发掘数据中的信息 -- 数据探索之描述性统计
在如今这个大数据时代,数据的价值得到普遍的认可。可是,数据为什么有价值呢?如果,数据只是静静地躺在服务器中,又或是默默地流淌在网络中,它们又能带来什么?
数据就如同海边的沙子,潮起潮落,岁月轮转,它们也仅仅是沙子而已;但如果有好奇的孩子在沙滩上玩耍,他们或许能发现沙子下埋藏的美丽贝壳,又或许能用沙子垒成有趣的玩具城堡;如果来了位手艺精湛的匠人,他就能将沙子变魔术般变成晶莹剔透的玻璃;如果来的是一群勤劳智慧的人们,他们就能将沙子与水泥混合成坚固的混凝土,从而盖起一座城。
你一定发现了,数据要经过加工和挖掘,变成有用的信息,才具备真正的价值。四百年前,在天文学和占星术还纠缠不清的时代,作为天文学家和占星术士的第谷几十年如一日地观测天体运行数据,其精度可谓达到了肉眼观测的极限。然而让这些数据真正发挥价值的却是第谷的弟子开普勒,经过大量的数据分析,开普勒发现了行星的椭圆运行轨迹,进而又得出了开普勒三定律。
数据分析的主旨,一直是发掘数据中的有价值的信息,更进一步是将信息转换为知识,最难的是将知识升华为洞见。做为数据分析的前奏,让我们首先用描述性统计学的方法来探索数据中隐含的信息。
在上一篇《数据分析的流程》中,我们讲到将使用美国行为风险因素监控系统BRFSS数据,来试图回答这么一个问题:如今美国的富人们是更胖还是更瘦呢?
那么接下来,我们将从数据的中心趋势、相对位置、离散度、相关性四个方面,使用统计量和统计图两种方式,来发掘BRFSS数据中的信息。
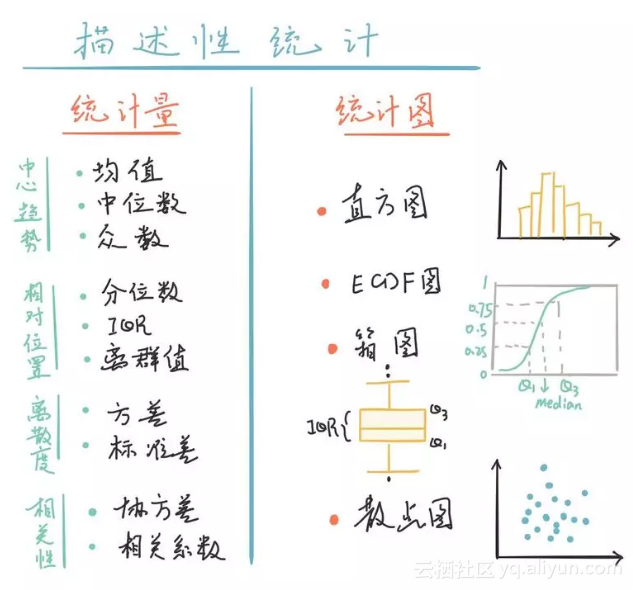
描述性统计内容大纲
数据导入
首先,我们导入相应的Python模块和BRFSS数据。如果你想亲手实践一下,也可以在此处github中下载数据和源代码。
(https://github.com/fishstar/Exploratory-Data-Analysis)
数据以DataFrame的格式存储,每一行是一个受访者的调查数据,每一列是一项属性,我们先选取bmi和income两列。其中bmi列代表BMI指数,用来衡量人的胖瘦程度,BMI指数越高人越胖。income列代表收入水平,这里分了8级,分别用数字1到8代表,8级是年家庭收入超过7.5万美元的人群,在这里我们将8级的人群定义为富人,其他1-7级的人群定义为普通人。下面列出了前5行数据,可以感受下数据的大致样子。
