python编程问题--第二次
![]()
本质上grp 是一个dataframe 后面接一个[] 得到 series 两个[] 得到dataframe
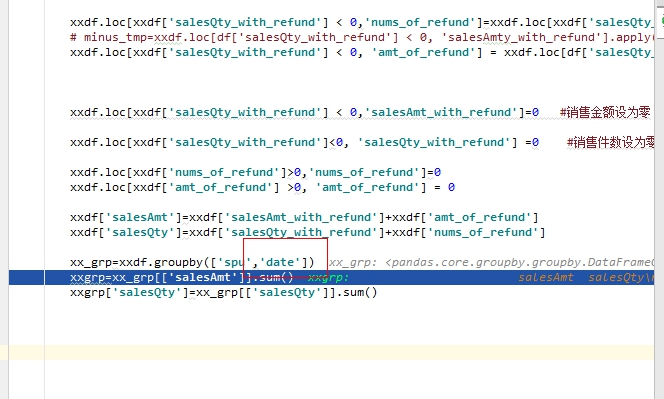
Groupby 如果后面放as_index=False
后面就能连续添加了
不加的话 同事后名 用[[]]可以连续添加字段,索引字段就通过 get 添加了
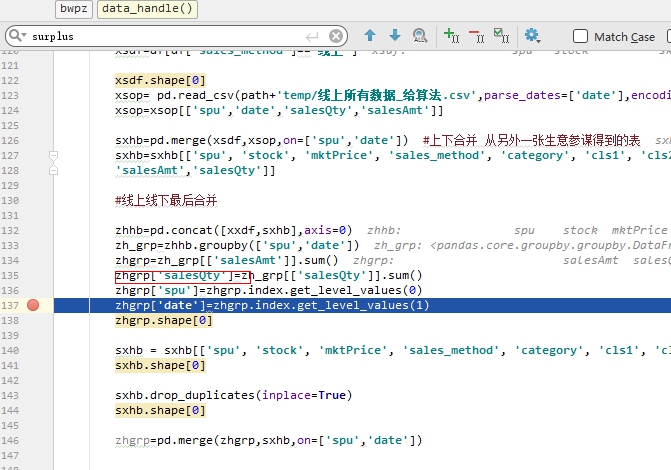
这个也换成 zhgrp 表的时候 上面同名的表会变成灰色
编程后的如何验证:
1. 看数据条数前后是否有缺失
Dataframe的列不能作为单独的 不能以整列的布尔值来判断是否正确 要以最终的结果 求和值来判断是为真还是为假
(ret['samount'] == 0) |(ret['sqty']==0)==True)
这样不行
spu_zero=sum((ret['samount'] == 0) |(ret['sqty']==0)==True))
后面这样才行
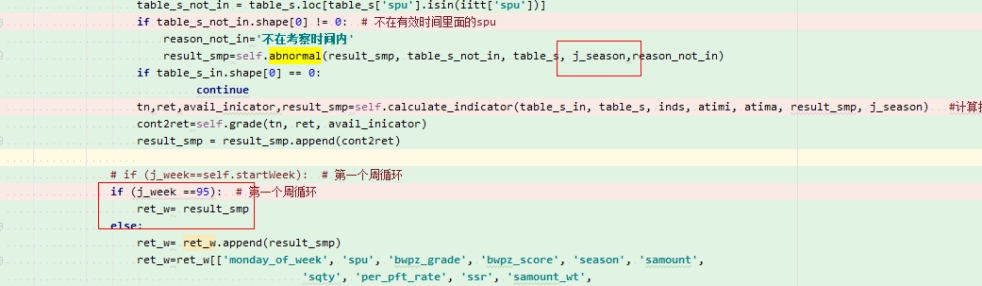
两个嵌套循环 都可以用同一个条件来增加初始化表 但是两个表的表名不一样
If j_week==startWeek
编程经验:
重复使用的代码和一个较多行的功能模块做作为一个函数
在循环外初始表,每次增加的值都会放到里面 最后再追加的话 肯定就重复了 追加每次只能追加增量
TypeError: 'module' object is not callable
改成 from datetime import * 即可以解决
编程经验
要在原有模型上改,尽量遵从原有模型的结果,即是要保留一些无用的东西
问题?
当引入包有问题的
用conda --upgrade all 更新所有的依赖
编程经验笔记
去掉无关紧要的东西 以免影响
编程经验
通过选定 可以令屏幕输出停止
编程经验
只有在所有情况都处理完之后 才可以用 continue
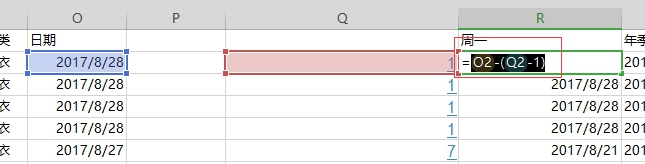
Excel 求周一
WEEKDAY(O2,2)
编程经验:
多分模块, 各个击破 不要浪费太多时间在找代码上
经验:
不同的IDE 不能同时运行同一个编译器
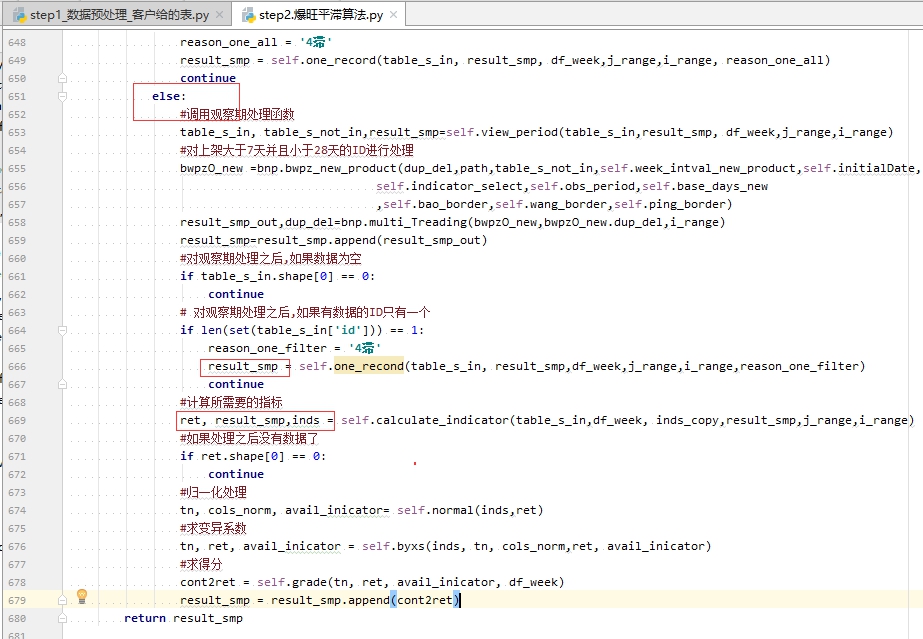
假设第三行超过了else 的作用域(向左突出了),那是不能传递到接下来外层的
编程经验
a=[1,2,4,7,9]
for i in a:
if i==1:
print(1)
elif i==2:
c=[6,6]
# else:
# d=[1,6]
print(c) #在没有else的时候,是可以传到最外层的
print(d)
a=[1,2,4,7,9]
for i in a:
if i==1:
print(1)
elif i==2:
c=[6,6]
else:
d=[1,6]
print(c) #else 是无法传到最外层的,所以else要慎用,如果一直要传递的话,最好用elif
print(d)
def test():
a=[1,2,4,7,9]
for i in a:
if i==1:
print(1)
elif i==2:
t=0
for j in [1,1,1]:
t+=j
return t #在 if和elif 下
print(test())
def test():
a=[1,2,4,7,9]
for i in a:
if i==1:
print(1)
elif i==2:
t=0
for j in [1,1,1]:
t+=j
return t #在 if和elif 下,return 对齐 elif 就能输出东西,提示变量不存在 应该是执行 if==1的时候出现问题的
print(test())
def test():
a=[1,2,4,7,9]
for i in a:
if i==1:
print(1)
elif i==2:
t=0
for j in [1,1,1]:
t+=j
return t #在 if和elif 下,return 对齐 elif还是不对齐,都没有什么关系 return的位置很关键 对齐elif 居然输出不了东西
print(test())
# if 和 elif 一起使用时候的,只挑选其中一条语句来运行,其他的不执行
# if,if,if 组合的时候,每条都要执行
def test():
a = [1, 2, 4, 7, 9]
for i in a:
if i == 1:
d=[1,1]
if i == 2:
c=[6,6]
print(d)
print(test()) #if 可以传到最外层的,除了else 不行之外 if和elif 都可以,运行一次会输出5次d
因为第一次产生的d一直保留了下来
# if,else return
def test(i):
if i == 1:
d=[1,1]
else:
d=[6,6]
print(d)
print(test(2)) #else 会传递到外层 没有错的
退出
Sys.exit(0) 退出 最外层还是会执行
Os._exit(0) 退出整个模块,注意参数零
问题:
注意 if,elif,else for return 函数 模块 等作用域的问题
问题:
长数字的处理
Python 安装时的帮助
直接输入命令名字 即可知道 命令的帮助
Pip 更新包 pip install pandas --upgrade
pip在多个python版本中将包安装到制定版本
$ pip install -t /usr/local/lib/python3.5/site-package/ beautifulsoup4
利用pip install -t 制定到具体位置
编程经验:
如果写完类之后,无法从另一个模块导入 那么就是重启IDE 就可以了
编程经验:
在当前模块引入包,至少要等于超过当前模块所在路径的父路径
编程问题:
怎么样把内部模块里面 for 循环里面的每一次 结果都输出到外层 要单独每次输出 而不是一次汇总输出
编程经验:
对应for 循环里面要对表做各种处理的时候,
再次循环的时候一定要初始化 导入词表最原始的情况
# # 编辑经验
# #快速获取某个库的帮助
# 在编译器里把其写出来,然后进入其类内部 通过IDE的structure 来查看包含的方法
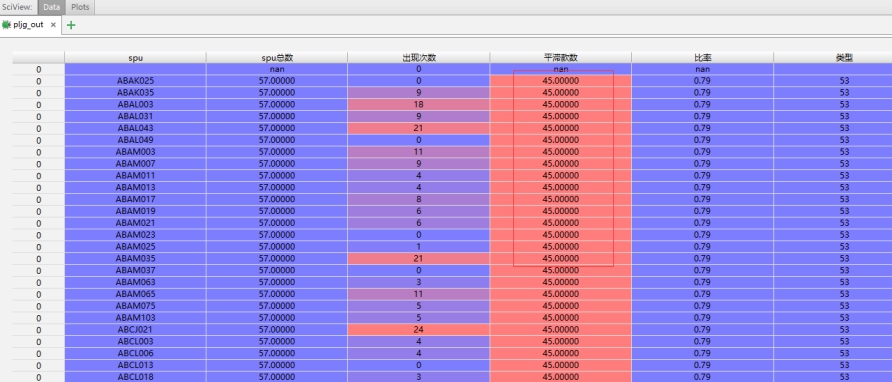
后面很多零的问题 通过转换为字符串之后就没有了
Weekofyear 周所在的年的问题
国睿林静艳:
isocalendar():返回(ISO year, ISO week number, ISO weekday)元组。
国睿林静艳:
datetime.date(2017, 1, 1).isocalendar()
Out[41]: (2016, 52, 7)
TypeError: cannot concatenate object of type "<class 'str'>"; only pd.Series, pd.DataFrame, and pd.Panel (deprecated) objs are valid
Concat 可能是中间某行或者某列值的格式 有问题
当concat 合并之后 的结果 可以在控制台打印处理 但是无法 在调速器里面显示出来的时候就是
两个表有相同的列名啊 啊 啊啊啊 啊啊
取列
Df.loc【‘A’】 这样是不对的
应该是 df【‘A’】
ImportError: Something is wrong with the numpy installation. While importing we detected an older version of numpy in
Import error
导入错误 很可能不只是numpy 太老 还有其他一些关联的包需要更新
用pip 不行 需要用 conda 才能全部更新
