(转)从CPU架构和技术的演变看GPU未来发展
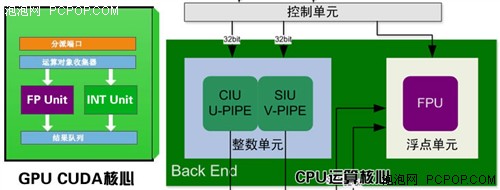
喜欢研究IT硬件技术的朋友应该知道,CPU和GPU都是由整数运算单元、浮点运算单元、一级缓存、二级缓存、内存控制器等等模块组成的,但最终它们的应用领域又是截然不同的。
到底是GPU取代CPU进行并行计算呢?还是CPU整合GPU成为大势所趋?这两种说法显然是相互对立的,均有不少支持者。但这只是表像,真正产生这一现状的原因依然隐藏在CPU和GPU的架构之中,通过笔者后文中的分析您会发现这两种说法不但不矛盾,反而代表了Intel、AMD和NVIDIA三大巨头已经达成的共识,他们正在以各自不同的方式去实现相同的目标。
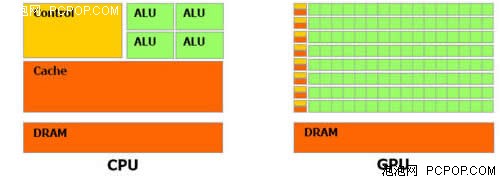
CPU和GPU的整体结构相似,但侧重点不同
事实上,CPU和GPU都保持着一套相对固定的趋势,按照各自的轨迹在不停的发展、演变,两者在技术和架构方面有着很多不谋而合的共同点,而且最终也因为相同的目的而走到了一起。那么,CPU和GPU的碰撞将会亮出什么样的火花,未来的发展方向会朝向何处呢?下面我们就通过CPU和GPU的发展史来推测未来产品应该具备什么样的特征。
CPU篇:整合浮点运算协处理器
首先我们来重拾一个几乎快要被遗忘的名词——协处理器,它是一种芯片,用于减轻系统微处理器的特定处理任务,早些年协处理器主要是用以辅助进行浮点运算。
★ 最初的CPU只能进行整点运算,浮点运算效率极低
CPU最基本的运算就是“加减乘除”,但实际上计算机只能用加法器来完成整数以及固定小数点位置(整点)的算术运算,而不能处理小数点可以浮动的数值(浮点)。对于小数多采用的是二进制的科学计数法、也就是浮点数表示法:尾数、阶数符号位各占一位,然后再对其余数位尾数、阶数的有效数位合理分配。
在CPU运算时,浮点数的运算量远比整数复杂,因为不仅尾数要参与运算,阶数也要参与,并且需要对尾数和阶数的符号位都进行处理,所以,最早的CPU并没有能力进行浮点运算(8088/8086,80286,80386SX),需要浮点运算时,由CPU通过软件模拟来实现,所以,进行浮点运算时就会慢很多。
★ 协处理器诞生,专门处理浮点运算

8086处理器和它的协处理器8087
8086是当今CPU的鼻祖,所谓X86架构也就是指8086处理器所开创的指令集体系。为了弥补8086在进行浮点运算时的不足,Intel与1980年设计了8087数学协处理器,并且为X86体系推出了第一个浮点格式IEE754。8087提供两个基本的32/64bit浮点资料形态和额外的扩展80bit内部支援来改进复杂运算之精度。除此之外,8087还提供一个80/17bit封装BCD (二进制编码之十进制)格式以及16/32/64bit整数资料形态。

386处理器和它的协处理器387
X87协处理器新增约60个指令给程序员,所有的指令都是以“F”开头跟其他的标准8086整数运算指令有所区别,举例来说,相对于ADD/MUL,8087提供FADD/FMUL。
8087是于1980年发布,然后被80287、80387DX/SX和487SX所取代。
★ 协处理器被整合进入CPU内部
以往,协处理器都是可选配件,在主板上X86处理器旁边一般都会为X87设计一个空的插槽,只有当用户确实有需要时才会专门购买相应的X87协处理器插进去,来加速浮点运算。

486DX是第一颗整合了浮点运算协处理器的产品,相当于486SX+487SX
随着时代的发展,越来越多的程序要求使用更高精度的浮点运算,X87协处理器几乎成为必备品。于是在制造工艺日趋成熟之后,Intel在486一代将X86和X87整合在了一起,浮点运算成为了CPU的一项基本功能,而且重要性越来越大。
Intel 486DX、Pentium之后的CPU都内含了协处理器,AMD K5、K6之后的CPU都内建了协处理器,所以此后就很少有人会提及协处理器的概念了。
CPU篇:扩展指令集加速浮点运算
所谓X86架构的处理器就是采用了Intel X86指令集的处理器,X86指令集是Intel公司为其第一块16位处理器i8086所专门开发的。而IBM在1981年所推出的第一台PC机上所使用的处理器i8088(i8086的简化版)也是使用的X86指令集,但是为了增强计算机的浮点运算能力,增加了X87数学协助处理器并引入了X87指令集,于是就将采用了X86指令集和X87指令集的处理器统称为X86架构的处理器。
X86基本指令集包括了:数据传输、算术运算、逻辑运算、串指令、程序转移、伪指令、寄存器、位操作、控制指令和浮点运算指令等十大类无数条。而Intel和AMD桌面级处理器在X86指令集的基础上,为了提升处理器各方面的性能,所以又各自开发新的指令集,它们被称为处理器扩展指令集。
扩展指令集能够大幅提高CPU在某些特定应用下的性能,如多媒体、3D、浮点运算等,其设计初衷与协处理器是异曲同工的,但协处理器需要增加额外的运算单元,而扩展指令集只需要加入新的指令和算法即可,无需设计新的运算单元,但必须要软件支持才能发挥功效。
★ MMX指令集:增强多媒体性能
MMX(Multi Media eXtension 多媒体扩展指令)指令集是Intel公司在1996年为旗下的Pentium系列处理器所开发的一项多媒体指令增强技术。MMX指令集中包括了57条多媒体指令,通过这些指令可以一次性处理多个数据,在处理结果超过实际处理能力的时候仍能够进行正常处理,如果在软件的配合下,可以得到更强的处理性能。
MMX指令集非常成功,在之后生产的各型CPU都包括这些指令集。据当年Tom's Hardware测试,即使最慢的Pentium MMX 166MHz也比Pentium 200MHz普通版要快。

Intel Pentium With MMX,首次支持MMX
但是,MMX指令集的问题也是比较明显的,MMX指令集不能与X86的浮点运算指令同时执行,必须做密集式的交错切换才可以正常执行,但是这样一来,就会造成整个系统运行速度的下降。
★ 3DNow!指令集:
3DNow!指令集最由AMD公司所推出的,该指令集应该是在SSE指令之前推出的,被广泛运用于AMD的K6-2和K7系列处理器上,拥有21条扩展指令集。在整体上3DNow!的SSE非常相相似,它们都拥有8个新的寄存器,但是3DNow!是64位的,而SSE是128位。