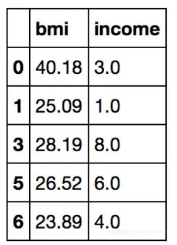
前5行数据
上面几行内容并不能展示出数据的全貌,所以我们使用info()方法,可以得到该数据一共有343092行,每一列都是浮点类型数据,且没有缺失值。
bmi_income.info()
接着我们提取收入水平为8级的富人们的bmi数据,存入变量bmi_rich中,相应的其他普通人的bmi数据存入变量bmi_ord中。
用describe()方法查看这两类人群的bmi数据在统计方面的信息,包括样本量(count)、均值(mean)、标准差(std)、最大(max)和最小(min)值,以及分位数。
bmi_rich.describe()
bmi_ord.describe()
目前为止,我们对所分析的数据有了笼统的感觉,那么接下来让我们逐一仔细研究一番。
中心趋势
如果要用一个数字来代表一组数据,你会用什么呢?你首先想到的大概会是算数平均值,我们生活中经常使用均值的概念,比如某某国家的人均收入,人均寿命,某个行业的平均薪水等等,不胜枚举。当然除了均值,还有中位数和众数,都可以用来代表一组数据的中心趋势。
● 均值:
由于存储两类人群的bmi数据bmi_rich和bmi_ord都是Pandas中的Series数据类型,所以我们使用mean()方法来求算数平均值。经计算,富人们的BMI指数均值为27.45,普通人的则是28.54,从均值上看,似乎富人们更瘦一些。
● 中位数
如果将数据从小到大按顺序排列,那么处于中间的那个数就是中位数。如果样本总量是偶数,中间就存在两个数,那么中位数就是这二者的平均值。当数据中出现异常偏离中心的值时,中位数就比均值更具代表性。比如我们常觉得自己的收入拖了全国人民的后腿,那是因为用了平均值作为错误的比较对象,如果将那些占比虽少但动辄就要先赚它1个亿的超级富豪们从计算中去除,那么你或许会得到不少安慰。
同样,使用median()方法可计算中位数。将这里得到的中位数和上面的均值作比较,你能得出什么结论呢?先思考一下,我们后面揭晓答案。