在 import pandas as pd 这一行出现问题 是由于 pandas 太老的原因
AttributeError: module 'numpy' has no attribute '__version__'
Pip 安装指定版本的包库 双等号
pip install robotframework==2.8.7
Python matplotlib 利用这个命令画图
plt.show()
ValueError: view limit minimum 0.0 is less than 1 and is an invalid Matplotlib date value. This often happens if you pass a non-datetime value to an axis that has datetime units
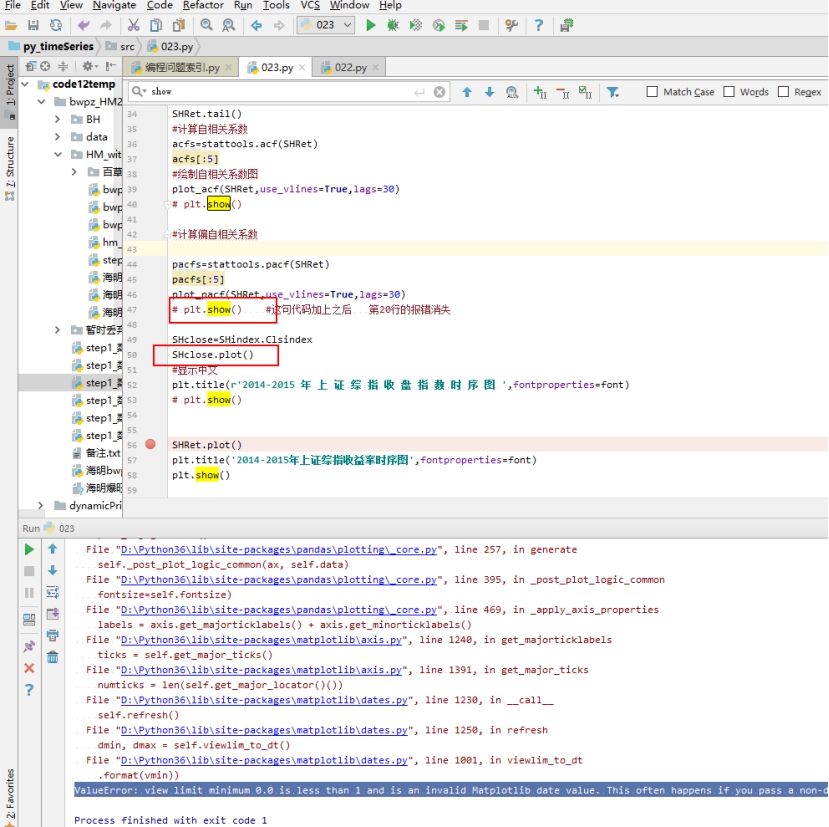
需要前面的plt.show() 开起来
前面的plot 不能传递到后面
python3错误处理“sre_constants.error: nothing to repeat”
正则表达式的问题
Series 只有一个值的时候,需要用索引把其取出来 a【0】
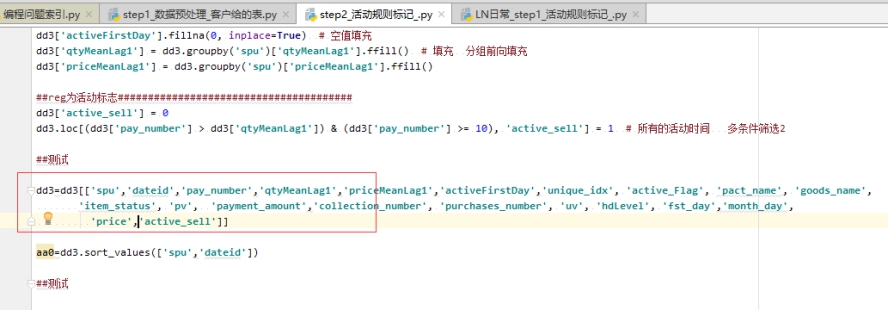
当筛选字段的时候,如果里面有字段重复的话 会返回空值
http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.map.html
Pandas series 的map
>>> s.map({'cat': 'kitten', 'dog': 'puppy'})0 kitten1 puppy2 NaN3 NaNdtype: object
It also accepts a function:
>>> s.map('I am a {}'.format)0 I am a cat1 I am a dog2 I am a nan3 I am a rabbitdtype: object
To avoid applying the function to missing values (and keep them as NaN) na_action='ignore' can be used:
>>> s.map('I am a {}'.format, na_action='ignore')0 I am a cat1 I am a dog2 NaN3 I am a rabbitdtype: object
问题 dataframe 所有值 变成一个list


问题 如何把一列追加到另一列

如何快速的,把所有列变成一列 同时标上属于自己的列名

这样实现
问题
Dataframe 增加一行数据
numpy.linalg.LinAlgError: Last 2 dimensions of the array must be square
A不是方阵会出错:numpy.linalg.linalg.LinAlgError: Last 2 dimensions of the array must be square
单位根检验,这个单位根检验不会因为不是方阵而无法计算的问题
import statsmodels.tsa.stattools as ts
for spu_test in spu_list:
print(spu_test)
spu_select=SHRet.loc[SHRet['spu']==spu_test]
# adf_ret=ADF(spu_select.qtyMean,method='AIC')
adf_ret=ts.adfuller(spu_select.qtyMean)
包导入
当想导入上级目录下的另一个包的时候 却导入了另一路径的同名包的时候
把另一路径从项目里面去掉
建模经验
去年同期会不会有使用未来数据的问题 当在训练的时候
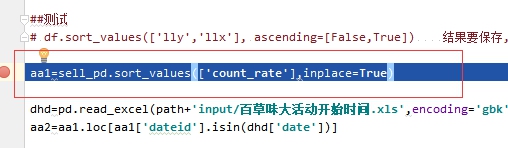
用了inplace 就不能再赋值了
实例化对象的时候 一定要在名字后面加圆括号
A=class1()
If else 里面的部分不能和if语句平行 否则下面不执行
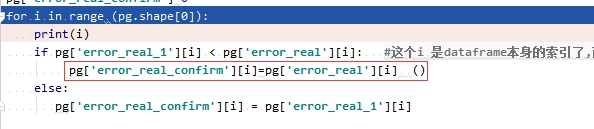
上下两个pg 不能对齐
问题 这两个的区别
type(pg['error_real_confirm'][i])
type(pg['error_real_confirm'].iloc[i])
问题
Jupyter 设置字体
https://blog.csdn.net/qq_30565883/article/details/79444750
python 更换国内安装源
2018年07月30日 10:00:45 sofo2017 阅读数:1207
常见国内镜像源
http://pypi.douban.com/simple/ 豆瓣
http://mirrors.aliyun.com/pypi/simple/ 阿里
http://pypi.hustunique.com/simple/ 华中理工大学
http://pypi.sdutlinux.org/simple/ 山东理工大学
http://pypi.mirrors.ustc.edu.cn/simple/ 中国科学技术大学
指定单次安装源
pip install <包名> -i http://pypi.douban.com/simple
指定全局安装源
在unix和macos,配置文件为:$HOME/.pip/pip.conf
在windows上,配置文件为:%APPDATA%\pip\pip.ini
echo %APPDATA% 得到 %APPDATA% 的path为 appdata\roaming,但是在appdata\roaming下没有pip文件夹,怎么办?自己在appdata\roaming建一个pip文件夹,在pip文件夹里再建一个pip.ini文件,建好文件之后,在文件里写入
[global]
index-url = http://pypi.douban.com/simple
[install]
trusted-host=pypi.douban.com
pip安装文件的时候使用pip install <包名> –trusted-host pypi.douban.com
比如 pip install pyquery –trusted-host pypi.douban.com
问题
前后填充的时候用【】对列进行填充 【【】】是产生dataframe 不能对列进行填充
base_data['price']=base_data.groupby(['spu'])['price'].ffill()
编程经验
尽量把代码放到一屏里面
当用一个表的值放到另一个表里的时候,如果二者的索引不相等是不行的
只有把右边的变成标量 不含索引才行
huafen['train_end']=ddtrain[['index']].tail(1).iloc[0,0]
问题 索引如果不连续 dd[] 通过方括号直接选取就不行
Xtrain = dd1_std[train_start:train_end, :-1] #
Iloc 适用于索引绝对的顺序
问题
huafen=huafen.iloc[i_time:i_time+1,:] i_time 是区间出来的是dataframe 否则是series
经验
后面要重复用到的变量 最好是重命名 和前面的区分开 避免覆盖
经验
当有很多次 groupby 要拼接的时候,紧盯 groupby 的字段 这样才不会头晕
import pandas as pd
df=pd.DataFrame({'a':[i for i in range(10)],'b':[i for i in range(10,20)]})
a1=df[df['a']<3]
a2=df.loc[df['a']<3]
当这里面是是否的时候 前面用不用loc 效果都是一样的?
