python3读取excel数据-Python3将爬取的数据存储到Excel
我们学习 Python3 爬虫的目的是为了获取数据,存储到本地然后进行下一步的作业,今天小雨就教大家 python3 如何将爬取的数据插入到 Excel
我们直接来讲如何写入 Excel 文件:
基本流程就是:新建工作簿--新建工作表--插入数据--保存工作表,和我们在电脑上面操作 excel 表是一样的。
workbook = xlwt.Workbook(encoding='utf-8')#创建 workbook 即新建 excel 文件/工作簿,
worksheet = workbook.add_sheet('my_worksheet') #创建工作表,如果想创建多个工作表,直接在后面再 add_sheet
worksheet.write(0,0,Value) #写入数据,共 3 个参数,第一个参数表示行,从 0 开始,第二个参数表示列从 0 开始,第三个参数表示插入的数值
workbook.save('top250.xlsx') #写完记得一定要保存
我们完成了第二个作业:输出豆瓣 top250 电影名,一行一个后,就可以把获取到的数据存储到 Excel 了。
Python3作业二:输出豆瓣top250电影名,一行一个
在python3 爬虫利器 Xpath:用 Xpath 提取文本这篇文章中,我们学会了用 Xpath 来提取网页中的文本,输出的格式是这样的 那么如何一行一个的输出呢? 这需要我们复习下小白教程中的列表和循环的章节,作为本次的第二个作业: 小雨给出了参考答案: 进群完成第二个作业后找群主索取密码 很多初学 pyt...

# coding:utf-8
from lxml import etree
import requests
import xlwt
title=[]
def get_film_name(url):
html = requests.get(url).text #这里一般先打印一下 html 内容,看看是否有内容再继续。
