python图表之pygal入门篇
pygal的简单使用
例子来自此书: 《Python编程从入门到实战》【美】Eric Matthes
pygal是一个SVG图表库。SVG是一种矢量图格式。全称Scalable Vector Graphics -- 可缩放矢量图形。
用浏览器打开svg,可以方便的与之交互。
以下代码均在Jupyter Notebook中运行
模拟掷骰子
来看一个简单的例子。它模拟了掷骰子。
import randomclass Die:"""一个骰子类"""def __init__(self, num_sides=6):self.num_sides = num_sidesdef roll(self):return random.randint(1, self.num_sides)
模拟掷骰子并可视化
import pygaldie = Die()
result_list = []
# 掷1000次
for roll_num in range(1000):result = die.roll()result_list.append(result)frequencies = []
# 范围1~6,统计每个数字出现的次数
for value in range(1, die.num_sides + 1):frequency = result_list.count(value)frequencies.append(frequency)# 条形图
hist = pygal.Bar()
hist.title = 'Results of rolling one D6 1000 times'
# x轴坐标
hist.x_labels = [1, 2, 3, 4, 5, 6]
# x、y轴的描述
hist.x_title = 'Result'
hist.y_title = 'Frequency of Result'
# 添加数据, 第一个参数是数据的标题
hist.add('D6', frequencies)
# 保存到本地,格式必须是svg
hist.render_to_file('die_visual.svg')
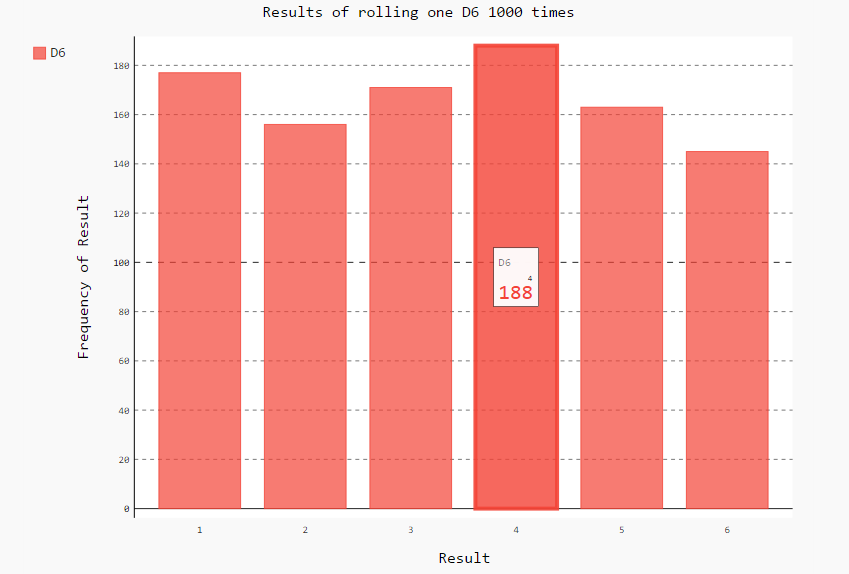
使用浏览器打开这个文件,鼠标指向数据,可以看到显示了标题“D6”, x轴的坐标以及y轴坐标。
可以发现,六个数字出现的频次是差不多的(理论上概率是1/6, 随着实验次数的增加,趋势越来越明显)
同时掷两个骰子
稍微改下代码就行,再实例化一个骰子
die_1 = Die()
die_2 = Die()result_list = []
for roll_num in range(5000):# 两个骰子的点数和result = die_1.roll() + die_2.roll()result_list.append(result)frequencies = []
# 能掷出的最大数
max_result = die_1.num_sides + die_2.num_sidesfor value in range(2, max_result + 1):frequency = result_list.count(value)frequencies.append(frequency)# 可视化