取不到索引2 但长度是2

-1 就是最后一个
引入包的时候提示不存在 说明包需要更新了
https://www.runoob.com/python/att-time-strftime.html
时间格式化
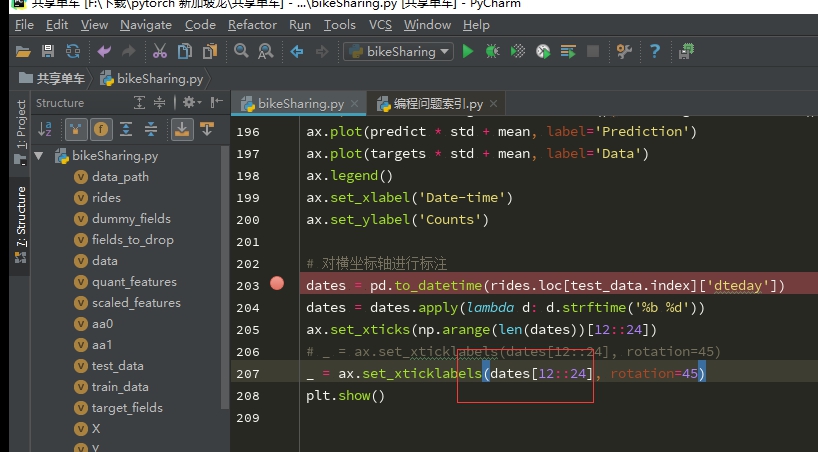
Pandas 同时取多个索引
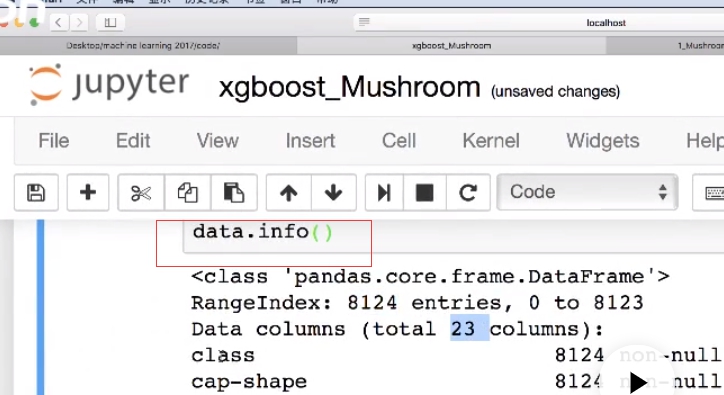
Df.info
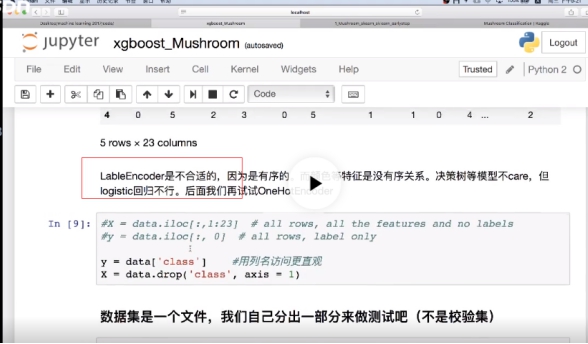
Lableencoder编码
https://www.cnblogs.com/fei-hsueh/p/3973280.html
assert函数(python)
assert语句:
用以检查某一条件是否为True,若该条件为False则会给出一个AssertionError。
用法:
assert type(x)=int and x>=0
如果不满足后面的expression,则会弹出
Traceback (most recent call last):
File "<pyshell#7>", line 1, in <module>
assert type(n)==int and n>0
AssertionError
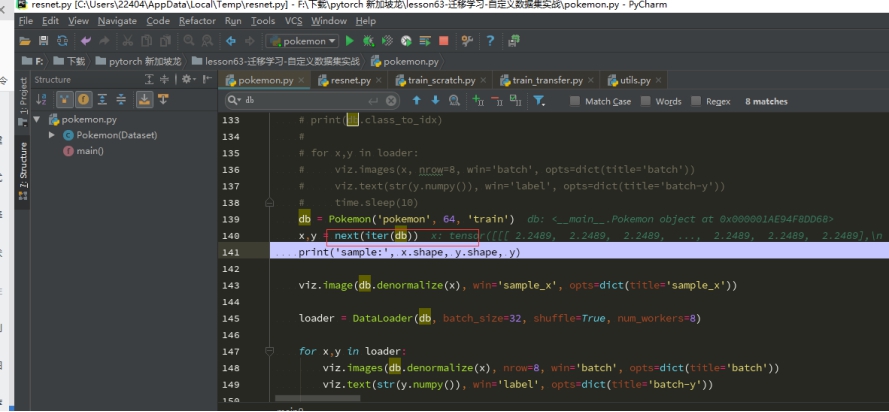
python中的next()以及iter()函数
https://blog.csdn.net/li1615882553/article/details/79360172
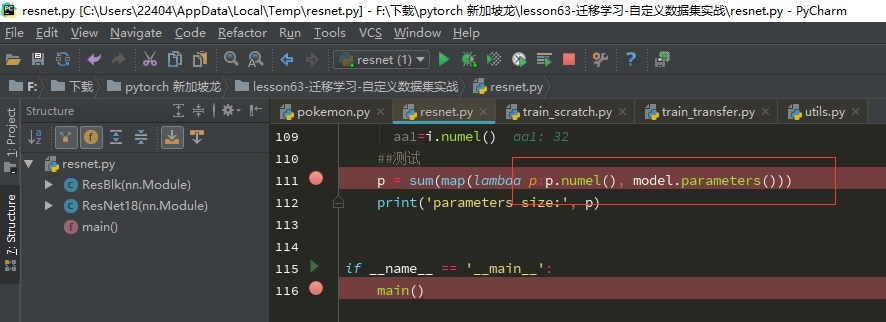
P.Numel()求p里面元素的个数
Map(lambda p:p.numel(),x) p取出x里面的每一个元素 然后每个元素再作用numel()方法
经验 看代码顺序
主函数 都有哪些函数 在详细看每个函数
Jupyter 安装和开始
Pip install jupyter 安装
http://(wsy or 127.0.0.1):8000/?token=92f80a0d915083ffee6d782bf06bc1995098be722b8afca6
Token为密码
通过 直接在cmd里面敲入 jupyter notebook 就可以直接打开jupyter

路径的斜杠写法 而不是反斜杠
添加工程
问题在 执行选中代码的时候出现整个问题
ValueError: list.remove(x): x not in list
Excute line in console
AttributeError: module 'builtins' has no attribute 'interpreter'
这种情况很有可能是pycharm 版本错误
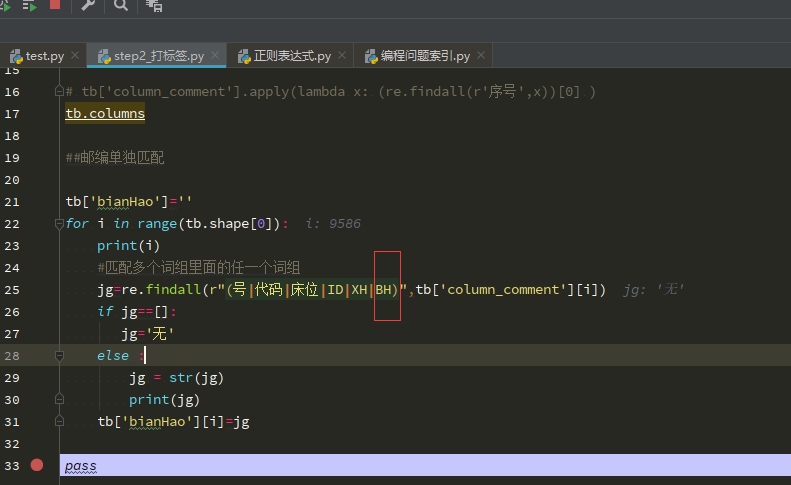
如果末尾加上竖线 最终结果 会出现很多空字符
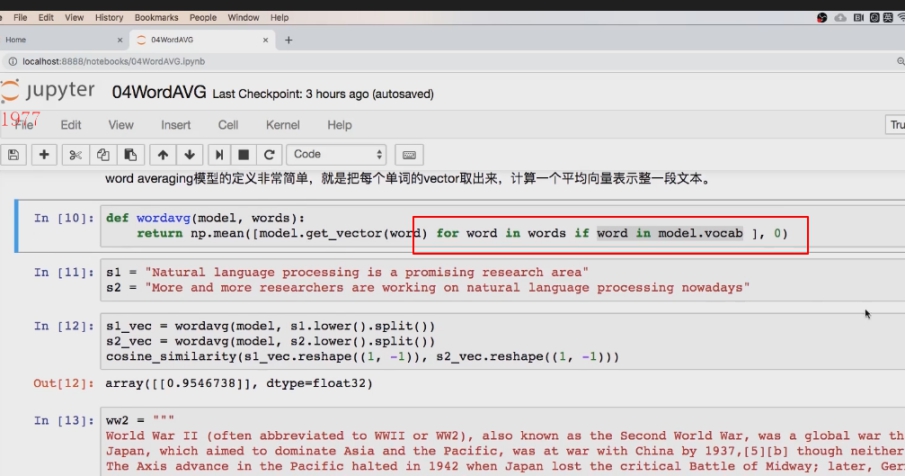
列表生成式和for if 等套用
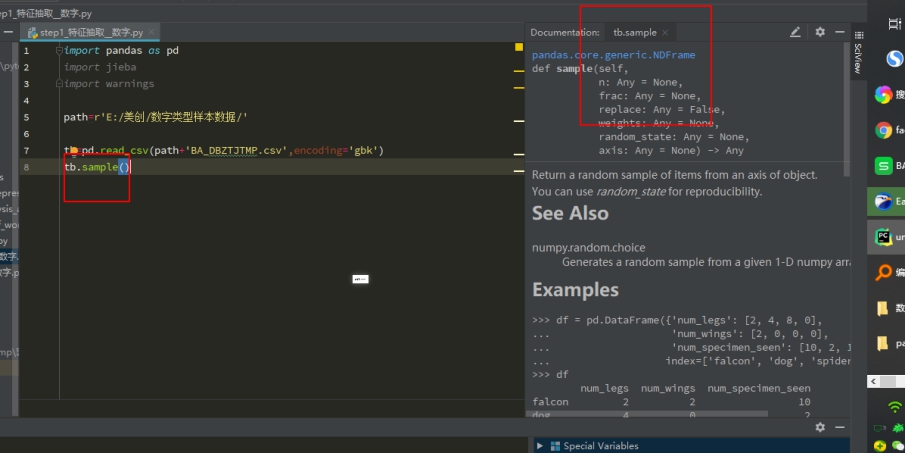
Pycharm 文档注释 ctrl+ 两次q
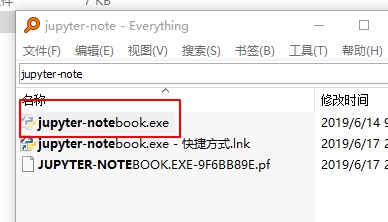
直接打开jupyter
简历jupyter 快捷方式
Is 用 true 和 False
== 用于其他
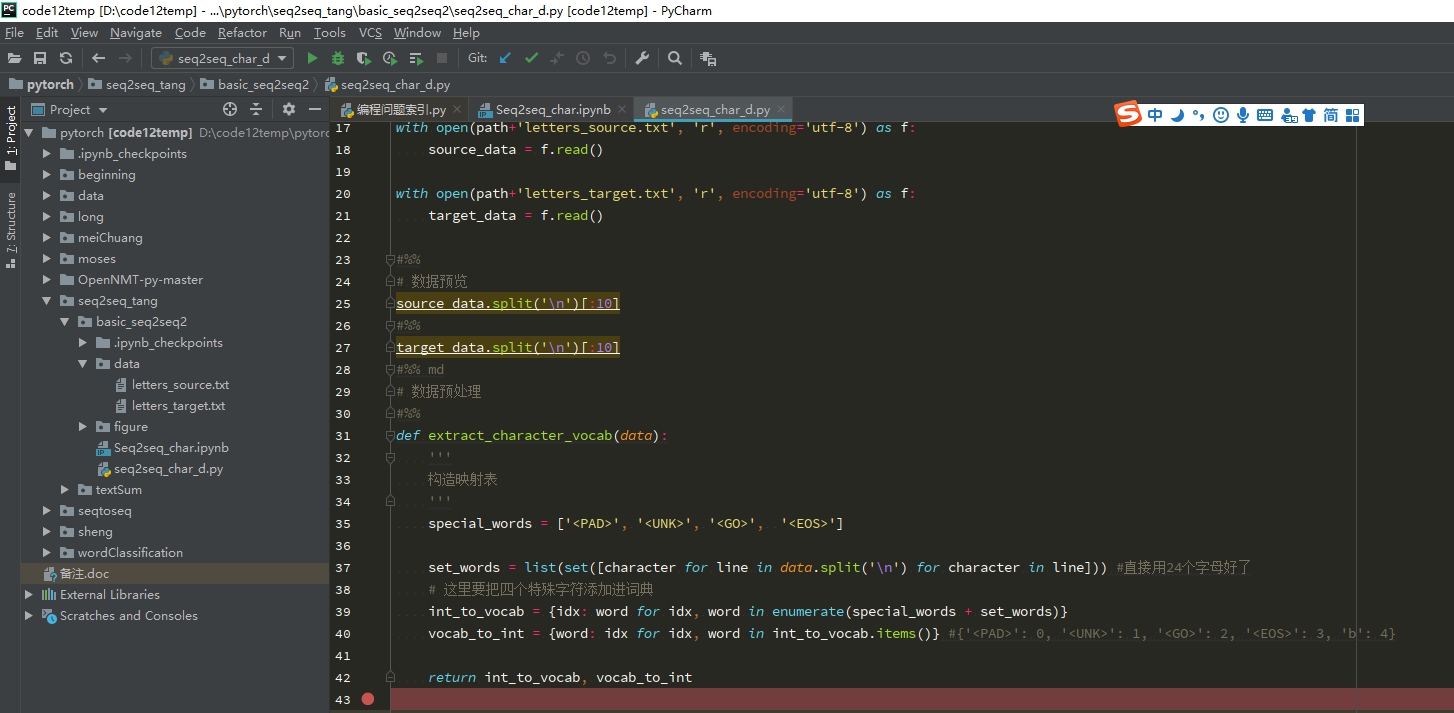
教学代码如果没有主函数 比如jupyter教学的
是按顺序执行的 那么可以一个一个函数的测试
key_out=[1 if i_key not in lang.word2index else 0 for i_key in pair_test[i]]
列表生成式的好处 在没有循环完成之前 可以不影响其他语句的执行