AMD K62加入3DNow!指令集
所以3DNow!它只能存储两个浮点数据,而不是四个。但是它和SSE的侧重点有所不同,3DNow!指令集主要针对三维建模、坐标变换和效果渲染等3D数据的处理,在相应的软件配合下,可以大幅度提高处理器的3D处理性能。AMD公司后来又在Athlon系列处理器上开发了新的Enhanced 3DNow!指令集,新的增强指令数达了52个,以致目前最为流行的Athlon 64系列处理器还是支持3DNow!指令的。
★ SSE指令集:加强浮点和3D性能
SSE是Streaming SIMD Extension(SIMD扩展指令集)的缩写,而其中SIMD的为含意为Single Istruction Multiple Data(单指令多数据),所以SSE指令集也叫单指令多数据流扩展。该指令集最先运用于Intel的Pentium III系列处理器,其实在Pentium III推出之前,Intel方面就已经泄漏过关于KNI(Katmai New Instruction)指令集的消息。这个KNI指令集也就是SSE指令集的前身,当时也有不少的媒体将该指令集称之为MMX2指令集,但是Intel方面却从没有发布有关MMX2指令集的消息。

奔腾3正式加入SSE指令集
最后在Intel推出Pentium III处理器的时候,SSE指令集也终于水落石出。SSE指令集是为提高处理器浮点性能而开发的扩展指令集,它共有70条指令,其中包含提高3D图形运算效率的50条SIMD浮点运算指令、12条MMX整数运算增强指令、8条优化内存中的连续数据块传输指令。理论上这些指令对当时流行的图像处理、浮点运算、3D运算、多媒体处理等众多多媒体的应用能力起到全面提升的作用。SSE指令与AMD公司的3DNow!指令彼此互不兼容,但SSE包含了3DNow!中的绝大部分功能,只是实现的方法不同而已。SSE也向下兼容MMX指令,它可以通过SIMD和单时钟周期并行处理多个浮点数据来有效地提高浮点运算速度。
★ SSE2指令集:进一步优化浮点运算
在Pentium III发布的时候,SSE指令集就已经集成在了处理器的内部,但因为各种原因一直没有得到充分的发展。直到Pentium 4发布之后,开发人员看到使用SSE指令之后,程序执行性能将得到极大的提升,于是Intel又在SSE的基础上推出了更先进的SSE2指令集。

奔腾4初代就加入了SSE2指令集(AMD直到Athlon64才加入SSE2)
SSE2包含了144条指令,由两个部分组:SSE部分和MMX部分。SSE部分主要负责处理浮点数,而MMX部分则专门计算整数。SSE2的寄存器容量是MMX寄存器的两倍,寄存器存储数据也增加了两倍。在指令处理速度保持不变的情况下,通过SSE2优化后的程序和软件运行速度也能够提高两倍。由于SSE2指令集与MMX指令集相兼容,因此被MMX优化过的程序很容易被SSE2再进行更深层次的优化,达到更好的运行效果。
SSE2对于处理器的性能的提升是十分明显的,虽然在同频率的情况下,Pentium 4和性能不如Athlon XP,但由于Athlon XP不支持SSE2,所以经过SSE2优化后的程序Pentium 4的运行速度要明显高于Athlon XP。而AMD方面也注意到了这一情况,在随后的K-8系列处理器中,都加入SSE2指令集。
★ SSE3指令集:加强并行数据处理能力
SSE3指令是目前规模最小的指令集,它只有13条指令。它共划分为五个应运层,分别为数据传输命令、数据处理命令、特殊处理命令、优化命令、超线程性能增强五个部分,其中超线程性能增强是一种全新的指令集,它可以提升处理器的超线程的处理能力,大大简化了超线程的数据处理过程,使处理器能够更加快速的进行并行数据处理。

SSE3中13个新指令的主要目的是改进线程同步和特定应用程序领域,例如媒体和游戏。这些新增指令强化了处理器在浮点转换至整数、复杂算法、视频编码、SIMD浮点寄存器操作以及线程同步等五个方面的表现,最终达到提升多媒体和游戏性能的目的。
Intel是从Prescott核心的Pentium 4开始支持SSE3指令集的,而AMD则是从2005年下半年Troy核心的Opteron开始才支持SSE3的。但是需要注意的是,AMD所支持的SSE3与Intel的SSE3并不完全相同,主要是删除了针对Intel超线程技术优化的部分指令。
★ SSSE3(SSE3S)指令集:加强多媒体图形图像处理
SSSE3(Supplemental Streaming SIMD Extensions 3)是Intel命名的SSE3指令集的扩充,不使用新的号码是因为SSSE3比较像是加强版的SSE3,以至于推出SSSE3之前,SSE4的定义容易被混淆。在公开Intel的Core微架构之时,SSSE3出现在Xeon 5100与Intel Core 2移动版与桌面型处理器上。

65nm Core 2 Duo引入SSSE3指令集
SSSE3包含了16个新的不同于SSE3的指令。每一个都能够运作于64位的MMX寄存器或是128位XMM寄存器之中。因此,有些Intel的文件表示有32个新指令。SSSE3指令集增强了CPU的多媒体、图形图象处理、多媒体编码、整数运算和Internet等方面的处理能力。
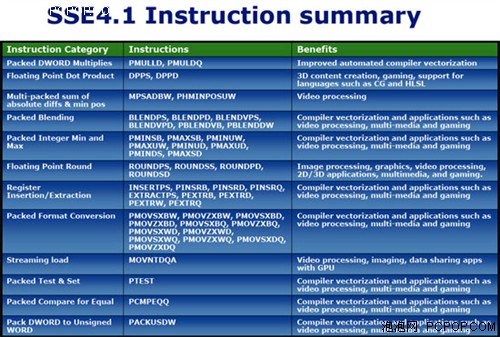
★ SSE4.1指令集:大幅提升浮点运算,优化CPU和GPU数据共享
SSE4.1指令集被认为是2001年以来Intel最重要的指令集扩展,包含54条指令。Intel在Penryn处理器中加入了对SSE4.1的支持,共增加了47条新指令,令处理器的多媒体处理能力得到最大70%的提升。SSE4加入了6条浮点型点积运算指令,支持单精度、双精度浮点运算及浮点产生操作,且IEEE 754指令 (Nearest, -Inf, +Inf, and Truncate) 可立即转换其路径模式,大大减少延误,这些改变将对游戏及3D内容制作应用有重要意义。
此外,SSE4加入串流式负载指令,可提高以图形帧缓冲区的读取数据频宽,理论上可获取完整的快取缓存行,即每次读取64Bit而非8Bit,并可保持在临时缓冲区内,让指令最多可带来8倍的读取频宽效能提升,对于视讯处理、成像以及GPU与CPU之间的共享数据应用,有着明显的效能提升。
45nm Core 2 Duo引入SSE4.1指令集
SSE4指令集让45nm Penryn处理器增加了2个不同的32Bit向量整数乘法运算单元,并加入8位无符号(Unsigned)最小值及最大值运算,以及16Bit及32Bit有符号 (Signed) 运算。在面对支持SSE4指令集的软件时,可以有效的改善编译器效率及提高向量化整数及单精度代码的运算能力。同时,SSE4改良插入、提取、寻找、离散、跨步负载及存储等动作,令向量运算进一步专门。
★ SSE4.2指令集:优化XML和交互式应用性能
在Nehalem架构的Core i7处理器中,SSE4.2指令集被引入,加入了STTNI(字符串文本新指令)和ATA(面向应用的加速器)两大优化指令。STTNI包含了四条具体的指令。STTNI指令可以对两个16位的数据进行匹配操作,以加速在XML分析方面的性能。Intel表示,新指令可以在XML分析方面取得3.8倍的性能提升。
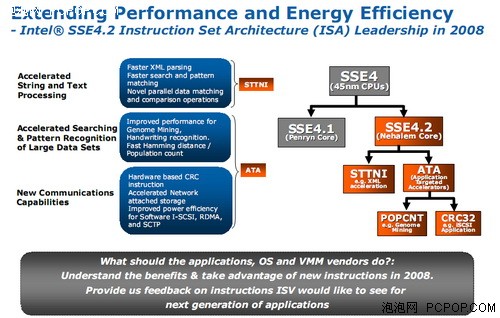
ATA包括冗余校验的CRC32指令、计算源操作数中非0位个数的POPCNT指令,以及对于打包的64位算术运算的SIMD指令。CRC32指令可以取代上层数据协议中经常用到的循环冗余校验,Intel表示其加速比可以达到6.5~18.6倍;POPCNT用于提高在DNA基因配对、声音识别等包含大数据集中进行模式识别和搜索等操作的应用程序性能。
CPU篇:整合片上二级缓存
缓存的基本作用是用来加速数据的传输。在电脑当中,由于内存和硬盘本身的速度较慢,都需要一个可以加速指令执行和数据预取的缓冲区,这个零时缓存就相当于部队里的集结待命区,它里边的内容是不断的在变化的。
http://www.yourdictionary.com/images/computer/SWFCACH2.SWF
缓存的作用和原理
一级缓存(L1)是内置在CPU芯片内部的一个存储区。二级缓存(L2)是第2块“集结待命区”(Staging Areas),它的用处就是给L1喂数据。L2可能内置于CPU之中,也可能是MCP(Multichip Package Module)里的一个独立芯片中,还可能是在主板上的一块独立存储芯片里。
典型的,缓存一般是SRAM(Static RAM,静止随机存储器,不需要刷新电路即能保存它内部存储的数据),而主内存通常是DRAM(Dynamic RAM,动态随机存储器,需要刷新电路)。SRAM非常消耗晶体管、成本高昂而且容量不可能做很大,因此最早的CPU都是没有缓存的,后来才开始加入缓存芯片。
★ 插在主板上的二级缓存(或者整合在主板上)

