Kylin集群部署和cube使用
Kylin集群部署和cube使用
- 安装集群环境
节点 Kylin节点模式 Ip 内存 磁盘
Node1 All 192.167.71.11 2G 80G
Node2 query 192.168.71.12 1.5G 80G
Node3 query 192.168.71.13 1.5G 80G
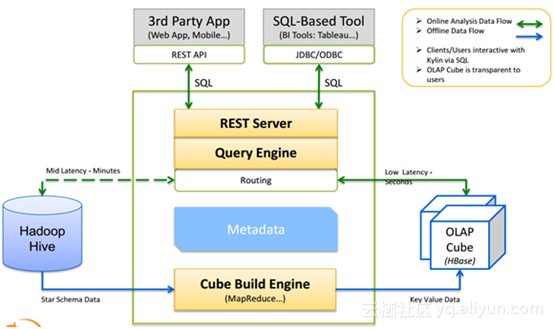
Kylin工作原理如下:
- 集群时间同步
Ntp服务自行设置 - 安装kylin之前所需要的环境
Hadoop-2.7.4
Hbase-1.4.0
Spark-2.2.0 可选
Zookeepr-3.3.6
Hive-2.1.1 使用mysql存放元数据,远程模式安装
Kylin-2.3.1
Hadoop环境,HBASE,zookeeper还有hive自行安装,集群环境变量如下:
HADOOP
export HADOOP_HOME=/home/zhouwang/hadoop-2.7.4
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djave.library.path=$HADOOP_HOME/lib"
ZOOKEEPER
export ZOOKEEPER_HOME=/home/zhouwang/zookeeper-3.3.6
export PATH=:$PATH:$ZOOKEEPER_HOME/bin
HIVE
export HIVE_HOME=/home/zhouwang/apache-hive-2.1.1-bin
export HIVE_CONF_HOME=$HIVE_HOME/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=:$PATH:$HIVE_HOME/bin:$HCAT_HOME/bin
SCALA
export SCALA_HOME=/home/zhouwang/scala-2.10.5
export PATH=:$PATH:$SCALA_HOME/bin
SPARK
export SPARK_HOME=/home/zhouwang/spark-2.2.0-bin-hadoop2.7
export PATH=:$PATH:$SPARK_HOME/bin
HBASE
export HBASE_HOME=/home/zhouwang/hbase-1.4.0
export PATH=$PATH:/home/zhouwang/hbase-1.4.0/bin
KYLIN
export KYLIN_HOME=/home/zhouwang/apache-kylin-2.3.1-bin
export KYLIN_CONF_HOME=/home/zhouwang/apache-kylin-2.3.1-bin/conf
export PATH=:$PATH:$KYLIN_HOME/bin:$CATALINE_HOME/bin
export tomcat_root=$KYLIN_HOME/tomcat
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.1.1.jar
- 安装kylin
(1)第一步修改bin/kylin.sh,这么做的目的是为了加入$hive_dependency环境,解决后续的两个问题,都是没有hive依赖的原因。
第一个问题是kylinweb界面load hive表会失败,第二个问题是cube build的第二步会报org/apache/Hadoop/hive/conf/hiveConf的错误。
更改如下:
export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
(2)第二步就是hadoop支持压缩的问题,本例的hadoop不支持snappy压缩,会导致后续cube build报错。如果要hadoop支持的话,另行找解决方案
解决这个问题对应的要修改kylin的三个配置文件
Kylin_job_conf.xml
不使用压缩
mapreduce.map.output.compress设置为false
mapreduce.output.fileoutputformat.compress 设置为false
kylin_hive_conf.xml
不使用压缩
hive.exec.compress.output 设置为false
kylin.properties
修改见下文
(3)第三步修改kylin.properties
主节点配置
kylin.metadata.url=kylin_metadata@hbase ###hbase上存储kylin元数据
kylin.env.hdfs-working-dir=/kylin ###hdfs上kylin工作目录
kylin.env=DEV
kylin.env.zookeeper-base-path=/kylin
kylin.server.mode=all ###kylin主节点模式,从节点的模式为query,只有这一点不一样
kylin.rest.servers=node1:7070,node2:7070,node3:7070 ###集群的信息同步
kylin.web.timezone=GMT+8 ####改为中国时间
kylin.job.retry=2
kylin.job.mapreduce.default.reduce.input.mb=500
