BTree,B-Tree,B+Tree,B*Tree
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
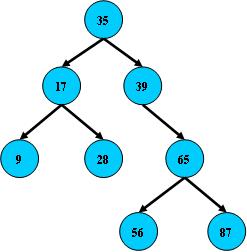
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
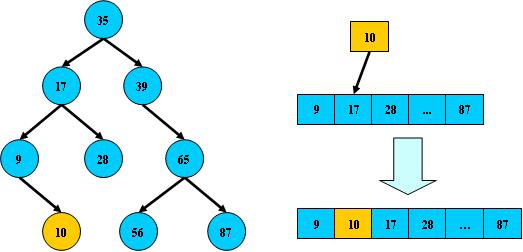
但B树在经过多次插入与删除后,有可能导致不同的结构:
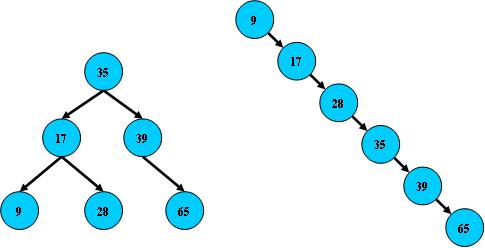
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
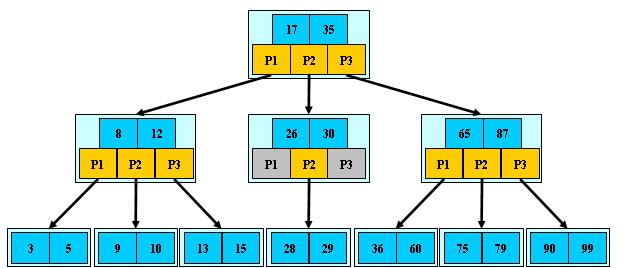
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
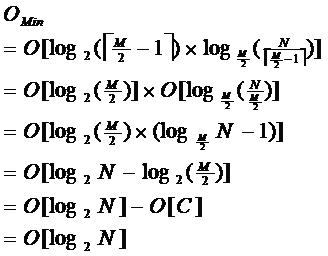
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
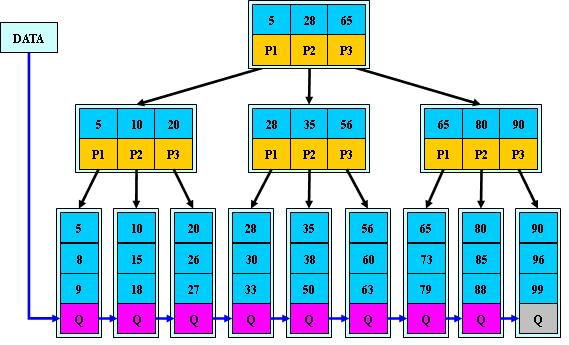
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
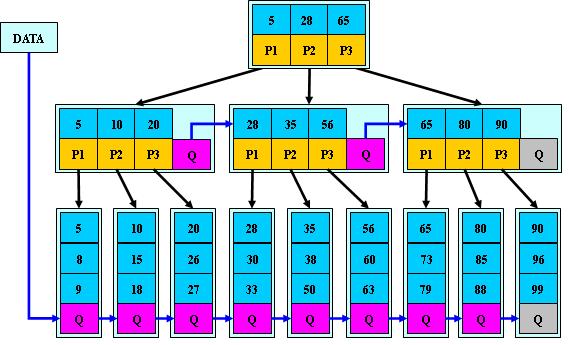
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
摘自:http://blog.csdn.net/manesking/archive/2007/02/09/1505979.aspx
Innodb 作为 MySQL 中使用最为广泛的 事务型存储引擎,不仅在事务实现数据版本控制方面和其他存储引擎有一定的区别,其数据结构也是以非常有特点的方式存储的。
每个Innodb表的数据其实可以说就是以一个树型(B-Tree)结构存储的,表的数据和主键(Primary Key)共同组成了一个索引结构,也就是我们常说的Innodb的Clustered Primary Key。在这个Clustered Primary Key中,Leaf Nodes其实就是实际的表记录,我们常规理解上的索引信息全部在Branch Nodes上面。
除了Clustered Primary Key之外的其他所有索引在Innodb中被称为Secondary Index。Secondary Index就和普通的B-Tree索引差不多了,只不过在Secondary Index的所有Leaf Nodes上面同时包含了所指向数据记录的主键信息,而不是直接指向数据记录的位置信息。
所以,在 Innodb 中,如果主键值占用存储空间较大的话,会直接影响整个存储 Innodb 表所需要的物理空间,同时也会直接影响到 Innodb 的查询性能。
下面是画的一张 Innodb 索引基本结构图,包括 Primary Key 和 Secondary Index 两种索引的比较。

在此之前曾经写过一篇介绍 “Innodb 索引结构了解 - Innodb Index Structure” 的文章,这次再接着分析一下 MyISAM 存储引擎索引的基本存储结构。
从索引基本的存放数据结构来说,MyISAM 的索引不论是 Primary Key 还是普通 Index,存储结构都基本一样,基本结构都是 Balance Tree (简称为 B-Tree),所有的键值详细信息和行“指针”信息都存放于 B-Tree 的 Leaf Nodes 上面。这个基本的数据结构和 MySQL 的其他存储引擎如 Innodb 也基本相同。但是,MyISAM 的索引并不像 Innodb 存储引擎那样 Primary Key 和 Secondary Index 中存放的数据存在较大区别。在 MyISAM 存储引擎中,Primary Key 和其他的普通 Index 的主要区别仅仅在于 Primary Key 的索引键需要满足是非空的唯一值而已,另外一个区别其实也是每一个普通索引之间都存在的区别,就是整个索引树的键值排列顺序不太一样。
由于 MyISAM 存储引擎中数据行的存储分为固定长度和动态长度两种,所以在 MyISAM 存储引擎的数据文件中定位一行数据所需要信息也存在两种方式。一种是直接通过行号(row number)来定位固定长度表数据的行,另外一种是通过其他一些相对的文件位置标识信息来定位动态长度表数据的行,这里我们姑且将两种方式统称为RID(Row ID)吧。
下面这张图片展示了 MyISAM 索引的基本存储方式:

myisam index structure
本文出自:http://www.jianzhaoyang.com/database/myisam-index-structure
转载于:https://www.cnblogs.com/ajian005/archive/2011/11/30/2753764.html
BTree,B-Tree,B+Tree,B*Tree相关推荐
- 『数据结构与算法』解读树(Tree)和二叉树(Binary Tree)!