● 众数
正如其名,众数就是数量最多的那一个数,比如选举中最多的那个票数,商家最畅销产品的销售量。众数一般是用在不连续的分类数据中,但如果用在连续数据中,一般是将连续数据划分成多个区间,统计每个区间的数据量,从而得出数量最多的那个区间。
在这里,BMI指数本是连续数值,但因为只精确到小数点后两位,所以也可以将之看成是离散不连续的,又因为我们数据的样本量非常之大,所以这里也可以用mode()得到bmi的众数。
● 均值的差值
还记得我们进行数据探索的初衷吗?就是找到富人胖瘦问题的答案。最简单的衡量方法,是计算两类人群BMI指数均值的差。
print("mean difference (rich - ordinary) : %.2f" % (mean_rich - mean_ord))
mean difference (rich - ordinary) : -1.09
上面的计算告诉我们,富人的BMI均值比普通人小了1左右,那么我们是否可以认为富人更瘦呢?是不是无法理直气壮地下结论,毕竟我们只用了一个数值来代表全体数据,这个均值有多可靠呢?让我们继续深入下去。
● 直方图
如果将BMI数据等分成若干个区间,统计落入每个区间的数据的数量,就可以得到下面的直方图,横轴代表BMI指数的值,纵轴是每个区间内数据量。直方图可以反映数据的总体分布情况,从图中可以看出人们的BMI指数大致集中在20到40之间,当然也有异常接近100的人,只是数量非常少。同时也能非常直观地找到众数,就是最高的那个竖条所在的区间。值得注意的是,直方图中区间划分的不同,也会影响图形的样子和众数,特别是在数据量较少的情况下。
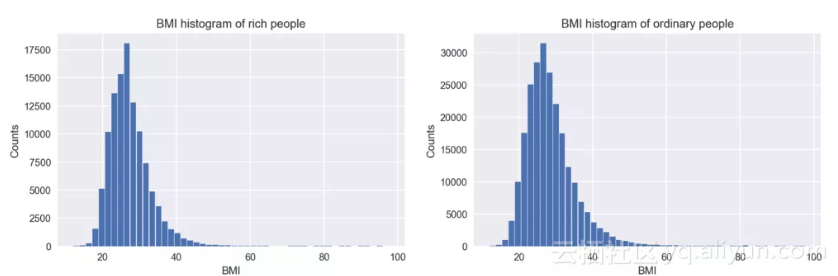
直方图1
为了更清晰地比较两类人群的数据分布,我们将上面两个直方图合在一起,同时截取了BMI取值在10到60之间的数据。用紫色代表的普通人群的分布总体上比用红色代表的富人的分布更向BMI值大的方向偏离,这让我们似乎更确信富人更瘦一些,因为现在让我们得出结论的不是单单一个数值,而是许多数据组成的图。但是在直方图中似乎看的还不够清楚,有没有更清晰的图来表示呢?显然我们也有更好的工具,但在此之前,让我们先来看下直方图中所反映的数据分布的一个性质:偏度。