#print(html)
s=etree.HTML(html) #将源码转化为能被 XPath 匹配的格式
filename =s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()') #返回为一列表
#print (filename)
title.extend(filename)
def get_all_film_name():
for i in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
get_film_name(url)
if '_main_':
myxls=xlwt.Workbook()
sheet1=myxls.add_sheet(u'top250',cell_overwrite_ok=True)
get_all_film_name()
for i in range(0,len(title)):
sheet1.write(i,0,i+1)
sheet1.write(i,1,title[i])
myxls.save('top250.xls')
输出结果如下:
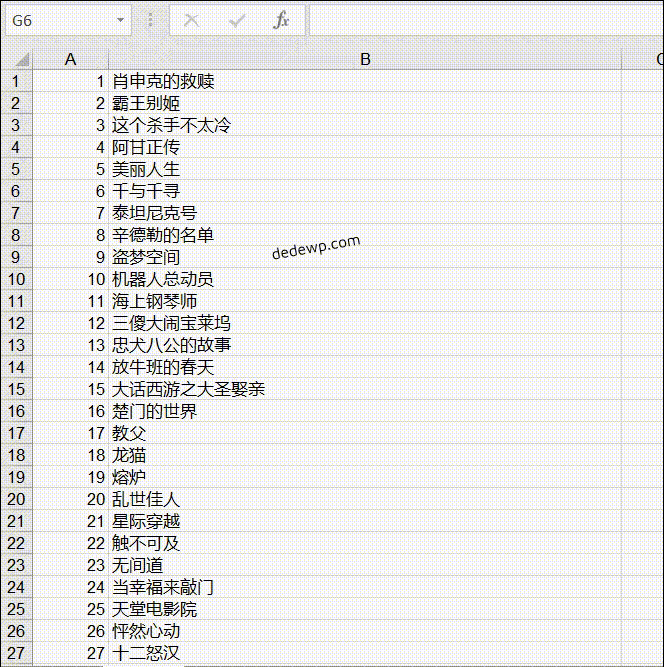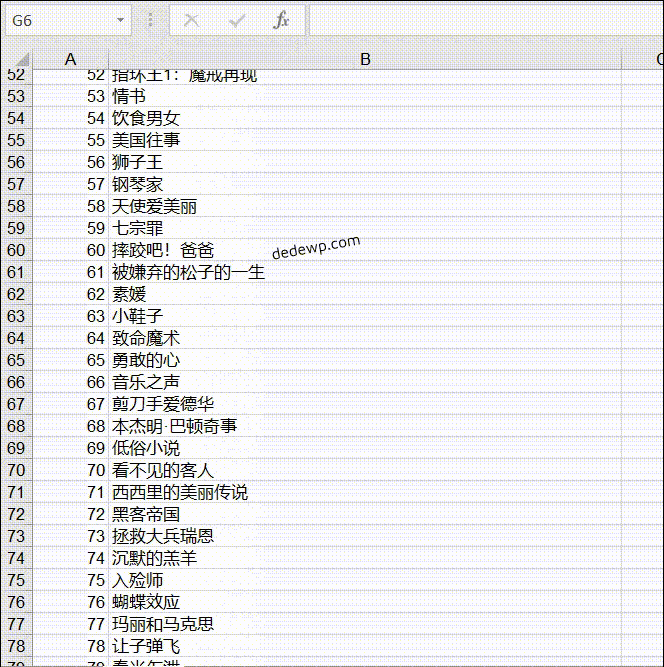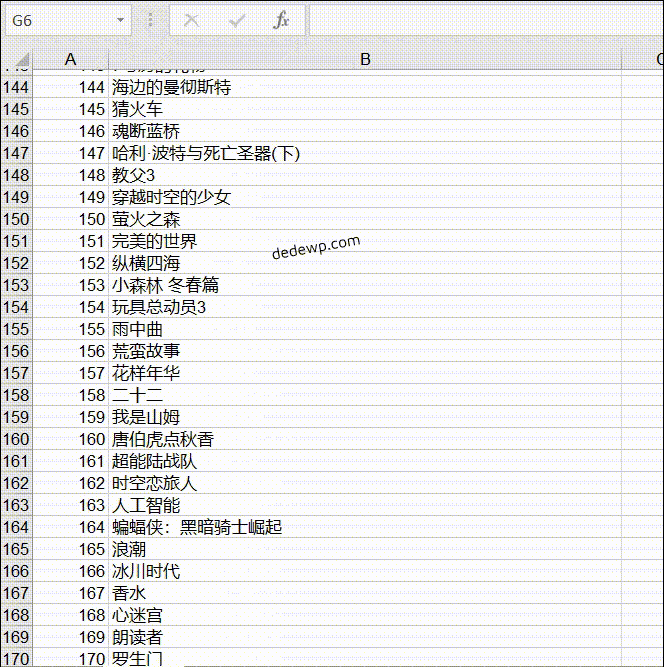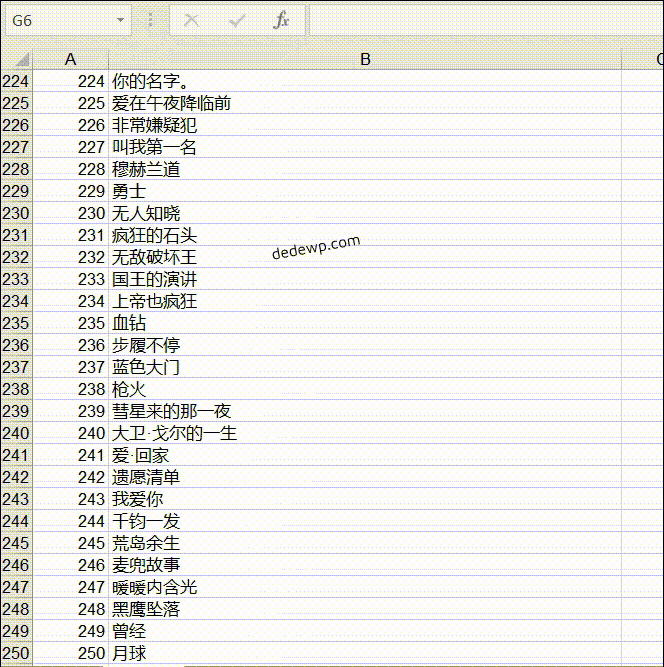
之前有小伙伴问如何将 250 个电影名全部输出来,实际上就是把网址根据规律循环一下就好了,可以参考上面的代码,还有就是列表的合并,这些基础知识在群文件的小白教程里都有介绍。
很多初学 python 的朋友,苦于找不到一群志同道合的朋友,小雨给大家提供了一个平台,一个纯粹学习 python 的交流平台,274728691 这是我的 QQ 号,也是 python 从入门到入魔的群号,欢迎加入。
加入须知:
Python3学习群重要通知,群友必看!
