举重若轻的人人车移动端数据平台
关于人人车数据平台,水永老师主要分享了4部分内容:
第一部分,整体的架构;
第二部分,Web IDE的实时计算平台;
第三部分,对于离线结果的BI报表平台;
第四部分,移动端的数据驱动实践。
整体架构
1. 数据门户中涵盖几个平台:
BI报表、元数据管理、实时计算平台、自助取数平台、数据工单平台、监控平台。
2. 数据平台的发展历程:
元数据管理平台、BI报表平台、实时计算平台、监控平台、自助取数平台、数据工单平台、统一数据权限平台
3. 大数据平台的整体架构:
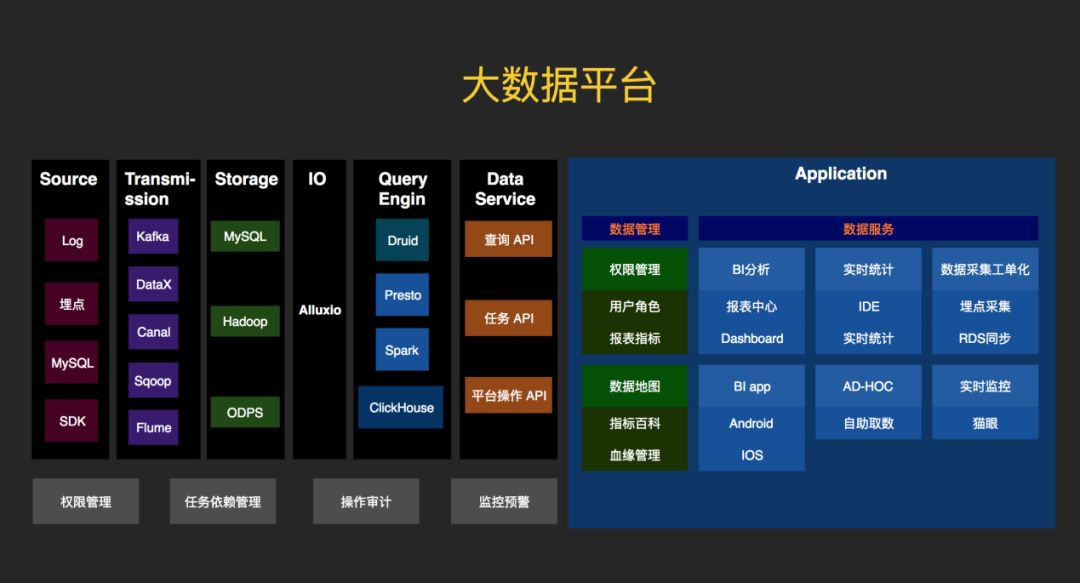
One data,如图,最左边是数据源,有日志、埋点、MySQL、SDK,最后统一落在Hadoop上。避免数据烟囱,降低计算、存储成本,保障数据指标口径一致,各种场景下看到的数据一致性,为上层建立了统一的数据服务层One service奠基。
One service,数据的下游使用方很多,不可能让每个使用的人直接查表,库。在这种状态下定义一个Service层,也就是api层,对外暴露查询服务。这些是service层以下的引擎,底层有很多的引擎,对上层应用来说是无感知的。比如时序数据库Druid,包括SQL on Hadoop模式的Presto,spark SQL。还有一些列式存储的数据库,比如ClickHouse。数据的使用通过数据元数据平台申请,按表级别粒度管控。Service层保证数据的一致性,不论是查Druid,还是ClickHouse,拿到的数据是一样的。如果是小量数据则是restful api,大批量数据则是下载任务。
One meta,统一的元数据管理,包含数据地图,指标管理,权限管控。元数据可能是最后一块要攻克的高地了,元数据是数据的数据,即数据的骨架。承载底层数据生产的血缘、上层应用报表/指标。使用数据第一步,申请权限,账号。在指标百科中可以看到自己使用的数据指标在哪个仪表盘中,在BI平台的仪表中申请权限,大大提高数据分发使用的效率。有句话说的好,元数据做得好,产品技术下班早。
4. 数据的流向
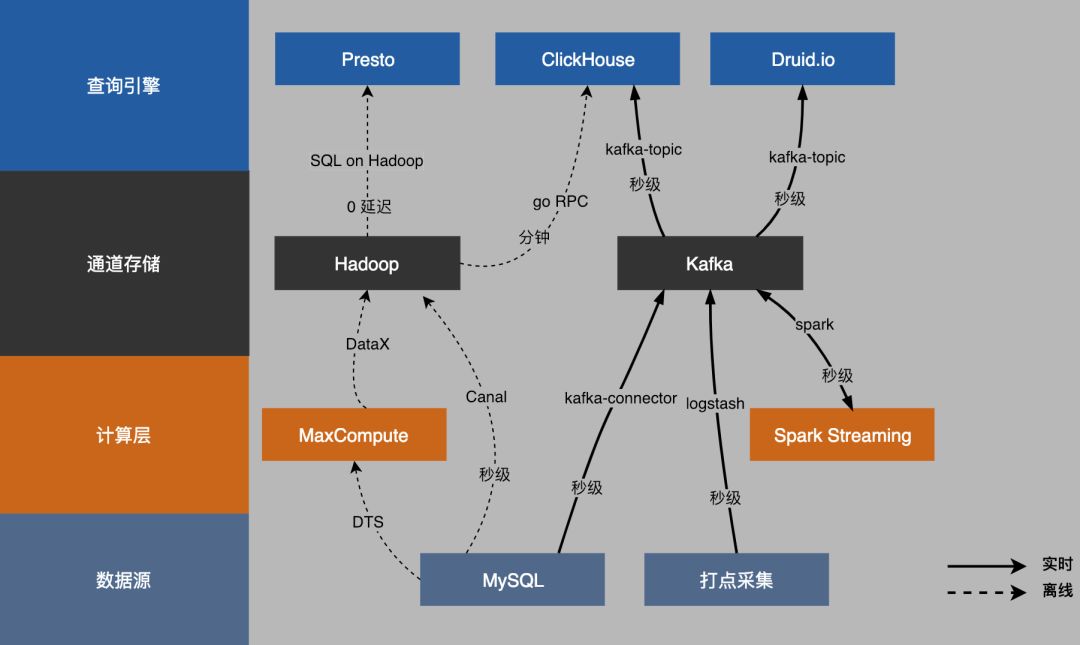
如图,左侧是它的分层,从数据源到计算层,到数据通道,到引擎。从下往上,左侧虚线是离线的数据,右侧实线,是实时的数据。