『数据结构与算法』解读树(Tree)和二叉树(Binary Tree)! 文章目录 一. 树 1.1. 树的定义 1.2. 树的基本术语 1.3. 树的性质 二. 二叉树 2.1. 二叉树的定义 2. ...
- B. Alyona and a tree(dsu on tree + bit)
B. Alyona and a tree(dsu on tree + bit) 给定一颗以111号节点为根的树,每个点有点权aia_iai,边有边权,如果vvv控制了点uuu,当且仅当uuu是vvv ...
- poj 2892 Tunnel Warfare (Splay Tree instead of Segment Tree)
poj.org/problem?id=2892 poj上的一道数据结构题,这题正解貌似是Segment Tree,不过我用了Splay Tree来写,而且我个人认为,这题用Splay Tree会更好写 ...
- linux tree显示乱码,Linux tree 命令乱码
今天在执行Linux下的tree命令的时候,出现了乱码.上网查了一下说需要使用tree --charset ASCII,强制使用ASCII字符.这样确实可以输出正常了.但是我的环境里的LANG=US. ...
- b tree和b+tree_B TREE实施
b tree和b+tree B TREE及其操作简介 (Introduction to B TREE and its operations) A B tree is designed to store ...
- mysql b tree索引原理_B+Tree原理及mysql的索引分析
一.索引的本质 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构.提取句子主干,就可以得到索引的本质:索引是数据结构. 我们知道,数据库查询是数据库的最主要功能之 ...
- echarts tree默认展开_echarts tree控制节点的展开收起
echarts使用版本 v4版本 需求 当数据量比较大时,tree的子节点会挤在一起,这不是产品想要的效果 产品期望点击某一子节点时,其他同级节点自动收起,效果如下 echarts官方文档并没有提供类 ...
- 的tree用法_linux命令tree用法
CentOS7.3学习笔记总结(四十九)-linux命令tree用法 tree命令用于以树状图形方式列出目录结构(指定目录下的所有文件.所有目录). 该命令默认未安装,安装命令:yum -y inst ...
- android studio tree,Git 、Sourse Tree 和 Android Studio配置遇到的问题
配置遇到的问题 1.首先你的电脑上要安装好Git,百度上搜Git客户端 安装这个就可以,根据提示一步一步安装就可以,安装成功后,右键单击桌面出现 (Git Gui here 和Git Bash h ...
- ICPC 南昌现场赛 K:Tree(dsu on tree + 动态开点线段树)
Tree 让我们找满足一下五个条件的(x,y(x, y(x,y)点对有多少: x≠yx \neq yx=y xxx不是yyy的祖先 yyy不是xxx的祖先 dis(x,y)≤kdis(x, y)\ ...
最新文章
- 开源助力!武汉新型冠状病毒防疫开源信息收集平台
- hive根据已有表创建新表_Hive基础之创建表
- php阿里大于验证码开发,阿里大于验证码发送 (ThinkPhp框架)
- 7分钟了解科大讯飞开发者节:AI红利期来临,全新1024计划发布(未完待续)
- 使用jconsole监控JVM内存
- 本地运行flowable_在CockroachDB上运行Flowable
- a20隐藏底部按钮及隐藏状态栏和虚拟按键栏
- python123第一周测试作业指导书_风速仪作业指导书.doc
- (转贴)正则表达式学习心得体会(5)
- J2EE学习笔记(1)
- mysql 、慢查询、到底如何玩
- Centos使用Cacti监控你的网络
- 视频教程-SQL语句视频课程(进阶版)-Oracle
- 使用技巧-输出彩色TIF格式分类结果
- python怎么画圆螺旋线_使用Turtle画正螺旋线的方法
- 如何使用python画一个爱心
- 1. 学校在线考试系统
- 解决手机端中文输入法中keyup不灵便的方法
- 当你热爱现实, 世界就是你照见的自己
- 第6章 关系数据理论 习题6