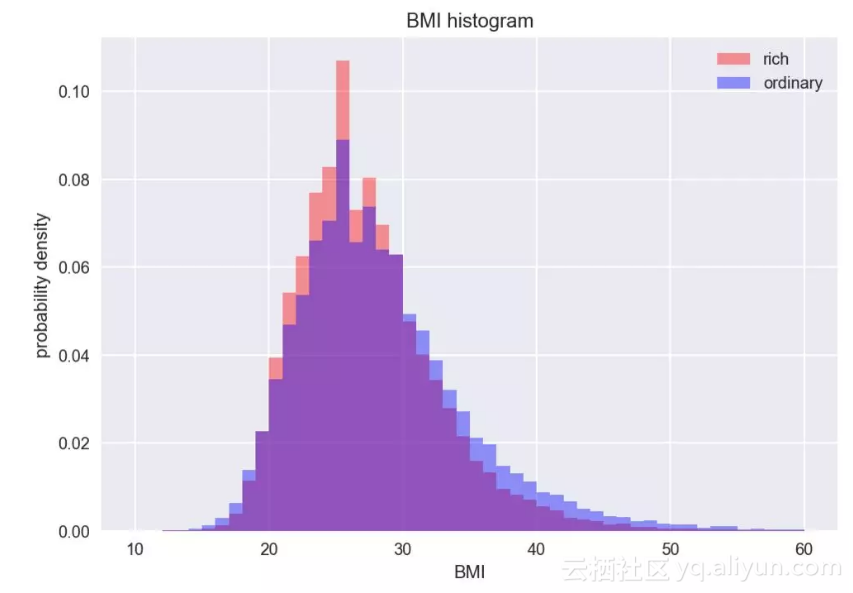
直方图2
● 偏度
仔细观察BMI分布的直方图,虽然数值集中在20到40之间,但是在其右边有一条细细长长的尾巴,我们称这样的分布是右偏的,计算其偏度也是一个正数。之前在得到BMI分布的均值和中位数时,我曾留下一个悬念,比较发现中位数比均值偏小,这正是右偏分布的特性。不仅如此,在右偏分布中,度量数据中心趋势的三个量关系如下:众数 < 中位数 < 均值。我们从下图中可以清晰的看出这一关系。
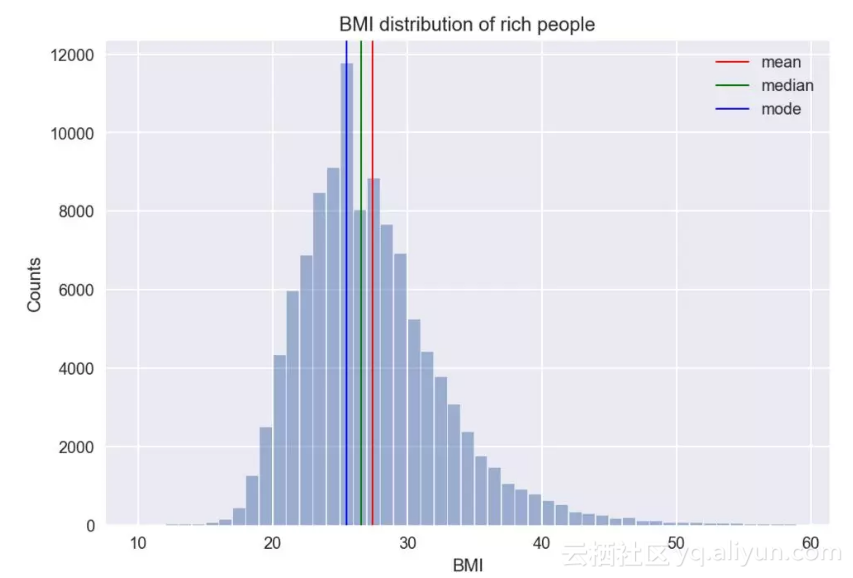
直方图3
既然有右偏,那自然也有左偏,其偏度为负值,性质也与右偏相反。下面给出了我们研究的样本人群收入水平的分布,是一个左偏的分布。
skewness: -0.74
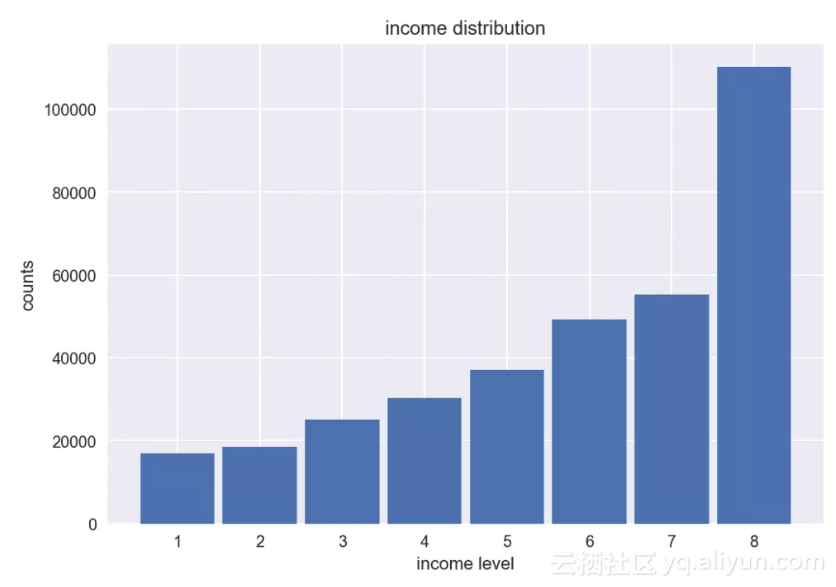
收入水平的直方图
相对位置
● ECDF图
在比较两类人群的bmi数据时,我们先后使用了均值和直方图,这两者其实都是对数据信息的压缩。均值将信息压缩到一个数值,而丢弃了大部分信息量;相比之下直方图则保留了更多的信息量,只是将数据压缩到一个个连续的区间中。这也就是为什么之前我们在比较两类人的直方图时,总有看不真切的感觉。那么有没有什么方法能显示所有的数据点呢?这就是下面所示的经验累积分布函数图:ECDF(Empirical Cumulative Distribution Function)。
将BMI数据从小到大排列,并用排名除以总数计算每个数据点在所有数据中的位置占比。比如总共100个数据中排第20位的数据,其位置占比为20/100=0.2 。将所有的数据以BMI值为横坐标,位置占比数值为纵坐标描画于图中,就得到了ECDF图。
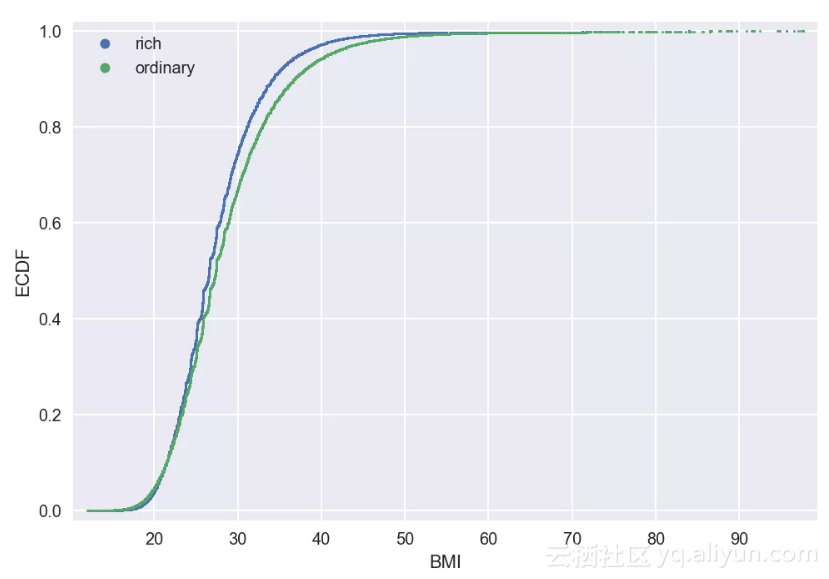
ECDF图
ECDF图中显示了所有的数据点及其在样本中所处的位置,从上图中可以清晰地看到普通人群(绿色点)比富人(蓝色点)的分布更靠右,即向BMI变大的方向偏移。
● 分位数
在ECDF图中我们可以得到许多信息,比如最大和最小值。
