深度学习——数据预处理篇
深度学习——数据预处理篇
文章目录
- 深度学习——数据预处理篇
- 一、前言
- 二、常用的数据预处理方法
- 零均值化(中心化)
- 数据归一化(normalization)
- 主成分分析(PCA、Principal Component Analysis)
- 白化(whitening)
- 三、注意事项
- 四、References
一、前言
深度学习和机器学习一个重要的区别就是在于数据量的大小。就目前的大量实验
和工作证明,数据量的大小能够直接影响深度学习的性能,我们都希望能够利用
小的数据集,简单的算法就能够取得不错的效果,但目前的事实是小数据集上使
用深度学习,往往效果没那么理想,所以老师也常常说,深度学习的三驾马车:
网络、损失、数据,由此可见数据对深度学习的重要性。
数据预处理在众多深度学习算法中都起着重要作用。首先数据的采集就非常的费时费力,因为这些数据需要考虑各种因素,然后有时还需对数据进行繁琐的标注。当这些都有了后,就相当于我们有了原始的raw数据,然后就可以进行下面的数据预处理部分了。
二、常用的数据预处理方法
在这之前我们假设数据表示成矩阵为X,其中我们假定X是N×D维矩阵,N是样本数据量,D为单张图片的数据向量长度。假设要处理的图像是5×5的彩色图像,那么D即5×5×3=75(因为彩色图像有RGB三个通道),假设N=1000,那么X就是1000×75的矩阵,即1000行图像的信息,每一行代表一个图像的信息。
零均值化(中心化)
在深度学习中,一般我们会把喂给网络模型的训练图片进行预处理,使用最多的方法就是零均值化(zero-mean) / 中心化,简单说来,它做的事情就是,对待训练的每一张图片的特征,都减去全部训练集图片的特征均值,这么做的直观意义就是,我们把输入数据各个维度的数据都中心化到0了。几何上的展现是可以将数据的中心移到坐标原点。如下图中zero-centered data(当然,其实这里也有不同的做法:我们可以直接求出所有像素的均值,然后每个像素点都减掉这个相同的值;稍微优化一下,我们可以在RGB三个颜色通道分别做这件事)
零均值化的代码为:
X -= np.mean(X, axis = 0)# axis=0,计算每一列的均值,压缩行# 举个例子,假设训练图片有5000张,图片大小为32*32,通道数为3,则用python表示如下: x_train = load_data(img_dir) # 读取图片数据 x_train的shape为(5000,32,32,3) x_train = np.reshape(x_train, (x_train.shape[0], -1)) # 将图片从二维展开为一维,x_train 变为(5000,3072) mean_image = np.mean(x_train, axis=0) # 求出所有图片每个像素位置上的平均值 mean_image为(1, 3072) x_train -= mean_image # 减去均值图像,实现零均值化# 即让所有训练图片中每个位置的像素均值为0,使得像素值范围变为[-128,127],以0为中心。
例如在吴恩达的作业中就有说到,机器学习中一个常见的预处理步骤是对数据集进行集中和标准化,这意味着从每个示例中减去整个numpy数组的平均值,然后将每个示例除以整个numpy数组的标准差。但是对于图片数据集来说,将数据集的每一行除以255(像素通道的最大值)会更简单、更方便,而且几乎同样有效。
数据归一化(normalization)
归一化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。举个容易理解的例子,在房价预测那题中,假设房价是由面积s和卧室数b决定,面积s在0200之间,卧室数b在05之间,则进行归一化就是s=s/200,b=b/5. 就是把这两个数据"归到1内",所以叫归一化。
通常我们有两种方法来实现归一化:
一个是在数据都去均值之后,每个维度上的数据都除以这个维度上数据的标准差,即
X /= np.std(X, axis = 0)另外一种方式是我们除以数据绝对值的最大值,以保证所有的数据归一化后都在-1到1之间。如上述的房价例子。