首先数据从数据源落到自己的Hadoop集群上。再往上是SQL on Hadoop模式,零延迟,可以快速查到数据。再往上,实时部分,使用Spark Streaming去做Kafka通道的转换,支撑订单预估,风险评估等。
Lambda架构很理想,但在数据的一致性和准确性的挑战上,大大增加了复杂度。对离线数据和实时数据上的应用和数据流进行拆分,业务分离,对不同的领域用专业的方案去解决。
实时计算平台
实时计算平台是基于Apache Spark构建的一站式、高性能实时大数据处理平台,提供了一整套Web IDE用于编写SQL,语法检测、调试、发布、监控。对于只会写SQL的BI同学来说,提供SQL语义的流式数据分析能力,可大幅降低流数据分析门槛。BI同学无需关注实现细节(将SQL转化为Spark流式任务),只需选取输入输出表,根据需求编写SQL即可实现一个实时计算任务。平台当前支持MySQL、Kafka两种数据源,并支持异构数据源join,及多流join(限定场景),支持用户自定义UDF,同时为了应对不同的场景需要,支持了三种端到端的消息传输语义:At-least-once、At-most-once、Exactly-once。
1. 计算引擎选型
实时计算常用的3个选型:Storm,Spark Streaming,Flink。
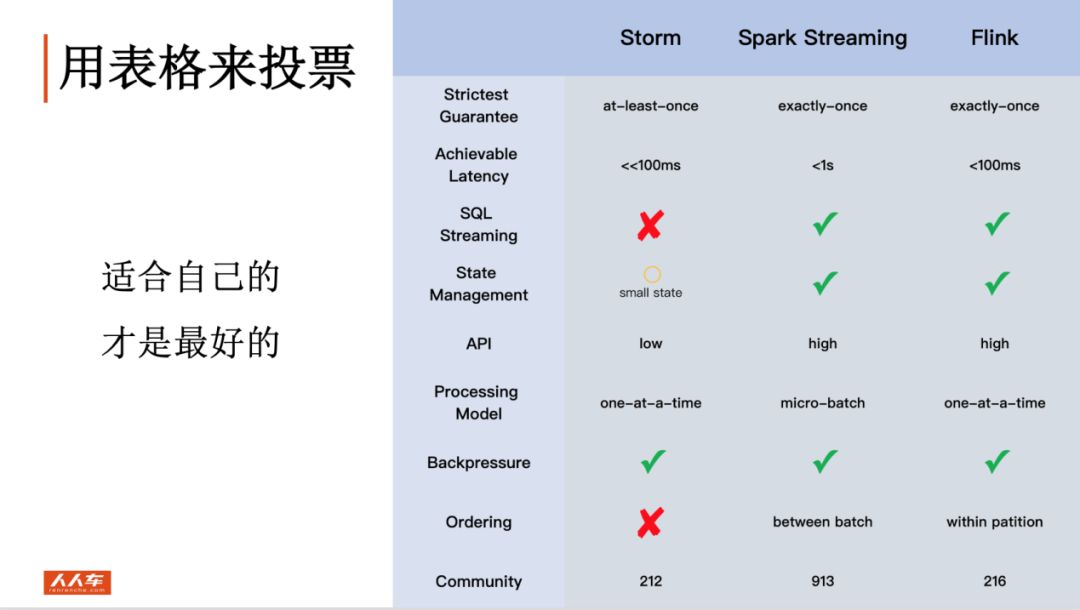
通过如上表格可对三者进行比较,首先淘汰的是Storm,因为它不支持使用SQL。
那剩下的就是Spark和Flink了,两者都基于内存计算,而且都支持SQL,尤其Spark在SQL方面做了深层次的优化。
虽然两者在流式计算方面做的都比较好。但两者还是有区别的,Spark当前支持两种引擎Streaming和Structured Streaming。Spark Streaming是Micro Batch模式,Structured streaming 即支持Micro Batch模式,又支持continuous模式(以流方式处理)。Flink Streaming以流的方式处理流数据。Spark和Flink当前都可以满足我司在实时方面的需求,鉴于Spark社区更加活跃,更加稳定,而且在SQL优化方面做的比较好,最终选择Spark作为计算引擎。
2. 实时计算平台整体架构