由于ECDF图的纵坐标的属性,我们从图中也可以得到任意比例所对应的分位数。比如中位数,就是占比为50%的分位数。另外时常用到的还有25%和75%所对应的四分位数,而这两者的差值,称为IQR(Interquartile range),它可以看做样本变异性的度量。
● 箱图(box plot)
更直观反映分位数的是箱图,图中直接画出了中位数、四分位数和IQR,并且从中还能发现离群值,它们是数据中异常大或异常小的数值。在箱图的上下两侧分别有两道篱笆,它们的数值分别是Q1-1.5IQR和Q3+1.5IQR,其中Q1,Q3是四分位数。而处于这两道篱笆之外的数值可以看做异常值。
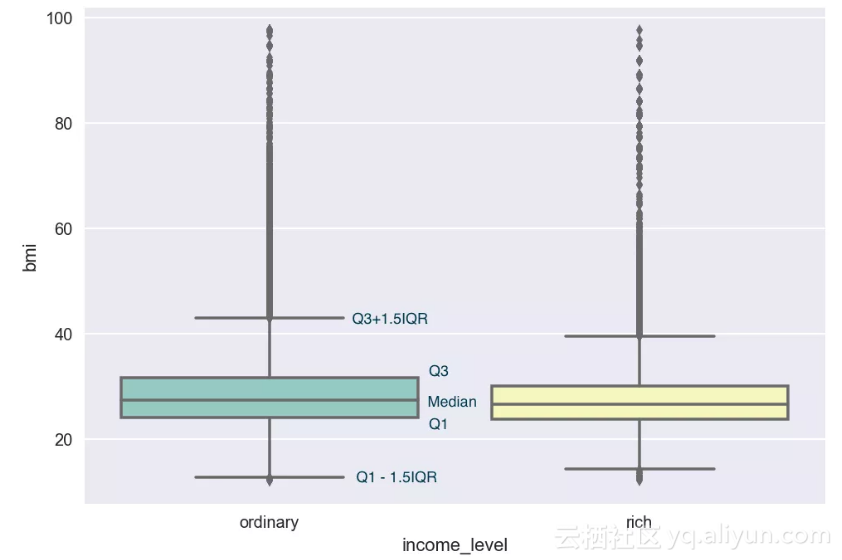
箱图
离散度
在比较富人和普通人BMI的均值后,让我们不敢妄下结论的还有一点,就是我们担心这样的差值是不是足够大,大到足以超越每组人群本身的波动性呢?
● 方差和标准差
数据围绕均值的上下波动,也可以看做是数据的离散程度,我们使用方差和标准差来衡量。标准差是方差的平方根,代表数据中所有点距离均值的平均距离,其公式定义如下:

标准差公式
这里分母中使用N-1而非N,是因为当使用样本数据推测总体的标准差时,需进行Bessel修正。
使用var()和std()方法计算方差和标准差。
● **Cohen's d **
当考虑了样本数据的离散度后,就能够更精准的衡量两类人群BMI值的差异,即使用一个新的量:Cohen's d,它可以简单看做是均值的差值除以两个样本综合的标准差。其公式定义如下:
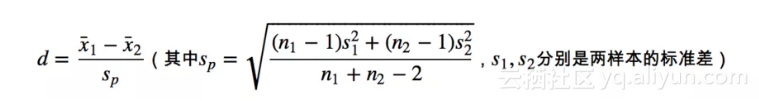
Cohen's d 公式
根据上面的公式,我们定义函数cohen_d()来计算BMI数据的Cohen‘s数值。
Cohen's d: -0.163
这里得到的Cohen’s d的绝对值是0.163, 这个值是大是小呢?首先我们需要对Cohen's d有一个大概的数值范围概念,当它的值为0.8代表有较大的差异,0.5位列中等,0.2较小,0.01则非常之小。所以这里计算出的0.163代表两类人群的BMI值有差异,但是差异较小。
然而到这里我们可以得出富人更瘦的结论了吗?且慢,目前为止我们看到差异显然是存在的,但要下十分肯定的结论,仍是不够火候。这个问题需要等后续讲到推论统计时才能彻底解决。
