各个分类方法的性能指标如下。
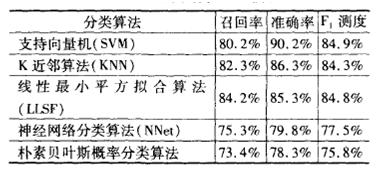
其中F1 测度是一种综合了查准率与召回率的指标,只有当两个值均比较大的时候,对应的F1测度才比较大,因此是比单一的查准或召回率更加具有代表性的指标。
由比较结果不难看出,SVM和kNN明显优于朴素贝叶斯方法(但他们也都优于Rocchio方法,这种方法已经很少再参加评测了)。
在英文语料上,路透社的Reuters-21578 “ModApt´e”是比较常用的测试集,在这个测试集上的测试由很多人做过,Sebastiani在文献[23]中做了总结,相关算法的结果摘录如下:
|
分类算法 |
在Reuters-21578 “ModApt´e”上的F1测度 |
|
Rocchio |
0.776 |
|
朴素贝叶斯 |
0.795 |
|
kNN |
0.823 |
|
SVM |
0.864 |
仅以F1测度来看,kNN是相当接近SVM算法的,但F1只反映了分类效果(即分类分得准不准),而没有考虑性能(即分类分得快不快)。综合而论,SVM是效果和性能均不错的算法。
前面也提到过,训练阶段的最终产物就是分类器,分类阶段仅仅是使用这些分类器对新来的文档分类而已,没有过多可说的东西。
下一章节是对到目前为止出现过的概念的列表及简单的解释,也会引入一些后面会用到的概念。再之后会谈及分类问题本身的分类(绕口),中英文分类问题的相似与不同之处以及几种特征提取算法的概述和比较,路漫漫……
参考:
http://wiki.52nlp.cn/
http://www.blogjava.net/zhenandaci/category/31868.html
[1]李晓明,闫宏飞,王继民,“搜索引擎——原理、技术与系统”.科学出版社,2004
[2]冯是聪, "中文网页自动分类技术研究及其在搜索引擎中的应用," 北京大学,博士论文, 2003
[3]Y. Yang and X. Liu, "A re-examination of text categorization methods" presented at Proceedings of ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR'99), 1999.
[4]F. Sebastiani, "A tutorial on Automated Text Categorization", Proceedings of ASAI-99, 1st Argentinian Symposium on Artificial Intelligence, Buenos Aires, AR, 1999
[5]王涛:文本自动分类研究,图书馆学研究,2007.12
[6]周文霞:现代文本分类技术研究,武警学院学报,2007.12
[7]奉国和:自动文本分类技术研究,情报杂志,2007.12
[8]崔彩霞,张朝霞:文本分类方法对比研究,太原师范学院学报(自然科学版),2007.12
[9]吴军:Google黑板报数学之美系列,http://googlechinablog.com
[10]刘霞,卢苇:SVM在文本分类中的应用研究,计算机教育,2007.1
[11]都云琪,肖诗斌:基于支持向量机的中文文本自动分类研究,计算机工程,2002,28(11)
[12]周昭涛,卜东波:文本的图表示初探,中文信息学报,第19卷 第2期
[13]Baeza-Yates,R.and Ribeiro-Neto:Modern Information Retrieval,1st ed.Addison Wesley Longman,Reading,MA,1999
[14]唐春生,张磊:文本分类研究进展
[15]李莼,罗振声:基于语义相关和概念相关的自动分类方法研究,计算机工程与应用,2003.12
[16]单松巍,冯是聪,李晓明:几种典型特征选取方法在中文网页分类上的效果比较,计算机工程与应用,2003.22
[17]Yiming Yang,Jan O Pedersen:A comparative Study on Feature Selection in Text Categorization, Proceedings of the Fourteenth International Conference on Machine Learning(ICML~97),l997
[18]董振东:知网简介,知网,http://www.keenage.com/zhiwang/c_zhiwang.html
[19]Tom M.Mitchell,”Machine Learning”,McGraw Hill Companies,1997
[20] Edda Leopold, Jorg Kindermann,“Text Categorization with Support Vector Machines:How to Represent Texts in Input Space?”, Kluwer Academic Publishers,2002
[21] Thorsten Joachims,”Text Categorization with Support Vector Machines: Learning with Many Relevant Features”
[22]Nello Cristianini,An Introduction to Support Vector Machines and Other Kernel-based Learning Methods,Cambridge University Press,2000
[23]F. Sebastiani, "MACHINE LEARNING IN AUTOMATED TEXT CATEGORIZATION", ACM Computing Surveys, Vol. 34, No. 1, 2002
[24]TRS公司,TRS文本挖掘基础件白皮书
[25]苏金树,张博锋:基于机器学习的文本分类技术研究进展,Journal of Software,2006.9
文本分类入门(六)训练Part 3相关推荐
- 文本分类入门(四)训练Part 1
文本分类入门(四)训练Part 1 训练,顾名思义,就是training(汗,这解释),简单的说就是让计算机从给定的一堆文档中自己学习分类的规则(如果学不对的话,还要,打屁屁?). 开始训练之前,再多 ...