列表生成式 for 的顺序 外部是 从大到小 列表生成式里面是 从右到左 而且需要嵌套
print([i if i == 0 else 100 for i in range(10)])
列表解析
Python 字典(Dictionary) get()方法
描述
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
语法
get()方法语法:
dict.get(key, default=None)
参数
· key -- 字典中要查找的键。
· default -- 如果指定键的值不存在时,返回该默认值值。
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
%s 在open函数中的应用
空格键就是tab键?
! 表示非。 a = true , !a 即 false
叹号的意思
list(reversed(p))
List reverse 直接对列表对进行反转
A=【a,b】 reverse(A) 结果为 [b,a]
没有返回值的类!!!!可以随意构建和反复使用!!!!
True if random.random() < teacher_forcing_ratio else False
If else 的横向表达方式
If 正负的表达
if use_teacher_forcing:
Import 总结
1. 可以直接导入某个模块的类
2. Import模块的时候知己as 重命名
如果是导入 xx.py 里面的 类 a
Import a from xx as 错不能这么导入
3. 只能导入模块之后 用点的方式访问
虽然在同一层 但是上一层要写上
如果其上一层本身就是源了 就不用写上了
不能导入
Can not import 某个类从某个模块 这种情况很有可能是二者相互导入 导致的问题
结构化代码
1. 从上往下 看其对调用方式 和对整个模块的变量使用情况 以及对其他函数的调用情况
如果比较独立 牵扯到别人的部分不是很多 就可以独立出来
2.如果独立出来 会和源文件相互调用 那就不能独立
这种情况直接安装 库就行了 其已经安装在了 anaconda 中
求字符长度
df['长度']=df['column_comment'].apply(lambda x:x.len())
第一种方式居然是错的 会报int 没有len
df['长度']=df['column_comment'].str.len()
Pycharm 调试
Step into 会进入子函数内部
Step into my code 会跳过子函数 如果在同一个模型 如果在不同的模块的话就会进入? my代表当前模块
任何类型的空值为false?
句子切片
A=’你好吗我很好’
B=a[2:3]
从零索引开始,左闭右开
c={'a':1,'b':2}
for i,k in c.items():
print(i,k)
可以通过items() 迭代出来 也可以通过生成器迭代出来
把测试注释之后 最好再重新运行 这样才能把代码对齐(执行白条和代码一致)
p
Full Mode: 但 也 并 不是 那么 出乎 出乎意料 意料 或 难以 难以置信 置信
0 1 2 3 4 5 6 7 8 7 8 9 10 9 10 11 12 13 12 13 14 15 1415
1. 当前长度为1,又和之前配过对了,就不用再输出了
2. 当前长度不为1,和之前已经配对过了 但是后半部分索引大于当前索引的时候 需要输出
3. aa0=100
aa1 = log(aa0 or 1)
aa2= log(aa0 or 1)
aa3=log(1)
如果输入为零的话 那就执行1(1可以是任意指定的值) 如果非零的话 就执行 非零元素
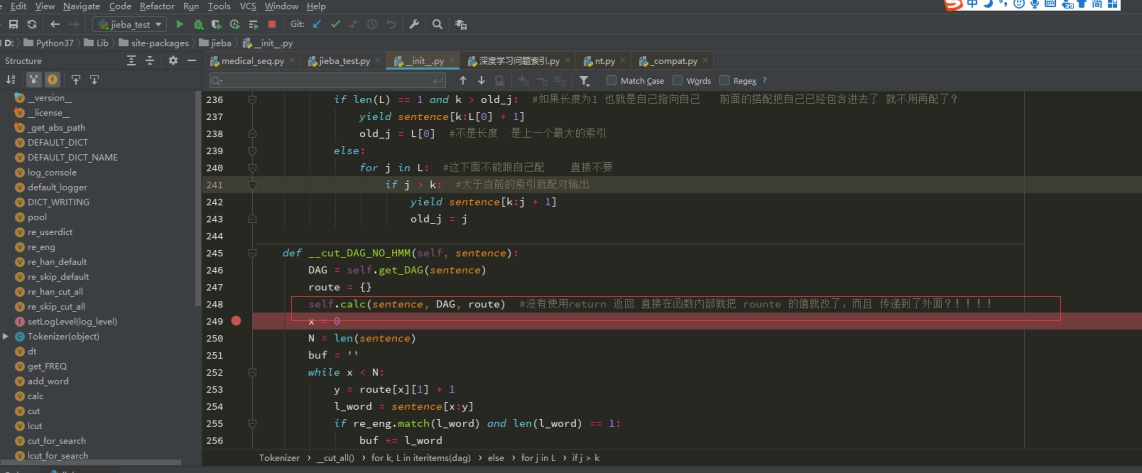
#没有使用return 返回 直接在函数内部就把 rounte 的值就改了,而且 传递到了外面?!!!!