相关性
之前我们观察的都是单个变量(主要是BMI指数)的统计学性质,接下来我们考察下两个变量之间的关系。
● 协方差
协方差(Covariance)是衡量两个变量的总体误差,方差可以看做是两个变量相同时的特殊情况。其公式如下:
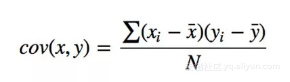
协方差公式
下面使用 numpy 中的cov()函数来计算样本人群中身高和体重的协方差。
这里得到的结果是一个2乘2的对称矩阵,对角线上的数值分别代表两个变量各自的方差,而处于第一行第二列的数值正是这两个变量的协方差。
● 相关系数
了解了协方差的概念后,就可以使用Pearson相关系数来衡量两个变量的相关性,它的定义是协方差除以两个变量各自的标准差,公式如下:
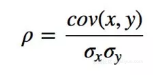
相关系数公式
Pearson相关系数的取值范围在-1到1之间,0代表无相关性,正数代表正相关,负数代表负相关,绝对值越大,相关性越高。
这里使用 numpy 中的corrcoef()函数计算身高和体重的相关系数。
np.corrcoef(height, weight)[0,1] # 计算Pearson相关系数
0.47180417408477093
得到0.47的相关系数,可见身高和体重之间是存在一些相关性的。我们将身高和体重分别做为横坐标和纵坐标,数据作于下方的散点图中,可以看出随着身高的增长,体重的总体趋势有上升,但关系不是特别明显。
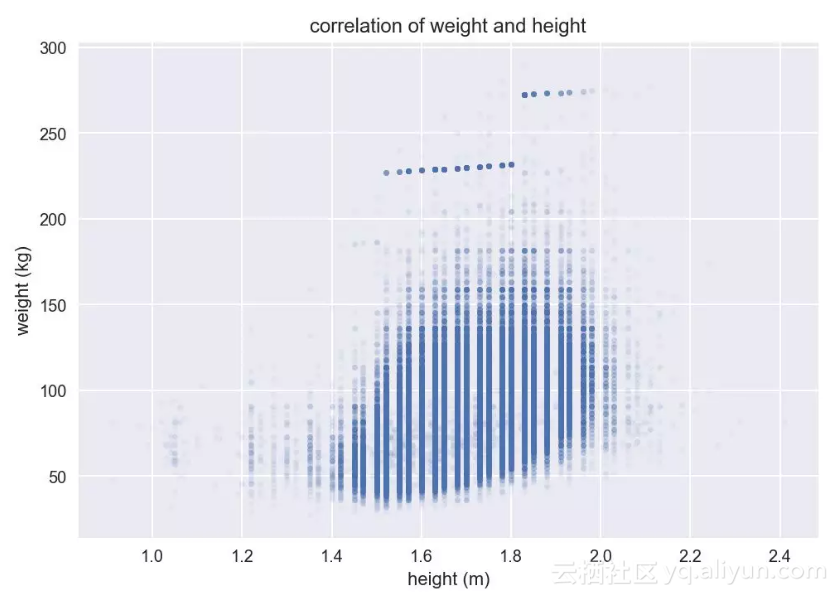
身高-体重散点图
同样,我们计算得到BMI值和体重的相关系数为0.87,有非常强烈的正相关性,从它们的散点图中也能看出来。
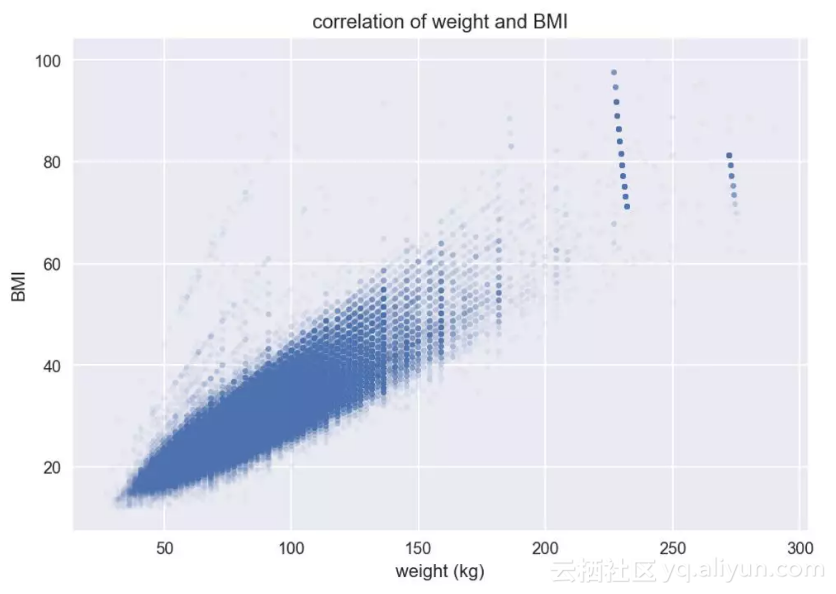
BMI-体重散点图
别忘了BMI指数的计算公式就是体重除以身高的平方,那么BMI和体重的正相关性也很自然了,即越重的人BMI值可能越高。那么你是不是觉得BMI和身高具有负相关性呢?从BMI公式看貌似有可能,但实际计算得出BMI和身高的相关系数只有-0.006,微弱到可以忽略的程度。其实从常识中也可以判断,BMI既然是胖瘦的衡量,高的人并不一定胖啊。