Intel 430FX芯片組上Socket 5主板及256KB外置二级缓存
此前的CPU一直都是Socket接口设计,但以当时的技术,直插式的设计无法在CPU上整合SRAM缓存芯片,只能将SRAM以扩展卡的形式插在主板上或者直接整合在主板上。此后数代产品,Intel和AMD改用了Slot封装形式,将SRAM芯片和CPU核心都集成在了Slot PCB上面,然后再插在主板上,这样SRAM二级缓存就正式成为了CPU不可缺少的一部分。
★ 整合在CPU上的二级缓存

这是一颗核心代号为代Klamath、采用350nm工艺的Pentium处理器,CPU+SRAM的结构,Slot 1接口。看上去是不是有点像现在的GPU+DRAM显存。实际上这样做只是上CPU和SRAM绑定在了一起,二级缓存依然以核心频率一半甚至更低的速度运行,性能不甚理想。
★ “胶水”式的二级缓存

Pentium Pro是Intel P5 核心Pentium的延伸,在1995年11月以Socket 8封装形式推出,它最大的特色是采用了双芯片封装形式,CPU和L2是各自独立的,片上(Onchip)L2的好处是可以让它以内核相同的频率运行,而不必再像过去使用主板上较慢速度的L2,从而为“乱序执行”所导致的大量内存超找提供了捷径,直接提升了性能。
Pentium Pro把L1和L2同时设计在CPU的内部,故Pentium Pro的体积较大。结果Pentium II又把L2 Cache移至CPU内核之外的黑盒子里。这是因为L2无法达到与核心相同的频率,因此还是分离式比较灵活一点。
★ 整合进CPU内部的二级缓存
Pentium Pro不仅是第一款整合了二级缓存的CPU,而且是第一颗32bit CPU,不过由于它并不兼容当时主流的16bit软件,因此Pentium Pro曲高和寡,仅定位于高端服务器市场,并没有得到广泛认可。此后Intel又发布了Pentium II XEON,同样集成了片上全速二级缓存,在当时全速二级缓存就代表着更高的性能。
Pentium Pro和Pentium II XEON并非民用产品,因此关注度并不高,而Pentium II去掉板载SRAM的产品被首次当作Celeron来卖,虽然它价格很低廉,但由于L2彻底为0,因此性能损失也非常惨重。为此,Intel推出了第二代Celeron 300A和Celeron 333,新赛扬的特点是在处理器芯片内集成了128KB二级高速缓存,容量上虽然比Pentium II的512KB少很多,但新赛扬的二级缓存在CPU内部,是全速的片上缓存,而Pentium的二级缓存频率只有核心的一半。正是这全速的二级缓存给与了Celeron质的改变,极大的改善了赛扬的整体性能,成为当时市场上炙手可热的一代经典产品!
首次出现三级缓存
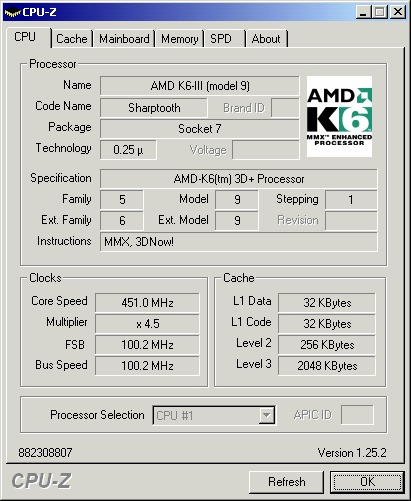
而当时的AMD也有一款经典产品,同样是因为集成了全速二级缓存而让性能产生质的飞跃,性能遥遥领先与同代Intel处理器,它就是K6-II和K6-III。
K6-II和K6-III使用的是Socket 7插槽,其性能比Intel后来的Pentium 3都要强,为什么?因为这K6-III CPU均内建了256KB的二级缓存,而且配套主板上还能再插2M容量的SRAM当作三级缓存使用,此时的性能比Pentium II拉开了较大的差距,而且其价格还比较实惠。
★ 奔三和速龙初期依然用外置二级缓存,后期全部整合全速缓存
提起奔三和速龙相信很多人就比较熟悉了,它们应该可以说是CPU的近代现代史了,不过奔三和速龙发布之初依然使用的Slot卡槽式封装,二级缓存依然是外置式,运行频率只有核心速度的一半,性能受到了限制。


初期Slot 1和Slot A接口的Pentium III和Athlon
制造工艺改进之后,Intel和AMD相继把L2整合在了CPU内部,成为单一的CPU核心,以大家喜闻乐见的Socket封装形式出现,全速的L2让奔三和速龙的性能都有所提升:


Socket 370和Socket A接口的Pentium III和Athlon
Pentium III和Athlon角逐1GHz大关的频率大战,最终Intel因为Pentium III 1.13GHz BUG问题而败北。而其问题的关键就是内置的二级缓存无法工作在1GHz以上的超高频率下,从而产生不可预料的错误。
CPU篇:整合内存控制器和北桥
CPU二级缓存之所以对CPU性能影响重大,就是因为内存的延迟较大、带宽太小,满足不了CPU密集型数据交换的需要,需要高速运作中转站二级缓存的支持。在二级缓存被CPU整合之后,大容量的内存显然是无法被整合到CPU里面的,那么如何才能进一步优化内存性能呢?
以往,CPU与内存之间的通信是通过北桥和进行的,准确的说是北桥当中的内存控制器,它决定了系统能支持内存的容量、频率和延迟。为了尽可能的缩小CPU访问内存的时间,显然CPU整合内存控制器是最高效的方法。
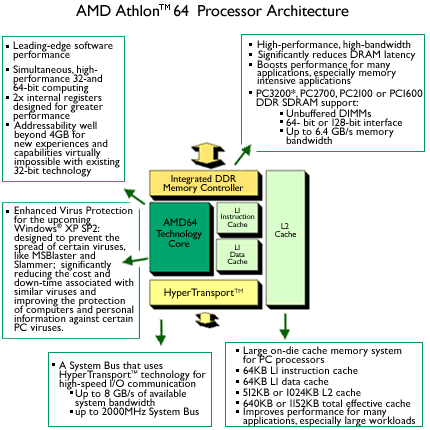
AMD率先将内存控制器整合在了CPU当中,Athlon 64这款划时代的产品成为了一代经典,当然其成功的原因不仅仅是因为整合了内存控制器,它还是第一颗64bit X86处理器,第一次使用了点对点的高速低延迟HT总线。AMD这次一领先就是五年,Intel直到Core i7时代才整合了内存控制器。
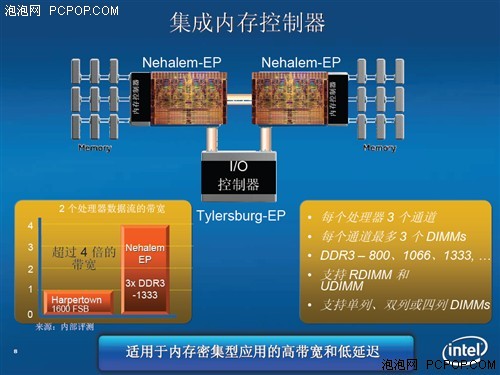
AMD当年为Athlon 64处理器整合了单通道DDR和双通道DDR两种内存控制器,分别对应754和939接口,此后逐步升级至双通道DDR2和DDR3内存控制器。而Intel是后来者居上,直接整合了三通道DDR3内存控制器,中低端产品也整合了双通道DDR3内存控制器,分别对应1366和1156接口。消除了内存瓶颈之后的Core i3/i5/i7处理器性能更上一层楼,大幅领先于同级AMD产品。
CPU篇:共享式大容量二/三级缓存
高频低能的Pentium 4和Pentium D苦苦抵抗Athlon 64和Athlon 64 X2疯狂进攻的同时,Intel也在秘密研发新一代Core微处理器架构,全新的Core 2 Duo虽然没有整合内存控制器,但凭借高效率、低层级流水线和融合大量先进技术的指令架构,Core 2 Duo一举击败Athlon 64 X2成为新的性能之王。
当然,Intel还有另外一项创新性的技术也助Core 2 Duo一臂之力,拉大与对手的优势,它就是Intel Advanced Smart Cache(高级智能缓存技术),简单来讲就是多颗处理器核心共享大容量缓存,通常被称为共享式大容量二级缓存。
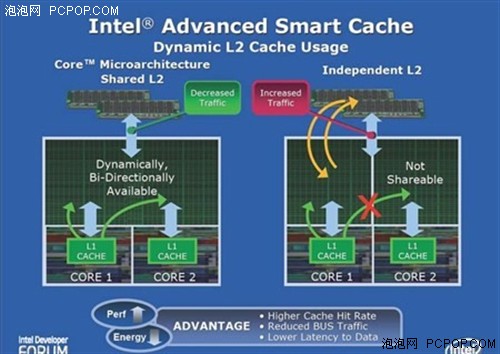
传统的双核心设计每个独立的核心都有自己的L2,但Intel Core微架构则是通过核心内部的Shared Bus Router共用相同的L2,当CPU 1运算完毕后把结果存在L2时,CPU 0便可通过Shared Bus Router读取CPU 1放在共用L2上资料,大幅减低读取上的延迟并减少使用FSB带宽,同时加入L2 & DCU Data Pre-fetchers及Deeper Write output缓冲存储器,大幅增加了缓存的命中率。
与AMD K8双核心L2架构相比,CPU 0需要读取CPU 2 L2中数据时,首先需要向系统总线发出需求,并通过Crossbar Switch就把取读资料,但CPU 0发现读取自己的L2没有所要的数据才会要求读取CPU 1的L2资料,情况等同于CPU 0的L3,而共享式的L2设计却没有以上需要。
Smart Cache架构还有很多不同的好处,例如当两颗核心工作量不平均时,如果独立L2的双核心架构有机会出现其中一颗核心工作量过少,L2没有被有效地应用,但另一颗核心的L2却因工作量过重,L2容量没法应付而需要传取系统内存,值得注意的是它并无法借用另一颗核心的L2空间,但SmartCache因L2是共用的而没有这个问题。
共享式L2不但能够减少两颗核心之间读取缓存数据的延迟、提高数据命中率,而且还能有效提高缓存利用率,避免分离式缓存存放重复数据的可能,变相提高的缓存容量。Intel上代的Core 2 Duo和Core 2 Quad至今在性能方面并不输给AMD的Phenom II系列处理器,其中共享式二级缓存设计功不可没。
★ 共享式三级缓存已成为主流:
共享式二级缓存固然拥有诸多优势,但需要对传统CPU架构进行大幅调整,双核心还算容易、多核心就比较麻烦了,缓存的存取机制都需要完全重新设计。因此AMD另辟蹊径,在保持现有二级缓存不变的情况下,直接新增大容量的三级缓存,从而为多核提供协同运算的高速暂存数据仓库。