kylin.job.concurrent.max.limit=10
kylin.job.yarn.app.rest.check.interval.seconds=10
kylin.job.hive.database.for.intermediatetable=kylin_flat_db ###build cube 产生的Hive中间表存放的数据库
kylin.hbase.default.compression.codec=none ###不采用压缩
kylin.job.cubing.inmem.sampling.percent=100
kylin.hbase.regin.cut=5
kylin.hbase.hfile.size.gb=2
定义kylin用于MR jobs的job.jar包和hbase的协处理jar包,用于提升性能(添加项)
kylin.job.jar=/home/zhouwang/apache-kylin-2.3.1-bin/lib/kylin-job-2.3.1.jar
kylin.coprocessor.local.jar=/home/zhouwang/apache-kylin-2.3.1-bin/lib/kylin-coprocessor-2.3.1.jar
配置完之后将kylin安装包传送搭配从节点
Scp -r apache-kylin-2.3.1-bin zhouwang@node2:~/apache-kylin-2.3.11-bin
Scp -r apache-kylin-2.3.1-bin zhouwang@node3:~/apache-kylin-2.3.11-bin
主从节点的配置的唯一不同就是kylin.server.mode,一个集群的所有节点必须只能有一个节点处于job或者all状态,其他节点全部为query状态。- 启动kylin
第一步,启动zookeeper,所有几点运行zkServer.sh start
第二步,启动hadoop,主节点运行start-all.sh
第三步,启动JobHistoryserver服务,主节点启动mr-jobhistoryserver-deamon.sh start historyserver
第四步,启动hivemetastore服务,hive –service metastore &
第五步启动hbase集群,主节点启动start-hbase.sh
第六步,检查基础依赖的服务,hadoop,hbase,hive,环境变量,工作目录等,hive依赖检查find-hive-dependency.sh ,hbase依赖检查find-hbase-dependency.sh,所有的依赖检查可吃用chek-env.sh。
第六步,启动kylin服务,所有节点运行bin/kylin.sh start
- 登录
http://node1:7070/kylin
默认的秘钥:admin/KYLIN
- 样例数据测试
启动kylin之后运行sample.sh脚本
导入sample数据,模型,cube成功之后系统会提示重启kylin或者重新加载元数据让数据生效。我们选择重新加载。
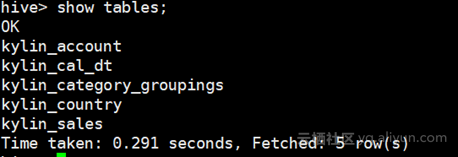
重新加载过后查看hive
查看hbase中的数据多了一个kylin_metadata元数据表
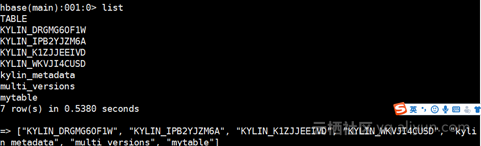
默认的有一个cube需要build
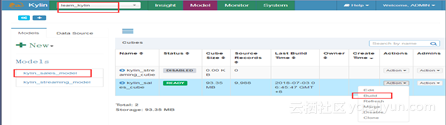
Build成功之后
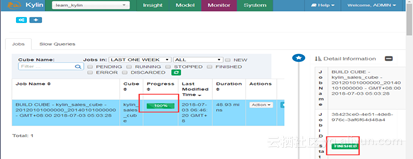
Build成功之后model里面会出现storage信息,之前是没有的,可以到hbase里面去找对应的表,同时cube状态变为ready,表示可查询。
8.查询性能对比(为本地自己的数据建的cube,不是sample数据)
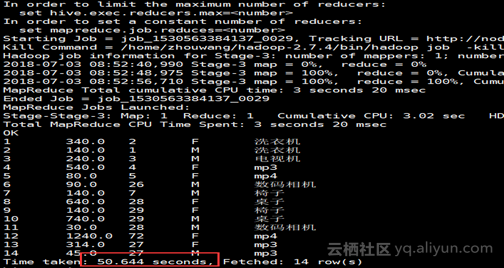
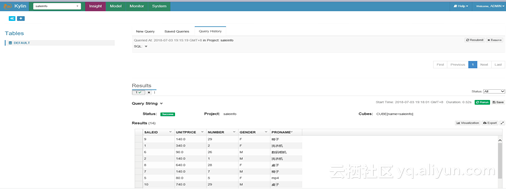
可以看出明细kylin要比hive快上很多倍,kylin集群部署结束。
- Cube使用
Cube使用分为五部:
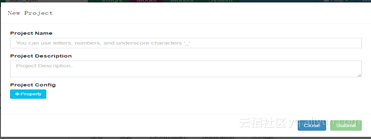
第一步:新建工程 
点击加号跳出下面的界面,输入工程名,提交即可。
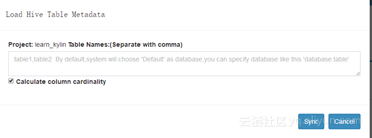
第二步,添加数据源 
三个按钮功能各不相同,自行了解,点击第一个输入表名同步,点击第二个加载出hive的元数据,点击选择表,同步。

第三步,新建model,自行设置各个步骤
第四部,新建cube,自行设置cube的每一步信息
第五步,cube的build
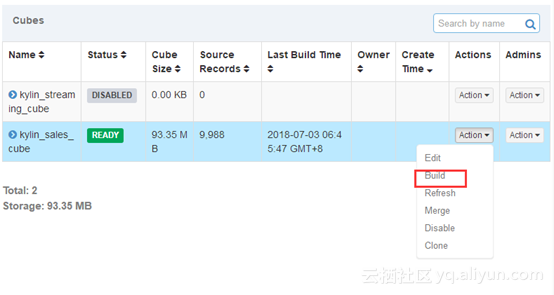
选择build,提交cube job,mapreduce计算(计算引擎自选mapreduce或者spark)。结果存在hbase。结果表在model的storage里面查看。
Kylin集群部署和cube使用相关推荐
- Kylin集群部署及基本架构简介
一.基本架构及原理 实现:利用hadoop中MapReduce框架对hive表中的数据进行预计算,将预计算结果缓存至Hbase中,解决TB级数据分析需求 原理架构参考:https://www.cnbl ...