很多人进群后不及时提交作业,不珍惜这个学习的机会,陌小雨就设置一些门槛,特此申明如下(2018-3-14): 很多初学 python 的朋友,苦于找不到一群志同道合的朋友,陌小雨给大家提供了一个平台,一个纯粹学习 python 的交流平台,274728691 这是陌小雨的 QQ 号,也是 python 从入门到入魔的群号(...

python3读取excel数据-Python3将爬取的数据存储到Excel相关推荐
- python爬表格数据_python爬虫,爬取表格数据
python爬虫,爬取表格数据 python爬虫,爬取表格数据 python爬虫,爬取全国空气质量指数 编程环境:Jupyter Notebook 所要爬取的网页数据内容如下图 python爬虫代码及 ...
- python如何爬虫网页数据-python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. ...
- python解析网页数据_python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. ...
- python爬取天气数据山东_Python爬取天气预报数据,并存入到本地EXCEL中-Go语言中文社区...
近期忙里偷闲,搞了几天python爬虫,基本可以实现常规网络数据的爬取,比如糗事百科.豆瓣影评.NBA数据.股票数据.天气预报等的爬取,整体过程其实比较简单,有一些HTML+CSS+DOM树等知识就很 ...
- python存数据到excel_python爬取的数据--保存数据到excel
在这里用到的是xlwt import xlwt 如果还未安装此模块,可以执行下面的命令安装: pip install xlwt 接下来就是将数据列表存储到excel当中: def save_to_ex ...
- python如何爬虫网页数据-如何轻松爬取网页数据?
一.引言 在实际工作中,难免会遇到从网页爬取数据信息的需求,如:从微软官网上爬取最新发布的系统版本.很明显这是个网页爬虫的工作,所谓网页爬虫,就是需要模拟浏览器,向网络服务器发送请求以便将网络资源从网 ...
- ajax实现动态及时刷新表格数据_如何爬取网页数据
网页数据爬取是指从网站上提取特定内容,而不需要请求网站的API接口获取内容."网页数据" 作为网站用户体验的一部分,比如网页上的文字,图像,声音,视频和动画等,都算是网页数据. 对 ...
- python爬取网页汉字_程序小技巧:Python3借助requests类库3行代码爬取网页数据!快来...
爬取网页数据是python很长干的一件事情,不过做起来基本上都是很冗长的一段代码,看起来复杂,不宜理解.今天给大家分享一个小诀窍,利用python3中的requests类库进行爬取网页数据. 我们先看 ...
- 爬虫批量保存网页html,2分钟带你学会网络爬虫:Excel批量爬取网页数据(详细图文版)...
面对网页大量的数据,有时候还要翻页,你还在一页一页地复制粘贴吗?别人需要几小时完成的任务,学会这个小技巧你只需要几分钟就能解决.快来学习使用Excel快速批量地爬取网页数据吧! 1.分析网页数据结构 ...
- python 爬虫爬取疫情数据,爬虫思路和技术你全都有哈(一)
python 爬虫爬取疫情数据,爬虫思路和技术你全都有哈(二.数据清洗及存储) 爬起疫情数据,有两个网址: 1.百度:链接 2.丁香园疫情:链接 在这两个中,丁香园的爬虫相对简单一点,所以今天就展示一 ...
最新文章
- 计算机视觉相关干货文章-20190807
- 18、计算机图形学——BRDF与渲染方程
- Java8中的流操作-基本使用性能测试
- centos6.7一键装机
- Coding Interview Guide -- 数组的partition调整
- 【Qt】QModbusPdu类
- React-引领未来的用户界面开发框架-读书笔记(三)
- Skywalking-09:OAL原理——如何通过动态生成的Class类保存数据
- VirtuoZo数字摄影测量(一)——单模型的建立
- 机器学习 流式特征_Web服务与实时机器学习端点的流式传输
- 计算机主机机箱结构图,带大家认识电脑主机拆开,内部结构
- MAC下切换多个IP的Shell脚本
- python字符串怎么加绝对值_每日一练 | Python绝对值有哪些实例?
- python 生成文字图案_Python|利用字母可以组成一些美丽的图形
- 老款Tplink路由器如何桥接
- scrapy 下载及处理文件和图片
- 秋招复盘 — 不忘初心,砥砺前行
- 2015老男孩Linux中高级运维19期
- 一颗芯片的内部设计原理和结构
- 【CEGUI】概念简介