- 文本分类入门(五)训练Part 2
将样本数据成功转化为向量表示之后,计算机才算开始真正意义上的"学习"过程. 再重复一次,所谓样本,也叫训练数据,是由人工进行分类处理过的文档集合,计算机认为这些数据的分类是绝对正确 ...
- 文本分类入门(一)文本分类问题的定义
原博客地址:http://www.blogjava.net/zhenandaci/category/31868.html?Show=All 文本分类入门(一)文本分类问题的定义 文本分类系列文章,从文 ...
- NLP文本分类入门学习及TextCnn实践笔记——模型训练(三)
这篇记模型训练. 距离第一篇已过去一个月.从学习到正式启动模型训练,花了两周.模型训练召回率和准确率达到上线标准又花了两三周. 训练及测试样本评估的精确率都是97%.98%,结果一到线上实验,结果惨不 ...
- 文本分类入门(三)统计学习方法
文本分类入门(三)统计学习方法 前文说到使用统计学习方法进行文本分类就是让计算机自己来观察由人提供的训练文档集,自己总结出用于判别文档类别的规则和依据.理想的结果当然是让计算机在理解文章内容的基础上进 ...
- 文本分类入门(二)文本分类的方法
文本分类入门(二)文本分类的方法 文本分类问题与其它分类问题没有本质上的区别,其方法可以归结为根据待分类数据的某些特征来进行匹配,当然完全的匹配是不太可能的,因此必须(根据某种评价标准)选择最优的匹配 ...
- 文本分类入门(七)相关概念总结
学习方法:使用样例(或称样本,训练集)来合成计算机程序的过程称为学习方法[22]. 监督学习:学习过程中使用的样例是由输入/输出对给出时,称为监督学习[22].最典型的监督学习例子就是文本分类问题, ...
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
文本分类入门(番外篇)特征选择与特征权重计算的区别 在文本分类的过程中,特征(也可以简单的理解为"词")从人类能够理解的形式转换为计算机能够理解的形式时,实际上经过了两步骤的量化- ...
- (已修改)机器学习之文本分类(附带训练集+数据集+所有代码)
本博客是我对之前博客进行的一些优化,对文件的处理,以及添加更多的注释让大家在NLP,文本分类等领域能够更快的让代码跑起来. 原文链接:https://blog.csdn.net/qq_28626909 ...
最新文章
- Varnish purges 缓存清除
- div地址跳转 vue_vue---导航栏点击跳转到对应位置
- Unable to instantiate default tuplizer [org.hibernate.tuple.entity.PojoEntityTuplizer]
- 第一篇:数据仓库概述
- 微软社区精英计划 - 你会如何回答【6月26日】北京.Net学习活动QA时提出的问题...
- 【点云分割】区域生长(用鼠标选中一个点长出一个)
- ChannelSplitterNode
- Canvas渲染会取代DOM吗?
- Python爬虫实战:应用宝APP数据信息采集
- python groupby agg_Python数据分析:探索性分析
- HTML DOM 的nodeType属性
- 设计模式(十): 代理模式
- Python实现最近邻nearest、双线性bilinear、双三次bicubic插值
- 2020年执业药师考试,5个锦囊助你做好最后冲刺!
- 混乱是阶梯:Web2与Web3的融合,也是COSO的窗口期
- 学生管理系统--【Java+MySQL】--数据库系统概论综合性实验
- 如何计算CAN通信波特率
- DPI、PPI、DP、PX 的详细计算方法及算法来源是什么
- 最新pr值大于6的网站大全
- DICOM:fo-dicom之C-STORE再分析‘解决System.ObjectDisposedException异常’