hist = pygal.Bar()
hist.title = 'Results of rolling two D6 dice 5000 times'
hist.x_labels = [x for x in range(2, max_result + 1)]
hist.x_title = 'Result'
hist.y_title = 'Frequency of Result'
# 添加数据
hist.add('two D6', frequencies)
# 格式必须是svg
hist.render_to_file('2_die_visual.svg')
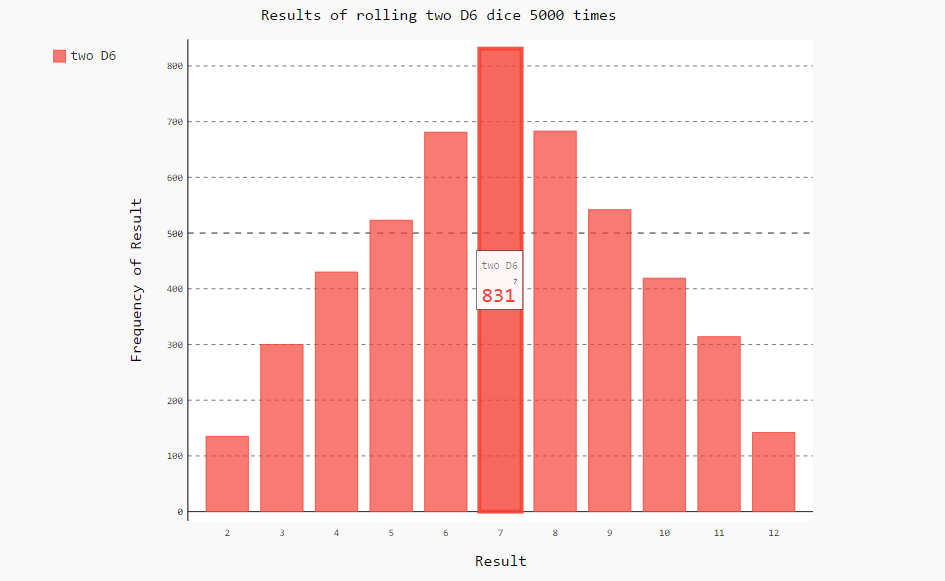
从图中可以看出,两个骰子之和为7的次数最多,和为2的次数最少。因为能掷出2的只有一种情况 -> (1, 1);而掷出7的情况有(1, 6) , (2, 5), (3, 4), (4, 3), (5, 2), (6, 1)共6种情况,其余数字的情况都没有7的多,故掷得7得概率最大。
处理json数据--世界人口地图
需要用到人口数据
点击这里下载population.json,该数据来源于okfn.org这个网站
打开看下数据,其实这是个很长的列表,包含了许多国家从1960~2015年的人口数据。看第一数据,如下。后面的数据和第一个键都一样。
[
{"Country Name":"Arab World","Country Code":"ARB","Year":"1960","Value":"92496099"},
...
只有四个键,其中Country Code指的是国别码,这里是3位的。Value就是人口数了。
import jsonfilename = r'F:\Jupyter Notebook\matplotlib_pygal_csv_json\population.json'
with open(filename) as f:# json.load()可以将json文件转为Python能处理的形式,这里位列表,列表里是字典pop_data = json.load(f)cc_populations = {}
for pop_dict in pop_data:if pop_dict['Year'] == '2015':country_name = pop_dict['Country Name']# 有些值是小数,先转为float再转为intpopulation = int(float(pop_dict['Value']))print(country_name + ': ' + population)
上面的程序打印了2015年各个国家的人口数,当然要分析2014年的,代码中数字改改就行。
Arab World: 392168030
Caribbean small states: 7116360
Central Europe and the Baltics: 103256779
Early-demographic dividend: 3122757473.68203
East Asia & Pacific: 2279146555
...