Pearson correlation coefficient: -0.0060
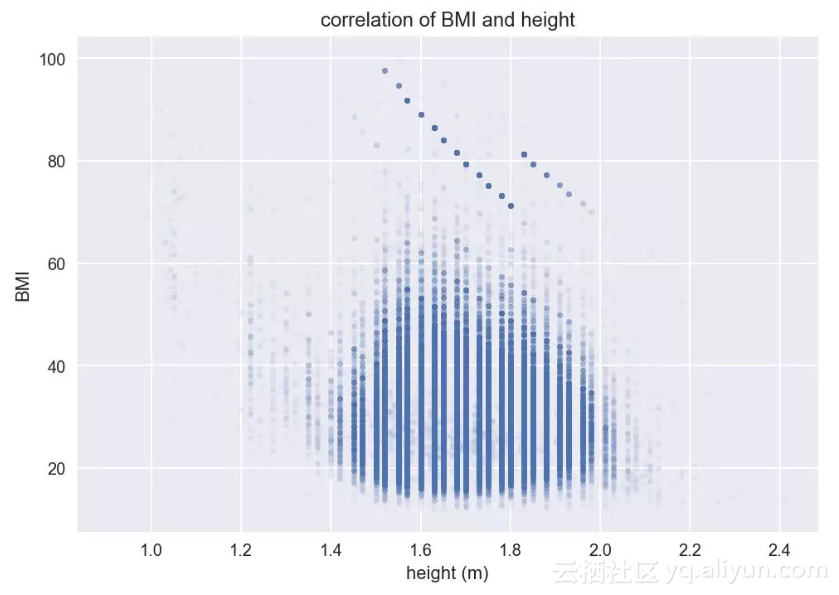
BMI-身高散点图
总结
本文分别从统计量和统计图两种视角来观察数据,查看了数据的中心趋势、相对位置、离散程度和相关性。统计量包括:衡量中心趋势的均值、中位数、众数,衡量相对位置的分位数,衡量离散程度的方差和标准差,以及衡量相关性的Pearson相关系数。统计图则包括直方图、ECDF图、箱图和散点图。
同时,围绕富人是胖还是瘦的问题,我们采用了均值的差值和Cohen's d数值来衡量这一效果量,同时也采用直方图和ECDF图这类可视化的方法得出了富人更瘦一些的观察,但是这些都只是描述性统计学的方法,真正要得出结论还需要推论统计学的帮助,这会在后续的系列文章中涉及。
数据探索系列目录:
● 开篇:数据分析流程
● 发掘数据中的信息 - 描述性统计分析(本文)
● 统计分布
● 参数估计
● 假设检验
原文发布时间为:2018-11-25
本文作者:鱼心DrFish
本文来自云栖社区合作伙伴“Python爱好者社区”,了解相关信息可以关注“Python爱好者社区”。
发掘数据中的信息 -- 数据探索之描述性统计相关推荐
- R语言数据描述性统计(Descriptive statistics)实战:数据全局描述信息、数值数据的描述性统计(Numerical data)、离散型数据的描述性统计(Categorical)
R语言数据描述性统计(Descriptive statistics)实战:数据全局描述信息.数值数据的描述性统计(Numerical data).离散型数据的描述性统计(Categorical) 目录
- 数据库进阶·如何针对所有用户数据中没有的数据去加入随机的数据-蜻蜓Q系统用户没有头像如何加入头像数据-优雅草科技kir
数据库进阶·如何针对所有用户数据中没有的数据去加入随机的数据-蜻蜓Q系统用户没有头像如何加入头像数据-优雅草科技kir 本内容主要用于学习,头像只是举例的一个字段,可以应用在其他方面,举一反三 问题背 ...