- Linux之FineBI集群部署
在企业应用中,通常单个计算机的配置是有限的,而企业应用又是高并发的需求,这个时候会通过计算机集群的方式来提高并发数,从而提高整体应用服务的性能.集群是将多台计算机作为一个整体来提供相关应用的服务.Fi ...
- Linux之FineBI集群部署 1
在企业应用中,通常单个计算机的配置是有限的,而企业应用又是高并发的需求,这个时候会通过计算机集群的方式来提高并发数,从而提高整体应用服务的性能.集群是将多台计算机作为一个整体来提供相关应用的服务.Fi ...
- Druid -- 基于Imply方式集群部署
向导 集群部署 1. 下载tar包,上传服务器,解压 2. 修改配置文件common.runtime.properties 3. 修改coordinator配置,vi overlord/runtime ...
- 堡垒机jumpserver集群部署
本文参考老广二次开发后的堡垒机部署方案,在此基础上进行集群部署,提高其可靠性.尽管国外已经有类似的功能的堡垒机的发布,但是还是要感谢老广在百忙之中开发出更加实用的堡垒机. 本文内容虽然亲测,但内容难免 ...
- 百度开源联邦学习框架 PaddleFL:简化大规模分布式集群部署
百度开源联邦学习框架 PaddleFL:简化大规模分布式集群部署 作者 | 钰莹近两年,联邦学习技术发展迅速.作为分布式的机器学习范式,联邦学习能够有效解决数据孤岛问题,让参与方在不共享数据的基础上联 ...
- 手动安装K8s第三节:etcd集群部署
手动安装K8s第三节:etcd集群部署 准备安装包 https://github.com/coreos/etcd 版本:3.2.18 wget https://github.com/coreos/et ...
- zookeeper+kafka集群部署+storm集群
zookeeper+kafka集群部署+storm集群 一.环境安装前准备: 准备三台机器 操作系统:centos6.8 jdk:jdk-8u111-linux-x64.gz zookeeper:zo ...
- Linux集群部署和ipvsadm命令的使用
在日常的使用中,一台服务器足够胜任很多的工作,但是当很多人同时访问的时候就会显得稍有些无力,这个时候.可以有两种解决的方法,第一种是不断的改善这台服务器的性能,但是总是会有一个上限存在,而且提升的效果 ...
最新文章
- 灵活运用 SQL SERVER FOR XML PATH
- antd Form 表单验证
- AtomicIntegerFieldUpdater字段原子更新类
- .NET手撸2048小游戏
- 第三方app_为什么第三方APP不能下载呢?
- 八皇后问题判断此位置是否需合适
- Ext grid js上移下移样例
- nlp中的经典深度学习模型(二)
- mysql一对多增删改查_SpringBoot+MySql+ElementUI实现一对多的数据库的设计以及增删改查的实现...
- e盾网络验证源码_Laravel [mews/captcha] 图片验证码
- 利用PowerDesigner15在win7系统下对MySQL 进行反向project(二)
- Springmvc和poi3.9导出excel并弹出下载框
- thinkphp的商城 好在哪里
- html+css常用代码(前端必备)
- 怎么查看计算机办公软件版本的,怎样查看电脑用的什么办公软件
- skimage rescale_intensity函数
- 布局中颜色搭配怎么看最舒服之白色的最佳10种颜色搭配
- Matlab论文插图绘制模板第60期—瀑布图(Waterfall)
- 电脑云便签怎么在桌面日历月视图上新增便签记录事情?
- 【图像去噪】基于matlab全变分算法图像去噪【含Matlab源码 626期】
热门文章
- Posted content type isn't multipart/form-data
- 7_2判断两个单链表是否相交,若相交,求出第一个交点
- 算术运算中隐式类型转换
- ×××作,不知写些什么
- eBCC性能分析最佳实践(1) - 线上lstat, vfs_fstatat 开销高情景分析...
- rabbitmq可靠发送的自动重试机制 --转
- Spring Cloud Alibaba 基础教程:Nacos 生产级版本 0.8.0
- Kotlin基本语法和使用
- Connection cannot be null when 'hibernate.dialect'
- CentOS7上编译多版本PHP并同时运行及systemd设置