需要注意的是,人口数据有些值是小数(不可思议)。人口数据类型是字符串str,如果直接转int,像'35435.12432'这样的字符串是不能强转位int的,必须先转为float,再丢失精度转为int。
获取两个字母的国别码
我们的数据中,国别码是三位的,而pygal的地图工具使用两位国别码。要使用pygal绘制世界地图。需要安装依赖包。
pip install pygal_maps_world就可以了
国别码位于i18n模块
from pygal_maps_world.i18n import COUNTRIES这样就导入了, COUNTRIES是一个字典,键是两位国别码,值是具体国家名。
key -> value
af Afghanistan
af Afghanistan
al Albania
al Albania
dz Algeria
dz Algeria
ad Andorra
ad Andorra
ao Angola
写一个函数,根据具体国家名返回pygal提供的两位国别码
def get_country_code(country_name):"""根据国家名返回两位国别码"""for code, name in COUNTRIES.items():if name == country_name:return codereturn None
世界人口地图绘制
先给出全部代码,需要用到World类
import jsonfrom pygal_maps_world.i18n import COUNTRIES
from pygal_maps_world.maps import World
# 颜色相关
from pygal.style import RotateStyle
from pygal.style import LightColorizedStyledef get_country_code(country_name):"""根据国家名返回两位国别码"""for code, name in COUNTRIES.items():if name == country_name:return codereturn Nonefilename = r'F:\Jupyter Notebook\matplotlib_pygal_csv_json\population.json'
with open(filename) as f:pop_data = json.load(f)cc_populations = {}
for pop_dict in pop_data:if pop_dict['Year'] == '2015':country_name = pop_dict['Country Name']# 有些值是小数,先转为float再转为intpopulation = int(float(pop_dict['Value']))code = get_country_code(country_name)if code:cc_populations[code] = population# 为了使颜色分层更加明显
cc_populations_1,cc_populations_2, cc_populations_3 = {}, {}, {}
for cc, population in cc_populations.items():if population < 10000000:cc_populations_1[cc] = populationelif population < 1000000000:cc_populations_2[cc] = populationelse:cc_populations_3[cc] = populationwm_style = RotateStyle('#336699', base_style=LightColorizedStyle)
world = World(style=wm_style)
world.title = 'World Populations in 2015, By Country'
world.add('0-10m', cc_populations_1)
world.add('10m-1bn', cc_populations_2)
world.add('>1bn', cc_populations_3)
world.render_to_file('world_population_2015.svg')
有几个变量比较重要
cc_populations是一个dict,里面存放了两位国别码与人口的键值对。cc_populations_1,cc_populations_2, cc_populations_3这是3个字典,把人口按照数量分阶梯,人口一千万以下的存放在cc_populations_1中,一千万~十亿级别的存放在cc_populations_2中,十亿以上的存放在cc_populations_3中,这样做的目的是使得颜色分层更加明显,更方便找出各个阶梯里人口最多的国家。由于分了三个层次,在添加数据的的时候也add三次,把这三个字典分别传进去。world = World(style=wm_style)这是一个地图类,导入方法from pygal_maps_world.maps import Worldwm_style = RotateStyle('#336699', base_style=LightColorizedStyle)这里修改了pygal默认的主题颜色,第一个参数是16进制的RGB颜色,前两位代表R,中间两位代表G,最后两位代表B。数字越大颜色越深。第二个参数设置基础样式为亮色主题,pygal默认使用较暗的颜色主题,通过此方法可以修改默认样式。