如图normalized data即为归一化
主成分分析(PCA、Principal Component Analysis)
这是一种使用广泛的数据降维算法,是一种无监督学习方法,主要是用来将特征的主要分成找出,并去掉基本无关的成分,从而达到降维的目的。
总结一下PCA的算法步骤:
设有n条m维数据。将原始数据按列组成m行n列矩阵X
将X的每一行(代表一个属性字段)进行零均值化
求出协方差矩阵
C=1mXXTC=\frac{1}{m}XX^{T} C=m1XXT求出协方差矩阵的特征值及对应的特征向量
将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
Y=P×X即为降维到k维后的数据
代码如下:
# 假定输入数据矩阵X是[N*D]维的 X -= np.mean(X, axis = 0) # 去均值 cov = np.dot(X.T, X) / X.shape[0] # 计算协方差 U,S,V = np.linalg.svd(cov) Xrot = np.dot(X, U) # decorrelate the data Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced becomes [N x 100]PCA处理结果如图中的decorrelated data:
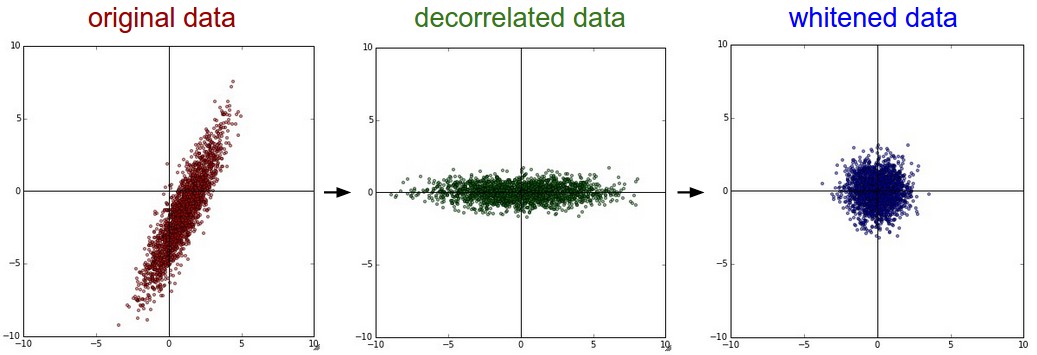
白化(whitening)
就是把各个特征轴上的数据除以对应特征值,从而达到在每个特征轴上都归一化幅度的结果。也就是在PCA的基础上再除以每一个特征的标准差,以使其normalization,其标准差就是奇异值的平方根:
# whiten the data: # divide by the eigenvalues (which are square roots of the singular values) Xwhite = Xrot / np.sqrt(S + 1e-5)但是白化因为将数据都处理到同一个范围内了,所以如果原始数据有原本影响不大的噪声,它原本小幅的噪声也会放大到与全局相同的范围内了。
另外我们为了防止出现除以0的情况在分母处多加了0.00001,如果增大他会使噪声减小。
白化之后得到是一个多元高斯分布,如下图whitened所示:可以看出经过PCA的去相关操作,将原始数据的坐标旋转,并且可以看出x方向的信息量比较大,如果只选一个特征,那么就选横轴方向的特征,经过白化之后数据进入了相同的范围。
三、注意事项
以上只是总结数据预处理的方法而已,并不是说每次都会用这么多方法,相反,在图像数据处理或者CNN中,一般只需要进行去均值和归一化,不需要PCA和白化
代码如下:
X -= np.mean(X, axis = 0) # 减去均值,使得以0为中心
X /= np.std(X, axis = 0) # 归一化
![]()
常见陷阱:在进行数据的预处理时(比如计算数据均值),我们只能在训练数据上进行,然后应用到验证/测试数据上。如果我们对整个数据集-整个数据集的均值,然后再进行训练/验证/测试数据的分割的话,这样是不对的。正确做法是计算训练数据的均值,然后分别把它从训练/验证/测试数据中减去。
四、References
- https://blog.csdn.net/bea_tree/article/details/51519844#commentBox
- https://blog.csdn.net/han_xiaoyang/article/details/50451460#commentBox
- http://ufldl.stanford.edu/wiki/index.php/数据预处理#PCA.2FZCA.E7.99.BD.E5.8C.96
深度学习——数据预处理篇相关推荐
- 比较全的深度学习数据预处理方法
当前深度学习的预处理方法 1.中心化/零均值化 程序代码 2.标准化/归一化 程序代码 (1)标准化与归一化的联系和差异 联系 差异 (2)为什么要归一化/标准化 ①某些模型求解需要 ②一些分类器需要 ...