不用return 也可以 把值传到函数外面
正则表达式 中默认的元字符 相当于保留符号 其本身是作为正则的参数
用斜杠来 行使其他功能 当然 如果本身不是保留字符的 比如 d 那加上斜杠之后 整体变成 正则系统的保留字符
for i_pred in tqdm([1]):
per_pred=pd.DataFrame({'dict':'','pred':'','prob':0},index=[0])
df_dict_col=df_dict[['col_name']]
df_dict_col['pred']=df_pred['col_name'][i_pred]
df_dict_col['pred']=df_dict_col['pred'].apply(lambda x:x+',')
df_dict_col['temp']=df_dict_col['pred']+df_dict_col['col_name']
df_dict_col['temp']=df_dict_col['temp'].apply(lambda x:x.split(','))
df_dict_col['similarity']=df_dict_col['temp'].apply(lambda x: editDistance(x[0],x[1]))
重点
要同时对多列的值进行引用并求值的话 就先想办法吧所有值集中在一个列
用容器装 然后再用 apply 导入函数进行 批量处理 比用for循环快多了
多线程或者多进程
多线程适合于IO密集
多进程适合计算密集
两种情况下 如果传入的函数是相互独立的话 就可以不管传入函数和参数具体如何 就可以用for循环添加子进程到进程池
否则就需要每个子进程单独加入 进程池
动态生成变量
def test_list_pre():
prepare_list = locals():字典形式
for i in range(16):
prepare_list['list_' + str(i)] = [] 右边是值 左边是变量
prepare_list['list_' + str(i)].append(('我是第' + str(i)) + '个list')
print(prepare_list['list_0'])
print(prepare_list['list_1'])
print(prepare_list['list_2'])
print(prepare_list['list_3'])
if __name__ == '__main__':
test_list_pre()
Pycharm 禁止联网之后 启动的时候 无法关闭提示窗口
列表解析 for if 对 i 进行多次多层处理 line
企业级的封装:要么封装成服务 网页实现 或者封装为本地级的文件
想咨询下大佬如何对训练好的模型进行部署上线,让它可以像百度翻译和谷歌翻译那样使用
八九点钟的太 2019/7/9 21:50:57
@10001@ru.ru
55435201 2019/7/9 21:51:06
做成web api
Tia 2019/7/9 21:51:43