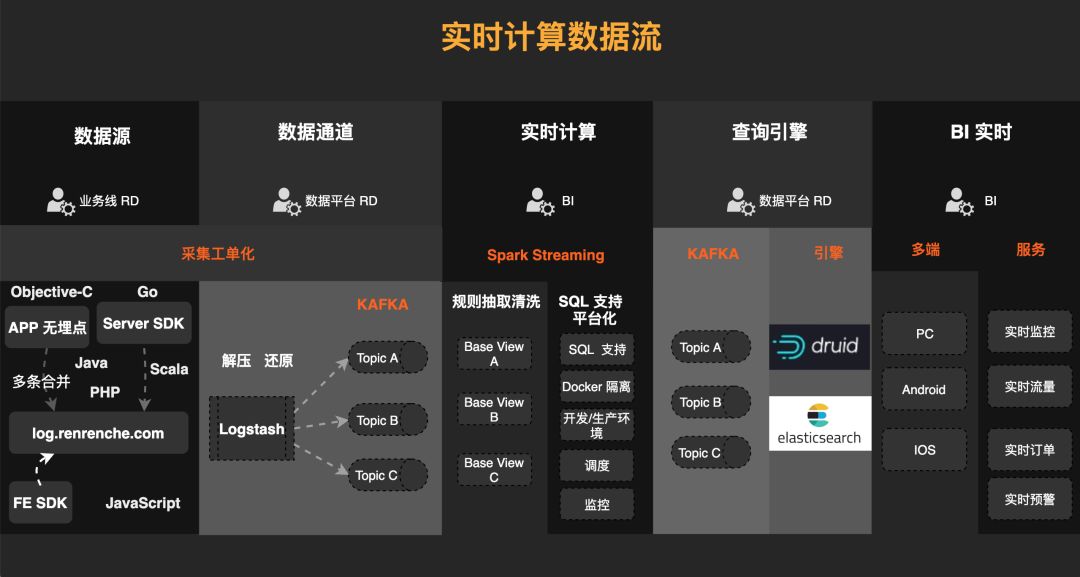
实时计算数据流如上图所示自左至右。数据源从左侧打点开始,业务RD在前端和后端会由不同的语言打点。通过统一的log打点平台(log.renrenche.com)接受打点过来的数据。数据收集上来之后,开始数据平台接入。数据上来以后做一个解压和还原,还原之后进入到Kafka相应Topic中。实时计算平台将Kafka topic作为数据源,抽象为View进行使用。BI同学编写SQL时可直接作为表查询使用,输出结果可根据实际需要选择输出到Mysql或者Kafka中。 进入到Mysql的数据可直接用于业务需要进行展示,进入Kafka的数据可通过同步工具,同步到ES或者druid中进行报表展示或者实时预警。
3. 实时数据管理
数据采集端有很多Client进行打点,将数据收集上来,这些数据如何管理?我们强调一个数据工单的平台,其最大的好处是,在下拉单选页面申请一个data job(业务线-部门-功能-xx),并填写其用途,下游消费方。当下游拿到这个data job时,可以在平台上查到Schema,这个Schema就是后续的一个基础。
4. 流与表的转换
数据处理有一个非常核心的概念就是流和表,在实时里就是一个流,在离线里面就是一个表。Kafka完美的诠释了流和表,因为Kafka既能为数据定义Schema,同时具有一个持久性以及可重放性,所以它能够完美被Spark Streaming/ Structured读取和解释。平台根据Topic对应的Schema,会将其生成一个base view。拿到这个base view之后对于用户来说,将这个流变成了一个表。有了表之后,就可以让用户进行SQL实现一个实时任务,可以对表进行聚合等离线常规操作。也可以异构表join,多流join等操作,底层流join由Spark Structured引擎支持。
计算之后的结果要被下游使用,又回写入到kafka中去,谁让kafka是最好的数据通道。实时的特点就是时序性,数据应用一个引擎最好的方式选择一个时序数据库,我们选择了Druid。
5. Web IDE
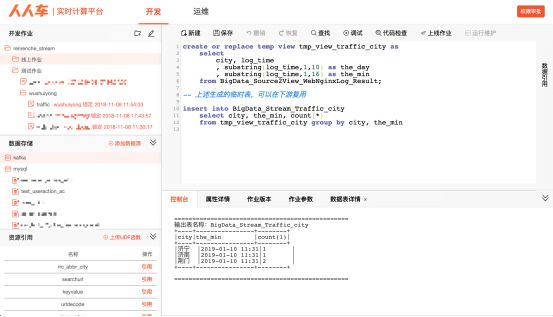