AMD初代的Phenom四核处理器就采用了共享式三级缓存设计,每颗核心的一级缓存保持不变,二级缓存都是独立的512KB,三级缓存为一体式的2MB。而到了Phenom II代,45nm工艺使得处理器能够整合更大容量的缓存,于是L3倍增至6MB,性能提升非常明显。
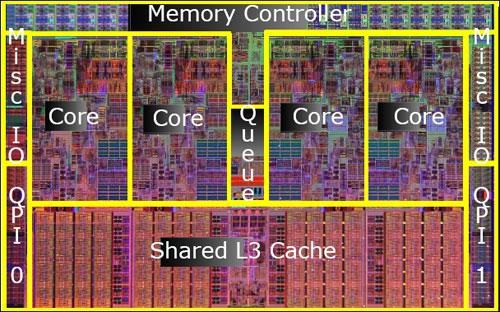
Core i7 Die示意图
Intel在Core 2 Quad之后,也在酝酿全新的原生四核产品,此次Intel集所有先进技术于一体,不仅整合了内存控制器,而且引入了比AMD HT更先进的QPI总线,还引入了共享式三级缓存,容量高达8MB,比Phenom II还多2MB。
至于低端的双核Core i3/i5处理器,Intel为了保持架构统一,也放弃了Core 2上面的共享二级缓存设计,每颗核心仅有256KB的独立L2,而是植入了4M容量的L3,虽然总缓存容量不如E8X00系列的6MB L2,但性能上还是取得了长足的进步。
此后,32nm工艺的引入使得Intel可以在单一芯片之中集成更多的核心和更大的缓存,所以我们看到i7-980X拥有六颗物理核心以及高达12MB的L3,性能更上一层楼,令人叹为观止!
GPU篇:整合VCD/DVD/HD/BD解压卡
在了解了CPU的发展历程之后,我们再来看看GPU的发展过程,其实GPU很多重大改进都与CPU的技术架构相类似。比如最开始我们介绍了古老的CPU协处理器,下面再介绍一个被遗忘的产品——解压卡,资历较老的玩家应该记得。
十多年前,电脑的CPU主频很低,显卡也多为2D显示用,当VCD兴起的时候,好多电脑(主频为100MHz以下)无法以软解压的方式看VCD影片,根本运行不起来!

ISA接口的VCD解压卡
这时,VCD解压卡就出现了,此卡板载专用的解码处理器和缓存,实现对VCD的硬解码,不需要CPU进行解码运算,所以,即使在386的电脑上也可以看VCD了。

PCI接口的DVD解压卡
随后,显卡进入了3D时代,并纷纷加入支持VCD的MPEG解码,而且CPU的主频也上来了,无论CPU软解还是显卡辅助解码都可以流畅播放视频,所以VCD解压卡就退出了市场!
但DVD时代来临后,分辨率提高很多,而且编码升级至MPEG2,对于CPU和显卡的解码能力提出了新的要求,此时出现了一些DVD解压卡,供老机器升级之用,但由于CPU更新换代更加频繁,性能提升很大,DVD解压卡也是昙花一现,就消失无踪了。

现在已经是1080p全高清时代了,高清视频解码依然是非常消耗CPU资源的应用之一,于是几年前NVIDIA和ATI就在GPU当中整合了专用的视频解码模块,NVIDIA将其称为VP(Video Processor,视频处理器),ATI将其称为UVD(Unified Video Decoder,通用视频解码器),相应的技术被叫做PureVideo和AVIVO。

硬解码几乎不消耗CPU和GPU的资源,看高清视频时接近于待机状态
虽然VP和UVD都被整合在了GPU内部,实际上它们的原理和作用与当年的协处理器/解压卡芯片没有实质性区别,都是为了减轻/分担处理器的某项特定任务。如今NVIDIA和ATI的GPU硬解码技术都能够支持高分辨率、高码率、多部影片同时播放,性能和兼容性都很出色。
如今多核CPU的性能已经相当强大了,软解高清视频简直轻松加愉快,但要论效率的话,依然是GPU硬件解码更胜一筹,专用模块解码消耗资源更少,整机功耗发热更小,因此手持设备和移动设备都使用硬件解码,而桌面电脑CPU软解和GPU硬解就无所谓了。
GPU篇:ShaderModel指令集的扩充与发展
掐指一算,从GPU诞生至今双方都已推出了十代产品,每一代产品之间的对决都令无数玩家心动不已,而其中最精彩的战役往往在微软DirectX API版本更新时出现,几乎可以说是微软DirectX左右着GPU的发展,而历代DirectX版本更新时的核心内容,恰恰包含在了ShaderModel当中:

ShaderModel 1.0 → DirectX 8.0
ShaderModel 2.0 → DirectX 9.0b
ShaderModel 3.0 → DirectX 9.0c
ShaderModel 4.0 → DirectX 10
ShaderModel 5.0 → DirectX 11
Shader(译为渲染或着色)是一段能够针对3D对象进行操作、并被GPU所执行的程序,ShaderModel的含义就是“优化渲染引擎模式”,我们可以把它理解成是GPU的渲染指令集。
高版本的ShaderModel是一个包括了所有低版本特性的超集,对一些指令集加以扩充改进的同时,还加入了一些新的技术。可以说,GPU的ShaderModel指令集与CPU的MMX、SSE等扩展指令集十分相似。
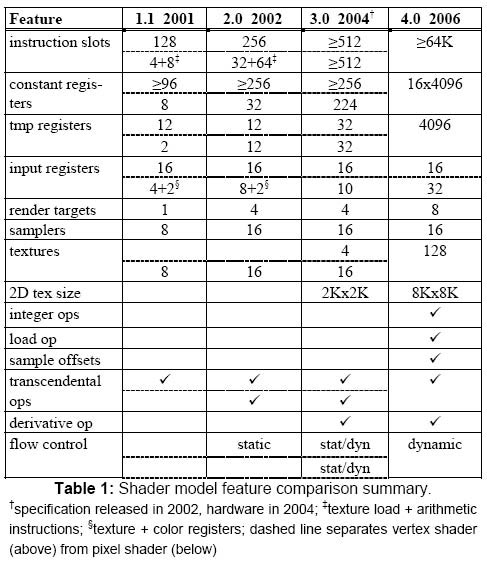
随着ShaderModel指令集的扩充与改进,GPU的处理资源和计算精度与日俱增,于是就有能力渲染出更加精美的图像,并且不至于造成性能的大幅下降。就拿最近几个版本来讲,新指令集并没有带来太多新的特效,但却凭借优秀的算法提升了性能,是否支持DX10.1(ShaderModel 4.1)可能游戏画面上没有差别,但速度就很明显了。
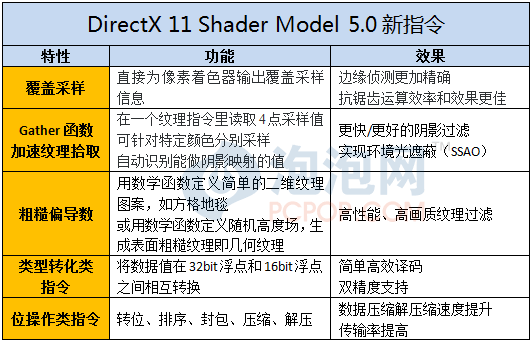
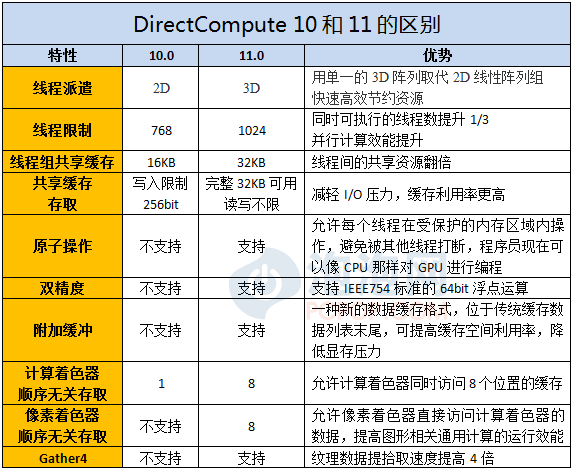
此外,DX11中的关键技术DirectCompute通用计算技术就是通过调用ShaderModel 5.0中的新指令集来提高GPU的运算效率,很多基于DirectCompute技术的图形后处理渲染特效也都要用到SM5.0指令集来提高性能。
GPU篇:真正的双核/四核GPU
从以往的多处理器系统到现在的双核、四核、六核,CPU只能依靠增加核心数量来提升性能。而GPU从一开始就是作为并行渲染的管线式架构,GPU性能的强弱主要就是看谁的管线、流处理器数量更多。
不过双显卡甚至多显卡也成为提升电脑游戏性能的一种途径,通过SLI和CrossFire技术能够轻松让3D性能倍增,于是双核心的显卡成为NVIDIA和AMD双方角逐3D性能王者宝座的杀手锏,近年来的旗舰级显卡几乎都是双核心设计的。
但与CPU单芯片整合多核心的设计不同,显卡一般是单卡多GPU设计,很少有单一GPU多核心设计,因为GPU性能提升的瓶颈主要在于制造工艺,只要工艺跟得上,那么他们就有能力在GPU内部植入尽可能多的流处理器。
★ 双核心设计的Cypress核心:
不管GPU架构改不改,流处理器数量总是要扩充的,准确的说是以级数规模增长,这样才能大幅提升理论性能。在流处理器数量急剧膨胀之后,如何管理好如此庞大的规模、并与其它模块协调工作成为新的难题。