tensorflow serving
数据集比例的划分
index=str(1) if split_num%15<2 else str(2) if split_num%15>1 and split_num%15<4 else str(3)
分成15份 但是这是很低效的 相比pandas
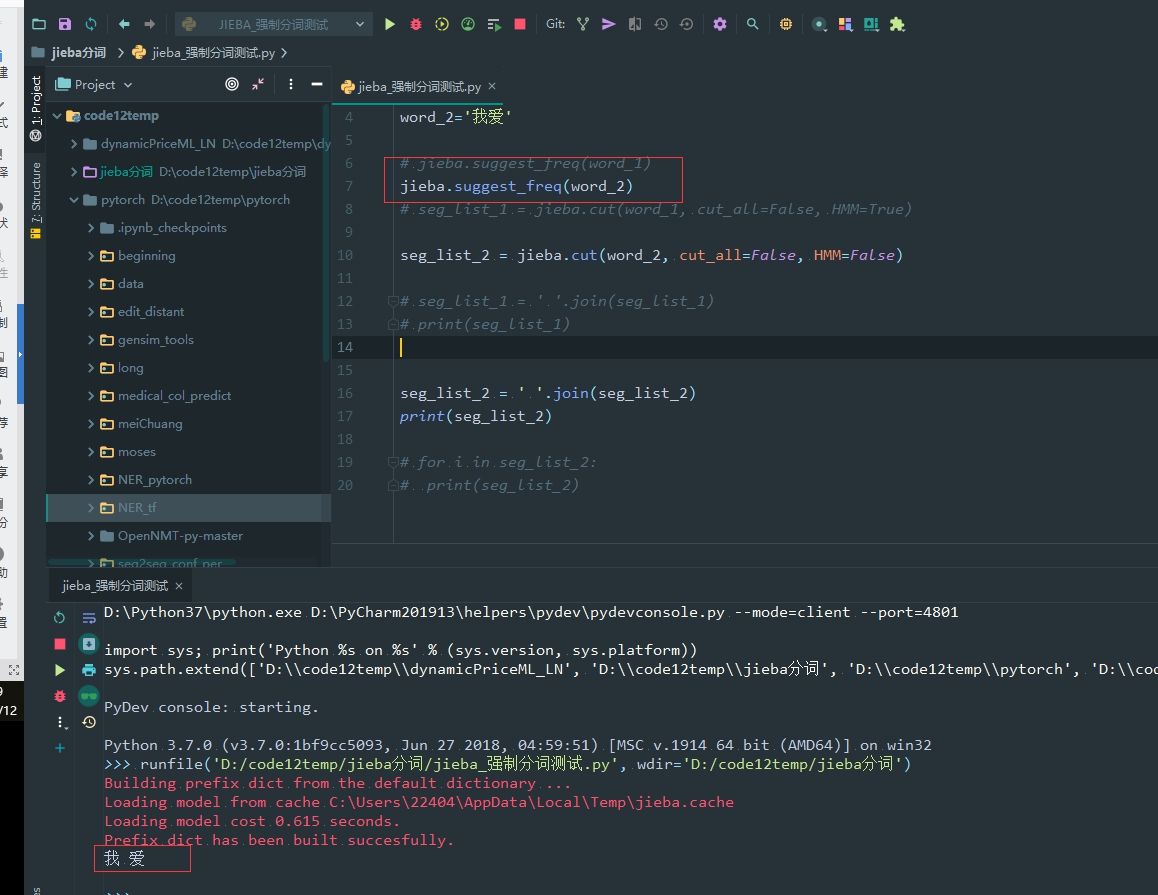
这里强制为什么不行
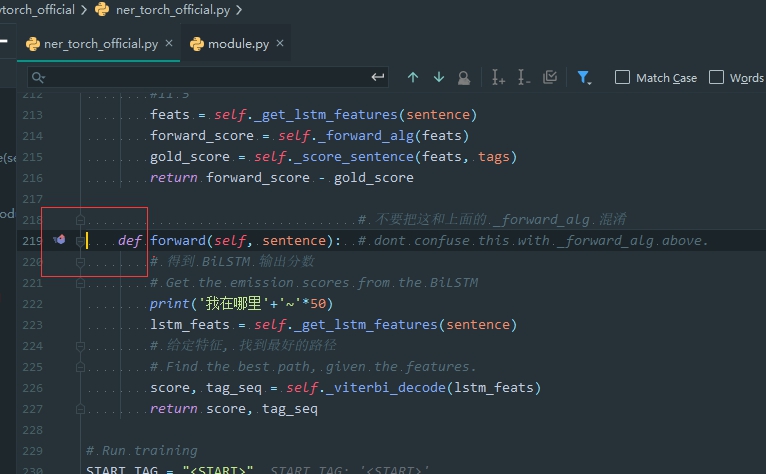
对于是基本类的复写 而找不到调用入口的方法 直接点左边的断点调试的地方就可以直达父类了
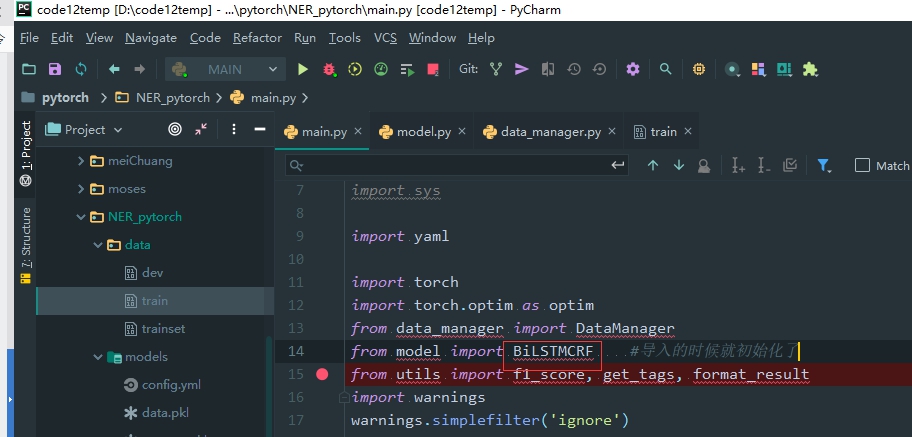
这个类导入的时候 就初始化了
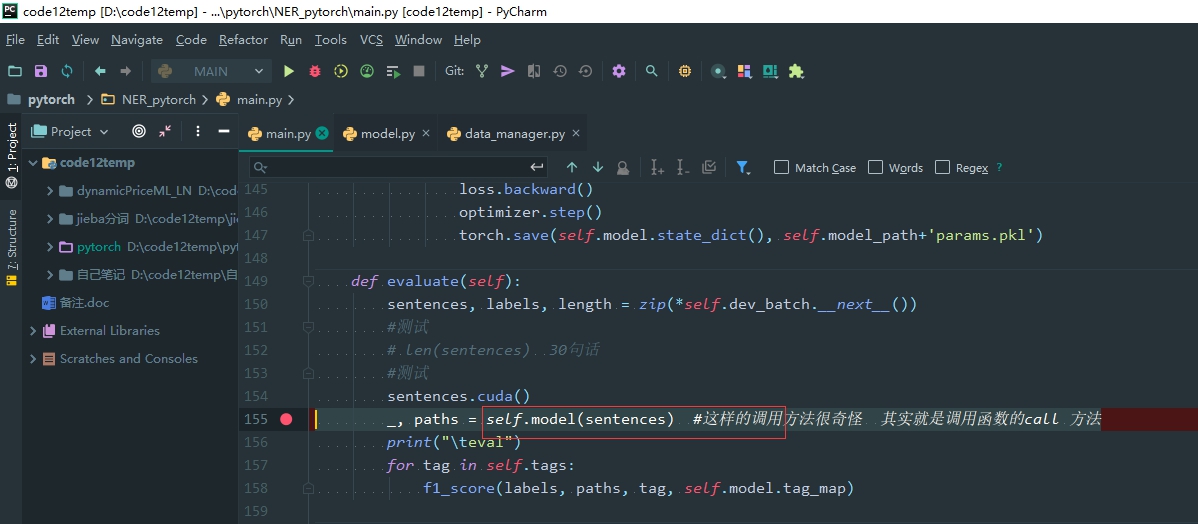
Model 的init 里面找不到传递参数的位置 那么一定是调用call 方法 传到call 方法里面去了
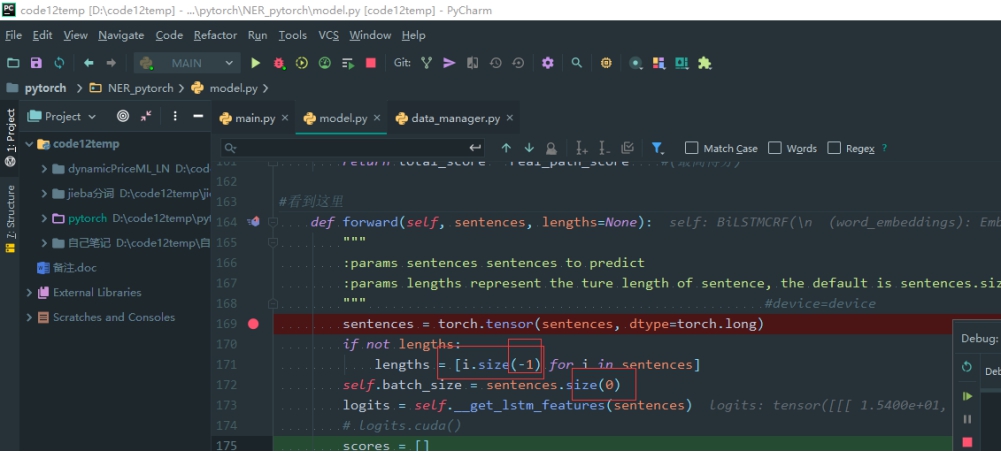
-1 除第一维的其他维
0 为第一维
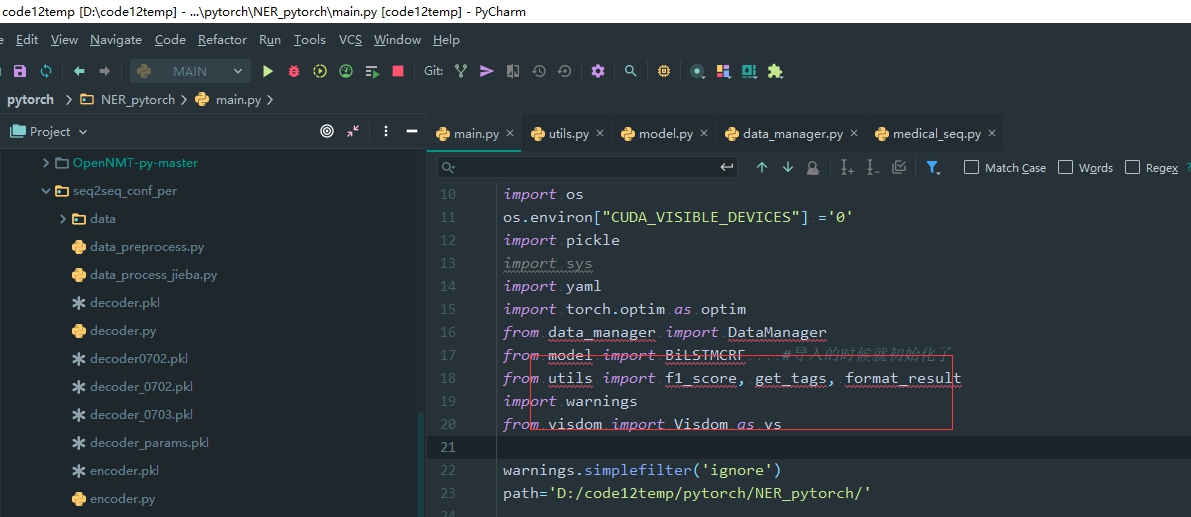
这样导入包 不好直接跳到源代码 最好不这样弄
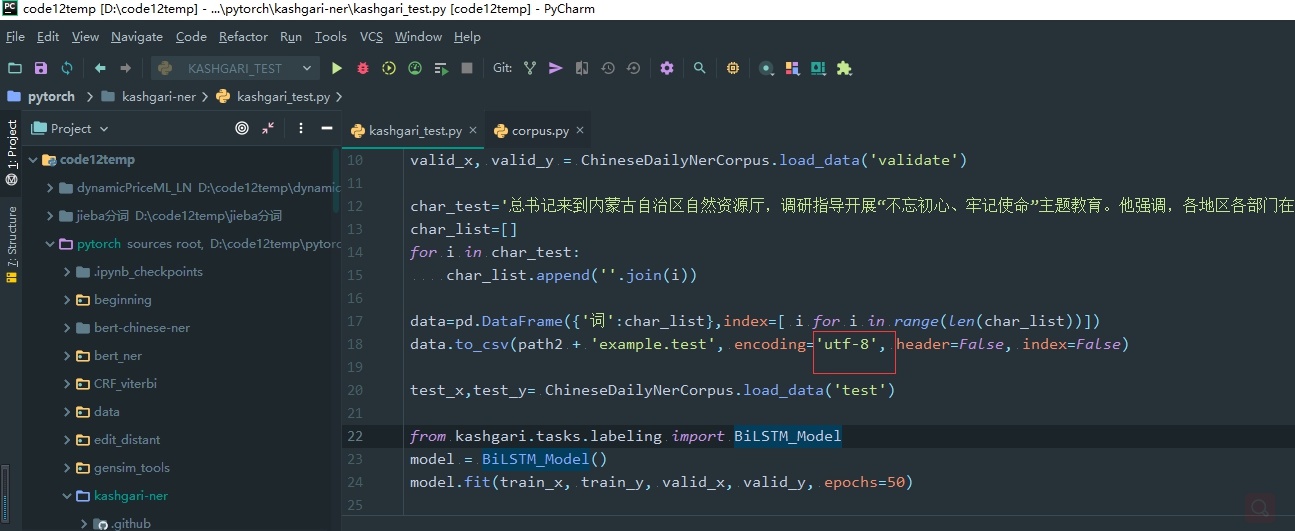
下面读数据用的 utf-8 上面保存最好也是 utf-8
安装
当通过pip下载安装源码到 python 下的包文件里面
同时又从 github上下载 源文件的时候 其优先调用 python下的文件
这个时候直接删掉 python的文件就好了
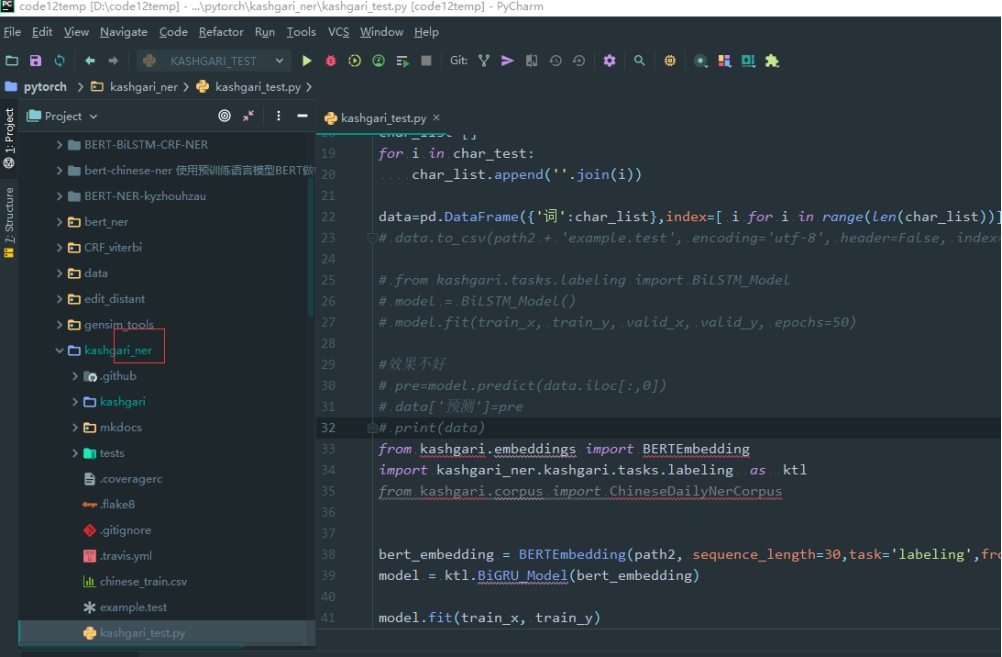
包 文件夹的命名 不能有横线 只能是下划线
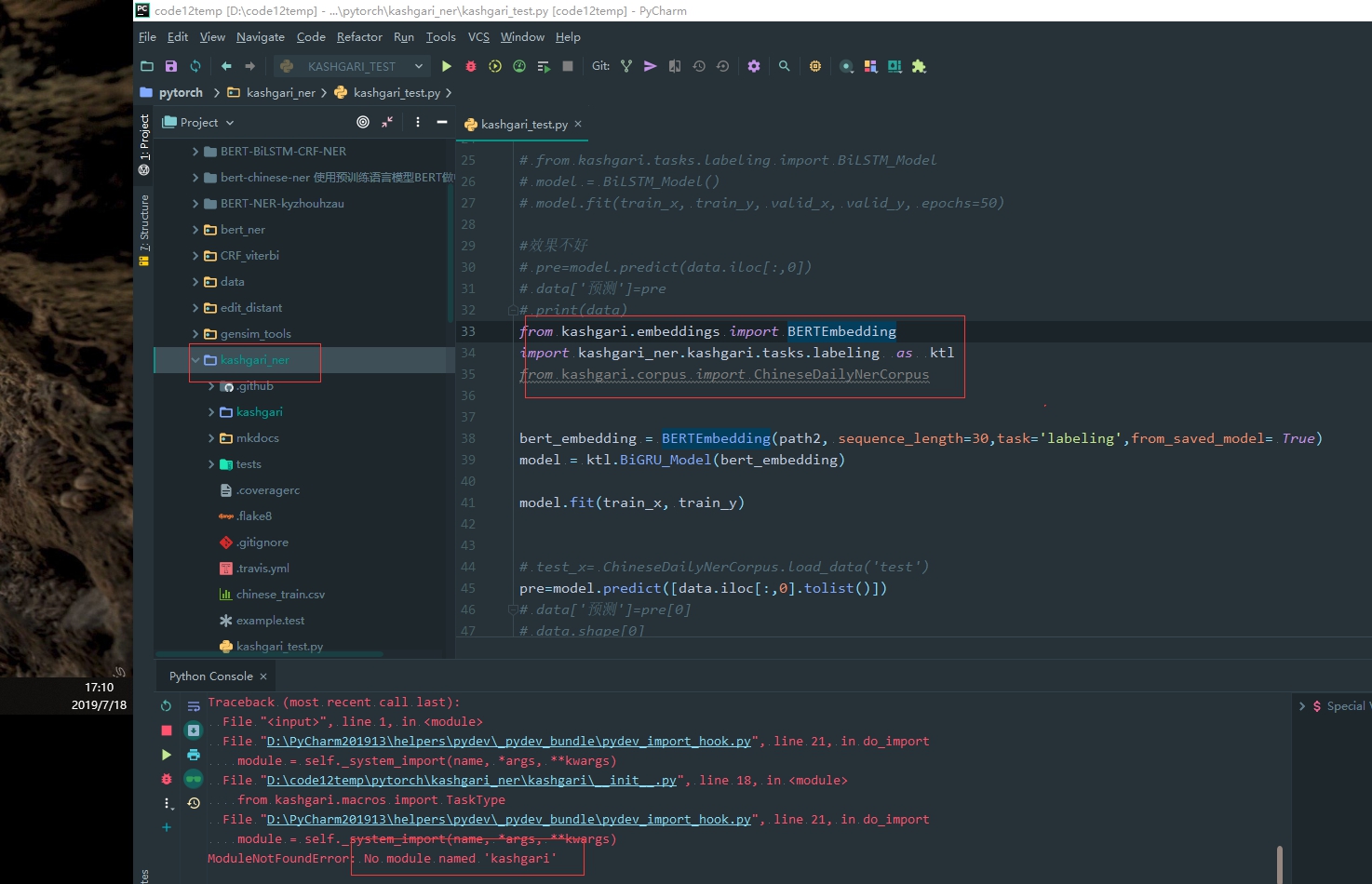
当import no module 的时候 考虑把import 最外层 作为 源 比如 这里 把 keshgari_ner 作为源
以很远的外层作为源的时候 应该可能存在太多的同名文件 而不知道 到底 import哪一个文件
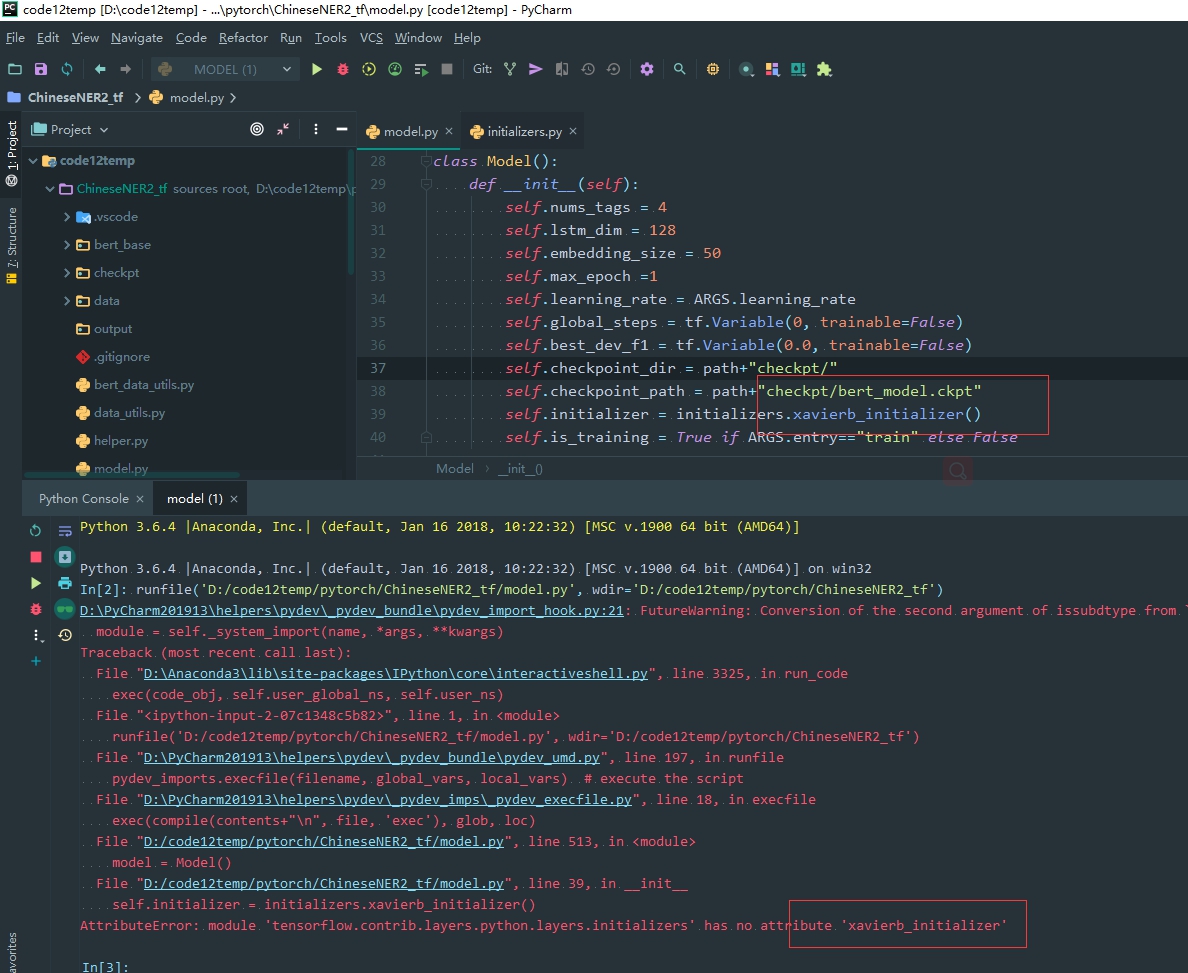
导包的时候 没有属性的情况 很有可能 当前路径下存在多个同名的包或者函数
类里面还可以嵌入类
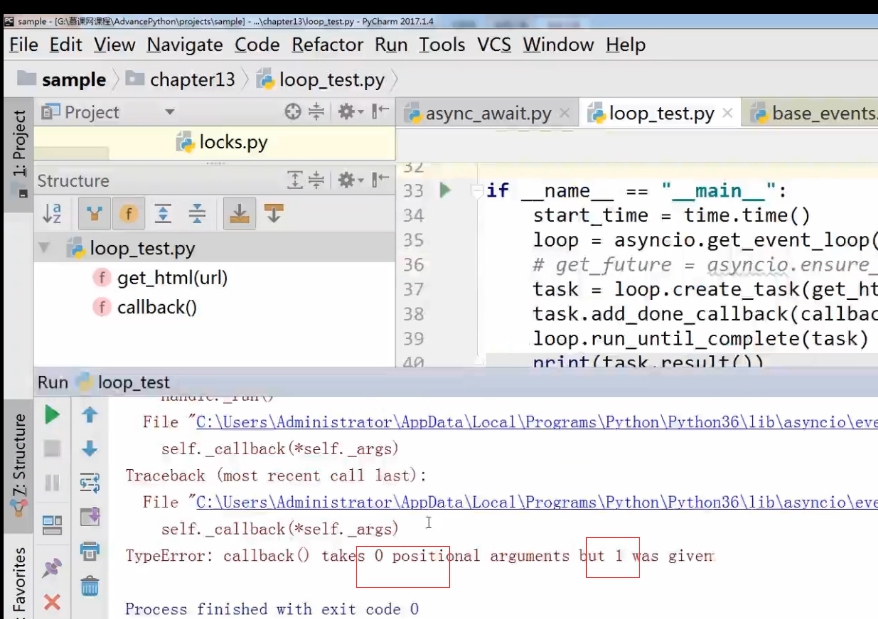
本来应该传递多少个参数 但是你实际上却传了一个参数
Pydev_matplotlibs 模块导入错误 是因为pycharm的原因
数据增多的情况
1. 很有可能就是 merge join 连接的时候出错了
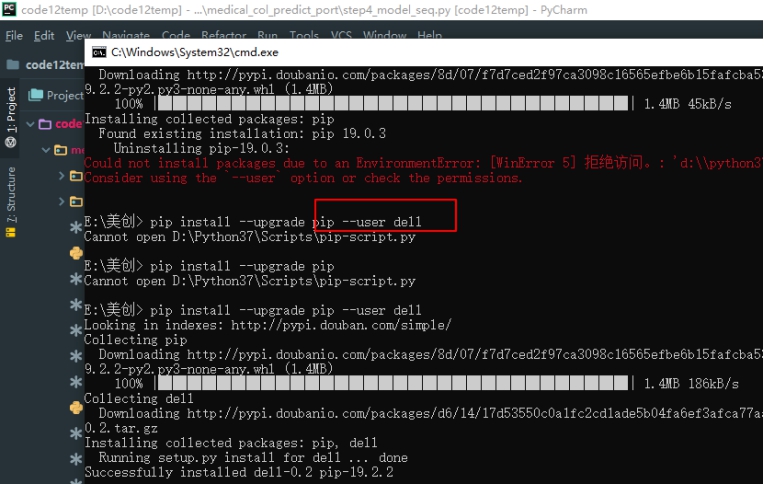
Pip 安装无权限的时候
Pip 当无法直接在cmd 下安装的时候 通过IDE 安装
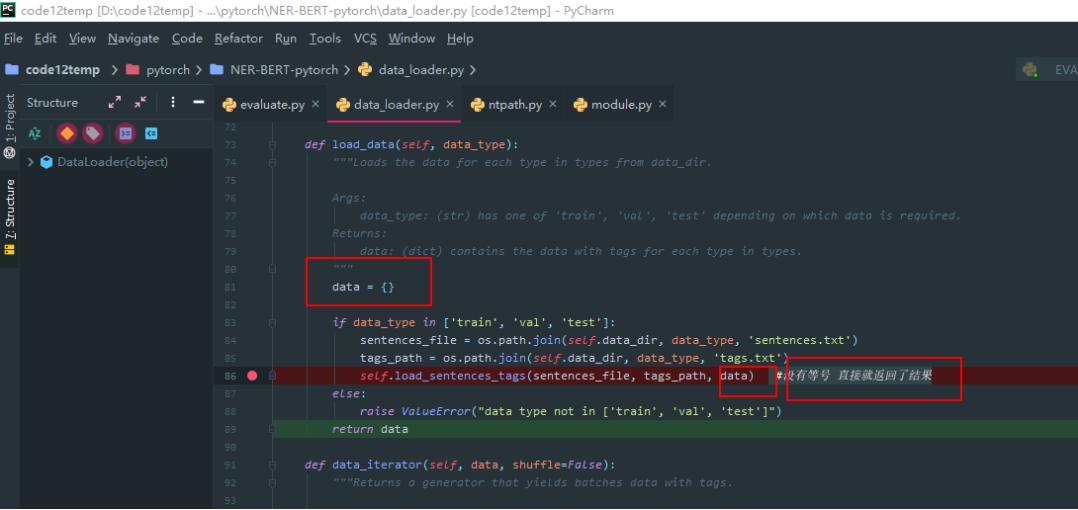
传入参数 经过内部函数处理之后 不用经过等号返回 就直接修改了最终结果
迭代器StopIteration