左侧上方的是目录树,方便进行项目管理。左中是数据源,包括Mysql和Kafka,亦可以自行添加数据源。左下是管理的UDF,引入进入项目即可使用,为了优化引入的jar包,亦可自行添加自定义UDF。右侧是主界面,写完SQL即可进行调试、排错,以及构造数据验收,屏蔽掉实时环境、DataSet、DStream、RDD等概念。IDE中包含,调试,监控,查看血缘关系功能,对于非实时开发的同学而言,是极低的理解和使用成本,完全可以WEB IDE上自行完成一个实时任务开发。
6. 调试
自动从数据源Mysql/Kafka中取前几条,填充到每一个字段中去,得到构造数据,亦可以手工自定义数据,即可调试和结果查看。整个过程是与生产环境隔离,在docker环境完成,任务与任务之间相互隔离。
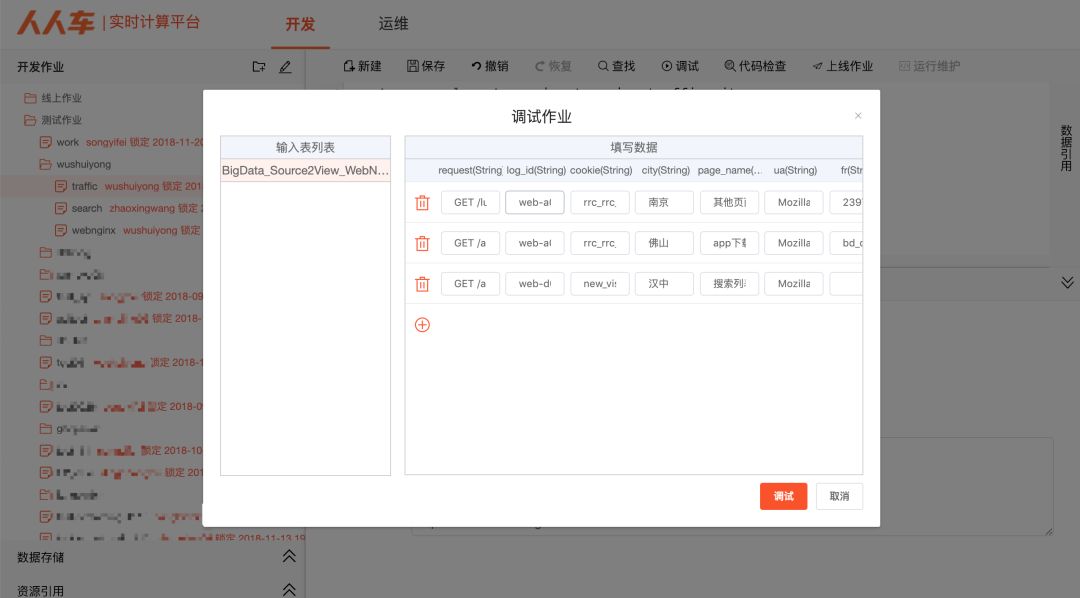
7. 监控
根据Spark暴露出来的API实现监控流数据的状态,可时刻监控数据流入以及调试延迟信息。
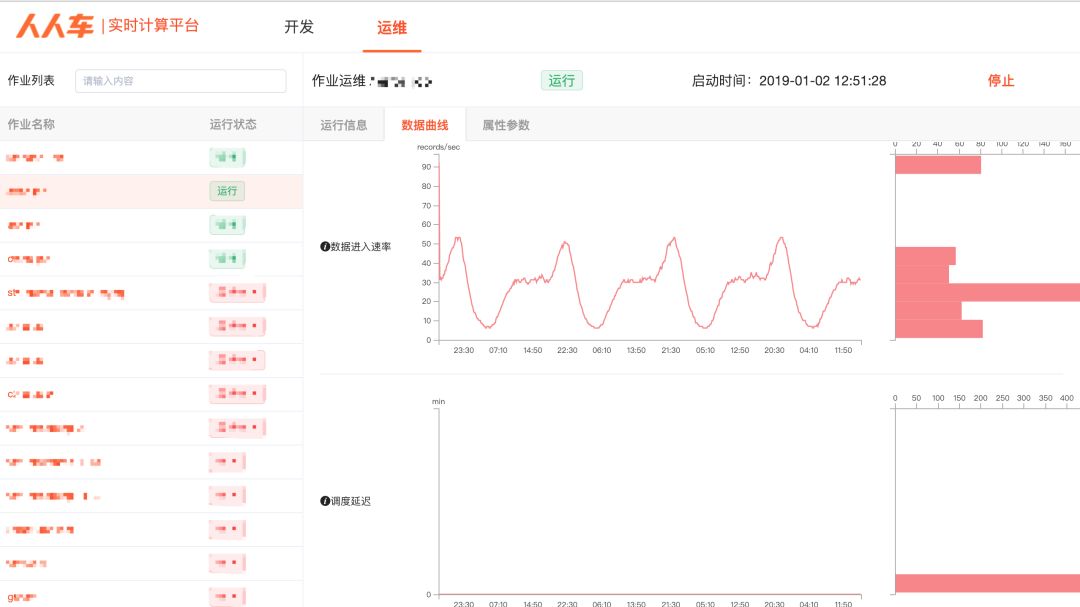
8. 血缘关系
方便BI同学进行表间依赖关系的梳理,表有类型三种类型:真实表、匿名表、临时表,尤其排查复杂的SQL时,此处一目了然。
9. 参数配置
Web IDE 意味着线下IDE的功能都要有,包括可以配置参数,比如配置信息,优化参数等,UDF的配置。对于各个参数要有默认参数。
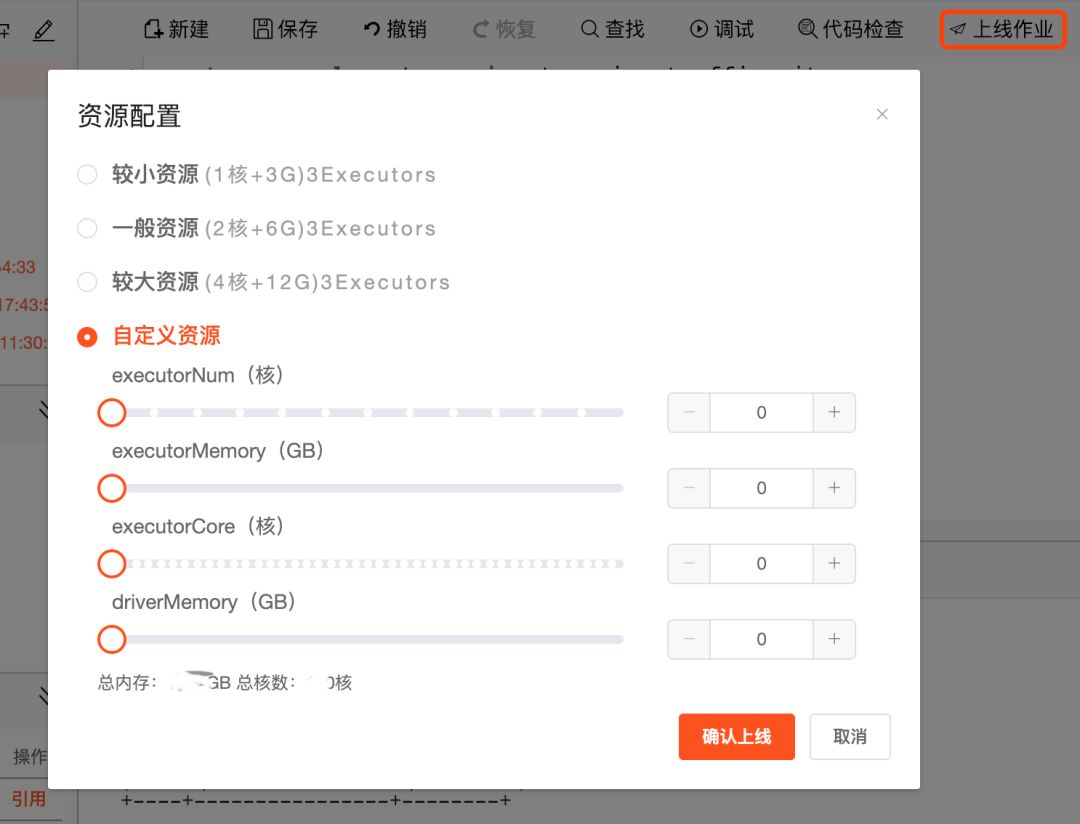
10. 开发-调试-发布
手动提交实时任务时都是使用spark-submit,但这种方式并不适合进行自动化提交(依赖客户端环境、上线速度慢、不便查看任务状态),最终确定基于YARN-API进行提交。所有的控制都在一个API中,无需上传依赖jar,上线速度快,也方便查看任务当前状态,同时YARN-API是更友好的API接口。这样就可以很轻易的去封装每个参数。
封装YARN-API的过程中包括了调试和发布。在Docker容器中编译调试,验收通过后发布上线,接入生产环境MySQL和Kafka数据。
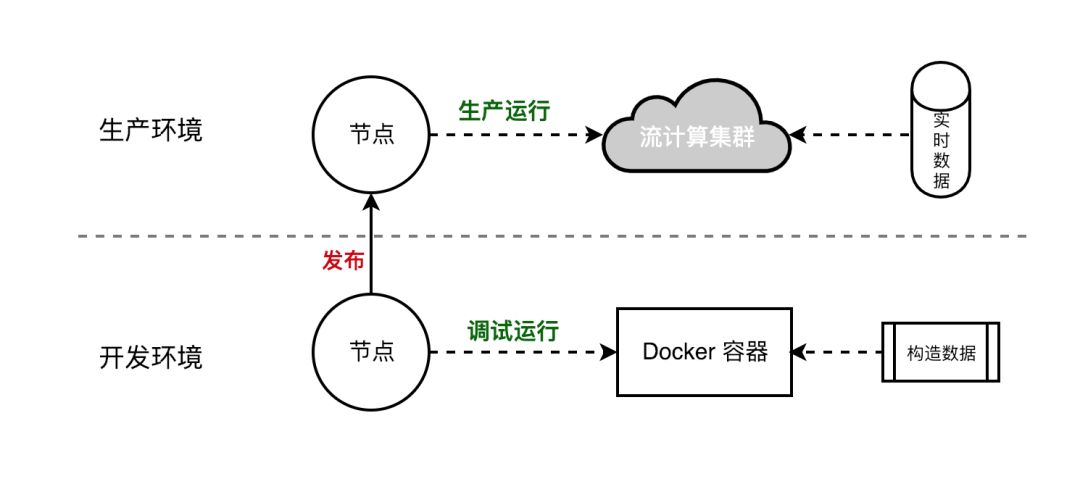
11. 最后总结下实时计算平台的特点:

BI报表平台
我们的目标是,构建一个小白级拖拽,所见即所得,包含移动端的数据平台。而在技术上需要考虑几个大难点:
低延时。包括数据更新低延时、数据查询低延时,在灵活的报表平台上,数据预构建类的引擎几乎不用考虑,需要精心管理索引的成本亦高,能在千万记录级别百余字段的数据基础上,亚秒或秒级别。
高并发。低延时的一个克星。没有大内存,MPP架构就难以施展能力。即使有大内存,复杂度和高并发下,同样也难以通过benchmark。
同步中全量增量的数据一致性。全量和增量同步还需要考虑主键去重、分区去重,一般的OLAP引擎数据写入都是append模式,几乎不支持update和delete。
1. 技术选型

在这些眼花撩乱的数据引擎中,各自有着自己特性,在不同的业务体系中,总有他们发挥的场景。我们需要一些标准评估哪个引擎更适合自身的业务场景,POC产品原型验证以及TPC benchmark压测。
自古磨刀不误砍柴工,梳理清楚业务场景才能在对每一个引擎做POC时高效靠谱,不至于贸然上船而到后期骑虎难下。若能转化成SQL场景,则在TPC-DS/TPC-H压测下更能科学判断一款引擎的场景能力。前者POC是定性分析,决定引擎能不能;后者TPC是定量分析,决定引擎到底有多强。
2. 一见钟情ClickHouse
人人车的BI平台选择了ClickHouse,支持较高的并发,支持亿级别量级查询,支持增量、全量同步,支持幂等性去重,支持更新update和删除delete,亚秒级延时,支持SQL。用自身业务的sql跑压测,4台测试机就跑出了10qps/30并发,已经是一见钟情了。
列式数据引擎ClickHouse,有很多特别适合BI场景的特性。在我们使用SQL的时候往往查询的列是很少的,列式数据库可以让我们在做聚合等操作时,只需要取出少量的列,可以大大减少内存与外存之间的数据交换。
ClickHouse性能确实太强悍了,在一台4核8G的机器上,对一亿七千条数据count,跑了3秒多。在第一次没有任何缓存的情况下,多维度group by+order by跑了9秒多。在我们看来ClickHouse如同AK47,简单可靠,性能强悍,手动性强。换言之大部分需要自己配置,如分布式和副本集,数据去重幂等性。Clickhouse已经支持update/delete,方便做数据的更新,但在大数据的性能要求下,ReplacingMergeTree在实践中仍然是更好的选择。
3. BI 数据架构
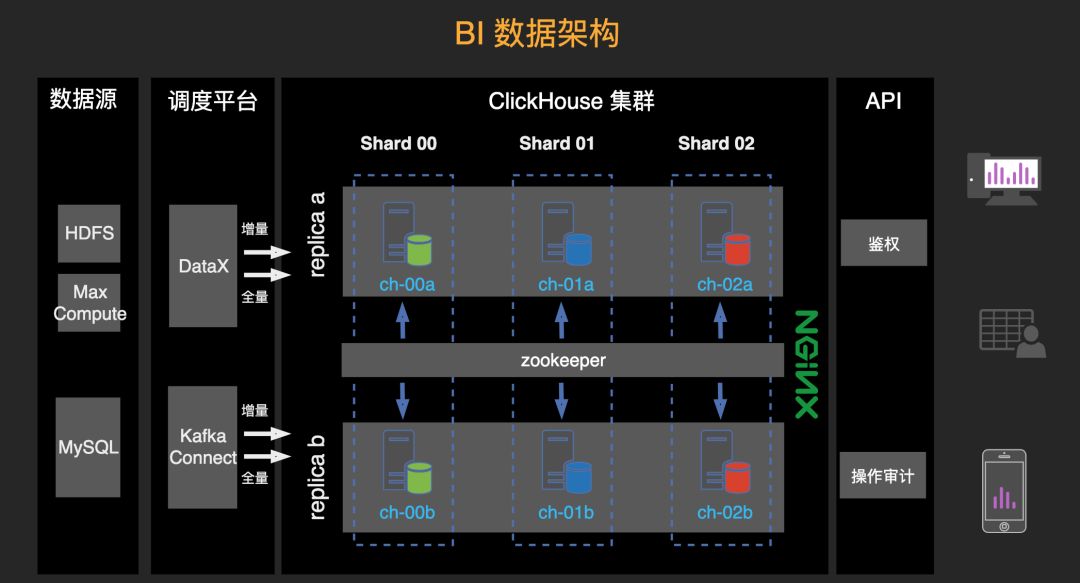