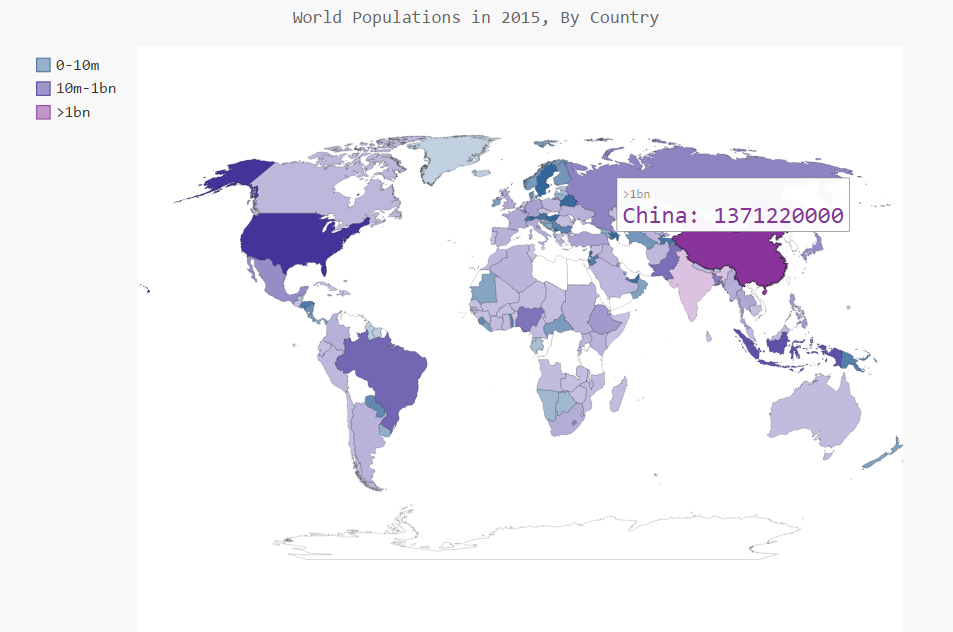
中国大佬,No. 1
图中可以看出,分的三个颜色层次为。紫色系,十亿以上;蓝色系,一千万到十亿之间;绿色系,一千万一下。这三种颜色里面颜色最深的就对应了三个阶梯里人口最多的国家。
<div class="image-package">
</div>
仔细观察,图中有些是空白的。并不是这些地方全部没人,而是我们的json数据中有些国家的名称与pygal中COUNTIES模块的国家名不对应导致。这算是一个遗憾,不过可以修改get_country_code函数,使得遇到不对应的国家名时,不返回None。对于这些国家,查阅COUNTRIES的代码,找出对应的国别码,返回之,应该就Ok了。比如下面这样
# 传入的参数country_name是json数据中的,可能与COUNTRIES里面的国家名不一致,按照上面的代码直接就返回None,导致绘图时这个国家的人口数据空白
if country_name == 'Yemen, Rep':return 'ye'
不过我懒得试了233
使用Web API分析数据
以GitHub为例,我想查看最受欢迎的Python库。以stars排序。
访问这个网址就可查看。数据大概长这样
{"total_count": 1767997,"incomplete_results": false,"items": [{{"id": 21289110,"name": "awesome-python","full_name": "vinta/awesome-python","owner": {"login": "vinta",...},... "html_url": "https://github.com/vinta/awesome-python",..."stargazers_count": 35234,...}, {...}...]
}
第三个数据,items。里面是得到stars最多的top 30。name即库名称,owner下的login是库的拥有者,html_url是该库的网址(注意owner下也有个html_url。不过那个是用户的GitHub网址,我们要定位到该用户的具体这个库,所以不要用owner下的html_url),stargazers_count至关重要,所得的stars数目。
顺便说下第一个键total_count,表示Python语言的仓库的总数;第二个键,incomplete_results,表示响应的值不完全,一般来说是false,表示响应的数据完整。
import requestsurl = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
response = requests.get(url)
# 200为响应成功
print(response.status_code, '响应成功!')
response_dict = response.json()total_repo = response_dict['total_count']
repo_list = response_dict['items']
print('总仓库数: ', total_repo)
print('top', len(repo_list))
for repo_dict in repo_list:print('\nName: ', repo_dict['name'])print('Owner: ', repo_dict['owner']['login'])print('Stars: ', repo_dict['stargazers_count'])print('Repo: ', repo_dict['html_url'])print('Description: ', repo_dict['description'])
其实像这样已经得到结果了
200 响应成功!
总仓库数: 1768021
top 30Name: awesome-python
Owner: vinta
Stars: 35236
Repo: https://github.com/vinta/awesome-python
Description: A curated list of awesome Python frameworks, libraries, software and resourcesName: httpie
Owner: jakubroztocil
Stars: 30149
Repo: https://github.com/jakubroztocil/httpie
Description: Modern command line HTTP client – user-friendly curl alternative with intuitive UI, JSON support, syntax highlighting, wget-like downloads, extensions, etc. https://httpie.orgName: thefuck
Owner: nvbn
Stars: 28535
Repo: https://github.com/nvbn/thefuck
Description: Magnificent app which corrects your previous console command.
...