1. 取数个数正好是迭代器内部元素个数的时候就不会报错了
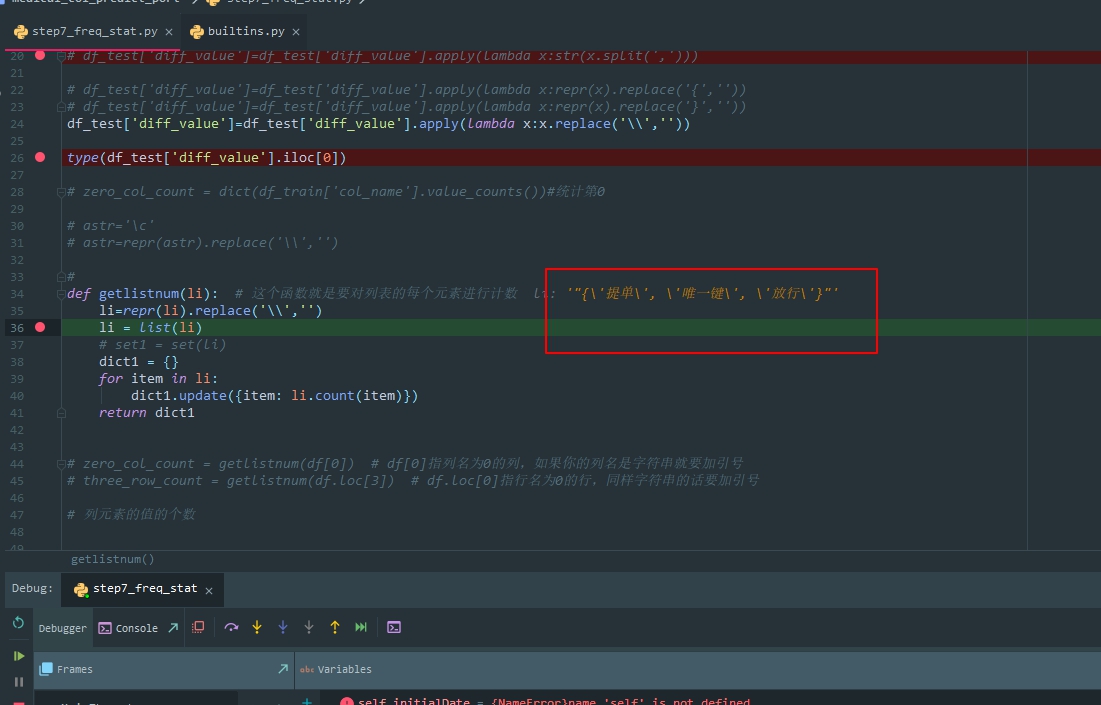
打印出来看不到 反斜杠 显示却有 而且 无法replace
'"{\'提单\', \'唯一键\', \'放行\'}"'
用replace(‘\’’, ’’) 把\’ 替换掉 正则 直接去斜杠貌似不好操作
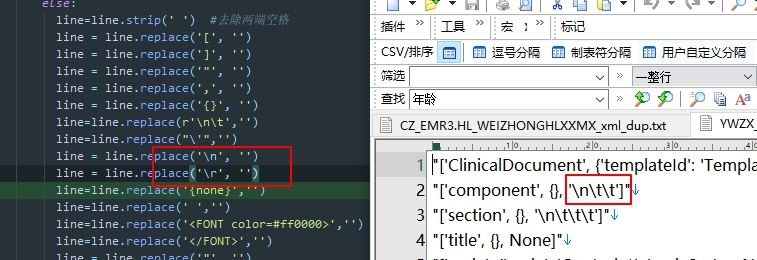
当\n和\r不在字符串里面的时候 不用r
由于多个空字符导致的问题
文件读取:最好先用 withopen 读取再转换成 dataframe
mge[data]=mge[data].apply(lambda x:x.replace(r'\n',''))
两种方法消除\n 一种 在前面加r 一种 \\n
要作为导入包的编写 最好都写成类 导入的时候不影响执行 只有调用时候才执行
当写在最前面作为环境的语句 不能达到效果的时候 考虑 前面导入的其他包是否执行了 相反的操作
列表长度
都是按逗号算的
算长度按列表来算 不用用dataframe 来算
用for 循环的 remove 和pop 删除 list 的元素 对应的索引下次不会再遍历了
用del 就不存在这个问题
静态语言 函数调用完成 整个栈全部被销毁
有可能是空字符的原因
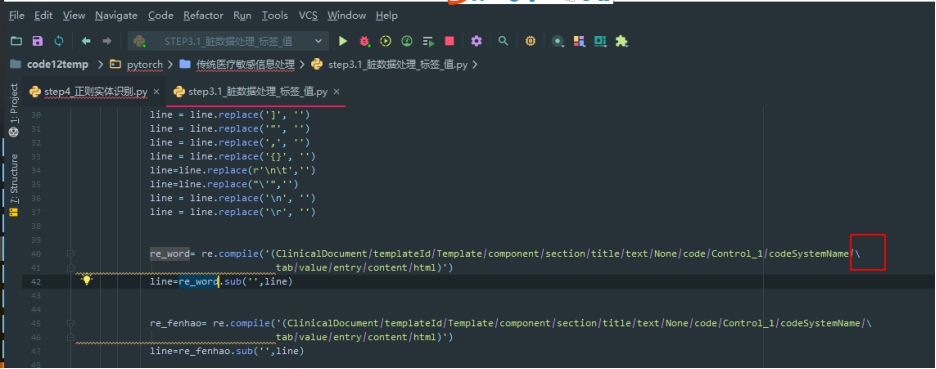
Pycharm 分行用斜杠
Pandas 值为空列表的判断
字符方法 统计某个字符串含有子串多少次
x[1].count(x[0]
能够在指定范围内做修改 就不要大范围的变化 很容易伤及无辜
比如 只有部分数据存在错误 就改部分数据
python编程问题--第二次相关推荐
- python编程学习——第二周
第二周 python学习笔记和做的一些习题 (python编程快速上手--让繁琐工作自动化) 第四章节 列表 列表数据类型 "列表"是一个值,它包含多个字构成的序列. 列表中的值成 ...
- 索引-python编程技术-第二版
本索引停止更新,第三版全重新收纳整理 索引导航-第三版 第一版 https://blog.csdn.net/ifubing/article/details/90750177 ....... 入门 ID ...
- Python编程基础 第二章 编程练习 (第2轮开课补充)编写程序实现以下功能:计算beg到end之间的所有水仙花数并输出。如果beg到end之间不存在水仙花数,则输出“not found”。
9 编写程序实现以下功能:计算beg到end之间的所有水仙花数并输出(水仙花数是一个三位整数,其值与各位数字的立方和相等).如果beg到end之间不存在水仙花数,则输出"not found& ...
- python苦逼_自学Python编程的第十天(希望有IT大牛看见的指点小弟我,万分感谢)---------来自苦逼的转行人...
2019-09-20-23:24:15 今天逛论坛.逛知识星球时.逛b站up主时,都说到低学历,非科班的人最好不要去自学Python 他们都说:如果我们学python是为了找工作,最好不要把pytho ...