ClickHouse借用Zookeeper实现集群管理,高效管理副本和分片。副本可以提高集群的稳定性,分片用于做性能的扩展。ClickHouse的副本,不仅可以提高稳定性,还可以提高性能。发来的请求可以均匀的落在副本上,压测过程在几乎性能随之线性增长。
4. BI 报表平台
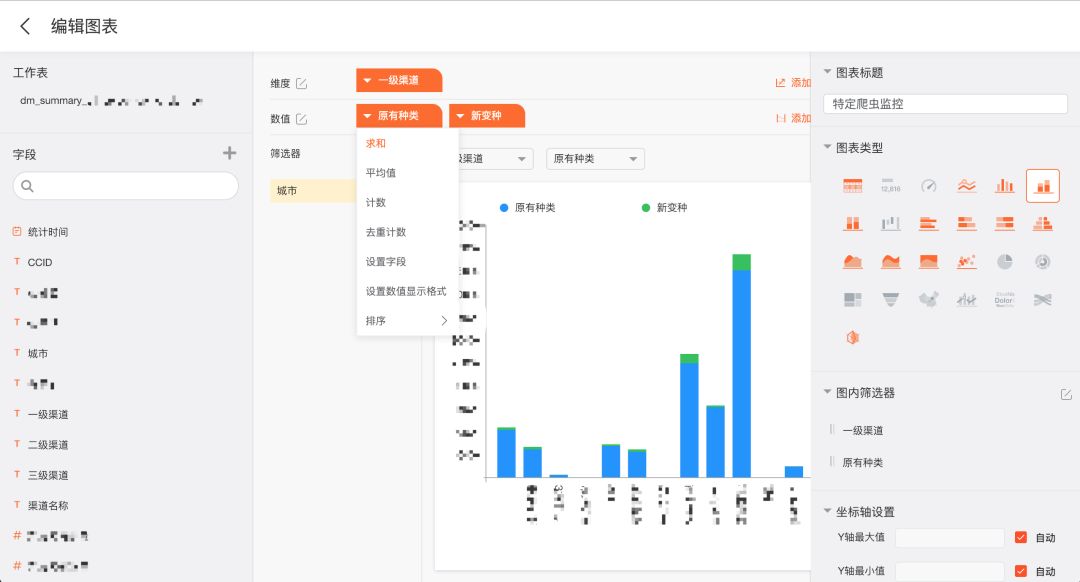
单表查询,选择一个表,左侧列出所有字段,亦可自定义配置字段名。拖拽字段到维度和数值上,右侧即会高亮显示可用图表类型。亦可增加对比轴,数据源过滤,图内筛选器,图表生成后前端方便用户自行筛选城市,时间等。
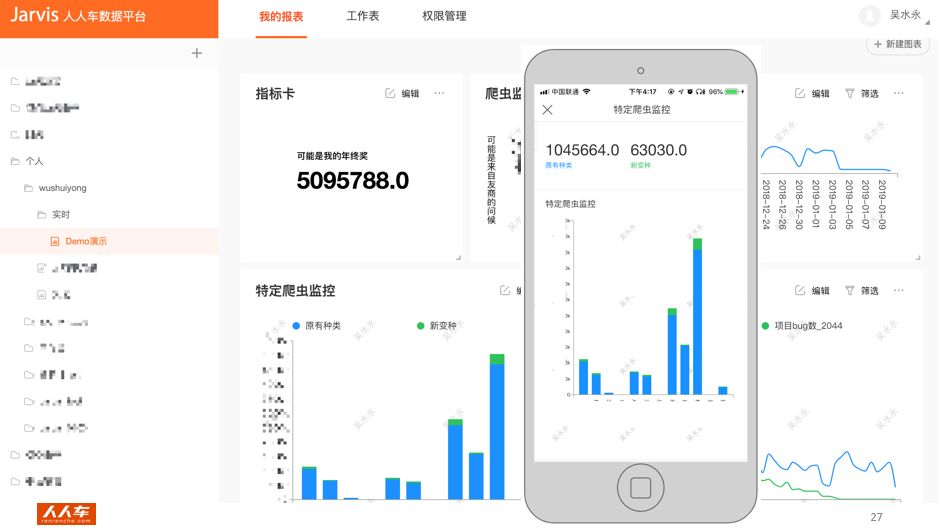
图表编辑生成后,三端(PC、Android、IOS)同步原样展示。
5. 高级功能
生成合表。除了单表查询外,还可以自己写SQL join/union生成新的表,仪表盘中的图表可以在合表的基础上输出。适合一些有能力的分析师对数仓的主题表做深度关联分析。

合表的血缘关系,上游的表是否生成,是否同步完成,以及被哪些合表作为源表使用,被哪些图表使用。另外高级用户可以根据自己的权限从数据仓库中查询数据,已经在全家桶中AD-HOC打通。
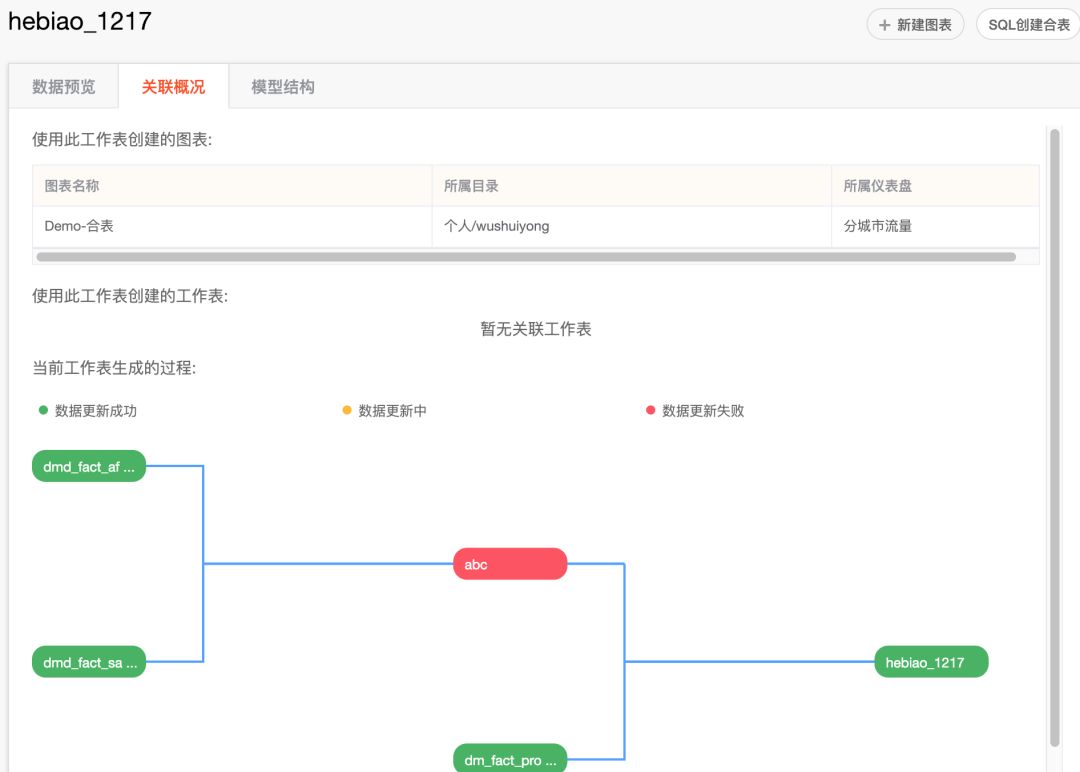
6. 最后总结BI报表平台特点:

数据驱动
我们线下有两万多人,包括销售,评估师等,线上有上千人,包括运营,产品等。线上做数据分析和线下执行完全不是一个思路,线上的总部可以在web上在几十个仪表盘关注几百个指标,但是线下人员一个手机。
其次,要分清线下管理的难点和本质。线下评估师销售面对的是各色各样的人,还要跟黄牛斗争,直面金钱的诱惑(飞单),让员工每天在一个开放的空间里做人性的考验,这种商业模式是不明智的。不要尝试与线下斗智斗勇,犹如秀才带兵打仗,如果没有一个有力的管理抓手,将会在无数次学习中成长。
如果管理抓手刚好又能跟数据结合,实现对线下的业务管理和数据管理,这就是数据驱动。

数据驱动一直是经常听说,但一直没有亲眼看到的东西,尤其在这种复杂的业务场景中。线上总部数据分析在PC端,做更全面深度分析,制定出与战略相匹配的业务指标,且与业绩直接挂钩。并且特别为线下提供掌上数据移动端(Android,iOS),使得线下随时随地只关注和自己业绩相关指标。考核什么就会得到什么,使线下人员的注意力聚焦自己每天业绩,各层级管理人员数据汇总,无论是在数据流通和人员调动上,管理抓手更为高效。