- html怎么拿json数据,如何使用Python从HTML数据中提取JSON数据?
我正在尝试制作一个python脚本,可以在outlook中读取JSON数据电子邮件.但是问题是如何从HTML数据中提取JSON数据.这是我要提取的原始JSON数据.在{ "vpn_detai ...
- 假设有一个字类型的数值arry1,试编写程序统计arry1数值及其后若干数值,在字单元中存储时每个数据中含“1”数据位的个数,并将统计结果保存在res1数组中。数据段的代码定义如下: data seg
假设有一个字类型的数值arry1,试编写程序统计arry1数值及其后若干数值,在字单元中存储时每个数据中含"1"数据位的个数,并将统计结果保存在res1数组中.数据段的代码定义如下 ...
- R语言获取dataframe数据中某一数据列以某一特定字符串开头的数据行
R语言获取dataframe数据中某一数据列以某一特定字符串开头的数据行 目录 R语言获取dataframe数据中某一数据列以某一特定字符串开头的数据行
- R语言使用epiDisplay包的summ函数计算dataframe数据中的指定数据列在分组变量下的统计量(样本数、均值、中位数、标准差、最大值、最小值)、可视化一个按照分类变量绘制的有序点图
R语言使用epiDisplay包的summ函数计算dataframe数据中的指定数据列在分组变量下的统计量(样本数.均值.中位数.标准差.最大值.最小值).可视化一个按照分类变量绘制的有序点图 目录
- R语言使用epiDisplay包的summ函数计算dataframe数据中的指定数据列在分组变量下的统计量、可视化一个按照分类变量绘制的有序点图(有序点图分析数值型变量的分布、密集趋势、异常值)
R语言使用epiDisplay包的summ函数计算dataframe数据中的指定数据列在分组变量下的统计量.可视化一个按照分类变量绘制的有序点图(有序点图分析数值型变量的分布.密集趋势.异常值) 目录
- R语言dplyr包summarise_at函数计算dataframe数据中多个数据列(通过向量指定)的计数个数、均值和中位数、使用funs函数指定函数列表
R语言dplyr包summarise_at函数计算dataframe数据中多个数据列(通过向量指定)的计数个数.均值和中位数.使用funs函数指定函数列表 目录
- R语言dplyr包summarise_at函数计算dataframe数据中多个数据列(通过向量指定)的计数个数、均值和中位数、使用list函数指定函数列表并指定自定义函数名称
R语言dplyr包summarise_at函数计算dataframe数据中多个数据列(通过向量指定)的计数个数.均值和中位数.使用list函数指定函数列表并指定自定义函数名称 目录
最新文章
- 非聚集索引和聚集索引
- 突破Android微信微博浏览器限制直接拉起应
- AttributeError: 'StatusHandler' object has no attribute 'async_callback'
- 2020蓝桥杯省赛---java---B---6(分类计数)
- [CLR via C#]18. Attribute
- NLP学习01--BP神经网络
- ubuntu12.04 如何设置wiznote到快捷启动栏
- sql创建和添加时间字段
- 平面变压器的设计(翻译)(4)
- 光学图像、SAR图像等区别
- JuniperSSG140使用PBR实现双线路接入
- 红队技术-父进程伪装(MITRE ATTCK框架:T1134)
- CSDN拒绝好友的私信内容信息太弓虽了
- sql server返回是星期几的函数
- 系统重启后mipi屏幕黑屏的问题
- 调度程序所用数据结构—Linux
- c#实现类似Sublime Text文本编辑器、电脑屏幕画板
- Debian修改桌面系统
- win 10网信政府版 无法登录微软账号
- c语言x的n次方怎么写_C语言入门教程(三)进制与操作符