- 《Python核心编程》第二版第36页第二章练习 -Python核心编程答案-自己做的-
<Python核心编程>第二版第36页第二章练习 这里列出的答案不是来自官方资源,是我自己做的练习,可能有误. 2.21 练习 2-1. 变量,print和字符串格式化操作符.启动交互式解 ...
- 《Python核心编程(第二版)》——1.9 练习
本节书摘来自异步社区<Python核心编程(第二版)>一书中的第1章,第1.9节,作者[美]Wesley J. Chun,宋吉广 译,更多章节内容可以访问云栖社区"异步社区&qu ...
- 《Python核心编程》第二版第18页第一章练习 -Python核心编程答案-自己做的-
<Python核心编程>第二版第18页第一章练习 这里列出的答案不是来自官方资源,是我自己做的练习,可能有误. 1.9 练习 1-1. 安装Python.请检查Python是否已经安装到你 ...
- “青少年编程能力等级”第一、第二部分:图形化编程 Python编程 含测试样题
标准由全国高校计算机教育研究会.全国高等院校计算机基础教育研究会.中国软件行业协会.中国青少年宫协会4个团体联合发布.清华大学.北京理工大学牵头的标准研制团队,通过调研.研讨.专家咨询等,广泛征求意见 ...
- 一、 Python 基础知识笔记 —— 《Python编程:从入门到实践(第二版)》学习笔记
前言 先安利这本书<Python编程:从入门到实践(第二版)>,作者埃里克-马瑟斯,很适合新手入门,我的python入门学习就是以这本书为核心: 再安利一个网站:菜鸟教程-Python3教 ...
最新文章
- mysql sock golang_golang thrift 总结一下网络上的一些坑
- Objective - C基础: 第一天 - 1. 第1, 2个OC程序
- k8s StatefulSet
- 004 IOC---IOC容器
- 基于Linux下嵌入式网关,基于嵌入式Linux系统的无线网络网关设计
- 自包含 .NET Core应用程序
- c语言通讯录动态文件操作,学C三个月了,学了文件,用C语言写了个通讯录程序...
- Vue中,在<template>内进行页面链接跳转
- 40行代码的人脸识别实践【转】
- 别再骂中年人了,对他们好点吧~
- 常见问题-瑞友天翼应用虚拟化系统安装之前需要做什么准备
- 【笔记17】使用 jad 工具把 java 的 class 文件转换为 java 文件;使用 luyten 把 java 的 jar 包转换为 java文件
- lwj_C#_周总结2 字符串练习
- 5G+如何改变社会--读书有感
- jmeter常见问题总结
- 使用PreListener与InteractionListener的一个小发现
- 厦门大学计算机调剂要求,厦门大学考研调剂复试有什么要求
- 深度linux 安装qq游戏,深度操作系统20下载
- 中国56民族 sql
- 强哥说Java--Java Scanner 类