- 深度学习-----数据预处理
转自:https://blog.csdn.net/dcxhun3/article/details/47999281 通过最近一段深度学习的学习与实现,发现数据预处理在深度学习中是非常重要的. 数据归一 ...
- 系列文章(一):机器学习与深度学习——数据预处理(数值型数据)
系列文章(一):机器学习与深度学习中的数据预处理(数值型数据) 目录 系列文章(一):机器学习与深度学习中的数据预处理(数值型数据) 一.引言 1.1 为何预处理(Why preprocessing? ...
- 深度学习数据预处理——批标准化(Batch Normalization)
数据预处理最常见的方法就是中心化和标准化,中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征.标准化也非常简单,在数据变成 0 均值之后,为 ...
- Keras学习---数据预处理篇
1. 数据预处理是必要的,这里以最简单的MNIST dataset的输入数据预处理为例. A. 设置随机种子 np.random.seed(1337) # for reproducibi ...
- 深度学习数据预处理方法及示例
文章目录 一.中心化/零均值化 二.归一化 三.PCA和白化 数据预处理在构建网络模型时是非常重要的,往往能够决定训练结果.当然对于不同的数据集,预处理的方法都会有或多或少的特殊性和局限性.在这里介绍 ...
- 深度学习数据更换背景_开始学习数据科学的最佳方法是了解其背景
深度学习数据更换背景 数据科学教育 (DATA SCIENCE EDUCATION) 目录 (Table of Contents) The Importance of Context Knowledg ...
- 计算机视觉面试宝典--深度学习机器学习基础篇(四)
计算机视觉面试宝典–深度学习机器学习基础篇(四) 本篇主要包含SVM支持向量机.K-Means均值以及机器学习相关常考内容等相关面试经验. SVM-支持向量机 支持向量机(support vector ...
- 机器视觉面试宝典--深度学习补缺补漏篇
机器视觉面试宝典–深度学习补缺补漏篇 一.深入理解Batch Normalization批标准化 机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通 ...
最新文章
- Mysql下载以及安装(新手入门,超详细)
- 搭建自己的Docker Harbor
- npm eject 暴露webpack报错,less或sass添加报错
- 解决SQLite异常:library routine called out of sequence
- WSL之Emacs中文乱码解决
- 再谈KMP/BM算法(II)
- Electron下使用samba相关问题记录
- Python对象转json【包括嵌套对象转json,django的model转json】
- 淘宝网站的设计与排版
- 玩转电脑|电脑回收站还能这么玩,自定义图标让你的回收站与众不同
- AR与VR的区别在哪?
- java开灯问题_算法入门之开灯问题
- Go语言国际电子表格文档格式标准实践
- Win11系统怎么关闭hyper-v虚拟机?
- 数据库技术之MVCC
- ScriptManager脚本管理器
- STM32F0系列出现overrun interrupt 和PB6 PB7映射的解决办法
- CCCC 天梯赛 PTA ZOJ 题目 L1 L2 L3
- 主机屋免费服务器 – 真的开启服务器免费时代?
- Linux运维~2.DNS——8.ddns 动态域名解析 花生壳
热门文章
- The method setButton(int, CharSequence, Message) in the type AlertDialog is not applicable for the a
- 当统计信息不准确时,CBO可能产生错误的执行计划,并在10053 trace中找到CBO出错的位置示例...
- 在进行商业运算时解决BigDecimal的精度丢失问题
- 宏使用 Tricks
- C++ 笔记(19)— 标准模板库(STL容器、STL迭代器、STL算法、STL容器特点、STL字符串类)
- Codeforces Round 367 Div. 2
- 将ADS1.2的工程迁移到KEIL上-基于2440
- Java学习笔记---字符类型
- Standup Timer的MVC模式及项目结构分析
- php发光字体代码,CSS3怎么实现字体发光效果