可视化一下当然会更加直观。
pygal可视化数据
代码不是很难,有一个plot_dict比较关键,这是鼠标放在条形图上时,会显示出来的数据,键基本上都是固定写法,xlink里面时仓库地址,只要点击,浏览器就会新开一个标签跳转到该页面了!
import requestsimport pygal
from pygal.style import LightColorizedStyle, LightenStyleurl = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
response = requests.get(url)
# 200为响应成功
print(response.status_code, '响应成功!')
response_dict = response.json()total_repo = response_dict['total_count']
repo_list = response_dict['items']
print('总仓库数: ', total_repo)
print('top', len(repo_list))names, plot_dicts = [], []
for repo_dict in repo_list:names.append(repo_dict['name'])# 加上str强转,因为我遇到了'NoneType' object is not subscriptable (: 说明里面有个没有此项, 是NoneTypeplot_dict = {'value' : repo_dict['stargazers_count'],# 有些描述很长很长,选最前一部分'label' : str(repo_dict['description'])[:200]+'...','xlink' : repo_dict['html_url']}plot_dicts.append(plot_dict)# 改变默认主题颜色,偏蓝色
my_style = LightenStyle('#333366', base_style=LightColorizedStyle)
# 配置
my_config = pygal.Config()
# x轴的文字旋转45度
my_config.x_label_rotation = -45
# 隐藏左上角的图例
my_config.show_legend = False
# 标题字体大小
my_config.title_font_size = 30
# 副标签,包括x轴和y轴大部分
my_config.label_font_size = 20
# 主标签是y轴某数倍数,相当于一个特殊的刻度,让关键数据点更醒目
my_config.major_label_font_size = 24
# 限制字符为15个,超出的以...显示
my_config.truncate_label = 15
# 不显示y参考虚线
my_config.show_y_guides = False
# 图表宽度
my_config.width = 1000# 第一个参数可以传配置
chart = pygal.Bar(my_config, style=my_style)
chart.title = 'Most-Starred Python Projects on GitHub'
# x轴的数据
chart.x_labels = names
# 加入y轴的数据,无需title设置为空,注意这里传入的字典,
# 其中的键--value也就是y轴的坐标值了
chart.add('', plot_dicts)
chart.render_to_file('most_stars_python_repo.svg')
看下图,chrome浏览器里显示效果。总感觉config里面有些设置没有起到作用, x、y轴的标签还是那么小orz...不过plot_dict里面的三个数据都显示出来了,点击即可跳转。
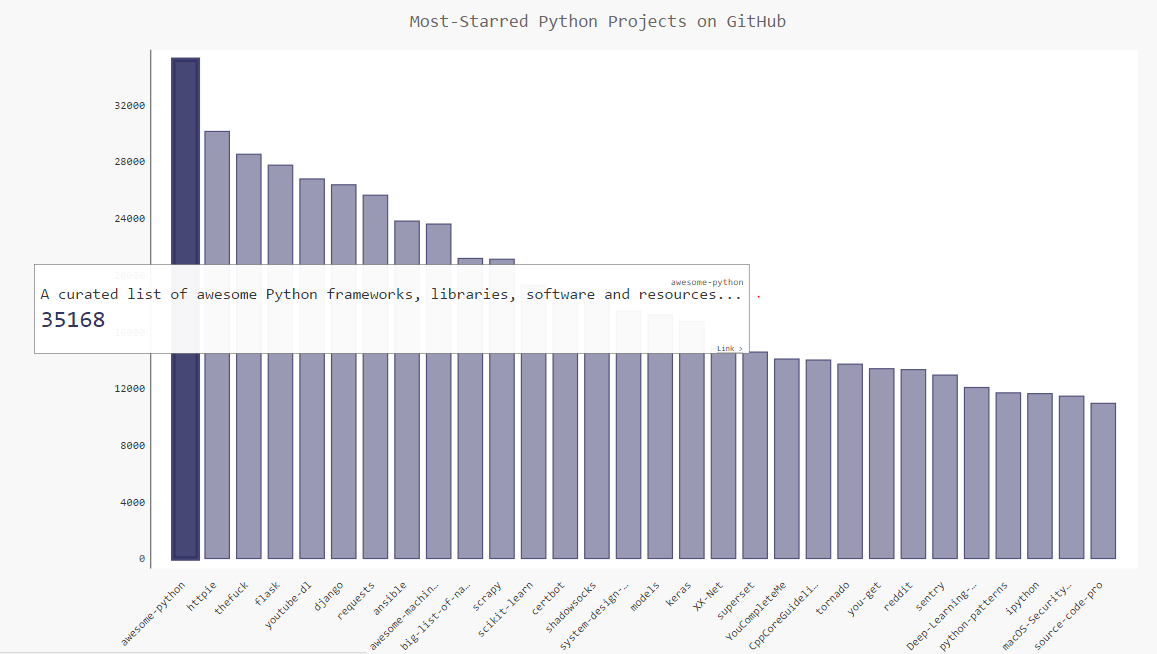
好了,就折腾这么多吧,这个库也不是特别大众的...