RV870的双核心模块设计
ATI RV870包括流处理器在内的所有核心规格都比RV770翻了一倍,ATI选择了“双核心”设计,几乎是并排放置两颗RV770核心,另外在装配引擎内部设计有两个Rasterizer(光栅器)和Hierarchial-Z(多级Z缓冲模块),以满足双倍核心规格的胃口。
★ 四核心设计的GF100核心:

GF100可以看作是四核心设计
如果说Cypress是双核心设计的话,那么GF100的流处理器部分就是“四核心”设计,因为GF100拥有四个GPC(图形处理器集群)模块,每个GPC内部包含一个独立的Raster Engine(光栅化引擎),而在以往都是整颗GPU共享一个Raster Engine。
我们知道RV870的Rasterizer和Hierarchial-Z双份的,而GF100则是四份的,虽然命名有所不同但功能是相同的。

GF100的每个GPC都可以看作是一个自给自足的GPU
GF100的四个GPC是完全相同的,每个GPC内部囊括了所有主要的图形处理单元。它代表了顶点、几何、光栅、纹理以及像素处理资源的均衡集合。除了ROP功能以外,GPC可以被看作是一个自给自足的GPU,所以说GF100就是一颗四核心的GPU。
★ 为什么GPU也会设计成多核心?
GPU本身就是一颗并行处理器,每一个流处理器都是一个独立的运算单元,ATI和NVIDIA双方第一次将GPU设计成为多核心方案,并不是为了提升其运算能力和流处理器资源,而是为了更好的管理和控制庞大规模的流处理器,更充分的利用它们的处理能力,以便在不同的应用环境下发挥出最强效能。
虽说流处理器数量决定着GPU的浮点运算能力,但GPU除了单纯的数学运算外,还要处理诸多不同类型的任务,将庞大的流处理器划分为多个独立的区块,每个区块都设计专用的控制引擎和特殊功能模块,这将会有效的平衡各个功能模块的资源利用率。
GPU篇:动态分配式一级共享缓存
GPU内部拥有很多种类型的缓存,不同的缓存都有各自特殊的用途,往往无法互相兼容,这完全不同与CPU内部L1、L2、L3这样简单的层级关系。
★ Cypress的一级缓存:固定功能、固定容量的专用缓存
AMD的Cypress核心内部的流处理器是按照SIMD(单指令多数据流)划分的,每组SIMD阵列内部包括了80个流处理器,这些流处理器拥有独立的纹理单元和一级缓存(L1)以及本地数据共享缓存(Local Data Share)。

为了满足DX11中DirectCompute 11的要求,AMD增加了本地数据共享缓存的大小(Local Data Share,LDS),容量达到了32KB,是RV770的两倍。LDS用于同一个线程组(Thread Group)中的线程共享数据。从上图中我们可以看到,每一个SIMD连接一个LDS,不同的SIMD是不能共享LDS的,因此所有属于同一个线程组的线程都会被线程调度器发送到同一个SIMD上执行。
如果不同的SIMD上的线程要共享数据,需要用到全局数据共享缓存(Global Data Share,GDS)。在Cypress中,GDS的容量也倍增了,达到64KB。到目前为止,我们对GDS的了解仍然有限,与LDS不同,并没有指令能显式的操作GDS。据Beyond3D的消息,在未来的OpenCL扩展中可能会提供对GDS的访问,目前GDS只对编译器可见。
★ GF100的一级缓存:可动态分配容量的多功能智能缓存
以往的GPU都是没有一级缓存的,只有一级纹理缓存,因为这些缓存无法在通用计算中用于存储计算数据,只能用于在纹理采样时暂存纹理。而在GF100当中,NVIDIA首次引入真正的一级高速缓存,而且还可被动态的划分为共享缓存。
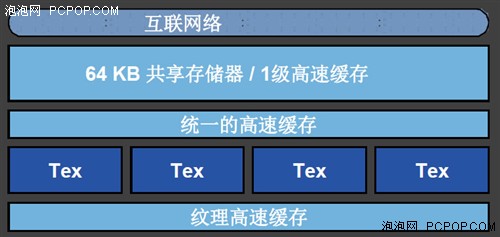
在GF100 GPU中,每个SM除了拥有专用的纹理缓存外,还拥有64KB容量的片上缓存,这部分缓存可配置为16KB的一级缓存+48KB共享缓存,或者是48KB一级缓存+16KB共享缓存。这种划分方式完全是动态执行的,一个时钟周期之后可自动根据任务需要即时切换而不需要程序主动干预。
一级缓存与共享缓存是互补的,共享缓存能够为明确界定存取数据的算法提升存取速度,而一级缓存则能够为一些不规则的算法提升存储器存取速度。在这些不规则算法中,事先并不知道数据地址。
对于图形渲染来说,重复或者固定的数据比较多,因此一般是划分48KB为共享缓存,当然剩下的16KB一级缓存也不是完全没用,它可以充当寄存器溢出的缓冲区,让寄存器能够实现不俗的性能提升。
而在并行计算之中,一级缓存与共享缓存同样重要,它们可以让同一个线程块中的线程能够互相协作,从而促进了片上数据广泛的重复利用并减少了片外的通信量。共享存储器是使许多高性能CUDA应用程序成为可能的重要促成因素。
★ 可动态分配的共享式一级缓存大幅提升并行计算效率
再来算算一级缓存的总容量,Cypress拥有8KBx20=160KB的一级缓存,和32KBx20=640KB的本地数据共享缓存,还有额外的64KB全局数据共享缓存。
而GF100拥有64KBx16=1MB容量的一级缓存+共享缓存,他们可以被动态的划分为256KB一级缓存+768KB共享缓存,或者768KB一级缓存+256KB共享缓存,另外还有12KBx16=192KB的纹理缓存,无论从哪个方面来比较,都要比Cypress强很多。