作者介绍:

吴水永,人人车大数据平台负责人,DevOps开源项目walle-web.io作者。2016年1月加入人人车,从0到1搭建起BI 报表平台、实时计算平台、元数据管理、Ad-Hoc、ETL、数据工单化等大数据平台,并结合大数据和营销实现平台化用户增长、全渠道营销。
本文来自吴水永在 DataFun 社区的演讲,由 DataFun 编辑整理。
举重若轻的人人车移动端数据平台相关推荐
- 基于MaxCompute打造轻盈的人人车移动端数据平台
摘要: 2019年1月18日,由阿里巴巴MaxCompute开发者社区和阿里云栖社区联合主办的"阿里云栖开发者沙龙大数据技术专场"走近北京联合大学,本次技术沙龙上,人人车大数据平台 ...
- 1年时间业务量疯长40倍,谈人人车的平台架构演进之路
人人车业务平台从最初典型的LNMP单机单服务部署架构,发展到如今分布式服务化架构,五百多台虚拟机部署,一路走来,踩过不少坑,也遇到过不少挑战,特别是对于基于云服务进行业务开发的场景,以及从零开始服务化 ...
- [转]1年时间业务量疯长40倍,谈人人车的平台架构演进之路
https://sdk.cn/news/5143 摘要:人人车业务平台从最初典型的LNMP单机单服务部署架构,发展到如今分布式服务化架构,五百多台虚拟机部署,一路走来,踩过不少坑,也遇到过不少挑战,特 ...
- 数据平台、大数据平台、数据中台……傻傻分不清?这次终于有人讲明白了!
来源 | 智领云科技 造概念,在IT行业可不是一件陌生的事儿,中文博大精深,新名词.新概念往往简单准确,既可以被大众接受,又可以被专家把玩,真正做到雅俗共赏.各有趣味.近年来,数据中台之火爆,什么数据 ...
- 数据平台、大数据平台、数据中台……还分的清不?
造概念,在IT行业可不是一件陌生的事儿,中文博大精深,新名词.新概念往往简单准确,既可以被大众接受,又可以被专家把玩,真正做到雅俗共赏.各有趣味.近年来,数据中台之火爆,什么数据平台.数据中台.数据湖 ...
- 大数据平台搭建_一文读懂数据平台、大数据平台、数据中台