原文地址

python图表之pygal入门篇相关推荐
- Python:Excel自动化实践入门篇 甲【留言点赞领图书门票】
*以下内容为本人的学习笔记,如需要转载,请声明原文链接 微信公众号「ENG八戒」https://mp.weixin.qq.com/s?__biz=MzUxMTgxMzExNQ==&mid=22 ...
- Python+django建站入门篇(2):素数判断
本文使用django框架搭建网站,运行之后,获取用户输入的整数,判断是否为素数并进行相应的提示. 本文技术要点: 1)使用django创建网站 2)了解MVC开发模式 3)设置路由 4)接收用户输入 ...
- python机器人视觉编程——入门篇(下)
目录 1 全篇概要 2 图像的读取与运算基础 2.1图像的读取 2.1.1 从磁盘的图像(.jpg,.npg,.gif等等)读取 2.1.2 从摄像头里读取图像 2.2图像的运算 2.2.1 图像的数 ...
- python语言自学教程-3D图示Python标准自学教程入门篇
内容简介: Python入门篇教程从最基础的计算机发展史.Python的来源与发展历史开始讲起: 依次讲解python变量与表达式.数据类型.运算符.流程控制语句等,末尾通过课堂练习.课后作业以及微型 ...
- python自学教程-3D图示Python标准自学教程入门篇
内容简介: Python入门篇教程从最基础的计算机发展史.Python的来源与发展历史开始讲起: 依次讲解python变量与表达式.数据类型.运算符.流程控制语句等,末尾通过课堂练习.课后作业以及微型 ...
- python tree结构_Python入门篇-数据结构树(tree)篇
Python入门篇-数据结构树(tree)篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.树概述 1>.树的概念 非线性结构,每个元素可以有多个前躯和后继 树是n(n& ...
- python自学课堂_3D图示Python标准自学教程入门篇
内容简介: Python入门篇教程从最基础的计算机发展史.Python的来源与发展历史开始讲起: 依次讲解python变量与表达式.数据类型.运算符.流程控制语句等,末尾通过课堂练习.课后作业以及微型 ...
- python机器人视觉编程——入门篇(上)
目录 1 全篇概要(主要阅读对象及内容提要) 2 python知识点之--环境及依赖的库安装简述 2.1 Python开发环境安装 2.2 Python 机器视觉模块安装 2.3 写第一个Python ...
- python群控_带你用 Python 实现自动化群控入门篇
点击上方"AirPython",选择"加为星标"第一时间关注 Python 技术干货! 1. 前言 群控,相信大部分人都不会陌生!印象里是一台电脑控制多台设备完 ...
最新文章
- js layui 模板属性 添加_layui.laytpl--模板引擎文档
- prometheus监控耗时MySQL_Grafana+Prometheus监控mysql性能
- java 注解 属性 类型_收藏!你一定要知道的Java8中的注解
- C---蝉、蜻蜓、蜘蛛
- sql 2008服务器内存一直居高不下_经验之谈:内存问题造成数据库性能异常怎么破?...
- 在linux中显示所有正在运行的进程
- GitLab 发布安全修复版本:11.9.4, 11.8.6 和 11.7.10
- RHEL7/CentOS7在线和离线安装GitLab配置使用实践
- Win10系列:C#应用控件进阶10
- java applet怎么传参,使用不带浏览器的参数运行java applet
- SheetJS 读取excel文件转出json
- Dell笔记本周期性闪屏故障
- 免费的顶级域名要在哪申请?
- BI与SaaS碰撞,让数据处理更加轻松(下)
- 光阴似锦,关于身体保养的那些事
- c语言测序,Hi-C测序
- Simulink S function 采样时间
- [JVM]了断局:字节码执行引擎
- 【王道考研】吸烟者问题
- 用Python实现Flickr照片文本数据下载入库及图片保存(第一次帮忙)