此次NVIDIA创新性的可动态划分一级缓存设计,是以往CPU上面都不曾有过的先进技术,大幅提升了GPU并行计算的数据处理能力,使得GPU庞大的流处理器资源在高负荷密集型运算时不至于出现瓶颈,从而发挥出恐怖的浮点运算能力。
GPU篇:共享式大容量二级缓存
再来看看GPU二级缓存部分的设计,这一方面就与CPU非常相似了。
★ Cypress的二级缓存:绑定显存控制器的分离式设计
以往的GPU,包括NVIDIA上代的GT200以及AMD最新的Cypress核心,二级缓存都是与显存控制器绑定在一起的,其作用就是缩短GPU到显存的响应时间。由于显存控制器一般都是64bit一组,为多组模块化设计,因此二级缓存也被划分为N个独立的模块,而不是统一的整体。
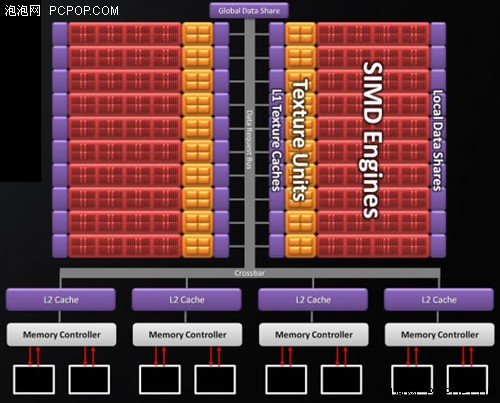
Cypress:L2绑定Memory Controller
Cypress拥有4个64bit显存控制器,每个显存控制器绑定128KB容量的二级缓存,总计512KB,这个容量要比NVIDIA上代的GT200大一倍。
★ GF100的二级缓存:统一的大容量高速缓存
而GF100拥有一个768KB容量统一的二级高速缓存,该缓存可以为所有载入、存储以及纹理请求提供服务。二级缓存可在整个GPU中提供高效、高速的数据共享。物理效果、光线追踪以及稀疏数据结构等事先不知道数据地址的算法在硬件高速缓存上的运行优势尤为明显。后期处理过滤器需要多个SM才能读取相同的数据,该过滤器与存储器之间的距离更短,从而提升了带宽效率。

统一的共享式缓存比单独的缓存效率更高。在独享式缓存设计中,即使同一个缓存被多个指令预订,它也无法使用其它缓存中未贴图的部分。高速缓存的利用率将远低于它的理论带宽。GF100的统一共享式二级高速缓存可在不同请求之间动态地平衡负载,从而充分地利用缓存。二级高速缓存取代了之前GPU中的二级纹理缓存、ROP缓存以及片上FIFO。

GF100的缓存架构让各流水线之间可以高效地通信,减少了显存读写操作
统一的高速缓存还能够确保存储器按照程序的顺序执行存取指令。当读、写路径分离(例如一个只读纹理路径以及一个只写ROP路径)时,可能会出现先写后读的危险。一个统一的读/写路径能够确保程序的正确运行,同时也是让NVIDIA GPU能够支持通用C/C++程序的重要因素。
与只读的GT200二级缓存相比,GF100的二级高速缓存既能读又能写,
而且是完全一致的。NVIDIA采用了一种优先算法来清除二级缓存中的数据,这种算法包含了各种检查,可帮助确保所需的数据能够驻留在高速缓存当中。
★ GF100共享式二级缓存堪比酷睿2:
可以看出,ATI的一二级缓存都是完全分散的,为了协调一二级缓存之间的数据交换,ATI特意设计了一个可全局共享的64KB数据缓存。
而GF100的一级缓存可以根据需求动态的为共享缓存或者一级缓存分配较大的容量,从而加速数据处理。二级缓存更是大容量一体式设计,当线程组在一级缓存中找不到数据时,可以直接从“海量”的二级缓存中索取,缩短了数据请求与定址时间,消除了瓶颈。
至于独享式缓存与共享式缓存的效率与性能,无需多言,大家可参照CPU的发展即可略知一二。
趋势:异构计算CPU强化整数GPU接管浮点
★ CPU发展趋势:不断的整合功能模块
通过前面详细的介绍我们可以发现,CPU的发展趋势就是不断去整合更多的功能和模块,从协处理器、到缓存、再到内存控制器甚至整个北桥。
目前AMD和Intel的所有主流CPU都已经整合了内存控制器,Intel最新的Lynnfield(Core i7 8XX和i5 7XX)已经整合了包括PCIE控制器在内的整个北桥,而Clarkdale(Core i5 6XX和i3 5XX)更是将GPU也整合了进去。
★ GPU发展趋势:不断的蚕食CPU功能
至于GPU,从某种意义上来说,它本身就是一颗协处理器,主要用于图像、视频、3D加速。之所以这么多年来没有被CPU所整合,是因为GPU实在太复杂了,以现有的制造工艺限制,CPU不可能去整合一颗比自身规模还要大很多的GPU,它顶多只能整合一颗主流中低端的GPU,而这样的产品只能定位入门级,无法满足游戏玩家和高性能计算的需要。
GPU从诞生至今一步步走来,就是在不断蚕食着原本属于CPU的功能,或者说是帮助CPU减负、去处理哪些CPU并不擅长的任务。比如最开始的T&L(坐标转换与光源)、VCD\DVD\HD\BD视频解码、物理加速、几何着色。而今后和未来,GPU将夺走一项CPU最重要的功能——并行计算、高精度浮点运算。
★ GPU前途似锦:浮点运算的未来
我们知道,CPU第一个整合的就是专门用来加速浮点运算的协处理器,此后历代SSE指令集也都是为了加强CPU的SIMD(单指令多数据流)浮点运算性能。而GPU打从一开始就被设计成为了SIMD架构(至今Cypress也还是这种架构),拥有恐怖浮点运算能力的处理器。当今GPU的浮点运算能力更是达到多核CPU的几十倍甚至上百倍!
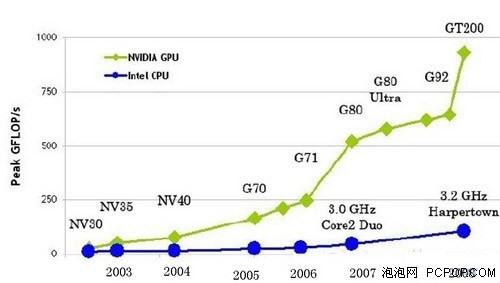
CPU和GPU的浮点运算能力
CPU永远都赶不上GPU的发展速度,因此最适合进行浮点运算的显然是GPU,CPU继续扩充核心数目已经变得毫无意义,因此整个业界都在想方设法的发掘GPU的潜能,将所有的并行计算任务都转移到GPU上面来。即便是Intel也看到了GPU广阔的前景,因此着手研发GPU。
此前由于API和软件的限制,GPU在并行计算方面的应用举步维艰、发展缓慢,NVIDIA孤身推广CUDA架构虽然小有成就但孤掌难鸣。好在OpenCL和DirectCompute两大API的推出让GPU并行计算的前途豁然开朗,此时ATI和NVIDIA又重新站在了同一起跑线上,那么很显然谁的架构更适合并行计算,那么谁就能获得更强的性能和更大范围的应用,通过本文的分析可以看出,ATI的架构依然是专注于传统的图形渲染,并不适合并行计算;而NVIDIA的架构则完全针对通用计算API和指令集优化设计,确保能发挥出接近理论值最大效能,提供最强的浮点运算性能!
★ CPU面临拐点:强化整数性能,浮点运算交给GPU
AMD同时拥有CPU和GPU,而且AMD在技术方面往往能够引领业界,因此其未来发展规划非常值得大家思考。根据AMD最新的产品路线图来看,其下一代的高端CPU核心Bulldozer(推土机),它最大的亮点就是每一颗核心拥有双倍的整数运算单元,整数和浮点为非对称设计:

AMD下一代“推土机”架构,大幅强化整数运算单元
在一个推土模块里面有两个独立的整数核心,每一个都拥有自己的指令、数据缓存,也就是scheduling/reordering逻辑单元。而且这两个整数单元的中的任何一个的吞吐能力都要强于Phenom II上现有的整数处理单元。Intel的Core构架无论整数或者浮点,都采用了统一的scheduler(调度)派发指令。而AMD的构架使用独立的整数和浮点scheduler。
据AMD透露,目前存在于服务器上的80%的操作都是纯粹的整数操作,因此AMD新一代CPU大幅加强了整数运算单元而无视浮点运算单元。而且,随着CPU和GPU异构计算应用越来越多,GPU将会越来越多的负担起浮点运算的操作,预计未来3-5年的时间内,所有浮点运算都将会交给最擅长做浮点运算的GPU,这也就是推土机加强整数运算的真正目的。
当然,AMD和Intel都会推出CPU整合GPU的产品,不管是胶水还是原生的解决方案,其目的并不是为了消灭显卡和GPU,而是通过内置的GPU为CPU提供强大的浮点运算能力。但由于制造工艺所限,被CPU所整合的GPU不是集成卡就是中低端,只能满足基本需求。所以想要更强大的游戏性能和并行计算性能的话,专为浮点运算而设计的新一代架构的GPU产品,才是最明智的选择。
所以说,CPU和GPU,谁也不可能取代谁,双方是互补的关系,只有CPU和GPU协同运算,各自去处理最擅长的任务,才能发挥出计算机最强的效能。CPU会整合GPU的,但仅限中低端产品;GPU会取代CPU进行浮点运算的,但它仍然需要CPU来运行操作系统并控制整个计算机。只有当制造工艺发达到一定程度时才有可能将CPU和GPU完美融合在一起,到时候是CPU整合GPU还是GPU整合CPU都很难说,但谁被谁整合已经不重要了。■
转载于:https://www.cnblogs.com/lancidie/archive/2010/11/02/1866912.html
(转)从CPU架构和技术的演变看GPU未来发展相关推荐
- 我对前端技术更新的看法以及未来发展趋势预测
我对前端技术更新的看法以及未来发展趋势预测 前端开发如何看待"别更新了,学不动了"?Deno.TypeScript 等新轮子层出不穷,未来前端重点方向在哪?前端开发在大前端浪潮下如 ...
- 手机已经代替钱包?移动支付技术的应用趋势及未来发展
移动支付已经成为了我们日常生活中不可或缺的一部分,无论是支付宝.微信支付.还是Apple Pay,这些移动支付工具已经取代了传统的纸币和硬币,成为了现代化支付的代表.移动支付技术的应用不仅仅是方便了我 ...
- 智能合约在区块链溯源技术中的应用及未来发展:提升企业运营效率
作者:禅与计算机程序设计艺术 智能合约在区块链溯源技术中的应用及未来发展:提升企业运营效率 引言 随着互联网.物联网.区块链等技术的快速发展,企业运营效率也逐渐有了很大的提高.特别是在区块链技术的作用 ...
- vr虚拟现实技术的前景!对未来发展带来有利的趋势吗?
科技的进步,人类的生活水平随之提高,因为科技智能时代的到来,我们才可以更加便利的生活,感受智能科技的力量,例如我们因为有vr虚拟现实技术才有了现在的3D影院,感受视觉的冲击带来身临其境的感觉,还有导航 ...
- php项目架构图,项目架构 · Lanson技术文档 · 看云
### 基础项目架构 **项目基于 ThinkPHP 3.2.3 版本做为项目的基础开发框架** 1. 项目采用MVC结构,入口文件在index.php 2. 调用Common 的 BaseContr ...
- 语音识别技术的研究难点以及未来发展方向
(文章来源:钛媒体) 目前,语音识别研究工作进展缓慢,困难具体表现在: (1)输入无法标准统一,比如各地方言的差异,每个人独有的发音习惯等,如下图所示,口腔中元音随着舌头部位的不同可以发出多种音调,如 ...
- java发展趋势看法_我对前端技术更新的看法以及未来发展趋势预测
前端开发如何看待"别更新了,学不动了"?Deno.TypeScript 等新轮子层出不穷,未来前端重点方向在哪?前端开发在大前端浪潮下如何持续学习.成长? SpriteJS 3.0 ...
- 计算机编程技术的历史变迁以及未来发展
技术在更迭,科技在变化.20 年前,或许只是处于概念型的技术,如今早已深入落地我们的日常生活中.随着大数据和AI人工智能时代的到来,计算机专业成为了最热门的专业之一,越来越多的孩子从小开始接触和学习计 ...
- 从Qualcomm技术看loT未来发展方向
Qualcomm正在引领5G之路,迈向智能联网终端的新时代.我们的产品正在变革汽车.计算.健康医疗.数据中心等行业,在loT领域更有建树.Qualcomm硬件在一定程度上决定了未来世界的loT设备的发 ...
最新文章
- ISelectionSet接口
- tensorflow分布式训练之同步更新和异步更新
- 重构:改善饿了么交易系统的设计思路
- [xmlpull]XmlPull常见错误
- SAP C4C url Mashup的跳转工作原理 - 新的浏览器窗口是如何打开的
- lamda获取参数集合去空_JAVA集合框架知识
- 通过path绘制点击区域
- 1核1g服务器php,虚拟主机1核1g什么意思
- 罗切斯特大学排名计算机排名,罗切斯特大学排名
- SAP License:CO-FI实时集成
- KKT条件 拉格朗日乘子法
- Android高效率编码-第三方SDK详解系列(三)——JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送...
- 印度首颗 CPU 横空出世:软件开发已开动
- 写shell工具类,一个常用实例
- 淘宝分类大全及其分组 (MySql, xls)文件,上下关系,拼写,层级,层级树,提示,2022年2月28日数据
- base64格式图片直接显示
- SAT阅读常见重要词汇
- 什么是安时数(AH)
- 第九章第八题(Fan类)(Fan class)
- 智慧校园管理系统全套源码 智慧学校源码(小程序端、电子班牌、人脸识别系统)
热门文章
- 消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?大量消息持续积压几个小时,怎么办?...
- git flow版本
- @Transactional-同一个类中方法自调,调用方法事物失效
- c++学习笔记内联函数,函数重载,默认参数
- php vendor 删除,yii2我删除了vendor目录,然后重新composer install composer update就不行了。。。...
- php array的实现原理,PHP数组遍历与实现原理
- Dockerfile ENV和ARG的区别与应用
- 【Zookeeper进阶】大白话解释Zookeeper的选举机制
- Redis最佳实践:业务层面和运维层面优化
- 享元模式 Flyweight Pattern