作者 | June 来源 | 智领云科技(ID:LinkTimeCloud) 造概念,在 IT 行业可不是一件陌生的事儿,中文博大精深,新名词.新概念往往简单准确,既可以被大众接受,又可以被专家把玩, ...
- 一文读懂数据平台、大数据平台、数据中台
作者 | June 来源 | 智领云科技(ID:LinkTimeCloud) 造概念,在 IT 行业可不是一件陌生的事儿,中文博大精深,新名词.新概念往往简单准确,既可以被大众接受,又可以被专家把玩, ...
- 独家解读:魅族数据平台的设计哲学和核心架构
由最初的纯设备生产厂商渐渐发展为今天的智能设备设计商和互联网服务提供商,"魅族"转眼间已经历了十年的成长,其Flyme系统也在逐渐走向成熟.而依托于Flyme的魅族互联网服务也逐渐 ...
- 二手车数据分析-爬取人人车二十余万条线上二手车数据
我国汽车保有量近年来持续高速增长,二手车交易也正蓬勃发展,涌现出瓜子.优信.人人车,等大量二手车交易网站. 这次就通过在线抓取人人车发布的线上二手车数据,对目前二手车的交易情况进行分析. 使用工具: ...
最新文章
- Spark-Java算子
- python将图片转换为灰度图
- 热像仪 二次开发 c++_重庆多功能红外线热像仪方案
- 【java】java中内存映射文件和IO
- 互联网35岁中年危机的来龙去脉
- 2018-3-7 色彩的一些知识
- c++ list排序_STL之list
- 软件测试简历,这一点你是否漏掉
- 基于Qt的Littlevgl移植(Windos10)
- 库乐队历史版本怎么下载_ios库乐队旧版本下载
- poj 1436 Horizontally Visible Segments(线段树)
- Canvas动画案例演示,含动画猫、变幻线、代码雨等
- label smooth方法论文调研
- 大数据工程师就业前景及发展方向分析
- 洛谷P1053篝火晚会题解--zhengjun
- fseek, _fseeki64 函数应用
- http://mirrors.aliyun.com/centos/7/os/x86_64/repodata/repomd.xml: [Errno 14] curl#6 - “Could not res
- VirtualBox免费虚拟机使用简介、3G无线上网的Virtualbox实现
- Android混淆编译、反混淆、反编译
- zlib.hpp封装